基于節點偽近鄰的電路板近鄰網絡排序算法
2020-03-04 02:48:41曾佩佩穆東旭賈春宇
現代電子技術 2020年2期
曾佩佩 穆東旭 賈春宇


摘 ?要: 在運用近鄰網絡排序集生成邊界掃描測試向量方法中,多以網絡局部或全局信息進行節點近鄰關系排序,導致偽近鄰點的識別排序能力較差。該文結合LeaderRank算法引入節點偽近鄰作為局部重要性指標,首先利用LeaderRank求得網絡節點的全局重要度,然后基于相關鄰居關系提出節點偽近鄰比計算方法,最后綜合LeaderRank的全局重要度值與節點偽近鄰性求得總體重要度,從而獲得近鄰網絡重要度排序。采用所提方法和以往近鄰排序算法對實際電路板網絡模型進行近鄰關系排序,對排序結果進行比較,并用SIR傳染病模型進行仿真分析。實驗結果表明,所提方法能夠彌補以往排序算法的不足,從而獲得更為精確的排序結果。
關鍵詞: 近鄰網絡排序; 節點偽近鄰; LeaderRank; 重要度排序; SIR模型; 仿真分析
中圖分類號: TN710?34; TP301.6 ? ? ? ? ? ? ? ?文獻標識碼: A ? ? ? ? ? ? ? ? ? ? ? 文章編號: 1004?373X(2020)02?0005?04
Circuit board neighboring network sorting algorithm based on node pseudo?adjacency
ZENG Peipei1, MU Dongxu2, JIA Chunyu2
Abstract: In the method of generating the boundary scan testing vector with the neighboring network sorting sets, the node adjacent relationship is sorted mostly according to the local or global network information, which results in poor recognition and sorting abilities of the pseudo?adjacent nodes. The pseudo?adjacency node is introduced as the local importance index by means of the LeaderRank algorithm. The global importance of the network node is obtained with the LeaderRank, and then the calculation method of the node pseudo?adjacency ratio is proposed based on the related neighboring relationship. The overall importance of the network node is acquired by synthesizing the global importance value of LeaderRank and the pseudo?adjacency property of nodes, so as to obtain the importance sorting of the neighboring networks. The neighboring relationship of the real circuit board network models is sorted by means of the method proposed in this paper and the previous neighboring sorting algorithm. The sorting results are compared, and the SIR infectious disease model is used for the simulation analysis. The experimental results show this method can make up for the shortcomings of the previous sorting algorithms, so as to obtain the more accurate sorting results.
Keywords: neighboring network sorting; node pseudo?adjacency; LeaderRank; importance sorting; SIR model; simulation analysis
0 ?引 ?言
