深度稀疏自編碼網絡融合多LBP特征用于單樣本人臉識別
2019-12-11 10:00:03趙淑歡萬品哲郭昌隆
物聯網技術 2019年11期
關鍵詞:數據庫
趙淑歡 萬品哲 郭昌隆

摘 要:單樣本人臉識別的關鍵在于充分挖掘單樣本判別性信息,采用深度稀疏自編碼網絡與空頻域多LBP特征融合進行特征提取。首先利用部分樣本訓練深度稀疏自編碼網絡,利用訓練好的網絡分別提取訓練及測試集的特征;其次,利用二維離散小波變換將時域樣本變換到頻域,實現樣本擴展,增加單樣本信息并分別提取各域上的多LBP特征;最后利用協同表示對深度自編碼網絡及多LBP特征進行分類識別,融合識別結果獲取最終分類結果。在AR及PIE數據庫上的實驗結果表明,該融合算法能提高樣本判別性信息的提取,提高單樣本人臉識別性能。
關鍵詞:稀疏自編碼;單樣本人臉識別;空-頻特征;多特征融合;二維離散小波變換;數據庫
中圖分類號:TP181文獻標識碼:A文章編號:2095-1302(2019)11-00-05
0 引 言
人臉識別是計算機視覺和模式識別領域重要的研究課題,在生活中應用廣泛,如視頻監控[1]、門禁[2]、行人再識別[3]、視覺追蹤[4]等。盡管目前已有的人臉識別算法在特定環境下性能較好,但在實際測試中人臉可能含有多重面部變化,例如光照、陰影、姿勢、表情、遮擋、不對齊等[5],因此人臉識別仍是一項具有挑戰性的任務。
在許多實際應用場合中,每人僅有一個訓練樣本,例如ID卡認證、航空港監測等,導致在單樣本識別中很難根據訓練樣本預測測試樣本中可能出現的類內變化信息,因此單樣本人臉識別仍是人臉識別中的難點。而傳統的判別性子空間學習算法,例如線性判別分析(Linear Discriminant Analysis,LDA)[6]、基于Fisher的算法[7-8]在此種情況下會失效。基于表示的分類算法如稀疏表示(Sparse Representation-based Classifier,SRC)[9]和協同表示(Collaborative Representation-based Classifier,CRC)[10]要求每類用多個訓練樣本來有效表示測試樣本,因此其在單樣本識別中性能也會大幅下降。
為處理單樣本人臉識別,研究人員提出多種算法,這些算法大致可以分為兩類[11],即全局算法和局部算法。全局算法[12-13]用整張人臉圖像作為輸入,其主要思想是擴大訓練樣本數以捕捉類內信息。文獻[14]中有兩個方向,分別為虛擬樣本生成和通用學習。虛擬樣本生成利用真實訓練樣本合成虛擬樣本,例如SPCA[15]和SVD-LDA[16]基于奇異值分解(Singular Value Decomposition,SVD)生成虛擬樣本。這些算法的主要缺點是虛擬樣本往往與訓練樣本高度相關,因此很難作為獨立的樣本進行特征提取[14]。
與基于虛擬樣本算法不同,泛型學習方法通常會引入一個輔助泛型集,由不感興趣的人員來補充原始的SSPP(Single Sample per Person,SSPP)圖庫集。Wang等人[17]假設不同的人之間共享相似的類內變化,據此利用泛型集估計類內散度。基于表示的算法包括擴展的SRC(ESRC)[12]、疊加SRC(SSRC)[18]、稀疏變化字典學習(SVDL)[13]、協同概率標簽(CPL)[19]等。盡管這些算法可以在一定程度上提高單樣本人臉識別算法的性能,但其性能仍嚴重依賴于巧妙的選取泛型集,理想的泛型集通常包括兩個特點:需與訓練樣本有相似的拍攝場景;需包含足夠的面部變化來預測測試樣本中未知的變化。然而實際中很難收集到足夠多的滿足上述條件的泛型集。
