我國(guó)居民保險(xiǎn)購(gòu)買行為的決策樹(shù)模型分析
2019-12-11 10:12:50王姍姍
現(xiàn)代商貿(mào)工業(yè) 2019年35期
王姍姍

摘 要:近幾年許多行業(yè)都步入大數(shù)據(jù)時(shí)代,但數(shù)據(jù)挖掘技術(shù)在我國(guó)保險(xiǎn)領(lǐng)域的應(yīng)用相對(duì)不多,并且我國(guó)保險(xiǎn)公司也要考慮通過(guò)改變傳統(tǒng)的經(jīng)營(yíng)方法來(lái)提升業(yè)績(jī),因此加大對(duì)數(shù)據(jù)的利用力度,過(guò)渡到數(shù)字化營(yíng)銷模式對(duì)保險(xiǎn)公司來(lái)說(shuō)十分關(guān)鍵。主要研究決策樹(shù)算法在保險(xiǎn)公司客戶識(shí)別方面的應(yīng)用,根據(jù)加入誤分代價(jià)的決策樹(shù)模型建立的分類規(guī)則,找出了影響我國(guó)居民是否購(gòu)買保險(xiǎn)產(chǎn)品的主要因素。
關(guān)鍵詞:決策樹(shù);誤分代價(jià);基尼指數(shù)
中圖分類號(hào):F23 文獻(xiàn)標(biāo)識(shí)碼:A doi:10.19311/j.cnki.1672-3198.2019.35.059
1 數(shù)據(jù)處理
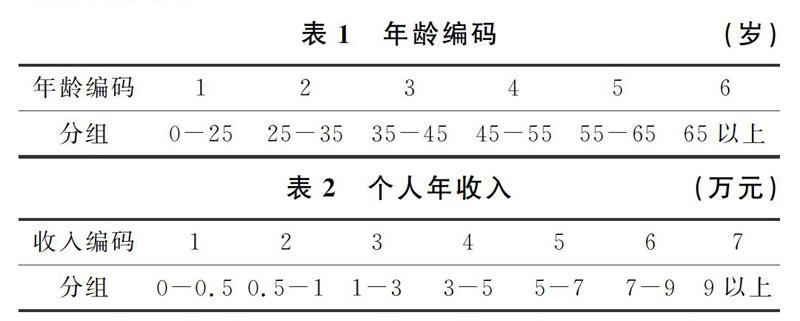
選取2015年中國(guó)綜合社會(huì)調(diào)查數(shù)據(jù),根據(jù)相關(guān)研究選取其中的性別、年齡、個(gè)人年收入、是否擁有城市/農(nóng)村基本醫(yī)療保險(xiǎn)情況這四個(gè)影響因素。性別是名義變量,給男性賦值1,女性賦值2。將年齡以及個(gè)人年收入進(jìn)行分段劃分,并且對(duì)這兩個(gè)影響因素?cái)?shù)據(jù)進(jìn)行離散化處理。
初始數(shù)據(jù)共有10968條,對(duì)其進(jìn)行精簡(jiǎn),只保留明確回答是否購(gòu)買了商業(yè)醫(yī)療保險(xiǎn)的數(shù)據(jù),即購(gòu)買了或是未購(gòu)買的,凡是回答“無(wú)法回答、拒絕回答、不知道、不適用”的都不適用于本文的研究,故直接將其舍去,處理后的數(shù)據(jù)為10747條。對(duì)于其中個(gè)人年收入的缺失值對(duì)其進(jìn)行同類插補(bǔ)將其補(bǔ)齊。最后得到的數(shù)據(jù)中購(gòu)買商業(yè)醫(yī)療保險(xiǎn)的居民有950個(gè),未購(gòu)買商業(yè)醫(yī)療保險(xiǎn)的居民有9797個(gè)。
2 決策樹(shù)分析
2.1 樣本不平衡處理
由于本文中購(gòu)買商業(yè)醫(yī)療保險(xiǎn)的居民有950個(gè),未購(gòu)買商業(yè)醫(yī)療保險(xiǎn)的居民有9797個(gè),樣本存在嚴(yán)重的不平衡性,因此我們?cè)诮r(shí)要對(duì)購(gòu)買了商業(yè)醫(yī)療保險(xiǎn)的樣本增加誤分代價(jià)。
2.2 模型建立
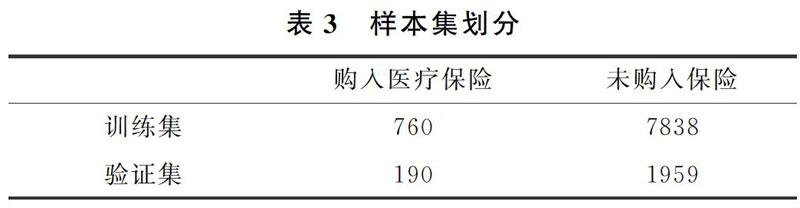
決策樹(shù)是使用類似于一棵樹(shù)的結(jié)構(gòu)來(lái)表示類的劃分,樹(shù)的構(gòu)建可以看成是變量(屬性)選擇的過(guò)程,內(nèi)部節(jié)點(diǎn)表示樹(shù)選擇哪幾個(gè)變量(屬性)作為劃分,每棵樹(shù)的葉節(jié)點(diǎn)表示為一個(gè)類的標(biāo)號(hào),樹(shù)的最頂層為根節(jié)點(diǎn)。本文用CART決策樹(shù)(回歸樹(shù))對(duì)居民是否購(gòu)買醫(yī)療保險(xiǎn)進(jìn)行分類,該算法是一個(gè)二叉樹(shù),即每一個(gè)非葉節(jié)點(diǎn)只能引申出兩個(gè)分支,因此十分適合用于本文的研究。將處理過(guò)后的10747條樣本劃分為訓(xùn)練集和驗(yàn)證集,隨機(jī)抽取80%為訓(xùn)練集,剩下的20%為驗(yàn)證集。
決策樹(shù)算法中包含最核心的兩個(gè)問(wèn)題,即特征選擇和剪枝,關(guān)于特征選擇目前比較流行的方法是信息增益、增益率、基尼系數(shù)和卡方檢驗(yàn)。CART算法的特征選擇就是基于基尼系數(shù)得以實(shí)現(xiàn)的,其選擇的標(biāo)準(zhǔn)就是每個(gè)子節(jié)點(diǎn)達(dá)到最高的純度,即落在子節(jié)點(diǎn)中的所有觀察都屬于同一個(gè)分類。
