一種基于生成式對(duì)抗網(wǎng)絡(luò)的圖像數(shù)據(jù)擴(kuò)充方法
2020-04-09 06:36:40王海文邱曉暉
計(jì)算機(jī)技術(shù)與發(fā)展 2020年3期
王海文,邱曉暉
(南京郵電大學(xué) 通信與信息工程學(xué)院,江蘇 南京 210003)
0 引 言
近些年來(lái),深度學(xué)習(xí)受到了各領(lǐng)域?qū)W者的廣泛研究,其中卷積神經(jīng)網(wǎng)絡(luò)(CNN)是用于圖像分類研究的最基本模型。目前常見(jiàn)的卷積網(wǎng)絡(luò)有AlexNet、VGGNet、GoogleNet、ResNet等。最早提出卷積神經(jīng)網(wǎng)絡(luò)并將其運(yùn)用于數(shù)字識(shí)別的是Yann LeCun[1]的LeNet-5模型,它包含了一個(gè)深度學(xué)習(xí)的必要模塊和卷積層、池化層、全連接層的基本組合方式,采用基于梯度的反向傳播算法BP[2]在圖像數(shù)量為60 000張,分類標(biāo)簽數(shù)為10的手寫(xiě)體Mnist數(shù)據(jù)集上對(duì)網(wǎng)絡(luò)進(jìn)行有監(jiān)督訓(xùn)練。直到AlexNet[3]的出現(xiàn),提高了神經(jīng)網(wǎng)絡(luò)的訓(xùn)練速度和網(wǎng)絡(luò)的分類能力,AlexNet采用訓(xùn)練集大小為1 400萬(wàn)張、涵蓋2.2萬(wàn)個(gè)類別的ImageNet數(shù)據(jù)集進(jìn)行訓(xùn)練。其主要優(yōu)勢(shì)在于,使用了一種非線性激活函數(shù)Relu[4]以及重疊的最大池化,提出局部響應(yīng)歸一化LRN(local response normalization),提取了圖像豐富的深層特征,增強(qiáng)了模型的泛化能力,并使用GPU并行計(jì)算,極大地縮短了對(duì)圖像計(jì)算的時(shí)間。此外,AlexNet還使用了數(shù)據(jù)增強(qiáng)和Dropout[5]組合防止過(guò)擬合,隨機(jī)地從256*256像素的原始圖像中截取224*224大小的區(qū)域,增加了2 048倍的數(shù)據(jù)量。該模型說(shuō)明了數(shù)據(jù)集的擴(kuò)充有效提升了網(wǎng)絡(luò)訓(xùn)練的質(zhì)量,由此也激發(fā)了研究人員對(duì)數(shù)據(jù)增強(qiáng)方法的研究和應(yīng)用。后來(lái)一些深層卷積神經(jīng)網(wǎng)絡(luò)如VGG16、ResNet[6],即使使用了質(zhì)量較高,且數(shù)量龐大的數(shù)據(jù)作為訓(xùn)練集,也都會(huì)對(duì)圖像數(shù)據(jù)進(jìn)行常見(jiàn)的預(yù)處理,如crop或小批量的數(shù)據(jù)增強(qiáng)。由此可見(jiàn),數(shù)據(jù)集的大小和質(zhì)量極大地影響了CNN網(wǎng)絡(luò)的訓(xùn)練過(guò)程和最終的質(zhì)量。
