面部運(yùn)動(dòng)單元檢測研究綜述
2020-03-06 12:55:58嚴(yán)經(jīng)緯王春茂王保青
計(jì)算機(jī)應(yīng)用 2020年1期
嚴(yán)經(jīng)緯,李 強(qiáng),王春茂,謝 迪,王保青,戴 駿
(杭州海康威視數(shù)字技術(shù)股份有限公司 研究院,杭州 310051)
0 引言
為了更精細(xì)地研究人類面部表情,美國著名情緒心理學(xué)家Ekman等[1]于1978年首次提出了面部運(yùn)動(dòng)編碼系統(tǒng)(Facial Action Coding System, FACS),又于2002年作了重要改進(jìn)[2]。基于FACS,各類表情可分解為一系列基礎(chǔ)的面部肌肉運(yùn)動(dòng)的組合,從而進(jìn)行后續(xù)的編碼。Ekman等根據(jù)面部肌肉的解剖學(xué)情況,定義了32種面部肌肉運(yùn)動(dòng)單元(Action Unit, AU),圖1所示分別為上半臉和下半臉中的幾種常見AU及AU組合的示意圖(http://www.cs.cmu.edu/~face/facs.htm)。從圖1中可見,每個(gè)AU描述了面部某塊特定肌肉或肌肉組的運(yùn)動(dòng)情況,如AU1表示通過額肌控制的內(nèi)眉角上抬,AU5表示由眼輪匝肌控制的抬升眼瞼等。本文所述的面部運(yùn)動(dòng)單元檢測的目標(biāo)即是讓計(jì)算機(jī)在給定人臉圖像或視頻中自動(dòng)判斷目標(biāo)AU是否存在,由于每種AU都經(jīng)過嚴(yán)格的定義,該問題也可稱為面部運(yùn)動(dòng)單元識(shí)別。此外值得注意的是,F(xiàn)ACS中對(duì)每種AU定義了從A到E五個(gè)級(jí)別的強(qiáng)度(A最弱,E最強(qiáng)),本文僅關(guān)注定性的AU檢測問題,對(duì)定量的AU強(qiáng)度回歸技術(shù)不作涉及。
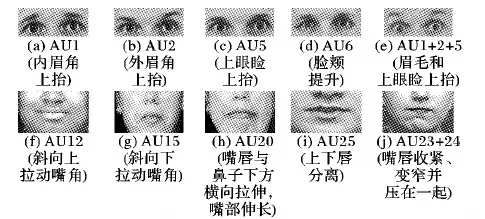
圖1 上下半臉中若干常見AU的定義及示意圖Fig. 1 Definiton and schematic diagram of some common AUs in upper and lower face
AU和面部表情的聯(lián)系十分緊密,既可將表情分解為不同AU的組合,同樣也可基于AU組合定義6種基本表情(憤怒、厭惡、恐懼、高興、悲傷和驚訝)或更為復(fù)雜的復(fù)合表情(驚喜、苦笑等)。與面部紋理等媒介相比,從AU的角度出發(fā)分析面部表情更為直觀且具有更強(qiáng)的可解釋性,因此在人機(jī)交互領(lǐng)域,特別是在表情相關(guān)的任務(wù)上有著廣泛的應(yīng)用需求[3-4],例如在安防感知場景中通過AU識(shí)別群體的情緒,對(duì)突發(fā)事件進(jìn)行警報(bào);在公安刑偵或?qū)徲嵾^程中基于AU識(shí)別對(duì)方無意識(shí)顯露的微表情,輔助相關(guān)人員判斷其是否撒謊;在網(wǎng)絡(luò)教育中通過攝像頭捕捉學(xué)員呈現(xiàn)的面部AU,了解其對(duì)所授知識(shí)是否存疑。近年來隨著大規(guī)模帶有專家標(biāo)注的面部運(yùn)動(dòng)單元數(shù)據(jù)庫的建立和深度學(xué)習(xí)技術(shù)在AU檢測領(lǐng)域的蓬勃發(fā)展,未來的應(yīng)用場景和需求將會(huì)越來越多。
1 AU數(shù)據(jù)庫
帶有準(zhǔn)確標(biāo)注的AU數(shù)據(jù)庫是開展AU檢測研究工作的基礎(chǔ),本章介紹6個(gè)常用的AU數(shù)據(jù)庫,分別為DISFA[5]、BP4D[6]、EmotioNet[7]、CFEE[8]、UNBC-McMaster肩痛表情[9]和CK+[10],各個(gè)AU數(shù)據(jù)庫的概況總結(jié)如表1,按照常用程度的順序依次介紹如下。
1)DISFA數(shù)據(jù)庫。
丹佛大學(xué)自發(fā)面部運(yùn)動(dòng)單元數(shù)據(jù)庫(Denver Intensity of Spontaneous Facial Action database, DISFA)[5]建立于2013年,采集了15位男性和12位女性,共27位被試的AU視頻樣本。被試坐著觀看由YouTube上的9個(gè)片段拼接而成242 s的視頻,每個(gè)片段激發(fā)一種情緒。在此過程中攝像機(jī)從正面采集被試的面部表情,被試所處環(huán)境如光照、背景等條件一致。視頻樣本分辨率為1 024×768,幀率為20 fps(frame/second),每位被試均采集4 845幀。2名FACS專家在數(shù)據(jù)庫中每幀圖像上標(biāo)注了12種AU的起始和終止,同時(shí)按照0~5共6個(gè)級(jí)別標(biāo)注了AU強(qiáng)度。
2)BP4D-Spontaneous數(shù)據(jù)庫。
