復雜場景下基于R-FCN的小人臉檢測研究
2020-01-06 02:16:08降愛蓮
計算機工程與應用 2020年1期
李 靜,降愛蓮
太原理工大學 信息與計算機學院,山西 晉中030600
1 引言
目前,人臉檢測[1]在面部相關應用系統中起著非常重要的作用。盡管近年來已取得巨大進步,但人臉檢測技術上的挑戰依然存在。如圖1所示,人臉因種種影響因素變化很大,包括面部部分的遮擋、不同的尺度、光照條件、不同的姿勢、豐富的表情等。最近,基于區域方法的成功,推動了目標檢測的發展。典型算法中Fast/Faster R-CNN[2-3]是基于R-CNN[4]的算法,以在感興趣的區域內進行區域檢測的方式實現檢測。但是,直接將區域特定操作的策略應用到完全卷積的網絡中,比如殘差網絡ResNet[5],由于分類精度高,最終導致檢測性能較差。

圖1 復雜場景下的多個人臉圖像示意圖
基于此,本文基于R-FCN[6]框架,引入Squeeze-and-Excitation模塊[7],使得能夠顯式地建模特征通道之間的相互依賴關系,且不需要引入新的函數或者層,最終在模型和計算復雜度上具有良好的特性。
通過查閱文獻,發現近期關于人臉檢測的研究進展,大多集中于使用深層卷積神經網絡。當圖像出現復雜場景及較大的外觀變化時,需要被不同類型的注意力機制關注。在注意力機制和人臉檢測研究進展的啟發下,本文在全卷積網絡結構中引入了殘差注意力機制。
2 相關工作
本文研究了復雜場景下基于R-FCN的小人臉檢測算法,通過文獻調研將相關工作組織成如下三個部分:
在過去幾年里,人臉檢測已經得到廣泛的研究。Viola 和Jones[8]發明了一個使用Haar-like 特征的級聯AdaBoost 人臉檢測算法,在那之后,大量的工作集中在發展更高級的特征和更強的分類算法。文獻[9]開發了一個多任務訓練算法,共同學習人臉檢測和校準。文獻[10-11]使用基于Faster R-CNN 算法,提高了人臉檢測算法的性能。文獻[12]探索了人臉的上下文信息,并提出一種實現高性能檢測小臉的算法。
現階段,人臉檢測方面的進展主要得益于強大的深度學習方法。基于卷積神經網絡CNN的目標檢測算法在人臉檢測方面取得了很大發展,典型的算法中R-FCN是以一種完全卷積的方式實現檢測,該算法大大提高了訓練和測試的效率。
為了能有效檢測到小人臉,近些年針對復雜場景下的人臉檢測研究提出,從空間維度層面來提升網絡的性能。但是,目前已很難再從空間維度層面來提升網絡的性能。文獻[7]提出網絡可以從其他層面來提升性能,即研究特征通道之間的關系。文獻[13]提出新的思路,即將深層卷積神經網絡與人類視覺注意力機制相結合,應用到圖像檢測中。
本文基于以上研究,提出將文獻[7]與文獻[13]中的核心方法,即重新分配圖像特征通道間的權重,以及特征圖間的權重,共同融合到R-FCN算法中,用于復雜場景下的小人臉檢測,取得了很好的效果。
3 提出的方法
本文從三個方面改進了針對人臉檢測的R-FCN框架。首先,為了更精準的檢測小臉,本文設置了更小尺寸的Anchors,并將位置敏感的感興趣區域池化到更小的尺寸;其次,提出在主干網絡ResNet 上引入Squeezeand-Excitation模塊,顯式地建立特征通道之間相互依賴的關系,并且自適應的重新校準通道的特征響應;最后,將深度卷積神經網絡與人類視覺注意力機制進行有效的結合,引入了Residual Attention Network(殘差注意力網絡),使得不同層次的特征圖能夠捕捉圖像中的多種響應結果。并且采用多尺度訓練策略和Online Hard Example Mining(OHEM)技術對數據進行訓練。
3.1 R-FCN框架
R-FCN最初用于目標檢測,是一個基于區域的完全卷積網絡。R-FCN主干網絡為殘差網絡ResNet-101,從ResNet-101 輸出的特征圖中,RPN 根據Anchors 生成一系列的ROIs,這些ROIs進一步被輸入到R-FCN模型的位置敏感RoI池化層中,并產生每一類的分數圖和邊界框的預測圖。R-FCN 模型的最后兩個全局平均池化層分別用于類分數圖和邊界框預測圖,得到聚合類分數和邊界框的預測。
本文采用R-FCN算法有兩個主要優點:第一,位置敏感RoI 池化層巧妙地將位置信息編碼到每個RoI 中,映射到輸出分數地圖的某個位置上;第二,將完全卷積網絡ResNet 與基于區域的模塊結合起來,使得R-FCN 的功能圖更容易表達,也更容易學習類的分數和邊界框。
為了提高檢測準確率,更好的檢測小目標人臉,本文基于R-FCN 列舉了多個小尺寸的anchors,比如設置anchors_scales 為(16,32,64,128,256,512),這些小的anchors 對于有效捕捉小人臉是極其有幫助的。此外,在位置敏感的RoI 池化層設置了更小的pool_size 來減少冗余信息。
3.2 Squeeze-and-Excitation模塊
在傳統R-FCN 工作中,ResNet-101 體系結構主要用于特征提取。眾所周知,ResNet 構建了一個極深的網絡,將channel-wise 和spacial 信息一起提取到local receptive fields 里,得到了具有高度代表性的圖像特征。但是,在此過程中,ResNet-101 忽略了圖像特征通道之間的關系。在local receptive fields中,特征通道之間的關系是一個不確定因素,導致了圖像中重要信息的丟失,因此,檢測小的人臉時,出現誤檢或漏檢的情況。
與傳統R-FCN相比,本文在主干網絡Resnet-101上引入了Squeeze-and-Excitation模塊,使得能夠顯式地建模特征通道之間的相互依賴關系。另外,采用了一種全新的特征重標定策略。具體來說,就是通過學習的方式來自動獲取到每個特征通道的重要程度,然后依照這個重要程度去加強有用的特征并抑制對當前任務用處不大的特征。
如圖2 為Squeeze-and-Excitation 模塊示意圖。給定一個輸入,其特征通道數為c1,通過一系列卷積等一般變換后得到一個特征通道數為c2的特征。與傳統R-FCN不一樣的是,本文通過三個操作來重標定前面得到的特征。

