基于像素級注意力機制的人群計數方法
2020-03-06 12:55:58陳美云王必勝梁永博
計算機應用 2020年1期
陳美云,王必勝,曹 國,梁永博
(南京理工大學 計算機科學與工程學院,南京 210094)
0 引言
人群計數[1]旨在統計擁擠場景中的人數,通常存在遮擋、分辨率低、人員分布不均勻、場景復雜等干擾因素,是非常值得探究的一個方向。目前,城市的人口數量隨著城市化的發展急劇增長,人口暴增導致各類人群活動顯著增加,如演唱會、路演、競技賽等。為了更好地保障社會治安,對這些場景進行準確的人群計數是非常必要的一項工作[2]。卓越的人群計數工作對構建高層次認知能力有極大的作用,例如分析道路擁塞[3-4]、檢測異常狀況[5]、檢測特定事件[6]等。除此以外,優秀的人群計數方法還可以推廣到車輛計數[7]、野生動物密度估計[8]和計量顯微圖像中的細胞[9]等多個領域。
在深度學習方法盛行之前,人群計數的方法主要以檢測和回歸為主。
以檢測為主的人群計數算法先訓練檢測器用以識別輸入圖中的個體,繼而將識別個體進行累加得出總人群數。過去采用檢測的人群計數算法是根據某些特征如方向梯度直方圖(Histogram of Oriented Gradients, HOG)[10]、Haar小波[11]等來訓練檢測器,從而將人體檢測出來。不過,當這種方式用來計數高密度人群時,就會受到遮擋、重疊等因素的嚴重干擾,而且這種方式在計算時間和計算資源方面占用比較大,性能不夠優異。
針對高密度場景,有研究人員提出了回歸人群數目和人群特征兩者間映射關系的方法。回歸算法先進行底層特征提取,然后進行模型回歸。其中,底層特征由場景的紋理特征(如LBP(Local Binary Pattern))[12-13]、局部特征(如邊緣特征)、全局特征得來;然而,回歸算法在進行模型回歸時會丟失掉部分關鍵的空間信息。
如今,科技的進步使得圖形處理器(Graphics Processing Unit, GPU)極大地提升了計算能力,時間的推移使得大型數據庫更多地涌現,而這兩者的發展則使得深度學習[14]在提取特征和泛化模型方面性能優越,甚至在許多方面已經完全超越了傳統算法。
鑒于卷積神經網絡(Convolutional Neural Network, CNN)顯著提升了目標識別、圖像分類[14-15]等多個計算機視覺領域的準確度,人群計數的研究人員也開始嘗試采用卷積神經網絡來探索人群密度與人群圖像兩者的非線性關系。實驗證明卷積神經網絡在人群計數準確性方面相比前兩種傳統方法提升顯著。
其實,采用卷積神經網絡方式進行人群計數也屬于回歸算法的一種。卷積神經網絡先提取輸入圖片中的人群特征,然后通過回歸方式計算出人群總數。回歸方式分為兩種:一種是卷積神經網絡學習輸入圖片與人數間的映射關系,然后直接回歸計算出人群總數;另一種是卷積神經網絡學習輸入圖片和人群密度圖的映射關系,然后對密度圖進行積分得出人群總數。
Zhang等[16]是第一個采用CNN來解決人群計數問題的,不過,該方法回歸結果并非人群總數而是人群的密度等級。此后,Zhang等[17]針對提升跨場景計數性能不佳問題,提出了一種先訓練一些場景圖片,測試時從訓練集中找到相似場景圖來微調網絡。雖然該算法提升了跨場景人群計數的準確性,但占用的資源過多。Sindagi等[18]提出了一種輸入為整幅原始圖片的卷積神經網絡,這是因為圖片切塊存在重疊部分,會造成計算重復。Zhang等[19]提出了一種包含三列卷積核尺寸各異的多列卷積神經網絡,各列子網絡對應處理不同尺度的人群。該算法還考慮到了圖片拍攝角度的問題,因此使用自適應卷積核來生成密度圖。