BP4D-Spontaneous[6]簡稱BP4D,由賓漢姆頓大學(xué)和匹茲堡大學(xué)合作建立,采集了18位男性和23位女性,共41位被試的視頻樣本。不同于直接觀看視頻激發(fā)情緒,BP4D采集過程中通過指導(dǎo)被試作8個(gè)任務(wù)激發(fā)相應(yīng)的情緒,整個(gè)過程由專業(yè)演員主持,任務(wù)之間通過被試自評(píng)確定是否產(chǎn)生期望的情緒。數(shù)據(jù)集中包含每個(gè)任務(wù)對(duì)應(yīng)的2D和3D視頻,只保留表情顯著的片段,每段平均時(shí)長1 min。對(duì)于每個(gè)視頻中一段20 s表情最為豐富的片段,由2位FACS專家標(biāo)注27種AU的起始和結(jié)束,同時(shí)對(duì)于AU12和AU14,按照0~5的級(jí)別標(biāo)注強(qiáng)度。該數(shù)據(jù)庫與DISFA是目前學(xué)術(shù)界使用最為廣泛的兩個(gè)AU檢測基準(zhǔn)數(shù)據(jù)庫。
文獻(xiàn)[11]又通過類似的方式(8個(gè)任務(wù)增加到10個(gè)任務(wù),其余不變)采集了一批140人的數(shù)據(jù)庫,大幅度擴(kuò)展了樣本規(guī)模,該數(shù)據(jù)庫被稱為BP4D+。除了視頻數(shù)據(jù)外,BP4D+中還包括如血壓、呼吸、心率、皮膚電等的生理信號(hào),為多模態(tài)分析提供了便利。5位FACS專家標(biāo)注了第1,6,7,8號(hào)任務(wù)中34個(gè)AU是否出現(xiàn),且對(duì)其中5種AU標(biāo)注了強(qiáng)度。
3)EmotioNet數(shù)據(jù)庫。
俄亥俄州立大學(xué)Benitez-Quiroz等[7]于2016年建立的百萬規(guī)模人臉表情數(shù)據(jù)庫EmotioNet,圖像均來自于互聯(lián)網(wǎng),相對(duì)于實(shí)驗(yàn)室場景中采集的數(shù)據(jù),EmotioNet中的數(shù)據(jù)來自于自然場景,因此更加真實(shí)且接近實(shí)際應(yīng)用場景。數(shù)據(jù)庫分為訓(xùn)練集和測試集,其中測試集包含26 116張圖像,通過FACS專家標(biāo)注了12種AU是否出現(xiàn),訓(xùn)練集有約95萬張樣本,由算法自動(dòng)檢測AU并標(biāo)注,其檢測準(zhǔn)確率約為80%。由于訓(xùn)練集的AU標(biāo)簽中含有一定程度的噪聲,EmotioNet被較多應(yīng)用于弱監(jiān)督學(xué)習(xí)中。
4)CFEE數(shù)據(jù)庫。
該數(shù)據(jù)庫是文獻(xiàn)[8]在研究復(fù)合表情(Compound Facial Expressions of Emotion, CFEE)時(shí)建立,CFEE數(shù)據(jù)庫由230位被試的正面面部圖像構(gòu)成,包括平靜狀態(tài)(中性)在內(nèi),共包括22種復(fù)雜的復(fù)合表情,如高興的驚訝、怨恨、敬畏、驚駭?shù)取ACS專家對(duì)每種表情標(biāo)注了特定的AU。經(jīng)統(tǒng)計(jì),數(shù)據(jù)庫中被標(biāo)注的AU有19種。
5)UNBC-McMaster肩痛表情數(shù)據(jù)庫。
UNBC-McMaster肩痛表情數(shù)據(jù)庫[9]由25名患有肩痛的被試的視頻數(shù)據(jù)構(gòu)成,共200個(gè)視頻序列,視頻為正面拍攝,被試表情為肩痛過程中的自然流露。FACS專家對(duì)視頻中的每一幀進(jìn)行了10種AU強(qiáng)度標(biāo)注。該數(shù)據(jù)庫的最大特點(diǎn)是含有其他數(shù)據(jù)庫中少見的與疼痛相關(guān)的AU43。
6)CK+數(shù)據(jù)庫。
CK+數(shù)據(jù)庫由CK(Cohn-Kanade)數(shù)據(jù)庫擴(kuò)展而來[10],大部分?jǐn)?shù)據(jù)為黑白視頻,少數(shù)為彩色視頻。數(shù)據(jù)庫中包含123位被試的593段表情視頻,所有視頻序列中的表情都是從平靜到峰值程度。FACS專家對(duì)593段視頻的峰值幀,即最后一幀進(jìn)行標(biāo)注,共標(biāo)注了30種AU是否出現(xiàn),其中大部分AU標(biāo)注了強(qiáng)度。
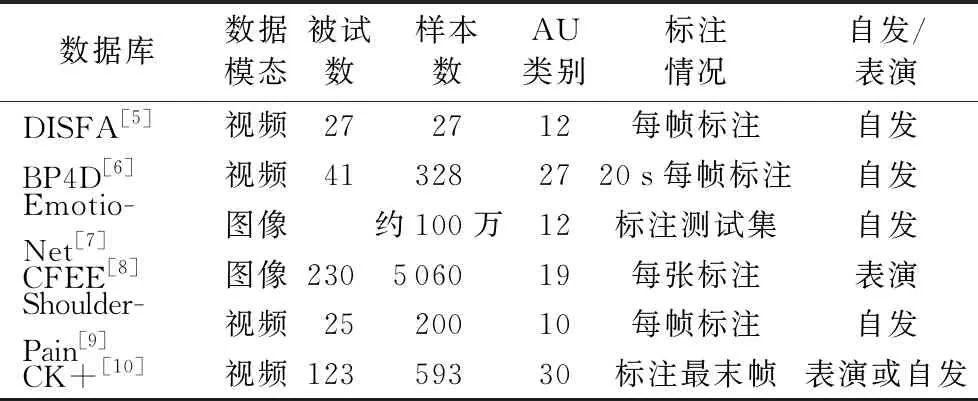
表1 AU數(shù)據(jù)庫概況 Tab. 1 Profile of AU databases
2 傳統(tǒng)AU檢測方法
現(xiàn)有AU檢測方法可簡單分為傳統(tǒng)方法和深度學(xué)習(xí)方法兩大類,如圖2所示,本章重點(diǎn)介紹傳統(tǒng)的AU檢測方法。
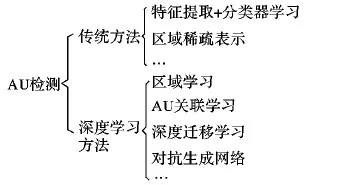
圖2 AU檢測方法Fig. 2 AU detection methods
傳統(tǒng)AU檢測方法一般可分為預(yù)處理、特征提取和分類器學(xué)習(xí)3個(gè)步驟,其中:1)預(yù)處理,主要包括人臉檢測、關(guān)鍵點(diǎn)定位、人臉對(duì)齊、尺寸歸一化等操作;2)特征提取或?qū)W習(xí),即從人臉圖像中提取或?qū)W習(xí)具有較強(qiáng)AU判別性的特征;3)分類器訓(xùn)練,即通過已獲得的特征訓(xùn)練分類器檢測AU是否出現(xiàn)。