圖2 Squeeze-and-Excitation模塊
如圖2 所示,X →U 的實現過程,一般就是CNN中的一些普通的操作,例如卷積或一組卷積,如公式(1)所示。

U 為圖2中左邊第二個三維矩陣,有c 個大小為的feature map。其中,vc表示第c 個卷積核,xs表示第s 個輸入,uc表示u 中第c 個二維矩陣,下標c 表示channel數目。
如公式(2)所示,對應圖2中的函數Fsq,即Squeeze操作,本文選擇最簡單的全局平均池化操作,順著空間維度來進行特征壓縮,對其每個feature map進行壓縮,使c 個feature map 最后變成1×1×c 的實數數列,這個實數數列某種程度上具有全局感受野,并且輸出的維度和輸入的特征通道數相匹配。Squeeze操作得到在特征通道上響應的全局分布,使得網絡低層也能利用全局信息。
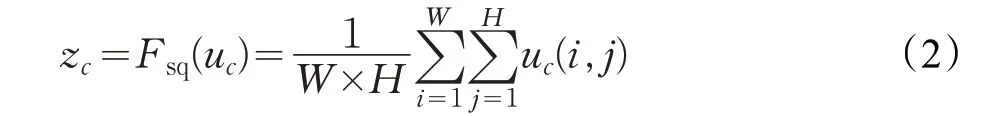
如公式(3)所示,對應圖2 中的函數Fex,即Excitation操作。學習參數W 來顯式地建模特征通道間的相關性,通過參數W 來為每個特征通道生成權重。

