CAN控制系統的時延分析及混合算法
2020-05-18 11:08:32張庭芳黃海林郭勁林
計算機工程 2020年5期
張庭芳,黃海林,郭勁林,曹 銘
(南昌大學 機電工程學院,南昌 330031)
0 概述
由于控制器局域網絡(Controller Area Network,CAN)總線具有較高的可靠性和較低的價格優勢,使其成為目前汽車上應用最多的總線。現代汽車的控制系統是通過總線技術將微控制器、傳感器和執行器連接起來而組成的網絡控制系統[1]。這種網絡控制系統具有結構分散化、硬件數量少、布線簡單、診斷方便的優點,但是網絡的引入會給系統帶來不必要的時延,使得系統性能降低,甚至使系統不穩定[2]。因此,有必要對CAN總線網絡控制系統的時延進行深入的理論研究,以保證CAN控制系統工作的實時性和穩定性。文獻[3]提出基于時域Smith預測器的反饋控制律的算法,并且計算提出的反饋控制律的反饋增益,最后通過兩個實例驗證了該算法的有效性。文獻[4]通過對CAN控制系統時延分析,推導出保證系統穩定的總時延和采樣周期的關系式,并采取已有的TTCAN協議進行了仿真驗證。文獻[5]提出了安全性、可靠性等5種多維非功能屬性集成的優化算法,提高了目標優化率。上述文獻都沒考慮到總線協議自身的局限性。
為提高CAN消息的實時性,目前研究人員已提出了靜態的調度算法,如文獻[6-7]的速率單調(RM)算法,但該算法的CPU利用率不高;另有研究人員提出了動態調度算法,如文獻[8-9]的最早截止期優先(EDF)算法,然而該算法任務頻繁切換會帶來不必要的開銷,并且負載太大時調度性能急劇下降。文獻[10-11]提出一種動態優先級分配方法雖然能使低優先級消息盡快被執行,但增加了高優先級消息的延遲,并且沒有很好地解決消息的碰撞問題。文獻[12]提出一種用相鄰節點傳遞消息的方法,消息在相鄰節點發送接收,雖然避免了消息的碰撞,但沒考慮多節點競爭總線和多節點接收消息的情況,缺乏靈活性,不具有現實意義。
TTCAN協議是在CAN基礎上制定的時間觸發協議。該協議采用時分復用的原理來離線分配各種消息的時間窗,達到有序發送消息的目的,增強了消息的實時性。但該方法無法和CAN節點設備兼容,并且如果要新增消息,需重新離線設計時間窗,靈活性較差。文獻[13-15]研究的共享時鐘算法是通過在軟件層面上實現時間觸發的CAN通信,但主節點需頻繁地發送時標消息來對從節點時鐘同步,對時標消息的抗干擾性要求很高并且額外增加了通信成本。本文對消息在CAN控制系統中產生的時延問題進行了分析,并結合文獻[15]改進的共享時鐘算法(TTC-SC3)和文獻[16]動態ID序列算法的思想,提出一種共享ID序列(Shared ID Sequence,SIDS)的混合算法。
1 時延分析
1.1 CAN控制系統時延組成
汽車的CAN控制系統由傳感器、控制器和執行器組成。端到端時延組成如圖1所示。