在預(yù)處理階段,目前可用的人臉檢測和關(guān)鍵點(diǎn)定位模型有很多,例如人臉檢測工具有Adaboost[12]、多任務(wù)級(jí)聯(lián)卷積神經(jīng)網(wǎng)絡(luò)(Multi-Task Cascaded Convolutional Neural Network)[13]、DSFD(Dual Shot Face Detector)[14]等,關(guān)鍵點(diǎn)定位工具有主動(dòng)外觀模型(Active Appearance Model, AAM)[15]、循環(huán)形狀回歸(Recurrent Shape Regression, RSR)[16]等,這里不再贅述。
提取或?qū)W習(xí)與AU相關(guān)的具有強(qiáng)判別性的特征是AU檢測的關(guān)鍵。傳統(tǒng)AU檢測方法的特征提取一般利用面部紋理特征[17]、幾何特征[18]或兩類特征的結(jié)合[19],即在面部關(guān)鍵點(diǎn)位置處提取紋理特征。與紋理特征相比,幾何特征不會(huì)受到光照、膚色和人與人之間面部差異的影響,但受限于預(yù)處理中關(guān)鍵點(diǎn)定位的精度,且對(duì)于如AU14、AU15這種相對(duì)基準(zhǔn)點(diǎn)幾何位移較小的AU效果不佳,而面部紋理特征則不會(huì)受到這種限制。由于目前沒有專門為AU檢測設(shè)計(jì)的特征算子,所以通常借助于計(jì)算機(jī)視覺領(lǐng)域中人工定義的經(jīng)典特征描述子,如圖像中常用的局部特征算子尺度不變特征變換(Scale-Invariant Feature Transform, SIFT)、Haar、Gabor等,視頻中常用的空時(shí)特征LBP-TOP(Local Binary Patterns on Three Orthogonal Planes)或光流特征[20]等。文獻(xiàn)[21]在20個(gè)面部關(guān)鍵點(diǎn)處提取Gabor小波特征,并用Adaboost和支持向量機(jī)(Support Vector Machine, SVM)進(jìn)行分類;文獻(xiàn)[22]將45個(gè)面部關(guān)鍵點(diǎn)轉(zhuǎn)換為Gabor小波系數(shù),并使用稀疏表達(dá)模型(Sparse Representation, SR)分類;文獻(xiàn)[23]將幾何特征與局部Gabor小波特征融合,并基于核子類判別分析(Kernel Subclass Discriminant Analysis, KSDA)分類;文獻(xiàn)[24]直接提取Haar特征作為AU的特征表達(dá)。
除直接提取特征外,為了獲得更具判別性的AU相關(guān)特征,文獻(xiàn)[25-26]中提出將人臉圖像用均勻網(wǎng)格劃分,基于每個(gè)區(qū)域?qū)τ贏U的貢獻(xiàn)進(jìn)行選擇或者加權(quán),但這種簡單的劃分方式對(duì)于人臉姿態(tài)的變化并不魯棒。文獻(xiàn)[27]使用兩層組稀疏在事先定義好的面部區(qū)域上進(jìn)行AU編碼;文獻(xiàn)[28]通過面部關(guān)鍵點(diǎn)確定區(qū)域中心并提取SIFT特征,再使用組稀疏學(xué)習(xí)自動(dòng)選擇圖像上與目標(biāo)AU相關(guān)的區(qū)域所對(duì)應(yīng)的特征。通過稀疏表達(dá)方法習(xí)得的特征判別性有一定程度的增強(qiáng),然而選擇出來的關(guān)鍵區(qū)域仍較為粗糙,無法習(xí)得像素級(jí)別的AU重要區(qū)域。
在分類階段,傳統(tǒng)AU檢測方法中一般使用如支持向量機(jī)、K近鄰(K-Nearest Neighbors,KNN)或稀疏表達(dá)模型等作為分類器。
上述方法大都使用人工設(shè)計(jì)特征描述子與傳統(tǒng)模式識(shí)別領(lǐng)域中的分類器,近年來隨著深度學(xué)習(xí)的興起,基于深度學(xué)習(xí)的AU檢測技術(shù)被廣泛研究。一方面由于深度卷積網(wǎng)絡(luò)能夠習(xí)得與AU檢測任務(wù)更相關(guān)的具有強(qiáng)判別性的特征;另一方面通過網(wǎng)絡(luò)全連接層的輸出可方便地解決多標(biāo)簽問題。當(dāng)然傳統(tǒng)方法與深度學(xué)習(xí)方法存在著密切的關(guān)聯(lián),很多在傳統(tǒng)方法中使用的解決問題思路也常被應(yīng)用在深度模型中。
3 基于深度學(xué)習(xí)的AU檢測方法
近年來由于深度學(xué)習(xí)方法在計(jì)算機(jī)視覺、模式識(shí)別等諸多方向上取得的巨大成功,在AU檢測領(lǐng)域,基于深度模型研究AU檢測已成為主流,如文獻(xiàn)[29]使用一個(gè)三層卷積一層全連接的淺層網(wǎng)絡(luò)學(xué)習(xí)AU檢測和AU強(qiáng)度判斷;文獻(xiàn)[30]中提出優(yōu)化的卷積核尺度CNN(Optimized Filter Size CNN, OFS-CNN)模型建模AU識(shí)別問題,OFS-CNN中卷積核的尺寸和權(quán)重在訓(xùn)練過程中同步更新以適應(yīng)不同的圖像分辨率。本章內(nèi)容主要以深度學(xué)習(xí)方法為主,同時(shí)在介紹一些通用問題時(shí)也將概述傳統(tǒng)方法中的解決方案。