可見針對人群計數這一課題,研究者們已經提出了許多以卷積神經網絡[14,20-21]為基礎的算法[16,18-19,22-23],雖然識別效果不錯,但仍然有一些基本問題沒有得到很好解決。
由于人頭在不同地方的分布存在很大的差異,許多人群計數算法會將人群圖像劃分為不同人群密度等級的圖像塊[18,22];然而由于真實密度圖是基于像素的,所以這種基于圖像塊圖像的分類方法無法與真實密度圖完美匹配,使得最終估計的密度圖中會造成模糊。針對這一問題,本文采用了一種新的不同于傳統注意力機制的像素級注意力機制。這種新方法不再對圖像塊進行分類,而是生成像素級的像素掩碼,從而指導密度估計網絡獲得更精確的密度值。
綜上所述,本文提出了相應的改進方法,采用了一種基于像素的注意力機制來處理人群非均勻分布的問題。設計了一種新的以更少的學習參數學習到更多代表性特征的單列網絡,可以得到高效的人群計數結果。
1 算法分析
本章將介紹本文的整體算法結構。如圖1所示,本文算法結構主要包括兩個部分:像素級注意力機制(Pixel-level Attention Mechanism, PAM)和人群密度估計網絡。
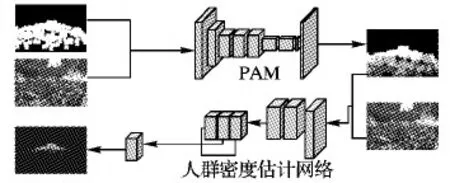
圖1 整體網絡架構Fig. 1 Overall network architecture
1.1 標簽密度圖的生成
人群圖像的標注是在人頭部中心作的點標注。圖2(a)采用一個3×3大小的方格來代表人群圖像的局部區域,像素點值為1表示人,值為0則表示背景。
在圖像中假設每個人頭大小都是3×3像素,圖2(b)就是圖2(a)對應的使用卷積神經網絡進行人群計數的標簽密度圖,各個人頭區域的概率之和為1,得到完整的人群圖像密度圖后,對其進行積分(求和)就是人群數目。

圖2 標簽密度圖的生成Fig. 2 Generation of label density map
為了保存更多的空間信息,本文實際使用歸一化高斯核將每個頭部標注模糊,估計圖像中每個人頭的大小并轉換為密度圖。步驟如下:
xi表示人頭中心坐標位置,用函數δ(x-xi)表示,對于一幅有N個人頭標注的人群圖像來說,可以表示為H(x)函數:
(1)
將式(1)與高斯核進行卷積,轉化為連續密度函數,如式(2)所示:
(2)
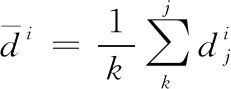

圖3 原圖和對應生成的標簽密度圖Fig. 3 Original image and corresponding generated label density map
1.2 像素注意力機制
人群計數的一些方法[22]將整幅圖像上的小塊分割成不同的密度類,然后利用分類結果提高局部密度估計的精度。這種圖像小塊級的注意力機制并不能很好地與真實值相匹配,因為真實值反映的是每個特定像素的密度信息,因此,本文提出了一種像素級注意力機制來定量模擬圖像的局部密度信息。
