全卷積神經網絡研究綜述
2020-01-06 02:07:02袁非牛張文睿曾夏玲
計算機工程與應用 2020年1期
章 琳,袁非牛,張文睿,曾夏玲
1.江西科技師范大學 數學與計算機科學學院,南昌330038
2.上海師范大學 信息與機電工程學院,上海201418
1 引言
卷積神經網絡已被廣泛地應用于很多視覺研究領域[1],比如圖像分類、人臉識別、音頻檢索、ECG 分析等。卷積神經網絡之所以取得如此巨大的成功是因為其所采用的卷積、池化等操作。卷積操作具有局部連接、權值共享的特點,能很好地保留二維數據的空間信息,而池化操作能夠很好地滿足平移不變性,這在分類任務中非常重要。但是卷積神經網絡有一個很大的缺陷,就是網絡輸入必須指定大小,而且一般只能進行一對一的預測,即一個輸入只能得到一個預測結果。但是隨著視覺領域的發展,這種預測已經無法滿足要求,完成的任務越來越復雜,往往需要的是密集預測,即輸入對象中的每一個元素都需要進行預測,這是卷積神經網絡無法完成的,而全卷積神經網絡就是在這種需求下被提出的。
顧名思義,全卷積神經網絡中包含的都是卷積層,根據任務需要可以適當保留池化層,為了完成密集預測,卷積神經網絡中的全連接層必須被卷積層替代,這也是全卷積神經網絡最大的特點之一。由于保留了卷積和池化操作,全卷積神經網絡具有卷積神經網絡的所有特點,此外,全卷積神經網絡對于輸入非常寬容,可以處理任意大小的輸入信號。早在1992 年,Matan 等[2]就已經將一個卷積神經網絡擴展為可以處理任意大小輸入信號,但是該網絡僅能處理一維信號;而在1994 年,Wolf等[3]將輸入信號擴展為二維圖像,提出了一個卷積定位網絡對郵政地址進行定位,該方法完全可以被看作全卷積神經網絡,因為其網絡結構中僅采用了卷積和下采樣操作,然后通過一個后續的候選框產生方法來完成定位任務。盡管該方法與后期的全卷積神經網絡有較大差距,并且不是端對端的,但是它為全卷積神經網絡的發展奠定了堅實的基礎。
目前,全卷積神經網絡被廣泛應用于目標分割、目標檢測、目標分類等研究領域,并取得了令人矚目的成果。下面,將分別介紹多個研究領域中一些比較經典的全卷積神經網絡算法以及目前一些最新的研究進展。
2 目標語義分割
語義分割,即密集分類問題,需要對輸入圖像中的每個像素點都進行分類來完成目標分割任務,任務最后的輸出是一張與原圖大小相關的分類結果圖,圖中每個值對應的是原圖中每個點的分類預測結果。由于語義分割能實現各類目標之間的精確分割,因此被廣泛應用于自動駕駛、醫療、地理、機器人等研究領域。
2.1 全監督語義分割
2.1.1 FCN
FCN[4]語義分割算法是在2015年提出的,它第一次真正實現了全卷積神經網絡在像素級預測任務上的端對端訓練。FCN算法通過將原始CNN網絡中的全連接層替換為1×1 的卷積層來實現全卷積網絡結構,如圖1所示。通過這個操作,FCN可以對圖像中的每個像素點都產生一個預測結果,最終輸出一個與輸入圖像大小相關的預測圖。在結果預測階段,提出了一種可學習的雙線性上采樣方法,實驗證明該方法優于采用固定參數的上采樣方法。為使分割結果更加精細,FCN采用了跳層結構,將來自多個不同層的特征圖上采樣到同樣大小后,通過求和的方式進行融合。由于淺層信息的加入,輸出結果的語義和空間精度得到了有效提升。此外,為了使網絡可以快速收斂,利用多種網絡結構在ImageNet上訓練好的權重對網絡參數進行初始化,然后再使用語義分割的訓練數據集對網絡參數進行微調。FCN 對AlexNet[5]、VGG16[6]和GoogLeNet[7]進行了微調,其中VGG16效果最好。

圖1 FCN框架圖
FCN有以下優點:1×1卷積層的使用使網絡可以處理任意大小的輸入;基于塊的方法需要在重疊塊上進行很多冗余計算,而FCN 中感受野的顯著重疊使得網絡在前饋和反饋計算中更加高效。FCN也存在以下缺陷:首先網絡整體規模過大,很難在相關任務上完成端對端訓練;其次,由于預測結果由多個下采樣后的特征圖通過上采樣直接產生,這些特征圖太過稀疏,導致分割結果不夠精細,缺乏細節信息。FCN通過跳層結構將來自不同層的特征圖進行有效融合能有效提升分割精度。這是由于FCN 中較深的層能學習到目標的全局特征,而較淺的層則可以捕獲目標的大量細節信息,這種信息的互補對目標分割任務有利。
2.1.2 U-net
U-net[8]是在2015 年提出的一個用于醫學圖像分割的全卷積網絡結構。它是一個對稱編-解碼網絡結構。U-net 也采用了FCN 的跳層結構,但兩者有較大區別:U-net 將編碼階段獲取的特征圖傳送到對應的解碼階段,并通過連接的方式融合來自不同階段的特征圖。U-net 采用的是3×3 的非填補卷積操作,因此每經過一次卷積,特征圖會縮小2×2個像素,為了實現連接操作,特征在傳送過程中還進行了裁剪。
