基于變長時間間隔LSTM方法的胎兒異常體重預測①
2020-03-18 07:54:32張碩彥吳英飛袁貞明胡文勝
計算機系統應用 2020年3期
關鍵詞:模型
張碩彥,吳英飛,袁貞明,盧 莎,胡文勝
1(杭州師范大學 杭州國際服務工程學院,杭州 311121)
2(杭州市婦產科醫院,杭州 310008)
1 介紹
預測胎兒體重是產前監護的重要內容,是醫生對孕婦進行臨床處理的重要依據.近年來研究顯示,低體重兒的存活率和扛感染能力相對低下[1],并且與低智商有密切聯系[2].而巨大兒則會引起胎兒宮內窘迫、新生兒窒息、肩難產[3,4]等.產前預測胎兒體重,對于避免新生兒體重異常,恰當選擇分娩方式具有重要意義.孕婦的產前體檢記錄屬于特殊的電子病歷.圍產醫學規定的產前體檢、孕婦個人的健康狀況和高危妊娠的隨訪等使得孕婦的體檢次數和體檢時間間隔各不相同.因而造成了體檢事件在妊娠時間上的不均勻時間間隔分布.圖1 是孕婦產前體檢示意圖.矩形表示妊娠起點,3 個圓點表示孕婦的前3 次產前體檢記錄,倒三角表示分娩.以上事件以時間順序在數軸上從左往右排列,事件之間的距離大小表示時間間隔的長短.妊娠時間用ΔTk表示,相鄰兩次體檢之間的時間間隔用 Δtk表示(k=1,2,3,···,N).孕婦每次體檢的時間間隔不僅與妊娠時間有關,而且與相鄰兩次體檢之間的時間間隔有密切聯系.傳統的RNN 和LSTM 模型默認序列之間是相等時間間隔的,以序列的先后順序表示時間信息,在模型層面并沒有時間概念,難以充分有效地表征數據不均勻時間間隔的關系.基于以上,本研究從模型層面出發,將妊娠時間 ΔT和間隔時間 Δt做嵌入表示,在LSTM 模型中的“遺忘門”和“記憶門”分別增添“時間門”,模型以“時間門控”的方式控制“狀態”信息,間接表征不均勻時間間隔信息.文章安排如下:第1 部分介紹,闡明胎兒體重預測的意義和孕婦的體檢事件分布特點,第2 部分相關工作,闡述目前胎兒體重預測任務的主流方法和不足,以及深度學習在電子病歷中的應用.第3 部分是任務定義和模型介紹,第4 部分是數據預處理和實驗設計,第5 部分是實驗結果和討論,最后部分是結論.
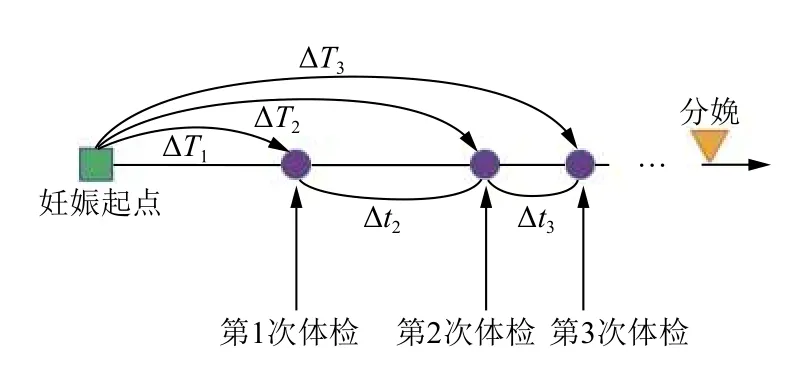
圖1 孕婦產前體檢記錄分布示意圖
2 相關工作
在臨床工作中,產科醫生經常采用宮高腹圍測量法[5-8]和超聲測量法[9,10]估算胎兒體重.兩者根據孕婦的檢查數據為參數,通過公式來估計胎兒體重.宮高腹圍法簡單快捷無副作用,孕婦可在家中自行測量.超聲法則以其更精確的優點成為目前應用最廣泛的方法.但是,這兩種方法均存在不同的弊端.首先,由于產科工作的特殊性,在一些緊急情況下不能及時為孕婦完成超聲檢查,此時使用宮高腹圍法便成為一個很好的選擇.超聲法是目前較為準確的測量方法,但是,多次做超聲檢查是否有副作用存在爭議,一般情況下,孕婦產前的超聲檢查僅為3-4 次.除以上兩種公式估算方法外,機器學習方法也可以將孕婦的宮高、腹圍,胎兒的雙頂徑、頭圍、腹圍、股骨長等數據為參數預測胎兒體重,在刁曉娣等的研究中[11],使用人工神經網絡預測胎兒體重,Xu ZP 等[12]在人工神經網絡中添加了正則化條件來預測胎兒體重.雖然,機器學習方法已應用到胎兒體重預測任務中,但是其方法大多為人工神經網絡,不同的研究雖對人工神經網絡有不同的修改,但其本質仍舊是MLP(多層感知機).無論是宮高腹圍法、超聲測量法還是經典機器學習方法,僅取孕婦分娩前一周內的數據作為估算或預測參數,而忽略了孕婦在多次體檢記錄中反映出來的變化.其次,在胎兒體重預測的研究中,尚未將孕婦的高危妊娠和疾病信息考慮進去.因此,此類研究不具有普適性.
3 變長時間間隔LSTM 模型
孕婦在孕周時間上的體檢統計分布如圖2 所示,橫軸表示妊娠周,深色的小矩形表示孕婦在對應的妊娠周做了體檢,每一橫行表示孕婦體檢周的一種統計分布,縱軸表示每一種統計分布的人數.例如,孕婦a 的體檢時間周是序列[16,20,24,28,30,32,34,35,36,37,38,39],序列中的每一項是做體檢的妊娠周,這串序列為一種體檢周統計分布,假設孕婦b 與孕婦a 的體檢時間周完全一致,即,孕婦b 的體檢妊娠周也為[16,20,24,28,30,32,34,35,36,37,38,39],那么,符合該統計分布的孕婦的數量加1,反映在圖2 中是最上方的第一橫行,橫坐標為[16,20,24,28,30,32,34,35,36,37,38,39]處是深色矩形.每一橫行在左邊對應的縱坐標上的數值是體檢的妊娠周完全符合該統計分布的孕婦人數,即,體檢孕周是[16,20,24,28,30,32,34,35,36,37,38,39]統計分布的孕婦共有21 人.10 473 個孕婦共有9480 種統計分布.按照每種分布的孕婦人數降序排列,圖2 繪制了人數最多的前30 種統計分布.根據圖2 可知,在9480 種體檢統計分布中,人數最多的僅有21 人,由于大部分孕婦的體檢周的分布差異巨大,因此,孕婦的體檢記錄在妊娠周時間上無法對齊,需要在傳統的LSTM 中引入時間信息.

