基于邊界混合重采樣的非平衡數(shù)據(jù)分類方法
2020-01-06 02:07:04侯貝貝劉三陽普事業(yè)
計算機工程與應(yīng)用 2020年1期
侯貝貝,劉三陽,普事業(yè)
西安電子科技大學(xué) 數(shù)學(xué)與統(tǒng)計學(xué)院,西安710126
1 引言
最近幾年,非平衡數(shù)據(jù)分類問題一直活躍在各個領(lǐng)域,如垃圾郵件過濾[1]、文本分類、信貸欺詐[2]、客戶賬戶信息流失和網(wǎng)絡(luò)入侵數(shù)據(jù)[3]等,這些問題存在一個共同的特征,即數(shù)據(jù)集中的某一類別的樣本數(shù)量遠遠多于另一類(分別稱為多數(shù)類和少數(shù)類),具有這種特征的數(shù)據(jù)集被看作是非平衡的。但實際問題重點考察的對象往往是已知信息較少的一類,這對傳統(tǒng)的分類算法有著天然的缺陷,因為它們最初的設(shè)計思想是以提高整個數(shù)據(jù)集的分類性能為標準,為了滿足這類算法的目標函數(shù)要求,分類器會將某些少數(shù)類樣點劃分到多數(shù)類,使得少數(shù)類樣本的分類準確率降低。因此,采取合適的策略或方法,降低由數(shù)據(jù)樣本數(shù)量的非平衡所帶來的影響是目前分類算法研究的難點和熱點[4]。
現(xiàn)有的關(guān)于非平衡數(shù)據(jù)分類問題的研究主要從數(shù)據(jù)和算法方面著手。數(shù)據(jù)層面上,重采樣技術(shù)是頗受關(guān)注的[5-6],其中,較具有代表性的是過采樣SMOTE[7](Synthetic Minority Oversampling Technique)算法和欠采樣[8](Under-Sampling)算法,分別通過對少數(shù)類和多數(shù)類進行添加數(shù)據(jù)和剔除數(shù)據(jù),以此來達到數(shù)據(jù)的平衡。在此基礎(chǔ)上,相關(guān)學(xué)者提出了一些改進的算法,文獻[9]中提出的Borderline-SMOTE 算法,區(qū)別于S-MOTE 算法中將所有少數(shù)類點作為種子節(jié)點,該算法認為少數(shù)類中的邊界樣本是更有價值的點,進一步合成新的樣本點,有效地避免了SMOTE算法容易造成過擬合的現(xiàn)象,但因其主要合成邊界樣本,加大了邊界模糊的可能,使得分類難度增大。針對隨機欠采樣算法中易刪除含有重要信息樣本點的問題,趙自翔等[10]提出基于歐氏距離的欠采樣算法(OSED),該算法在刪除多數(shù)類樣本時既保留了樣本的分布情況又平衡了數(shù)據(jù)集,一定程度上提高了少數(shù)類的分類精度。從算法層面上,通過引入某種機制來克服樣本數(shù)量非平衡對算法造成的影響,常用的算法有基于代價敏感學(xué)習(xí)法[11](DEC)、集成學(xué)習(xí)方法[12]和模糊支持向量機[13]等,雖然這類算法避免了由合成數(shù)據(jù)或刪減樣本帶來的誤差,但其較難改進,因為不同類別的懲罰因子人為較難設(shè)定,并且對于不同分布的數(shù)據(jù)集,算法中參數(shù)的選擇也會較棘手,往往需要做大量的實驗去尋找。針對欠采樣和過采樣在非平衡數(shù)據(jù)分類上的不足之處,混合采樣的非平衡數(shù)據(jù)分類方法相繼被提出。文獻[14]提出了基于邊界混合采樣的非均衡數(shù)據(jù)處理算法,該算法利用變異系數(shù)對訓(xùn)練樣本邊界進行區(qū)分,對多數(shù)類邊界樣本利用基于歐氏距離的欠采樣算法刪除,但對少數(shù)類邊界樣本僅使用SMOTE合成樣本,仍無法避免SMOTE易過擬合的缺陷。文獻[15]提出了一種基于鄰域混合抽樣和動態(tài)集成的不平衡數(shù)據(jù)分類方法,該算法依據(jù)每個數(shù)據(jù)點的危險程度賦予樣本點一定的權(quán)重,對多數(shù)類樣本和少數(shù)類樣本分別進行處理,實驗結(jié)果表明,該算法能夠提高數(shù)據(jù)集的分類性能。
針對上述多數(shù)類樣本易刪除重要信息點和少數(shù)類樣本合成無效樣本點的問題,本文提出一種基于邊界混合重采樣的分類方法(BMRM)。該算法通過設(shè)置支持k-離群度閾值[16]來劃分邊界樣本和非邊界樣本,對少數(shù)類中的邊界樣本使用改進的SMOTE 算法,多數(shù)類中的非邊界樣本使用基于距離的欠采樣算法[17],最后將本文算法與SMOTE 算法、Borderline-SMOTE 算法、基于歐氏距離的欠采樣算法,以及基于支持k-離群度概念定義非邊界樣本,對多數(shù)類的非邊界樣本使用隨機欠采樣的算法進行對比。實驗結(jié)果顯示,本文算法具有更好的分類性能,SVM算法是具有代表性的數(shù)據(jù)分類算法,本文實驗中均將其作為基準分類器。
2 基于邊界混合重采樣的非平衡數(shù)據(jù)處理
文中提出的基于邊界混合重采樣的非平衡數(shù)據(jù)分類方法,主要以兩個過程對樣本點的邊界集和非邊界集進行處理,在使多數(shù)類和少數(shù)類樣本數(shù)量達到平衡的同時,最小程度地降低樣本信息的流失,保留對分類性能有影響的點,以此達到更好的分類效果。其主要思想是,引入支持k -離群度和邊界因子概念區(qū)分數(shù)據(jù)集中的邊界點集和非邊界點集,找到對分類性能有影響的點,使混合重采樣算法更加合理。
2.1 邊界集的識別
從數(shù)據(jù)層面對數(shù)據(jù)集進行分類,為了使類之間的樣本數(shù)量均衡,有時會將多余的數(shù)據(jù)點刪除掉,但并不是僅僅去掉部分樣本就能實現(xiàn)較好的分類效果。該前提是要將含有重要信息的樣本點保留下來,從支持向量機(SVM)的分類思想上了解到,超平面只與支持向量有關(guān),而支持向量大都位于多數(shù)類和少數(shù)類的邊界樣本上,所以,在處理數(shù)據(jù)時,直接刪除邊界上的數(shù)據(jù)點這種做法是不合適的。為了能更好地識別出邊界樣本點,文中采用基于支持k-離群度的邊界點檢測算法找出非平衡數(shù)據(jù)集中的邊界集和非邊界集,具體定義如下。
(1)對于數(shù)據(jù)集M 和任意正整數(shù)k,對象s 的k 距離記為k_dist(s),對于任意對象o ∈M ,對象s 的k 距離為k_dist(s)=dist(o,s),需滿足:
①至少有k 個對象t ∈M-{s}使得

