基于條件隨機場的中醫臨床醫案癥狀命名實體抽取研究*
2020-03-13 03:09:16高佳奕謝佳東史話躍董海艷胡孔法
世界科學技術-中醫藥現代化 2020年6期
高佳奕,劉 震,楊 濤**,謝佳東,史話躍,董海艷,胡孔法
(1. 南京中醫藥大學人工智能與信息技術學院 南京 210023;2. 南京中醫藥大學第一臨床醫學院 南京 210023)
1 引言
中醫臨床信息抽取是從臨床醫案中自動抽取特定信息的計算機技術,是從海量中醫臨床數據中快速發現關鍵信息,并將其自動分類、提取和重構的過程[1],包括命名實體識別、事件抽取、關系抽取等[2]。醫案是中醫臨床診療的記錄,蘊含著中醫專家豐富的學術思想與臨床經驗,深入挖掘其中的知識對中醫的傳承與發展至關重要。然而,臨床上病情千變萬化,專家表述各具特點,使得醫案的文字表述極其復雜,這給從醫案文本信息抽取帶來挑戰[3]。因此,如何從海量中醫醫案中有效地抽取關鍵信息,挖掘其中蘊藏的辨證規律和潛在的數據價值,已經成為中醫藥研究的熱點之一。本文嘗試從醫案中最為復雜的癥狀入手,利用自然語言處理技術進行癥狀命名實體的識別和抽取,為中醫臨床文本醫案自動化處理提供參考。
2 命名實體抽取研究現狀
命名實體抽取是自然語言處理領域的重要研究內容,在機器翻譯、知識問答等領域取得了良好效果,但在醫藥領域的研究尚處于初級階段[4]。自2000年起有學者陸續將基于詞典、規則的方法應用于醫藥實體的信息抽取,如徐梓豪等[5]利用醫學專業詞典設計相關統計模型,在中文臨床病歷的命名實體識別中取得了良好效果;包小源等[6]設計定制化的規則學習及信息抽取方法,通過抽樣標注、模板重寫以及自動驗證等步驟,進一步探究了非結構化電子病例中信息抽取方法。Szekér S 等[7]提出基于文本挖掘的命名實體識別方法,實現了超聲心動圖檢查中的信息提取。基于詞典、規則的方法雖然可以提高命名實體識別率,但是在應用于特定領域時[8],現有的規則往往不可移植,仍需依靠人工編寫,過長建設周期使得它們的可行性較低。
自動內容抽取(Automatic Content Extraction,ACE)評測會議從多種角度對信息抽取進行了探索,在ACE 會議的推動下,其研究深度和廣度也在不斷加強[9]。