由AU的定義可知AU與面部肌肉是密切相關(guān)的,相比于其他物體檢測任務(wù),AU檢測具有其特殊的性質(zhì)。自從文獻(xiàn)[31]于1996年首次展開AU檢測研究以來,該領(lǐng)域發(fā)展至今一直存在兩個(gè)研究重點(diǎn)被廣泛關(guān)注,大量研究工作圍繞這兩個(gè)問題展開:1)如何更好地確定AU所在的關(guān)鍵面部區(qū)域并加以重點(diǎn)學(xué)習(xí);2)如何更好地建模AU之間的相關(guān)性,通過習(xí)得的AU關(guān)聯(lián)信息輔助提升整體檢測性能。這兩個(gè)問題逐漸抽象為兩條研究路線:區(qū)域?qū)W習(xí)與AU關(guān)聯(lián)學(xué)習(xí),本章前兩節(jié)將詳細(xì)介紹這兩個(gè)方向上的研究進(jìn)展;同時(shí),由于AU標(biāo)注數(shù)據(jù)的稀缺性,近年來弱監(jiān)督學(xué)習(xí)被引入解決這一問題,3.3節(jié)將介紹這一方向的相關(guān)工作。
3.1 區(qū)域?qū)W習(xí)
每個(gè)AU所在人臉區(qū)域的位置可由AU定義確定,對(duì)任意一個(gè)AU考慮其檢測問題,顯然并非所有面部區(qū)域?qū)λ欠癯霈F(xiàn)都有貢獻(xiàn),若不考慮AU之間的關(guān)聯(lián),一般來說僅有其對(duì)應(yīng)面部肌肉所在的幾塊稀疏的區(qū)域?qū)λ臋z測是有貢獻(xiàn)的,其他區(qū)域則不需要過多關(guān)注,因此找到那些需要關(guān)注的區(qū)域并加以重點(diǎn)學(xué)習(xí)才能更好地進(jìn)行AU檢測,專注于這一問題的解決方案一般被稱為區(qū)域?qū)W習(xí)(Region Learning, RL)。
類似于傳統(tǒng)方法中在AU中心處提取特征的做法,文獻(xiàn)[32]基于面部關(guān)鍵點(diǎn)和AU領(lǐng)域的先驗(yàn)知識(shí)對(duì)每一個(gè)AU提前選擇一個(gè)相關(guān)區(qū)域,并構(gòu)造二值的掩膜,然后基于此區(qū)域和掩膜使用卷積神經(jīng)網(wǎng)絡(luò)和長短時(shí)記憶(Long Short-Term Memory, LSTM)網(wǎng)絡(luò)進(jìn)行學(xué)習(xí),然而這種做法需要人工構(gòu)造掩膜且檢測性能依賴于掩膜的準(zhǔn)確程度。
2016年Zhao等[33]首先提出深度區(qū)域和多標(biāo)簽學(xué)習(xí)(Deep Region and Multi-label Learning, DRML)框架,通過提出的區(qū)域?qū)?Region Layer)自動(dòng)學(xué)習(xí)與AU相關(guān)的重要面部區(qū)域,如圖3所示,使得在各個(gè)區(qū)域習(xí)得的權(quán)重能夠捕獲面部的結(jié)構(gòu)信息。該模型將區(qū)域?qū)又糜诘谝粚泳矸e輸出之后,首先用均勻網(wǎng)格將卷積特征映射圖分塊,在每塊小區(qū)域上使用一組獨(dú)立的卷積核學(xué)習(xí)該區(qū)域上與AU相關(guān)的特征,最后將各區(qū)域的特征映射圖拼回原來的位置并與原始特征映射圖相加,類似于深度殘差網(wǎng)絡(luò)中的殘差結(jié)構(gòu)。除區(qū)域?qū)油猓渌糠值木W(wǎng)絡(luò)結(jié)構(gòu)類似于AlexNet,最后一個(gè)全連接層的節(jié)點(diǎn)數(shù)與目標(biāo)AU個(gè)數(shù)相同,從而隱式地進(jìn)行多標(biāo)簽學(xué)習(xí),且可直接輸出多個(gè)AU的檢測結(jié)果。得益于像素級(jí)別的關(guān)鍵區(qū)域精度和多標(biāo)簽學(xué)習(xí)方式,DRML取得了超越傳統(tǒng)方法及普通CNN模型的檢測性能。

圖3 區(qū)域?qū)咏Y(jié)構(gòu)Fig. 3 Structure of region layer
沿襲這一思路繼續(xù)改進(jìn)的有文獻(xiàn)[34]中提出的EAC-Net (Enhancing And Cropping Net),通過構(gòu)造增強(qiáng)層(E-Net)和裁切層(C-Net)學(xué)習(xí)與AU更相關(guān)的面部區(qū)域。EAC-Net的基礎(chǔ)網(wǎng)絡(luò)架構(gòu)為VGG- 19,在第2組和第3組卷積之后加上增強(qiáng)層,在第4組卷積之后加上裁切層。為了顯式地限制網(wǎng)絡(luò)需要重點(diǎn)學(xué)習(xí)的面部區(qū)域,增強(qiáng)層中人工構(gòu)造了一種AU注意力映射圖,該圖由BP4D數(shù)據(jù)集中的12個(gè)AU定制而來,首先以數(shù)據(jù)庫中給定的面部關(guān)鍵點(diǎn)坐標(biāo)為基礎(chǔ),基于各AU所在面部肌肉位置選擇與其最為鄰近的關(guān)鍵點(diǎn)并進(jìn)行一定的偏移修正,由此得到每個(gè)AU對(duì)應(yīng)的中心點(diǎn)坐標(biāo),然后再基于各個(gè)中心點(diǎn),將其分別擴(kuò)展成大小為11×11的AU相關(guān)區(qū)域,并且在該區(qū)域內(nèi),點(diǎn)離中心的距離越遠(yuǎn)則其所在位置對(duì)應(yīng)的權(quán)重越小,由此在深度模型中人為地引入AU所在位置的先驗(yàn)信息。