圖1 網絡傳輸時延組成
時延由以下4個部分組成:
1)消息的生成時間Tsour
在源節點上對生成的信號處理打包成消息的時間,主要包括信息采集、信息處理和信息編碼打包時間。這部分時延主要和軟硬件性能有關,通常認為是定常或者忽略不計的[17]。
2)消息的排隊時間Tw
從報文開始排隊到獲得總線控制權的時延,與所采取的協議有關。
3)消息在總線上的傳輸時間Tc
消息的傳輸時間有2個部分,一個是和數據幀大小、通信波特率有關,另一個是和節點距離、電信號在傳輸媒介的傳播速度有關,由于傳播速度很快(電磁波是光速的0.3倍),并且節點之間的距離很小,此傳輸時間忽略不計。
4)目標節點上的處理時間Tobj
目標節點上的處理時間是處理器將接收到的報文進行解析,將數字量轉為模擬量所耗費的時間。這和控制器軟硬件的性能有關,通常認為是定常或者是忽略不計的。
因此,CAN上的傳輸延遲為:
Tdelay=Tsour+Tw+Tc+Tobj
(1)
為便于分析,Tsour、Tobj忽略不計,所以式(1)可改為:
Tdelay=Tw+Tc
(2)
從式(2)可知,排隊時間Tw是由CAN協議引起的,Tc是由報文長度和總線通信速率決定的,在報文發送過程中是定值,CAN總線通信的不確定性主要體現在排隊等待時間Tw上。
1.2 消息的排隊時間Tw
Tw的不確定性主要是因為多節點消息同時競爭總線引起的,當多個消息競爭總線時,優先級高的消息搶占優先級低的消息,使低優先級消息排隊等待時間過長,有資料表明當事件率達到60%~70%時,優先級低的節點消息將得不到保證,整個系統是不可靠的[18],而且優先級高的消息也會被優先級低的消息阻塞。為便于理解,通過下面例子對此加以說明。
在500 kb/s的CAN網絡中,有節點A、B、C、D、E、F,其中,節點A發送消息m1,節點B發送消息m2,節點C發送消息m3,節點D發送消息m4,節點E發送消息m5,節點F發送消息m6,m1優先級最高,m6優先級最低。上述消息滿足下列條件:
1)所有消息第一次發送時間都在0時刻;
2)所有報文都是數據幀格式,單幀傳送;
3)沒有錯誤幀;
4)m1的消息為T1,其他報文周期都為T,且T/2=T1;
5)滿足可調度性。
如圖2所示,所有消息都在0時刻開始競爭總線,由于消息m1的優先級最高,m1在k1時刻獲得總線控制權傳輸消息。剩下的消息則一直監聽總線,等待總線空閑。在k2時m1消息傳輸完畢,剩下的5個消息競爭總線,由于m2的優先級最高,m2獲得總線控制權傳輸消息,以此類推,直到k6時刻,到了m1周期T1,消息m1第二次發送,但是此時消息m5正在傳輸,m1被低優先級消息阻塞,等到m5消息傳輸完畢在k7時刻m1才能傳輸。消息m1傳輸完畢后在k8時刻消息m6開始傳輸。至此,第一個周期T內的消息仲裁完畢,直到第二個周期T到來,新一輪仲裁開始,仲裁過程和第一個周期T的類似。仲裁過程既發生優先級高的消息搶占優先級低的消息,又發生優先級高的消息被優先級低的消息阻塞。

圖2 不同周期消息發送時序示意圖
Fig.2 Schematic diagram of message sending timing in different periods
由以上例子可知,假設消息m1,m2,…,mi,…,mn滿足可調度性,i越小優先級越高,當消息同時競爭總線時Tw包含以下3種情況:
1)最高優先級消息m1被低優先級消息阻塞的延遲。
2)中優先級消息mi(i≠1且i≠n)被高優先級消息搶占的延遲或被低優先級消息阻塞的延遲。
3)最低優先級消息mn被高優先級搶占的延遲。
又由文獻[19-21]可知,消息mi被低優先級阻塞的延遲為:
(3)
其中,l(m)是所有優先級低于消息mi的集合。被高優先級消息搶占總線造成的延遲為:

(4)
其中,hp(m)為所有優先級高于m的消息的集合,Ji為消息的抖動時間,τbit為位傳輸時間。
式(3)與式(4)之和便是最大的等待時間Tw,即:

(5)
1.3 消息的傳輸時間Tc
CAN總線采用位填充技術來減少消息幀在傳輸過程的出錯。在CAN消息幀中,從幀起始到CRC界定符之前都以位填充的方式進行編碼。當發送器在發送位流中檢測到5個相同的顯性位或者隱性位時,自動插入一個補碼位,例如11111 0000 1111 0000,位填充后變成11111 0 0000 1 1111 0 0000 1。因此,在標準幀中參與位填充的長度為:
L=34+8×DLC
(6)
由式(6)可知,在標準幀中最大位填充數為:

(7)
又由式(7)可知,在標準幀中最大傳輸時間為:
(8)
擴展幀中最大傳輸時間為:
(9)
其中,DLC為字節數,τbit為位傳輸時間。
由式(8)和式(9)可知,消息的傳輸時間Tc是由數據幀的長度和通信速率決定的,在已知通信速率的CAN中傳輸的數據越多,Tc越大。由式(5)可知Tw非常復雜,這也是引起CAN總線消息的不確定性的原因,并且對于低優先級消息來說這部分延遲更為嚴重。因此,應深入研究Tw以降低或者消除這部分延遲。
2 共享ID序列混合算法
2.1 TTC-SC3算法
共享時鐘算法(Shared Clock,SC)是作為一個軟件平臺角度來實現節點間消息的通信,像TTCAN一樣采用時分多址(TDMA)協議,但不需要相應的硬件支持。而文獻[15]改進的共享時鐘算法(TTC-SC3)在共享時鐘算法上作了稍微改動。在TTC-SC3算法中,允許多個從節點在一個時標間隔內應答。每次主節點發送一個時標消息時,消息中也會發送一個ID(與共享時鐘算法相同)。與共享時鐘算法不同,這是一個“組ID”,而不是一個ID,并且如果一個特定的組中有多個從節點,組中的所有從節點都將同時作出應答。CAN控制器自行處理任何消息的碰撞。主節點在傳輸下一條時標消息之前,檢查從節點是否已作出了應答,如假設有4個節點消息在CAN總線上進行通信,通信模式如圖3所示。

圖3 TTC-SC3算法中主從節點的通信模式
Fig.3 Communication mode of master and slave nodes in TTC-SC3 algorithm
此算法是通過主節點不斷地發送一個時標消息來對從節點進行時鐘同步,對本地時鐘的魯棒性要求很高,并且從節點不斷發送應答消息給主節點來達到錯誤檢測的功能,如文獻[15]所述,當其中一個從節點發生錯誤導致不斷地重傳消息時,將會使一系列低優先級消息的從節點無法訪問總線,顯然會造成大量數據丟失,導致網絡不穩定。
2.2 動態ID序列算法
文獻[16]研究的動態ID序列算法的核心思想是在參加通信的節點中離線預設好一個消息ID序列,如圖4所示,每個節點都按照消息序列和發送周期來發送消息。該算法最大的優點是不需要頻繁地發送時標消息來對各個節點同步,但為了動態更新節點中消息ID序列,算法需要每個節點接收總線上的全部消息,這對節點中CPU的負擔是很大的。