目前比較好的神經(jīng)網(wǎng)絡(luò)都具有一定的深度。然而隨著神經(jīng)網(wǎng)絡(luò)的加深,需要學(xué)習(xí)的參數(shù)也會(huì)隨之增加,這樣就容易導(dǎo)致過(guò)度擬合。過(guò)度擬合是指神經(jīng)網(wǎng)絡(luò)可以高度擬合訓(xùn)練數(shù)據(jù)的分布情況,但對(duì)于測(cè)試數(shù)據(jù)準(zhǔn)確率很低,缺乏泛化能力。造成訓(xùn)練網(wǎng)絡(luò)過(guò)度擬合的原因有很多,數(shù)據(jù)集數(shù)量少和質(zhì)量差是最直接的原因。早在2012年Alex贏得ImageNet競(jìng)賽后便提出PCA Jittering,對(duì)網(wǎng)絡(luò)的輸入數(shù)據(jù)進(jìn)行規(guī)范化,并在整個(gè)訓(xùn)練集上計(jì)算了協(xié)方差矩陣,進(jìn)行特征分解,用于PAC Jittering,從而有效地對(duì)輸入數(shù)據(jù)進(jìn)行預(yù)處理,規(guī)范數(shù)據(jù)質(zhì)量。后來(lái)的Inception網(wǎng)絡(luò)[7],VGG和ResNet也均使用Scale Jittering,即尺度和長(zhǎng)寬比的增強(qiáng)變換方法來(lái)擴(kuò)充數(shù)據(jù),對(duì)圖像進(jìn)行預(yù)處理,實(shí)現(xiàn)數(shù)據(jù)增強(qiáng)。這些最先進(jìn)的研究均表明了數(shù)據(jù)增強(qiáng)對(duì)一般深層網(wǎng)絡(luò)最后的識(shí)別性能和泛化能力有著至關(guān)重要的作用。所以,為了避免出現(xiàn)過(guò)擬合(over-fitting)且數(shù)據(jù)量較小時(shí),數(shù)據(jù)增強(qiáng)十分必要。
1 數(shù)據(jù)增強(qiáng)算法
一般來(lái)說(shuō),數(shù)據(jù)增強(qiáng)分為兩類:離線增強(qiáng),即在網(wǎng)絡(luò)未獲取數(shù)據(jù)之前,直接對(duì)數(shù)據(jù)集進(jìn)行擴(kuò)充處理,數(shù)據(jù)的數(shù)目會(huì)根據(jù)增強(qiáng)因子直接成倍增長(zhǎng),這種方法常用于數(shù)據(jù)集很小的時(shí)候。在線增強(qiáng),這種方法主要用于,在獲取一組Batch數(shù)據(jù)后,對(duì)該組數(shù)據(jù)中的每個(gè)對(duì)象實(shí)現(xiàn)數(shù)據(jù)增強(qiáng),如:旋轉(zhuǎn)、平移、翻折等變換。近些年研究人員發(fā)現(xiàn),卷積神經(jīng)網(wǎng)絡(luò)對(duì)于放置在不同方向的對(duì)象也能進(jìn)行穩(wěn)健的分類,即具有旋轉(zhuǎn)不變性。更具體地說(shuō),CNN對(duì)于平移、視角、尺度變化甚至光照的組合都可以是不變的。這一特性使得可以利用基本變換對(duì)數(shù)據(jù)集進(jìn)行有效擴(kuò)充。例如,空間變換類:翻轉(zhuǎn)、裁剪(ROI)、旋轉(zhuǎn)、縮放變形;頻域變換類:旋轉(zhuǎn)畸變變換[8]、極坐標(biāo)變換[9]、RGB變換。
此外,還有一些特殊的數(shù)據(jù)增強(qiáng)方法。SMOTE(synthetic minority over-sampling technique)針對(duì)數(shù)據(jù)集中樣布分類不平衡現(xiàn)象導(dǎo)致的特征提取不足,基于插值法為小樣本類合成新的樣本,其主要思路為:
(1)定義好特征空間,將每個(gè)樣本對(duì)應(yīng)到特征空間中的某一點(diǎn),根據(jù)樣本不平衡比例確定采樣倍率N。
(2)對(duì)每一個(gè)小樣本類樣本(x,y),按歐氏距離找k個(gè)最近鄰樣本,從中隨機(jī)選取一個(gè)樣本點(diǎn),假設(shè)選擇的鄰近點(diǎn)為(xn,yn)。在特征空間中樣本點(diǎn)與最近鄰樣本點(diǎn)的連線段上隨機(jī)選取一點(diǎn)作為新樣本點(diǎn),滿足式(1):
