基于Hadoop平臺及LSTM模型的城市交通出行數據挖掘
2020-02-01 15:23:16葉奕黃檢寶唐斌斌肖波雄賀紫月
現代計算機 2020年34期
葉奕,黃檢寶,唐斌斌,肖波雄,賀紫月
(1.南華大學計算機學院,衡陽421000;2.南華大學經濟管理與法學學院,衡陽421000)
0 引言
自21世紀起,在中國智慧城市建設持續推進、城鎮化速度不斷加快等條件的推動下,國內的城市交通系統行業以及透過城市交通帶動的其他產業逐漸從前期走向快速發展、產業化發展階段。科技產業鏈及信息產業鏈在帶動了城市GDP高速增長的同時,也相應地為城市的交通監管帶來了一系列應戰。如何更加合理地調控和配置交通資源呢?如何優化一個城市的交通部署,在規劃資源有限的情況下最大程度地減少人力和物力的投入,減少交通運輸的維護成本呢?如何減少能源消耗與廢氣廢物排放,打好綠色生態發展的“城市攻堅戰”呢?
基于上述考慮,越來越多的城市依靠大數據技術等新興科技技術手段,開發建設城市交通數據分析系統,挖掘交通數據背后隱藏的價值,分析問題所在來管理和規劃城市交通。針對本文,我們需要做的是通過挖掘分析城市一天的人流交通出行數據,復現城市一天的交通規劃管理。
我們以遼寧省沈陽市為例,通過對沈陽市各縣(市)、區一天的人群軌跡移動數據,分析其每個區域的人群密度變化,人群的出行方式變化,得到人群的駐留分析。除此之外,基于挖掘分析的交通數據,進一步進行預測分析,通過預測人群密度,得出人群對出行方式的傾向性。
1 數據預處理
在進行數據的預處理之前,我們需要安裝使用Ha?doop平臺的Linux操作系統、搭建Hadoop平臺偽分布式集群模式及處理好相應的配置文件。本文使用的Linux系統版本為Ubuntu 18.04,Hadoop版本為2.7.1。
1.1 HDFS文件操作
預處理的數據需要以文件的模式先上傳至Hadoop分布式文件系統(簡稱HDFS),通過輸出控制臺指令,對數據實行增添、刪減、修正和下載的操作。指令代碼如下所示:
hdfs dfs-mkdir/myTask
hdfs dfs-put/mydata/test.txt/myTask/input
hdfs dfs-rmr/myTask/wordcount.txt
hdfs dfs-get/myTask/input/wordcount.txt/test
1.2 數據清洗
從HDFS讀取的數據中,存在一些噪點干擾,也就是常說的“臟數據”。我們需要根據自定義的清洗規則對數據進行篩選清理。對于數據項中存在的特殊字符,例如‘#’、‘*’、‘^’,對此條數據進行剔除操作。對于信息殘缺的一整條數據,也需要刪除。

圖1 部分噪點數據展示
1.3 時間戳處理
當原始數據中存在時間數據(如20190603000000)時,需要將時間轉換為易讀的格式(如2019-06-03 00:00:00)。這里可以借助java.util.Data包進行時間轉換,具體代碼如下所示:

1.4 部分數據關聯
當原始數據中存在具體的空間定位信息時,我們需要進行合并操作。例如需要將緯度和經度合并成坐標表示,將定位基站的唯一標識id和基站信息碼進行關聯等。可采取數據庫語言進行簡單的表連接操作,關聯效果如圖2所示。

圖2 部分數據關聯效果展示
2 并行詞頻化統計批處理
通過數據預處理,原始數據中存在的噪點和無價值的數據已經被取代,但此時的數據僅僅代表了一個人在某一個時刻駐留的定位信息和其選擇的何種出行方式。我們需要將冗余的數據信息通過唯一標識id進行歸類操作(標簽化),即將同一個人在一天當中所有時刻的定位信息進行合并,得到此人當天出行的數據集合。
2.1 MapReduce并行詞頻框架
MapReduce框架技術對數據采取分而治之的思維,通過構建抽象模型函數(Map映射和Reduce歸類),并行自動化處理數據。
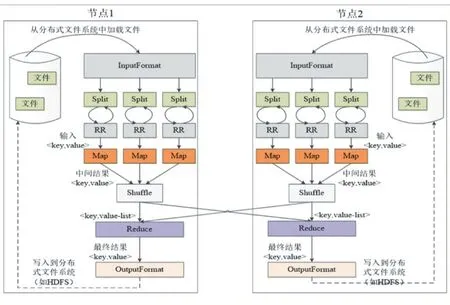
圖3 MapReduce并行詞頻執行流程
2.2 具體過程
(1)重寫Hadoop框架函數類。readFields類和write類可以將存儲數據的自定義類通過定義的變量名在集群模式上讀寫。這里的變量名包括id、時間、經緯度和出行方式標簽值等,代碼如下所示:

