利用協變量調整控制混雜因子的魯棒文本分類①
2020-03-18 07:55:06董園園
計算機系統應用 2020年3期
董園園
(齊魯師范學院,濟南 250013)
1 引言
文本分類[1]方法的研究已經超過了50 年,該類方法大多被應用于專題文獻分類.然而,隨著科技的發展和創新,跨學科領域如計算社會科學[2]、公共衛生監測[3]和流行病學[4]等都對文本分類提出了新要求.這些領域的待分類對象通常是在線文本[5],預測標簽則可能是健康狀況、政治立場或人類表情等差異化的術語.這些變化對文本分類(或稱為文檔分類)提出了新要求和新挑戰.
目前,已有很多研究者對文本分類進行了探討和研究,如文獻[6]為了提取更多的可信反例和構造準確高效的分類器,提出一種基于聚類的半監督主動分類方法,該方法利用聚類技術和正例文檔共享盡可能少的特征,從未標識數據集中盡可能多地移除正例,但該方法僅適用于較少文本特征的情況.文獻[7]中提出一種基于聚類的改進KNN 算法,采用改進統計量方法進行文本特征提取,依據聚類方法將文本聚類為幾個簇,最后利用改進的KNN 方法對簇類進行分類,但該方法難以提高文本分類效率.還有一些學者開發出控制混雜因子[8]的方法,包括匹配[9]、分層和回歸分析[10].文獻[11]開發出了用于因果圖模型的測試方法,用于確定哪種結構允許使用后門調整對混雜因子進行控制.文獻[12]提出了一種基于LDA 模型的文本分類方法,應用LDA 概率增長模型對文本集進行主題建模,在文本集的隱含主題-文本矩陣上訓練SVM,構造文本分類器,具有較好的分類效果.
上述方法各有特點,但其主要缺點是:混雜變量不能得到很好地控制,從而造成分類器的錯誤輸出.本文的目的是對影響分類的因子進行控制和調整,使得文本分類器具有良好的準確性和魯棒性.因此,本文基于Pearl 的后門調整方法[11],提出了一種基于協變量調整的文本分類方法,該方法以訓練階段的混雜變量為條件,在預測階段計算出混雜變量的總和.另外,本文還進一步探討了該方法的參數影響,以允許對預期調整的強度進行調整.實驗結果表明,所提方法能夠提高分類器的魯棒性,即使在混雜因子與目標變量之間的關聯從訓練集到測試集發生倒置的極端情況下,也能保持較高的準確度.
2 用于文本分類器的協變量調整
2.1 文本分類中得分協變量調整
假設研究目的是估計變量X對變量Y的因果效應,但無法進行隨機對照實驗.則已知混雜因子變量Z的一個充分集,可以使用式(1)估計對因果關系:

該公式稱作協變量調整(也稱為后門調整).協變量標準是一個圖形化測試,決定Z是否是估計因果效應變量的一個充分集,并要求Z中不存在X的子節點,且Z會阻止X和Y之間包含指向X的每一條路徑.p(y|x)≠p(y|do(x)),其中的符號“do”表示假設X=x.
協變量調整已經在因果推理問題中得到了充分研究,但本文的研究是文本分類中的應用.假設已知一個訓練集集合中的每個實例均包含一個術語特征向量x,一個標簽y和一個協變量z.本文的目的是對一些新實例xi的 標簽yi進行預測,同時控制一個未觀測到的混雜因子zi.也即:本文假設混雜因子可在訓練階段觀察到,但無法在測試階段觀察到.
所提方法的有向圖模型如圖1 所示,給出了對文本分類的一種省略混雜因子Z的判別式方法,假設混雜因子對P(Y|Z)中的向量和目標標簽均有影響,用已觀察到的向量x為條件的logistic 回歸分類器對P(Y|X)進行建模,該模型的結構確保Z可以滿足用于調整的協變量標準.

圖1 本文方法的有向圖模型
雖然協變量調整方法通常用于識別X對Y的因果關系,但并沒有解釋任何因果關系.然而,式(1)給出了一個框架,在控制Z中X為已知時,作出對Y的預測.這樣,可以訓練一個分類器,對P(Y|Z)從訓練數據到測試數據發生變化的情況下具備魯棒性.
