機器翻譯的終極之路在哪里(上)
2020-02-10 04:07:35倪俊杰
中國信息技術教育 2020年1期
倪俊杰


編者按:據不完全統計,世界上現存語言超過7000多種,即使人類不眠不休窮盡一生的力量也只能掌握幾十種語言。于是,很多科學家開始思考,如何用機器來幫助人們解決溝通問題,因此機器翻譯應運而生了。那么,什么是機器翻譯?機器翻譯是如何發展的?目前還有哪些應用呢?接下來,我們將共同來了解這些內容。
50多年前,由劉涌泉、高祖舜、劉倬三人共同編著的《機器翻譯淺說》由科學普及出版社出版,書中提出了兩個很有意思的設想。第一個設想是當你在人民大會堂的時候,你會發現無論哪個國家的人在臺上講話,與會者都能從耳機里聽到自己國家的語言,同時你會發現在耳機里進行翻譯的不是人,而是我們的萬能翻譯博士;第二個設想是當你去國外旅行的時候,隨身可以攜帶一個半導體和其他材料制成的小型萬能博士,當我們跟外國朋友交談的時候,博士能立刻給你翻譯出各自國家的語言。這兩個設想在當時看來是“天方夜譚”,但現在都已經成為現實,第一個是現在的同聲傳譯,第二個就是翻譯機。這兩項技術的實現都得益于機器翻譯技術。那么,什么是機器翻譯呢?實際上,機器翻譯是一個充滿挑戰的研究領域,正因為難度很大,所以它被列為21世紀世界十大科技難題之首。但隨著全球化進程的加速以及國際交流的日趨頻繁,人們對翻譯的需求空前增長,在這一領域的競爭正變得空前激烈,世界各國都在這個領域投入了大量的人力和財力,也使得機器翻譯能夠深切地融入到我們的生活中。既然如此,我們就有必要了解機器翻譯的發展歷程以及它的基本應用。
什么是機器翻譯
百度百科釋義:機器翻譯(Machine Translation)又稱為自動翻譯,是利用計算機將一種自然語言(源語言)轉換為另一種自然語言(目標語言)的過程。機器翻譯是自然語言處理(Natural Language Processing)的一個分支,與計算語言學(Computational Linguistics)和自然語言理解(Natural Language Understanding)之間存在著密不可分的關系。實際上,機器翻譯的研究歷史早于計算機的誕生,可以追溯到20世紀30年代初,法國科學家G.B.阿爾楚尼提出了用機器來進行翻譯的想法。1933年,蘇聯發明家特羅揚斯基設計了把一種語言翻譯成另一種語言的機器,只可惜他的翻譯機因為客觀原因最終沒有制成。1946年,第一臺現代電子計算機ENIAC誕生。隨后不久,信息論的先驅、美國科學家W. Weaver和英國工程師A. D. Booth在討論電子計算機的應用范圍時,提出了利用計算機進行語言自動翻譯的想法。1949年,W. Weaver發表《翻譯備忘錄》,正式提出機器翻譯的思想。
細數機器翻譯的發展進程,也是漫長而曲折的。1954年,美國喬治敦大學在IBM公司的協同下,用IBM-701計算機首次完成了英俄機器翻譯試驗(如下頁圖1),向公眾和科學界展示了機器翻譯的可行性,從而拉開了機器翻譯研究的序幕。它能將俄語翻譯為英文,但里面只內建了6條文法規則以及250個單字。
中國也在1956年就把這項研究列入了全國科學工作發展規劃。1957年,中國科學院語言研究所與計算技術研究所合作開展俄漢機器翻譯試驗,翻譯了9種不同類型的較為復雜的句子。但是在1966年,美國國家科學院語言自動處理咨詢委員會(Automatic Language Processing Advisory Committee,ALPAC)發布題為《語言與機器》的報告,宣稱“目前給機器翻譯研究以大力支持沒有太多的理由”“機器翻譯遇到了難以克服的語義障礙”,從而導致機器翻譯研究在世界范圍內走向低迷。