圖4 CPU中ID序列
Fig.4 ID sequence in CPU
2.3 共享ID序列混合算法原理
本文結合TTC-SC3算法和動態ID序列算法的思想,提出了一種共享ID序列(SIDS)混合算法,該算法能有效地將消息發送時刻錯開,避免消息之間的碰撞,消除了時延Tw,從而提高消息傳輸的實時性。算法流程如圖5所示。
該算法首先在主節點中預設好ID序列(ID序列根據優先級從左至右降序排列),當程序啟動時,主節點(此節點消息優先級設置為最高級別)把預設的ID序列像TTC-SC3算法一樣以廣播的方式發送給各個從節點(一個節點可能既是發送節點又是接收節點,稱為從節點)。從節點根據接收到的ID序列CPU會產生一個中斷響應,判斷本節點消息ID是否是下一個要發送的ID,接著判斷是否到了發送周期,如果是,則各個從節點按ID序列順序把消息發送給接收節點和主節點,否則直接退出程序。顯然,當各個消息按ID發送時,它們之間的延遲為消息的傳輸時間Tc,根據式(8)和式(9)計算得出,在500 Kb/s的通信速率中,標準幀中一幀的傳輸時間范圍為Tc∈[94 μs,270 μs],擴展幀一幀的傳輸時間范圍為Tc∈[134 μs,320 μs]。值得注意的是,各個從節點的消息也要發送給主節點,類似TTC-SC3算法,從節點發送應答消息給主節點,即主節點會接收所有從節點產生的消息。如果主節點沒在下一個周期到來之前收到消息,說明數據包丟失,則代表接收節點的數據包同樣丟失,主節點報錯計數,當達到設定的閾值(該閾值根據消息的重要程度設置)后,主節點的CPU會以中斷響應的方式在ID序列中檢索相應的出錯ID并刪除它,接著生成一個全新的ID序列以廣播的方式發送給各個從節點,開始新一輪通信。當有新的節點加入時,總線的消息傳輸完成,該節點立即控制總線(臨時生成第二高優先級偽ID方式搶占總線,真正ID寫入數據場),發送消息給接收節點和主節點,主節點提取此消息的真正ID重新排列ID序列,把此更新后的ID序列以廣播方式發給各個從節點(包括新加入的節點),開始新一輪通信。
2.4 算法實例說明
本文通過實例來更清晰地說明此算法。假設節點A有消息m1,節點B有消息m2,節點C有消息m3,節點D有消息m4,節點E有消息m5,節點F有消息m6。m1優先級最高,m6優先級最低,m1、m2的周期為10 ms,m3、m4的周期都為20 ms,m5、m6周期都為30 ms。剛開始在CAN中進行通信的節點有節點A、B、C、D、F,各節點消息通信如圖6所示。
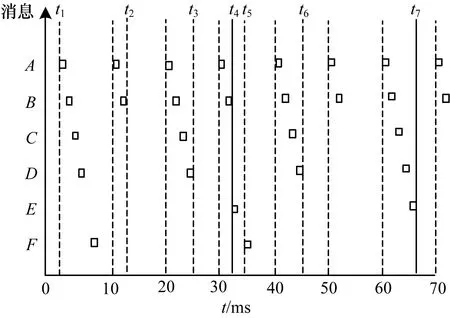
圖6 各節點消息通信情況
從圖6可知,剛開始主節點在0時刻發送ID序列給各個節點。在t1時刻,各個從節點收到ID序列,CPU產生中斷響應,進入圖5所示的程序判斷后(為方便分析,忽略CPU中斷和處理的時間),因為是在各個消息的第一周期,所以節點A、B、C、D、F中的消息按ID序列有序發送到接收節點和主節點,相鄰優先級節點消息之間的最小延遲為上一個消息的傳輸時間大小。傳輸完各節點消息后,經過一段總線空閑到了10 ms時刻,到了節點A、B的消息周期,按ID序列發送消息m1、m2,由于節點C、D消息周期為20 ms,節點F消息周期為30 ms,所以節點C、D、F不發送消息,在t2時刻就完成消息傳輸。經過一段總線空閑后到了20 ms時刻,到了節點A、B、C、D的消息周期,根據ID序列發送消息,由于沒到節點F的消息周期,節點F不發送消息,在t3完成消息傳輸。