通過引入兩個1×1的conv層,一個是參數為W1的降維層,降維比例為r(本文設置r 為16),一個是參數為W2的升維層。其中,,δ 表示Relu 函數。最終得到維度為1×1×c 的結果s,用來刻畫U中c 個feature map 的權重。其中,c 表示channel 數目。且s 是通過兩個1×1 的conv 層和非線性層學習得到的。
如公式(4)所示,對應圖2 中的函數Fscale,是一個重新加權的操作,將Excitation 輸出的權重看作是特征選擇后每個特征通道的重要性,然后通過Fscale函數將通道加權到先前特征上,完成在通道維度對原始特征的重標定。

其中,X=[x1,x2,…,xc],Fscale(uc,sc)為特征映射uc∈RW×H和標量sc之間的對應通道乘積。
Squeeze-and-Excitation 模塊本質上引入了以輸入為條件的動態特征,其有助于提高特征辨別力,使得網絡模型更加敏感。
如圖3 所示,通過原始殘差模塊和本文引入的SE-ResNet模塊對比可以發現,本模塊構造非常簡單,而且很容易部署。
3.3 殘差注意力網絡
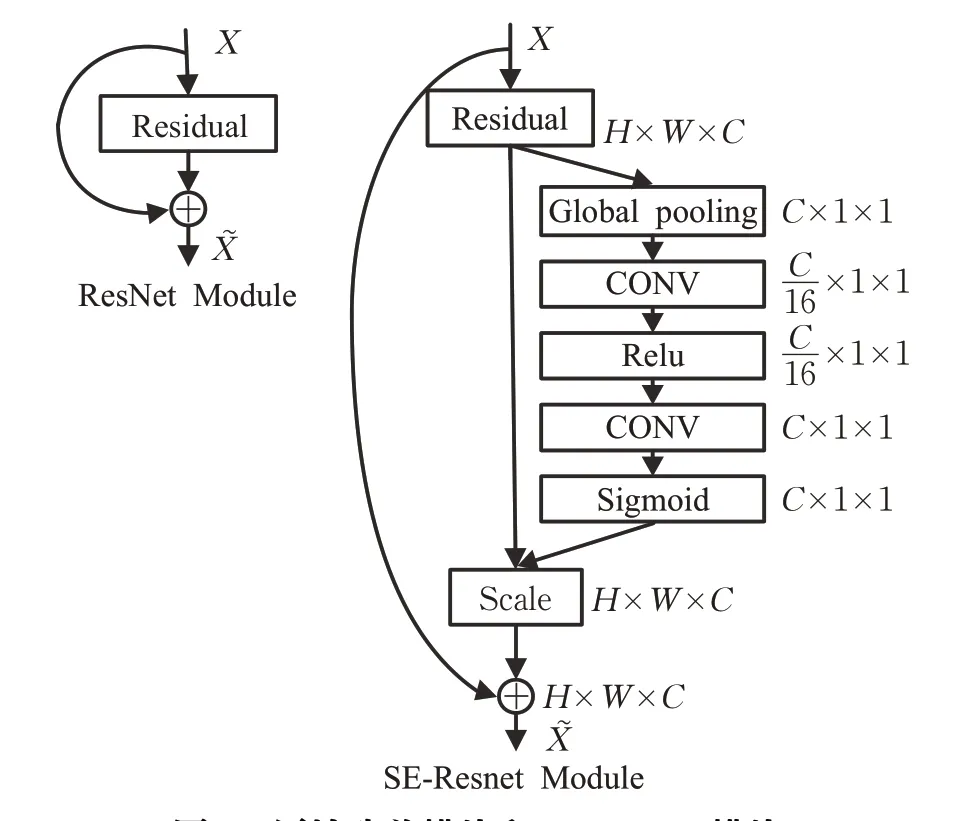
圖3 原始殘差模塊和SE-ResNet模塊
傳統的目標分類、檢測和分割,往往是通過單一的網絡結構提取整張圖像的特征。從人腦注意力機制去思考,這種方法不一定是最優的,每一個圖像樣本都具有內容性,而且基本每張圖片的內容并不會均勻分布在圖片中的每一塊區域。所以,對于圖像的內容區域使用注意力機制進行輔助,在增強有效信息的同時抑制無效信息,使得進行更準確的檢測。
殘差注意力網絡主要由多層注意力模塊堆疊而成,每個注意力模塊包含了兩個分支:主干分支(Trunk Branch)和軟掩膜分支(Soft Mask Branch)。
其中,主干分支為ResNet-101,掩膜分支通過對特征圖的處理,輸出維度一致的注意力特征圖(Attention Feature Map),通過點乘操作將兩個分支的特征圖組合在一起,得到最終的輸出特征圖。
如圖4所示,對于某一層輸出feature map,即下一層的輸入,傳統R-FCN網絡,只有右半部分Trunk Branch,本文在這個基礎上增加了左半部分,即Soft Mask Branch。