②至多有k-1 個對象t ∈M-{s}使得

其中,dist(o,s)為對象ο 與對象s 間的歐氏距離。
(2)對象s 的支持k-離群度的定義為:s 的k 距離與其ε 鄰域內(nèi)的所有點(包括s)的k 距離的平均值之比,記為k_od(s),即
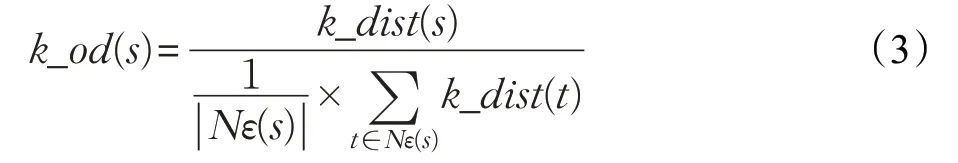
其中,Nε(s)為對象s 的ε 鄰域內(nèi)的所有對象, ||Nε(s) 表示對象s 的ε 鄰域內(nèi)的樣本點個數(shù),該公式主要利用樣本點自身的k 距離與其鄰居樣本的k 距離來刻畫數(shù)據(jù)的分布特征。
考慮到數(shù)據(jù)集中存在樣本點分布不均勻的情況,較難為每個數(shù)據(jù)集樣本點找到合適的ε 值,可能有的點處于高密度區(qū)域,有的點處于低密度區(qū)域,為了避免這種不確定因素,將點s 的ε 鄰域半徑設(shè)置為s 的k 距離。
(3)數(shù)據(jù)集M 中點s 的支持k-離群度與1 之差的絕對值記為點s 的邊界因子k_bd(s),即

