古籍數字化中計算機自然語言處理應用現狀分析*
2020-05-07 03:42:36馬海麗
古籍研究 2020年2期
馬海麗 王 曦
關鍵詞:古漢語;古籍數字化;分詞;詞性標注
中國漢語典籍浩如煙海,但因其歷史久遠、難理解、無句讀等問題,人們難以研讀學習。雖有不少古漢語工作者堅持傳承傳統文化,但因標點斷句等基礎性工作而耗費了大量的時間和精力。“我們期望能有可以用於漢語史電子文獻自動分詞、自動斷句、自動標注的軟件早日問世, 專家只需對結果刊謬補缺,這將大大減輕屬性式標注的勞動強度,加快工作進度。”(1)尉遲治平:《計算機技術和漢語史研究》,《古漢語研究》2000年第3期,第56—60頁。尉遲治平的呼籲反映了衆多古漢語工作者的心聲。採用計算機自然語言處理技術實現對古代典籍自動化處理,承載著學者們殷切的希望,也是傳承中華文明的重大責任。
隨著近年來自然語言處理技術的發展,現代漢語分詞與詞性標注工作已經取得了頗爲優秀的成果,但是在古漢語處理方面的研究是較爲薄弱的。目前對古籍文獻處理現代化的研究主要是字的輸入、輸出、建立電子資源庫,在詞彙、語義層面上的研究卻是寥寥。本文將綜合多篇相關論文討論古籍數字化自然語言處理的研究現狀。
一、 古籍數字化現狀
想要實現對古籍文獻處理的現代化,構建古漢語語料庫是最爲基礎的工作。相關研究最早是從計算機技術較爲發達的美國開始的,直到20世紀80年代,海岸兩峽及香港相繼開始研發中文古籍數字化專案。1984年,中國臺灣“中研院”開始“史籍自動化計劃”,計劃開發《二十五史(全文資料庫)》全文資料庫,後又於1990年著手建立“古漢語語料庫”。經過三十多年不懈努力,現已整理建設了一個具有數億字的古籍資料庫,具有重要實用價值。其次,香港中文大學在1988年開始著手古漢語典籍的數字化建設,建立了“漢達文獻資料庫中心”,該中心致力於將全部出土文獻收入文獻資料庫。相較於臺灣、香港地區,大陸地區的古籍數字化建設相對起步較晚,1998年成立北京愛如生數字化計算研究中心進行相關研究。雖起步較晚,但發展速度迅猛,國家、地方高校及商業機構都在積極研發相關專案,如現有規模較大的“北大CCL古代漢語語料庫”“國家語委古籍語料庫”“中華古籍語料庫”等語料庫。
學者對古籍數字化的研究不僅體現在上述語料庫的構建方面,相關的理論研究也在逐步深入。2014年常繼紅和魏曉峰發表的《國內古籍數字化研究進展與啓示》(2)常繼紅、魏曉峰:《國內古籍數字化研究進展與啓示》,《河北科技圖苑》2014年第3期,第82—85頁。中,以中國知網(CNKI)全文期刊資料庫爲樣本,以“古籍數字化”爲檢索詞,選定2001—2013的特定年限進行模糊檢索,經過人工資料篩選處理,排除不相關數據,最後得到國內CNKI期刊論文數據361條。發文量總體呈穩步增長的態勢,21世紀初期發文量增長平緩,自2004年開始迅速增長,年均論文數達到28篇,其中2012年達到最高值52篇,研究成果主要集中在圖書情報與檔案文獻等領域,同時廣泛涉及中文、教育、醫藥、計算機技術、信息工程等專業領域。研究熱點主要有6個方面,如圖表所示。