近年來,一些學者嘗試利用統計學習方法進行命名實體抽取,如Liu 等[10]應用支持向量機(Support Vector Machines,SVM)的分類模型,將醫學實體之間的語義關系分類為相應的語義關系類型并抽取出語義關系三元組;馬民艷等[11]基于單分類器的生物醫學命名實體識別,采用最大熵算法(Maximum Entropy,ME)和條件隨機場算法(Conditional Random Field,CRF),對Yapex 語料中的蛋白質名稱進行了識別;劉凱等[12]基于CRF 探究中醫病歷命名的實體抽取方法,提出利用Bubble-Bootstrapping 算法、前向最大匹配算法和手工標注相結合的方式構建中醫語料庫,其中表現最好的命名實體抽取的F1值為癥狀0.80,疾病名稱0.74,誘因0.63;王世昆等[13]通過比較CRF、SVM 和ME算法在中醫古代醫案中的癥狀與發病機制上的實體識別表現,發現CRF 更具優勢,其中CRF 的準確率87.16%,ME 的準確率為83.88%,SVM 的準確率僅為81.92%。袁玉虎等[14]應用CRFs 模型對中醫現病史中的癥狀術語進行實體抽取,發現CRFs 模型在癥狀術語的序列標注任務中表現良好。上述研究在醫藥信息抽取上作出了有益探索,但在中醫臨床復雜癥狀的命名實體識別和處理的研究較少。從研究方法來看,基于CRF 及其改進方法的應用逐漸成為當前命名實體識別研究的重要方向。
條件隨機場是用來標注和劃分序列結構數據的概率化結構模型[15]。其通過隱含變量的馬爾科夫鏈Y ={y1,y2,…,yn} 和可觀測狀態的隱含變量X ={x1,x2,…,xn}的條件概率P(Y|X)來描述模型[4]。測試集語料標簽的類別標記即為隱含變量,訓練集的語料特征即為可觀測狀態,條件隨機場通過可觀測的語料特征推斷每個標簽應有的類別標記。本文嘗試將CRF應用到中醫臨床醫案數據處理中,構建中醫癥狀命名實體抽取模型,探究CRF 在中醫癥狀命名實體識別上的效果,為中醫臨床復雜文本的信息抽取提供參考。
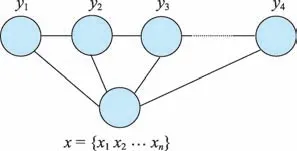
圖1 CRF鏈式結構圖
3 研究方法
3.1 中醫醫案CRF模型設計
設G = V,E 為一個無向圖,V 表示癥狀結點集合,E 為癥狀與癥狀之間的無向邊集合。V 中每個癥狀結點與對應一個隨機變量Yv,設其取值范圍為標識集合Y,即Y ={yv|v ∈V }。如果以觀測序列X 為條件,每一個隨機變量Yv都滿足以下馬爾可夫性[16]:
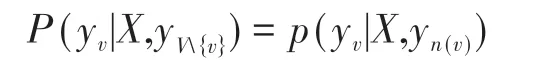