U-net 另一個亮點在于針對生物細胞圖像的特點,提出了一個加權交叉熵損失函數:

其中,ω 是一個權重圖譜,通過形態學操作的方式計算獲得:
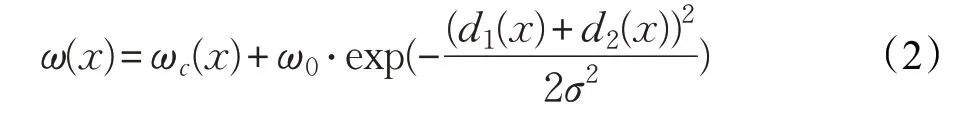
損失函數的目的是為了補償訓練數據集中每類像素出現的不同頻率,使網絡將重點放在相互接觸的細胞之間比較細微的區域。此外,采用了He等[9]提出的自適應權重初始化方法:采用標準方差為的高斯分布去初始化權重,其中N 為神經元輸入結點的數量。
2.1.3 SegNet
SegNet[10]與U-net非常相似,但二者又有明顯不同,首先SegNet沒有采用跳層結構;其次,SegNet的編碼階段直接采用了VGG16的前5個塊,為了加快收斂抑制過擬合,還在每個卷積層后面增加了一個Batch Normalization(BN)[11],SegNet 使用VGG16 在ImageNet 上訓練好的權重來進行網絡初始化。
SegNet 最大的亮點在于提出了一種更加有效的unpool方法。作者指出語義分割中邊界輪廓至關重要,在內存條件允許的情況下,編碼階段所有特征圖的邊界信息都應該被保存,但這并不符合實際,因此提出了一種更加有效的方法去存儲邊界信息。該方法與原始unpool[12]的相同之處是,在編碼階段都需要保存下采樣操作中最大特征值在每個池化窗口中的位置信息,文中稱之為最大池化索引,然后在解碼階段,利用最大池化索引對輸入的特征圖進行上采樣。不同之處在于最大池化索引的保存方式,原始unpool 采用的是浮點精度,而SegNet僅采用2 bit數據量就完成了存儲,這使得SegNet的網絡規模大幅度減小,具有更快的運行速度。
2.1.4 Deeplab系列算法
Deeplab 系列算法包括deeplab v1[13]、v2[14]、v3[15]和v3+[16]。Deeplab v1是2016年提出的,它將FCN與全連接條件隨機場相結合,分割性能有了很大提升。主要原因在于:首先,為了改善FCN 分割結果太過稀疏的問題,deeplab v1將VGG16中最后兩個池化層的步長由2改為1,同時采用邊界補0 的方式使池化之后的特征圖盡量保持原有大小;其次,為了保證后續卷積層的感受野不受影響,deeplab v1 將最后3 個卷積層和第一個全連接層替換為步長為2和4的空洞卷積(hole algorithm);為了減少計算時間,改用4×4或3×3的卷積核去替換第一個全連接層中的7×7卷積核。經過以上操作,deeplab v1 的輸出比FCN 增大了4 倍。由于分割結果邊緣過于平滑,在網絡后端增加了一個全連接條件隨機場去銳化分割邊緣。這樣做雖然可以獲取很好的邊緣細節,但是全連接條件隨機場的使用大大增加了算法的計算復雜度。
2017年deeplab v2被提出[14],它在v1的基礎上進行了兩方面改進,首先將基礎網絡改為ResNet101[17];然后提出了空洞空間金字塔池化(ASPP)以實現目標在多個尺度上的魯棒分割。ASPP是受到R-CNN[18]中空間金字塔池化方法的啟發,對同一特征圖同時采用多個并行的帶有不同采樣率(rate)的空洞卷積層以實現多尺度,然后對不同采樣率提取的特征在各自的分支中做進一步的處理并以求和方式進行融合,產生最終結果。ASPP能捕獲目標的多尺度信息,空洞卷積的引入解決了特征分辨率和感受野之間的矛盾,為獲取足夠大的感受野,空洞卷積需要足夠大的采樣率,當采樣率過大時會造成空洞卷積操作無效以及算法復雜度劇增的后果。
同年12 月,deeplab v3[15]問世,它的一個明顯不同就是不再使用全連接條件隨機場。同時做了以下改進:通過級聯方式提出了一個更深的網絡模型,復制ResNet網絡最后一個塊(即block4)的幾個副本(即block5-block7),將這些副本通過級聯方式連接到網絡后端,每個塊包含3個3×3的卷積層,除了最后一個塊,其他塊的最后一個卷積層采用的步長都為2。還提出了一種稱為Multi-gird的方法,即在網絡中的block4到block7采用了具有不同rate 的空洞卷積。在ASPP 中加入了BN[11],將rate=24的空洞卷積替換為一個1×1的卷積,并且加入了圖像級特征。這個改進就是為了解決當采樣率過大時,卷積核的大小可能會超過特征圖,這種情況下卷積會退化為一個只有中心點權重有效的1×1濾波器。
2018 年,deeplab 系列作者提出了deeplab v3+算法[16]。相比之前的算法,v3+的網絡結構有較大改變,它在網絡中加入了一個簡單但有效的解碼模型,如圖2所示。v3+模型采用v3 網絡作為編碼模型,并將其中的ResNet101 替換為Xception[19],并增加了其深度;此外,為了減少網絡參數,在ASPP 模塊和解碼模型中引入了深度可分離卷積(depth wise separable convolution)[19],對于模型中的空洞卷積,則采用空洞可分離卷積替換。此外,將網絡中所有的最大池化層替換為步長為2的深度可分離卷積,并且在每個3×3的深度可分離卷積后面都增加了BN和ReLU操作。