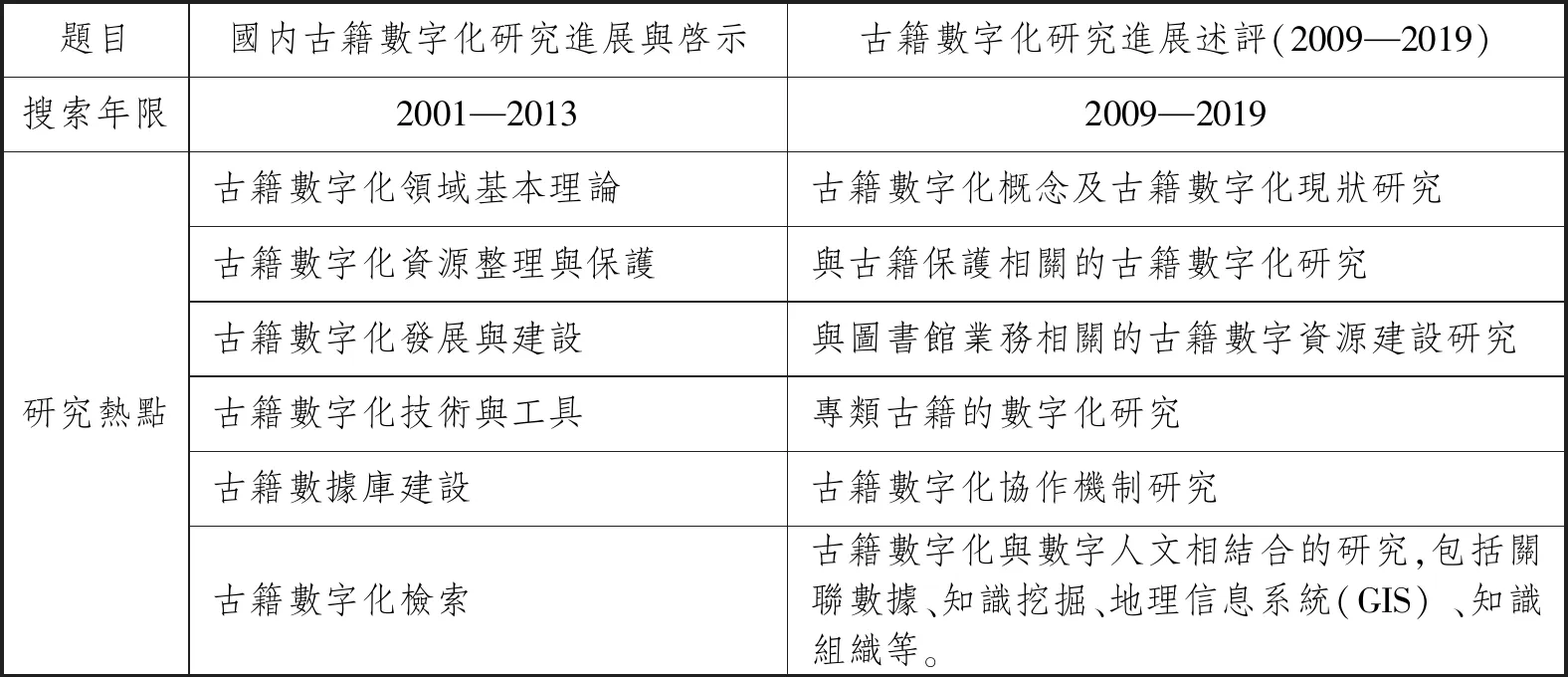
古籍數字化研究熱點對比圖表
2020年李明傑、張纖軻、陳夢石發表的《古籍數字化研究進展述評(2009—2019)》(3)李明傑、張纖軻、陳夢石:《古籍數字化研究進展述評(2009—2019)》,《圖書情報工作》2020年第6期,第130—137頁。,同樣以中國知網(CNKI)全文期刊資料庫爲樣本,以“古籍”“數字化”等爲主題,以2009年至2019年爲時間限定,篩選、剔除後得到759條相關結果。結果顯示研究者多來自于不同的學科背景,研究主題較爲分散,成果主要還是涉及圖書情報、文史、醫藥等,但在計算機方面的研究有所增加。作者將研究熱點也歸爲6個方面,如圖表所示。
對比兩篇文章中的研究熱點,不難發現,學者對於古籍數字化的研究,理論方面、技術層面都在不斷深入,且始終秉持著通過古籍數字化實現古籍再生性保護的信念,國家、高校、商業機構之間也在不斷地進行統籌協作,努力實現各類古籍資源的共用;各學科的古籍整理也在不斷的精細化,同時也在不斷加強學科之間的交叉研究。但是,縱觀古籍數字化的理論研究與不同高校、機構之間的實際語料庫整理可以發現,古籍數字化還未能構建出一套完整的學術規範體系,以至於無法保障古籍數字化的品質;其次,進行古籍數字化研發,一方面是爲了保護古籍資源,但另一方面也是爲相關的人文社會科學研究者進行古籍知識研究提供服務,但目前多數古籍數字化研發停留在文本的輸入、輸出層面,深度的處理技術層面還遠不能滿足古籍工作者的需求。
二、 古漢語分詞、詞性標注技術
(一) 分詞、詞性標注簡述
分詞是指將一個句子中的字元切分爲詞的過程,是中文信息處理的最基礎研究工作。關於自然語言處理系統,國內研究相較於國外,起步較晚。中文分詞系統始於20世紀80年代初北京航空航天大學的CDWS(Chinese Distinguishing Word System),在該系統研發過程中,研究人員首次論證了中文分詞的可行性並初步建立了相關的計算模型。隨後,中文分詞研究在國內興起一片浪潮,更多的研究人員投身其中,取得豐碩的研究成果。首先在分詞方法方面,常見的主要分爲三種:機械分詞方法、基於規則的分詞方法和基於統計的分詞方法。在基於統計的分詞方法中,最基本的方法包括隱馬爾科夫模型(HMM)、最大熵馬爾科夫模型(MEMM)以及條件隨機場模型(CRF)。利用上述方法開發且已開放的引擎有中國科學院技術研究所的ICTCLAS分詞系統、SCWS分詞系統、搜狗分詞、結巴分詞、盤古分詞、庖丁解牛等。