本文使用式(1)對測試樣本x進行分類.假設對于訓練樣本,z為已觀測狀態,但沒有在測試樣本中觀察到.因此,需要從已標記的訓練數據中估計兩個變量p(y|x,z)和p(z).假設xi是 一個二進制特征向量,yi和zi則是二進制變量.對于p(z),可使用最大似然估計:
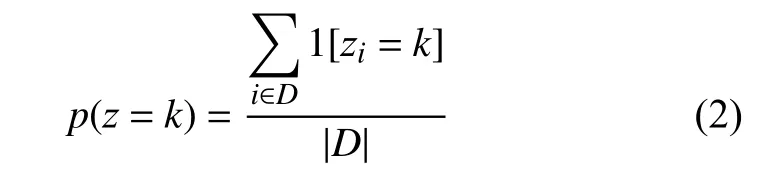
式中,1 [·]是 一個指示函數;D表示訓練集;p(z)表示為訓練集中指示函數之和與訓練集樣本數的比例.對于p(y|x,z),使用L2-正則化logistic 回歸,計算過程可以參考文獻[13].
2.2 對調整強度進行調節
從實施的角度來看,上述方法可表述為:使用上述最大似然估計(Maximum Likelihood Estimation,MLE)計算出p(z).本文通過對每個實例xi,附加上兩個分別表示z=0 和z=1 的額外特征ci,0和ci,1,高效地計算出p(y|x,z).如果zi=0,將第一個特征設為v1,將第二個特征設為0;若zi=1,則將第二個特征設為v1,將第一個特征設為0.默認情況下設v1=1,但可因情況而定.為了對一個新實例進行預測,使用式(1)計算后驗概率.
考慮到術語特征向量x通常包含數以千計的元素變量,而協變量z添加兩個額外特征就能夠對分類產生較大影響.為了理解這一點,可以考慮正則化logistic回歸中的權重訓練不足的問題[13].由于在文本分類中使用了數以千計的相互聯系和重疊的變量,對一個logistic 回歸模型進行的優化涉及到相關變量系數間的權衡問題,以及由L2 正則化懲罰所決定的系數量級.在這個設定中,少數高預測性特征的存在會導致低預測性特征的系數低于期望數值,因為高預測性特征在模型中占據主導地位,會導致在低預測性特征設定中的模型性能較差.因此,本文通過引入z的特征(一個潛在的高預測性特征),故意對x中的術語系數進行不充足訓練.例如,若z指的是性別,則通過使用協變量調整,使得與其他術語相比,性別指示性術語具有相對較低量級的系數.通過對協變量調整的強度進行調節,改寫了L2 正則化logistic 回歸[13]對數似然函數,對術語向量的系數和混雜因子的系數進行區分:

式中,θx為術語向量系數;θz為混雜因子系數;θ 為θx和θz的串聯參數;λx和 λz分別為控制術語系數和混雜因子系數的正則化強度.在默認情況下設λz=λx=1.但是,通過設 λz<λx,能夠降低混雜因子系數θz的量級懲罰.這使得系數θz在分類決策中發揮比θx更重要的作用,并增加 θx中不充分訓練的數量.本文通過提高v1的混雜因子特征數值,同時將其他特征數值保持為0,達到這個效果.由于本文沒有將特征矩陣標準化,增加v1的數值同時保持x的數值不變,能夠促使 θz的數值較小,并有效地使得對 θz的L2 懲罰相對小于θx.
3 實驗與分析
本文使用了3 個公開數據集進行實驗,其中混雜因子Z和分類變量Y之間的關系在訓練集和測試集中有所差異.有以下兩種情況:直接控制訓練和測試數據之間的差異;Z和Y之間的關系發生了突然.
為對具有不同的P(Y|Z)分布的訓練/測試集進行采樣,假設已有包含元素 {(xi,yi,zi)}標注后的數據集Dtrain和Dtest,其中yi和zi為二進制變量.本文引入了一個偏差參數P(y=1|z=1)=b;根據定義可知P(y=0|z=1)=1-b.對于每個實驗,從每個集合進行不放回抽樣D′train?Dtrain,D′test?Dtest.為了模擬P(Y|Z)中的變化,對于訓練和測試使用不同的偏差項btrain和btest.因此,根據以下約束條件進行采樣:
1)Ptrain(y=1|z=1)=btest;
2)Ptest(y=1|z=1)=btest;
3)Ptrain(Y)=Ptest(Y);
4)Ptrain(Z)=Ptest(Z).
其中,3)和4)的兩個約束條件是為了隔離對P(Y|Z)中的變化影響.因此,從訓練數據到測試數據中,保持P(Y)和P(Z)不變,P(Y|Z)則會發生變化.本文對P(Y,Z|X)的聯合分布進行建模,使用一個logistic 回歸分類器,其中標簽在Y和Z的積空間中.在測試階段,本文對z的可能分配進行求和,以計算y的后驗分布.
3.1 實驗數據及設置
為構建微博數據集,本文使用微博信息流應用編程接口采集包含上海和杭州地理坐標的博文.該實驗在4 天時間中(2016 年,6 月15 日至6 月18 日)共收集了246 930 條包含上海坐標的博文和218 945 條包含杭州坐標的博文.通過移除刪減,并對采集到的博文進行了二次采樣,保留6000 個用戶的博文,使得所有用戶的性別和地理位置均勻分布.其中,用戶的性別作為預測其位置的混雜變量.因此,設yi=1表示上海,zi=1表示男性.構建這個數據集的方式使得數據在4 種可能的y/z配對中均勻地分布.