(2)key值排序和組合。通過對key值進行排序和再次組合達到二次排序的效果。第一次排序,繼承Writ?ableComparator類,重寫compare方法將key值按照自定義類的id進行升序排序。第二次排序,在key值有序的情況,將id相同的數據合并,并按時間進行升序排序。
(3)Map階段。Map讀入HDFS文件每一行內容,然后對數據進行處理,創建自定義類為key鍵,在二次排序中,主要是對key進行排序與組合處理,所以可將鍵值對中的value設置為null。
(4)Reduce階段。接受處理過的鍵值對,遍歷集合列表獲取key鍵排序結果,然后自定義輸出格式后輸出到HDFS中。
(5)結果分析。通過圖4展示,的確實現了二次排序的效果,將id歸類,并且對每個人的經緯度按照時間順序進行了排序,利用此結果可以進一步得出個人的交通出行軌跡。
圖4 處理效果展示
3 LSTM預測分析
3.1 模型簡介
長短期記憶神經網絡(Long Short Term Memory,LSTM)是一種循環時間神經網絡,設計的目的是為了處理在傳統RNN神經網絡中存在的神經單元依賴問題,可以在一定程度上解決RNN的梯度爆炸或梯度消失等問題。LSTM適宜應用于處理和預測時間序列中間隔和延遲比較長的場景。
3.2 模型闡述
(1)符號說明
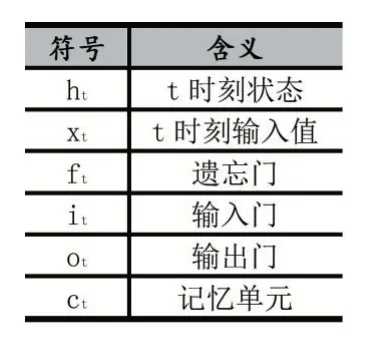
表1 符號含義
(2)模型結構
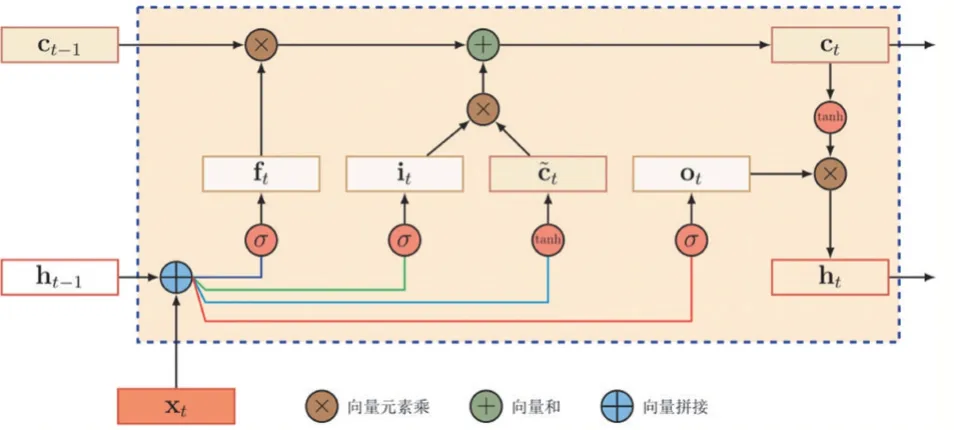
