一種基于復合特征的惡意PDF檢測方法
2020-03-04 02:48:41李國黃永健王靜徐俊潔王鵬
現代電子技術 2020年2期
李國 黃永健 王靜 徐俊潔 王鵬
摘 ?要: 為了提高特征有效性和擴大檢測范圍,提出在提取PDF文件的惡意結構特征的基礎上再提取JavaScript的惡意特征;為了減少檢測時間,提出在特征提取前,增加基于信息熵差異的預檢測過程。先利用惡意PDF和良性PDF的信息熵差異篩選出可疑PDF文件和良性PDF文件;然后在檢測過程中,提取可疑PDF文件的結構和JavaScript特征;再利用C5.0決策樹算法進行分類;最后,通過實驗檢測,驗證了提出的方法對惡意PDF文件檢測有效。實驗結果表明,與PJScan,PDFMS等模型做對比,該方法檢測率比PJScan高27.79%,時間消耗低390 s,誤檢率比PDFMS低0.7%,時間消耗低473 s,綜合性能更優。
關鍵詞: 惡意PDF文檔; 文檔檢測; 文件篩選; 文件特征提取; 信息熵預檢; 實驗驗證
中圖分類號: TN911.23?34; TP393 ? ? ? ? ? ? ? ?文獻標識碼: A ? ? ? ? ? ? ? ? ? ? 文章編號: 1004?373X(2020)02?0045?04
Method of malicious PDF detection based on composite features
LI Guo1, HUANG Yongjian1, WANG Jing1, XU Junjie1, WANG Peng2
Abstract: A method that the JavaScript malicious features are extracted on the basis of extracting the malicious structural features of PDF files is proposed, so as to improve the feature validity and expand the scope of detection. A scheme that the pre?detecting process based on the information entropy difference is added before the feature extraction is proposed to shorten the detection time. The information entropy difference between malicious PDF and benign PDF is utilized to screen out the suspicious PDF files and benign PDF files in pre?detection process. The structures and JavaScript features of the suspicious PDF files are extracted during the detection process, and the C5.0 decision tree algorithm is adopted to classify them. The experimental results verify that the proposed method is effective for detecting malicious PDF files; in comparison with the PJScan, PDFMS and other detection models, the proposed method′s detection rate is 27.79% higher and the time consumption is 390 s lower than the PJScan, and the proposed method′s error detection rate is 0.7% lower and the time consumption is 473 s lower than PDFMS; its comprehensive performance is more superior.
Keywords: malicious PDF file; file detection; file screening; file feature extraction; information entropy predetection; experimental verification
0 ?引 ?言
近年來,對商業組織和政府機構的高級持續性威脅 (APT)攻擊時有發生,而惡意PDF文件是APT攻擊的重要載體[1]。目前大部分殺毒軟件采用基于啟發式或字符串匹配的方法進行查殺,但這些方法無法有效處理多態攻擊的問題[2]。在解決該問題時,最近的研究主要集中在以下三個方面:
1) 先提取PDF文件中的JavaScript特征,再經過機器學習進行分類。這類方法可應對基于惡意JavaScript的攻擊,但易受到代碼混淆的影響。如2011年,Laskov開發的經典工具PJScan存在檢測率低,無法分析混淆代碼的問題[3]。2014年,Doina Cosovan等人提出的基于隱馬爾可夫模型和線性分類器檢測惡意PDF文件的方法,存在誤報率高的問題[4]。2017年,徐建平提出的改進N?gram的檢測模型只針對三種代碼混淆技術進行反混淆[5]。