(xnew,ynew)=(x,y)+rand(0,1)×((xn-x),(yn-y))
(1)
(3)重復(fù)選取取樣,直到大、小樣本數(shù)量平衡。
2018年1月,Google科學(xué)家Ekin Dogus Cubuk和Barret Zoph開(kāi)發(fā)了一款自動(dòng)尋找數(shù)據(jù)本身最佳增強(qiáng)策略的優(yōu)化工具AutoAugment。AutoAugment能為計(jì)算機(jī)視覺(jué)數(shù)據(jù)集自動(dòng)設(shè)計(jì)圖像增強(qiáng)策略,它不僅包含了水平/垂直、旋轉(zhuǎn)、改變顏色等常規(guī)方法增加圖像數(shù)據(jù)量,還能預(yù)測(cè)每種增強(qiáng)方法使用的最優(yōu)占比,從而尋找最優(yōu)的圖像增強(qiáng)策略。AutoAugment在數(shù)據(jù)集ImageNet的實(shí)驗(yàn)結(jié)果也表明,對(duì)于顏色和色調(diào)敏感度不同的數(shù)據(jù)集,如果僅僅運(yùn)用裁剪或改變顏色去增強(qiáng)數(shù)據(jù),用最后生成的圖像訓(xùn)練模型可能會(huì)降低模型性能。尋找一種或組合使用多種數(shù)據(jù)增強(qiáng)算法,可以進(jìn)一步提升網(wǎng)絡(luò)模型做圖像分類時(shí)的準(zhǔn)確率。
生成式對(duì)抗網(wǎng)絡(luò)(GAN)[10]自2014年被Goodfellow提出后,被譽(yù)為近十年來(lái)最富想象力的深度學(xué)習(xí)網(wǎng)絡(luò)模型,并且被不斷改進(jìn),形成了CGAN、DCGAN、WGAN、BEGAN、infoGAN[11]等用于圖像、自然語(yǔ)言處理甚至語(yǔ)音處理等領(lǐng)域的新模型。由于傳統(tǒng)方法在數(shù)據(jù)增強(qiáng)方面的效率較低,且生成的圖像數(shù)據(jù)帶有很多的冗余信息,給網(wǎng)絡(luò)訓(xùn)練帶來(lái)更多不確定性。為了得到更豐富的圖像數(shù)據(jù),降低網(wǎng)絡(luò)訓(xùn)練難度,一定程度上緩解因數(shù)據(jù)集太小造成網(wǎng)絡(luò)模型泛化能力不強(qiáng)的問(wèn)題,文中受生成式對(duì)抗網(wǎng)絡(luò)啟發(fā),將帶深度卷積的GAN網(wǎng)絡(luò)用于生成圖片,從本質(zhì)上分離傳統(tǒng)圖像增強(qiáng)時(shí)帶來(lái)的生成樣本相關(guān)性,實(shí)現(xiàn)數(shù)據(jù)增強(qiáng)。目前生成式對(duì)抗網(wǎng)絡(luò)主要使用了一些常見(jiàn)的激活函數(shù)如Tanh、Relu[12]和Batch Normalization等方法簡(jiǎn)化網(wǎng)絡(luò)模型參數(shù),使訓(xùn)練變得快速高效,但這些方法實(shí)際使用中還是會(huì)由于參數(shù)調(diào)整不當(dāng)而造成求解損失函數(shù)最小值時(shí)不收斂或震蕩,生成圖像質(zhì)量較差等問(wèn)題,為此引入一種新的激活函數(shù)Selu使訓(xùn)練更加穩(wěn)定,改善訓(xùn)練生成式對(duì)抗網(wǎng)絡(luò)不夠穩(wěn)定的缺點(diǎn)。
2 基于Selu的改進(jìn)DCGAN網(wǎng)絡(luò)