依次計(jì)算出各個(gè)屬性的基尼指數(shù),并比較各屬性基尼指數(shù)的大小得到個(gè)人年收入的基尼指數(shù)最大,從而確定個(gè)人年收入為第一個(gè)劃分屬性。個(gè)人年收入基尼指數(shù)計(jì)算步驟如下:
首先在對(duì)樣本劃分前,總的訓(xùn)練數(shù)據(jù)共有2類,即N=2,其中參與商業(yè)保險(xiǎn)的居民共有760,未參與商業(yè)保險(xiǎn)的居民共7878,D=7118。
首先利用個(gè)人年收入進(jìn)行劃分,此屬性共有7個(gè)值,K=7,即a1=1,a2=2,a3=3, a4P=4,a5=5,a6=6,a7=7,數(shù)據(jù)集劃分成1個(gè)集合,即D1,D2,D3,D4,D5,D6,D7。
其中Dk表示包含個(gè)人年收入為編碼取k的樣本,Dk表示總共有多少個(gè)樣本位于此區(qū)間,其中購(gòu)買了醫(yī)療保險(xiǎn)的有X人,Py=1=P1=XDk表示a=k時(shí)購(gòu)買了商業(yè)醫(yī)療保險(xiǎn)的人數(shù)占樣本總體的比例,Py=-1=P2=Dk-XDk表示未購(gòu)買醫(yī)療保險(xiǎn)的比例。
購(gòu)買商業(yè)醫(yī)療保險(xiǎn)的樣本量比未購(gòu)買商業(yè)保險(xiǎn)的樣本量少很多,因此使用加入誤分代價(jià)的CART決策樹(shù)模型,根據(jù)樣本中購(gòu)買了醫(yī)療保險(xiǎn)和未購(gòu)買醫(yī)療保險(xiǎn)的人數(shù)比例進(jìn)行設(shè)置誤分代價(jià)如表5。
進(jìn)行建模得到的決策樹(shù)風(fēng)險(xiǎn)如表6。
從上表可以看出分類的標(biāo)準(zhǔn)誤差很低,說(shuō)明分類的效果比較理想,得到簡(jiǎn)單樹(shù)形圖為圖1。
2.3 模型結(jié)果解釋
建模得到的特征重要性如表7所示。
可以看到影響到我國(guó)居民是否購(gòu)買商業(yè)醫(yī)療保險(xiǎn)的因素由重要性的從高到低依次為您個(gè)人去年全年的總收入、是否參加基本醫(yī)療保險(xiǎn)、年齡、性別。從這點(diǎn)我們可以看出,收入是一個(gè)人是否會(huì)購(gòu)買商業(yè)醫(yī)療保險(xiǎn)的首要決定因素,當(dāng)收入達(dá)到一個(gè)較高水平時(shí)居民會(huì)選擇購(gòu)買商業(yè)醫(yī)療保險(xiǎn),例如在本文的模型中可以看到收入高于9萬(wàn)元時(shí)居民會(huì)購(gòu)買商業(yè)醫(yī)療保險(xiǎn),這說(shuō)明我國(guó)居民在家庭較為富裕的情況下才會(huì)考慮為自己購(gòu)買醫(yī)療保險(xiǎn)增加保障。
對(duì)于保險(xiǎn)公司來(lái)說(shuō),需要在營(yíng)銷時(shí)著重了解潛在客戶的收入情況,將收入較高的潛在客戶作為首要推銷目標(biāo),降低營(yíng)銷成本。
參考文獻(xiàn)
[1]王星,謝邦昌,戴穩(wěn)勝.數(shù)據(jù)挖掘在保險(xiǎn)業(yè)中的應(yīng)用[J].數(shù)據(jù),2004,24(4):50-51.
[2]王書爽.基于后修正貝葉斯決策樹(shù)模型的保險(xiǎn)企業(yè)營(yíng)銷決策[J].統(tǒng)計(jì)與決策,2013,14(3):180-182.
[3]Zhang Y,Chi 在X,Xie F D,Li N.A weights-based accuracy evaluation method for multi class multipliable classifier [J].Journal of Computational Information Systems,2008,4(2):589-594.
[4]Bolton R N,Kennan P K,Bramlett M D.Implications of loyalty program membership and service experiences for customer relation and value [J].Journal of the Academy of Marketing Svience,2000,20(1):95-108.