2) 利用 PDF文件的結構信息來檢測惡意 PDF文件,其特點是不分析其攜帶的攻擊代碼,能夠檢測到非JavaScript攻擊,并且不會受代碼混淆的影響,但是如何增強模型的健壯性是其所面臨的大挑戰。如2012年,Maiorka等人設計的經典工具PDFMS存在一些結構性弱點[6]。2015年,Davide Maiorca等人從PDF文件的結構和內容中提取信息的方法存在對樣本數據的質量要求較高的問題[7]。
由于大多數的惡意PDF文件的大小比良性PDF文件小,而且惡意PDF文件的間接對象數量比良性PDF文件少,因此,除了上述所提的標識JavaScript,Actions,Triggers和Form Action關鍵字的7種動態結構特征以外,所提取的結構特征集還包括兩種結構的一般特征:文件的大小和間接對象的數量。
2.2.2 ?JavaScript代碼分析
在這個階段,分析PDF文件結構部分的JavaScript代碼和文件中嵌入的JavaScript代碼,并提取JavaScript代碼中經常出現的惡意特征。基于以前的研究,本文方法所提取的JavaScript特征共有9種,分別是:
1) 用于混淆代碼的字段(5種):substring,document.Write,document.create Element,fromCharCode和stringcount。其中,惡意攻擊者可以利用fromChar 將Unicode值轉換為字符,利用stringcount分解字符串。
2) 用于動態解釋惡意Javascript的字段(4種):Eval,setTime Out,eval_length和max_string。其中,惡意攻擊者可以使setTime Out代替eval,在超時后運行隨機的JavaScript代碼。
2.3 ?分 ?類
為了對PDF文件進行分類,可以使用任何學習算法創建的分類器。本文選取C5.0決策樹作為分類算法,PDF文件樣本集合S={S1,S2,…,Sn}(n為樣本總數),共分為兩類C={C1,C2}(C1代表良性PDF文件;C2代表惡意PDF文件)。每個PDF文件將由一個向量表示,該向量由結構的一般特征、結構的動態特征和JavaScript特征組成,即:
Si={T1,T2,T3,T4,T5,T6,T7,T8,T9,T10,T11,T12,T13,T14,
T15,T16,T17,T18 }, ?i=1,2,…,n
其中:
1) 結構的一般特征:T1表示文件Si的大小,以字節為單位;T2表示文件Si的間接對象的數量。
2) 結構的動態特征:T3~T9分別表示文件Si中以“/JS”為標識的JavaScript關鍵字的數量、以“/JavaScript”為標識的JavaScript關鍵字的數量、以“/Go To”為標識的Action關鍵字的數量、以“/Go To R”為標識的Action關鍵字的數量、以“ /Go To Z”為標識的Action關鍵字的數量、以“/open action”為標識Triggers關鍵字的數量、以“/Submit Form”為標識的Form Action關鍵字的數量。
3) JavaScript特征:T10~T16分別表示文件Si中substring,fromChar Code,stringcount,document.Write,document. create Element,Eval,setTime Out出現的次數;T17表示文件Si中傳給eval的最長字符串長度eval_length;T18表示文件Si中最長字符串的長度max_string。
定義p(Ci,S)表示樣本屬于類別Ci(i=1,2)的概率,則樣本集合S的信息熵Info(S)計算公式為:
[Info(S)=-i=12(p(Ci,S) )·log2(p(Ci,S))] (3)
[p (Ci,S)]的計算公式如下:
[p(Ci,S)=fre(Ci,S)n] (4)
式中:n為樣本總數;[fre(Ci,S)]是樣本集合中,類別是Ci的樣本個數。
樣本的特征屬性為T,每個屬性變量有N類,屬性T的條件熵Info(T)的計算公式為:
[Info(T)=-i=1N((Ti|T|)·Info(Ti))] (5)
引入特征屬性變量T后的信息增益Gain(T)的計算公式為:
[Gain(T)=Info(S)-Info(T)] (6)
C5.0算法利用信息增益率Gainration(A)來生成節點,其中A為假設情況,Gainration(A)的計算公式為:
[Gainration(A)=Gain(A)Info(A)] (7)
式中,Gain(A)表示A情況下所生成的節點產生的信息增益,子節點越多,Info(A)越大。
3 ?實驗結果與分析
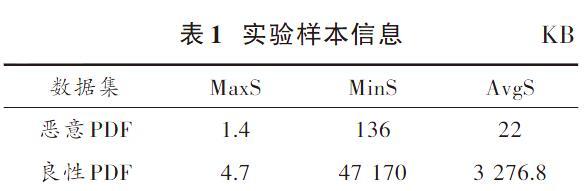
實驗所采用的數據集是由從Contagiodump[11]中收集的11 207個惡意文件和從工作實驗室中收集的9 745個良性文件組成,樣本信息包括樣本最大值MaxS,樣本最小值MinS,樣本平均值AvgS,如表1所示。
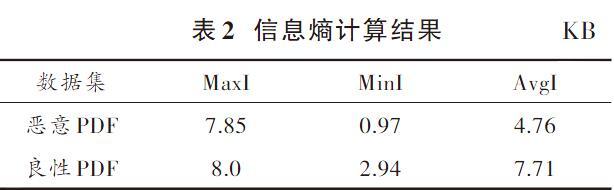
通過實驗,樣本的信息熵計算結果如表2所示,包括樣信息熵最大值MaxI,信息熵最小值MinI,信息熵平均值AvgS。
根據表1和表2可以看出,惡意PDF文件的大小和信息熵明顯比良性PDF文件小。
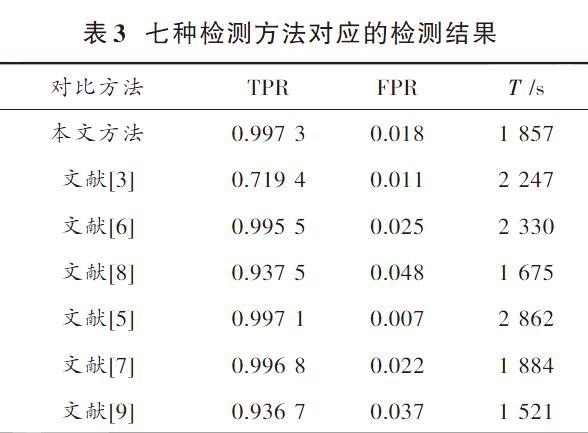
正式檢測通過10折交叉驗證重復10次,當α值取7.74時,準確率達到99.73%,誤檢率達到1.8%,時間消耗降至1 857 s。與文獻[3,5]提出的基于JavaScript特征的檢測方法、文獻[6,7]提出的基于結構特征的檢測方法和文獻[8?9]提出的直接對整個PDF 文件進行分析的檢測方法相比,結果如表3所示。