進入70年代,隨著計算機科學、語言學研究的發展,特別是計算機硬件技術的大幅度提高以及人工智能在自然語言處理上的應用,各種實用的以及實驗的系統被先后推出,如Weinder系統、EURPOTRA多國語言翻譯系統、TAUM-METEO系統等。20世紀80年代末期,IBM公司實現了基于噪聲信道模型的統計機器翻譯系統,并在美國國防部高級研究計劃署(ARPA)組織的評測中取得了較好成績,推動了機器翻譯技術的快速發展。我國的“784”工程也給予了機器翻譯研究足夠的重視。80年代中期以后,我國首先成功研制了 KY-1 和MT/EC863 兩個英漢機譯系統。進入90年代,互聯網的快速發展讓人們對機器翻譯的需求空前增長,國際性的關于機器翻譯研究的會議頻繁召開。中國也取得了前所未有的成就,相繼推出了一系列機器翻譯軟件,如“譯星”“雅信”等。21世紀以來,互聯網公司紛紛成立機器翻譯研究組,研發了基于互聯網大數據的機器翻譯系統,從而使機器翻譯真正走向實用,如“有道翻譯”“百度翻譯”“谷歌翻譯”等。近年來,隨著深度學習的進展,機器翻譯技術得到了進一步的發展,促進了翻譯質量的快速提升,在口語等領域的翻譯也能更加地道、更加流暢。
機器翻譯技術的發展歷程
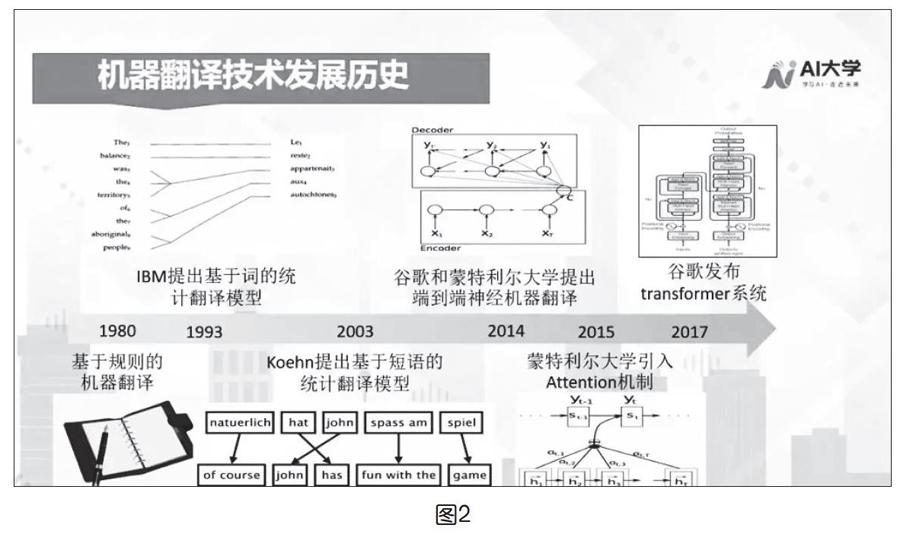
機器翻譯的原理并不簡單,其發展歷程也是由淺入深的。隨著計算機技術和語言學的快速發展,機器翻譯的方法也在更新迭代(如圖2)。大致可以分為三種類型,分別是基于規則的方法、基于統計的方法和基于神經網絡的方法。
1.基于規則的方法
最早期的機器翻譯就是采用基于規則的方法。這類方法要找大量的人類語言學家來寫規則,把一個單詞翻譯成另外一個單詞、這個成分翻譯成另外一個成分、在句子中出現在什么位置,都要用各種各樣的規則表示出來,如早期的文曲星(如上頁圖3)。這類方法是知識驅動,需要語言學家的專業知識,包括源語言和目標語言的詞法、語法、句法等,翻譯的時候就基于這些規則去“嵌套運用”,最終“組合”成相應的句子。很顯然,這種方法的優點是準確率比較高,缺點是成本很高,這里包括人力成本和開發周期成本,不同的語言要找不同語言的語言學家,而且如果句子長度、語境做出改變,規則的復雜度也會越來越高。基于規則的機器翻譯的優點是十分精細的翻譯引擎可翻譯廣泛的文本,缺點是必須為每個語言建立自定義的解析軟件和詞典,而且,基于規則的方法是相當“脆弱”的,它不能很好地處理俚語或隱喻文本。
基于規則的機器翻譯的主要供應商包括Systran、PROMT、Lucy Software(商業軟件)和Apertium(開源)。Systran從業較久,是網頁翻譯的先驅(早在20世紀90年代他們的翻譯引擎就為Babelfish提供網頁翻譯服務了)。Apertium是由西班牙Universitat dAlacant主導的開源項目。
2.基于統計的方法