在裁切層中,類似于DRML中的區(qū)域?qū)W習(xí),將上述定義的20個(gè)感興趣的區(qū)域裁切出來后使用互相獨(dú)立的卷積核學(xué)習(xí)AU相關(guān)特征,再通過全連接層進(jìn)行特征融合并輸出AU檢測結(jié)果。相比于DRML,EAC-Net對(duì)關(guān)鍵區(qū)域進(jìn)行了進(jìn)一步的強(qiáng)化,通過關(guān)鍵點(diǎn)的先驗(yàn)知識(shí)引入AU所在面部區(qū)域,從而使網(wǎng)絡(luò)更容易在關(guān)鍵區(qū)域?qū)W習(xí)AU相關(guān)的特征。
除了EAC-Net,類似地文獻(xiàn)[35]在視頻的AU檢測任務(wù)中提出了感興趣區(qū)域(Region Of Interest, ROI)裁切網(wǎng)絡(luò),同樣使用面部關(guān)鍵點(diǎn)定位了20個(gè)與AU相關(guān)的ROI區(qū)域,然后對(duì)于每塊感興趣的區(qū)域使用獨(dú)立的CNN進(jìn)行學(xué)習(xí),并使用LSTM推導(dǎo)出AU的標(biāo)簽。
進(jìn)一步地,文獻(xiàn)[36]于2018年提出聯(lián)合的AU檢測和人臉對(duì)齊框架JAA-Net(Joint AU detection and face alignment)。由于面部關(guān)鍵點(diǎn)與AU位置的密切關(guān)聯(lián),JAA-Net將面部關(guān)鍵點(diǎn)定位作為附加任務(wù)引入網(wǎng)絡(luò),與AU檢測同步優(yōu)化,以此促進(jìn)AU檢測性能的提升,JAA-Net的多任務(wù)網(wǎng)絡(luò)結(jié)構(gòu)如圖4所示。JAA-Net中的初始注意力映射圖通過網(wǎng)絡(luò)輸出的面部關(guān)鍵點(diǎn)位置構(gòu)造,構(gòu)造方法與EAC-Net相同,不同的是,EAC-Net中的注意力圖是固定不變的,而JAA-Net中考慮了padding對(duì)AU檢測結(jié)果的影響,在注意力圖上通過上采樣等操作進(jìn)行優(yōu)化。此外,不同于DRML和EAC-Net中只有一個(gè)尺度的區(qū)域?qū)W習(xí),JAA-Net中使用了分層的多尺度區(qū)域?qū)W習(xí),將卷積輸出的特征映射圖均勻分成8×8、4×4和2×2三種尺度,在三個(gè)尺度上對(duì)每塊區(qū)域使用一組獨(dú)立的卷積核進(jìn)行學(xué)習(xí),最后將每塊的特征映射圖拼回原來的位置,并將所有尺度的輸出級(jí)聯(lián)起來與原始特征映射圖相加。目前JAA-Net是AU區(qū)域?qū)W習(xí)方向上表現(xiàn)最佳的網(wǎng)絡(luò),在BP4D和DISFA上均超越了EAC-Net和DRML的性能。
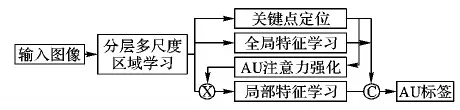
圖4 JAA-Net框架Fig. 4 JAA-Net framework
3.2 AU關(guān)聯(lián)學(xué)習(xí)
AU是在面部肌肉解剖學(xué)的基礎(chǔ)上定義的,描述了一塊或幾塊肌肉的運(yùn)動(dòng),某些肌肉在運(yùn)動(dòng)過程中會(huì)牽動(dòng)幾個(gè)AU同時(shí)出現(xiàn),因此AU之間存在一定程度的相關(guān)性。某些AU常常一同出現(xiàn),而一些AU則無法同時(shí)出現(xiàn)[36]。顯然,這些AU關(guān)聯(lián)性信息會(huì)有助于模型檢測性能的提升,因此如何挖掘AU之間的關(guān)聯(lián)并基于相關(guān)性提升AU模型檢測性能是另一個(gè)需要重點(diǎn)關(guān)注的問題[37]。
在傳統(tǒng)方法中研究人員一般建立一個(gè)獨(dú)立的關(guān)系模型描述AU之間的相關(guān)性,然后基于已預(yù)測的AU標(biāo)簽進(jìn)行相關(guān)性推理,相當(dāng)于對(duì)預(yù)測標(biāo)簽進(jìn)行進(jìn)一步的后處理,其優(yōu)點(diǎn)在于:1)增大了一些難以直接從圖像上檢測到AU的被檢概率;2)修正了一些基于圖像或視頻預(yù)測錯(cuò)誤的AU,提升了檢測模型的魯棒性;但是由于關(guān)聯(lián)模型的獨(dú)立性和對(duì)預(yù)測標(biāo)簽后處理的方式,使這種建模方式無法影響前端的特征學(xué)習(xí)和檢測過程。這類工作的典型代表有:文獻(xiàn)[38]使用隱馬爾可夫模型建模AU關(guān)聯(lián),并與SVM相結(jié)合。文獻(xiàn)[39-41]中提出使用貝葉斯網(wǎng)絡(luò)建模AU之間的關(guān)聯(lián),貝葉斯網(wǎng)絡(luò)是用來表達(dá)一組變量之間的聯(lián)合概率分布的一種有向無環(huán)圖,首先通過分析AU數(shù)據(jù)庫中兩兩AU出現(xiàn)概率分布以此構(gòu)造初始貝葉斯網(wǎng)絡(luò),然后通過優(yōu)化網(wǎng)絡(luò)結(jié)構(gòu)分?jǐn)?shù)更新貝葉斯網(wǎng)絡(luò),從而得到更加準(zhǔn)確的AU關(guān)聯(lián)。