基于改進深度學習算法的文本極性智能判斷方法研究
2020-03-03 13:20:44宋思晗王興芬杜惠英
現代電子技術 2020年1期
宋思晗 王興芬 杜惠英


摘 ?要: 為了解決傳統的文本極性智能判斷方法判斷結果準確率和召回率普遍較低的問題,基于改進深度學習算法研究一種新的文本極性智能判斷方法。在CNN結構基礎上設計一種新的深度學習算法模型,模型由輸入層、輸出層、采集層、連接層、卷積層五部分構成。使用該模型對文本進行智能判斷,判斷過程共有五步,分別是文本預處理、情感詞提取、表情符號提取、感情傾向值計算和情感最終傾向值分析。為檢測所提方法的有效性以及優越性,與傳統判斷方法進行實驗對比,結果表明,基于改進深度學習算法的文本極性智能判斷方法判斷的準確率和召回率更高,發展空間更廣闊。
關鍵詞: 文本極性; 智能判斷方法; 算法模型設計; 有效性檢測; 深度學習算法; 文本預處理
中圖分類號: TN911.1?34; TP393 ? ? ? ? ? ? ? ? ? 文獻標識碼: A ? ? ? ? ? ? ? ? ? 文章編號: 1004?373X(2020)01?0076?04
Research on text polarity intelligent judgment method
based on improved deep learning algorithm
SONG Sihan, WANG Xingfen, DU Huiying
Abstract: The accuracy and recall rate of traditional text polarity intelligent judgment methods both are generally low. In view of the above, a new method of text polarity intelligent judgment is studied based on improved deep learning algorithm. A new deep learning algorithm model is designed based on the CNN structure. The model consists of five parts: input layer, output layer, acquisition layer, connection layer and convolution layer. This model is used for text intelligent judgment. The judgment process is devided into five steps: text preprocessing, emotion word extraction, expression symbol extraction, emotion tendency value calculation and emotion final tendency value analysis. In order to test the effectiveness and superiority of the proposed method, an experimental comparison with the traditional judgment method was performed. The results show that the judgemental accuracy and recall rate of the text polarity intelligent judgment method based on the improved deep learning algorithm is higher, and the development space is broader.
Keywords: text polarity; intelligent judgment method; algorithm model design; effectiveness detection; deep learning algorithm; text pre?processing