隨著電路板的不斷集成化,電路網絡結構的復雜化,掃描測試難度也不斷加大。在應用邊界掃描技術對電路板進行相關測試時,難點在于如何生成緊湊性更好,完備性更高的測試向量。目前,主流的測試向量生成算法設計思想來源于1989年C.W.YAU和Jarwala提出的近鄰網絡排序集最大獨立性算法。但由于無法有效獲得準確的近鄰排序網絡集,所以只能在理論上探討。隨后有關學者相繼提出了多種近鄰網絡排序算法,如Jarwala后來提出的基于近鄰獨立性的測試生成優化方法,該方法前提是已獲得近鄰網絡排序集,然后根據近鄰獨立性對測試向量生成進行相關優化,并獲得了較好效果。近年來,學者在網絡重要節點近鄰排序上提出了很多指標和算法,如基于電路板結構信息的近似近鄰網絡排序算法,該算法運用有限制短路故障模型[1?2],根據網絡間短路可能性大小,利用最短路徑法得到該電路板網絡結構的一個近似近鄰排序網絡集。但該方法不僅概率閾值難以確定,而且只從局部重要度指標考慮,排序結果并不理想。LeaderRank算法是對PageRank算法進一步優化,通過在原網絡中加入背景節點,相當于PageRank中的跳轉概率S,從而使得算法的收斂速度和魯棒性有了明顯提升,相比其他同類型近鄰節點重要性排序方法,該方法更有優勢[3?4]。
雖然上述方法能夠較好地解決近鄰網絡排序問題,但多數只片面從節點的全局重要度或局部重要度上進行考慮,忽略了電路網絡節點間相互作用對整個網絡的影響,從而導致在復雜網絡偽近鄰節點排序不明確,不能獲得更精確的網絡排序集。為解決上述問題,本文在LeaderRank的基礎上引入節點偽近鄰性作為局部重要性指標,提出了基于節點偽近鄰性的PseudoRank電路板近鄰網絡排序方法。首先結合相關鄰居關系從局部表征節點偽近鄰;然后將其擴展到全局,提出一種綜合方法來獲得節點的偽近鄰比;最后結合LeaderRank算法求得節點的總體重要度值。該方法綜合利用節點全局和局部重要性指標對節點進行近鄰重要度評價,最終和其他幾種經典算法進行比較,從實驗結果可以看出,本文方法能夠克服以往的不足,從而獲得更為準確的近鄰網絡排序,實現測試向量的進一步優化。
1 ?PseudoRank近鄰網絡排序算法
1.1 LeaderRank算法
LeaderRank算法是在原網絡基礎上增加一個節點[vg]與其余所有[n]個節點相連,組成一個節點數為[n+1]的強連接網絡。
定義1 ?[LRi]定義為節點[vi]的全局重要度。[LRi(k)]為經過[t]次迭代系統達到穩態后節點[vi]的重要度初值。隨后,背景節點[g]將其重要度值平均分配給網絡其他[n]個節點,從而得到節點[vi]的全局重要度。因此節點[vi]的最終的全局重要度[LRi]值為:
[LRi(0)=1nLRi(t)=j=0naijdjLRj(t-1) , t=1,2,…LRi=LRi(t)+LRg(t)·n-1] ? ? ?(1)
式中:[n]為網絡節點總數;若節點[vi],[vj]直接相連,則[aij=1],否則為0;[dj]為節點[vj]的度值;[LRg(t)]為系統穩定狀態下背景節點[vg]的重要度。
1.2 ?節點偽近鄰性
在實際電路網絡中,隨著電路板的不斷集成化,器件管腳、焊點、網絡間距愈發密集,近鄰網絡間通常具有一定偽近鄰關系。如圖1所示,假定相連節點物理間距近似相等,由有限制短路故障模型理論[5]可知,相鄰網絡間短路的可能性相同。又由于節點1,2的一階近鄰度相同,均為4,故依據以往排序方法無法對兩節點有效排序。然而,節點1,2二階近鄰度不同,節點C與F相連,致使C的重要性增加,從而使得節點1,2的重要度略有差異,即節點間存在偽近鄰關系。
目前計算節點偽近鄰相似性算法大致分為兩種:一是局部節點近鄰相似性算法,如文獻[6?7]基于相關鄰居關系的節點偽近鄰度;二是全局節點近鄰相似性算法,如文獻[8?10]將網絡結構局部特征信息擴展到全局來求解節點的偽近鄰度。
本文綜合全局和局部重要度,利用相關鄰居關系從局部拓撲上來衡量節點偽近鄰度,然后將其擴展到全局來求解節點偽近鄰度。相關鄰居關系計算方法如下:
[P(vi,vj)=N(vi)?N(vj)+E[N(vi)?N(vj)]] ? ? (2)
式中:[N(vi)?N(vj)]為節點[i],[j]間的共同鄰居節點數;[E(G[N(vi)?N(vj)])]為節點[i],[j]共同鄰居間的邊數。
結合相關鄰居關系計算方法,本文定義局部節點偽近鄰比為:
[Lpse(vi,vj)=N(vi)?N(vj)+E [N(vi)?N(vj)]1+N(vi)?N(vj)+E [N(vi)?N(vj)]]
(3)
式中: [N(vi)?N(vj)]為節點[i],[j]的一階共同鄰居節點數;[E[N(vi)?N(vj)]]為節點[i],[j]所有共同一階鄰居節點間的邊數;[N(v1)?N(v2)]表示節點[i],[j]非共同一階鄰居節點數;[E[N(v1)?N(v2)]]表示節點[i],[j]非共同一階鄰居節點間的邊數。如圖1所示,[N(v1)?N(v2)=2],[E[N(v1)?N(v2)]=1],[N(v1)?N(v2)=4],[E[N(v1)?N(v2)]=3],所以節點1和節點1之間的局部相似性為[(1+2+1)(1+4+3)]=0.5。