局部算法利用局部面部特征識別測試樣本。通常生成局部特征的方法是將一張人臉樣本分割成一些重疊或不重疊的圖像塊,因此該類型的局部算法通常被稱作基于塊的方法[20]。該類方法中每個被劃分的塊都被看作是這個人的獨立樣本,基于該假設,研究人員將傳統的子空間學習和基于表示的分類算法(例如PCA,LDA,SRC,CRC)進行擴展得到對應基于塊的算法,例如塊PCA[21],塊LDA[22],塊SRC(PSRC)[9]和塊CRC(PCRC)[20],整合每個塊的識別結果,得到最終的單樣本人臉識別結果。Lu等人[14]提出一種判別性多流行學習算法(DMMA),將人臉識別轉換成域到域的匹配問題。基于這一工作,Yan等人[23]通過整合多個局部特征提出多特征多流形學習方法來提升人臉識別性能。Zhang等人[21]通過加入另一個基于稀疏圖的Fisher準則修正了DMMA算法,并為被劃分出來的塊學習一個判別性子空間。
最近,有研究人員嘗試將泛型學習整合到基于塊的方法中用于單樣本人臉識別。例如,Zhu等人[24]從泛型集中提取塊變化字典,然后將其與訓練塊字典串聯來度量每個測試塊的表示殘差。這類算法與現有的基于塊的表示方法相比可在單樣本人臉識別中獲得更好的性能,但理想的泛型集的獲取仍是實際應用中的難題。
本文將樣本投影到頻域空間以實現樣本的擴充,同時采用通用訓練集采集部分類內變化信息,減小類內變化導致的單樣本識別率下降現象,最后將空頻域的識別結果進行融合獲得最終的識別結果并在數據集上驗證。
1 相關工作
1.1 深度稀疏自編碼網絡
SSAE是一種無監督特征學習算法,該算法采用層級訓練方案構造深度網絡,每一層包含兩個部分,即編碼器和解碼器。編碼器為一個函數,可將輸入向量x映射到隱藏層表示a,即。解碼器將隱藏層表示映射成一個重構向量y,即。其中W(1)和W(2)分別表示輸入到隱藏層及隱藏層到輸入的權重;b(1)和b(2)分別表示隱藏層單元和輸出層單元的基;f(·)表示隱藏層單元的激活值,一般選用sigmoid函數;g(·)表示輸出單元的激活值,一般設置為g(x)=x。對SSAE每層訓練即最小化該層損失函數J:
式中:x(i)表示第i個訓練樣本,同時也是期望輸出;y(i)表示對應預測輸出;m表示訓練樣本的個數;h表示隱藏層單元的個數。相對熵懲罰項是為了增強隱藏層的稀疏度,參數表示第j個隱藏單元在訓練集上的平均激活度,而ρ表示稀疏度參數,其值接近0,采用反向傳播算法進行訓練。
建立并訓練SSAE后,隱藏層單元的激活度可作為下一層的輸入。逐層訓練SSAE的每一層,一旦SSAE的每一層都訓練好,則編碼器參數W和b可用于構建網絡。
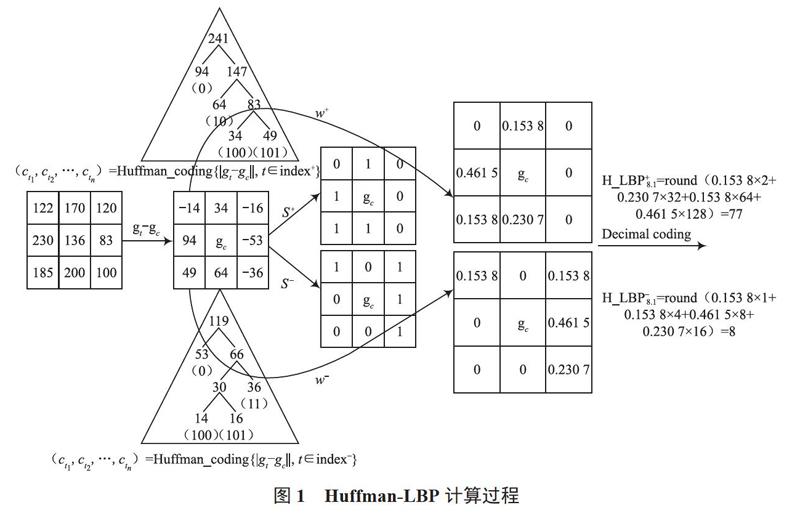
1.2 Huffman-LBP
為實現關于灰度任何單調變換的不變性,LBP僅考慮對比度值的符號[26],而LBP的這種屬性有時會導致意想不到的混亂,致使兩組不同的圖像紋理進行LBP編碼后得到相同的結果。霍夫曼編碼通常用于無損數據壓縮[27],然而很少有研究人員將霍夫曼編碼應用于特征提取。為了解決LBP紋理信息丟失的問題,文獻[25]首先采用霍夫曼編碼對對比度值進行加權,以補充豐富的紋理信息,這種新方法被稱為Huffman-LBP。
霍夫曼編碼使用可變長度碼字實現對源碼元的編碼,根據頻率確定編碼。頻率較大的符號將用較少的位表示,即在霍夫曼樹中,接近根節點的葉節點頻率較小;遠離根節點的葉節點頻率較大。此外,每個葉節點霍夫曼碼的長度與葉節點和根節點之間的距離一致。霍夫曼樹,以gt-gc(t=0, 1, ..., p-1)的絕對值作為每個葉節點的頻率,得到相應的霍夫曼碼,根據代碼長度,度量對比度值的權重。