圖2 孕婦體檢周統計分布圖(前30 種統計分布)
本文用P={p1,p2,···,pi,···,pN}表示孕婦集合,用R={r1,r2,···,ri,···,rN} 表示孕婦體檢記錄集合.N表示孕婦總人數,i表示第i個孕婦,孕婦pi對應的體檢記錄為ri.每一個孕婦的體檢記錄和體檢時間表示為Mi:=其中,和分別表示第i個孕婦的第k次體檢的記錄和時間,l表示體檢次數.根據當前的妊娠時間Δ和距上次體檢的間隔時間Δ的計算方式分別如式(1),式(2):

本文的目標是根據Mi,輸出胎兒出生體重的預測值.在標準的RNN 和LSTM 中,第k個時間步的輸入是xk=其中,⊕ 表示做向量拼接.在變長時間間隔LSTM 中,第k個時間步的輸入是xk,由于孕婦第一次體檢無間隔時間 Δt,故令
變長時間間隔LSTM 模型即為Variable Time Interval-LSTM(VTI-LSTM).標準的LSTM 模型的表達式[13]如式(3)-式(7):
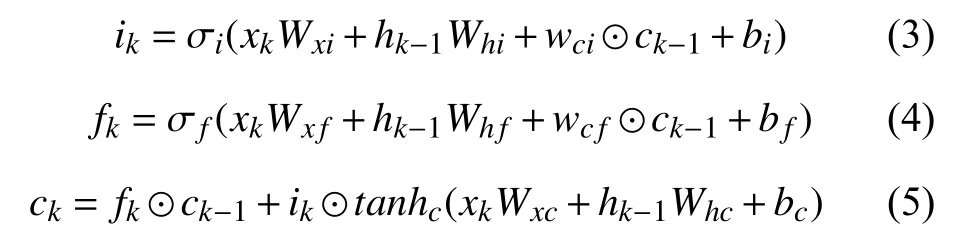