生成的標簽密度圖的每個像素都表示一個密度值。根據這些像素的密度值設定閾值,分成不同密度程度的類別,以反映人群的多樣性。舉例來說,類別標號為{0,1,2,3,4},其中,{0}表示背景,{1,2,3,4}表示4種不同密集程度的人群。需要注意的是,針對不同的數據集,設置的密度等級會有所不同。至于設置多少類別以及密度等級閾值大小可根據實驗確定。本文根據局部區域的人頭大小通過實驗設置了閾值,而類別數量則由實驗對比決定。具體實驗結果見第2.2節。
將每個像素劃分到特定類別是一個像素對像素的語義分割問題,因此本文使用了表現性能優異的全卷積網絡(Fully Convolutional Network, FCN)[24]來解決像素劃分問題。
直觀來看,用卷積層替換卷積神經網絡的全連接層就得到了全卷積神經網絡。全卷積神經網絡的輸出是一幅已經完成標記的圖。
全卷積神經網絡的輸入是大小為h*w的原圖,原圖經過第1次卷積、池化以后縮小為原來的1/2;然后繼續進行第2次卷積、池化,圖像變為原來的1/4;第3次卷積、池化后輸出圖像是原始圖像的1/8,保留本次池化后的特征圖(featureMap);然后經歷第4次卷積、池化,輸出圖像是原始圖像的1/16,同樣保留本次池化后的特征圖(featureMap);繼續進行第5次卷積、池化,輸出圖像是原始圖像的1/32;接著進行第6次卷積、第7次卷積操作,此時,輸出的圖像依然是原始圖像的1/32大小,但是featureMap數量改變了,此時的圖像稱作熱圖(heatMap)。
上述保留的熱圖通過上采樣來還原圖片,但是得到的只是第5次卷積操作的卷積核特征,精度還不夠高,所以需要繼續向前迭代,具體的操作是先使用第4次卷積中的卷積核來反卷積上一個上采樣還原圖,其實就是作差值的過程,然后用第3次卷積中的卷積核來反卷積剛剛的上采樣還原圖,實現圖像的整體還原,其中兩次反卷積都是為了補充細節。
PAM的網絡如圖4所示,使用了全卷積神經網絡的網絡結構,輸入為任意尺寸的自然圖,輸出則是與輸入圖大小相同的分類圖。采用反卷積操作對相應卷積層特征圖上采樣,在保留原始圖空間信息的同時還能夠預測每個像素,實現逐個像素的分類。采用歸一化指數函數(Softmax函數)來計算每個像素的損失,等同于一個訓練樣本對應一個像素。針對不同數據集,PAM網絡對FCN模型分別進行微調,只需要重新定義網絡的輸出類別數(保證輸出的類別數與數據集對應的密度級別種類數一致),從而輸出對應的分類圖。

圖4 PAM網絡(基于FCN結構的像素級注意掩碼生成網絡)Fig. 4 PAM network (pixel level attention mask generation network based on FCN structure)
1.3 改進的人群密度估計網絡
人群密度估計[18,25]網絡的作用是將輸入圖像轉換成密度圖。由于圖像中不同位置的人頭尺度存在很大差異,現有的方法多是采用不同卷積核大小的多列網絡來求解;然而,多列網絡往往需要更多的時間,而且難以收斂。通過實驗發現,設計合理的單列網絡不僅同樣可以得到良好的計算結果,而且還降低了計算復雜度。本文設計的單列人群密度估計網絡結構如圖5所示。
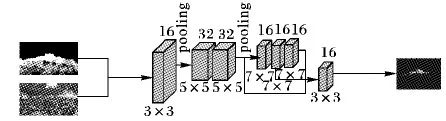
圖5 人群密度估計網絡Fig. 5 Crowd density estimation network
本文進行了大量的實驗來分析不同因素對最終結果的影響,這些因素包括深度、卷積核大小、卷積核大小順序和不同層的連接。為了與基準方法進行比較,本部分只使用原始RGB圖像作為輸入。通常,頭部較大的密度圖需要使用具有較大感受野的濾波器來提取特征,頭部較小的密度圖則應使用感受野較小的濾波器提取特征,而一般來說,合理的深層次網絡效果要優于淺層網絡。