圖1所示為Huffman-LBP計算過程,從Huffman-LBP編碼過程中可知Huffman-LBP包含正值和負值,它們表示對比度值的符號信息。且霍夫曼編碼可以測量周圍像素之間相對精確的重量關系。使用新穎的編碼規則后,對比度值的符號不再是唯一的編碼對象,對比度值的大小也將在編碼過程中發揮作用。從圖1可以看出,通過補充對比度值的權重信息可以提高LBP的辨別能力。雖然兩組不同的圖像紋理具有相同的二進制編碼(s+和s-),但使用Huffman-LBP編碼后它們會得到不同的特征值。
此外,一些LBP的改進算法可通過在編碼過程中補充對比度值的評估來實現更好的性能識別,但必須考慮參數優化設置問題,例如選擇LTP閾值和設置LMLCP層數將嚴重影響最終的識別結果,而霍夫曼編碼將自動評估對比度值的權重,其優勢在于其非交互性屬性,這意味著它可以靈活工作。Huffman-LBP直方圖可以通過累加像素的Huffman-LBP值來獲得,然后將其用作模式特征來分類人臉圖像。
1.3 本文算法
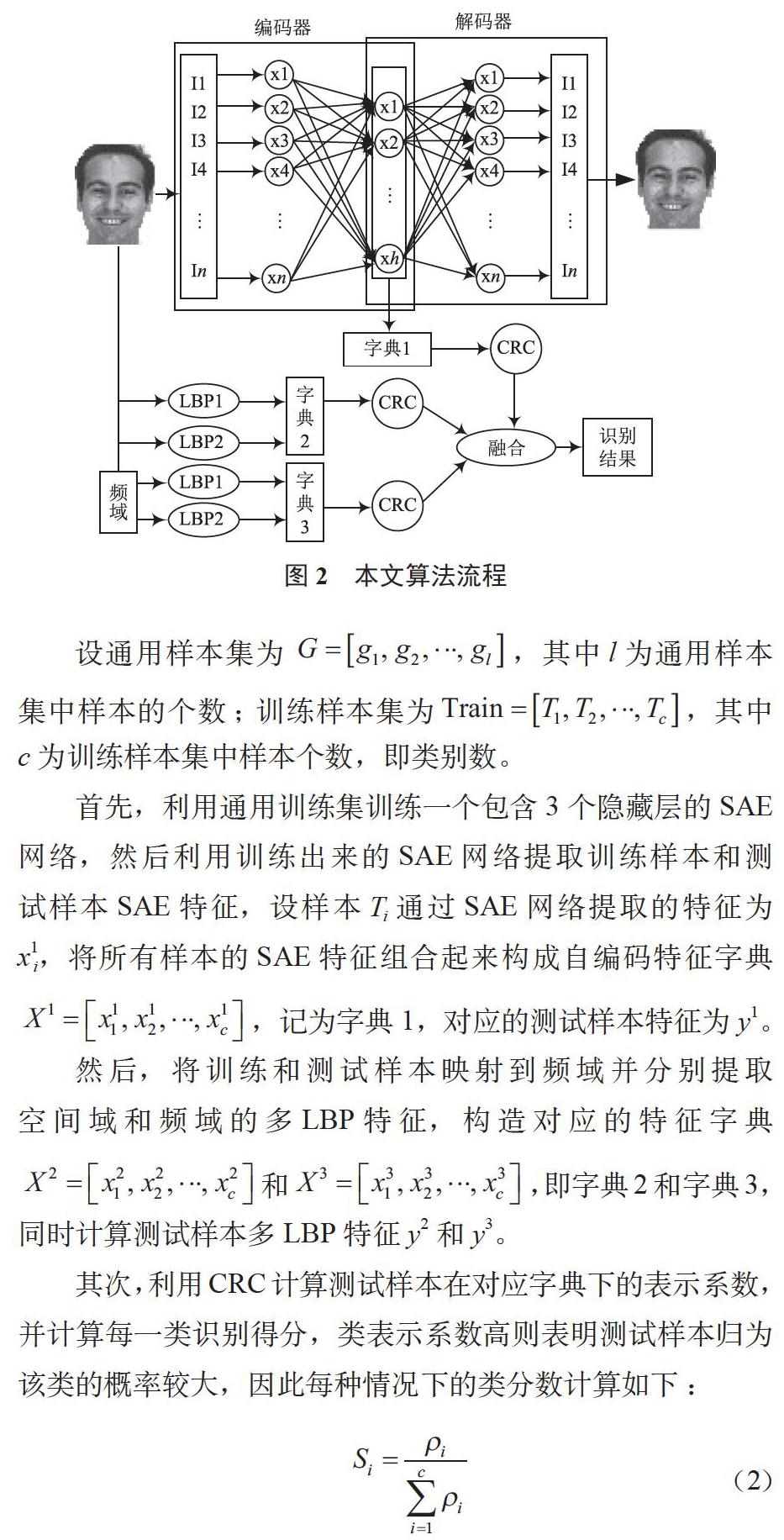
本文提出一種融合深度SAE及空頻域的多LBP特征算法(SAE_MLBP)以解決單樣本人臉識別問題,算法流程如圖2所示。
設通用樣本集為,其中l為通用樣本集中樣本的個數;訓練樣本集為,其中c為訓練樣本集中樣本個數,即類別數。
首先,利用通用訓練集訓練一個包含3個隱藏層的SAE網絡,然后利用訓練出來的SAE網絡提取訓練樣本和測試樣本SAE特征,設樣本Ti通過SAE網絡提取的特征為x1i,將所有樣本的SAE特征組合起來構成自編碼特征字典,記為字典1,對應的測試樣本特征為y1。
然后,將訓練和測試樣本映射到頻域并分別提取空間域和頻域的多LBP特征,構造對應的特征字典和,即字典2和字典3,同時計算測試樣本多LBP特征y2和y3。
其次,利用CRC計算測試樣本在對應字典下的表示系數,并計算每一類識別得分,類表示系數高則表明測試樣本歸為該類的概率較大,因此每種情況下的類分數計算如下:
最后,將各字典下各類的識別得分求和,得出最終得分值,并將測試樣本歸類為分值最高的類。
2 實驗
2.1 AR數據庫
為驗證算法性能,在數據集AR上進行測試,并與時域LBP算法(SLBP_CRC)、頻域LBP(FLBP_CRC)算法作對比。
首先在AR數據庫上測試各算法的性能,選擇前1~30人的每人13張圖像作為通用訓練集,其余90人從V1~V7中選擇一張圖像作為訓練樣本。測試分為如下3種情況:
(1)無遮擋情況下每人選取前7張照片中除訓練樣本外的其余6張作為測試樣本,即測試樣本數量為90×6=540;
(2)每人選取3張墨鏡遮擋圖像作為測試樣本,即測試樣本數量為90×3=270;
(3)每人選取三張圍巾遮擋圖像作為測試樣本,即測試樣本數量為90×3=270。
每組實驗分別選取不同的樣本作為訓練樣本,運行7次,計算平均結果作為最終的測試結果,見表1所列。
從表1的結果可以看出,與ESRC算法及SAE特征相比,本文算法聯合空頻域并融合深度自編碼網絡提取的特征可有效提高算法的識別率。圖3記錄了不同訓練樣本下本文算法的識別率,可以看出,當訓練樣本為每類的V3時,識別率均下降,而將每類的V5作為訓練樣本時,識別率較高。觀察V3,V5樣本可以發現,與其他樣本相比V3樣本中眼睛張開程度較小,V5則更接近自然狀態下的樣本。V2和V4也含有表情變化但大部分表情信息體現在嘴部變化,由此可知眼睛在人臉識別中包含重要的判別性信息。口罩遮擋的識別率明顯低于墨鏡遮擋的識別率,說明遮擋比例過大時人臉判別性信息丟失較為嚴重。