LSTM 模型結構如圖3(a)所示.我們將妊娠時間ΔT和間隔時間Δt做嵌入表征[14],如式(8),式(9):
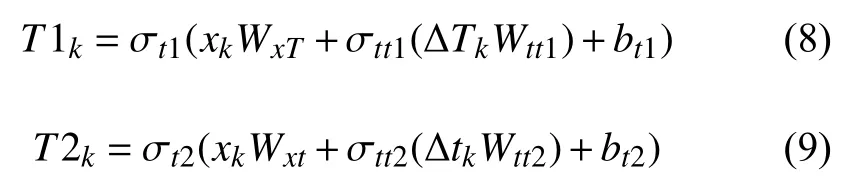
然后,本文分別向Standard LSTM 模型的“輸入門”和“遺忘門”中以時間門控的方式引入妊娠時間ΔT和間隔時間Δt,即,將式(5)換為式(10):

對于式(10)中(1-T2k)項,時間間隔的嵌入表征T2k越小,模型對過去事件的“遺忘”越少.而T1k則表示某次體檢的妊娠時間對該次輸入的“記憶”的多少.VTI-LSTM 模型結構如圖3(b)所示,左上角分別是兩個“時間門”時間門1 和時間門2,時間門1 的輸入是xk和ΔTk,時間門2 的輸入是xk和Δtk.
4 實驗和數據
4.1 特征篩選
研究表明,胎兒體重不僅與孕婦的宮高[15]、腹圍[16]相關,而且與身高體重[17,18]、胎次[19]、年齡、糖尿病[20]等因素有關.本研究中,本文選取孕婦的宮高腹圍和高危因素等方便獲取的參數作為模型的輸入特征.根據數據中的特征,計算各項特征與胎兒體重的皮爾森相關系數和P值.皮爾森相關系數計算公式如式(11).

圖3 兩個LSTM 模型圖

其中,xi和yi分別是兩個變量的數據項,和分別是兩個變量的平均值,N是樣本總數.sx和sy分別是兩個變量的標準差.P值即為原假設H0:ρ =0,備擇假設H1:ρ ≠0的t分布雙邊檢驗.P值計算公式如式(12),式(13):


其中,T服從n-2 自由度的t分布,Pvalue即為P值.計算結果如表1 所示,保留3 位有效數字.我們選擇P值低于0.05 的特征,包含妊娠周、年齡、身高、體重、宮高、腹圍、胎次、早產史、胎盤異常、胎位不正、胎膜早破、糖尿病、輔助生殖、多胎共14 個特征.其中,妊娠周、年齡、身高、體重、宮高、腹圍、胎次屬于數值型數據,早產史、胎盤異常、胎位不正、胎膜早破、糖尿病、輔助生殖、多胎屬于類別型數據.

表1 相關性分析結果
4.2 數據預處理
將胎兒體重以小于2500 g、在2500 g 和4000 g之間、大于4000 g 為標準分別劃分為低體重兒、正常體重兒、巨大兒,如表2 所示,可以看出,低體重兒和巨大兒樣本量與正常體重兒數量差距較大,因此在分類任務的訓練集中,將低體重兒和巨大兒樣本做過采樣處理,在總體的回歸任務上不做過采樣處理.為避免數據中不同的量綱對模型造成影響,本文采用歸一化的方式處理數值型數據.繪制胎兒體重分布圖,如圖4所示,橫坐標表示胎兒體重,縱坐標表示與該體重對應的胎兒數量.根據橫坐標間距和樣本數量,將樣本劃分為3 段,分別用倒三角、圓點、正三角表示.觀察可得,胎兒體重大多集中在中間圓點的區域,兩邊倒三角和正三角區域則較為稀疏,并且胎兒體重在橫坐標上跨度較大,使用常規的歸一化方法必然導致中間區域大量樣本的歸一化結果差異非常小,導致模型表現較差.因此,我們采用分段縮放的方法,犧牲小樣本上橫坐標的間距,放大大量樣本的橫坐標間距.倒三角樣本點、圓樣本點、正三角樣本點分布的橫坐標區間分別記為I1、I2、I3,區間內胎兒體重數值種類的數量分別記為C1、C2、C3,則各區間的密度分別記為式(14)~式(16),

