基于GPU的LDPC增強準最大似然譯碼器并行實現
2020-05-18 11:07:44孔飛躍蔣學芹萬雪芬陳思井
計算機工程 2020年5期
孔飛躍,蔣學芹,萬雪芬,陳思井,崔 劍,楊 義
(1.東華大學 信息科學與技術學院,上海 201620; 2.華北科技學院 a.河北省物聯(lián)網監(jiān)控工程技術研究中心; b.計算機學院,河北 廊坊 065201; 3.武漢船舶通信研究所,武漢 430205; 4.北京航空航天大學 網絡空間安全學院,北京 100083)
0 概述
低密度奇偶校驗(Low Density Parity Check,LDPC)碼是一種線性分組碼,其糾錯能力可以接近香農極限。LDPC碼校驗矩陣構造靈活、時延小,低密度性使其譯碼復雜度低,且譯碼方式可用并行操作實現。在許多工業(yè)協(xié)議中都采用了LDPC碼,如DVB-S2、DVB-T2、WiFi(802.11n)、WiMAX(802.16e)和5G移動通信系統(tǒng)。
由于5G移動通信系統(tǒng)標準中要求更高的吞吐量,因此針對LDPC譯碼器提出專用集成電路(Application Specific Integrated Circuit,ASIC)[1]和現場可編程門陣列(Field Programmable Gate Array,FPGA)實現方案[2-3],但是,這些方案的設計成本較高且功能單一。近年來,GPU因高計算能力得到廣泛應用,如文獻[4-5]將GPU分別用在H-Storm平臺和視頻加速解碼上,因為其可以同時執(zhí)行多個線程,峰值達到每秒萬億次浮點運算的處理能力。與ASIC和FPGA方案相比,基于GPU的解決方案更便捷,可擴展性和靈活性也更好。基于GPU的LDPC譯碼器實現已經取得較大進展。文獻[6-7]在GPU平臺上采用壓縮基矩陣的方式,設計一種大規(guī)模并行譯碼方案。文獻[8-9]在GPU上實現了LDPC卷積碼譯碼器。文獻[10-11]提出壓縮奇偶校驗矩陣,并充分利用共享內存提高譯碼速度。文獻[12-13]在GPU上實現了收斂速度更快的分層調度LDPC碼譯碼算法。文獻[14]根據規(guī)則LDPC碼Tanner圖中的邊,提出一種邊并行譯碼方案,以最大化利用GPU內的線程。文獻[15]在GPU上實現了連續(xù)變量的量子秘鑰分發(fā)方案。文獻[16]在GPU上實現了非二進制LDPC碼的譯碼器。
為降低譯碼器的誤幀率(Frame Error Rate,FER),一些研究者提出在傳統(tǒng)置信傳播(Belief Propagation,BP)譯碼算法譯碼失敗后引入再處理過程,按照相關規(guī)則對輸入的碼字選出一些點進行飽和處理,對飽和處理后的碼字序列重新進行BP譯碼,這樣能大幅提高譯碼器的糾錯性能[17-19]。文獻[19]提出增強準最大似然(Enhanced Quasi-Maximum Likelihood,EQML)LDPC譯碼器,利用更準確的節(jié)點選擇方法和合理的譯碼停止規(guī)則提高了糾錯性能,但其譯碼速度卻大幅下降。
針對譯碼器譯碼速度下降的問題,本文基于GPU平臺,利用LDPC奇偶校驗矩陣壓縮存儲、核函數BP算法譯碼重排、再處理過程多碼字并行譯碼、內存訪問優(yōu)化及流并行譯碼方案,設計針對EQML譯碼器的并行化實現方案,在保持譯碼器的糾錯性能的同時提高譯碼速度。