如果一個數(shù)據(jù)樣本的邊界因子越小,那么就說明該點及其k 距離鄰居的距離相差較小,數(shù)據(jù)分布相對均勻,該點是類內(nèi)部的點的可能性較大。相反,如果一個數(shù)據(jù)樣本的邊界因子越大,那么就說明該點附近點的分布相對離散,k 距離變化較大,數(shù)據(jù)分布不均勻,即該點為類內(nèi)部點的可能性就越小,設(shè)定一個閾值σ ,當k_bd(s)>σ 時,稱滿足此條件的s 樣本點為邊界點,否則為非邊界點。
2.2 邊界集的處理
(1)Random-SMOTE算法
根據(jù)SMOTE 算法本身存在的不足,無法解決數(shù)據(jù)集中少數(shù)類樣本分布過擬合以及計算復(fù)雜度大的問題。本文針對其不足引用Random-SMOTE 算法[18],此算法重點關(guān)注新樣本產(chǎn)生的區(qū)域,使得新樣本更貼合樣本點分布的隨機性,Random-SMOTE 算法首先計算區(qū)域內(nèi)少數(shù)類樣本x0的k 個同類近鄰樣本,并在k 個同類近鄰樣本中任意選取兩個,設(shè)這兩個少數(shù)類樣本點的向量表示為X 和Y ,然后在這兩個少數(shù)類樣本點之間隨機確定一點P ,記P 為臨時樣本點,最后在樣本x0與臨時樣本P 之間使用公式(5),合成新的樣本點,記為Xnew1。

區(qū)域內(nèi)的少數(shù)類樣本點與它的兩個近鄰?fù)悩颖军c組成三角形,這個方法使得新合成的樣本點在三角形區(qū)域內(nèi)具有一定的隨機性,更貼合樣本點本身的分布特性。
(2)NP-SMOTE算法
針對多數(shù)類樣本分布對少數(shù)類分類效果有很大影響的問題,本文首先給出如下定義:
定義1 若樣本x0的k 近鄰都是同類樣本,則x0為安全樣本,若k 近鄰中存在非同類樣本,則x0為非安全樣本。
為了提高邊界集中少數(shù)類樣本的分類效果,對邊界集中少數(shù)類樣本x0計算k 近鄰樣本,當k 近鄰樣本中存在多數(shù)類樣本Q 時,在該少數(shù)類樣本x0與多數(shù)類樣本Q 之間使用公式(6),合成新的樣本點,將算法命名為NP-SMOTE。