表2 胎兒體重分類

圖4 胎兒體重分布圖
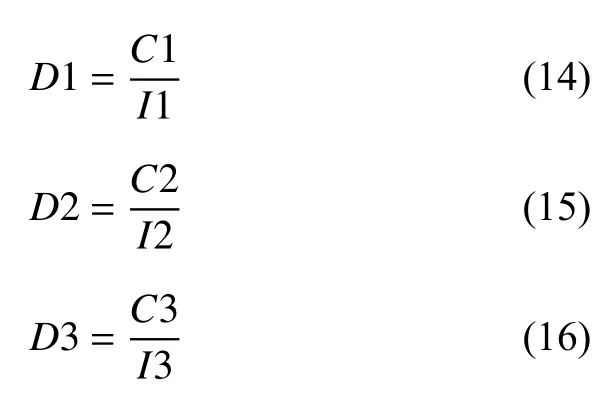
在區間I1 上,對樣本進行一次線性歸一化,如式(17):


將I1new、I2new、I3new合并為一個大區間,記為Itotal,再對Itotal做一次類似式(14)的線性歸一化計算.
經過上述分段縮放和歸一化計算,最終,數值類型數據的間隔相對均勻,且保留了各子區間內的線性關系,可提升模型效果.我們對身高、體重、宮高、腹圍、胎兒體重5 個數值型數據做了上述計算,其他數值型數據分布較為均勻,僅做簡單的線性歸一化.對于類別型數據,本文采用one-hot 的編碼方式,當某一孕婦的體檢記錄包含多種類別型數據,那么與該孕婦對應的類別信息為multi-hot 向量.
孕婦的體檢次數如圖5 所示,橫坐標表示孕婦體檢次數,縱坐標表示孕婦人數.最少體檢次數為1 次,最多體檢次數為24 次,孕婦的體檢記錄是一個變長序列.對于時序模型,需要將孕婦的體檢記錄做填充.上面提到的特征篩選中,孕婦的一次體檢記錄共有14 維.本文用1×14 的0 向量將孕婦的體檢記錄填充至24 次,0 向量不參與模型計算.因此,10 473 個孕婦的122 462條體檢記錄轉化為一個三維矩陣,第一維度表示最大體檢次數,第二維度表示每條體檢記錄的特征數量,第三維度表示孕婦總人數.
4.3 實驗設置
本文將產前的體檢記錄作為模型的輸入,胎兒出生體重作為預測目標,10 473 個孕婦的最后一次體檢記錄與分娩時間在同一周內.實驗分為公式法和機器學習方法2 部分.公式法是選取4 個不同的胎兒體重估算公式[5-8]作為對照,4 個估算公式如式(21)~式(24),分別對應公式法1~公式法4.其中,BW是胎兒的出生體重(單位為g),FH是宮高(單位為cm),AG是腹圍(單位為cm).

機器學習方法采用GBDT、MLP、SVR、RNN、LSTM、VTI-LSTM 等6 種模型,損失函數采用二次代價函數,如式(25):
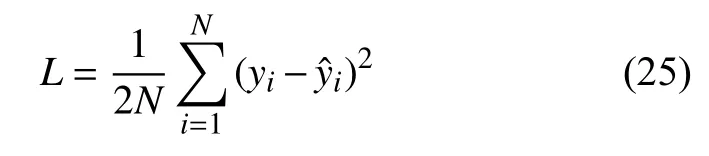
其中,yi和分別是預測值和真實值.N是訓練集中孕婦總人數.為直觀展示預測誤差,我們采用平均相對誤差如式(26):
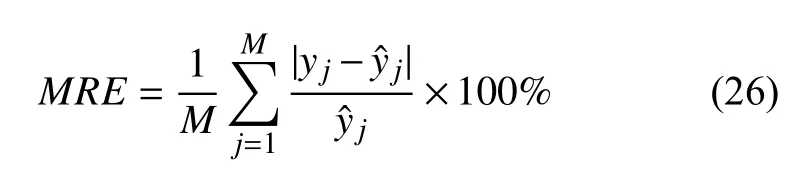
其中,yj是 預測值,是真實值.M是測試集中孕婦總人數.在實際臨床工作中,我們更關注異常體重胎兒,僅以回歸任務的相對誤差作為預測結果顯然是不夠的,因此,實驗分為兩個任務:
(1)對低體重兒、正常體重兒、巨大兒的分類.分類按照表2 劃分為3 類,我們從低體重兒、正常體重兒、巨大兒中各抽取50 個作為分類任務的測試集,根據分類預測結果計算各類體重的MRE 并繪制混淆矩陣.由于胎兒體重的各類樣本數量不平衡,因此需要對訓練集中的低體重兒和巨大兒做過采樣處理.
(2)計算總體上的回歸誤差,訓練集不做過采樣處理,總體回歸的測試集保持數據中原始的各類體重兒的比例.訓練集和測試集按照10:1 劃分.