2.1 DCGAN網(wǎng)絡(luò)原理及特點(diǎn)
DCGAN(deep convolutional GAN)是一種帶深度卷積的GAN模型。GAN模型如圖1所示,主要包括了一個(gè)生成模型G(generator)和一個(gè)判別模型D(discriminator)。G負(fù)責(zé)生成圖像,它接受一個(gè)隨機(jī)的噪聲z,通過(guò)該噪聲生成圖像,將生成的圖像記為G(z);D負(fù)責(zé)判別一張圖像是否為真實(shí)的,它的輸入是x,代表一張圖像,輸出D(x)表示x為真實(shí)圖像的概率,實(shí)際上D是對(duì)數(shù)據(jù)的來(lái)源進(jìn)行一個(gè)判別:究竟這個(gè)數(shù)據(jù)是來(lái)自真實(shí)的數(shù)據(jù)分布pdata,還是來(lái)自于一個(gè)生成模型G所產(chǎn)生的一個(gè)數(shù)據(jù)分布p(z)。所以在整個(gè)訓(xùn)練過(guò)程中,生成網(wǎng)絡(luò)G的目標(biāo)是生成可以以假亂真的圖像G(z)讓D無(wú)法區(qū)分,即D(G(z))=0.5,此時(shí)便得到了一個(gè)生成式模型G用來(lái)生成圖像擴(kuò)充數(shù)據(jù)集。模型訓(xùn)練的過(guò)程構(gòu)成了G和D的一個(gè)動(dòng)態(tài)博弈,可以構(gòu)造式(2)所示的交叉熵?fù)p失函數(shù):
V(D,G)=Ex~pdata(X)[lnD(x)]+Ez~pz(Z)[ln(1-
D(G(z)))]
(2)
其中,x為用于訓(xùn)練的真實(shí)圖像數(shù)據(jù),pdata(X)為圖片數(shù)據(jù)的分布,z為輸入G網(wǎng)絡(luò)的噪聲且已知噪聲z的分布為pz(Z),而G(z)為網(wǎng)絡(luò)生成的圖片。在理想狀態(tài)下,經(jīng)過(guò)訓(xùn)練,G盡可能學(xué)習(xí)到真實(shí)的數(shù)據(jù)分布pdata(X),G將已知分布的z變量映射到了未知分布的x變量上。判別模型D的訓(xùn)練目的就是要盡量最大化自己的判別準(zhǔn)確率。當(dāng)這個(gè)數(shù)據(jù)被判別為來(lái)自于真實(shí)數(shù)據(jù)時(shí),標(biāo)注1,來(lái)自于生成數(shù)據(jù)時(shí),標(biāo)注0。而與這個(gè)目的和過(guò)程相反的是,生成模型G的訓(xùn)練目標(biāo)是要最小化判別模型D的判別準(zhǔn)確率。在訓(xùn)練過(guò)程中,GAN采用了一種交替優(yōu)化方式,它分為兩個(gè)階段,第一個(gè)階段是固定判別模型D,然后優(yōu)化生成模型G,使得判別模型的準(zhǔn)確率盡量降低。而另一個(gè)階段是固定生成模型G,來(lái)提高判別模型的準(zhǔn)確率。
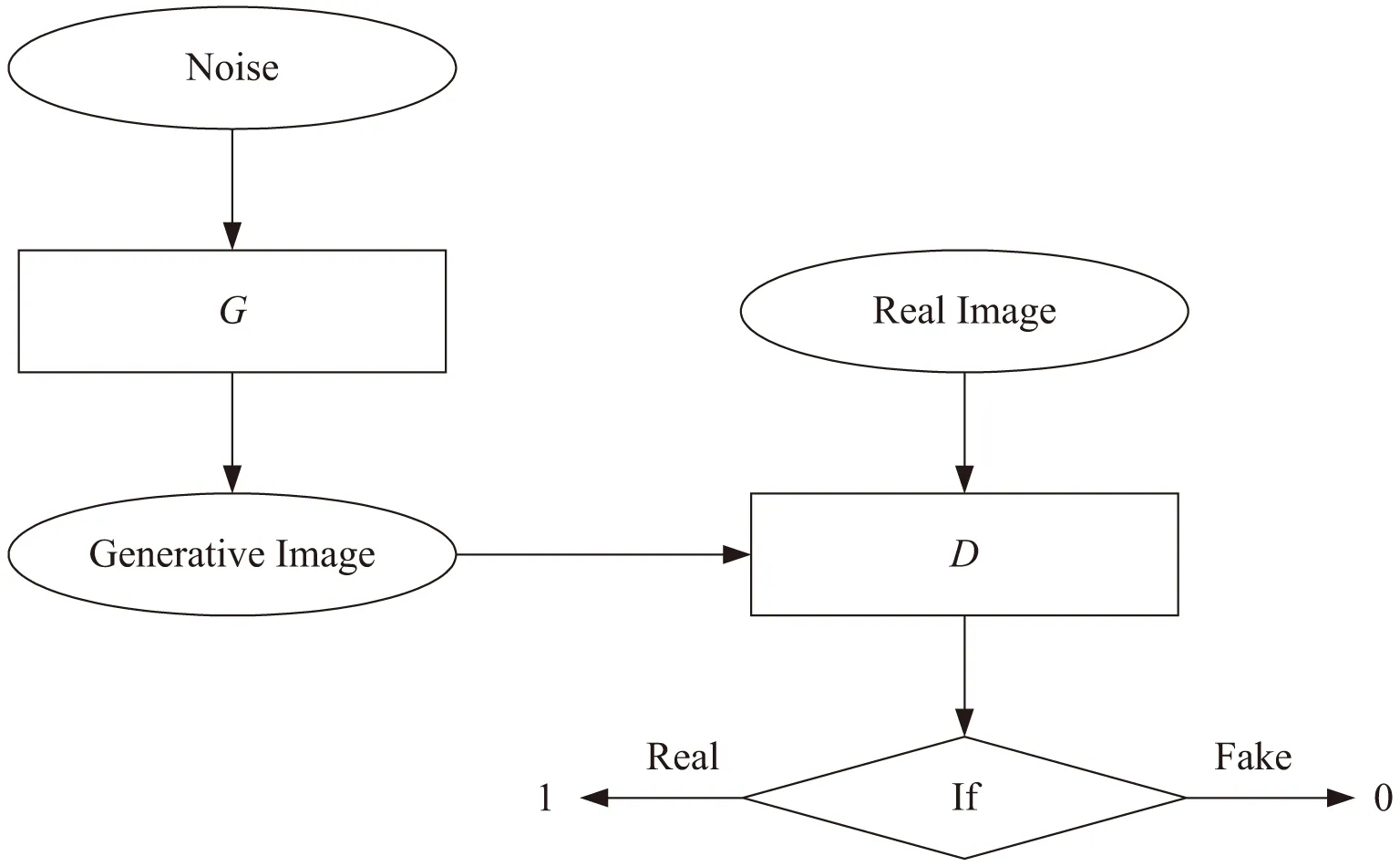
圖1 DCGAN網(wǎng)絡(luò)判別結(jié)構(gòu)示意圖
DCGAN的特點(diǎn)是在G和D網(wǎng)絡(luò)中使用了深度卷積網(wǎng)絡(luò)。D網(wǎng)絡(luò)與一般卷積神經(jīng)網(wǎng)絡(luò)類似,使用了帶步長(zhǎng)的二維卷積,提取深層特征的同時(shí)不斷減小特征圖的大小,實(shí)現(xiàn)下采樣。而G網(wǎng)絡(luò)則使用了一種轉(zhuǎn)置卷積,從一維向量逐漸擴(kuò)充成二維圖像,實(shí)現(xiàn)上采樣過(guò)程。其中卷積濾波器長(zhǎng)寬L=3,卷積步長(zhǎng)P=2的正向卷積完成特征圖大小5×5到3×3下采樣(見(jiàn)圖2)和轉(zhuǎn)置卷積完成特征圖大小3×3到5×5上采樣(見(jiàn)圖3)。