本文的人群密度估計網絡屬于卷積神經網絡,設計思想來源于Zhang等[19]發表的多列卷積神經網絡(MCNN),本文設計的網絡如圖5所示,將MCNN并行的3列融合成單列,借鑒其卷積核大小將本文網絡參數設定如下:7層網絡并且進行PAM處理,卷積核分別為3×3、5×5、5×5、7×7、7×7、7×7、3×3(融合第3、5、6層輸出作為第7層輸入)。
每層卷積層的激活函數均采用修正線性單元(Rectified Linear Unit, ReLU):
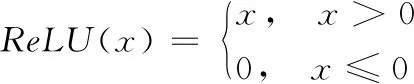
(3)
由于池化操作會丟失細節信息,所以僅在第一層和第三層卷積后設置了步長為2(stride=2)的最大池化操作;融合第3、5、6層輸出作為第7層輸入的設置,將合并的特征輸出到卷積核大小為3×3的第7層,在保證了網絡可以收斂的同時提高了網絡效果。把第3、5、6層提取的特征合并后輸出到卷積核大小為3×3的第7層卷積層,使用3×3卷積核替代1×1卷積核,可以估計出密度圖。該網絡有3個特點:
1)更深層次的單列架構。內核的大小和深度對于CNN來說是至關重要的。
2)不同層次的拼接。受文獻[14,26-27]的啟發,將低層和高層連接在一起,學習底層信息(如形狀、顏色、紋理)和語義信息。
3)卷積核大小的逆序。在本文的網絡中,小卷積核在較低的層中選擇,而大卷積核在較高的層中選擇。這種策略的優點有兩個:首先,使用反序的卷積核大小具有更大的感受野,可以獲得更多的上下文信息;其次,在合并相鄰層時,起到組合淺層和高層不同類型信息的作用,提高預測準確性。這是一個與現有的卷積神經網絡完全不同的考慮。
通過這些設計,本文的網絡與MCNN[17]和Sindagi[18]相比具有更少的參數,但得到了更好的結果。
1.4 損失函數
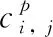
(4)
對于人群密度估計網絡模塊,采用歐幾里德損失層來測量真實值與估計密度圖之間的差異。損失函數定義如下:
(5)
其中:θ表示網絡中的可學習參數,Xi是輸入圖像,F(Xi;θ)和Fi分別為預測密度圖和真實值。
2 實驗
在4個公開的具有不同挑戰性的數據集上,將本文方法與上下文金字塔神經網絡(Contextual Pyramid Convolutional Neural Network, CP-CNN)、多列卷積神經網絡(MCNN)、交換卷積神經網絡(Switching Convolutional Neural Network, Switch-CNN)[22]、擁塞場景識別網絡(Network for Congested Scene Recognition, CSRNet)[28]、檢測和密度估計網絡(Detection and Density Estimation Network, DecideNet)[29]等方法進行了比較。這4個數據集分別是Shanghaitech數據集(包括part_A和part_B兩部分)、UCF_CC_50數據集以及WorldExpo_2010(Expo’10)數據集。有關這些數據集的數據信息詳見表1。

表1 各數據集相關信息 Tab. 1 Information about each dataset