文獻(xiàn)[42]基于定性的先驗(yàn)知識(shí)和定量的數(shù)據(jù)通過Credal網(wǎng)絡(luò)學(xué)習(xí)AU之間的關(guān)系。文獻(xiàn)[43]使用三層受限玻爾茲曼機(jī)(Restricted Boltzmann Machine, RBM)挖掘AU之間的高階相關(guān)性關(guān)系,與其他僅能學(xué)習(xí)兩兩AU之間關(guān)系的方法相比,RBM能習(xí)得全局的AU之間的相關(guān)性。類似的,文獻(xiàn)[44]使用四層RBM學(xué)習(xí)全局的AU關(guān)聯(lián)和AU檢測與面部關(guān)鍵點(diǎn)定位之間的關(guān)聯(lián)。
為了克服這種后處理模式帶來的弊端,有研究人員將AU關(guān)聯(lián)性學(xué)習(xí)與前端基于視覺特征的檢測過程結(jié)合起來,作為一個(gè)整體同時(shí)進(jìn)行優(yōu)化,以此提升模型的整體性能。文獻(xiàn)[45]在多任務(wù)中通過多核學(xué)習(xí)(Multiple Kernel Learning, MKL)方法同時(shí)學(xué)習(xí)更具判別性的面部特征表達(dá)和AU之間的關(guān)聯(lián)。文獻(xiàn)[46]基于多個(gè)條件隱變量模型同時(shí)融合面部特征和檢測AU,在連續(xù)隱變量空間中,不需要AU之間的先驗(yàn)關(guān)系也能有效地在大量AU輸出之間建模關(guān)聯(lián)信息。文獻(xiàn)[28]從數(shù)據(jù)庫中統(tǒng)計(jì)同時(shí)存在和互斥的成對(duì)AU,即正相關(guān)和負(fù)相關(guān)的AU關(guān)系,然后構(gòu)造關(guān)系正則項(xiàng)并加入目標(biāo)表達(dá)式中一同優(yōu)化,以此學(xué)習(xí)AU之間的關(guān)聯(lián)。文獻(xiàn)[36]基于一般性的領(lǐng)域知識(shí)將AU關(guān)聯(lián)用有向圖表達(dá),在沒有訓(xùn)練數(shù)據(jù)的前提下也能實(shí)現(xiàn)AU檢測。上述方法大都直接使用傳統(tǒng)計(jì)算機(jī)視覺中人工定義的底層特征描述子提取面部特征,導(dǎo)致AU關(guān)聯(lián)學(xué)習(xí)與前端特征學(xué)習(xí)互相獨(dú)立,在一定程度上仍然限制了模型的性能。
由于深度學(xué)習(xí)模型自身具有的端對(duì)端特性,直接在深度網(wǎng)絡(luò)后端加入關(guān)聯(lián)模型即可將特征學(xué)習(xí)、關(guān)聯(lián)性學(xué)習(xí)和AU檢測融為一個(gè)整體同時(shí)進(jìn)行優(yōu)化,進(jìn)一步消除了上述方法的弊端。文獻(xiàn)[47]將copula函數(shù)作為條件隨機(jī)場(Conditional Random Field, CRF)的團(tuán)學(xué)習(xí)AU之間的相關(guān)性,并將其與CNN聯(lián)合迭代優(yōu)化;類似的,文獻(xiàn)[48]使用CRF-RNN建模AU之間的關(guān)系,而在3.1節(jié)所述的DRML、EAC-Net、ROI-Net和JAA-Net中,最后一層全連接均直接輸出AU的多標(biāo)簽檢測結(jié)果,即通過一層全連接網(wǎng)絡(luò)學(xué)習(xí)各個(gè)AU之間的關(guān)聯(lián)性,達(dá)到多標(biāo)簽學(xué)習(xí)的目的;然而僅通過一層全連接學(xué)習(xí)AU之間的關(guān)聯(lián)性并不充分,近年來已有一些研究人員試圖通過其他方法進(jìn)行顯式地建模。
文獻(xiàn)[49]中提出深度結(jié)構(gòu)推理網(wǎng)絡(luò)(Deep Structure Inference Network, DSIN),使用類似于圖模型推理的思路學(xué)習(xí)AU之間的關(guān)聯(lián),這里的結(jié)構(gòu)信息即指AU之間的關(guān)聯(lián)信息,其網(wǎng)絡(luò)結(jié)構(gòu)如圖5所示。首先在輸入圖像的幾個(gè)AU相關(guān)的關(guān)鍵區(qū)域切割出若干小圖像塊,經(jīng)互相獨(dú)立的CNN提取特征后輸出AU的多標(biāo)簽概率,經(jīng)全連接層融合之后,進(jìn)入結(jié)構(gòu)推理模塊,該模塊由一組互相連接的循環(huán)結(jié)構(gòu)推理單元(Structure Interference Unit, SIU)構(gòu)成,SIU如圖6所示。
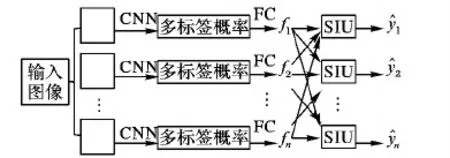
圖5 深度結(jié)構(gòu)推理網(wǎng)絡(luò)Fig. 5 Deep structure inference network
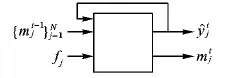