0 ?引 ?言
隨著互聯網技術的進步,網絡成為人們工作生活必不可少的組成部分。據2018年市場調查顯示,我國互聯網的發展速度已經處于世界前列,互聯網在全國的普及率高達61.3%,網民規模達到了8.25億[1]。近年來,隨著移動互聯網的不斷普及,網絡服務范圍得以最大化推廣,大眾生活方式也得以改變[2]。
人機智能是一種新型技術,在智能識別和智能判斷中發揮著重要作用,將人機智能融入到文本極性智能判斷中,可以大大提高判別算法的工作效率。在機器學習研究中,深度學習算法有著很大的發展空間,這種起源于人工神經網絡的學習算法可以模擬人的大腦對事物進行分析、解釋文本、辨別聲音[3]。深度學習算法不需要監督,它可以在低層特征中不斷組合,再根據高層特征和屬性特征找到數據的分布特征,從而完成文本分層、預測、判斷等工作[4]。
本文基于改進深度學習算法研究了一種文本極性智能判斷方法,在卷積神經網絡(CNN)的基礎上進行優化,重新訓練學習數據,采用隱式特征抽取的方式從訓練數據中學習。該判別方法可以達到細粒度標記水準,將被判別文本清晰明確地分成非常消極、消極、中性、積極、非常積極五個層次[5]。
本文設計的改進深度學習算法采用了局部權值共享的特殊結構,能夠更好地處理語音文本和圖像文本,在布局上與生物神經網絡十分相似。多維向量輸入使判斷過程不需要重建數據,降低工作復雜度[6]。為了更好地檢測所設計的文本極性智能判斷方法的有效性,本文以微博熱門話題作為樣本數據進行實驗,通過準確率、召回率的比較實驗,對比改進模型與普通的CNN、RNN模型。
1 ?改進深度學習算法模型建立
結合已有的CNN、LSTM、多層CNN、Bi?LSTM?CRF等結構,建立了一種新型深度學習算法網絡結構。該神經網絡結構共包括輸入層、輸出層、采集層、連接層、卷積層五部分,改進神經網絡結構圖如圖1所示。
改進神經網絡中,每層之間的變換都涉及一次特征提取,提取后的層由多個二維平面組成,這些二維平面統稱為特征映射圖。在輸入層中輸入原始文本,多次提取原始文本數據。本文采用的計算方式為二次計算,即使輸入的原始數據有很大的形變,二次計算也能夠較好地計算出結果[7]。
改進神經網絡結構中卷積層和子采樣層都是獨立工作的,卷積層工作過程如圖2所示。
觀察圖2可知,卷積層會利用訓練濾波器對輸入的數據和文本進行卷積、偏置處理,從而得到卷積層[8]。卷積層將最初的輸入文本編程為不同的網格,每個網格都記錄著不同的特征數據,便于進行后續工作。
子采樣過程如圖3所示。
將鄰域的4個像素匯集到一起求和,集合成一個像素后,進行加權處理和偏置處理,通過激活函數縮小特征映射圖,縮小后的特征映射圖可以被直接提取,耗費成本低[9]。
卷積運算和采樣運算都能夠強化文本特征,降低噪音。
連接層是以隱含狀態存在的,能夠連接上一層和下一層,在連接層中設置了權重向量和偏置向量,輸入數據經過加權處理和偏置處理后得到一個新的數值,該數值最終會被傳給sigmoid函數。
輸出層具有分類功能,通過回歸曲線計算輸入文本屬于各種類別的概率。
將本文建立的改進深度學習算法模型應用到文本極性智能判斷中,選取文本中的小部分區域在神經網絡最低層次中輸入,依次濾波處理和加權處理,直至確定文本信息最顯著的特征。為確保識別的一致性,每個映射上使用的權值都是相等的,隨著逐層輸出,網絡參數會變得越來越少,最后會出現唯一的不變性特征[10]。文本也可以直接以網格方式輸出,不需要重建數據,工作方式較為簡單。
2 ?基于改進深度學習算法的文本極性智能判斷方法
利用前文建立的深度學習算法改進模型對文本進行極性智能判斷,分析文本中的情感詞和語義規則,判斷流程圖如圖4所示。
分析圖4可知,本文研究的文本極性智能判斷方法共分為五步:
1) 對提取出來的文本數據進行預處理,通過Java工具提煉所有的分詞。
2) 構建情感詞典,將情感詞典與文本中的數據進行匹配,如果情感詞典中不包含文本數據中的關鍵詞,則要重新設定閾值,計算情感極性。
3) 通過表情詞典提煉文本中的表情符號,如果文本中不包含表情符號,則直接進入下一步。
4) 同時使用否定詞典、修飾詞典和連接詞典計算出文本的感情傾向值。