20世紀80年代,日本京都大學的長尾真教授提出了基于實例的機器翻譯(example based machine translate),也就是別再去想讓機器從無到有來翻譯,它的理念是利用相似性復用系統中現有的翻譯用例,這是一種數據驅動的方法。基于實例的機器翻譯為統計機器翻譯奠定了基礎。統計機器翻譯系統是基于概率和統計的模型而不是語法規則,它建立了一個數學建模,可以在大數據的基礎上進行訓練。它的工作方式是使用非常龐大的平行文本(源文本及其翻譯)以及單語語料庫訓練翻譯引擎。系統會尋找源文本和譯文之間的統計相關性,然后根據源語言句子,去查找概率最大的譯文,翻譯引擎本身沒有規則或語法概念。IBM于1993年發表了論文《機器翻譯的數學理論》,提出了由五種以詞為單位的統計模型,稱為“IBM模型1”到“IBM模型5”。基于統計的機器翻譯能夠結合上下文,以及詞、短語、句法等知識,從統計學的角度判斷哪種翻譯方式的正確率更高,統計模型的思路是把翻譯當成幾率問題。
總的來說,統計機器翻譯的主要優點是不需要像基于規則的機器翻譯一樣,針對每個語言打造專門的翻譯引擎,只要收集足夠多的文本,就可以訓練針對任何語言的通用翻譯引擎。統計機器翻譯的主要缺點是在翻譯訓練語料庫中沒有相似的資料文本時,不能得到準確譯文。統計機器翻譯通常不能生成高質量的文本,它經常在不顧及上下文聯系的情況下翻譯原文,而且譯文語序往往不對。相比基于規則的方法,基于統計的方法成本較低,因為它和語言沒有關系,一旦翻譯模型建立以后,其翻譯知識來自于大數據的自動訓練。因此,在基于統計的機器翻譯中,語言模型的建立至關重要,因為語言模型是衡量一個句子在目標語言中是不是流利和地道的關鍵,計算機可以使用翻譯模型來“計算”如何將文本從一種語言轉換為另一種語言。
基于統計的機器翻譯的主要產品提供商有BeGlobal (SDL)、Google Translate、Microsoft Bing Translator、Moses等。其中Google Translate是谷歌基于自有的翻譯引擎和研究技術,提供的免費在線翻譯服務。Moses是一個開源的統計機器翻譯引擎,它已被業界廣泛應用于構建定制的機器翻譯引擎。
3.基于神經網絡的方法
隨著深度學習技術的發展,從2014年起基于神經網絡的機器翻譯方法開始興起。相比統計機器翻譯,神經網絡翻譯從模型上來說相對簡單,它主要包含兩個部分,一個是編碼器,一個是解碼器。編碼器是把源語言經過一系列的神經網絡的變換之后,表示成一個高維的向量。解碼器負責把這個高維向量再重新解碼(翻譯)成目標語言。2015年,百度發布了全球首個基于互聯網神經網絡的翻譯系統。2016年,Google公布了神經網絡機器翻譯(GNMT),科大訊飛也上線了NMT系統。短短三四年間,神經網絡翻譯系統在大部分的語言上已經超過了基于統計的方法(PBMT),已經極大地接近普通人的翻譯水平。
從圖4中可以看出,從基于統計的方法到基于神經網絡的方法,翻譯能力可以提升到60%以上,這是極大的進步。相比基于規則和統計系統,基于神經網絡的結構使系統更自適應,能處理更多更復雜的模型。它也可以根據經驗自我學習,如果它提供了不正確的輸出,它能從錯誤中吸取教訓,并做出調整,以便下次更有效地執行任務。
機器翻譯在生活中的應用
機器翻譯的快速發展,在很多領域得到了廣泛的應用。機器翻譯技術的進步和系統性能的提升在為人們日常生活和工作帶來更多便利的同時,也為該技術的產業化發展帶來了更多商機。關于機器翻譯的基本應用,大致可以分為三大場景:信息獲取為目的的場景、信息發布為目的的場景、信息交流為目的的場景。以信息獲取為目的的場景,可能大家都比較熟悉,如翻譯或是海外購物,遇到一些生僻的詞就可以借助機器翻譯技術,來了解它的真正意思。在信息發布為目的的場景中,典型的應用是輔助筆譯,比如起草一份文件需要多國語言的版本,就需要用到機器翻譯技術了。以信息交流為目的的場景,主要解決人與人之間的語言溝通問題,如同聲傳譯等。接下來,我們來看一些比較有意思的應用。