圖4 殘差注意力網絡
在軟掩膜分支(Soft Mask Branch)中,特征圖的處理操作主要包括采樣過程和上采樣過程,前者是為了快速編碼,獲取特征圖的全局特征;后者主要是將提取出來的全局高維特征上采樣之后,與之前未降采樣的特征組合在一起。其目的是使得上下文,高低維度的特征能夠更好的組合在一起,這樣就結合了全局和局部的特征,增強了特征圖的表達能力。
接下來,將Soft Mask Branch與Trunk Branch的輸出相結合,Soft Mask Branch輸出的Attention Map中每一個像素值,是對原始Feature Map 上的每一個像素值的重新加權,它會增強有意義的特征,同時抑制無意義的信息。由于Soft Mask Branch的激活函數是Sigmoid,輸出值在(0,1)之間,所以,無法直接將這個Weighted Attention Map輸入到下一層中,導致前后兩層的Feature Map有較大的差異。因此,為了進一步抑制不重要信息,將Soft Mask Branch與Trunk Branch輸出的Feature Map進行相乘,得到了一個加權后的注意力圖Weighted Attention map,最終該注意力模塊的輸出特征圖如公式(5)所示。
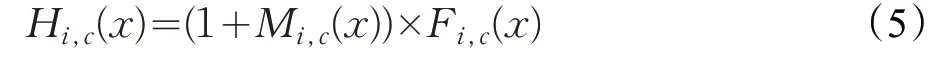
其中,M(x)為Soft Mask Branch的輸出,F(x)為Trunk Branch的輸出。
3.4 多尺度訓練和測試
本文受文獻[14]的啟發,采用多尺度的訓練和測試策略以提高性能。在訓練階段,將輸入的最短邊調整為1 024。這個訓練策略保證模型在不同尺度上檢測人臉的魯棒性,特別是在小人臉上,能夠很好地檢測。在測試階段,為每個測試映像構建一個圖像金字塔,金字塔中的每一個尺寸都獨立測試,用于更好地檢測小的和一般人臉。最終將各種尺寸的測試結果合并為圖像的最終結果。
在RPN階段,為了精準的檢測小人臉,將一系列多尺度和縱橫比結合起來構造多尺度anchors,比如縱橫比設為(0.5,1,2),然后這些anchors 映射到原始圖像來計算IoU(Intersection-over-Union,交集并集比)分數,規則如下:(1)擁有最高IoU 分數的anchors 被嚴格地視為正樣本;(2)IoU得分高于0.7的被視為正樣本;(3)IoU得分低于0.3 被視為負樣本。最后,采用Non-Maximum Suppression方法,根據給定的IoU評分來調整anchors。
本文算法采用多分類損失函數,同時考慮了分類的損失,和位置的損失,如公式(6)~(8)所示。
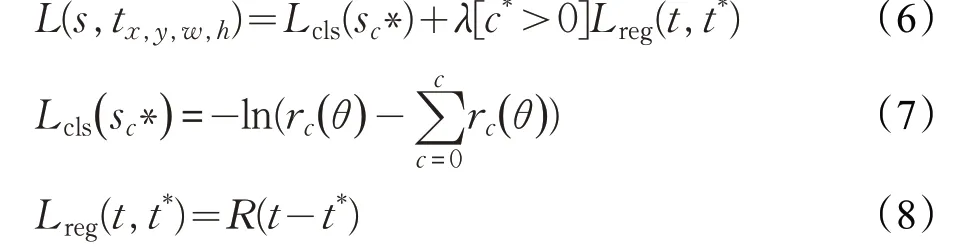
其中,c*表示ROI的類標,Lcls表示分類的交叉熵損失,Lreg表示位置的損失,t*表示真實回歸框的參數,t=( tx,ty,tw,th)表示RPN得出的回歸框的參數。如果分類正確,[c*>0]為1,分類錯誤則為0,對分類錯誤的不進行位置損失。超參數λ=1,表示分類損失和位置損失同等重要。
本文算法采用回歸函數Smooth-L1 loss,如公式(9)所示。