根據對deeplab 算法的分析,在網絡設計方面可以歸納出一些結論:(1)采用空洞卷積能有效提升分割結果的分辨率,使細節信息更加豐富;(2)全連接條件隨機場能有效恢復分割結果的細節,但其計算復雜度較高;(3)更深的網絡有利于獲取更有效的特征;(4)ASPP 能有效捕獲多個尺度的上下文信息,有效解決多尺度問題;(5)深度可分離卷積能有效減少模型參數數量,降低模型計算量,同時有效提升模型的表達能力;(6)編-解碼模型能使編碼階段計算速度更快,而解碼階段能通過逐步恢復空間信息獲取目標更好的邊緣細節[16]。
2.1.5 其他算法

圖2 Deeplab v3+網絡結構圖
RefineNet[20]是一個多通道微調全卷積網絡,提出的長距離殘差連接方法可以利用早期卷積層獲取的細粒度低階特征直接去微調更深層捕獲的高階特征。網絡的輸入來自ResNet 的4 個不同尺度的特征輸出,RefineNet模塊中包含殘差卷積單元,多分辨率融合單元以及鏈條式殘差池化單元,這種設計可以保證網絡中的梯度通過長距離殘差連接輕松地被傳播到較早的低階層,確保整個網絡可以進行端對端的訓練。
Peng 等[21]提出大部分網絡都偏向堆疊小尺寸卷積核,如1×1、3×3,原因在于當計算復雜度相同時,堆疊小卷積核效果更好。但是本文指出當需要同時進行分類和定位時,大卷積核反而更加重要,因此提出了一個采用大卷積核的全局卷積模塊以及提升目標邊緣精度的邊界微調模塊,當卷積核大小為11時效果最佳。
PSPNet提出了一個金字塔池化模塊[22],并將其嵌入全卷積網絡后端,該模塊包含多個并行的具有不同步長的全局均值池化操作,可以聚合更多的上下文信息,不同感受野下獲取的全局信息可以減少很多誤分割。DenseASPP 認為ASPP 獲取的特征圖尺度不夠豐富,感受野覆蓋范圍不夠密集[23],因此借鑒DenseNet 的思想,將ASPP以更加密集的方式進行連接、組合。
Cheng 等[24]提出了一個位置敏感反卷積模塊(LSDeconvNet),該模塊在deeplabv2 的基礎上增加了一個反卷積子網絡,網絡將RGB 圖像和由深度圖像編碼成的HHA 圖像并行送入LS-DeconvNet 并采用一個門控融合層合并兩個語義分割結果;黃龍等[25]通過層間融合方式提出了一種快速全卷積網絡,有效地避免了連續卷積層造成的圖像特征信息損失;Yuan等[26]則提出了一個雙支路非對稱編-解碼網絡結構對煙霧目標進行分割。
此外,文獻[26-31]都將全卷積網絡用于醫學圖像分割。Yuan 等[27]提出了一個編-解碼兩階段全卷積網絡,編碼階段包括5個卷積層、3個池化層和1個dropout層,解碼階段包括4 個反卷積層和3 個上采樣層,同時針對皮膚圖像中病變區域較小的特點提出了基于杰卡德距離的損失函數。文獻[28]中提出兩種全卷積網絡,第一種將三維大腦圖像分為冠狀位、矢狀位和軸狀位3種二維圖像,同時送入一個多尺度全卷積網絡,然后融合3個輸出獲取分割結果,這樣做有效地避免了使用計算量巨大的三維卷積;第二種模型是Auto-U-net,與U-net非常類似,最大的差別在于Auto-U-net 將U-net 中的卷積全部替換為填補卷積,即卷積層的輸入輸出大小一致。同樣的,文獻[29]和[30]也以U-net 為基礎進行改進,前者在編碼階段的最后引入一個門控循環神經元以獲取全局特征,并將網絡循環使用提出了一個周期全卷積網絡(RFCN);后者則在編碼階段加入了一個ASPP 模塊。Li 等[31]提出的全卷積殘差網絡能同時完成分割和分類任務,包括88 個卷積層和4 個反卷積層,其中采用了類似FCN[4]的跳層結構,同時為了加大網絡深度,還提出了一種Residual in Residual 結構。Jia 等[32]則提出了一個基于弱監督的全卷積網絡,利用多尺度學習提出了一個深度弱監督損失函數,同時為了獲取對學習過程有顯著幫助的額外弱監督信息,在網絡中引入了關于正樣本的約束條件。
文獻[32-34]都采用和deeplab v1近似的策略,在全卷積網絡后端增加一些后處理模塊來進一步提升分割精度。Zhang等[33]提出了一種基于概率超像素的全連接條件隨機場去改善全卷積網絡得到的粗糙分割圖,Sun等[34]則采用數字表面模型(DSM)去增強全卷積網絡的分割結果,黃英來等[35]則將改進后的FCN和全連接條件隨機場結合用于林木圖像分割。
