基于改進(jìn)的免疫遺傳的選擇性隨機(jī)森林優(yōu)化算法及應(yīng)用
2020-03-16 02:31:46劉林慧
電子技術(shù)與軟件工程 2020年24期
關(guān)鍵詞:優(yōu)化
劉林慧
(黑龍江工業(yè)學(xué)院 黑龍江省雞西市 158100)
1 算法
1.1 選擇性集成
集成學(xué)習(xí)就是通過集成很多個學(xué)習(xí)器來完成學(xué)習(xí)任務(wù),通常集成學(xué)習(xí)得到的結(jié)果比單個學(xué)習(xí)器得到的結(jié)果更加準(zhǔn)確。而選擇性集成[1]是指在現(xiàn)有的集成學(xué)習(xí)的學(xué)習(xí)器中,剔除掉一部分作用不大或者是起反作用的學(xué)習(xí)器,使得結(jié)果更加準(zhǔn)確的一種算法。
1.2 免疫遺傳算法
免疫算法[2]是一種仿生智能算法。相比于其他仿生智能優(yōu)化算法,免疫算法有很多優(yōu)點,如全局收斂性、種群多樣性等。免疫遺傳算法[3]是免疫算法中的一類,也是遺傳算法的改進(jìn)算法。
1.3 隨機(jī)森林
隨機(jī)森林[4][5][6]是一種集成學(xué)習(xí)算法,隨機(jī)森林的每個學(xué)習(xí)器是決策樹。通常隨機(jī)森林與決策樹相比,有更低的泛化誤差。
2 初始種群生成方式的改進(jìn)
基因空間均勻分布策略[7]的主要思想就是突變其中占比高的基因,讓所有的基因都最大限度的均勻分布在編碼空間中,達(dá)到使初始種群多樣化的目的。
將基因空間均勻分布策略的思想用在隨機(jī)森林子集優(yōu)化中,為了保證每棵樹在種群中是均勻分布的。優(yōu)先突變的抗體應(yīng)符合如下條件:
(1)抗體濃度高的抗體。
(2)種群中樹的列表值重復(fù)的抗體。
抗體i 的第k 位基因突變方式如下:
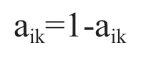
以表1 所示的原始基因為例,按照隨機(jī)森林問題下的基因分布均勻策略的原則對基因進(jìn)行突變,改進(jìn)前后抗體濃度對比結(jié)果如表2。
從實驗結(jié)果可以看出,新生成的初始種群有更低濃度,說明抗體之間的相似度大大降低;樹的總和中有更多的組合值出現(xiàn),說明改進(jìn)的方法很好的增加了初始種群的多樣性。
因此,隨機(jī)森林問題下基因空間均勻分布策略的算法如算法1。
算法1: 隨機(jī)森林問題下基因空間均勻分布策略

隨機(jī)森林問題下基因空間均勻分布策略輸入:隨機(jī)產(chǎn)生的初始種群過程:1.生成抗體濃度列表、種群中樹的列表和基因為0 的分布列表2.For 檢測種群中每一基因位的組成{

表1:原始基因分布表

圖1:UCI 數(shù)據(jù)集上免疫遺傳、改進(jìn)免疫遺傳的適應(yīng)度函數(shù)值折線對比圖

3.If 某基因在該位所占比例大于平均值4.Then 把這種基因變異成在該位所占比例最低5. 遍歷抗體濃度列表和樹的列表6. 優(yōu)先選擇抗體濃度高且樹的列表有所重復(fù)的位的基因 的基因}抗體,突變該基因7. 更新抗體濃度列表和種群中樹的列表輸出:經(jīng)空間均勻分布策略處理后的新的初始種群
3 新方法在優(yōu)化隨機(jī)森林問題中的有效性檢驗

表2:改進(jìn)前后基因為0 的抗體濃度對比表

表3:數(shù)據(jù)形式表

表4:優(yōu)化前后模型泛化誤差表
從圖1 可以看出,針對隨機(jī)森林優(yōu)化問題改進(jìn)的免疫遺傳算法每次搜索的效率更高,且更快收斂,說明改進(jìn)的初始種群的生成方式可以用來優(yōu)化隨機(jī)森林子集。
4 基于改進(jìn)的免疫遺傳的選擇性隨機(jī)森林優(yōu)化算法
綜上,基于改進(jìn)的免疫遺傳的選擇性隨機(jī)森林優(yōu)化算法如算法2。
算法2:基于改進(jìn)的免疫遺傳的選擇性隨機(jī)森林優(yōu)化算法基于改進(jìn)的免疫遺傳的選擇性隨機(jī)森林優(yōu)化算法