2.1 評價指標
根據現有的人群統計工作[19,22,28],本文采用較為通用的兩個評價指標——平均絕對誤差(Mean Absolute Error, MAE)和均方誤差(Mean Squared Error, MSE),來對本文方法與現有方法的性能進行比較。MAE和MSE定義如下:
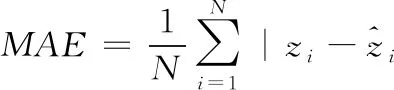
(6)
(7)
2.2 PAM模塊的閾值選取
正如在2.2節中分析的那樣,對于不同的數據集需要人為地定義合適的PAM閾值和類數,以優化性能。本文通過觀察對比根據真實值(Ground Truth)生成的密度圖對應原圖的人群密集程度,從而劃分出人群密度等級以及閾值。結果劃分如表2。圖6(a)~(d)左圖為各數據集中選取的一幅原始圖片,圖6(a)~(d)右圖為對應原始圖片經PAM分割后得到的分類圖。

表2 PAM模塊閾值劃分 Tab. 2 PAM module threshold division

圖6 各數據集經PAM所得分類圖Fig. 6 Classification map of each dataset obtained by PAM
2.3 參數設置及訓練步驟
2.3.1 參數設置
本文模型是在配置為i7- 6700K CPU、NVIDIA GTX 1080 GPU(顯卡內存為8 GB)的臺式機的Ubuntu系統下的Caffe框架下運行的。訓練過程采用隨機梯度下降法(Stochastic Gradient Descent, SGD),訓練階段的batchsize設置為1,為了提高模型的擬合速度,沖量設置為0.9,權重衰減設置為0.000 5來控制模型的過擬合。具體的模型參數設置見表3,其中base_lr為學習率,max_iter為最大迭代次數,lr_policy為學習策略。

表3 訓練參數設置 Tab. 3 Training parameter setting
2.3.2 訓練步驟
1)根據數據集的真實標注Ground Truth采用歸一化高斯核生成標簽密度圖density_map;
2)根據設定的閾值參數將density_map轉變為劃分了像素等級的掩碼標簽圖gt,采用FCN對原圖和掩碼標簽圖gt進行訓練;
3)使用訓練的FCN獲取圖像n通道標簽圖(n為該數據集劃分的密度級別數),然后與原圖(3通道)融合為n+3通道圖,作為人群密度估計網絡的輸入;
4)訓練人群密度估計網絡,使用訓練的模型來估計圖片的人群密度,采用回歸計算得到人群總數。
算法偽代碼:
Train(){
初始化network的權和閾值;
while 終止條件不滿足{
for samples中的每個訓練樣本X{
向前傳播輸入;
for 隱藏或輸出層每個單元j{
相對于前一層i,計算單元j的凈輸入;
計算單元j的輸出;
}
反向傳播誤差;
for 輸出層每個單元j{
計算誤差,選擇ReLU函數作為激活函數;
}
for network中每個權重ωij{
權重增值;
權重更新;
}
for network中每個偏差Qj{
偏差增值;
偏差更新;
}
}
}
2.4 Shanghaitech數據集
MCNN[19]中首次建立Shanghaitech數據集,數據集分為part_A和part_B兩部分:part_A的圖片總共482幅,是從互聯網上隨機收集的;而part_B的圖片總共716幅,是上海市區繁華的街道圖片。此外,part_B圖片中的人群分布相比part_A圖片中的人群分布更為稀疏。