與ESRC算法相比發現本文在墨鏡遮擋識別情況下可有效提高算法的識別率,說明本文算法能夠有效提取眼部之外的信息。而其他兩種情況下,相比于ESRC算法,本文算法的識別率亦有大幅提高。AR數據庫上不同訓練樣本下本文算法的識別率如圖4所示。
為進一步分析本文算法與ESRC算法性能,本文將兩種算法的運行時間進行比較,發現本文算法的運行時間遠低于ESRC算法的運行時間。因SAE網絡可利用通用訓練樣本集提前訓練好,因此本文不考慮SAE網絡的訓練時間。不同訓練樣本下,本文算法與ESRC算法運行時間如圖5所示。
2.2 PIE數據庫
PIE數據庫包含68個人5種視角下的人臉圖片,每個視角下的圖像還包含光照及表情變化,姿勢1共包含49張圖像,姿勢2共包含24張圖像,姿勢3共包含24張圖像,姿勢4共包含49張圖像,姿勢5共包含24張圖像。部分PIE實例如圖6所示,可見該數據庫進行人臉識別測試面臨的主要挑戰是姿勢變換,其次為光照及表情變化。
[14] LU J,TAN Y P,WANG G. Discriminative multimanifold analysis for face recognition from a single training sample per person [J]. IEEE transactions on pattern analysis and machine intelligence,2013,35(1):39-51.
[15] ZHANG D,CHEN S,ZHOU Z H. A new face recognition method based on SVD perturbation for single example image per person [J]. Applied mathematics and computation,2005,163(2):895-907.
[16] GAO Q X,ZHANG L,ZHANG D. Face recognition using FLDA with single training image per person [J]. Applied mathematics and computation,2008,205(2):726-734.
[17] WANG J,PLATANIOTIS K N,LU J,et al. Venetsanopoulos,On solving the face recognition problem with one training sample per subject [J]. Pattern recognition,2006,39(9):1746-1762.
[18] DENG W,HU J,GUO J. In defense of sparsity based face recognition [C]// Proceedings of CVPR,2013:399-406.
[19] JI H K,SUN Q S,JI Z X,et al. Collaborative probabilistic labels for face recognition from single sample per person [J]. Pattern recognition,2017,62:125-134.