輸入:數(shù)據(jù)集、隨機(jī)森林、迭代次數(shù)、適應(yīng)度函數(shù)、相似度閾值、變異算子、交叉算子過程:1.For i in range(迭代次數(shù)):2. If i 為1:3. 使用空間均勻分布策略生成初始種群4.else:5. images/BZ_155_309_2093_388_2163.png過選擇、交叉、變異之后的種群,再隨機(jī)生成一部分新種群6. 將種群解碼,解碼的值為樹的平均精度、樹的殘差相關(guān)度以及森林規(guī)模組成的矩陣7. 將解碼的值代入到適應(yīng)度函數(shù)中,求解適應(yīng)度函數(shù)的值8.將適應(yīng)度最大的值所對應(yīng)的二進(jìn)制串作為最優(yōu)的子集輸出9.使用得到的隨機(jī)森林最優(yōu)子集進(jìn)行預(yù)測輸出:預(yù)測結(jié)果
5 實驗
在實驗部分本文仍然從上述UCI 數(shù)據(jù)集上選取一組數(shù)據(jù),共包含8 個屬性,一個因變量。使用基于改進(jìn)的免疫遺傳的選擇性隨機(jī)森林優(yōu)化算法對其進(jìn)行預(yù)測。數(shù)據(jù)形式如表3。
將數(shù)據(jù)集進(jìn)行拆分,選取75%的數(shù)據(jù)作為訓(xùn)練集,25%的數(shù)據(jù)作為測試集進(jìn)行預(yù)測。
本實驗?zāi)繕?biāo)函數(shù)設(shè)定同上,其中隨機(jī)森林的規(guī)模設(shè)為100,迭代次數(shù)為設(shè)為100,種群個數(shù)設(shè)為50,變異算子設(shè)為0.1,交叉算子設(shè)為0.8,相似度閾值設(shè)為0.5,使用改進(jìn)的免疫遺傳算法優(yōu)化隨機(jī)森林,最終得到的優(yōu)化前后的模型的泛化誤差和森林規(guī)模如表4。
優(yōu)化后森林的規(guī)模從原來100 棵樹壓縮到了40 棵樹,壓縮率達(dá)到了60%,且有更低的泛化誤差。
6 總結(jié)
傳統(tǒng)的免疫遺傳算法存在種群多樣性差,搜索效率低,容易陷入局部最優(yōu)等問題,為解決該問題,本文提出一種基于基因空間均勻分布策略的初始種群生成方法,針對優(yōu)化隨機(jī)森林子集問題隨機(jī)生成初始種群,增加種群多樣性,提高算法運(yùn)行效率。本文在UCI數(shù)據(jù)集上對其進(jìn)行驗證,發(fā)現(xiàn)針對隨機(jī)森林子集優(yōu)化問題改進(jìn)的免疫遺傳算法每次搜索的效率更高,且更快收斂。
本文旨在建立一個基于改進(jìn)的選擇性隨機(jī)森林優(yōu)化模型,在縮減森林規(guī)模的同時,降低模型的泛化誤差。從本文的實驗結(jié)果來看,森林規(guī)模能夠縮減至一半,但模型的泛化誤差降低的不多,下一步應(yīng)繼續(xù)對模型進(jìn)行改進(jìn),提高模型預(yù)測的準(zhǔn)確率。
猜你喜歡
房地產(chǎn)導(dǎo)刊(2022年5期)2022-06-01 06:20:14
能源工程(2022年1期)2022-03-29 01:06:28
建材發(fā)展導(dǎo)向(2021年12期)2021-07-22 08:06:48
建材發(fā)展導(dǎo)向(2021年7期)2021-07-16 07:07:52
中學(xué)生數(shù)理化(高中版.高二數(shù)學(xué))(2021年12期)2021-04-26 07:43:48
中學(xué)生數(shù)理化(高中版.高考數(shù)學(xué))(2021年12期)2021-03-08 01:28:50
今日農(nóng)業(yè)(2020年16期)2020-12-14 15:04:59
消費導(dǎo)刊(2018年8期)2018-05-25 13:20:08
家庭影院技術(shù)(2018年4期)2018-05-09 07:07:41
電子制作(2017年20期)2017-04-26 06:57:45