圖2 正向卷積示意圖
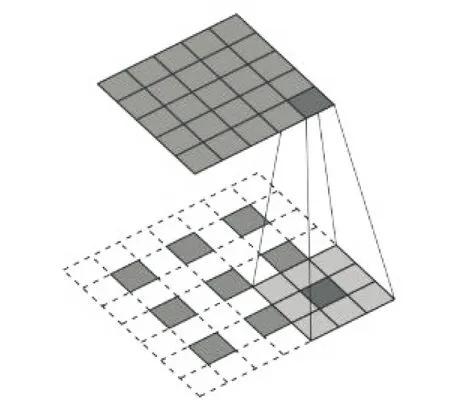
圖3 轉(zhuǎn)置卷積示意圖
生成網(wǎng)絡(luò)是否能生成判別網(wǎng)絡(luò)無(wú)法區(qū)分真假圖片的關(guān)鍵不僅依賴合理的卷積層,還需要選取合適的激活函數(shù),如不用激活函數(shù),下面每一層輸出都是上一層輸入的線性函數(shù),如早期的感知機(jī)模型,即使使用生成式對(duì)抗網(wǎng)絡(luò)也無(wú)法學(xué)習(xí)和生成有意義的圖像。只有引入非線性函數(shù)作為激活函數(shù),深層網(wǎng)絡(luò)層才具有意義,生成需要的圖像,并完成非線性映射和加速網(wǎng)絡(luò)收斂的速度。相較于Tanh和Sigmoid函數(shù),在GAN網(wǎng)絡(luò)中運(yùn)用Relu在使用隨機(jī)梯度下降法(SGD)中能更快地收斂,且為神經(jīng)網(wǎng)絡(luò)提供了稀疏表達(dá)能力。研究中人們還會(huì)使用LeakyRelu、Relu等Dropout組合構(gòu)建網(wǎng)絡(luò)的激活層[5],這些激活函數(shù)不僅能將卷積層提取的圖像特征非線性地映射到高維空間,還能在一定程度上簡(jiǎn)化計(jì)算網(wǎng)絡(luò)參數(shù)的難度,加速網(wǎng)絡(luò)的訓(xùn)練過(guò)程,如在利用反向傳播(BP)訓(xùn)練參數(shù)時(shí),Relu函數(shù)在求導(dǎo)后僅剩常數(shù)。Relu的公式如下:
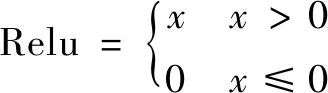
(3)
2.2 結(jié)構(gòu)簡(jiǎn)化的改進(jìn)DCGAN網(wǎng)絡(luò)
由于在DCGAN網(wǎng)絡(luò)中,Relu層和歸一化層(batch normal)分別完成了卷積層的非線性激活和去復(fù)雜歸一化[13],文中算法使用了一種自歸一化Selu(縮放指數(shù)線性單元)激活函數(shù)(如式(4)),目的是為了替代激活層和歸一化層,簡(jiǎn)化網(wǎng)絡(luò)結(jié)構(gòu),解決對(duì)抗網(wǎng)絡(luò)訓(xùn)練不穩(wěn)定的問(wèn)題,提升生成圖像質(zhì)量。
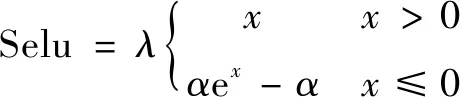
(4)
其中,λ≈1.05,α≈1.67。
Relu在之前表現(xiàn)較好的特性是因?yàn)樗谳斎胧秦?fù)值時(shí),神經(jīng)元就不會(huì)被激活,從而使得網(wǎng)絡(luò)很稀疏,提升了計(jì)算效率,但在反向傳播中,會(huì)出現(xiàn)一個(gè)趨于0的梯度空間,即輸入值變換到負(fù)值后梯度會(huì)再也不更新,這些神經(jīng)元將永遠(yuǎn)不會(huì)被激活且很可能會(huì)對(duì)整個(gè)生成網(wǎng)絡(luò)甚至判別網(wǎng)絡(luò)產(chǎn)生弊端。理論上,希望經(jīng)過(guò)激活函數(shù)后使得樣本分布?xì)w一化到均值為0,方差為1,這樣在利用梯度下降法的訓(xùn)練過(guò)程中,不會(huì)產(chǎn)生梯度越來(lái)越大或者消失的情況[14]。