對式(3) 進行推廣,定義全局節點偽近鄰比:[Gpse(vi,vj)=0, ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ?i,j不可達k=1nLpse(vqk,vq(k+1)), ? i,j非鄰居但可達] ?(4)
式中:[vq1=vi];[vq(n+1)=vj];[qk(k=1,2,…n)]為節點[i]到[j]的最短路徑上所有節點集合。
從而得到本文中節點間偽近鄰比:
[pse(vi,vj)=Lpse(vi,vj), ? ? ?i,j相鄰Gpse(vi,vj), ? ? 其他] (5)
定義2 ?PseudoRank矩陣[PseR],節點[i]的[PR]重要度值如下:
[PRi=LRij∈αipse(vi,vj)+1ki+1LRj] (6)
式中,[αi]為節點[vj]的鄰居節點集合。從式(6)可以看出,節點重要度與其鄰居節點個數、鄰居節點重要度值以及節點對間的相互影響力有關。
2 ?算法仿真與分析
2.1 節點重要性排序
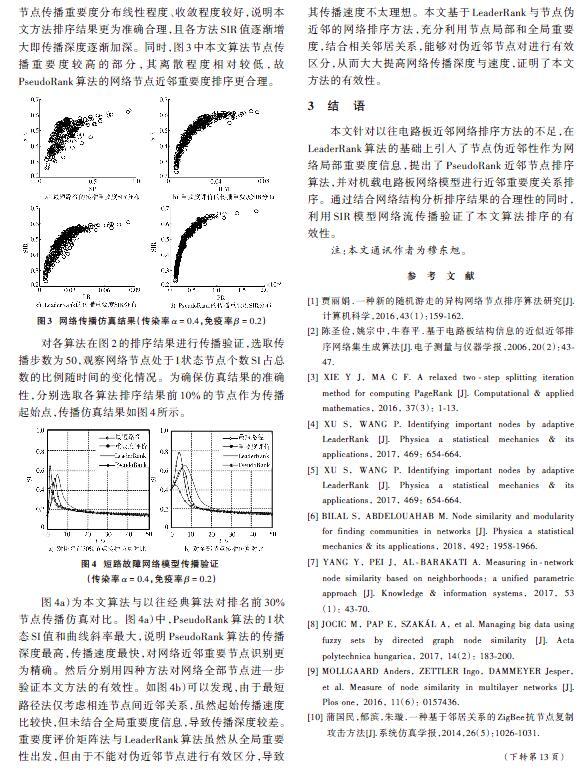
對所提算法進行仿真與分析驗證前,首先根據Protel DXP提供的電路板結構信息、網表信息建立短路故障網絡模型。本文以某機載雷達信號處理板為樣例建立短路故障模型[2],如圖2所示。
[6] BILAL S, ABDELOUAHAB M. Node similarity and modularity for finding communities in networks [J]. Physica a statistical mechanics & its applications, 2018, 492: 1958?1966.
[7] YANG Y, PEI J, AL?BARAKATI A. Measuring in?network node similarity based on neighborhoods: a unified parametric approach [J]. Knowledge & information systems, 2017, 53(1): 43?70.
[8] JOCIC M, PAP E, SZAK?L A, et al. Managing big data using fuzzy sets by directed graph node similarity [J]. Acta polytechnica hungarica, 2017, 14(2): 183?200.
[9] MOLLGAARD Anders, ZETTLER Ingo, DAMMEYER Jesper, et al. Measure of node similarity in multilayer networks [J]. Plos one, 2016, 11(6): 0157436.
[10] 蒲國民,郁濱,朱璇.一種基于鄰居關系的ZigBee抗節點復制攻擊方法[J].系統仿真學報,2014,26(5):1026?1031.
[11] 單治超.有限隨機圖上的隨機游動和傳染病模型[J].數學進展,2017,46(1):1?12.
[12] T?NSING C, TIMMER J, KREUTZ C. Profile likelihood?based analyses of infectious disease models [J]. Statistical methods in medical research, 2018, 27(1): 44?46.
[13] RUI X, MENG F, WANG Z, et al. SPIR: the potential spreaders involved sir model for information diffusion in social networks [J]. Physica a statistical mechanics & its applications, 2018, 506: 101?110.
[14] KUNIYA T, WANG J. Global dynamics of an SIR epidemic model with nonlocal diffusion [J]. Nonlinear analysis real world applications, 2018, 43: 262?282.
[15] YUAN X, WANG F, XUE Y, et al. Global stability of an SIR model with differential infectivity on complex networks [J]. Physica a statistical mechanics & its applications, 2018, 499: 162?168.
作者簡介:曾佩佩(1988—),男,助理工程師,主要研究方向為圖像處理、飛行控制系統、機載電子系統故障診斷。
穆東旭(1992—),男,碩士研究生,主要研究方向為機載電子系統可測試性技術、故障診斷。
賈春宇(1993—),男,碩士研究生,主要研究方向為機載電子系統可測試性技術、故障診斷。