圖5 LSTM模型結構
模型計算過程為:在上一個時刻的外部狀態ht-1和當前時刻輸入xt的基礎上,計算it,ft,ot和c?t,根據遺忘門ft和輸入門it來更新記憶單元ct,再根據輸出門ot,將內部狀態的信息傳遞給外部狀態ht。
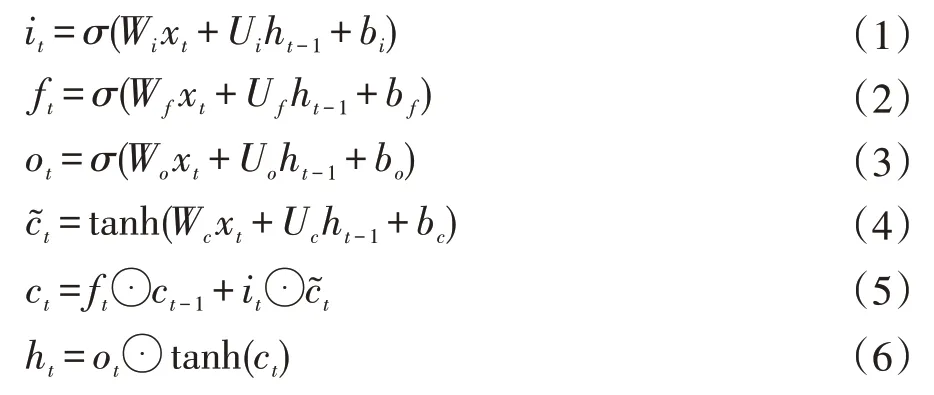
3.3 模型建立
模型首先添加兩層的LSTM網絡結構,其中每一層有128個記憶單元,通過對每一層dropout隨機失活來抑制過擬合,由于預測數據呈線性分布,最終的全連接輸出層激活函數設為sigmoid函數,用均方差衡量預測值與真實值之間的差距,并通過adam優化器來更新梯度。具體結構如圖6所示。
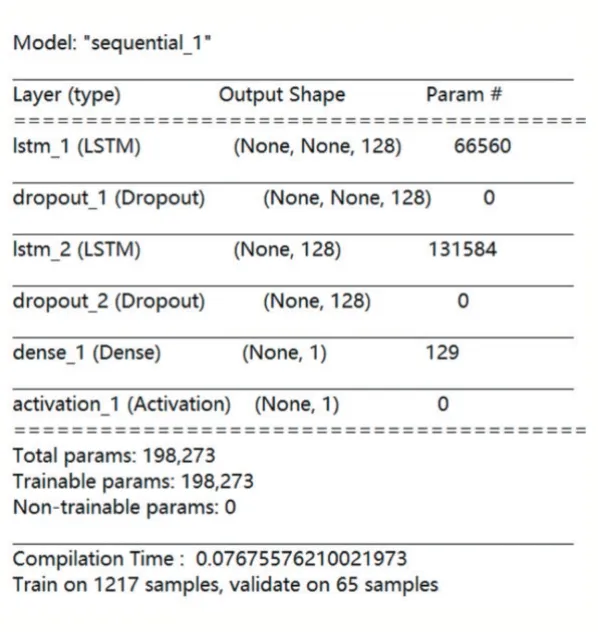
圖6 模型具體結構圖
3.4 模型求解和訓練
(1)求解思路
為了實現對某種出行方式(地鐵和公交)的人流預測,得出人群對出行方式的傾向性,我們需要對單一出行方式的人流進行統計。以每個車站為原點,百米為半徑,對每個車站附近的流動人口計數,基于車站面積的一致性,可以用人流數量來代替人群密度;再對每個時刻每種出行方式的人群數量進行統計,出于對數據的正則化效率的考慮,我們以分鐘為基本單位統計。
(2)正則化和歸一化
歸一化就是將大范圍的離散數據,放縮到某個單位區間內,這樣能加快模型的收斂速度。而正則化是采取一系列的措施限制,來避免模型過擬合,以提高模型的泛化能力。
首先對數據進行歸一化,將數據標本縮小到0和1之間,這里用到的歸一化公式為:

然后對歸一化的數據進行正則化,優化問題可以寫為:
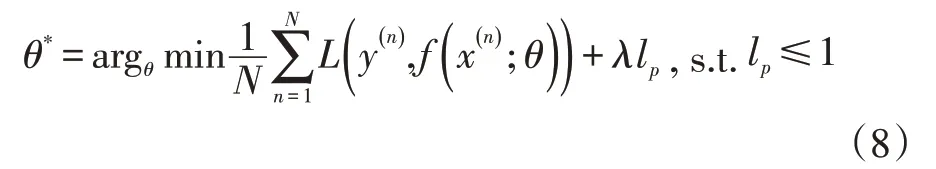
其中L為損失函數,N為訓練樣本,f為待學習的神經網絡,θ為其參數,lp為范數函數,λ為正則化系數。
(3)訓練過程
將滑動區間設置為15分鐘,以前15分鐘的數據統計預測后1分鐘的走向,對數據集拆分為輸入數據和label標簽值數據,由于只有一天的數據集,將訓練集和測試集的劃分比例設置為9:1,迭代次數為30次較適宜。

圖7 部分訓練過程
3.5 結果分析
通過比較公交和地鐵兩種出行方式的真實值和預測值,可以直觀地發現模型訓練效果較好,但由于訓練樣本有限,模型過擬合的幾率也就不可估量,泛化能力也有待提高。在人群密度波動比較大的情況下,該模型還是能夠達到較好的監控交通人流變化的效果。
4 Echarts可視化數據
Echarts作為當前被開發者極力推崇的前端框架,它提供了豐富的可高度自制、性能優異、交互體驗良好的數據可視化組件及模板。我們在前面處理的各種數據需要通過類似于Echarts一類的數據可視化框架展示在前端網頁中。依托Echarts中的折線圖、扇形圖、柱狀圖、城市地圖等響應式交互組件,配以JavaScript語言編寫代碼完成異步加載數據和地圖的series視覺映射,我們的城市交通系統實現了對沈陽市地圖輪廓的復現、各縣(市)區實時流量比對和人群選擇出行方式的統計等功能。

圖8 地鐵預測結果圖
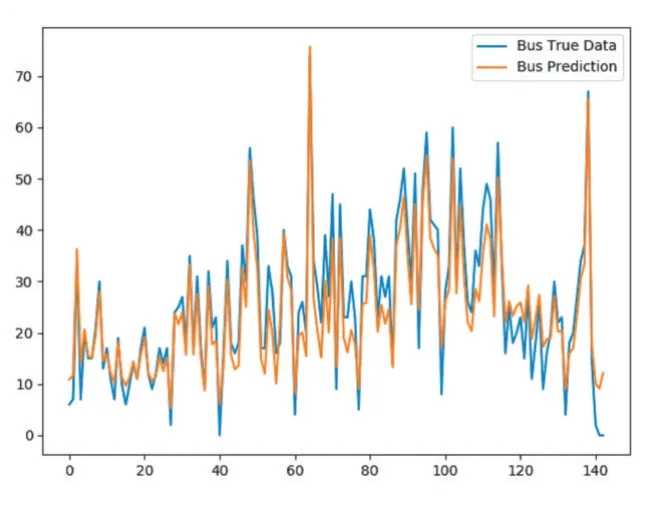
圖9 公交預測結果圖

圖10 系統主界面展示
5 結語
基于Hadoop平臺并行詞頻化技術,我們實現了對交通數據的批處理,將無用的數據剔除,把有價值的數據進行進一步挖掘歸類。通過深度學習領域中的LSTM模型,我們實現了對選擇不同出行方式的人群密度預測,根據結果展示,在絕大多數時刻,人群傾向于選擇公交的基數比傾向于選擇地鐵的多,并且預測效果良好,與真實情況大體一致。針對挖掘分析的數據,之所以能發現數據背后潛在的價值,離不開直觀的可視化數據展示。我們在進行數據處理、挖掘和分析的同時,同樣要兼顧系統開發的架構,在開發前端界面時,要考慮圖表、視圖制作所引用數據的規范性、合理性和可行性,如此才能更好地實現數據可視化。在系統展示中,和平區、鐵西區和沈河區人群流量的波動最大,這一點可以從實現24小時實時輪播的人群密度比對的扇形圖表中發掘,于是我們重點提取了人群密度最大的和平區進行更加細致的監控,以達到交通資源進一步合理分配的效果。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
兒童時代·幸福寶寶(2022年12期)2022-12-09 11:24:14
中學生數理化·七年級數學人教版(2022年11期)2022-02-14 07:14:12
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
科普童話·學霸日記(2020年1期)2020-05-08 16:45:11
小天使·一年級語數英綜合(2019年2期)2019-01-10 11:57:30
兒童繪本(2018年5期)2018-04-12 16:45:32
光學精密工程(2016年6期)2016-11-07 09:07:19
核科學與工程(2015年4期)2015-09-26 11:59:03