詞性標注是指在給定句子中判定每個詞的語法範疇,確定其詞性並加以標注的過程,這也是自然語言處理中一項非常基礎且重要的研究工作。詞性標注的研究分爲標注集的研究和方法的研究。在詞性標注集方面,對於同一種自然語言,劃分標注集時,多是根據不同的應用目的針對性地制定相應的劃分標準,所以目前還沒有統一的詞性標注集。在詞性標注方法方面,研究者的方向主要集中在兩種,一種是基於規則的方法,一種是基於統計的方法。在基於規則的方法中,最基礎的就是先要制定出一個有一套標注規則集的規則庫,但因爲語言表達的相對抽象性,人們難以制定出一套十分完備的規則集,且過多的規則,相互之間又會産生種種衝突。所以,基於規則的方法因自身的矛盾性漸漸退到邊緣,基於統計的標注方法逐漸成爲詞性標注研究的主流方法。另外,因爲詞性標注任務和分詞任務兩者從本質上講都是序列標注任務,所以研究人員多採用相同模型來解決此類問題,即隱馬爾科夫模型(HMM)、最大熵馬爾科夫模型(MEMM)以及條件隨機場模型(CRF)等。
(二)應用實例
歷史進程的推進,隨之而來的時代特徵也是在不斷變化的,這些特徵不僅僅是表現在社會的政治、經濟方面,文化方面的變化也是顯著的,僅僅聚焦在字詞的形、音、義及使用規則這一小點上,時代的差別性也是顯而易見的。所以,對漢語史進行時代的劃分,明確界定古籍所屬時代是十分重要的。目前對於漢語史的分期問題,學界還有爭議,不過方一新所持觀點:“以東漢爲界,把西漢列爲過渡期和參考期,把古代漢語分爲上古漢語和中古漢語兩大塊,以東漢魏晉南北朝隋爲中古漢語時期,從語法、詞彙上看都是比較合理的。”(4)方一新:《從中古詞彙的特點看漢語史的分期》,《漢語史學報》第4輯,上海教育出版社2004年,第178—184頁。基本被學界認同。所以可基本明確:漢語史分期,可以東漢爲界,在大約3世紀以前的是上古漢語;東漢其下的是中古漢語;南宋(大約13世紀)之後,則是近代漢語;1919年五四運動以來,就是現代漢語。
(1) 上古漢語古籍研究
對上古漢語古籍文獻的自動分詞、詞性標注的研究是一個循序漸進的過程。臺灣“中研院”的“漢籍電子文獻”在對以《十三經》爲主的先秦文獻進行分詞和詞性標注時,以較爲傳統的最大概率和隱馬爾科夫模型爲主;其後邱冰、皇甫娟提出啓發式的混合分詞方法,以反向最大匹配分詞爲主,針對《論語》《國語》等21種古代漢語語料進行研究(5)邱冰、黃甫娟:《基於中文信息處理的古代漢語分詞研究》,《微計算機信息》,2008年第24卷第8—3期,第100—102頁。;石民、李斌、陳小荷以《左傳》爲例,採用條件隨機模型(CRF),通過自動分詞、詞性標注、分詞一體化的對比實驗,證明了一體化分詞比傳統先分詞後標注的“兩步走”方法更有效(6)石民、李斌、陳小荷:《基於CRF的先秦漢語分詞標注一體化研究》,《中文信息學報》,2010年第2期,第39—45頁。。
梁社會、陳小荷《先秦文獻〈孟子〉自動分詞方法研究》(7)梁社會、陳小荷:《先秦文獻〈孟子〉自動分詞方法研究》,《南京師範大學文學院學報》,2013年第3期,第175—182頁。以先秦文獻《孟子》爲例,研究了上古漢語古籍的分詞方法。文中採用了兩種分詞方法:1. 基於條件隨機場統計模型的自動分詞方法;2. 利用注疏文獻的自動分詞方法。在基於條件隨機場統計模型的分詞實驗中,採用《左傳》《論語》作爲訓練語料,根據古漢語的語料構成,選取了簡單字面信息和複雜漢字特徵作爲文本特徵進行自動分詞實驗,值得一提的是在複雜漢字特徵中作者將漢字的聲、韻、調及部首信息涵蓋其中。