1 基于LDPC碼的EQML譯碼算法
當LDPC碼長較長時,若校驗矩陣中沒有短環(huán),則BP譯碼算法中節(jié)點輸出的消息可以成功收斂。然而,當碼長較短時,校驗矩陣存在大量的短環(huán),短環(huán)中的各節(jié)點在迭代過程中具有相關性,消息在迭代過程中變得不可靠,所以短環(huán)的存在會造成譯碼性能的急劇下降。為解決短環(huán)導致的性能損失,文獻[17]提出一種準最大似然(Quasi-Maximum Likelihood,QML)譯碼器。文獻[19]提出的EQML譯碼器能夠在0.3 dB的FER范圍內達到接近最大似然(Maximum Likelihood,ML)的譯碼性能。
基于LDPC的QML譯碼器的譯碼過程具體為:1)對輸入的碼字進行BP迭代譯碼,如果譯碼成功,則繼續(xù)下一個碼字,反之執(zhí)行再處理過程;2)對譯碼失敗的碼字進行節(jié)點選擇,選出最不可靠的節(jié)點進行飽和處理,對飽和處理后的碼字序列再次進行BP迭代譯碼,直至到達最大階段數,最終選出最優(yōu)碼字輸出,QML譯碼器的整體流程如圖1所示。
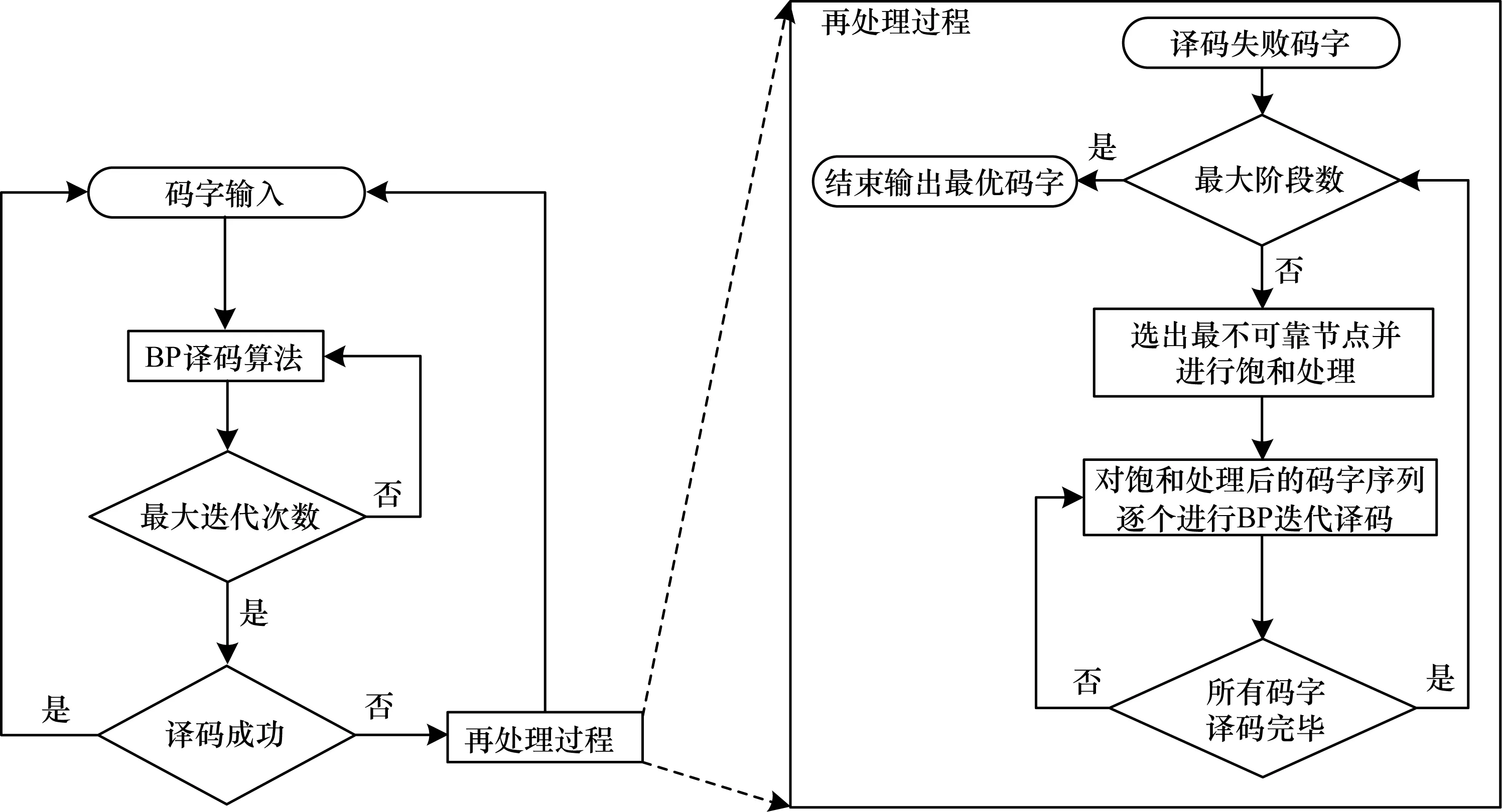
圖1 QML譯碼器的整體流程
判斷QML譯碼器是否具有較好的譯碼性能的關鍵在于提出的節(jié)點選擇算法能否選擇出最不可靠的節(jié)點。文獻[19]的創(chuàng)新在于提出一種更加準確的變量節(jié)點選擇算法,即邊選擇(Edge-Wise Selection,EWS)算法,同時為降低譯碼延遲,利用部分剪枝停止(Partial Pruning Stopping,PPS)算法在譯碼延遲和誤碼率性能之間取得了較好的平衡。
1.1 基于LDPC碼的BP譯碼算法
BP譯碼算法在對數似然比域上進行運算,其中,變量節(jié)點用VN表示,校驗節(jié)點用CN表示。BP譯碼算法的具體步驟如下:
1)初始化。計算信道傳遞給VN的初始概率似然比信息r(vi)(i=1,2,…,n),對于VNi及其相鄰的CNj∈Ci,經過二進制相移鍵控(Binary Phase Shift Keying,BPSK)調制后在高斯白噪聲(Additive White Gaussian Noise,AWGN)信道中得到VN傳遞給CN的初始信息為:
(1)
2)CN信息更新。對所有的CNj及其相鄰的VNi∈Rj,CN信息的計算公式為:
(2)
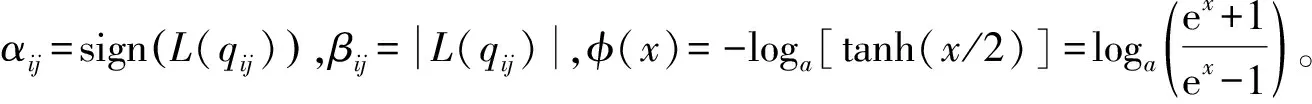
3)VN信息更新。對所有的VNi及其相鄰的CNj∈Ci,VN信息的計算公式為:
(3)
4)判決譯碼。對所有的VN計算判決信息:
(4)
(5)
for t1=0:M do
for t2=0:rowdegree[t1]-1 do
tm p=0
for t3=0:rowdegree[t1]-1 do
if t2=t3then
continue
end if
tmp=tmp+φ(t3)
end for
end for
end for
分步計算譯碼方案時間復雜度的偽代碼具體如下:
for t1=0:M do
tm p=0
for t2=0:rowdegree[t1]-1 do
tmp=tmp+φ(t2)
end for
end for
for t1=0:M do
for t2=0:rowdegree[t1]-1 do
tmp=tmp+φ(t2)
end for
end for
1.2 再處理過程
1.2.1 EWS算法
EWS算法的基本思想是計算Tanner圖上每條邊上VN傳給CN的信息正負號變換次數,最后將與每個VN相連的CN信息變換次數相加,從所有VN中選出信息變換次數最大的VN組成集合,從集合中選出所對應r(vi)絕對值為最小值的點,利用一個預設的飽和值±α代替原有信息,重新進行譯碼。
使用wl,i表示VNi傳遞到與其相連的第l個CN的消息的正負號翻轉次數;d(vi)表示VNi的度,即校驗矩陣第i列非零元素的個數;w(vi)表示VNi的消息正負號翻轉總次數,計算如下:
(6)
EWS算法偽代碼如下:
For each VNi,compute w(vi) according to equation(6)
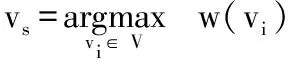
if vs?? then
Select the VN with the smallest a posterior probability among vs
end if
1.2.2 部分剪枝停止算法
文獻[19]在不影響FER的情況下,提出一種PPS規(guī)則有效終止再處理過程。TA表示第TA個譯碼的碼字,x(TA)表示第TA個碼字的判決輸出,χ表示收斂碼字集合;TF表示剩余要進行譯碼的碼字,jmax表示再處理過程的最大階段數,jc表示當前再處理階段,初始化TF=2jmax+1-2。PPS算法偽代碼如下:
if converge after TAtests then
Save valid codeword x(TA)in χ//存儲收斂的碼字
TF=TF-2jmax+1
Terminate the decoding on sub-branches thereafter//剪枝操作
else
Continue the decoding on non-convergent sub-branches
end if
if jc=jmaxor TF=0 then//當預設最大階段或所有的分支//都收斂時停止譯碼
Terminate reprocessing procedure
end if
再處理過程的樹形流程如圖2所示,輸入譯碼失敗后的碼字進行EWS,并對選出的節(jié)點進行飽和處理,重新進行譯碼。當TA=1時,即第一個飽和后需進行譯碼的碼字,譯碼成功進行PPS操作;當TA=2時,飽和后的碼字譯碼不成功,再次進行EWS,重復以上步驟,直至到達預設的階段數或所有的碼字都收斂。
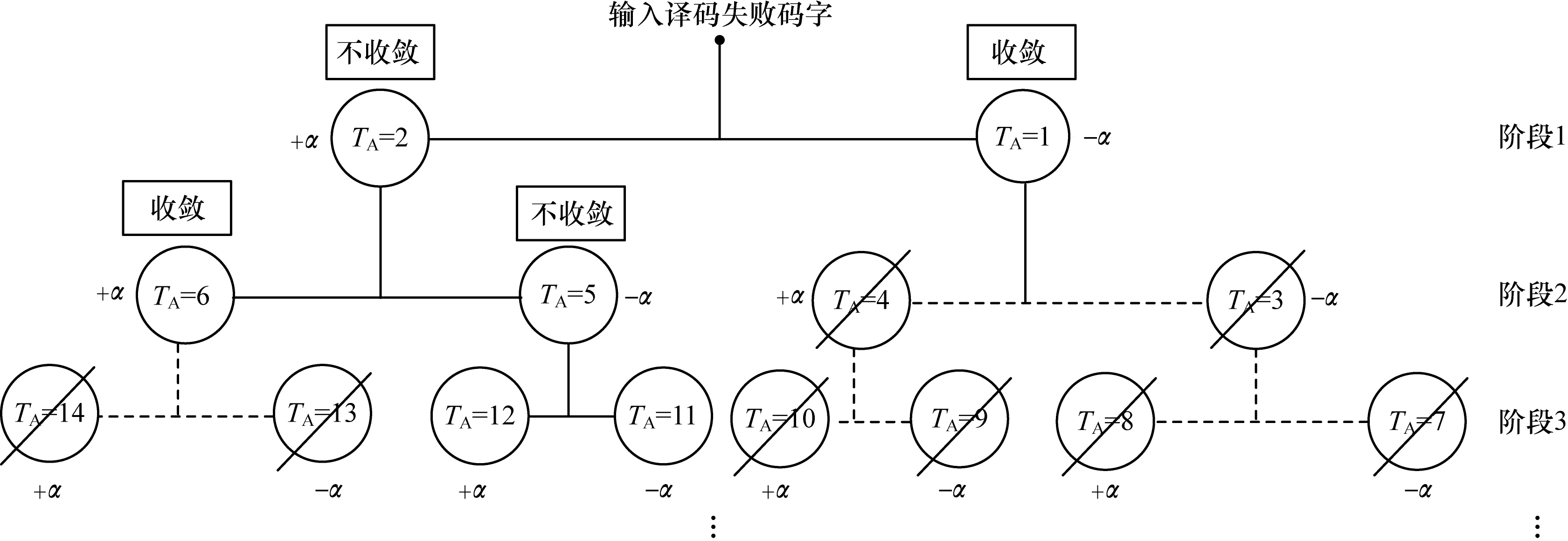
圖2 再處理過程的樹形流程
2 基于GPU的EQML譯碼器并行化計算