圖6 結(jié)構(gòu)推理單元Fig. 6 Structure interference unit
每個(gè)目標(biāo)AU對(duì)應(yīng)一個(gè)專門的SIU,以類似于RNN的方式循環(huán)更新AU標(biāo)簽。類似于LSTM中的元胞狀態(tài),SIU通過信息單元m存儲(chǔ)其他所有AU的標(biāo)簽狀態(tài),由此接收其他AU的標(biāo)簽信息,通過迭代地更新m學(xué)習(xí)目標(biāo)AU與其他AU之間的關(guān)聯(lián),同時(shí)每個(gè)AU的預(yù)測值也在不斷迭代優(yōu)化。假設(shè)目標(biāo)AU個(gè)數(shù)為N,SIU實(shí)現(xiàn)了如下功能:
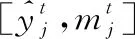
(1)
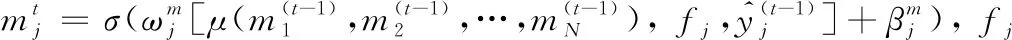

(2)
(3)
(4)
(5)
(6)
(7)
其中:Av是節(jié)點(diǎn)v的鄰接矩陣;⊙為元素間點(diǎn)乘;W和U為需要學(xué)習(xí)的權(quán)重矩陣。由于每個(gè)節(jié)點(diǎn)在每一時(shí)刻均接收到其他節(jié)點(diǎn)的信息,因此在迭代過程中能夠?qū)W習(xí)到AU之間的全局關(guān)聯(lián)。在經(jīng)過T輪迭代后,每個(gè)節(jié)點(diǎn)的輸出為:
(8)
其中:xv為節(jié)點(diǎn)v的標(biāo)注;g為全連接網(wǎng)絡(luò),由此可以得到各個(gè)目標(biāo)AU的檢測結(jié)果。經(jīng)實(shí)驗(yàn),SRERL超越DSIN,在BP4D和DISFA數(shù)據(jù)庫上達(dá)到了目前最好的性能,具體性能對(duì)比見文獻(xiàn)[50]。
3.3 結(jié)合弱監(jiān)督學(xué)習(xí)
與其他計(jì)算機(jī)視覺領(lǐng)域中的任務(wù)一樣,在AU檢測任務(wù)中,無論是區(qū)域?qū)W習(xí)還是AU關(guān)聯(lián)學(xué)習(xí)均依賴準(zhǔn)確標(biāo)注的AU數(shù)據(jù),且基于深度學(xué)習(xí)的方法一般需要大量數(shù)據(jù)才能取得較好的檢測性能。相比于在圖像中框出人臉或者標(biāo)注其中物體的標(biāo)簽,在一張人臉圖像上辨別幾十種AU是否出現(xiàn)乃至標(biāo)注其強(qiáng)度對(duì)于普通的數(shù)據(jù)標(biāo)定人員,甚至AU檢測領(lǐng)域的專業(yè)研究人員而言,都是非常困難的,所以在建立AU數(shù)據(jù)庫時(shí)一般需要邀請(qǐng)至少兩名經(jīng)過專業(yè)訓(xùn)練的FACS專家進(jìn)行數(shù)據(jù)標(biāo)注,從而保證數(shù)據(jù)標(biāo)注的準(zhǔn)確度,而即便如此也并非意味著所有AU標(biāo)簽完全正確,這些問題導(dǎo)致獲得大規(guī)模有準(zhǔn)確標(biāo)注的AU數(shù)據(jù)的門檻很高且代價(jià)高昂,嚴(yán)重限制了AU檢測技術(shù)的發(fā)展。另一方面,現(xiàn)實(shí)世界中存在海量的未標(biāo)注過AU或者僅有不準(zhǔn)確標(biāo)注的人臉圖像。為了充分利用這些易于獲得的大規(guī)模數(shù)據(jù)提升AU檢測性能,弱監(jiān)督學(xué)習(xí)技術(shù)被引入AU檢測任務(wù)中,希望借此改善AU準(zhǔn)確標(biāo)注數(shù)據(jù)嚴(yán)重不足的問題。近年來在各個(gè)頂級(jí)學(xué)術(shù)會(huì)議中出現(xiàn)了一批結(jié)合弱監(jiān)督學(xué)習(xí)的AU檢測研究,目前已逐漸成為AU檢測領(lǐng)域內(nèi)的主流研究方向。
文獻(xiàn)[51]通過數(shù)據(jù)庫中正確的AU標(biāo)簽學(xué)習(xí)AU分布,然后基于大量未標(biāo)注數(shù)據(jù)最大化關(guān)于AU標(biāo)簽分布的log似然映射函數(shù)訓(xùn)練SVM分類器,由于該方法基于原始數(shù)據(jù)庫中的AU分布,故對(duì)于分布不同的未標(biāo)注數(shù)據(jù)性能有限;文獻(xiàn)[52]為了讓AU檢測模型對(duì)數(shù)據(jù)庫中的噪聲標(biāo)簽魯棒,提出一種全局-局部(Global-Local, GL)損失函數(shù),在保證AU檢測準(zhǔn)確率的同時(shí),模型能夠快速收斂;文獻(xiàn)[53]基于不準(zhǔn)確AU標(biāo)注的互聯(lián)網(wǎng)人臉數(shù)據(jù),提出一種弱監(jiān)督譜聚類方法學(xué)習(xí)一個(gè)嵌入空間來耦合圖像特征及其AU語義;文獻(xiàn)[54]僅利用視頻序列中標(biāo)注的峰值幀,提出一種基于領(lǐng)域知識(shí)的半監(jiān)督深度CNN模型回歸AU強(qiáng)度;不同于文獻(xiàn)[48],文獻(xiàn)[55]將與數(shù)據(jù)庫無關(guān)的AU先驗(yàn)概率分布與AU分類器損失函數(shù)相結(jié)合,實(shí)現(xiàn)了在無AU標(biāo)注樣本下的AU檢測,取得了較高的性能。