則(X,Y)構成一個條件隨機場。其中n(v)表示結點v的所有相鄰結點,即V{v} = V -{v},換而言之,yv僅與結點v 鄰接的結點相關。其中X,Y 的CRF 鏈式結構圖如圖1所示。
在條件隨機場中,我們定義一組關于觀測序列{0,1}二值特征b(X,i)來表示訓練樣本中癥狀的分布特性,如:
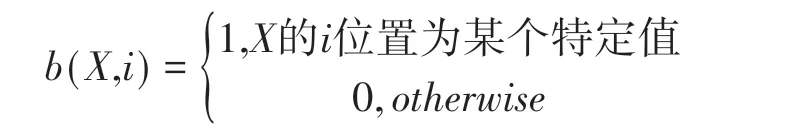
轉移函數定義為如下形式:
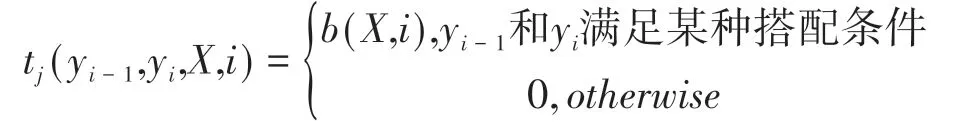
這樣,特征函數可以統一表示為:
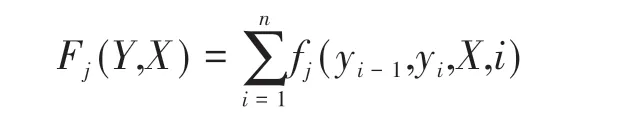
其中,每個局部特征函數fj(yi-1,yi,X,i)表示狀態特征sk(yi-1,yi,X,i)或轉移函數為tj(yi-1,yi,X,i)。
由此,中醫臨床醫案CRF 的條件概率可以由下式給出,其中Z(X)為歸一化參數:
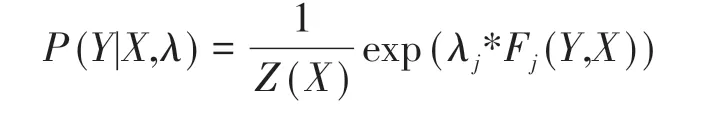
3.2 中醫醫案CRF的訓練流程
如圖2 所示,模型訓練需輸入標注語料的模板序列。標注語料的模板序列存儲了語料庫中每一個語料標簽的類別特征,其中語料標簽可以采用基于字的標注方法,也可以基于詞進行標注。考慮到中醫臨床術語大多按詞出現,按字劃分會損失中醫術語本身包含的豐富信息特征[17],因此本文利用基于詞的標注方法,采用BIO(B-begin,I-inside,O-outside)標注方法對數據進行標注處理[18],B-X 表示此元素所在的片段屬于X 類型并且位于詞首,I-X 表示此元素所在的片段屬于X 類型并且位于非詞首,O 表示此元不屬于任何實體類型,其輸入格式如下:
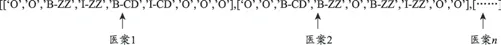
特征的選擇是影響條件隨機場模型訓練結果的關鍵因素。訓練語料的特征應囊括語料標簽的詞語特征、詞位特征、上下文窗口特征等信息,本文選擇詞語標記、實體前后詞語為主要特征,其輸入格式如下:

4 實驗及結果分析
4.1 數據來源
實驗數據來源于江蘇省中醫院病案庫和國醫大師周仲瑛工作室,均為名老中醫治療肺癌的臨床病案。設定病案納入和排除標準,具體如下:
納入標準:①病案中明確記載診斷為肺癌的患者;②就診時的主訴辨治是以肺癌為主者;③數據完整,至少包含臨床表現、病機分析和治法、用藥等內容者。