該數據集總共有1 198幅標記圖片:part_A部分300幅用于訓練,182幅用于測試;part_B部分400幅用于訓練,316幅用于測試。具體的信息可以在MCNN[19]中找到。表4是本文方法與其他方法在Shanghaitech數據集上的結果對比。
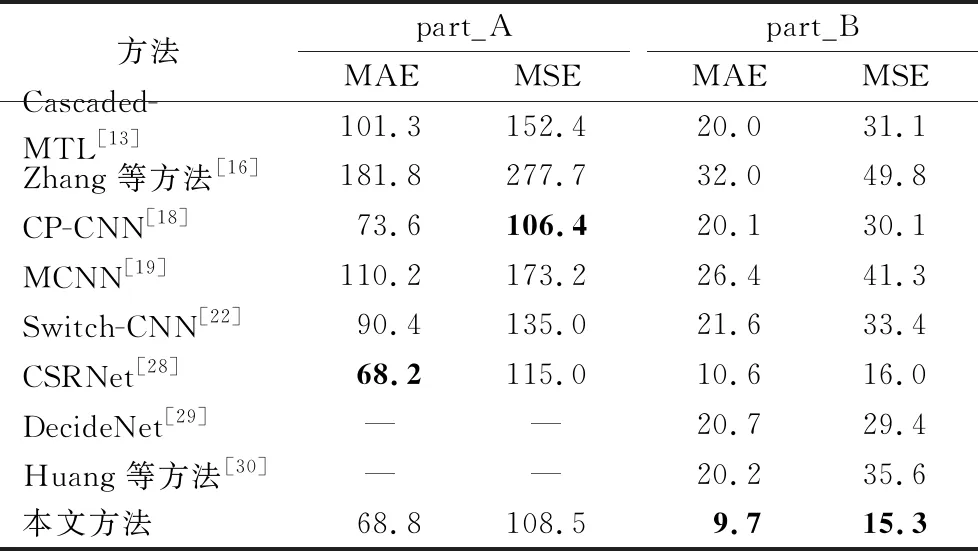
表4 Shanghaitech數據集上不同方法結果對比 Tab. 4 Comparison of results of different methods on Shanghaitech dataset
2.5 UCF_CC_50 數據集
UCF_CC_50數據集包含來自互聯網的50幅圖像。這是一個非常具有挑戰性的數據集,因為它不僅圖像數量非常有限,而且圖像的人群數量也變化巨大。人頭計數范圍在94~4 543,每幅圖像平均有1 280人。作者總共為這50幅圖像提供了63 974條標注。
本文將這50幅圖像以7∶3的比例分成訓練集和測試集。表5是本文方法與其他方法在UCF_CC_50數據集上的結果對比。
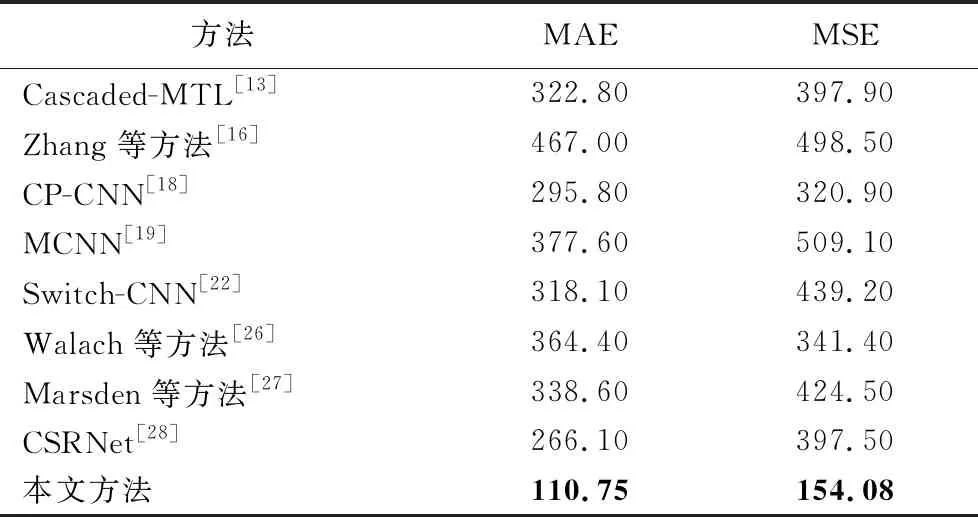
表5 UCF_CC_50數據集上不同方法的結果對比 Tab. 5 Comparison of results of different methods on UCF_CC_50 dataset
2.6 WorldExpo’10 數據集
WorldExpo’10 數據集是由Zhang等提出的[16]。該數據集包含1 132個帶注釋的視頻序列,由108個監視槍攝像機拍攝,來自于2010年舉辦的上海世界博覽會。此數據集提供了3 980幀圖像,共計199 923個行人頭部中心標注。其中3 380幀為訓練集,另外600幀為測試集,測試數據集包含5個不同場景,每個場景有120個標記幀。測試場景提供了5個不同的感興趣區域(Regions Of Interest, ROI),因此人群計數只在ROI部分進行。與其他數據集相比,該數據集人群數量相對較小,平均每個圖像有50人。表6是本文方法與其他方法在WorldExpo’10數據集上的結果對比。
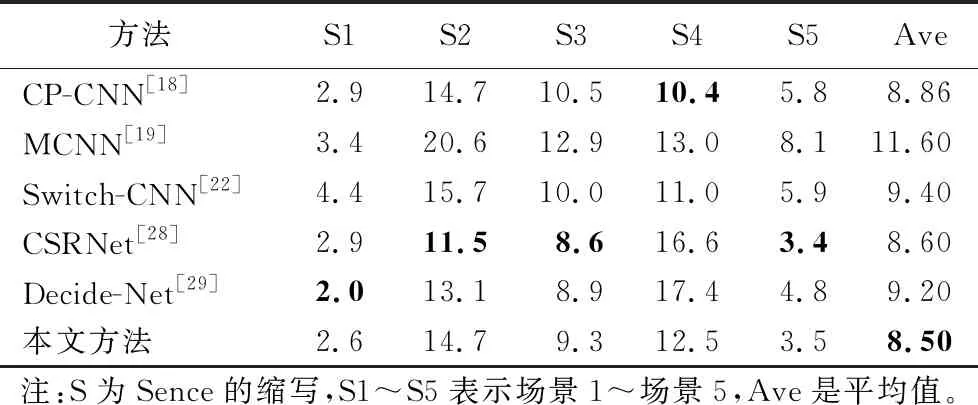
表6 Expo’10數據集上不同方法的MAE比較結果 Tab. 6 MAE comparison of different methods on Expo ’10
3 結語
人群計數的任務是準確估計出圖像中人群的總人數,同時給出人群密度的分布情況。人群計數可以用于事故預防、空間規劃、消費習慣分析和交通調度等多個領域。除此之外,圖像人群計數算法還可以應用到一些其他的計數領域,例如野生動物計數、車輛計數、細胞計數等領域,因此,人群計數的研究具有十分重要的意義。
本文提出了一種由兩個模塊生成高質量人群密度圖,達到精確的人群計數效果的新體系結構。首先,與現有的采用分塊注意機制方法相比,生成像素級掩碼并與原圖結合,能夠更精確地估計局部密度。此外,本文所采用的單列網絡與其他估計器相比,該網絡可以用更少的參數得到相似甚至更好的結果。最后,在三個高挑戰性的數據集上進行了實驗,通過對比表明本文方法具有更好的性能。
