風電機組齒輪箱高溫故障分析與預測
2020-04-19 07:08:45銀磊孫啟濤魯納納
風能 2020年12期
銀磊 孫啟濤 魯納納
近年來國內風電裝機容量不斷增加,齒輪箱作為風力發電機組的關鍵部件,雖然制造工藝已成熟,但是風力發電機組工作環境的特殊性和承受載荷的復雜性致使齒輪箱易發生故障和損壞,而且損壞一旦觸發,其維修過程相對復雜,造成機組停機時間較長,嚴重影響風電機組的安全性和經濟性,因此對風電機組齒輪箱的故障進行預測及識別變得尤為重要。
齒輪箱高溫不僅會導致風電機組限功率運行或超溫停機,而且無法保證滿負荷運行機組的穩定性。有些廠家為了回避此問題,調高油溫報警閾值,但此方法給齒輪箱的潤滑造成嚴重危害,使齒面容易出現膠合現象。另外,現今基于齒輪箱高溫故障的研究大多集中于結構設計方面的技術升級,雖然提出的方案有一定的效果,但還不夠理想。為了更好地解決此類問題,基于齒輪箱高溫故障預測的預防性維修將逐漸發展為有效的手段之一。換言之,風電機組部件的故障預測技術在一定程度上能夠有效避免部件因突發失效進而導致故障事故發生。
當前關于風電機組故障分析與預測的研究存在明顯不足,如基于長短時記憶神經網絡(Long Short -Term Memory,LSTM)對齒輪帶故障進行預測,能夠有效提高齒輪帶斷裂故障預測的精度,但是在訓練時間成本上并沒有顯著的優勢。基于復數據經驗模態分解和隨機森林(Random Forest,RF)理論的風電機組多域特征故障診斷研究,驗證了隨機森林具有很高的準確率,卻未考慮齒輪箱高溫故障從早期出現微弱特征到徹底失效需要經歷一個漸變演化過程等等。故本文提出采用長短時記憶神經網絡和隨機森林組合模型LSTM-RF進行風電機組齒輪箱高溫故障(包括齒輪箱驅動端軸承溫度高、齒輪箱非驅動端軸承溫度高及齒輪箱油溫高三類)預測,該模型考慮了故障特征演變的時變性和周期性。仿真結果驗證了混合模型能夠有效提高齒輪箱高溫預測精度,并且具有較高穩定性,可以實現提前預測未來一周齒輪箱高溫故障。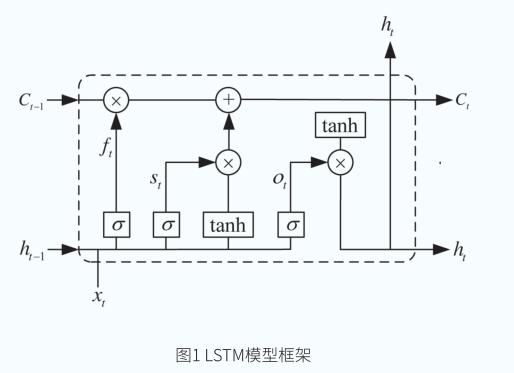
齒輪箱高溫預測模型理論分析
一、LSTM的原理
LSTM作為RNN的改進模型,其實質為在RNN基礎上引入“門”的概念,由控制“門”的手段來控制新信息對已存信息神經元的擾亂程度,從而能夠有效地保留歷史信息。如圖1為LSTM模型架構,LSTM的關鍵在于細胞的狀態和穿過細胞的水平線。細胞狀態類似傳送帶,直接在整個鏈上運行,只涉及少部分的線性交互,因此信息在上面流傳不易發生改變。LSTM通過忘記門、輸入門和輸出門這三個“門”來控制細胞狀態,“門”結構支持LSTM更新或丟棄信息,及更新細胞狀態。

二、RF的原理