5) 利用加權算法對上述步驟進行求值,得到最終的情感傾向值[S],如果[S>0],則判斷該文本方向為正向;如果[S<0],則判斷該文本方向為負向。
2.1 ?文本數據提取與預處理
2.1.1 ?文本數據提取
文本數據提取采用網絡爬蟲提取方式,所有的目標網站和關鍵字需要自定義[11]。文本數據信息量大,一些文本數據還需要登錄,普通爬蟲難以直接提取數據,本文利用Python設計了一種新的爬蟲,能夠模擬登錄用戶ID,本文設計的爬蟲為scrapy爬蟲,獲取文本信息的流程圖如圖5所示。
本文加入了1 000個關鍵詞組成關鍵詞數據庫,使爬蟲能夠更快地獲取信息。
2.1.2 ?文本預處理
通常爬蟲得到的文本都會含有噪聲信息,如果直接對其進行判斷,準確度會大大降低,因此需要對文本數據進行預處理[12]。預處理主要從三個方面進行:繁體字處理;無效鏈接處理;交互信息處理。
雖然絕大多數的文本信息都是簡體字,但是也有部分文本信息為繁體字,影響后續的分詞判斷、情感詞判斷、權重處理等操作,所以有必要將文本中的繁體字轉化成簡體字。很多文本中可能會存在無效鏈接,對于智能判別毫無幫助,在整體處理之前,要將沒有用的鏈接剔除。通常只有少量文本含有交互信息,這些交互信息對于實際判別沒有任何幫助,需要去除。
2.2 ?文本中情感詞提取
在文本中,情感詞是十分重要的組成部分,提取情感詞對于文本判斷有著重要意義。每一段文本中的信息都要與情感詞典進行匹配,如果能夠在情感詞典中匹配到相應的信息,則只需要記錄下極性和強度值即可;如果不能匹配到對應的詞語,則需要利用語義相似度計算方法計算出每個詞匯的情感傾向,設定固定閾值[13]。
情感詞典中的詞被劃分到五個類別中,分別為非常消極、消極、中性、積極、非常積極,結構如圖6所示。
圖6中的情感詞典是經過多次提煉和反復匹配的,包括了大量能夠表達情感的詞語,但是也有部分情感詞難以在情感詞典中匹配到,所以需要利用語義相似度方法計算文本中詞匯的情感傾向值。設定文本中的詞語為[x],被對比的詞語為[y],假設詞語[x]可以解釋成[m]個義項,則每個義項就可以用[x1],[x2],…,[xm]來表示,假設詞語[y]有[n]個義項,則每個義項就可以用[y1],[y2],…,[yn]來表示,詞語[x]和詞語[y]每個義項的最大相似度計算公式如下:
[Sim(x,y)=max[Sim(xi,yi)]] (1)
利用可變參數[λ]計算出義項原相似度:
[Sim(x1,y1)=λλ+d(xi,yi)] (2)
將每個義項原值進行相似度計算,通過計算平均值差,得到最終的情感值計算結果。
2.3 ?語義規則與表情符號判斷
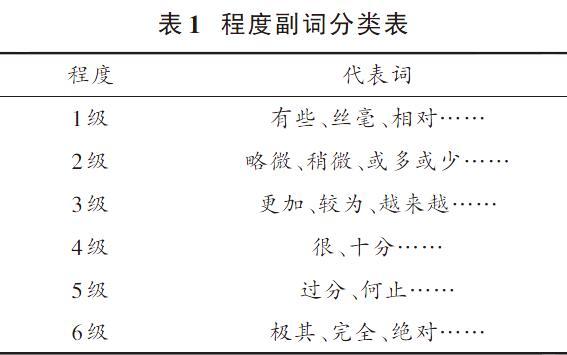
每一個文本句子都會有自己的語義規則,不同的語義規則將句子劃分為不同的種類,情感傾向通常通過修飾副詞表現出來,修飾強度不同,情感傾向也不同。如果句子中加入了否定詞語,那么情感的極性也會完全發生改變,例如未加否定詞語之前,該句子表達的為“絕對肯定”,加入了否定詞后,該句子想要表達的意思就變成了“絕對否定”。例如“我非常喜歡明星A”表達的是自己對A明星的絕對喜愛之情,在加入否定詞后,就會變成“我非常不喜歡明星A”,表達的是對某個明星的絕對厭惡之情,這是兩種完全不同的感情。
修飾程度副詞可以分為6級,代表性詞語如表1所示。
除了情感詞外,本文設定的判斷方法也會對表情符號進行判斷,因為判斷過程比較簡單,所以本文不做研究。
3 ?驗證實驗
3.1 ?實驗數據
為了檢測本文研究的基于改進深度學習算法的文本極性智能判斷方法的實際工作效果,與傳統判斷方法進行對比,從具有明確情感信息的30 000條微博數據中隨機選取正向情感的微博和負向情感的微博各10 000條進行實驗。微博中文本信息示例如表2所示。
3.2 ?實驗評判標準
本文將準確率和召回率作為評價指標,將判斷正確的正向情感微博文本記為TP,判斷錯誤的正向情感微博文本記為TN,判斷正確的負向情感微博文本記為FP,判斷錯誤的負向情感微博文本記為FN。
正向類別的微博文本準確率計算公式為:
[Ppos=TPTP+FP] (3)
正向類別的微博文本召回率計算公式為:
[Rpos=TPTP+FN] (4)
負向類別的微博文本準確率計算公式為:
[Pneg=TNTN+FN] (5)