排除標準:①其它系統癌癥轉移到肺臟患者,為非原發性肺癌如復發癌或者轉移性腫瘤;②就診時主訴辨治不是以肺癌為主者;③病案記錄存在明確錯誤或缺失。
根據設定的病案納入標準和排除標準對病案數據進行篩選,最終選擇1000 份高質量病案進行研究,圍繞病史進行癥狀命名實體識別。病史信息格式如下:“起病有胸悶,今年四月出現咳嗽,咳吐粘痰,痰色黃膿化療后轉為白粘,咳則胸痛,血象底下目前氣短乏力,胸悶,納差,大便1~2日一行,口干苦,飲水不多,體重下降8 斤,兼有低熱,痰中血少,面色少華,貧血貌。”

圖2 CRF命名實體識別流程
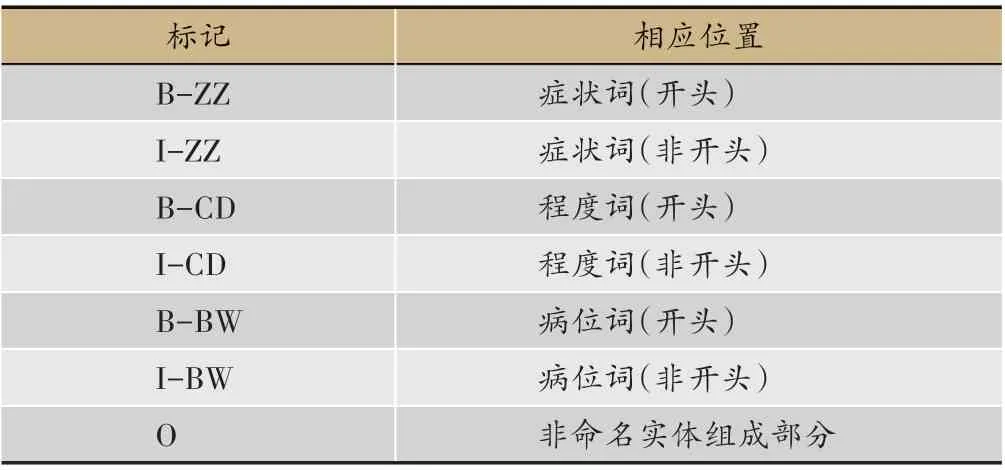
表1 命名實體標注方法
4.2 數據預處理
我們將數據集中的實體類型分為三類:癥狀(名)、(癥狀)程度、(癥狀發生)部位,代碼分別為ZZ、CD、BW。利用BIO 三元集標注方法進行標注,具體的標注方法如表1所示。
依照BIO 標注方法,上述臨床肺癌的原始病案可標注為:“起/O 病/O 有/O 胸/B-BW 悶/B-ZZ,今/O 年/O四/O 月/O 出/O 現/O 咳/B-ZZ 嗽/I-ZZ,/O 咳/B-ZZ 吐/IZZ 粘/I-ZZ 痰/I-ZZ,/O 痰/B-ZZ 色/I-ZZ 黃/I-ZZ 膿/IZZ,/O 化/O 療/O 后/O 轉/O 為/O 白/O 粘/O,/O 咳/B-ZZ則/O 胸/B-BW 痛/B-ZZ,/O 血/O 象/O 低/B-CD 下/ICD,/O 目/O 前/O 氣/B-ZZ 短/I-ZZ 乏/B-ZZ 力/I-ZZ,/O胸/B-BW 悶/B-ZZ,/O 納/B-ZZ 差I-ZZ,/O 大/O 便/O1/O~/O2/O 日/O 一/O 行/O,/O 口/B-BW 干/B-ZZ 苦/BZZ,/O 飲/O 水/O 不/B-CD 多/I-CD,/O 體/O 重/O 下/BCD降/I-CD8/I-CD斤/I-CD,/O兼/O有/O低/B-ZZ熱/IZZ,/O 痰/B-ZZ 中/I-ZZ 血/I-ZZ 少/I-ZZ,/O 面/B-BW色/I-BW 少/B-ZZ 華/I-ZZ,/O 貧/B-ZZ 血/I-ZZ 貌/O。/O”。
4.3 模型構建
(1)提取1000條病歷中80%的病歷文本作為訓練集,20%的病歷文本作為測試集。
(2)根據語料特征構建特征模板。
(3)建立CRF 模型,采用十折交叉驗證對模型效果進行測試。利用sklearn_crfsuite 開源包構建CRF模型。