由于當樣本點的k 近鄰都是同類點時,該樣本點相對來說不容易被分錯,在邊界集少數(shù)類樣本與k 近鄰多數(shù)類樣本的連線上加入少數(shù)類樣本,使得該少數(shù)類樣本從非安全樣本變成安全樣本。
利用上節(jié)給定的邊界定義公式,找到數(shù)據(jù)集中的邊界集,對邊界集中的少數(shù)類樣本點,利用Random-SMOTE算法和NP-SMOTE 算法合成新的少數(shù)類樣本點,該操作即減少了對分類性能影響不大的點的合成,又平衡了邊界集中的多數(shù)類與少數(shù)類樣本點。
2.3 非邊界集的處理
現(xiàn)實中大規(guī)模的數(shù)據(jù)樣本集普遍存在,對SMOTE算法來說,會增大算法的時間復(fù)雜度,為了降低算法的時間消耗,需要采用一種合適的欠采樣算法。由于距少數(shù)類樣本中心點遠的多數(shù)類樣本點為噪聲的可能性較大,因此,本文對于非邊界集的多數(shù)類樣本點采用基于距離的欠采樣算法,該方法首先需要先找到少數(shù)類的中心點,計算非邊界集中的多數(shù)類樣本到該中心點的距離,然后對距離進行排序,刪除一定比例的多數(shù)類樣本點,經(jīng)過該算法處理后的樣本點既保留了有價值的點,又使得數(shù)據(jù)點數(shù)量趨于均衡。
2.4 基于邊界混合重采樣的非平衡數(shù)據(jù)分類流程
基于邊界混合重采樣的非平衡數(shù)據(jù)分類方法,使得邊界集和非邊界集的少數(shù)類與多數(shù)類樣本點均達到平衡,一定程度上提高了非平衡數(shù)據(jù)集的分類性能。
假設(shè)D 為處理前的非平衡數(shù)據(jù)集,則D 中的邊界集、非邊界集、邊界集中的多數(shù)類樣本、邊界集中的少數(shù)類樣本、非邊界集中的多數(shù)類樣本、非邊界集中的少數(shù)類樣本分別定義為BMRM 算法的流程如圖1 所示。本文算法首先利用支持k-離群度概念計算原始數(shù)據(jù)集中每個樣本點的邊界因子,設(shè)置邊界閾值σ ,將邊界因子大于該閾值的樣本歸為邊界集,反之歸為非邊界集;然后對邊界集中的少數(shù)類樣本利用改進的SMOTE算法合成新的少數(shù)類樣本點,并加入到訓(xùn)練樣本集中;對于邊界集中的多數(shù)類樣本點不做處理,同樣加入到訓(xùn)練樣本集中;最后,對非邊界集中的多數(shù)類樣本點采用基于距離的欠采樣算法刪除對分類性能影響較小的樣本點,保留下的樣本點連同非邊界集中少數(shù)類樣本點一起加入到訓(xùn)練集中。

圖1 BMRM算法流程圖
本文所提算法的具體過程分析如下。
輸入:非平衡數(shù)據(jù)集D(i=1,2,…,N),N 為樣本總數(shù),邊界因子閾值σ。
輸出:平衡化后的數(shù)據(jù)集。
1.計算訓(xùn)練集中每個樣本的邊界因子k_bd(xi)(i=1,2,…,N)
1.1.計算樣本點xi到其余樣本點的歐氏距離,并對該距離進行排序,得出其對應(yīng)的k 距離
1.2.找到距離樣本xi最近的k 個樣本點,并計算這k 個點所對應(yīng)的k 距離
1.3.計算每個樣本點的支持k-離群度
1.4.求出每個樣本點的支持k-離群度與1之差的絕對值,記為k_bd(xi)(i=1,2,…,N)
2.若k_bd(xi)>σ,則將xi歸為邊界集D1中;否則歸為非邊界集D2中
3.將D1中的樣本點使用Random-SMOTE 算法和NP-SMOTE 算法合成新的樣本點集,并將其與、組成新的點集Train_data_1
4.將Dmajor2 中的樣本采用基于距離的欠采樣算法刪減,然后將與刪減后的的組成新的點集Train_data_2
5.將Train_data_1和Train_data_2合并成處理后的數(shù)據(jù)集Train_data
邊界因子閾值σ 是本文算法需要解決的一個問題,下面給出相關(guān)定義。
定義2 平均k 距離:設(shè)有N 個樣本點,N 個對象的k 距離為k_dist(s),其中,s=1,2,…,N ,則可定義所有對象的平均k 距離為:

定義3 最大樣本k 距離:
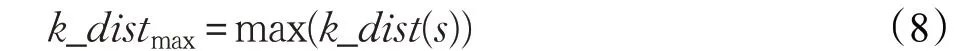
其中,s=1,2,…,N 。
定義4 一個樣本數(shù)量為N 的數(shù)據(jù)集,選擇樣本間的平均k 距離與最大樣本k 距離的比值作為邊界因子閾值σ,即

