遺傳算法優(yōu)化BP神經(jīng)網(wǎng)絡(luò)的股價預測研究
2020-04-09 01:43:04隋金城
經(jīng)濟技術(shù)協(xié)作信息 2020年7期
◎隋金城
一、引言
最近幾年,越來越多的專家學者利用神經(jīng)網(wǎng)絡(luò)算法進行股票預測,但普遍存在選取的輸入屬性過少,預測天數(shù)普遍過短的問題。因此,本文在選擇輸入屬性時,不僅僅使用所選股票金陵藥業(yè)自身的指標,還增加了深證成指和中國生物醫(yī)藥指數(shù)連續(xù)5天共計135個輸入屬性,預測金陵藥業(yè)接下來5天的收盤價。使用遺傳算法優(yōu)化BP神經(jīng)網(wǎng)絡(luò)的初始權(quán)值和閾值,構(gòu)建遺傳算法優(yōu)化BP神經(jīng)網(wǎng)絡(luò)的股票預測模型。不僅提高了預測的準確度,而且縮短了模型的運行時間。
二、GA-BP神經(jīng)網(wǎng)絡(luò)預測模型
1.BP神經(jīng)網(wǎng)絡(luò)。
BP神經(jīng)網(wǎng)絡(luò)由多個網(wǎng)絡(luò)層構(gòu)成,分別是輸入層、隱含層和輸出層。它的運行過程包含前饋傳播和反向傳播兩個部分。在前饋傳播中,信息從輸入層,經(jīng)過隱含層,到達輸出層。每一層的狀態(tài)只能影響其下一層的狀態(tài),而不能對其它層產(chǎn)生任何影響。若輸出層沒有獲得理想的輸出,則開始反向傳播,誤差信號將沿著原網(wǎng)絡(luò)返回,每一層的連接權(quán)值和閾值會逐一修改。該過程不斷迭代,直到誤差信號滿足標準。
由于BP神經(jīng)網(wǎng)絡(luò)初始神經(jīng)元之間的權(quán)值和閾值是隨機選擇的,容易陷入局部最小值。因此本文使用遺傳算法對初始神經(jīng)元之間的權(quán)值和閾值進行優(yōu)化。
2.遺傳算法。
遺傳算法是一種特殊的進化算法,包含了遺傳、變異等生物學知識。可以說,遺傳算法是一種優(yōu)化技術(shù),它試圖找出產(chǎn)生最佳輸出的輸入值。
首先要產(chǎn)生初始種群。編碼長度為輸入屬性的數(shù)量,用二進制方法編碼,編碼值為“0”或“1”。隨機產(chǎn)生 n個個體,即 n 個初始種群。
然后計算適應度函數(shù)。適應度函數(shù)是遺傳算法獲得最佳結(jié)果的關(guān)鍵,適應度越大,則個體遺傳進入下一代的概率也就越高。本文選擇誤差平方和作為適應度函數(shù)。
選擇運算選用輪盤賭方法,個體適應度越大,被選擇的可能性就越大。交叉運算使用算術(shù)交叉算子,將個體兩兩隨機配對獲得新個體。變異運算采用非均勻變異算子,隨機產(chǎn)生變異點,防止陷入局部最優(yōu),維持種群豐富性。
3.遺傳算法優(yōu)化BP神經(jīng)網(wǎng)絡(luò)。
遺傳算法優(yōu)化BP神經(jīng)網(wǎng)絡(luò)的步驟如下:
(1)初始化種群。
(2)計算適應度函數(shù)。
(3)用輪盤賭方法選擇個體。
(4)交叉、變異,獲得新個體。
(5)計算新個體的適應度。
(6)如果獲得符合預期的個體或超過設(shè)置的最大迭代次數(shù),繼續(xù)下一步。否則,返回(2)繼續(xù)執(zhí)行。
(7)解碼,獲得優(yōu)化的權(quán)值和閾值。
三、實驗與結(jié)果分析
1.實驗數(shù)據(jù)。
利用Python從開放金融大數(shù)據(jù)平臺Tushare獲取金陵藥業(yè)(000919)、深證成指(399001)和生物醫(yī)藥指數(shù)(399441)的股票數(shù)據(jù)。使用2013年1月17日到2019年3月20日共計1500個交易日的數(shù)據(jù)進行訓練。共選擇135個輸入屬性(金陵藥業(yè)、深證成指和中國生物醫(yī)藥指數(shù)連續(xù)5天的開盤價、收盤價、最高價、最低價、漲跌幅、成交額、成交量、5日均值及5日均量)。用GA-BP模型預測2019年3月21日到2019年3月27日期間5個交易日的股票收盤價。