LDPC碼的校驗矩陣是一種稀疏矩陣,含有大量的“0”元素和少量的“1”元素,針對“0”元素無用問題,本文提出一種壓縮存儲LDPC碼的校驗方案,對提高譯碼速度非常重要。CN更新過程存在計算復雜度過高的問題,根據GPU并行特性提出一種BP算法重排方案,即使用大量線程并行、中間值計算和訪存合并相結合的譯碼方案來提高譯碼速度。根據再處理過程中每個階段都有大量碼字需要譯碼的問題,在GPU上采用多碼字并行譯碼方案。利用GPU內不同儲存器訪問速度不同的特性,采用帶寬更大的儲存器及流并行機制來提高訪存速度。
2.1 適用于GPU的奇偶校驗矩陣壓縮存儲方法
文獻[15]提出利用鏈表儲存奇偶校驗矩陣,需要建立大量的表結構,較復雜且占用內存。文獻[6-7]提出的存儲基矩陣方法,需解決算法映射問題,實現較復雜。文獻[10]僅給出了規(guī)則LDPC碼的校驗矩陣存儲方案。本文在文獻[10]基礎上,給出一種不規(guī)則LDPC碼的校驗矩陣存儲方案,通過7個一維數組表示校驗矩陣:rowdegree,coldegree,rowsum,colsum,colnum,V2C,C2V。存儲7個一維數組的方式如圖3所示。rowdegree、coldegree分別儲存CN的行度和VN的列度。colnum、rowsum和colsum分別代表校驗矩陣中每個非零元素按列順序排列所在的列,按行順序排列到本行時所有非零元素的總數和按列順序排列到本列時所有非零元素的總數,V2C和C2V分別代表按順序儲存校驗節(jié)點的邊及其與VN相連的CN編號。

圖3 Tanner圖上稀疏矩陣轉化為一維數組的過程
2.2 EQML譯碼算法的GPU實現
2.2.1 GPU Kernel內線程排布
Tanner圖中CN和VN之間高度不規(guī)則的連接結構,使得在GPU上實現EQML譯碼器時不能同時在內存中對連續(xù)數據進行讀寫操作。因為執(zhí)行無序的內存讀或寫操作需要處理多個事務,所以此時所有Kernel內的線程都必須停止等待。相反地,對連續(xù)內存位置的訪問可以在單個事務中執(zhí)行并允許并發(fā)線程執(zhí)行,從而減少Kernel的運行時間。此外,對無序的內存進行寫操作比對無序的內存進行讀操作需要更多的執(zhí)行時間[20]。因此,本文對BP譯碼算法重新排序以避免未合并的內存寫操作,并使用最大數量的線程級并行計算。

圖4 BP譯碼算法的GPU實現
基于GPU的BP迭代譯碼并行化算法具體如下:
1)初始化。通過式(7)進行初始化,上標0代表迭代次數,L(Qi)和r(vi)為一個長度為N的數組,用于儲存譯碼判決消息和初始概率似然比信息。
L(Qi)0=r(vi)=2yi/σ2
(7)
2)Kernel 1 VN更新。L(rji)是一個長度為T的數組,用來儲存初始化為0的CN更新消息。在Kernel 1中,通過式(8)計算VN更新消息:
L(qij)k=L(Q[colnum[Idx]])k-1-L(rji)k-1
(8)
其中,k=1→Imax,Imax為BP譯碼的最大迭代次數,L(qij)為一個長度為T的數組,用于儲存VN更新信息,Idx為Kernel中的線程索引,Kernel 1中Idx=0→T-1。
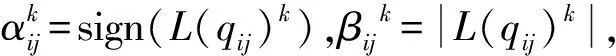
通過式(9)對比前后兩次信息計算EWS算法中的wl,i,Tsign為一個長度為T的數組用于存儲wl,i的數值。
(9)