通過大量實驗,閾值在0.3~0.5 之間能夠得到較好的邊界識別結(jié)果。
3 實驗及結(jié)果分析
3.1 評價指標
在非平衡數(shù)據(jù)分類問題中,一個分類算法的分類情況可通過混淆矩陣來評估,其對應(yīng)的混淆矩陣如表1所示。
表1 中,TP 是實際為少數(shù)類且預(yù)測正確的樣本個數(shù),TN 是實際為多數(shù)類且預(yù)測正確的樣本數(shù)量,F(xiàn)N 是實際為少數(shù)類且預(yù)測錯誤的樣本數(shù)量,F(xiàn)P 是實際為多數(shù)類且預(yù)測錯誤的樣本數(shù)量。因為非平衡數(shù)據(jù)分類中少數(shù)類樣本較少,相比多數(shù)類樣本較難識別,對于少數(shù)類樣本的邊界是較難準確定義的,為了最大化準確率,分類器往往會將整個數(shù)據(jù)集的大部分樣本劃分到多數(shù)類,如果仍以分類準確率作為評判標準,對于少數(shù)類樣本顯然是不公平的。因此,本文采用較為綜合的F-value和G-mean 指標來衡量非平衡數(shù)據(jù)分類性能的優(yōu)劣,公式定義為:

表1 混淆矩陣

其中,Se 代表分類器預(yù)測少數(shù)類樣本的能力,Sp 代表分類器預(yù)測多數(shù)類樣本的能力,G-mean 是比較綜合的指標,而且只有當Se 和Sp 都較大時,才能保證G-mean也較大。
F-value作為非平衡數(shù)據(jù)分類的評價指標,其定義為:

3.2 數(shù)據(jù)集描述
為了驗證本文所提方法的有效性,從UCI國際機器學(xué)習(xí)數(shù)據(jù)庫(http://www.ics.uci.edu)中選擇了8 組非平衡數(shù)據(jù)集。由文獻[19-20]可知,一般當少數(shù)類與多數(shù)類的類分布比例低于1∶2時,數(shù)據(jù)具有非平衡特征。所用數(shù)據(jù)集樣本點個數(shù)范圍為215~4 601,樣本點的屬性維數(shù)范圍為3~57,非平衡比率為多數(shù)類樣本數(shù)與少數(shù)類樣本數(shù)的比值,本文解決的是二分類非平衡問題,對于含有多個類別的數(shù)據(jù)集,人為的進行重構(gòu),并將重構(gòu)后樣本數(shù)量多的一類定義為多數(shù)類,樣本數(shù)量少的一類定義為少數(shù)類。其中,Haberman 數(shù)據(jù)集的第二類作為少數(shù)類,第一類作為多數(shù)類;Ecoli數(shù)據(jù)集的第pp、om為少數(shù)類,其他合起來為多數(shù)類;biodeg數(shù)據(jù)集的第RB類為少數(shù)類,NRB為多數(shù)類;Throid數(shù)據(jù)集第二類為少數(shù)類,其他類為多數(shù)類;Vehicle 數(shù)據(jù)集第van 類為少數(shù)類,其他合起來為多數(shù)類;Innosphere數(shù)據(jù)集的第b類為少數(shù)類,g類為多數(shù)類。各個數(shù)據(jù)集詳細信息如表2所示。