之前介紹的都是基于圖像的語義分割,文獻[36-39]則是針對視頻的。He等[37]最大貢獻在于提出了一種時空數據驅動池化方法,該方法包括空間池化層、時間池化層和區域-像素池化層,首先利用全卷積網絡產生每一幀圖像的超像素分割圖,并且利用光流信息建立不同幀對應區域之間的聯系,最后采用提出的池化方法將兩者進行融合。在文獻[36-38]中,都采用了雙流結構來進行視頻目標分割。Qiu 等[38]利用二維像素和三維像素之間的空間和時間依賴性,提出了一種深度時空全卷積網絡,其中二維全卷積網絡與卷積長短期記憶模型(ConvLSTM)結合用于二維像素,三維全卷積網絡用于三維像素。而Caelles 等[39]和Jain 等[40]提出的雙流結構采用的是一樣的網絡結構,前者一條分支用于分割前景目標,另一條分支用于產生目標輪廓;后者一條分支用于學習視頻的外觀信息,另一條則用于學習光流信息。
2.2 弱監督語義分割
雖然基于FCN 的全監督語義分割取得了巨大成功,但是圖像標簽需要像素級標注,這是一項巨大的工程。因此,很多學者考慮是否可以采用一些比像素級標注更容易獲取的標注信息來替代,如圖像級標簽,這種方法被稱為弱監督語義分割。
2.2.1 STC
Wei等[41]提出了一種由分割簡單圖像逐步升級為分割復雜圖像的弱監督語義分割框架(STC),如圖3所示,模型中所有DCNN 均為全卷積結構。該方法的一個前提是假設簡單圖像只包含一個語義標簽,那么就可以通過顯著性方法將簡單圖像中的目標檢測出來,給前景候選像素直接分配相應的圖像級標簽,這就把問題轉換成了全監督語義分割,這部分工作由I-DCNN完成,其中采用的顯著性分割方法為判別區域特征融合(DRFI)[42]。第二階段為E-DCNN,它利用I-DCNN 對簡單圖像進行分割,同時結合圖像級標簽去訓練E-DCNN。最后階段為P-DCNN,和E-DCNN 策略一樣,利用E-DCNN 對復雜圖像進行預測,同時結合圖像級標簽去增強P-DCNN的分割能力。基于這個由簡單到復雜的模型,圖像分割結果被逐步優化。雖然STC在PASCAL VOC2012上取得了51.2%的成績,但該模型有兩個較大的缺陷,首先必須收集很多具有簡單背景單一目標的簡單圖像作為第一階段的訓練樣本,否則后續工作無法繼續;其次,STC需要分3個階段采用不同數據對網絡進行訓練,因此訓練過程復雜,時間過長。
在STC方法之后,針對弱監督語義分割還提出了很多方法[43-45],但這些方法中都包含了使用了全連接層的分類網絡,在此不做詳細介紹。
2.2.2 WILDCAT
WILDCAT[46]包括3個子網絡能同時完成圖像分類,檢測和分割任務,如圖4 所示。該結構以ResNet101 為骨干網絡用于提取圖像初級特征,通過1×1 卷積層,即圖中WSL轉換層,將初級特征編碼為多個特征圖,其中每類C 包含M 個,這部分僅使用圖像級標簽進行學習。為了總結來自多個特征圖的信息,采用平均池化將屬于同一類的M 個特征圖合并為一個特征圖,最后采用提出的空間池化對C 個來自不同類的特征圖進行分類、檢測和分割。
表1 給出了一些方法在PASCAL VOC2012 測試集上的語義分割結果對比,可以發現,跳層結構、殘差結構、空洞卷積、多尺度結構等技巧的使用極大地提升了分割精度。相比全監督算法,雖然弱監督算法的精度還有較大差距,但由于弱監督算法對標簽的要求很低,因此也非常具有研究價值,性能也有很大提升空間。
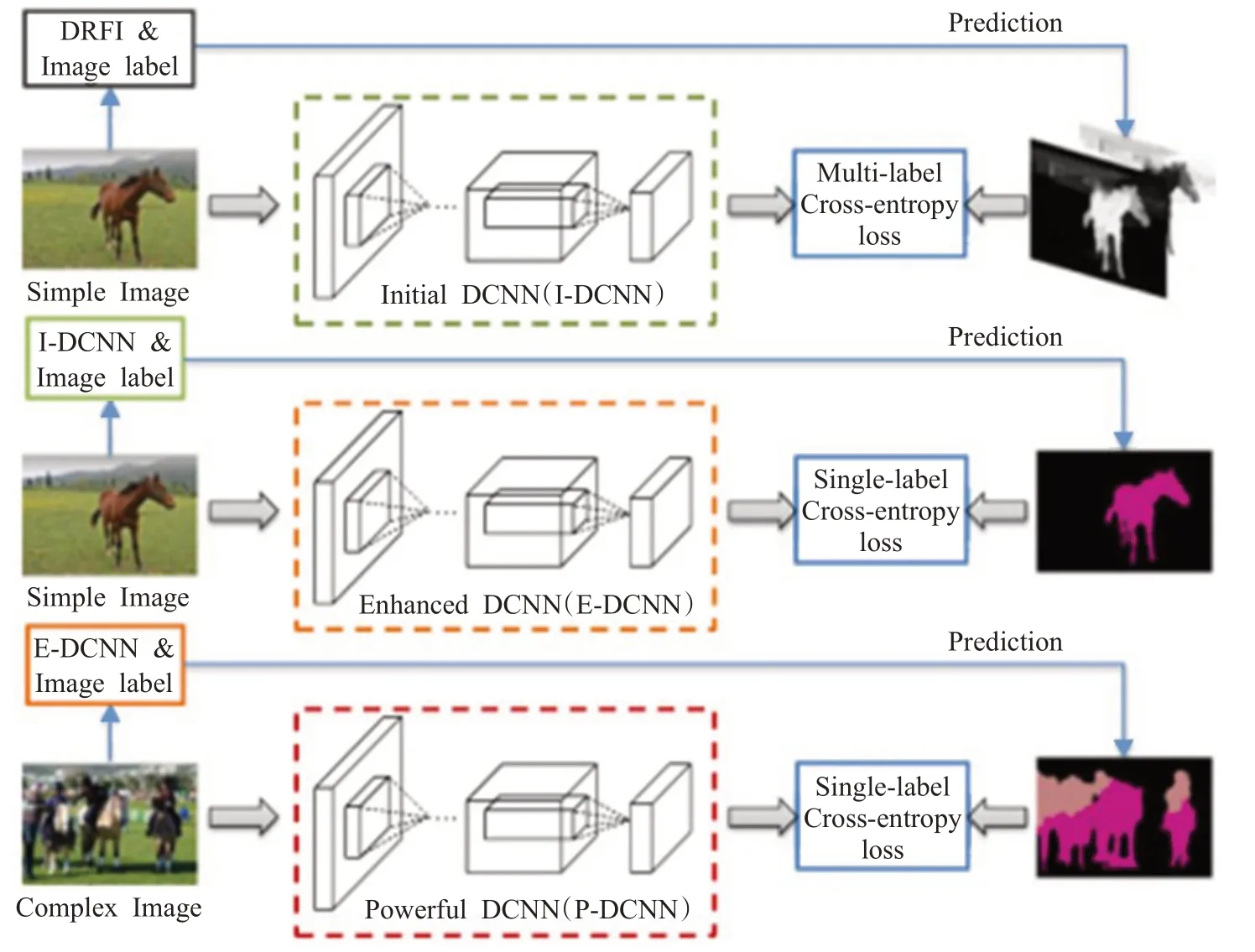
圖3 STC框架圖
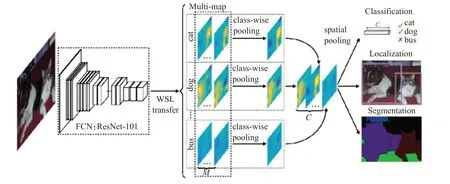
圖4 WILDCAT框架圖

表1 幾種方法在PASCAL VOC2012測試集上的性能對比
3 目標實例分割
實例分割與語義分割有非常本質的區別,且更加符合人類觀察物體的實際情況,基于實例的分割要求將屬于同一類別的不同目標區分開來,因此實例分割需要目標檢測技術作為基礎,然后再進行像素級分類。
3.1 實例FCN
由于目標不同,原始FCN 并不能被直接用于目標實例分割。但是Dai 等[47]發現,FCN 分割結果中大部分像素都是可以被再次使用的,因此,他們對FCN進行改進,提出了可用于實例分割的FCN 網絡,稱之為實例FCN。實例FCN的整體流程包括兩個分支,第一條分支用于產生輸入圖像中所有可能的實例分割圖,第二條分支產生的是與第一條分支中所有分割圖對應的一個分數,用于判斷該分割圖中是否含有目標,有則為1,沒有則為0。最后,根據兩條分支的共同輸出,產生一些候選的實例分割圖。文中采用的損失函數為:

其中第一部分來自第二分支,而第二部分則來自第一分支;i 表示訓練時隨機選取的滑動窗口的個數,j 為窗口中像素的索引。為進一步提升分割精度,還在網絡后端采用了非極大值抑制算法。