其中,x=t-t*。
4 實驗及結果與分析
4.1 實驗環境
本文的實驗環境配置如表1所示。

表1 實驗環境配置
4.2 數據集
本文使用人臉檢測領域最常用的標準公開數據集Widerface[15]來評估本文算法,它包含32 203 張圖片及393 703 張已標注人臉,Widerface 數據集圖片中的人臉在比例,姿勢和遮擋方面都具有很大的變化。圖片中人臉數據偏多,平均每張圖片有12.2 個人臉,密集小人臉非常多。數據集包含三部分:訓練集train、驗證集val、測試集test,分別占40%、10%、50%。本文在復雜場景下進行檢測,難度會有所加大,所以在這種檢測困難的情況下驗證集和測試集分為三個難度等級為“easy”“medium”“hard”的子集。
4.3 模型訓練策略
本文采用預訓練的ResNet-101模型進行特征提取,經過ImageNet[16]數據集的訓練,使其具有強大的圖像特征提取能力。在訓練階段,將輸入的最短邊調整為1 024,模型使用SGD算法(隨機梯度下降)在Widerface數據集上進行訓練,更新網絡權值,每次迭代訓練時,從這些正負樣本中隨機選擇128 張為一個Mini-batch,將OHEM應用于負樣本,并設置正和負樣本的比例為1∶3,設置初始學習率為0.001,經過4 萬次迭代后,降低學習率為0.000 1,繼續迭代2 萬次結束訓練。測試時,圖片不需要縮放,直接以原圖的方式輸入到已訓練好的模型中。在Widerface測試集上進行人臉檢測的部分檢測結果,如圖5 所示的綠色矩形框。如圖所示,是本文算法在Widerface 測試集上的部分測試效果圖,對于復雜背景中的小尺度人臉一般算法往往不能有效檢測,而本文算法在檢測小人臉上具有顯著的優勢。

圖5 部分測試效果圖
4.4 實驗結果分析
4.4.1 模型性能分析
在殘差網絡ResNet-101 上進行融合后,首先驗證融合后殘差網絡模型的有效性,本文在數據集上進行了實驗,并從性能的增益來進行論證,結果如表2所示。

表2 不同模型的性能對比
表2 分別展示了ResNet-101、ResNet-152 和融合后模型的結果。從上表可以看出,融合后的模型在錯誤率上遠遠低于原始模型,這說明其能夠給網絡帶來性能上的增益。值得一提的是,本文錯誤率甚至低于更深的ResNet-152。
從表3可以得出設置多個尺寸、多個比例的anchors,有助于提升人臉的檢測精度,同時設置較小尺寸的anchors,可以有效地捕捉小的人臉。