表2 數(shù)據(jù)集信息
3.3 實驗及分析
為了驗證本文所提出的基于邊界混合重采樣的非平衡數(shù)據(jù)分類算法的分類性能,將其與基于SVM 分類器的SMOTE 算法、Borderline-SMOTE(B-SMOTE)算法、基于歐氏距離的欠采樣算法(OSED)和基于支持k-離群度概念,但對多數(shù)類非邊界樣本進行隨機欠采樣,與少數(shù)類邊界樣本進行SMOTE 結(jié)合的算法(RUSMOTE)進行對比。實驗環(huán)境均在MATLAB2018b 軟件運行,對于每一個數(shù)據(jù)集,均采用五折交叉驗證,每次選擇其中4組作為訓(xùn)練集,1組作為測試集,且每組數(shù)據(jù)集中的多數(shù)類與少數(shù)類樣本個數(shù)比值為原始數(shù)據(jù)集中多數(shù)類與少數(shù)類樣本數(shù)量非平衡比率,8個數(shù)據(jù)集在少數(shù)類上的對比結(jié)果見表3,多數(shù)類上的對比結(jié)果見表4,綜合性指標(G-mean和F-value)對比結(jié)果見表5,并將最大的值用粗體標出。
從表3中觀察發(fā)現(xiàn),本文算法較好地提高了少數(shù)類的分類準確率,大部分數(shù)據(jù)集在經(jīng)過本文算法處理后得到的Se 值大于文中列舉的其他對比算法。因為本文算法在處理數(shù)據(jù)時,對多數(shù)類和少數(shù)類中的邊界點分別作了相應(yīng)的處理,較好地降低了由邊界樣本點分錯而帶來的不良影響,同時對于多數(shù)類中的非邊界集,采取了基于距離的欠采樣算法,保留了對分類結(jié)果有價值的樣本點,相比隨機欠采樣算法,分類性能有了明顯地改善。表4中本文算法在多數(shù)類上的分類準確率均較高,雖然在數(shù)據(jù)集Haberman 和Biodeg 上沒有取得最優(yōu)的值,但與其他對比算法相差不大,說明B-MRM算法在保證多數(shù)類樣本分類性能的基礎(chǔ)上,一定程度上可以提高少數(shù)類樣本的分類性能,在實際應(yīng)用中,少數(shù)類樣本往往才是要考察的對象。
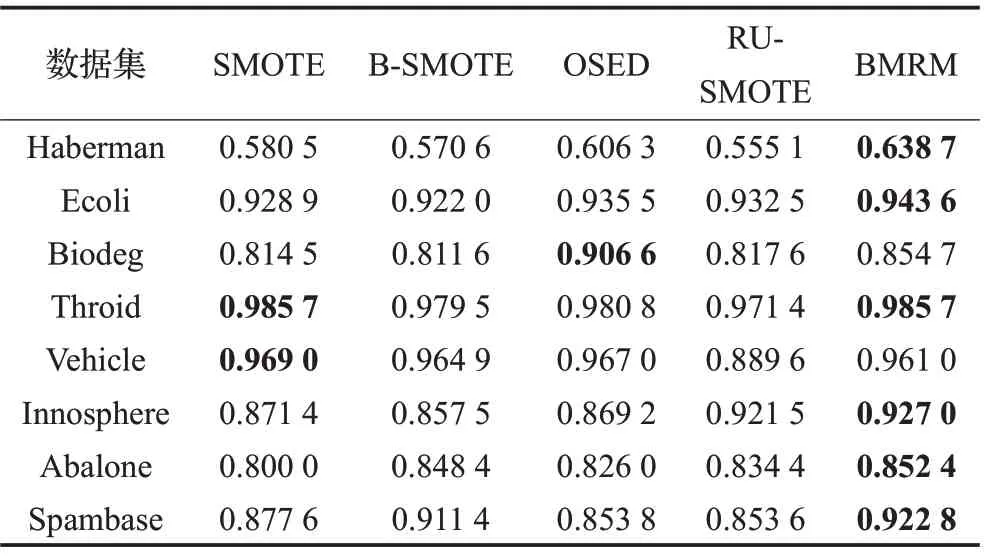
表3 5種算法在少數(shù)類上的對比結(jié)果

表4 5種算法在多數(shù)類上的對比結(jié)果
從表5 中發(fā)現(xiàn),針對F-value 指標,在數(shù)據(jù)集Vehicle上,對比算法B-SMOTE 高于本文結(jié)果,這是因為Vehicle數(shù)據(jù)集的邊界點重疊度較大,而B-SMOTE算法是針對少數(shù)類中的危險樣本點設(shè)計的算法。本文算法雖然加入了邊界因子概念,但對邊界復(fù)雜度大的數(shù)據(jù)集顯得有些不足,說明本文算法仍需改進。雖然本文算法較好地提高了少數(shù)類的分類準確率,但當數(shù)據(jù)集不平衡比率較大時,例如Abalone數(shù)據(jù)集,本文算法中的邊界因子閾值這一關(guān)鍵參數(shù)對該數(shù)據(jù)集的分類性能有所影響,導(dǎo)致OSED 算法的F-value 值高于本文算法。但從Gmean指標上看,本文算法分類性能優(yōu)于對比算法,是較為有效的。