(4)利用多分類評價指標對此模型進行評測。
模型建立的步驟如下:
條件隨機場模型
輸入:訓練集T(800條病案)的特征序列及標注序列,測試樣本t(200條病案)的標注序列。
輸出:各標記標簽的P、R、F1 值及Macro-averag?ing、Micro-averaging值。
步驟1:根據T 的特征序列Tfea和標注序列Tsig,訓練模型。

步驟2:根據測試樣本t的標簽特征序列預測標注序列tpre。
tpre= crf.predict(te_content)
步驟3:通過比較tpre與測試樣本t 的標注序列tsig,得出多分類評測指標值。
4.4 模型評價
為了評估CRF 在中醫臨床醫案中實現癥狀實體識別策略的可行性和其在癥狀實體抽取上的性能,本文使用準確率(Precision,簡記為P),召回率(Recall,簡記為R)和F1-測度值(F1-measure,簡記為F1)3 個指標來衡量:

計算F 值時,一般取(β = 1),因此,以上公式可修改為:
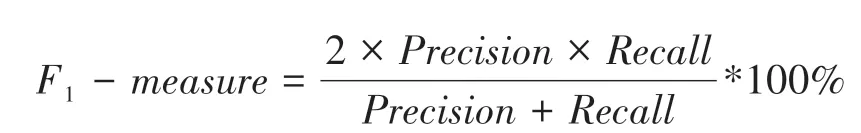
如圖3 所示,準確率的實際意義為模型正確識別的標簽數與模型識別的標簽總數的比值,召回率的實際意義為模型正確識別的標簽數與各類別中所有標簽數的比值。
考慮到中醫文本的分類并非單純的二分類,需要在不同類別下綜合考察分類器的優劣,此處引入宏平均(Macro-averaging)、微平均(Micro-averaging)對訓練結果做出進一步評估。宏平均是計算每一個類別的評測指標值,再對所有類別的評測指標值取算術平均。宏平均定義式如下:
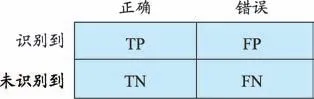
圖3 評價指標
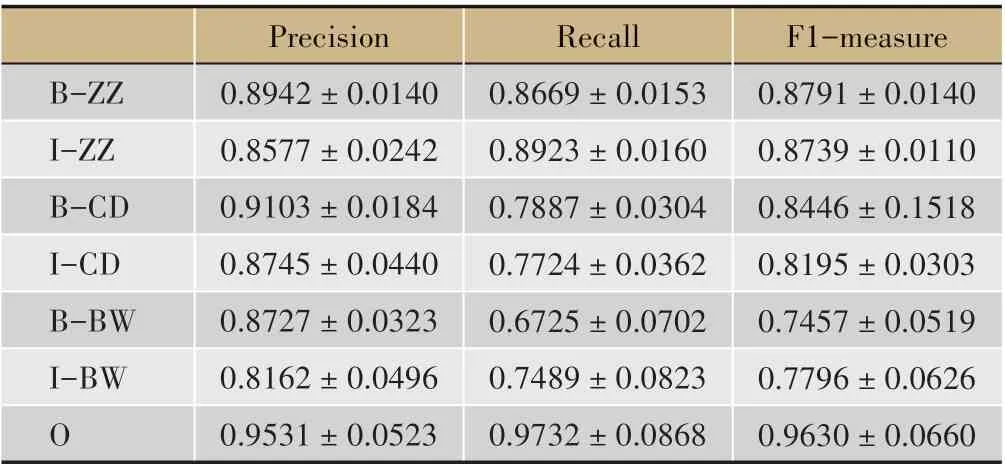
表2 十折交叉驗證結果(均值± 標準差)
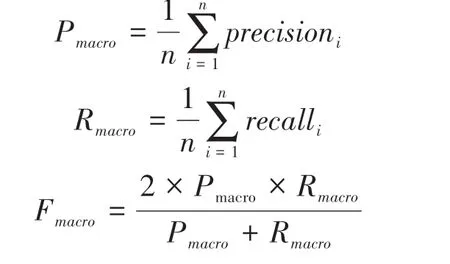
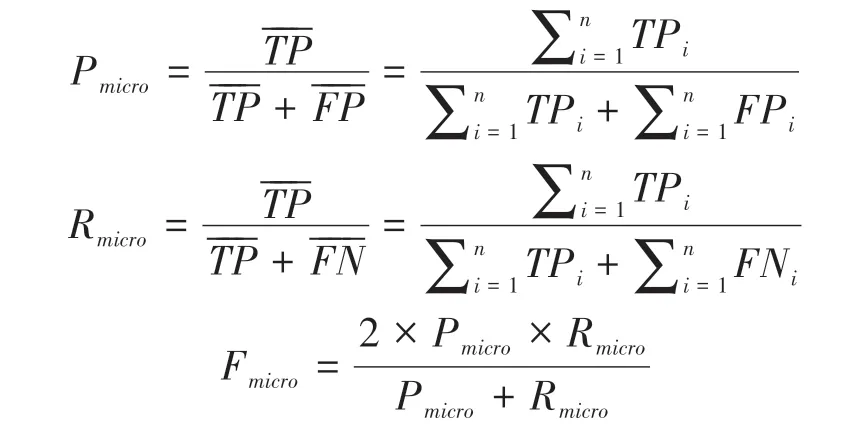
微平均是對數據集中的每一個標簽不分類別進行統計建立全局混淆矩陣,進而計算相應的指標[19]。微平均定義式如下:
4.5 實驗結果
本文采用十折交叉驗證對模型進行訓練和測試,觀察模型對癥狀、程度、病位實體的識別情況,排除非命名實體組成部分,結果顯示模型對癥狀詞的識別精度最高,而對病位詞的識別精度最低(詳見表2)。