1.特殊中文翻譯
機器翻譯除了能做多國不同語言的翻譯之外,還可以在中文方面做一些有意思的事情。中文博大精深,源遠流長,文言文就是很有中國特色的語言表達方式。在百度翻譯中,實現了輸入白話文后,就能輸出文言文的效果(如圖5)。
除了翻譯文言文,機器翻譯還可以寫詩、寫春聯。在微信里關注小程序“為你作首詩”,輸入藏頭文字,選擇詩句類型,就可以由程序自動寫一首詩(如下頁圖6)。說起機器寫詩,就不得不提微軟小冰了。微軟小冰是由微軟(亞洲)互聯網工程院于2014年正式推出的融合了自然語言處理、計算機語音和計算機視覺等技術的人工智能“機器人”。微軟小冰已通過人工智能創造技術,學習優秀的人類創造者的能力,進行基于文本、語音和視覺的內容生成。在文本創作方面,主要覆蓋詩歌、金融摘要及研報等領域。2017年5月,微軟與湛廬文化公司合作,授權出版了歷史上第一部由人工智能創作的詩集《陽光失了玻璃窗》。同年8月,中國臺灣與時代文化公司合作,授權出版了該詩集的繁體中文版本。2019年,與中國青年出版總社合作并授權出版了第一部由人工智能與200位人類詩人聯合創作的詩集《花是綠水的沉默》。
2.同聲傳譯設備
什么是同聲傳譯?其實可以分解開來看,“同”表示時間延遲要短,在說話的同時基本上翻譯結果就傳遞出來;“聲”是指用到的是語音技術,包括語音識別和合成;“傳”就是信息傳遞要準確,得把原本的意思準確地表達出來;“譯”就是翻譯技術,對應到機器翻譯。同聲傳譯設備是實現高級別國際會議同步翻譯不可缺少的系統設備,通過該設備可以保證演講者在演講的同時,內容被同聲翻譯成指定的目標語言。隨著當前社會現代化進程的不斷推進以及人們生活水平的提高,同聲傳譯已經不僅僅是高端需求,普通民眾在出國旅游或者商務洽談的時候也會有此類需求。在某購物網站搜索“同聲傳譯器”,價格從幾百到幾千不等,款式有手持式、頭戴式,也有耳機式。點開某熱銷款同傳翻譯設備,可以看到如下介紹:支持59種語言,可以實現0.5秒快速翻譯,中英文離線翻譯也能達到大學英語六級水平(如圖7)。
美國發明家、未來學家雷·科茲威爾最近在接受《赫芬頓郵報》采訪時預言,到2029年機器翻譯的質量將達到人工翻譯的水平。對于這一論斷,學術界還存在很多爭議。當機器翻譯得到廣泛應用的時候,就有聲音說機器翻譯將會取代人工翻譯,“翻譯員”可能會集體下崗,真的會這樣嗎?夢想與現實的距離到底有多遠?客觀地說,盡管神經網絡帶來了翻譯質量的巨大提升,但仍面臨許多挑戰。為此,關于機器翻譯關鍵技術原理以及它的發展與挑戰,我們將在下一期進行探討,敬請期待!
猜你喜歡
小獼猴智力畫刊(2022年3期)2022-03-29 01:09:42
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:26:14
文苑(2020年4期)2020-05-30 12:35:30
制造技術與機床(2019年10期)2019-10-26 02:48:08
電子制作(2018年18期)2018-11-14 01:48:06
小學生作文(中高年級適用)(2018年3期)2018-04-18 01:24:47
Coco薇(2017年11期)2018-01-03 20:59:57
暨南學報(哲學社會科學版)(2016年9期)2017-01-15 13:52:02
華北電力大學學報(社會科學版)(2016年4期)2016-12-01 03:59:30
小學教學參考(2015年20期)2016-01-15 08:44:38