隨機森林分類模型針對多變量的分類效果較好,不易出現過擬合,但結果與參數選擇有關,因此需要進行參數調優。隨機森林使用重采樣方法從原始樣本中抽取多個子樣本的數據,為每個子樣本建立決策樹模型,然后結合多個預測結果,通過投票方式來獲得最終的預測分類。
RF是Bagging的擴展版本,套袋仍是它的主要思想,但它基于套袋做了一些獨特的改進。首先,RF的基本分類器是CART決策樹;其次,在決策樹的訓練過程中引入隨機屬性選擇,進一步提高模型的泛化能力,原理如圖2所示。
三、LSTM-RF的原理
傳統的齒輪箱高溫故障診斷方法集中于齒輪箱溫度異常診斷流程或者溫度高原因分析及解決方法,以風電機組齒輪箱潤滑系統原理及高溫原因分析為切入點,提供合理的處理方案,在一定程度上能有效降低齒輪箱油溫,避免齒輪箱高溫停機,延長其剩余壽命。或者通過對齒輪箱潤滑油冷卻系統熱交換器傳熱原理進行分析,通過改變散熱器翅片結構,解決齒輪箱油溫高問題—— 該方法雖然在齒輪箱故障技改上得到推廣使用,但是缺乏預測性的分析,只考慮齒輪箱潤滑系統設計層面的研究及導致此現象的可能因素,忽略了時間相關特征為在預測過程中需要考慮的關鍵因素等等。
風電機組齒輪箱故障由初期出現微弱跡象漸變演化為徹底失效的過程伴隨著較強的時間序列性,本文提出的組合模型LSTM-RF考慮了齒輪箱油溫高的數據在時間上的特征空間域,提高了齒輪箱高溫預測的精度,選取隨機森林主要用以特征篩選及參數調優。仿真實驗結果表明,該組合模型在故障時間序列預測中具有較高的精度,其基本框架如圖3所示。
預測模型建立
通過對采集的數據進行預處理、特征選取以及LSTMRF模型訓練,從而實現預測效果。其中,在數據采集階段,考慮到數據集過于龐大,倘若以秒級數據作為訓練樣本會導致訓練時間成本太高,故對原始數據以1分鐘為基準進行等距壓縮處理。考慮到實時數據運算等操作的時效性,采用固定間隔采樣,以此獲取故障樣本和正常樣本。建模流程如圖4所示,其主要包括:
1. 數據壓縮、清洗
通過數據抽樣方式獲取故障樣本和正常樣本,作為特征提取樣本。
2. 多重K-means聚類去除冗余數據
K-means實現數據的聚類,并對每行數據打上類別標簽。設某部件的故障種類數為c,則多重K-means聚類的指定聚類K值為從c到2c。在多個K值的聚類時,若某批數據的類別標簽始終相同,則這批數據的數據特征相近,將其視為同類型數據,將這批數據的行數記為X—— 若X極小,則認為這些數據在聚類過程中貢獻值極小,視為冗余、噪聲數據,將其從訓練集中剔除,最終生成新的數據集。

(2)計算這批數據中每行數據與中心點的歐式距離;
(3)取距離中心點最近的前80%的數據行數,剩余的剔除;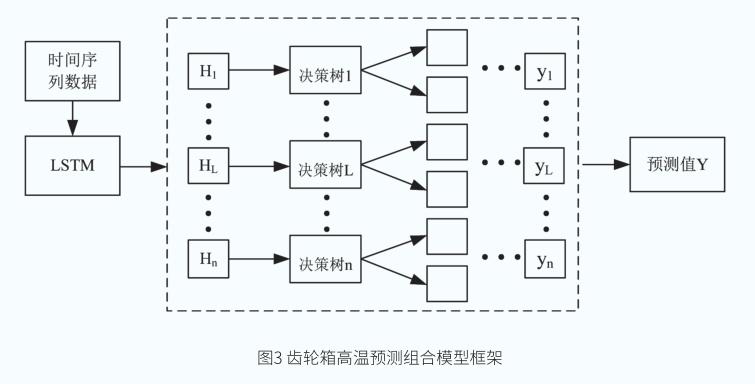


(4)生成新的訓練集。
3. 隨機森林+專家經驗篩選特征點位