而Selu函數(shù)正符合這樣的特點(diǎn):在負(fù)半軸坡度平緩,在激活后方差過(guò)大的時(shí)候可以讓它減小,防止了梯度爆炸,正半軸設(shè)置了大于1的常數(shù),在方差過(guò)小的時(shí)候可以讓它增大,同時(shí)也防止了梯度消失。這樣激活函數(shù)就有了一個(gè)不動(dòng)點(diǎn),在網(wǎng)絡(luò)加深后每一層的輸出都是均值為0且方差為1。所以,引入Selu激活函數(shù)加入DCGAN網(wǎng)絡(luò),從理論上簡(jiǎn)化了網(wǎng)絡(luò)結(jié)構(gòu)。DCGAN網(wǎng)絡(luò)在訓(xùn)練時(shí)易發(fā)生因生成網(wǎng)絡(luò)或判別網(wǎng)絡(luò)結(jié)構(gòu)過(guò)于復(fù)雜或?qū)W習(xí)率選取不當(dāng)造成的不穩(wěn)定現(xiàn)象,從而導(dǎo)致無(wú)法生成有意義的圖片,仿真實(shí)驗(yàn)驗(yàn)證了文中方法網(wǎng)絡(luò)訓(xùn)練的有效性和穩(wěn)定性,同時(shí)也能生成更高質(zhì)量的圖片。
2.3 a_Dropout技術(shù)
通常可以采用更深的網(wǎng)絡(luò)和更多的神經(jīng)元來(lái)提高網(wǎng)絡(luò)的分類表達(dá)能力,但是復(fù)雜的網(wǎng)絡(luò)如果沒(méi)有足夠多的數(shù)據(jù)去訓(xùn)練,就會(huì)造成過(guò)度擬合現(xiàn)象。過(guò)擬合具體表現(xiàn)在:模型在訓(xùn)練數(shù)據(jù)上損失函數(shù)較小,預(yù)測(cè)準(zhǔn)確率較高;但是在測(cè)試數(shù)據(jù)上損失函數(shù)較大,預(yù)測(cè)準(zhǔn)確率較低。在2012年的AlexNet中就使用了一種Dropout方法,在前向傳播的時(shí)候,讓某個(gè)神經(jīng)元的激活值以一定的概率q停止工作,即在訓(xùn)練階段隨機(jī)組成了無(wú)數(shù)的神經(jīng)元網(wǎng)絡(luò),簡(jiǎn)化了每次訓(xùn)練網(wǎng)絡(luò)時(shí)的參數(shù),提升了訓(xùn)練網(wǎng)絡(luò)所耗費(fèi)的時(shí)間。另一方面,Dropout降低了神經(jīng)元間的相互依賴,大大提升了網(wǎng)絡(luò)泛化能力,起到一種正則化效果。
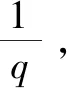
對(duì)于Selu激活函數(shù),引用了一種帶參數(shù)歸一化的a_Dropout方法。使用該方法后的均值和方差滿足式(5),其中β的值為Selu中的-λα。
E(xd+β(1-d))=qμ+(1-q)β
Var(xd+β(1-d))=q((1-q)(β-μ)2+υ)
(5)
在計(jì)算中還會(huì)利用a,b兩個(gè)參數(shù)進(jìn)行仿射變換保證均值和方差不變,如式(6),并且可以通過(guò)μ,v計(jì)算出最佳的a,b值。
E(α(xd+β(1-d))+b)=μ
Var(α(xd+β(1-d))+b)=υ
(6)
3 實(shí)驗(yàn)仿真
實(shí)驗(yàn)采用Intel Cpu8750H、Nvidia GTX1070、Win10操作系統(tǒng),基于tensorflow1.8-GPU的網(wǎng)絡(luò)構(gòu)建及訓(xùn)練,數(shù)據(jù)集采用Mnist。
3.1 Selu激活函數(shù)的自歸一化特性仿真
在一個(gè)層數(shù)為2的卷積網(wǎng)絡(luò)上分別使用Selu(左)和Relu(右)激活后激活函數(shù)輸出值分布激勵(lì)圖如圖4所示。