從十折交叉驗證的結果來看,宏平均的三個評測指標(P,R,F1)為(0.8822,0.8322,0.8556),上下波動均小于0.022;微平均的三個評測指標為(0.9233,0.9222,0.9211),上下波動均小于0.007,微平均效果優于宏平均效果(詳見表3)。每一折下各個評價指標的變化情況如圖4~圖6所示。

表3 十折交叉驗證結果(均值± 標準差)
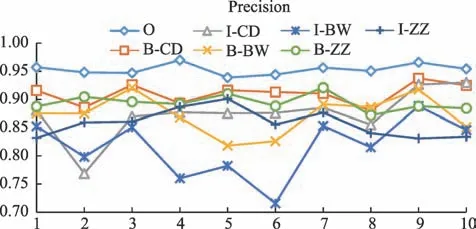
圖4 評價指標折線圖
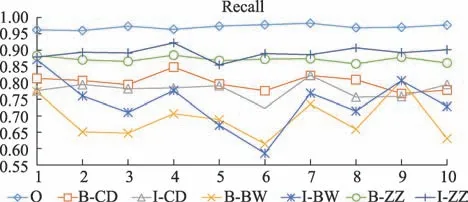
圖5 評價指標折線圖
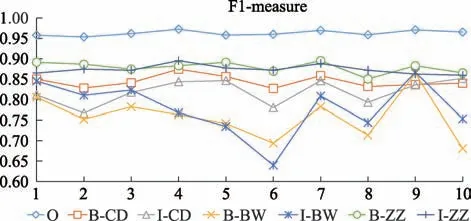
圖6 評價指標折線圖
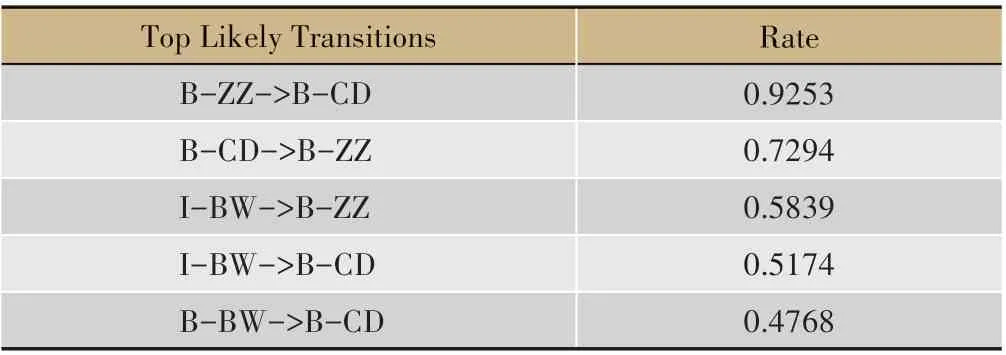
表4 實體標簽中的可能傳遞方式
考慮到不同標簽間的傳遞方式具有方向性,為了進一步查看模型內部的運行機制,本文將各實體標簽的可能的傳遞方式以及標簽傳遞權重進行了分析(詳見表4~表5)。
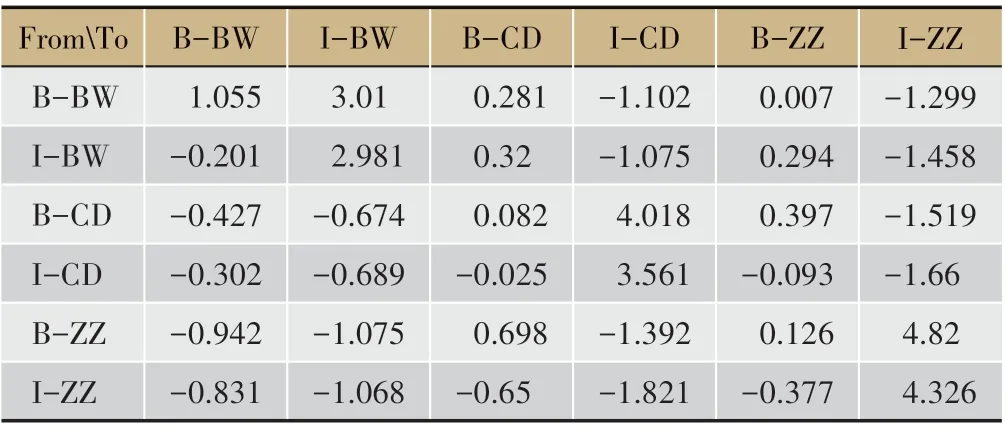
表5 各實體標簽傳遞方式的權重值
深入挖掘各實體標簽和相應語料的關系,分析模型內部各個標簽特征的權重,進而為模型解釋提供支撐,本文對每個標簽中權重較高的語料特征進行分析,分析結果詳見表6。
為了增強類別特征,本文采用不同的窗口大小,對模型再次進行測試,不同窗口下的宏平均評測指標值如表7所示。
4.6 結果分析和討論
本文提出了基于條件隨機場的中醫臨床復雜癥狀的命名實體識別方法,對中醫臨床數據進行實驗,模型宏平均的評測指標(P,R,F1)為(0.8822,0.8322,0.8556),上下波動小于0.022;微平均的評測指標為(0.9233,0.9222,0.9211),上下波動小于0.007(詳見表2~表3、圖4~圖6),實驗結果顯示微平均的效果優于宏平均。從微平均和宏平均的實際意義進行分析,微平均實際反應的是預測正確的樣本數與輸入分類器的預測樣本數的比值,而宏平均是將每個類別標記分開考慮,計算單獨每個類別的正確率,反映的是每個類別標記正確率的算數平均值,因此小樣本預測正確率低的情況對宏平均的影響較大。