第一分支的實例FCN 和傳統FCN 有什么關系呢?傳統FCN中,同一像素點會產生相同分數,這對實例分割是不夠的。在實例分割中,同一像素可能會屬于不同實例,需要有不同的分數與其對應。因此為了實現這一目標,實例FCN會輸出一系列分數圖,每個分數圖是圖像中每個像素點與實例相對位置的一個分類。其實實例FCN 還是對圖像中的每個像素進行分類,不過這里的類別變成了是否屬于某個實例的相對位置。通過這種方法,即使是圖像中的同一像素,只要它位于實例的不同相對位置,那么在不同的實例中就可以得到不同的分數。然后通過一個滑動窗口來組合每個分數圖,產生最終的結果,具體如圖5 所示,這里滑動窗口的作用等同于邊界框。實例FCN 產生的分數圖的個數與k 的選取有關,k 表示滑動窗口中子窗口的個數,即k=3,生成的分數圖有k2個。每個分數圖代表的是每個像素點是否屬于該實例的某個相對位置的分類結果,也就是說在圖中,第二排第三列的6號分數圖中每個像素點都被分類為是或不是屬于這個實例的右邊。然后,在相應的分數圖中,直接復制對應位置子窗口的值,并根據其位置組合在一起形成實例分割圖。最后,為了提高分割結果的分辨率,實例FCN 借鑒了deeplab v1 的方法,將VGG16 中pool4 層的步長由2 改為1,并且在最后一個塊的3個卷積層上采用了空洞卷積。

圖5 實例FCN分割分支結構圖
實例FCN 的優點在于能直接完成實例分割,并且網絡參數數量很少。缺點在于只能完成分割任務,如果想對實例進行分類,后續還需再添加一個分類網絡。
3.2 FCIS
實例FCN 是將分割和分類任務分開進行,如果想實現實例分類還需要添加一個分類網絡。Li 等[48]認為這樣沒有完全利用兩個任務之間的相關性,因此對實例FCN進行改進,首次實現了全卷積網絡用于端對端實例分割任務,稱之為FCIS。該方法在閾值取0.5 時,平均準確率達到了59.9%。FCIS與實例FCN有幾點不同:首先,采用候選區域生成網絡(RPN)[49]獲取一些感興趣的區域(RoIs),即采用邊界框去替換滑動窗口,這里RPN直接作用于特征圖而不是原始輸入圖像;其次,FCIS除了獲取實例FCN 中的分數圖(文中稱為位置敏感內部分數圖),另外還獲取了一組分數圖用于分類任務(文中稱為位置敏感外部分數圖);然后,采用和實例FCN 一樣的組合方式產生兩個分割圖,一個用于實例分割,一個則用于實例分類;最后為增強網絡提取特征的能力,采用ResNet 替換了VGG16。FCIS 具有很多優點:首先網絡參數數量少,所有分數圖由單支FCN獲取,沒有多余操作;其次保留了FCN中局部權重共享的特性;最后每個RoI的計算非常簡單、快速。
3.3 Mask R-CNN
Mask R-CNN 是2017 年提出的[50],該方法擊敗了COCO2016挑戰賽的冠軍,同等條件下的平均準確率提升了5.5%。Mask R-CNN 是對Faster R-CNN[49]的一個擴展,在Faster R-CNN的網絡結構中增加了一條分支專門用于生成目標的實例分割結果。由于Faster R-CNN中RoIPool[49]采用的量化操作會造成輸入RoI 與輸出特征之間無法對齊,因此Mask R-CNN 提出盡量避免對RoI 的邊界或塊(bins)進行量化操作,使用雙線性插值去計算每個RoI塊的輸入特征在固定的4個采樣位置上的精確值,然后通過平均或最大值方法將這四個值進行合并。該方法稱為RoIAlign,能有效提升分割精度,克服類內競爭問題。Mask R-CNN算法包括兩個階段:第一階段采用RPN 生成一系列候選目標邊界框,經過卷積神經網絡進行特征提取并將這些候選邊界框映射到特征圖上產生一系列RoIs,然后采用RoIAlign提取每個RoI的特征用于后續操作;第二階段是一個并行結構,一條分支和Faster R-CNN一樣生成目標的類別和最終的目標邊界框,另一條分支直接采用FCN[4]對每個RoI 生成一個精細的分割圖。這與實例FCN中先完成精細分割,分類依靠分割結果進行形成了鮮明對比。在第一階段,將ResNeXt101[51]與Lin 等[52]提出的特征金字塔網絡(FPN)結合進行圖像特征提取,有效地提升了整體網絡的精度和速度。此外,由于增加的分割分支規模很小,Mask R-CNN運行速度并未受到什么影響。盡管如此,Mask R-CNN畢竟還是兩階段算法,其速度相比單階段算法還是不夠理想。
3.4 其他算法
Hayder等[53]采用的方法比較類似,先使用RPN對圖像產生一些候選框,然后在候選框的基礎上采用提出的基于距離變換的殘差反卷積結構去進行實例分割,整體網絡會重復殘差反卷積結構兩次。而Liu等[54]的想法則比較新穎,將一個實例分割問題分為水平方向和垂直方向分別進行,首先采用一個帶有跳層連接的全卷積網絡分別獲取目標的水平和垂直分割圖,然后通過一個融合網絡去生成最終結果。而文獻[55]則通過學習靜態圖特征進行視頻實例分割,以deeplab v2 為基礎,將視頻當前幀以及前一幀的預測分割結果送入網絡,通過仿射變換和非剛性變換來模擬兩幀之間同一目標的預期運動,引導當前幀進行實例分割。