最終結果爲:基於上下文3個漢字、三字同現、並考慮字元分類的模板“3W+3+C1”,是最適合《孟子》的自動分詞的。其中,在字元基礎上再增加聲、韻、調及部首信息,實驗效果差別不大。僅就聲韻方面究其原因,一方面上古漢語的聲、韻、調皆是後人構擬的,沒有準確的標準,作者選用描寫中古漢語的《廣韻》字表作爲基本資料庫,這其中肯定會産生不可避免的誤差;另一方面因爲漢字有一字多音的特性,以及上古漢語的文獻中會有很多的通假字、諧音等,漢字的聲、韻、調在不同的詞性或者義項下往往又是不同的。這方面問題還是值得學者們深入研究的。其次作者還進行了利用注疏文獻幫助自動分詞的實驗。這也是一種另闢蹊徑的辦法,可以説作者以一種獨特的眼光抓住了古漢語分詞的優勢,上古漢語文獻年代久遠,一些字詞句的含義,後人難以理解,因此産生了大量的注疏文獻,這些注疏文獻的存在,恰好爲計算機的機器學習提供了一個重要的語言知識庫。最後的實驗結果也證明這種方法行之有效,是進行古籍文獻信息處理的新方法。
留金騰、宋彥、夏飛的《上古漢語分詞及詞性標注語料庫的構建》(8)留金騰、宋彥、夏飛:《上古漢語分詞及詞性標注語料庫的構建:以〈淮南子〉爲範例》,《中文信息學報》,2013年第6期,第6—15,81頁。以《淮南子》爲文本,採用自動標注和人工校正相結合的方法構建深加工的上古語料庫。首先文章以《淮南子》爲底本分析了上古漢語詞語的特點,主要集中在古漢語複音詞的構詞特點、詞語的形態特徵和詞語的詞性轉化三個方面,深入細緻的分析,爲下文的實驗提供了很好的特徵模板。在進行分詞、標注實驗過程中,該文創造性的提出,在適應領域方面,採用半監督學習領域適應技術,將基於現代漢語訓練的模型應用到古漢語的分詞任務中,且取得較爲理想的效果。在進行詞性標注實驗中,綜合分析了前人的實驗結果,爲了取得更爲理想的詞性標注結果,拋棄了其他學者常用的分詞和詞性標注的聯合解碼,而採用串列的分詞+標注的方案,實驗結果也證明了其方法的有效性。同時,該文最後基於人工校正的實際情況匯總了自動分詞和詞性標注時産生的常見錯誤,爲後來者的研究提供了很好的借鑒。
魏一《古漢語自動句讀與分詞研究》(9)魏一:《古漢語自動句讀與分詞研究》,北京:北京大學碩士學位論文2020年。結合最新的深度學習技術,提出古漢語的BERT預訓練模型,以期更好地解決古漢語研究中的句讀與分詞問題。在進行古漢語分詞任務時,作者以《左傳》作爲測試語料,首次嘗試使用無指導方法,通過將非參數貝葉斯模型與預訓練BERT深度學習語言建模方法相結合。經測試,隨著訓練集使用資料量的增大,其分詞效果能取得與有指導訓練下測試的相同結果,甚至在準確率、召回率等值上遠超前人基於CRF方法取得的數值。並且在使用有指導訓練後,這一模型表現出極佳的泛化能力和穩定性,具有很大的實用化潛力。最值得肯定的是,作者提出的這一新方法不僅可以利用無標注文本,而且不需要除了分詞以外的任何語言學特徵標注,這無形中就解決了前人研究中的一大難題,即需要考慮漢字聲、韻、調、部首信息等各種複雜的特徵,極大的降低了工作成本。