在本文采用的肺癌病例語料中,I-BW 和B-BW 均屬于小樣本,僅1119和1382 處,相比之下,B-ZZ 和I-ZZ 的樣本數目較大,有7201 和11268 處,據圖4~圖6 也可以觀察到I-BW和B-BW 的P、R、F1 值普遍偏低,這就對十折交叉驗證的結果產生了影響,使得微平均的評測值優于宏平均;就標簽的識別效果而言,癥狀詞的識別效果較好,部位詞的識別效果較差,因為癥狀詞的訓練樣本數較多,類別特征相對明顯,而部位詞因為訓練樣本數過少,類別特征不明顯,又常常和癥狀交叉混淆,如“胸悶胸痛”被識別為“B-ZZ/I-ZZ/B-ZZ/I-ZZ”,這就導致了二者識別效果差異較大。
通過深入挖掘不同標簽間的傳遞方式,我們發現癥狀詞與程度詞間的關聯度最高,即癥狀詞前后出現程度詞的可能性最大,其傳遞可能性高達0.9253。病位與其他標簽間的關聯性相對較弱,多呈現病位->癥狀,病位->程度這兩種共現方式(詳見表4~表5)。考慮到中醫臨床醫案中往往以癥狀來描述部位的病變情況,以程度來形容部位的病變輕重,如“咯B-ZZ 痰I-ZZ 不B-CD 多I-CD”、“胸B-BW 不B-CD 悶BZZ”等,該分析結果與中醫醫案的陳述方式基本相符。深入分析實體標簽和相應語料之間的權重,我們發現‘,’,‘、’等符號以及“但”、“仍”等語句連接詞已被模型學習為非實體組成部分;病位多與“背”、“胸”、“口”、“腰”、“鼻”等詞相關,其中“背”與病位的關聯度最高;癥狀多與“咳”、“痛”、“痰”、“酸”、“悶”、“血”等詞相關,其中“咳”與癥狀的關聯度最高(詳見表6)。從中醫理論出發探尋數據背后的辨證知識,肺居胸中,左右各一,癌毒侵襲肺臟,往往出現 胸痛、背痛等癥,正如《靈樞.邪氣臟腑病形》所言:“肺脈……微熱為肺寒熱,怠惰,咳唾血,引腰背胸”;肺開竅于鼻,且肺為儲痰之器,氣機不利,外邪乘之,津聚為痰,痰瘀阻肺,則口鼻多痰;肺主氣,司呼吸,肺失宣降,氣滯于胸則出現咳嗽、胸悶等癥。如《雜病源流犀燭》云:“邪居胸中,阻塞氣道,氣不得通,為痰,為食,為血,皆邪正相搏,邪勝,正不得制之,遂結成形而有塊。”從上述結果可以看出,CRF 實體標簽的學習結果與中醫對肺癌的認識基本一致,因而可以將CRF 應用于中醫臨床復雜癥狀的命名實體識別。
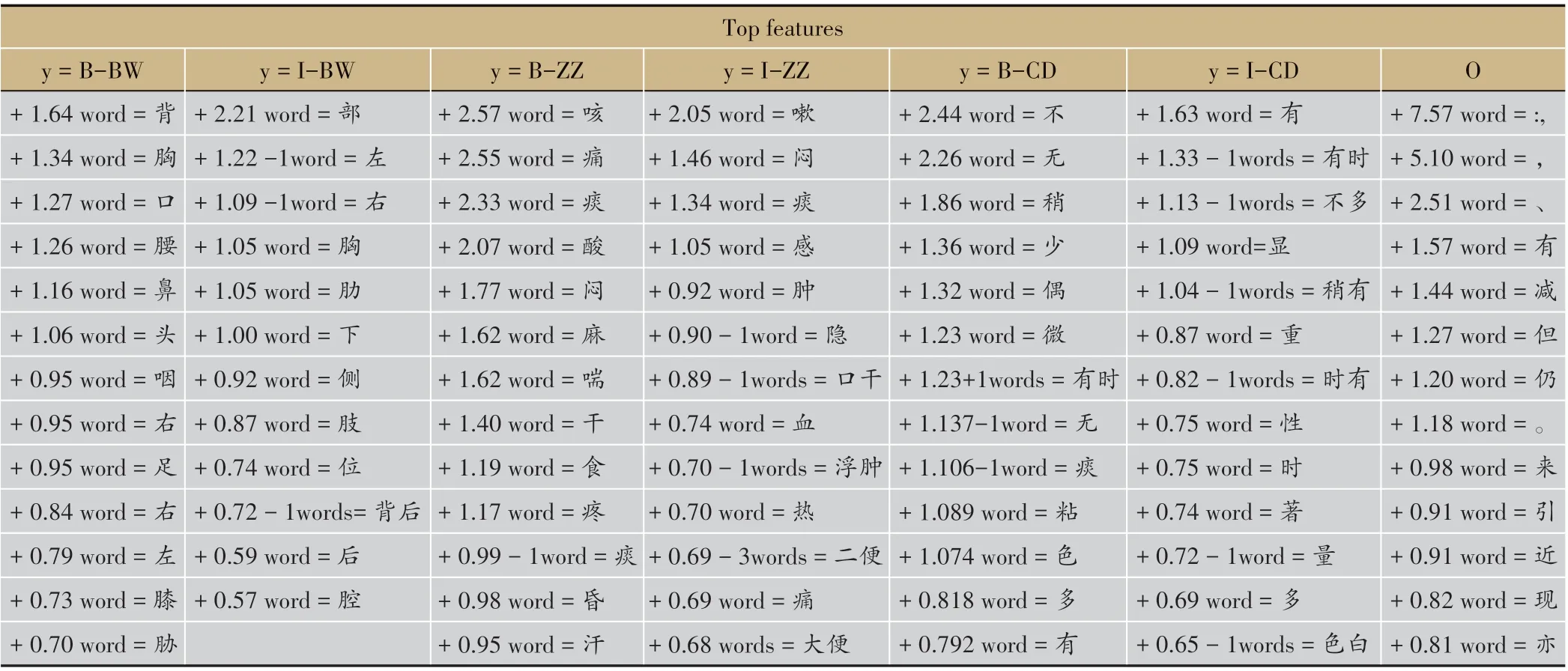
表6 標簽特征