4 目標檢測
4.1 目標檢測方法
4.1.1 Overfeat
Overfeat是比較早采用1×1全卷積層替換全連接層的方法之一[56]。該方法能同時完成分類、定位和檢測任務。為了增加檢測結果的可信度,沒有對生成的多個候選框采用抑制方式,而是改用累加方式,通過這種操作,該方法不需要在背景樣本上進行訓練就可以完成檢測任務,可以避免耗時又復雜的訓練過程,同時也能讓網絡更加關注正樣本,提升準確率。
Overfeat 最大的特點,是3 個任務共享網絡的特征提取部分,只需改變網絡的最后幾層就可以完成不同的任務。因此在分類任務完成之后,定位和檢測的微調并不需要很長時間。文中提出了兩種模型,一種速度快,一種精度高。兩種模型都以AlexNet[57]為基礎,高精度模型的改進為:沒有使用對比歸一化,池化區域不重疊,第一個卷積層采用更小的步長以獲取更大的特征圖。另一個亮點在于提出了offset池化。一般的池化都是從特征圖第一個像素開始,而且只將一個池化結果送入后續層。但是,分別從特征圖的第1、2、3個像素開始,并將3種情況下的池化結果分別送入網絡后續層,然后選取多個預測結果中的最大值作為最終結果。由于Overfeat以AlexNet為骨干網絡,且沒有采用多尺度特征融合,因此對特征的表達能力不足;盡管提出了一種速度快的模型,但是由于采用了貪婪的劃窗策略,其計算復雜度還是很高。
4.1.2 R-FCN
為解決分類問題中的平移不變性和目標檢測中的平移可變性之間的矛盾,Dai 等[58]提出了一個基于區域的全卷積網絡(R-FCN),其整體框架和FCIS 非常類似。與FCIS一樣,R-FCN也會產生一系列分數圖,但是數量與實例FCN一樣,僅為FCIS的一半,因為只需要完成目標檢測任務。其次,R-FCN 也是基于區域的,即會由RPN 方法產生一系列RoIs,目標檢測任務都在這些RoIs上完成。最后R-FCN沒有使用直接復制的方式去合成最后的預測結果,而是提出了一個位置敏感RoI池化操作,其中采用了平均池化,每個RoI會產生k2(C+1)個分數,其中C 為圖像中目標類別的數量,然后對每一類的這k2個分數通過平均方式進行投票,對產生的(C+1)維向量采用softmax進行分類。
4.1.3 其他算法
文獻[59]和[60]將全卷積網絡用于文本目標檢測。Zhang 等[59]提出了一個Text-Block 全卷積網絡,直接移植VGG16前5個塊,采用跳層結構融合來自5個塊的特征圖,每個特征圖都被反卷積上采樣到原始圖像大小。He等[60]指出文本對象之間存在較大尺度差異,僅采用一個全卷積分支不足以準確地捕捉如此大的文本差異,因此提出一個包含3條分支的網絡結構。3條分支結構相同,共享相同的卷積參數,輸入為3 個不同尺度上的同一圖像。通過這種聯合預測,該模型可以捕獲更多的上下文信息。Zhu等[61]基于文本目標將全卷積網絡用于交通信號檢測。采用兩階段策略,首先直接采用Text-Block全卷積網絡[59]將交通信號的大致區域從圖像中分割出來,這樣可以移除一些非文本或背景文本區域,減少文本檢測范圍,緩解文本尺度變化較大的問題。然后為滿足實時要求,利用交通信號文本尺度變化相對較小的特性對TextBoxes[62]進行簡化。
Li等[63]將全卷積網絡用于三維目標預測,網絡主干是一個類似FCN[4]的全卷積網絡,然后在第四層進行分裂,一條分支用于目標分類,一條用于三維邊界框預測;Zuo等[64]將全卷積網絡與循環神經網絡相結合用于人類皮膚檢測;羅明柱等[65]將改進后的AlexNet 與金字塔模型、非極大值抑制結合進行人臉檢測;Yang 等[66]在全卷積神經網絡后面采用了基于多馬爾科夫隨機場的候選區域產生方法對遙感圖像中的飛機進行檢測;Lin 等[67]將來自網絡的淺層特征和深層特征相結合用于近海船只檢測;Persello 等[68]則將空洞卷積引入全卷積網絡用于VHR圖像非正式居住點檢測。
4.2 顯著目標檢測
基于全卷積網絡在目標檢測上取得的成績,很多人都將其引入顯著性檢測領域。顯著目標檢測與目標檢測最大不同在于,顯著檢測只需將人眼最關注的那個目標檢測出來,它主要依靠目標的顯著性來完成任務。
DeepFix 首次將全卷積網絡用于預測人眼關注區域[69],其結構與VGG16類似,引入了空洞卷積和兩個類似于inception 的模塊;Kruthiventi 等[70]提出的方法能預測人眼關注區域并完成顯著目標分割,兩個任務共享網絡前半部分,并在分割任務中采用跳層結構。Hou等[71]提取VGG16 中6 個不同層的特征圖,每個深層特征圖都傳送到前面提取了特征圖的層級進行上采樣并進行連接操作,最終結果通過融合6 個初始結果產生。Luo等[72]提取VGG16的5個不同階段的特征圖,并在每組特征圖后填加了一系列卷積層、池化層和反卷積層。