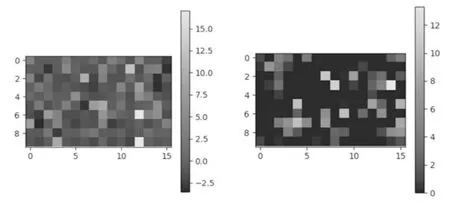
圖4 Selu(左)與Relu(右)激活值分布激勵(lì)圖
由于Selu的自歸一化特性,保證了網(wǎng)絡(luò)訓(xùn)練的參數(shù)分布均值為0,方差為1。不同于Relu激活后無(wú)負(fù)數(shù),且分布整齊,為DCGAN網(wǎng)絡(luò)生成復(fù)雜的樣本提供了可能。
3.2 DCGAN網(wǎng)絡(luò)的圖像數(shù)據(jù)集擴(kuò)充仿真
文中分別按下面常用的5種判別網(wǎng)絡(luò)結(jié)構(gòu)和1種生成網(wǎng)絡(luò)結(jié)構(gòu)構(gòu)建。判別網(wǎng)絡(luò)與一般神經(jīng)網(wǎng)絡(luò)類似,采用卷積層-激活層的組合方式,不同的是由于訓(xùn)練參數(shù)較多,需要加入歸一化層對(duì)神經(jīng)元統(tǒng)一。在實(shí)驗(yàn)中保持了一種穩(wěn)定的生成網(wǎng)絡(luò)結(jié)構(gòu),即使用轉(zhuǎn)置卷積和Relu直接連接的網(wǎng)絡(luò)層。判別網(wǎng)絡(luò)則是設(shè)計(jì)了五種結(jié)構(gòu)仿真,其中D1采用了一種傳統(tǒng)DCGAN結(jié)構(gòu)方式,即在做激活前對(duì)所有參數(shù)歸一化,加快訓(xùn)練速度,D2和D3則是比較了bn層位置變換對(duì)整體訓(xùn)練效果的影響,D4則是將Selu加入驗(yàn)證文中方法的有效性,最后D5選取了一種與Selu更適合的Dropout方法簡(jiǎn)化網(wǎng)絡(luò)參數(shù),加快訓(xùn)練過(guò)程。D1-D5、G0分別為判別網(wǎng)絡(luò)和生成網(wǎng)絡(luò)單層結(jié)構(gòu)設(shè)計(jì)(conv1表示第一層卷積層,bn表示歸一化層,conv2表示第二層卷積層):
D1:conv1->bn->Relu->conv2
D2:conv1->Relu->bn->conv2
D3:conv1->bn->Relu->bn->conv2
D4:conv1->bn->Selu->conv2
D5:conv1->Selu->A_Dropout->conv2
G0:deconv1->Relu->tanh
當(dāng)G & D learning rate=0.000 2,batch_size=64時(shí),生成的圖片如圖5所示。

圖5 D1-D5各結(jié)構(gòu)所生成數(shù)據(jù)圖像比較
生成器D1-D5訓(xùn)練所需時(shí)間如表1所示。

表1 網(wǎng)絡(luò)訓(xùn)練時(shí)間對(duì)比 s
從表1可以看出,在判別器和生成器學(xué)習(xí)率分別為0.000 2時(shí),使用了Relu激活與Selu激活的時(shí)間相當(dāng),激活層和歸一化層對(duì)訓(xùn)練時(shí)間無(wú)明顯加長(zhǎng)。
實(shí)驗(yàn)結(jié)果表明,利用DCGAN可以有效地生成圖像數(shù)據(jù),用于擴(kuò)充數(shù)據(jù)集。在評(píng)價(jià)圖像質(zhì)量時(shí)主要采用人眼主觀評(píng)價(jià),通過(guò)手寫(xiě)體Mnist圖像生成效果,可以明顯發(fā)現(xiàn),使用了一種自歸一化激活函數(shù)的深度卷積對(duì)抗網(wǎng)絡(luò),生成的圖片更清晰,且效果整體更穩(wěn)定。