通過改變窗口大小來進一步探索類別特征對于實驗結果的影響。當窗口大小為5 時,宏平均的P、R、F1 值最高,較窗口大小為3 時分別提高了0.47%、1.35%和2.50%,較窗口大小為7時分別提高了2.56%、4.15%和2.65%(詳見表7)。考慮到過大的訓練窗口不僅使訓練的復雜度增加,而且容易產生噪音影響最終的評測結果;較小的窗口難以反應上下文關系,會損失語料間的豐富信息,當窗口為5時,能夠恰好反應上下文關系且不會產生過多噪音。從整體上觀察,窗口大小對于評測指標的影響并不大,樣本集中的標簽分布不均衡對評測結果產生了決定性影響。因此,本研究后續將把重點將放在對樣本集進行擴充和篩選,平衡各個類別,提高宏平均指標。
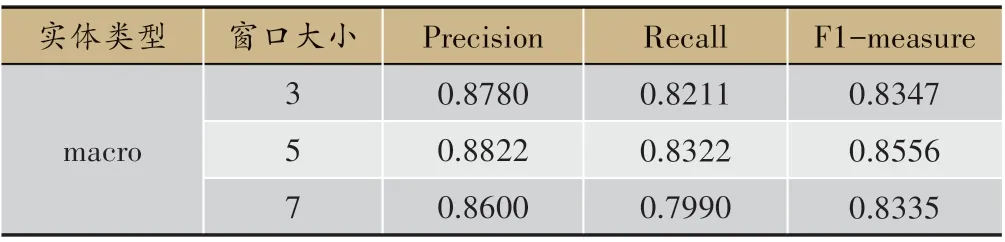
表7 窗口大小對宏平均評測指標的影響
5 結語
在中醫臨床的診療過程中,復雜多變的中醫臨床癥狀和表達形式獨特的中醫專業術語給中醫臨床的信息抽取帶來了極大挑戰。本文通過分析中醫醫案信息抽取的重要意義,對中醫領域的信息抽取現狀進行思考,提出了將CRF 模型應用于中醫癥狀的命名實體抽取。從已標記過的肺癌病歷語料庫入手,構造基于CRF 的中醫臨床醫案癥狀命名實體抽取模型,采用十折交叉驗證對模型結果進行測試,利用多分類評價指標對模型進行評價,證實了CRF 模型在中醫臨床癥狀的命名實體識別中的性能較好,可以有效的實現中醫文本的信息抽取。“中醫之功,醫案最著”,中醫臨床醫案是輔助中醫進行辨證用藥的基礎,抽取名老中醫臨床醫案的有效信息,是中醫藥發展的基礎,也是歷史賦予我們的重任。將CRF 模型應用到中醫臨床癥狀的命名實體抽取領域,可以為中醫臨床工作者提供更便捷有效的信息抽取工具,提高中醫臨床醫案的研究效率,為中醫藥信息抽取提供方法學參考。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
初中生學習指導·提升版(2023年8期)2023-09-12 10:26:19
保健醫苑(2022年1期)2022-08-30 08:39:40
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
基層中醫藥(2020年10期)2020-02-13 15:45:52
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
光學精密工程(2016年6期)2016-11-07 09:07:19