張守東等[73]提出的方法包含三部分:利用顯著性提名網絡獲取顯著目標候選區域;通過候選區域的空間信息和類別置信值獲取目標的空間位置特征;融合深層特征、空間位置特征以及初始顯著圖置信圖特征。
Li等[74]將全卷積網絡用于顯著實例檢測任務,提出的方法包括三步:估計顯著圖;檢測顯著目標輪廓;識別顯著目標實例。提出了一個帶跳層結構的多尺度全卷積網絡完成前兩步,并根據目標輪廓檢測結果產生固定數量的顯著目標候選框,然后采用子集優化算法對候選框進行篩選,最后將估計顯著圖和篩選得到的候選框一起送入條件隨機場,進行分割結果優化。
Kuen等[75]和Wang等[76]都額外引入了循環神經網絡,前者先利用一個卷積-反卷積網絡獲取初始顯著圖,然后采用提出的循環關注卷積-反卷積網絡對初始結果進行反復微調,這種關注的順序特性可以使網絡利用過去迭代的上下文模式來增強被關注子區域的表達。后者提出了一個循環全卷積網絡,將原始圖像和其顯著先驗知識作為網絡第一時段的輸入,然后將第一時段的結果與原始圖像一起送入第二時段,循環多次得到最終結果,由于每次都利用了前一時段的結果作為輔助,因此該方法可以通過逐步修正前期錯誤來改善顯著分割結果。
Wang 等[77]將全卷積網絡用于視頻顯著目標檢測。首先采用一個對稱的卷積-反卷積網絡對當前幀進行靜態顯著目標檢測,以獲取視頻目標的空間顯著信息,然后將當前幀、后一幀和當前幀的顯著檢測結果一起送入動態顯著檢測網絡,兩個檢測網絡結構相同。該方法沒有依賴光流、邊緣圖或其他需要預先計算的信息,因此在保證精度的同時,處理速度上得到了極大提升。
4.3 邊界語義檢測
邊界語義檢測能獲取目標精確的邊界語義信息,可以作為語義分割的研究基礎。HED[78]是最早將全卷積網絡用于邊界語義檢測的算法,它直接融合VGG16的5個不同階段的輸出并對這5 個輸出和最后的輸出進行聯合監督訓練,同時針對任務中正負樣本嚴重不均衡的問題提出了一個帶權重的二值交叉熵損失函數;Liu等[79]采用的網絡結構與HED類似,也針對樣本不均衡問題提出了一個魯棒標注損失函數;Yang等[80]采用的是一個非對稱編-解碼全卷積結構;CASENet 則認為對所有階段的輸出都進行監督是不合理的[81],尤其是淺層階段,因此僅對最后階段和融合結果進行了監督訓練,同時提出一種共享連接方法去融合高階和低階特征。
5 分類及識別
Lee 等[82]首次將全卷積網絡用于高光譜圖像分類,提出了一個結合了多尺度濾波器組和殘差結構的網絡,通過多尺度濾波器組獲取圖像的初始空間和光譜特征,然后融合兩種特征送入網絡進行分類。Li 等[83]將全卷積網絡與優化的極限學習機結合進行高光譜圖像分類。Jiao等[84]直接使用FCN-8s[4]網絡提取高光譜圖像的深度多尺度特征,然后采用權重融合方法將光譜特征和深度多尺度特征進行融合。Mou 等[85]采用無監督方式進行高光譜圖像分類,文中采用一個全卷積-反卷積網絡進行圖像的無監督光譜-空間特征學習,結構中添加了殘差學習和在SegNet中的unpool操作。
Zhan 等[86]將全卷積網絡用于衛星圖像中云和雪的分類,結構與deeplab v1 類似,提出了一個多尺度策略對特征圖進行融合。Mancini等[87]將全卷積網絡與樸素貝葉斯最近鄰模型結合,輸入圖像被縮放到不同尺度并行送入網絡,利用樸素貝葉斯分類器對多尺度特征進行分類。Karim 等[88]將長短期記憶網絡(LSTM)和全卷積網絡結合用于時間序列分類。
Yu等[89]設計了一個雙流全卷積網絡,兩條分支采用相同結構用于提取外觀和運動特征,然后采用一個線性權重融合方法來融合這兩種特征,同時引入時間金字塔池化來構建視頻級特征以完成動作識別;Liu 等[90]通過人類視覺注意力的幫助去完成動作識別,該網絡采用多流全卷積結構,前兩條分支用于提取外觀和運動特征,第三條分支是一個注視預測全卷積網絡用于學習動態注視特征;Yu 等[91]將識別分為兩階段,首先將ResNet[17]改為全卷積網絡同時引入跳層,將圖像中的皮膚病灶區域分割出來,然后構造一個深度殘差網絡對第一階段的結果進行分類,兩個網絡的不同在于分割網絡后面添加了一個7×7平均池化層用于提取全局深度殘差特征。
可以發現使用深度網絡框架提取的特征能更好地反應數據的內在本質,合適的特征融合方式能有效提升網絡的性能,殘差結構和多尺度信息的優勢越來越明顯。
6 其他應用
除了以上應用較廣泛的領域,全卷積神經網絡在圖像摳圖、圖像修復、目標候選框生成等領域也有所表現。
6.1 圖像摳圖