(2) 中古漢語古籍研究
王嘉靈以中古時期的傳世文獻《漢書》爲例,從詞彙獲取和字標注兩個層面探討了古代漢語分詞的多種方法(10)王嘉靈:《以〈漢書〉爲例的中古漢語自動分詞》,南京:南京師範大學碩士學位論文2014年。。首先在詞彙獲取層面,作者結合中古時期的詞彙特徵,針對性地做出《漢書》 詞語的切分細則,並且創造性地提出關於疑難字串的處理辦,雖是淺嘗輒止,但是這方面的研究還是值得大家深入探究。在上述工作的基礎上,作者對《漢書》中的專有名詞和已登録詞這類特殊的複音詞進行了匯總處理,整理出人名表、地名表、先秦沿襲詞表、互信息詞表以及注疏詞表五張詞表,分別統計了單個詞表及各個詞表組合後對分詞結果的影響。最後得出結論:加入專名詞表和注疏詞表的分詞結果要明顯優於其他詞表的分詞結果。這一結果也表明,將多個詞表綜合運算並不代表其分詞效果就最好,古漢語詞彙的表達、劃分是極其複雜的,且進行分詞時過多的細則反而會影響分詞的結果。其次在字標注層面,利用CRF模型對《漢書》進行了一系列的實驗,選用了字元分類,中古聲、韻,上古聲、韻等語言特徵來輔助分詞,最終結果表明:增加了字元分類和上古音的1W+2+C1’5’模板在特徵二元同現的情況下分詞效果可以達到最優。同時從音韻學角度來看,《漢書》屬於中古時期的文獻,但是在上古音語音特徵的輔助下分詞效果較好,也表明了漢語發展的繼承性,因爲中古語音中仍保留著上古語音的特徵。
王曉玉《中古漢語語料庫分詞不一致問題研究》(11)王曉玉:《中古漢語語料庫分詞不一致問題研究》,南京:南京師範大學碩士學位論文2016年。從中古漢語語料庫中選取史書、佛經、小説三類共28萬餘人工分詞語料,通過計算機自動處理和人工校對的方法,分析匯總出中古語料分詞不一致現象産生的原因和分類,並提出初步解決的設想方案。在上述研究的基礎上,王曉玉、李斌發表《基於CRFs和詞典信息的中古漢語自動分詞》(12)王曉玉、李斌:《基於CRFs和詞典信息的中古漢語自動分詞》,《數據分析與知識發現》,2017年第5期,第62—70頁。,針對中古漢語中常常發生分詞不一致的字串,制定並優化分詞規範,以此規範校準人工分詞語料,然後將整理後的語料,引入字元分類和字典信息兩種特徵進行隨機場分詞實驗。最後認爲,在有效提高分詞一致性的前提下,字元分類、詞典標記特徵能夠有效提高中古漢語CRFs分詞的精確度。
古漢語的自然語言處理除上文提到的分詞和詞性標注技術之外,還有一項較爲基礎性的研究工作——斷句標點(也稱句讀)。國內利用計算機對古籍進行自動標點的研究,最初多是集中在詩歌、韻文方面。1997年,北京大學計算機語言研究所和北京大學古文獻研究所合作開發《全宋詩》系統,該系統可根據已儲存的韻書和押韻規則自動判斷任一詩作的押韻狀況與韻腳,這可視爲利用計算機對古籍進行自動斷句標點的先聲。