表3 anchors的設置分析對比
4.4.2 不同子集下算法準確率分析
將本文算法與近幾年提出的人臉檢測算法Faceness-Net[17]、MTCNN[9]、Faster RCNN[3]、CMS-RCNN[11]進行比較,在Widerface驗證子集上的測試結果,如表4所示。
本文算法與其他算法在同一數據集上的實驗結果表明,本文算法在easy、medium、hard子集上精度分別為89.3%、87.0%、75.7%。與其他人臉檢測算法相比,本文算法在easy、medium、hard子集上的檢測精度與Faceness-Net 相比,分別提高了17.7%、26.6%、44.2%;與MTCNN算法相比,分別也提高了4.2%、5.0%、15.7%。與上述兩個算法相比本文通過重新分配圖像特征通道間的權重,及特征圖間的權重,使得網絡模型更加敏感,最終證明本文算法在人臉檢測上的精確性。

表4 本文算法與其他人臉檢測算法的對比
雖然本文算法在easy、medium 子集上檢測結果略遜于Faster RCNN、CMS-RCNN,但是在hard 子集上卻遠遠超過了以上兩種算法,分別提升了4.1%、11.4%。說明本文算法在小人臉檢測上比其他方法表現得更好,在easy、medium子集上也具有一定魯棒性。
4.4.3 運行時間分析
所有算法都在NVIDIA GeForce TITAN X GPU上運行,從Widerface 數據集中隨機抽取1 000 張圖像,結果如表5所示。
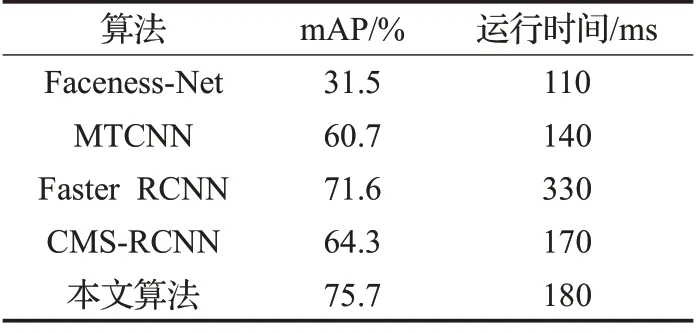
表5 不同人臉檢測算法的運行時間對比
表5 給出了在Widerface 人臉數據集中不同檢測算法的運行時間比較,運行時間是在Widerface 數據集中隨機抽取1 000張圖像的平均檢測時間。
與近幾年提出的人臉檢測算法相比,本文算法在Widerface 測試集上測試的精度為75.7%,運行時間為180 ms,Faceness-Net、MTCNN雖然運行時間為110 ms、140 ms,但是它們檢測的平均精度為31.5%、60.7%,遠遠低于本文結果,FasterRCNN 檢測的平均精度雖然達到不錯的結果,但是其運行時間過長;相較于CMSRCNN,本文算法精度明顯高出10%,運行時間卻與其基本相近。
綜合以上,本文算法無論是檢測精度還是運行時間均優于其他算法。
5 結束語
本文提出一種基于R-FCN 框架的人臉檢測算法,融合Squeeze-and-Excitation 模塊、殘差注意力機制、多尺度的訓練和測試,以及Online Hard Example Mining策略,通過將圖像的特征通道與特征圖進行加權,增強重要信息的同時抑制無效信息,使得網絡模型更加敏感。在處理復雜的人臉和非人臉分類與檢測問題時,能夠更加精準。通過在Widerface 數據集上的實驗,驗證了在檢測小人臉時,本文算法檢測精度上優于現有的算法。雖然改進后的算法參數有所增加,但實驗證明本文算法的時間復雜度并沒有明顯提高,下一步的工作將設計更加精簡的網絡框架,進一步降低檢測的時間復雜度。
猜你喜歡
數學小靈通·3-4年級(2024年2期)2024-05-15 02:02:28
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2020年12期)2021-01-18 06:57:46
中學生數理化·七年級數學人教版(2020年12期)2021-01-18 06:57:46
世界科學技術-中醫藥現代化(2020年2期)2020-07-25 02:05:36
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