此外由于生成對(duì)抗網(wǎng)絡(luò)(Generative Adversarial Network, GAN)能夠在一定程度上消除兩組異質(zhì)數(shù)據(jù)之間的差異[56],目前有部分研究人員關(guān)注于將其應(yīng)用到AU檢測任務(wù)中。文獻(xiàn)[57]將對(duì)抗訓(xùn)練思路與弱監(jiān)督學(xué)習(xí)結(jié)合起來,依靠AU先驗(yàn)知識(shí)和帶有表情標(biāo)簽的數(shù)據(jù)訓(xùn)練AU檢測模型,由此充分利用表情數(shù)據(jù)量大的優(yōu)勢(shì)解決AU檢測問題。
4 存在的不足及潛在的發(fā)展
借助深度學(xué)習(xí)方法,面部運(yùn)動(dòng)單元檢測技術(shù)在區(qū)域?qū)W習(xí)和AU關(guān)聯(lián)學(xué)習(xí)等方面取得了長足的進(jìn)步,模型的檢測性能已大幅度超越傳統(tǒng)方法,在公安刑偵、在線教育和社會(huì)感知等人機(jī)交互領(lǐng)域應(yīng)用前景廣泛。然而,現(xiàn)有的AU檢測研究仍存在一些不足,這些不足也是未來的潛在發(fā)展方向。
1)大部分檢測模型只能處理正面人臉的情況,對(duì)于非正面人臉性能下降嚴(yán)重,導(dǎo)致圖像或視頻在輸入網(wǎng)絡(luò)前需經(jīng)過繁瑣的預(yù)處理步驟,除了必要的人臉檢測外,還需進(jìn)行面部關(guān)鍵點(diǎn)定位和人臉對(duì)齊,在實(shí)際應(yīng)用場景中影響整體檢測速度。該問題的主因是目前非正面的人臉AU數(shù)據(jù)十分匱乏,此外非正面人臉上的AU特性與正面情況不同。未來需要從數(shù)據(jù)和算法兩方面入手:一方面建立大規(guī)模的AU數(shù)據(jù)庫,數(shù)據(jù)庫內(nèi)需要包含各種姿態(tài)、光照、遮擋、背景噪聲等條件的AU數(shù)據(jù);另一方面需要研究非正面AU的特點(diǎn)并建立非正面AU檢測模型。
2)目前的AU檢測研究局限于強(qiáng)度顯著的AU,按照FACS的定義,AU強(qiáng)度由弱到強(qiáng)分為A、B、C、D、E五個(gè)級(jí)別,在文獻(xiàn)的實(shí)驗(yàn)中往往使用強(qiáng)度大于B或C的樣本作為正樣本,其他強(qiáng)度視為負(fù)樣本,對(duì)于弱強(qiáng)度AU檢測研究還不多。由于弱強(qiáng)度AU與微表情緊密關(guān)聯(lián),可用于測謊等領(lǐng)域,所以是未來AU檢測領(lǐng)域的一個(gè)發(fā)展趨勢(shì)。
3)很多研究中通過引入注意力映射圖強(qiáng)化AU的區(qū)域?qū)W習(xí),而目前大部分注意力映射圖需要人工根據(jù)目標(biāo)AU所在位置進(jìn)行事先定義,當(dāng)數(shù)據(jù)庫中AU種類有限時(shí)這一做法尚可行,但AU種類增多到一定程度則十分不便,需要研究自適應(yīng)地學(xué)習(xí)AU注意力映射的方法。
5 結(jié)語
自1978年面部運(yùn)動(dòng)單元的概念被提出后,面部運(yùn)動(dòng)單元檢測技術(shù)逐漸被越來越多的研究人員關(guān)注,并且在最近二十年來得到了蓬勃的發(fā)展。本文綜述了面部運(yùn)動(dòng)單元檢測中包括預(yù)處理、特征學(xué)習(xí)、分類器學(xué)習(xí)等各個(gè)環(huán)節(jié)的技術(shù)發(fā)展情況,著重總結(jié)了在AU區(qū)域?qū)W習(xí)、關(guān)聯(lián)學(xué)習(xí)以及結(jié)合弱監(jiān)督學(xué)習(xí)等AU檢測方向利用深度學(xué)習(xí)技術(shù)取得的研究進(jìn)展。未來面部運(yùn)動(dòng)單元檢測技術(shù)將在大規(guī)模數(shù)據(jù)庫的建立、區(qū)域?qū)W習(xí)和運(yùn)動(dòng)單元關(guān)聯(lián)學(xué)習(xí)上繼續(xù)發(fā)展,同時(shí)基于弱監(jiān)督學(xué)習(xí)等方法的面部運(yùn)動(dòng)單元檢測也將成為主流的研究方向之一。
猜你喜歡
當(dāng)代陜西(2021年17期)2021-11-06 03:21:36
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當(dāng)代陜西(2019年10期)2019-06-03 10:12:04
學(xué)苑創(chuàng)造·A版(2018年11期)2018-02-01 06:29:20
數(shù)學(xué)小靈通·3-4年級(jí)(2017年9期)2017-10-13 08:10:54
財(cái)經(jīng)(2017年2期)2017-03-10 14:35:35
讀者(2017年5期)2017-02-15 18:04:18
財(cái)經(jīng)(2016年15期)2016-06-03 07:38:02
財(cái)經(jīng)(2016年3期)2016-03-07 07:44:46
財(cái)經(jīng)(2016年6期)2016-02-24 07:41:51