圖5 孕婦體檢次數分布圖
5 實驗結果和討論
胎兒體重預測結果的平均相對誤差如表3 所示.其中,實驗結果的前3 列是分類任務在低體重兒、正常體重兒、巨大兒的預測上的MRE.第4 列是總體回歸任務的誤差,也即,前3 列的機器學習方法中,對訓練集中的小樣本做了過采樣處理,第4 列的機器學習方法中,對訓練集中的小樣本沒有做過采樣處理,保留原始數據中各類樣本的比例.公式法無訓練集,直接在測試集上計算即可.總體來看4 個公式法預測的結果弱于機器學習方法.式(21)、式(24)方法包含宮高腹圍兩個參數,式(22)僅有宮高參數,式(23)僅有一個腹圍參數,所以,式(23)法容易受到孕婦腹部脂肪的干擾,結果較差,式(22)相對式(23)較好,但弱于式(21)和式(24).式(21)的預測結果偏向于正常體重兒,在所有的方法中取得最小的正常體重兒預測結果誤差.GBDT、MLP、SVR 等3 種經典的機器學習模型的預測結果并無較大差異.RNN、LSTM、VTI-LSTM 等3 種時序模型方法中,LSTM 結果僅次于VTI-LSTM,RNN 結果較差,說明僅使用簡單的遞歸循環難以學習到孕婦多次體檢的變化.VTI-LSTM 在低體重兒和巨大兒MRE 上取得最好的預測結果,而在正常體重兒MRE 上弱于式(21).
由于在分類任務中,我們對小樣本做了過采樣處理,所以導致機器學習模型犧牲正常體重兒的結果,偏向低體重兒和巨大兒.觀察第4 列的結果,不做小樣本過采樣處理的總體回歸誤差仍舊是VTI-LSTM 效果最好,根據表2 的統計結果,占據樣本大多數的正常體重兒的體重范圍是2500~4000 g,區間跨度并不大,所以導致機器學習模型的總體MRE 結果相差較小.由于我們采用的是MRE 作為誤差度量的方式,根據圖4 可以看出,低體重兒的多樣性比巨大兒豐富,并且低體重兒計算MRE 公式的分母較小,所以在所有的方法中,低體重兒的MRE 高于巨大兒.
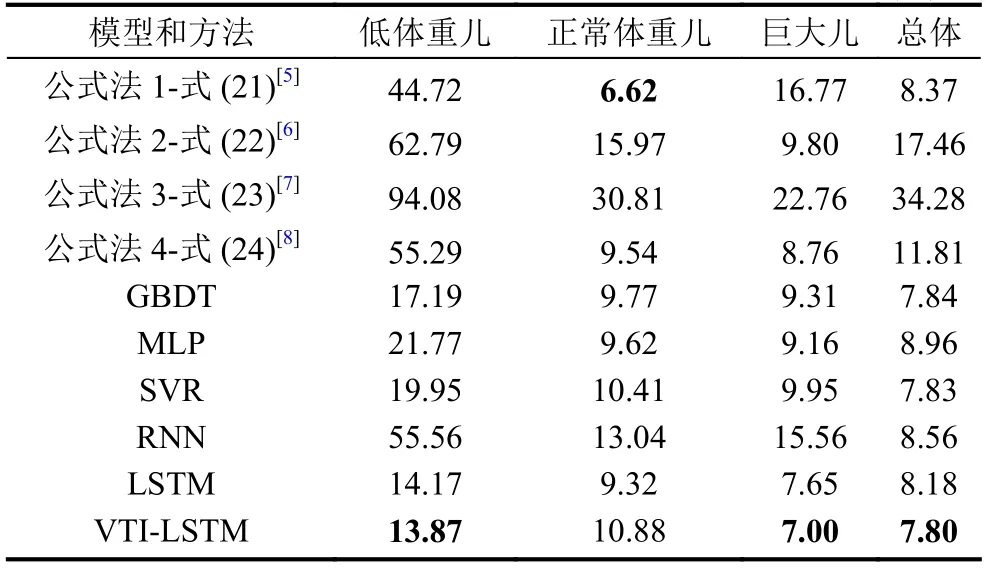
表3 測試集中胎兒體重預測的平均相對誤差MRE(%)
分類預測結果的混淆矩陣如圖6 所示.縱坐標表示真實類別,橫坐標表示預測類別.L表示低體重兒(low birth-weight infant),N表示正常體重兒(normal birth-weight infant),M表示巨大兒(macrosomia).公式法1、公式法2、公式法4 中,將大部分樣本分類到正常體重中,僅使用腹圍作為預測參數的公式法3 則傾向于將樣本分類到巨大兒中,預測結果受到了孕婦腹部脂肪的影響.GBDT、MLP、SVR 三者中,MLP 結果相對較差,GBDT 和SVR 無明顯差異.RNN 的分類結果與公式法接近,LSTM 和VTI-LSTM 明顯優于其他方法,LSTM 與VTI-LST 相比,LSTM 偏向于分類到正常體重兒中,VTI-LSTM 則在低體重兒和巨大兒的分類中取得最好的結果,說明不均勻離散時間在“輸入門”和“遺忘門”上的嵌入表征起到了很大的作用.