Xu 等[92]提出了一個編-解碼+微調的兩階段全卷積網絡。第一階段是一個非對稱編-解碼結構,主要用于產生一個粗糙的分割結果,由于摳圖對圖像細節要求很嚴格,因此增加了一個微調階段用于增強第一階段結果的邊緣部分。微調階段的結構非常簡單,是一個只包括4 個卷積層的殘差結構。該方法的優點在于泛化能力強,摳圖結果擁有非常精確的邊緣,采用聯合損失函數使網絡更加快速的收斂;缺點在于訓練過程不是端對端的,待第一階段收斂后才能訓練第二階段。
6.2 圖像修復
Tan等[93]提出了一個基于全卷積網絡的深度去馬賽克模型,任務分兩階段,首先采用全卷積網絡產生一個初始去馬賽克圖像,該網絡只包含一系列卷積層,沒有任何池化層;然后使用一個深度殘差估計和多模融合方法產生一個更高質量的結果,該部分將第一階段提取的特征送入一個只包含一個1×1 卷積層的殘差層以生成殘差圖像,然后將其與初始去馬賽克圖像求和形成一副合成圖像,最后利用原始圖像對合成圖像進行矯正。為提升方法性能,提出一種多模訓練方式,其中包含3 種模型,每種模型結構相同,區別在于輸入信號,第一個模型使用所有數據,另外兩個模型分別使用光滑紋理圖像和粗糙紋理圖像,最后采用加權雙插值融合方法去合并3個模型的輸出。由于加入了對不同紋理圖像的關注,修復的圖像能很好地保留原始圖像的紋理細節。
6.3 目標候選框生成
最著名的全卷積目標候選框生成方法當屬區域建議網絡(Region Proposal Network,RPN)[49],將RPN 設計為全卷積網絡是為了能夠和Fast R-CNN[94]共享一些卷積層。RPN 的輸入是共享卷積層最后一層的輸出特征圖,采用一個3×3 滑動窗口對特征圖進行滑動,這里采用的是3×3卷積,然后將獲得的特征圖送入分類層和回歸層,分類層輸出2k 個分數用于估計k 個候選框中是否有目標,回歸層輸出4k 個結果用于編碼k 個候選框的坐標信息。為使網絡輸入可以是任意尺寸,分類層和回歸層全部采用1×1 卷積層實現。文中給RPN 的候選框取了另外一個名字:Anchor,Anchor 的中心位置位于滑動窗口中心,每個Anchor 對應不同的尺度和長寬比,如果有3個不同尺度和3個不同長寬比,每個滑動窗口會產生9 個不同的Anchor,RPN 則會輸出18 個分類信息和36個坐標信息。
Jie 等[95]采用的結構與VGG16 非常相似,為實現多尺度,將輸入圖像縮放到不同大小,然后從這些圖像中裁剪出40×40 的塊送入網絡產生一系列目標候選框。由于采用了固定的多尺度輸入以及基于塊的訓練方式,會產生一些檢測錯誤,因此使用一種貪婪迭代搜索方法對每個候選框進行微調;隨后,Jie 等[96]又提出了一個尺度感知像素級目標候選網絡(SPOP-net)用于解決小目標定位差的問題,SPOP-net 包括三條分支:第一條被稱為置信度網絡,以預訓練好的deeplab v1 為基礎,對圖像進行像素級分類,另外兩條分別用于定位圖像中的大目標和小目標,共享同一結構,目標的最終預測坐標為兩個分支結果的加權和,權重信息來自第一條分支獲取的大/小目標置信度圖。
7 結束語
本文對全卷積神經網絡在多個研究領域取得的成果進行了系統梳理和分析,重點剖析了幾個熱門研究方向的一些經典算法的核心所在,同時對目前最新提出的一些方法進行了分析總結。將全卷積神經網絡中采用較多的技術進行歸納總結,分析其優缺點,詳見表2。

表2 全卷積神經網絡采用技術的分析
全卷積神經網絡具有能支持任意大小的輸入,支持完整圖像的端對端訓練,更加高效,能更好地學習上下文信息的優點。當然它還存在大量值得研究的問題:
(1)提出更加適合于弱/無監督訓練方式的全卷積網絡結構。弱/無監督更加符合人腦的思維模式,現有的很多全卷積網絡在全監督訓練下可以取得很好的成績,但是移植到弱/無監督之后其效果顯著下降,探尋數據內在本質特點,設計更加合適的網絡結構值得研究。
(2)全卷積網絡通過堆疊眾多卷積層來獲取長距離依賴信息,以學習目標的可區分性特征。卷積層堆疊過多會帶來算法計算復雜度劇增、網絡優化困難、多跳依賴關系建模困難的問題。不依靠增加網絡深度,提出可區分性特征學習模塊也是值得研究的問題。
(3)研究效果與效率并存的卷積操作。全卷積網絡中使用最多的就是卷積操作,當由于任務需求需采用大尺寸卷積核時,卷積操作的計算復雜度會劇增。可分離卷積[97]、HetConv[98]等的提出,給這方面研究指引了方向,指出高性能高效率的卷積操作是值得研究的問題。
(4)隨著手機終端的大力發展,對實時網絡結構需求量劇增,如何設計輕量級、小巧的全卷積網絡結構,同時保證一定的性能也是值得研究的問題。
猜你喜歡
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
中學生數理化·七年級數學人教版(2019年4期)2019-05-20 10:06:32
中學生數理化·七年級數學人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