經過一段總線空閑到了30 ms時刻,節點A、B發送消息,在t4時刻E節點加入總線,按前面所述方法立即控制總線發送消息m5給接收節點和主節點,主節點提取此消息的ID在節點重新排列ID,發送新的ID序列給節點A、B、C、D、E、F,各節點再通過周期判斷是否發送消息,在t5時刻,只有節點F到了發送周期,發送消息。在t7時刻,主節點沒收到節點F的消息m6,主節點報錯,刪除此消息ID(錯誤閾值設置為1,這個根據消息重要程度設定)并重新排列ID序列,發送給節點A、B、C、D、E、F,所以最后進行通信的消息有m1、m2、m3、m4、m5,開始新一輪通信。
由本文算法可知,主節點不需要頻繁地發送時標消息對各個從節點時鐘同步,只需一開始發送預設好的ID序列和更新后的ID序列給各個從節點,對于報錯的節點消息用刪除ID的方法屏蔽,相比文獻[16]方法只需一個主節點接收總線上所有的消息,節約了CPU軟硬件資源。明顯可以看出,SIDS混合算法通過融合TTC-SC3算法和動態ID序列算法的優點,弱化了它們各自的缺陷。
3 仿真實驗結果與分析
3.1 仿真模型
CANoe是德國VECTOR公司為總線開發推出的一款集建模、仿真、測試與診斷等功能于一體的軟件。首先在CANoe中的CANdb++ Editor寫好有關的DBC文件,各參數如表1所示,其中,通信速率為500 Kb/s。建立包括主從節點的8節點仿真模型,如圖7所示。其中,Main_Node是主節點,New_Node_1到New_Node_6是發送節點,Receive_Node是接收節點。
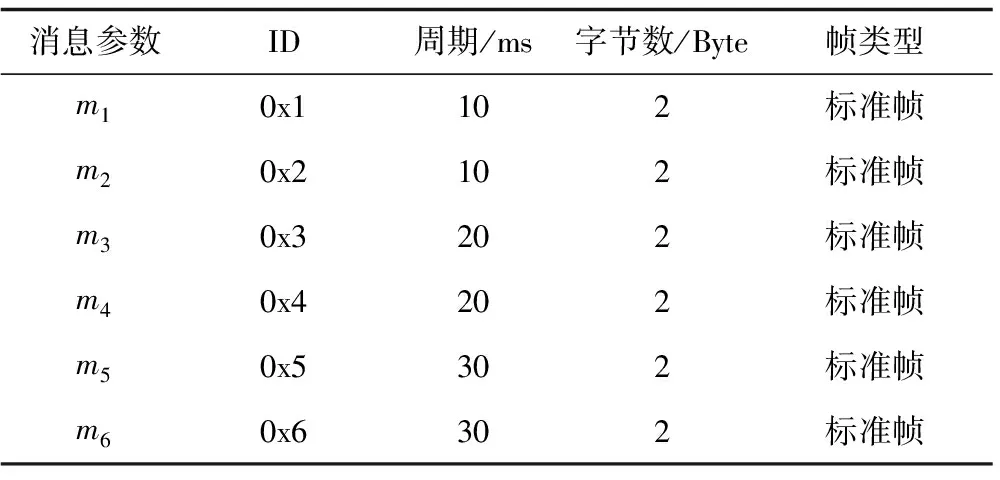
表1 各消息的參數
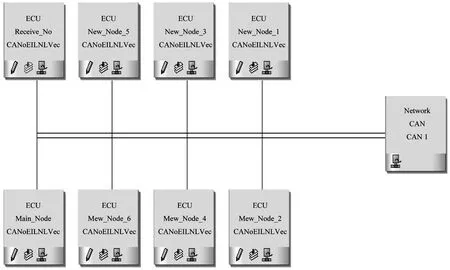
圖7 CAN網絡中節點仿真模型
3.2 結果分析
在Trace窗口可以看到相關報文數據,各消息的報文數據如圖8~圖13所示。由各個消息的ID可知,總共占3個字節長度,根據式(9),主節點通過總線發送給各個從節點的最大傳輸時間是170 μs,假設主節點的消息從0.100 000 s開始發送,如圖8所示,從節點接收的時間為0.100 152 s,即從消息發出到被接收的延遲為152 μs,小于170 μs,是合理的。接著各個從節點按ID序列發送,由于m1的優先級最高,m6的優先級最低,消息m1先發送,m1字節數為2,所以最大傳輸時間是150 μs,消息m1被接收的時間為0.100 288 s,即延遲為136 μs,小于150 μs,是合理的。因為消息的字節數都設置為2,傳輸時間都為136 μs,從圖8~圖13各個消息被接收時間可知,消息之間的延遲都約為136 μs,與理論符合。

圖8 m1報文數據

圖9 m2報文數據

圖10 m3報文數據

圖11 m4報文數據
圖12 m5報文數據

圖13 m6報文數據
4 結束語
CAN總線是目前汽車上應用最普遍的總線,對CAN總線研究有實際意義。本文通過CAN控制系統的時延分析可知,消息的延遲主要體現在排隊等待時間Tw和Tc上,而忽略排隊等待時間Tw。本文結合TTC-SC3算法和動態ID序列算法,提出一種SIDS混合算法,該算法可有效避免消息的碰撞,消除消息的Tw時延,提高消息的實時性和穩定性。最終通過CANoe軟件建立的仿真模型驗證了該算法的有效性。