本文特別選擇將深證成指(深圳證券交易所成份股價指數(shù))和中國生物醫(yī)藥指數(shù)加入到訓練數(shù)據(jù)。深證成指代表了所有深圳證券交易所上市公司的股票價格波動;而生物醫(yī)藥指數(shù)是一個行業(yè)指數(shù),它可以衡量中國生物醫(yī)藥行業(yè)股票的表現(xiàn)。考慮這兩個指數(shù)是因為深證成指提供了中國股市的總體情況,而生物醫(yī)藥指數(shù)則提供了中國生物醫(yī)藥行業(yè)的特定情況。
2.評價指標。
使用平均絕對誤差(MAE)、平均絕對百分比誤差(MAPE)和均方根誤差(RMSE)來衡量模型預測股價的性能。
它們的計算公式如式(1)-(3)所示。
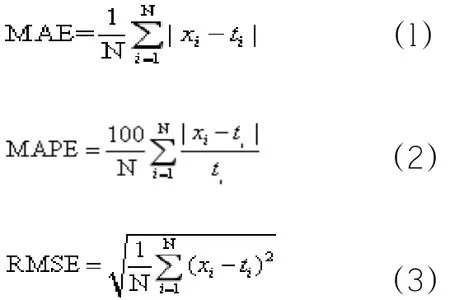
其中,xi代表第 i個樣本預測值,ti代表第i個樣本實際值,N為樣本數(shù)目。
3.實驗結(jié)果分析。
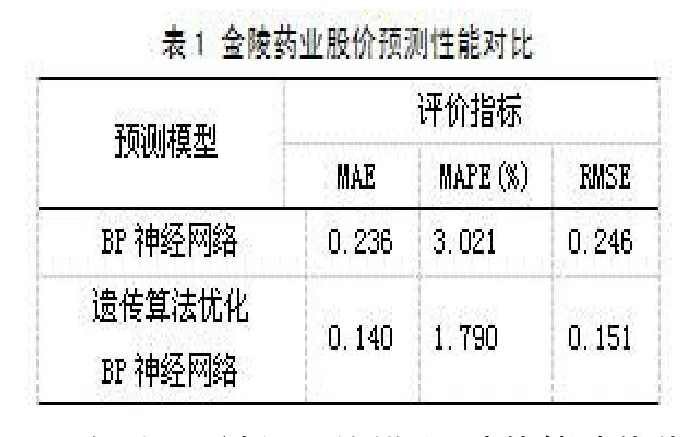
共有135個輸入屬性,預測未來5天收盤價,隱藏層為1層,神經(jīng)元個數(shù)為50個,建立3層BP神經(jīng)網(wǎng)絡(luò),拓撲結(jié)構(gòu)為135-50-5。傳遞函數(shù)方面,隱藏層使用S型正切函數(shù)tansig,輸出層使用線性函數(shù)purelin。為了消除不同數(shù)據(jù)間量級差異大而造成的預測誤差,需要對原始數(shù)據(jù)進行歸一化處理,使用matlab中的premnmx函數(shù)將網(wǎng)絡(luò)的輸入數(shù)據(jù)和輸出數(shù)據(jù)歸一化到[-1,1]。訓練算法選擇 Levenberg-Marquardt算法,可以獲得更快的訓練速度。神經(jīng)網(wǎng)絡(luò)的學習速率設(shè)為0.1,最大訓練次數(shù)1000,目標誤差0.00001。利用遺傳算法進行優(yōu)化,染色體長度設(shè)置成135,種群大小40,最大迭代次數(shù)100。對比分析BP神經(jīng)網(wǎng)絡(luò)模型和遺傳算法優(yōu)化BP神經(jīng)網(wǎng)絡(luò)模型,得到股價預測圖如圖3所示。預測性能的優(yōu)劣通過MAE、MAPE、RMSE及模型的運行時間評判,對比結(jié)果如表1所示。
?
相比BP神經(jīng)網(wǎng)絡(luò)模型,遺傳算法優(yōu)化BP神經(jīng)網(wǎng)絡(luò)模型預測準確度更高,建模時間也更短。
四、結(jié)語
本文用遺傳算法優(yōu)化BP神經(jīng)網(wǎng)絡(luò)的初始權(quán)值和閾值,構(gòu)建了遺傳算法優(yōu)化BP神經(jīng)網(wǎng)絡(luò)的預測模型,預測中國生物醫(yī)藥公司金陵藥業(yè)連續(xù)5天的股價,相較BP神經(jīng)網(wǎng)絡(luò)獲得了更好的預測效果。數(shù)據(jù)準備和初步分析是提高股票價格預測模型準確性的一個有效方法。在以后的研究中,可以嘗試加入更多相關(guān)的輸入屬性進行預測,以求獲得更好的預測效果。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
房地產(chǎn)導刊(2022年5期)2022-06-01 06:20:14
建材發(fā)展導向(2021年12期)2021-07-22 08:06:48
建材發(fā)展導向(2021年7期)2021-07-16 07:07:52
中學生數(shù)理化(高中版.高二數(shù)學)(2021年12期)2021-04-26 07:43:48
中學生數(shù)理化(高中版.高考數(shù)學)(2021年12期)2021-03-08 01:28:50
中學生數(shù)理化·七年級數(shù)學人教版(2020年10期)2020-11-26 08:24:50
數(shù)學物理學報(2020年2期)2020-06-02 11:29:24
光學精密工程(2016年6期)2016-11-07 09:07:19
核科學與工程(2015年4期)2015-09-26 11:59:03