3)Kernel 2中間值更新。通過式(10)計算CN更新的中間值:
devM[Idx]=devM[Idx]+
φ(V2C[rowsum[Idx]+t])
(10)
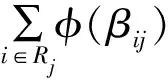
4)Kernel 3 CN更新。通過式(11)計算CN更新,Kernel 3中Idx=0→T-1。
L(rji)k=φ(devM[C2V[Idx]]-φ(Idx))
(11)
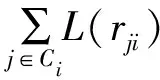
devN[Idx]=devN[Idx]+
L(r[colsum[Idx]+t)k
(12)
L(Qi)k=r(vi)+devN[Idx]
(13)
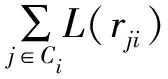
在達到最大迭代次數時通過式(14)計算出w(vi),Nsign是一個長度為N的數組,用于儲存w(vi)的值。
Nsign[Idx]=Nsign[Idx]+Tsign[colsum[Idx]+t]
(14)
通過Kernel 4計算出L(Qi)及w(vi),在到達最大迭代次數后將w(vi)及判決結果從GPU讀到CPU內存中cudaMemcpy(h_Nsign,Nsign,N×sizeof(int),cudaMemcpyDeviceToHost)。
2.2.2 再處理過程中的多碼字并行譯碼
為提高Kernel中線程的利用率并充分利用再處理過程的可并行譯碼特性,采用多碼字并行譯碼方案,即將每個階段生成的碼字序列同時譯碼。假設需要Kernel提供N個線程來譯碼單個碼字,如果有Ncodeword個碼字需要進行譯碼,將Ncodeword個碼字合并,采用N×Ncodeword個線程對這些碼字進行并行譯碼。譯碼器階段與階段之間采用串行方式,階段內的所有碼字采用并行譯碼,具體方案如圖5所示。
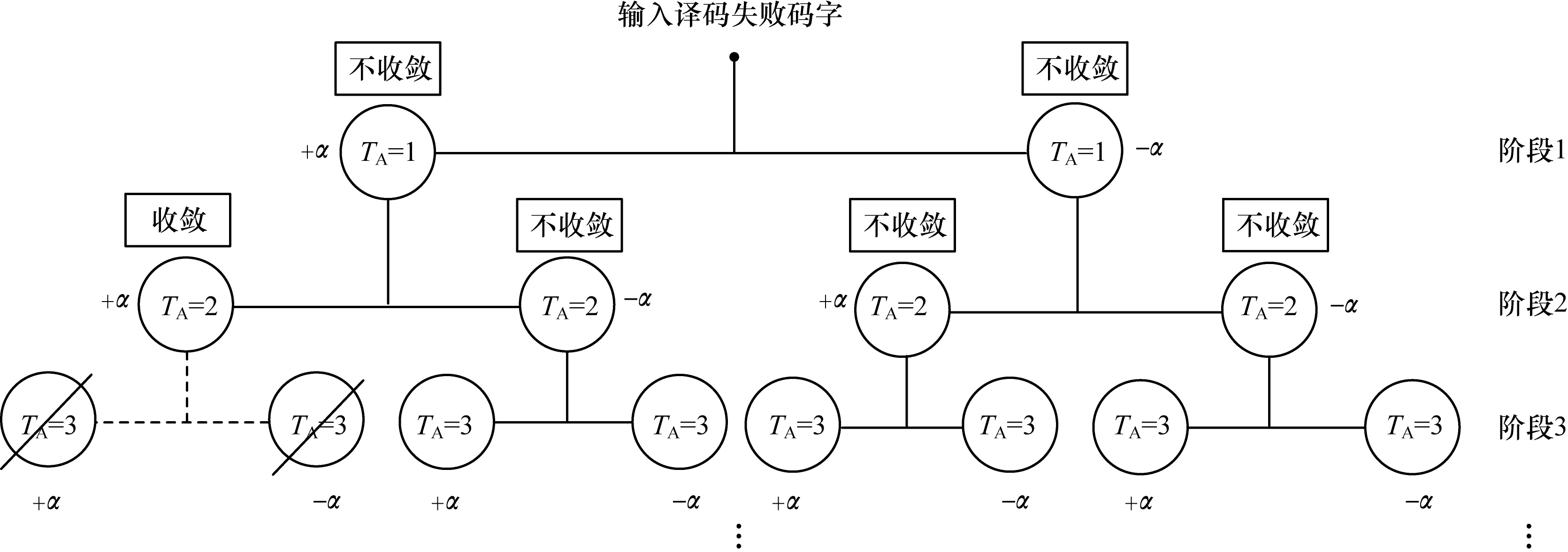
圖5 再處理階段中的多碼字并行譯碼方案
在圖5中,每個TA代表一個需要譯碼的碼字,TA=1的碼字有兩個,代表第一階段要并行譯碼的碼字有兩個。同理,第二階段有4個,第三階段有6個。與CPU相比,其通過并行方式對單個碼字進行譯碼,節(jié)省了大量譯碼時間。
2.3 GPU內存訪問數據優(yōu)化
由于warp是GPU中調度和運行的基本單元,因此每個warp包含32個線程。當對常量內存進行讀取時,GPU將單次讀操作廣播到每個半線程束(half-warp),即線程束中線程數量的一半。如果在半線程束中的每個線程從常量內存的相同地址上讀取數據,那么GPU只會產生一次讀取請求并在之后將數據廣播到每個線程,該方式的理論速度可達到使用全局內存時的16倍。共享內存是GPU內位于每個流處理器中的高速內存空間,主要作用是存放線程塊中所有線程均會頻繁訪問的數據。GPU上儲存器的帶寬參數如表1[21]所示。

表1 GPU儲存器帶寬
為提高譯碼速度,將頻繁讀寫的局部變量使用高帶寬的共享內存存儲,使代表校驗矩陣的7個一維數組存儲在只讀存儲器常量內存中,因為這幾個數組中儲存的數據只需進行讀操作,無需對數組中的數據進行修改,可以有效減少存儲器事務的處理時間。共享內存和常量內存的具體使用方法如下:
__shared__double RCache[];//申請使用共享內存存儲//Kernel中重復訪問的局部變量
__device__ __constant__ int V2C[T];//申請常量內存用//于存儲V2C數組
cudaMemcpyToSymbol(V2C,h_V2C,T*sizeof(int));//使用內置函數將數組從CPU內存拷貝到GPU常量內存中
2.4 GPU流并行機制
EQML譯碼器在GPU平臺上運行所消耗的時間中,除去核函數執(zhí)行時間外,其余大部分時間是用于CPU與GPU之間通過PCI-E總線傳輸碼字信息和硬判決輸出信息。因此,可以引入CUDA流機制,在提升Kernel自身執(zhí)行效率的同時,優(yōu)化數據傳輸和譯碼內核函數之間的調度機制。通過CUDA流可以實現多幀譯碼數據傳輸和執(zhí)行Kernel函數之間的交疊執(zhí)行,如圖6所示,其中H2D和D2H分別表示碼字信息數據從CPU傳輸到GPU和判決信息從GPU傳輸到CPU的傳輸過程,能夠降低在PCI-E總線數據傳輸時的空閑等待時間。流并行的具體算法如下:
cudaStream_t stream;
cudaStreamCreate(& stream);//流初始化
cudaHostAlloc((void**)& lratio,N * sizeof(double),cudaHostAllocDefault);//對流使用的頁鎖定內存進行分配
cudaMemcpyAsync(dev_lratio,lratio,N * sizeof(double),cudaMemcpyHostToDevice,stream);//將數據復制到GPU上

圖6 流并行機制
3 實驗結果與分析
EQML譯碼器的運行環(huán)境為GTX 1060 GPU,在英偉達CUDA 8工具包下進行編譯,編譯環(huán)境是Visual Studio2017,Windows10 64位操作系統(tǒng)。實驗選取的LDPC碼為802.16e標準碼率為0.5、碼長為2 304與576的LDPC碼。
為比較EQML譯碼器在GPU上實現的FER性能,應用碼長為576的LDPC碼在jmax分別為1、2、3、4和5時進行譯碼仿真,同時對傳統(tǒng)BP譯碼器及文獻[16]提出的ABP譯碼器進行仿真,仿真結果如圖7所示。可以看出,EQML譯碼器能夠提供比BP譯碼器和ABP譯碼器更好的糾錯能力,其與5G移動通信系統(tǒng)安全性、可靠性、穩(wěn)定性的要求相一致,所以通過EQML譯碼器進行并行化提升譯碼速度非常必要。

圖7 EQML譯碼器與BP譯碼器和ABP譯碼器的FER性能對比
Fig.7 Comparison of FER performance of EQML decoder,BP decoder and ABP decoder
文獻[5]提出一種常見的壓縮基矩陣存儲方案,因為作者在其github上公布了源碼,所以本文將壓縮基矩陣與壓縮奇偶校驗矩陣的實現方案進行仿真。仿真條件為信噪比1.0 dB,固定迭代30次。為使仿真結果更公平,防止因計算平臺造成誤差影響實驗結果,這兩種方案都是在GTX1060 GPU上應用碼長為2 304的LDPC碼進行仿真。由于文獻[6]中使用MSA譯碼算法,為方便對比本文也采用MSA算法,結果如表2所示。由此可知,采用壓縮奇偶校驗矩陣比采用壓縮基矩陣的存儲方案具有更快的譯碼速度。壓縮奇偶校驗矩陣存儲方案能提高1.45倍的譯碼速度。