對于每種方法,都顯示了檢測率(TPR)、誤檢率(FPR)和時間開銷T。從三類檢測方案的七種方法的檢測率、誤檢率和時間消耗的對比結果中可以看出:本文提出的方法檢測率高于其他文獻提出的方法,與誤檢率最低且檢測率第二高的文獻[5]相比,其檢測時間為2 862 s,比本文提出的方法多1 005 s;與檢測時間最少的文獻[9]提出的方法相比,其檢測率為93.67%,誤檢率為3.7%,比本文提出的方法的檢測率低6.06%,誤檢率高1.9%;與文獻[3]提出的PJScan和文獻[6]提出的PDFMS相比,本文提出的方法檢測率比PJScan高27.79%,時間消耗低390 s,誤檢率比PDFMS低0.7%,時間消耗低473 s,因此,本文提出的方法綜合性能更好。
4 ?結 ?語
針對惡意PDF文件檢測率低和檢測時間長的問題,本文提出基于信息熵下結合結構特征和JavaScript特征進行惡意判別的方法。經過基于熵的預檢測過程,確定可疑PDF,然后提取可疑PDF文件的惡意結構特征和JavaScript特征,最后利用C5.0決策樹算法進行分類。通過實驗結果表明,本文提出的方法在檢測率和檢測時間性能上更優。但是在預檢測過程中,α值是通過實驗確定的,而非經驗值確定,因此在今后的研究中,應該實現閾值動態設置和范圍調整算法以減少檢測的時間。
參考文獻
[1] 文偉平,王永劍,孟正.PDF文件漏洞檢測[J].清華大學學報(自然科學版),2017,57(1):33?38.
[2] 林楊東,杜學繪,孫奕.惡意PDF文檔檢測技術研究進展[J].計算機應用研究,2018,35(8):1?7.
[3] LASKOV P. Static detection of malicious JavaScript?bearing PDF documents [C]// Twenty?Seventh Computer Security Applications Conference, ACSAC 2011.Orlando: DBLP, 2011: 373?382.
[4] COSOVAN D, BENCHEA R, GAVRILUT D. A practical guide for detecting the java script?based malware using hidden Markov models and linear classifiers [C]// International Symposium on Symbolic and Numeric Algorithms for Scientific Computing. Timisoara: IEEE, 2015: 236?243.
[5] 徐建平.基于改進的N?gram惡意PDF文檔靜態檢測技術研究[D].南昌:東華理工大學,2017.
[6] MAIORCA D, GIACINTO G, CORONA I. A pattern recognition system for malicious PDF files detection [C]// International Conference on Machine Learning and Data Mining in Pattern Recognition. [S.1.]: Springer, 2012: 510?524.
[7] MAIORCA D, ARIU D, CORONA I, et al. A structural and content?based approach for a precise and robust detection of malicious PDF files [C]// 2015 International Conference on Information Systems Security and Privacy. Angers: IEEE, 2015: 27?36.
[8] SHAFIQ M Z, KHAYAM S A, FAROOQ M. Embedded malware detection using Markov n?grams [C]// Proceedings of 5th International Conference on Detection of Intrusions and Malware, and Vulnerability Assessment. Paris: Springer, 2008: 88?107.
[9] 任卓君,陳光.熵可視化方法在惡意代碼分類中的應用[J].計算機工程,2017,43(9):167?171.
[10] 李玲曉.基于靜態分析技術的惡意PDF文檔檢測系統的設計與實現[D].北京:北京郵電大學,2016.
[11] Anon. Mila: Contagio malware dump [EB/OL]. [2017?12?21]. http://contagiodump.blogspot.in/2010/08/Malicious?documents?archive?for.html.
作者簡介:李 ?國(1961—),男,河南新鄉人,碩士,教授,碩士生導師,研究方向為民航智能信息處理與航空物聯網、網絡安全。
黃永健(1993—),女,河北秦皇島人,碩士研究生,主要研究方向為機載信息系統、網絡安全。
王 ?靜(1980—),女,山西太谷縣人,博士,講師,主要研究方向為民航信息系統、網絡安全。