本文對電影評論中的情感進行預測,并使用來自“豆瓣”等的IMDB 電影數據將影片類型作為混雜因子.該數據集中包括50 000 條來自IMDB 的影片評論,這些評論帶有正面或負面的情感標簽.移除了英語或中文停用詞和出現次數不到10 次的術語,使用一個二進制向量來表示特征的存在與否.電影是否是由IMDB分類所確定為“動作”類型影片作為一個混雜因子.由此,對于動作影片,本文設zi=1,對于其他類型影片則設zi=0.這個數據集在4 種可能的標簽/混雜因子配對中是不均勻分布的.大約18%的影片為動作電影,而對動作電影帶有正面情感的評論約占5%.
對于微博和IMDB,本文在訓練/測試中進行了變化模擬,將訓練集和測試集的偏差值b設為0.1-0.9,并對一些分類模型的準確度進行了比較.對于每對btrain和btest,抽樣5 段訓練/測試的分割樣本,并計算平均準確度.
3.2 對比的模型
本文對以下模型進行了比較:
協變量調整(BA):即本文所提方法,通過設置混雜特征的數值v1=10,進行強度更高的協變量調整的模型,該模型表示為BAZ10.
Logistic 回歸(LR):本文研究的主線是一個標準L2 正則化logistic 回歸分類器,該分類器不會為混雜因子做任何調整,僅簡單地對P(Y|X)進行建模.
二次采樣(LRS):在訓練階段,一種移除偏差的簡單方式是選擇數據的子樣本,使得P(Y|Z)均勻分布.當存在一個較強的混雜偏差時,該方法會丟棄很多實例,且實例數量會隨著混雜因子數量的增加而進一步減少.
匹配(M):匹配通常被用于從觀測研究中評估因果效應.對于每個y=i,z=j的訓練實例,采樣另一個訓練實例,其中y≠i,z=j.
3.3 結果分析
對于微博和IMDB 電影數據,本文分別建立了兩組實驗.隨著訓練和測試偏差的差異變化,研究測試準確度的變化情況.另外,計算Z和Y之間的皮爾森相關性[14],并給出在測試階段和訓練階段相關性的差異.
3.3.1 微博實驗
微博數據的實驗結果如圖2 所示,在極值區域表現最佳的方法是BAZ10 和LRS.這兩種方法在區間[-1.6,-0.6]和區間[0.6,1.6]中的性能超過了其他分類器:與BA 方法相比,超過了15 分;與LR 和M 方法相比超過了20 分;比SO 方法超過了30 分.而在這個區間之外的中間區域,BAZ10 方法的性能僅次于BA 和LR 方法.此外,當相關性差異為0 時,BAZ10 方法的最大準確度損失大約為2 分.這一結果表明,BAZ10 方法對混雜因子的魯棒性明顯高于LR 方法,前者在混雜因子影響較小的情況下,僅會產生最低限度的準確度損失.
在所有訓練偏差上,每個測試偏差的平均準確度如圖2(b)所示.BA 和BAZ10 方法在總體上比其他方法的準確度更高.SO 的總體性能不佳,與其他方法相比,其準確度要低4 到8 分.
為了找到BAZ10 方法比其他方法的準確度和魯棒性更高的原因,本文給出了當偏差值為0.9 時,LR、BA 和BAZ10 分類器的系數,如圖3 所示.由圖3 可知,根據 χ2統計數據,10 個最能預測類標簽的特征和10 個最能預測混雜變量的特征.與位置相關的特征權重在協變量調整方法中有少許下降,但依然保持相對較重要的地位.與之相反,與性別相關的特征權值在協變量調整方法中則非常接近0.
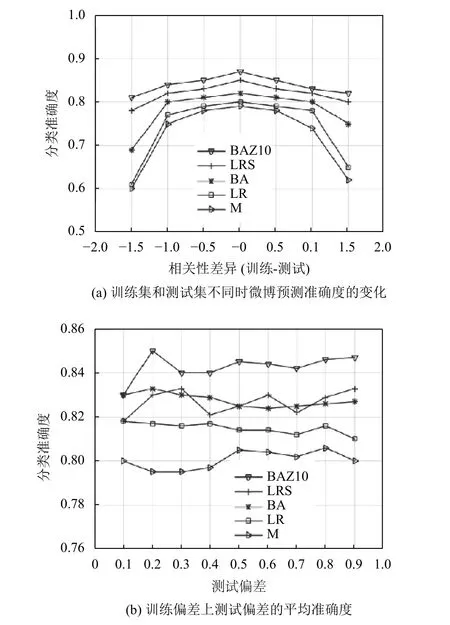
圖2 微博數據的實驗結果
已知擬合數據偏差的強度時,Simpson 悖論[15]的特征百分比如圖4 所示,其中,微博數據中大概包含22 K的特征.由圖可知,BAZ10 的Simpson 悖論特征數量相對保持不變;而在其他方法中,該特征數量則在偏差接近極值時迅速增長.