表2 校驗矩陣存儲方案的譯碼時間比較
Table 2 Comparison of decoding time of check matrix storage schemes s

方案譯碼時間CPU存儲方案784.54壓縮基矩陣存儲方案20.29壓縮奇偶校驗矩陣存儲方案13.92
為對比本文提出的BP算法重排方案的加速效果,對傳統(tǒng)BP譯碼與重排后的BP譯碼方案在碼長為2 304的LDPC碼下進行對比。通過表3中數據可知,重排后譯碼速度比傳統(tǒng)BP譯碼算法提升了1.68倍,證明了BP算法重排后的譯碼優(yōu)勢。
表3 BP重排譯碼方案與傳統(tǒng)BP譯碼方案的譯碼時間比較
Table 3 Comparison of decoding time of BP rearrangement decoding scheme and traditional BP decoding scheme s

方案譯碼時間CPU譯碼方案845.35傳統(tǒng)BP譯碼方案39.39BP重排譯碼方案23.41
EQML譯碼器采用經BP算法重排后的譯碼方案。為對比不同jmax下基于GPU與CPU實現的EQML譯碼器所需的譯碼時間,對碼長為576的LDPC碼進行仿真,仿真結果如表4所示。
表4 不同jmax下的譯碼時間比較
Table 4 Comparison of decoding time at differentjmaxs

Jmax值譯碼時間CPUGPU1380.7119.952788.9130.2631508.7541.0342870.9660.1656481.63100.46
圖8表示不同jmax下基于GPU實現的EQML譯碼器的加速倍數,由此可知,EQML譯碼器隨著jmax的增加,加速倍數也在增加,所以基于GPU譯碼方案的優(yōu)勢在jmax取較大值時加速效果將更加明顯。當jmax取5時,速度提升了約64倍,顯示了基于GPU的譯碼方案的性能優(yōu)勢。
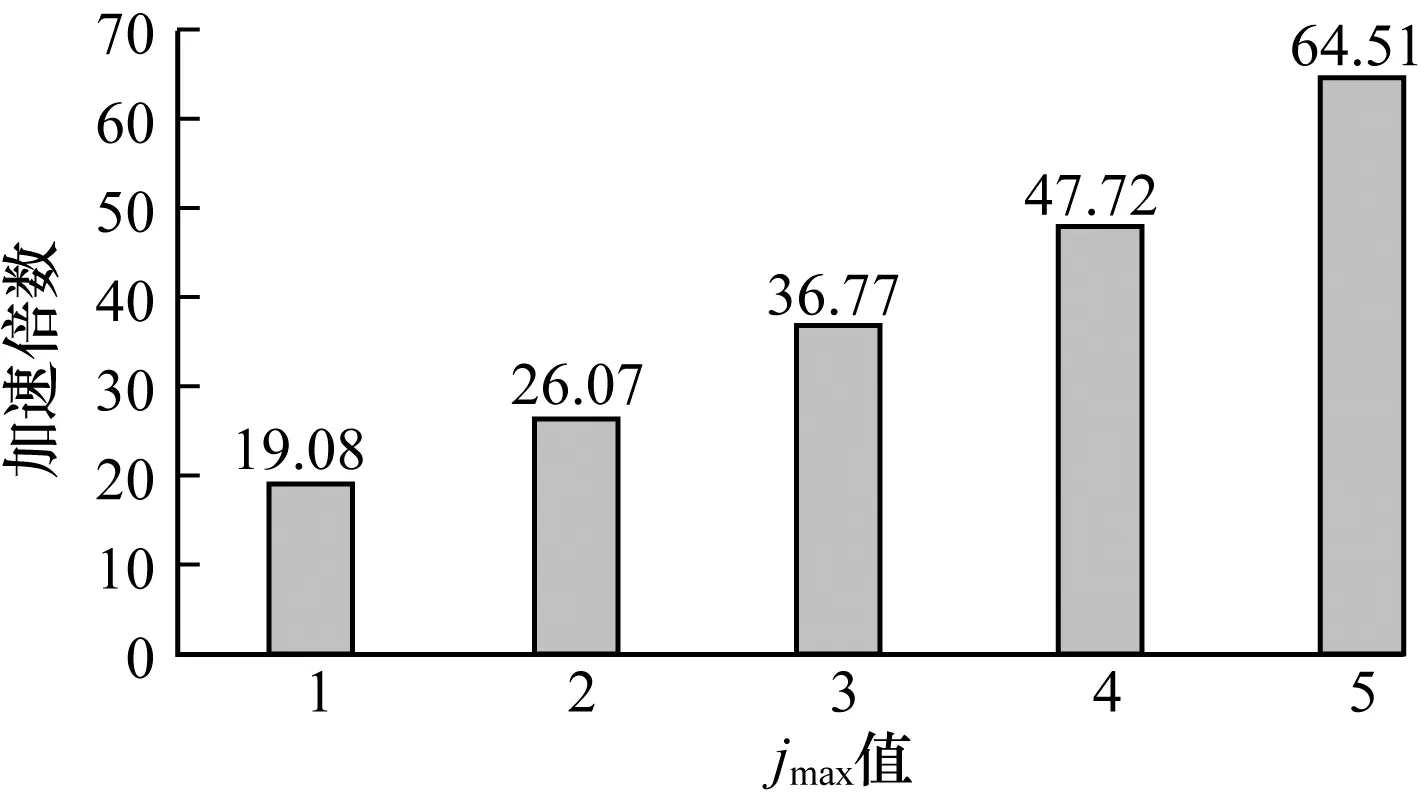
圖8 基于GPU的EQML譯碼器在不同jmax下的加速倍數
Fig.8 Speedup of GPU-based EQML decoder at differentjmax
為比較譯碼器在不同信噪比下的譯碼速度,以碼長為576的LDPC碼為研究對象,設置jmax為3,分別在不同信噪比下對EQML譯碼器在CPU和GPU上所需的譯碼時間進行仿真,仿真結果如表5所示。
表5 不同信噪比下的譯碼時間比較1
Table 5 Comparison of decoding time at different signal to noise ratio 1 s
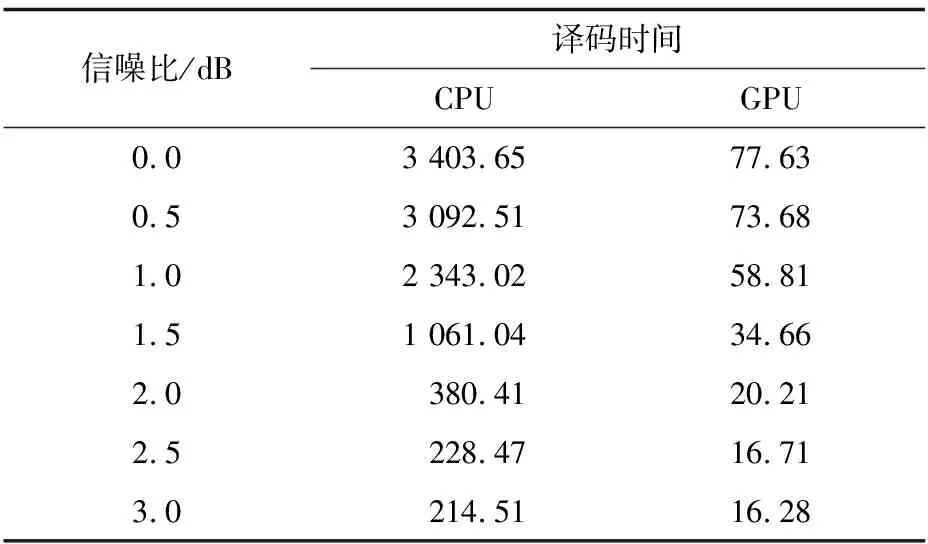