如圖5展示了整體比較效果,改進(jìn)后的DCGAN網(wǎng)絡(luò)生成完整輪廓或清晰紋理圖像樣本的數(shù)量更多,出現(xiàn)概率更大。其中D1、D2為DCGAN經(jīng)典模型生成的手寫(xiě)體圖像,類似結(jié)構(gòu)D4只改變激活函數(shù)特性圖像效果有所提升,但訓(xùn)練時(shí)間相對(duì)更長(zhǎng)(見(jiàn)表1)。圖6則展示了從判別網(wǎng)絡(luò)中使用Relu和Selu生成圖像中隨機(jī)抽取的樣本,通過(guò)‘2’、‘3’上下分析比較,下行樣本質(zhì)量明顯更高更穩(wěn)定,前者方法生成的圖像存在更多模糊樣本。最后選取D5結(jié)構(gòu)得到的仿真結(jié)果表明,使用了a_Dropout算法的Selu函數(shù)網(wǎng)絡(luò)模型,不僅沒(méi)有降低圖像質(zhì)量,保持了一定的穩(wěn)定性,而且由表1可知,相較于直接替換激活函數(shù),其訓(xùn)練時(shí)間還有所減少。

圖6 分別隨機(jī)抽取使用Relu(上)和Selu(下)生成的樣本圖像
4 結(jié)束語(yǔ)
針對(duì)深度卷積網(wǎng)絡(luò)做圖像分類時(shí)數(shù)據(jù)集過(guò)小造成訓(xùn)練網(wǎng)絡(luò)時(shí)帶來(lái)的樣本特征不足及網(wǎng)絡(luò)過(guò)度擬合問(wèn)題,利用DCGAN網(wǎng)絡(luò)生成人造圖像,引入Selu作為判別網(wǎng)絡(luò)各卷積層后的激活函數(shù),結(jié)合帶參數(shù)歸一化的Dropout方法成功實(shí)現(xiàn)對(duì)圖像數(shù)據(jù)集的擴(kuò)充,并就訓(xùn)練時(shí)間和生成圖像樣本質(zhì)量,與使用Relu激活函數(shù)的DCGAN網(wǎng)絡(luò)生成效果進(jìn)行比較。實(shí)驗(yàn)結(jié)果表明,DCGAN網(wǎng)絡(luò)可以極大地豐富數(shù)據(jù)集大小;在將激活函數(shù)Relu改為Selu并結(jié)合帶參數(shù)歸一化的Dropout方法后,在選取適當(dāng)?shù)纳删W(wǎng)絡(luò)和判別網(wǎng)絡(luò)學(xué)習(xí)率和保持網(wǎng)絡(luò)訓(xùn)練速度基本不變的情況下,改善了生成圖像質(zhì)量,從而更好地為訓(xùn)練分類網(wǎng)絡(luò)提供了有利條件,實(shí)現(xiàn)了離線數(shù)據(jù)增強(qiáng)。
猜你喜歡
童話王國(guó)·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學(xué)生數(shù)理化·七年級(jí)數(shù)學(xué)人教版(2020年10期)2020-11-26 08:24:50
數(shù)學(xué)物理學(xué)報(bào)(2020年2期)2020-06-02 11:29:24
兒童故事畫(huà)報(bào)(2019年5期)2019-05-26 14:26:14
光學(xué)精密工程(2016年6期)2016-11-07 09:07:19
Coco薇(2016年2期)2016-03-22 02:42:52
核科學(xué)與工程(2015年4期)2015-09-26 11:59:03
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長(zhǎng)指南(2015年7期)2015-08-11 15:03:12
小雪花·成長(zhǎng)指南(2015年4期)2015-05-19 14:47:56