3.3.2 IMDB 實驗
圖5 給出了IMDB 數據的實驗結果.結果顯示,BA 和BAZ10 是對混雜偏差的魯棒性最好的方法.LRS 方法魯棒性最低.LRS 方法的結果不理想原因可能是在IMDB 數據中,y/z變量的分布不均衡,使得LRS 方法每次僅能在很小比例的訓練數據上擬合.這也是在IMDB 實驗中,整體準確度的變化幅度要比微博實驗小得多的原因.

圖3 根據卡方統計的結果

圖4 Simpson 悖論的特征百分比
3.4 參數分析
對于IMDB 和微博實驗,本文還計算了一個成對的t-測試,以使用相關性差異的每個數值對BAZ10 和LR 方法進行比較.實驗結果發現,在19 個案例中,BAZ10 的性能優于LR;在8 個案例中,LR 的性能優于BAZ10;而在5 個案例中,結果并沒有明顯差別.從圖中還可以觀察到,當測試數據與訓練數據相對于混雜因子非常類似時,BAZ10 的性能大致相當或稍弱于LR 方法;然而,當測試數據在混雜因子上與訓練數據不同時,BAZ10 的性能要優于LR.
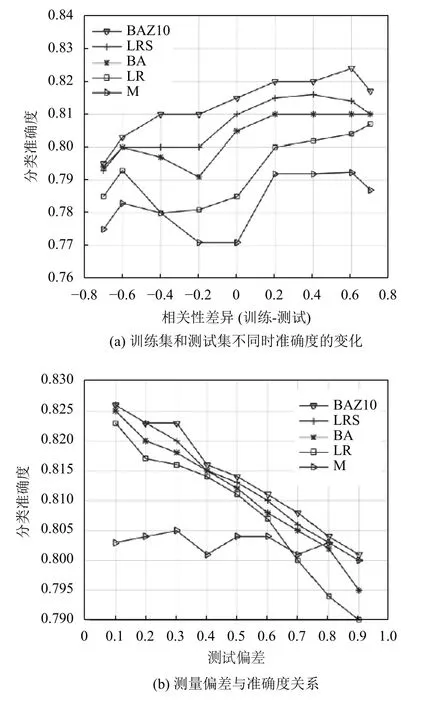
圖5 IMDB 數據的實驗結果
總之,當在混雜因子的影響中存在極端和突然轉變時,最好的方法是丟棄發生該轉變之前的大部分數據.然而,一旦在該轉變后可用的實例數量適中時,BAZ10 方法能夠作出調整解決混雜偏差的問題.
關于參數分析,本文以BA 方法為例,圖6 給出了控制著協變量調整強度的v1參 數影響.該圖給出了c0和c1成 比例系數絕對值的變化,及當v1在微博中增加時準確度的變化.這些結果是在訓練數據集偏差差異較大的情況下產生的,從圖6 中可看到,當v1小于10-1時,準確度較低,但較穩定.然后隨v1的增加而增長,并且在v1=10時,開始大幅攀升.這個數據集中,準確度在兩個峰值之間出現了15 點增益.對于所有實驗中給定v1=10,使用交叉驗證可以選擇出能夠產生期望魯棒性的v1數值.

圖6 混雜因子特征系數和準確度
4 結論與展望
本文提出了一個快速有效的文本分類方法,即使用協變量調整來控制混雜因子.在3 個不同的數據集上,本文發現協變量調整能夠在混雜關系從訓練數據到測試數據發生變化時,提高分類器的魯棒性,并且在混雜偏差很大的情況下,可以使用一個額外的參數對調整的強度進行調節.協變量調整不但能夠降低與混雜因子相關的系數量級,而且可以糾正與目標類標簽相關聯的系數標注.
未來本文將研究在訓練階段僅有Z的帶噪估計,以及Z是一個變量向量的情況.
猜你喜歡
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
制造技術與機床(2019年10期)2019-10-26 02:48:08
當代陜西(2019年10期)2019-06-03 10:12:04
中學生數理化·七年級數學人教版(2019年4期)2019-05-20 10:06:32
電子制作(2018年18期)2018-11-14 01:48:06
中學生數理化·七年級數學人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
小學教學參考(2015年20期)2016-01-15 08:44:38