後臺灣陳郁夫先生在進行《古今圖書集成》項目時,成功實現對句法嚴整,兼有押韻的收録詩文詞賦的“藝文”、“選句”,約1700萬字韻文的自動標點。隨著計算機技術的發展,對古籍進行自動斷句標點的研究也有了較大突破,其常用方法與分詞、標注技術相同,有基於規則和基於統計的兩種方法。目前,魏一(13)魏一:《古漢語自動句讀與分詞研究》,北京:北京大學碩士學位論文2020年。等人利用較爲流行的深度學習技術,又提出使用BERT預訓練模型加微調來解決斷句標點任務,取得較爲可觀的效果。同時針對古籍文本無句亦無段,可能長達若干千字的連續文本,設計了基於滑動視窗的句讀方法,使得模型可處理的序列長度不受限制,具有較強的實用性。
深入研究斷句標點、分詞、標注技術的同時,學者們也在努力開拓新的疆土,例如利用計算機對古漢語進行自動句法語義分析,但相關研究較少,現有馮秋香《基於數據庫語義學的古漢語句法語義分析研究》(14)馮秋香:《基於數據庫語義學的古漢語句法語義分析研究》,大連:大連理工大學博士學位論文2011年。,馮秋香等《數據庫語義學在古漢語自動分析上的應用》(15)馮秋香、汪榕培:《數據庫語義學在古漢語自動分析上的應用》,《大連理工大學學報》2012年第6期,第902—907頁。;樹庫構建方面,因古漢語的句法標注資源較少,樹庫的構建多是在小樣本集上的嘗試,如John Lee等構建的唐詩依存樹庫,彭煒明等選取《論語》等語料構建的圖解樹庫(16)何靜、宋天寶、彭煒明、朱淑琴、宋繼華:《基於“詞—詞性”匹配模式獲取的古漢語樹庫快速構建方法》,《中文信息學報》,2017年第31卷第4期,第114—121頁。;研究方法上,有學者開始探究利用最新流行的深度學習方法設計針對古漢語分詞的長短時神經網絡,但相關研究較少,現有如高毅《基於長短時神經網絡的古漢語分詞系統》(17)高毅:《基於長短時神經網絡的古漢語分詞系統》,《自動化與儀器儀錶》2020年第2期,第128—131頁。。
三、 結語
綜上所述,我國在古漢語自然語言處理研究的過程中有值得肯定的地方,也有其不足之處。值得肯定的是,無論是對上古漢語古籍的研究還是對中古漢語古籍的研究,學者都在盡自己最大的努力一步步深入,不斷提出新的研究思路。例如,學者在進行分詞、標注研究時,將漢字的形、音作爲輔助工具,不單單是從技術上革新,更多關注到理論知識層面,解構漢字的形、音本質。能與時俱進,將最新技術運用到古漢語的具體研究中,即深度學習技術的應用。其不足之處在于,古漢語信息處理技術需要跨學科研究,研究者知識儲備不足時,相關研究只能淺嘗輒止,如上文提到的《漢書》中疑難字串的處理,這就需要進一步加強學科之間的交流合作或培養知識更加全面的人才。同時,無論是在古漢語語料庫構建方面還是在古漢語分詞、詞性標注方面,其成果遠遠比不上現代漢語,未能達到古漢語研究者的期望。除此之外,筆者查找論文時發現,關於古漢語自然語言處理研究的文章較多集中在2014—2017年,近幾年發表的文章寥寥無幾,這是一個令人擔憂的現象,古漢語自然語言處理技術藴藏著巨大的潛能,值得人們深入挖掘。