表5 8種數(shù)據(jù)集在5種算法上的G-mean和F-value性能比較
為了更清晰地分析各個算法的分類效果,圖2~5分別繪制了5 種算法在8 個數(shù)據(jù)集上的分類結(jié)果變化曲線。其中,橫坐標代表不同算法,縱坐標代表分類結(jié)果取值,其范圍在0~1之間,從圖中觀察得出,本文算法相比較其他算法在各個指標上都有了一定程度的提高。事實證明,綜合考慮對分類性能有影響的樣本點,對不同區(qū)域的數(shù)據(jù)樣本采取不同的方法是有效的,并在一定程度上表現(xiàn)出更強的適應(yīng)性。
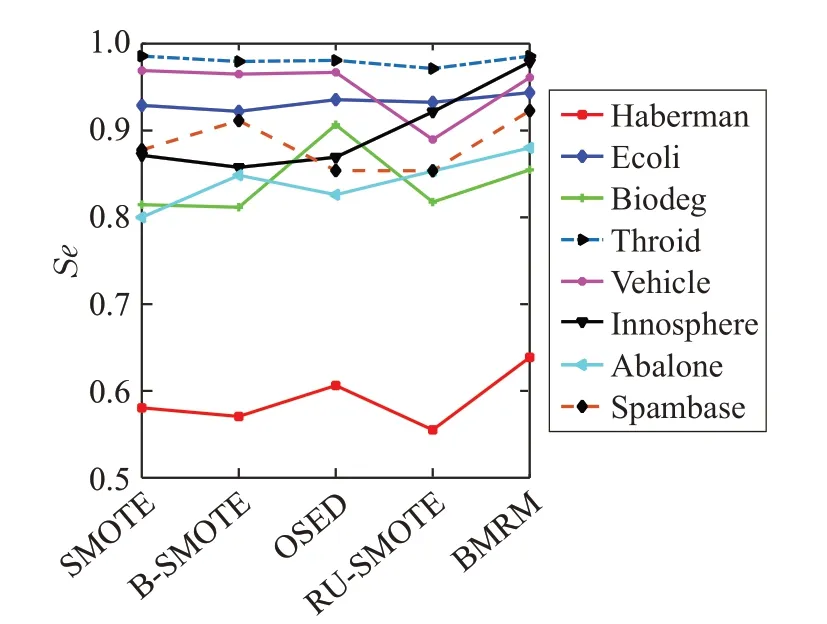
圖2 少數(shù)類準確率變化曲線

圖3 多數(shù)類準確率變化曲線
4 總結(jié)與展望

圖4 G-mean變化曲線

圖5 F-value變化曲線
本文針對非平衡數(shù)據(jù)分類問題,提出了一種基于邊界混合重采樣的方法,通過計算數(shù)據(jù)集中每一個樣本點的支持k-離群度,利用設(shè)定的閾值來劃分邊界集和非邊界集,并對邊界集中的少數(shù)類點進行Random-SMOTE和NP-SMOTE合成,非邊界集中的多數(shù)類樣本進行基于距離的欠采樣剔除,以此實現(xiàn)數(shù)據(jù)集的平衡。實驗結(jié)果對比表明,本文算法一定程度上提高了數(shù)據(jù)集的分類性能,可將該算法用于解決生活中普遍存在的非平衡分類和預(yù)測評估問題。但本文算法也存在著不足:一方面,邊界因子閾值σ 在設(shè)置時,本文雖考慮了所有訓(xùn)練樣本的分布特征,但卻忽略了類內(nèi)樣本的分布情況;另一方面,在定義支持k-離群度時僅僅選擇基于距離的離群度,對于文獻[21]中所給的其他離群度定義形式還有待研究。今后的工作可以在本文算法的基礎(chǔ)上,利用其他效果較好的重采樣算法來實現(xiàn)非平衡數(shù)據(jù)分類,并研究如何通過自適應(yīng)方法產(chǎn)生邊界因子閾值。
猜你喜歡
數(shù)學(xué)小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
大眾健康(2021年6期)2021-06-08 19:30:06
海峽姐妹(2020年9期)2021-01-04 01:35:44
VOGUE服飾與美容(2020年9期)2020-09-02 14:47:26
中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2019年4期)2019-05-20 10:06:32
中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
山東青年(2016年1期)2016-02-28 14:25:25
少兒科學(xué)周刊·少年版(2015年3期)2015-07-07 21:00:00
當代修辭學(xué)(2014年3期)2014-01-21 02:30:44