負向類別的微博文本召回率計算公式為:
[Rneg=TNTN+FP] (6)
3.3 ?實驗結果與分析
根據上述參數和評價標準進行實驗,設定[α]為判斷后的準確率。不同[α]值下的文本分類準確率如圖7所示。
觀察圖7可知,當[α]值達到0.3時,準確率最高。選用傳統判斷方法和本文判斷方法對同一文本進行判斷,對比兩種方法的準確率和召回率,實驗結果對比如表3所示。
綜上所述,本文研究的判斷方法相較于傳統方法在準確率和召回率方面均有很大程度的提高,對于關鍵詞的提取也十分準確,即使在文本表達復雜的情況下,也能夠快速準確地做出智能性判斷。
4 ?結 ?語
本文基于改進深度學習算法提出一種新的文本極性智能判斷方法,該方法將傳統的情感詞典匹配法和語義相似度計算法結合到一起,同時構建了新的情感詞典。本文設計的判斷方法不需要多次對數據進行標記,具有實時判斷能力。
雖然具備上述優點,但本文提出的判斷方法仍然有一部分需要深入研究,如網絡新詞的判斷,以及如何更好地搜尋到文本中表達關鍵信息的詞匯,希望在后續的研究中能夠得以解決。
參考文獻
[1] 馬勝藍.基于深度學習的文本檢測算法在銀行運維中應用[J].計算機系統應用,2017,26(2):184?188.
[2] 朱國進,沈盼宇.基于深度學習的算法知識實體識別與發現[J].智能計算機與應用,2017,7(1):17?21.
[3] 劉江玉,李天劍.基于深度學習的倉儲托盤檢測算法研究[J].北京信息科技大學學報(自然科學版),2017,32(2):78?84.
[4] 左艷麗,馬志強,左憲禹.基于改進卷積神經網絡的人體檢測研究[J].現代電子技術,2017,40(4):12?15.
[5] 呂淑寶,王明月,翟祥,等.一種深度學習的信息文本分類算法[J].哈爾濱理工大學學報,2017,22(2):105?111.
[6] 喻一梵,喬曉艷.基于深度學習算法的正負性情緒識別研究[J].測試技術學報,2017,31(5):398?403.
[7] 廖健,王素格,李德玉,等.基于增強字向量的微博觀點句情感極性分類方法[J].鄭州大學學報(理學版),2017,49(1):39?44.
[8] 徐嵩,李玉峰.最大效益準則下基于分配公平性的CSGC改進算法[J].電子設計工程,2017,25(5):97?102.
[9] 陳江昀.一種基于深度學習的新型小目標檢測方法[J].計算機應用與軟件,2017,34(10):227?231.
[10] 李翌昕,馬盡文.文本檢測算法的發展與挑戰[J]. 信號處理,2017,33(4):558?571.
[11] 鄒煜,劉興旺.基于深度學習手寫字符的特征抽取方法研究[J].軟件,2017,38(1):23?28.
[12] 蔣兆軍,成孝剛,彭雅琴,等.基于深度學習的無人機識別算法研究[J].電子技術應用,2017,43(7):84?87.
[13] 馮通.基于深度學習的航空飛行器故障自助檢測研究[J].計算機仿真,2015,32(11):119?122.
作者簡介:宋思晗(1992—),男,山東曲阜人,碩士,主要研究方向為自然語言處理。
王興芬(1968—),女,山東平度人,博士,教授,主要研究方向為Web安全、電子商務、大數據分析與管理創新。
杜惠英(1982—),女,福建泉州人,博士,副教授,主要研究方向為移動互聯網、電子商務、大數據消費者行為。
猜你喜歡
中學生數理化·七年級數學人教版(2020年11期)2020-12-14 06:59:52
制造技術與機床(2019年10期)2019-10-26 02:48:08
藝術品鑒證.中國藝術金融(2018年8期)2019-01-14 01:14:28
藝術品鑒證.中國藝術金融(2018年10期)2019-01-08 02:44:26
文苑(2018年23期)2018-12-14 01:06:06
電子制作(2018年18期)2018-11-14 01:48:06
文苑(2018年19期)2018-11-09 01:30:14
文苑(2018年17期)2018-11-09 01:29:26
文苑(2018年21期)2018-11-09 01:22:32
藝術品鑒證.中國藝術金融(2018年12期)2018-08-26 06:03:48