(1)將訓練集輸入到多個隨機森林,輸出每個維度的特征在分類器模型的貢獻值,若某個特征的貢獻值大于0.05,則判為重要特征;
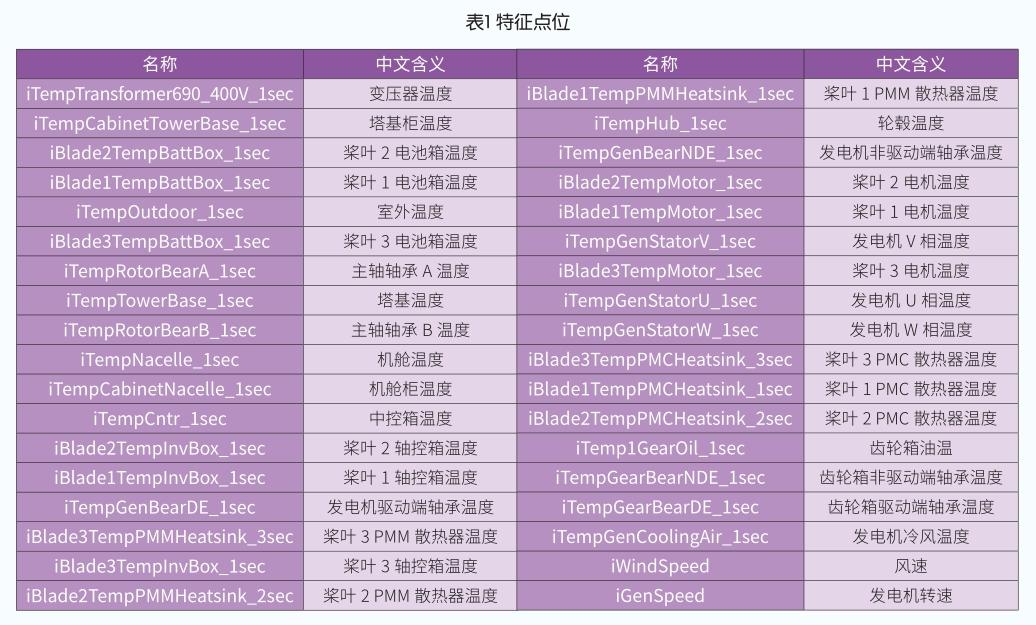
(2)將篩選出的特征和經驗特征結合,使用經驗點位和刪除點位來更新特征點位,即保證最終選取的結果中包含所有的經驗點位,然后采用皮爾遜相關系數的計算,去除關聯較大的變量,最終,得到的特征點位如表1所示。
4. 模型訓練及預測
利用處理后的數據進行模型訓練及預測。
預測結果分析
組合模型LSTM-RF是用LSTM對處理后的數據進行計算,將得到的結果作為隨機森林的輸入,利用投票法確定LSTM預測的結果中有沒有故障。由仿真結果可知,LSTMRF預測模型非常適用于處理與時間序列高度相關的齒輪箱油溫高等問題。在故障為齒輪箱驅動端軸承溫度高、齒輪箱非驅動端軸承溫度高及齒輪箱油溫高的情形下,LSTM-RF預測模型的準確率及召回率如表2所示。由表2可知,運用組合模型LSTM-RF進行風電機組齒輪箱高溫故障預測具有一定的可行性。
基于隨機森林特征選擇,對比分析LSTM-RF與XGBoost、AdaBoost、GBDT和RF等機器學習算法在相同測試集上的訓練時間成本和準確率,結果如表3所示。由表3易知,LSTM-RF相比其他幾種機器學習算法,具有較高的齒輪箱高溫故障預測準確率,比其他機器學習預測算法平均提高3.35%;盡管GBDT和RF的時間成本低,但GBDT和RF 均是以決策樹為基礎的,其預測準確率比LSTM-RF略差。因此,綜合來看,LSTM-RF用于齒輪箱高溫故障預測較為可行。
結論
為捕捉風電機組齒輪箱高溫初期故障,達到高溫故障預測的效果,本文構造了LSTM-RF組合模型:與其他預測模型相比,該模型考慮了故障漸變過程,非常適合處理與時間序列高度相關的問題;由案例仿真分析結果可知,LSTMRF可以實現故障分析及預測的目的。除此之外,相比XGBoost、AdaBoost、GBDT和RF機器學習算法,LSTMRF具有較優的預測精度,可進一步研究其在風電機組其他大部件上應用的可行性。
(作者單位:明陽智慧能源集團股份公司)
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
汽車維修與保養(2019年7期)2020-01-06 03:30:42
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
光學精密工程(2016年6期)2016-11-07 09:07:19
汽車維護與修理(2016年10期)2016-07-10 08:17:41
汽車維修與保養(2015年6期)2015-04-17 03:31:50