上述的方法和模型中,無論是哪一種,對低體重兒和巨大兒的分類仍舊是一個挑戰.根據表2 中的數據,低體重兒和巨大兒分別僅占新生兒總數的3.41%和3.27%,各類樣本比例失衡,雖然在訓練集中我們采取了對小樣本過采樣的預處理方式,但仍舊難以避免小樣本數據缺乏多樣性的問題.另外,體重低于2 000 g 的低體重兒和體重高于4 500 g 的巨大兒分別占低體重兒和巨大兒較小的比例,導致低體重兒、正常體重兒、巨大兒的分類間隔較小.對比低體重兒和巨大兒的分類,低體重兒的分類結果明顯優于巨大兒.原因有如下兩點:第一,在我們的特征中,包含孕周信息,分娩低體重兒的孕婦的妊娠時間普遍少于正常的妊娠時長.第二,由于現代社會生活水平普遍較高,胎兒體重偏大,在孕36 周時,許多胎兒已經發育成熟,且體重在正常范圍內,這類胎兒和足月兒相比會提前1-2 周分娩,增加了模型識別巨大兒的難度.
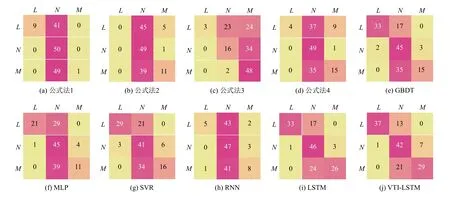
圖6 測試集上預測結果的混淆矩陣
6 結論
本研究在胎兒體重預測任務上分別使用了4 種公式法和3 種經典的機器學習方法以及3 種時序模型方法.其中,本研究提出的VTI-LSTM 模型在低體重兒和巨大兒的分類預測中取得了較好的結果并在總體的誤差回歸上取得最小的MRE.傳統的公式法弱于經典的機器學習模型和時序模型.而時序模型中的LSTM 可以學習到孕婦每次體檢的變化以及胎兒的生長速率,預測結果有大幅提升.VTI-LSTM 將每次體檢的時間間隔和體檢的妊娠時間在模型層面上表征,模型可以學習到孕婦體檢記錄的不均勻時間間隔,又在LSTM 的基礎上得到提升.綜上,本研究可為醫生和孕婦判斷胎兒生長發育提供一個相對準確的參考.
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
網絡安全與數據管理(2022年1期)2022-08-29 03:15:20
導航定位學報(2022年4期)2022-08-15 08:27:00
中學生數理化·中考版(2022年8期)2022-06-14 06:55:24
新世紀智能(數學備考)(2021年9期)2021-11-24 01:14:36
成都醫學院學報(2021年2期)2021-07-19 08:35:14
新世紀智能(數學備考)(2020年9期)2021-01-04 00:25:14
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
光學精密工程(2016年6期)2016-11-07 09:07:19