信噪比/dB譯碼時間CPUGPU0.03403.6577.630.53092.5173.681.02343.0258.811.51061.0434.662.0380.4120.212.5228.4716.713.0214.5116.28
圖9表示在不同信噪比下的加速倍數,由此可知在信噪比較低的情況下加速倍數較高,因為EQML譯碼器在信噪比低時譯碼成功率低,再處理過程啟動頻繁,所以譯碼時間增加。在信噪比較高的情況下,譯碼成功率高,再處理過程啟動次數、譯碼時間、加速倍數均降低。

圖9 基于GPU的EQML譯碼器在不同信噪比下的加速倍數1
Fig.9 Speedup of GPU-based EQML decoder at different signal to noise ratio 1
為對比不同碼長對基于GPU的譯碼器的影響,在相同情況下對碼長為2 304的LDPC碼進行仿真,仿真結果如表6所示。
表6 不同信噪比下的譯碼時間比較2
Table 6 Comparison of decoding time at different signal to noise ratio 2 s
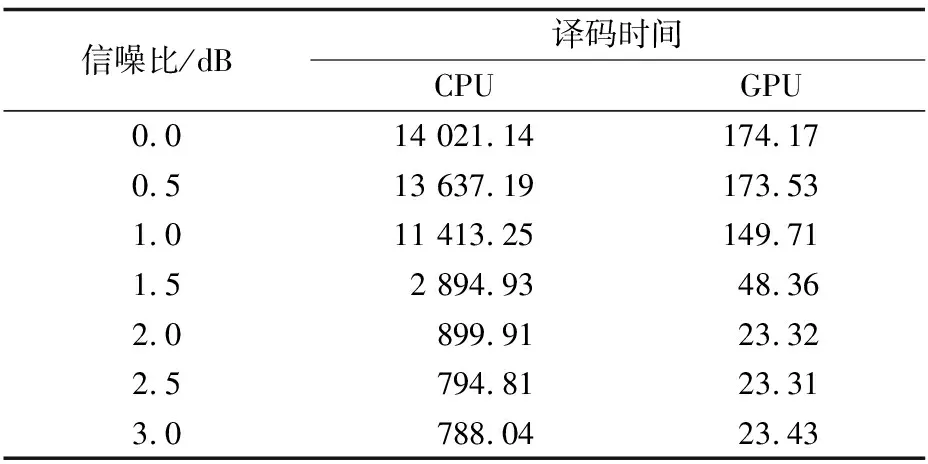
信噪比/dB譯碼時間CPUGPU0.014021.14174.170.513637.19173.531.011413.25149.711.52894.9348.362.0899.9123.322.5794.8123.313.0788.0423.43
圖10表示碼長為2 304時不同信噪比下的GPU譯碼方案的加速倍數,當信噪比為0時加速倍數達到80倍,大幅節(jié)省了譯碼時間。與圖9相比可知,碼字越長獲得的加速倍數越大,因為當碼字較長時GPU可以利用Kernel內的線程優(yōu)勢,使用更大量的線程譯碼提高譯碼速度,所以當碼字很長時,采用GPU譯碼方案的優(yōu)勢將會更加明顯。
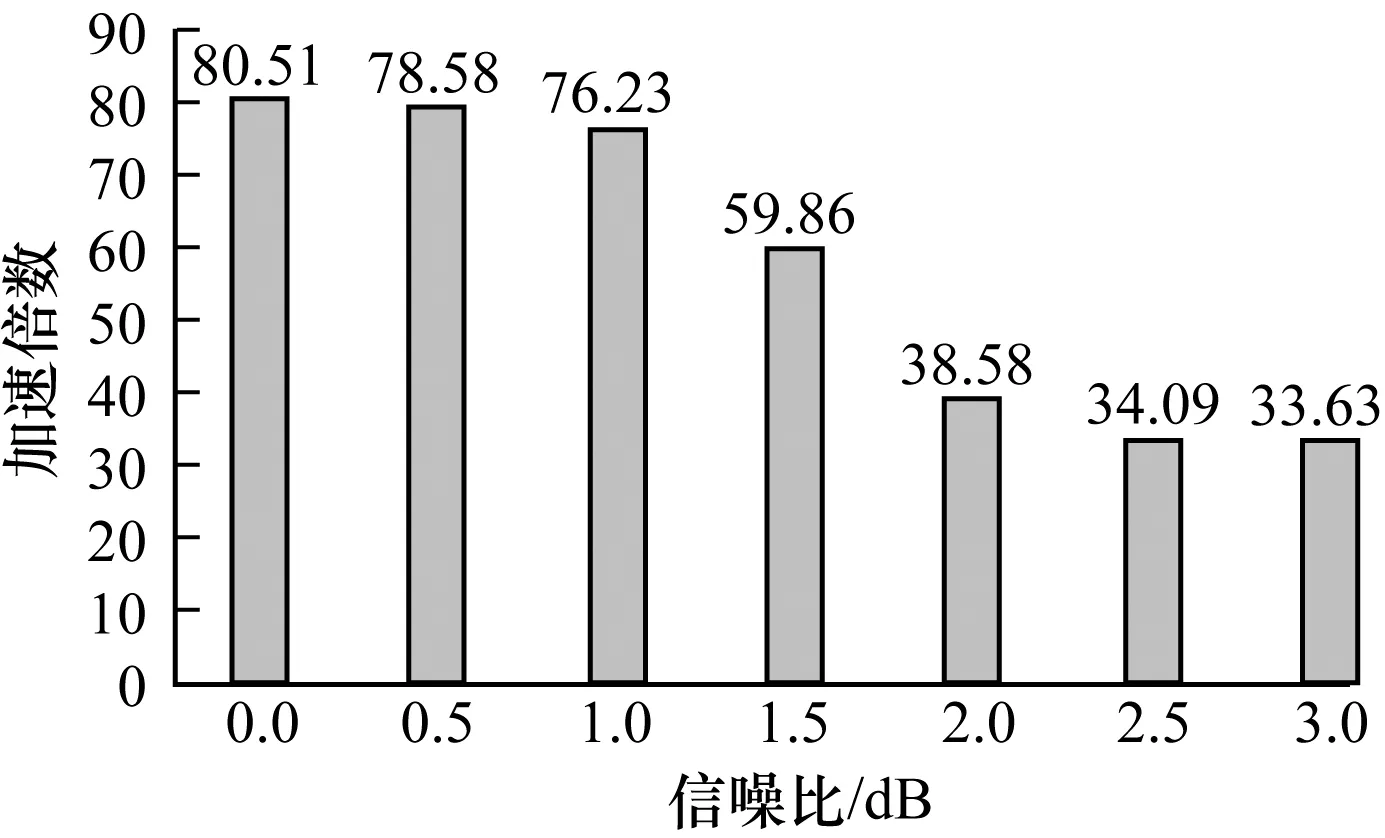
圖10 基于GPU的EQML譯碼器在不同信噪比下的加速倍數2
Fig.10 Speedup of GPU-based EQML decoder at different signal to noise ratio 2
4 結束語
5G移動通信系統(tǒng)要求在確保低成本及傳輸安全性、可靠性、穩(wěn)定性的前提下,能夠提供更高的數據傳輸速率、更多的服務連接數和更好的用戶體驗。EQML譯碼器可以消除大量導致BP譯碼器不收斂的偽碼字,實現更加可靠的通信,但是EQML譯碼器是以犧牲譯碼速度來換取譯碼性能,因此本文設計一種基于GPU的EQML譯碼器來提升EQML譯碼器的譯碼速度。針對不規(guī)則LDPC碼,提出壓縮校驗矩陣存儲方案,使用共享內存和常量內存分別儲存頻繁訪問的局部變量和只讀數據,在Kernel中對BP譯碼算法進行重新排序,并采用每階段多碼字并行譯碼方案,提高EQML譯碼器再處理過程的可并行性。實驗以802.16e WiMax LDPC碼為例對基于GPU的EQML譯碼器性能進行驗證,結果表明EQML譯碼器在GPU上的并行實現較在CPU上的串行實現譯碼速度有了較大提升,當碼長為2 304碼字且信噪比較低時的最大加速倍數可達80倍,證明了GPU技術在并行譯碼中的可行性和有效性。