[20] ZHANG P,YOU X,OU W,et al. Sparse discriminative multi-manifold embedding for one-sample face identification [J]. Pattern recognition,2016,52:249-259.
[21] GOTTUMUKKAL R,ASARI V K. An improved face recognition technique based on modular PCA approach [J]. Pattern recognition letters,2004,25(4):429-436.
[22] CHEN S,LIU J,ZHOU Z H. Making FLDA applicable to face recognition with one sample per person [J]. Pattern recognition,2004,37(7):1553-1555.
[23] YAN H,LU J,ZHOU X,et al. Multi-feature multi-manifold learning for single-sample face recognition [J]. Neurocomputing,2014,143:134-143.
[24] ZHU P,YANG M,ZHANG L,et al. Local generic representation for face recognition with single sample per person [C]// Proceedings of ACCV,2014:34-50.
[25] L F ZHOU ,Y W DU,W S LI,et al. Pose-robust face recognition with Huffman-LBP enhanced by divide-and-rule strategy [J]. Pattern recognition,2018,78:43-55.
[26] AHONEN T,HADID A,PIETIK?INEN M. Face description with local binary patterns:application to face recognition [J]. IEEE trans. pattern anal. mach. Intel,2006,28(12):2037-2041.
[27] KAVOUSIANOS X,KALLIGEROS E,NIKOLOS D. Optimal selective Huffman coding for test-data compression [J]. IEEE trans. comput.,2007,56(8):1146-1152.
猜你喜歡
財經(2017年15期)2017-07-03 22:40:49
財經(2017年2期)2017-03-10 14:35:35
華東師范大學學報(自然科學版)(2017年1期)2017-02-27 13:41:08
財經(2016年15期)2016-06-03 07:38:02
財經(2016年3期)2016-03-07 07:44:46
財經(2016年6期)2016-02-24 07:41:51
財經(2015年3期)2015-06-09 17:41:31
財經(2014年21期)2014-08-18 01:50:18
財經(2014年6期)2014-03-12 08:28:19
財經(2013年6期)2013-04-29 17:59:30
