面向財稅領域的實體識別與標注研究
2020-05-18 11:08:36仇瑜,程力
計算機工程 2020年5期
仇 瑜,程 力
(1.中國科學院新疆理化技術研究所,烏魯木齊 830011; 2.中國科學院大學,北京 100049;3.新疆民族語音語言信息處理實驗室,烏魯木齊 830011)
0 概述
隨著對谷歌知識圖譜研究和應用的深入,知識庫成為理解自然語言中實體和關系的背景信息。基于知識庫的各類智能應用(如檢索、推薦、問答等)也得到了廣泛研究,并已取得顯著效果[1-2]。目前通用知識庫如YAGO、DBpediat、NELL和FreeBase等已經形成較大的規模,但是這些知識庫仍然不夠完備,需要不斷對其缺失信息進行補充。
近年來,為解決信息缺失問題,知識庫擴充技術得到廣泛關注。在通用領域,相關研究主要從非結構化的文本中抽取三元組信息(實體,關系,實體),如DeepDive、NELL等[3-4]。這些研究主要關注實體和實體之間的關系抽取,對實體類別標注考慮較少(或僅涉及較為有限的實體類別)。通用領域知識庫較重視知識的廣度,而特定領域知識庫強調知識的深度,其更加關注實體的類別信息。相較于通用領域,特定領域的實體類別更加豐富,而且具有較深的層次結構。
傳統的命名實體是指現實世界中某個對象的指稱(如人名、地名、機構名等),在近期的一些研究中,命名實體的范圍更加廣泛,實體類別粒度也更細致。如在某些特定領域(如金融、醫療、生物等),命名實體還可以指商品名稱、會議名稱、疾病名稱等[5]。更廣泛而言,實體還包括某類實物的總稱,如“大象”是一類動物的總稱,而不是特定的某個動物。在財稅領域中,命名實體涉及更加復雜的實例,如“征稅對象”是一個范疇較高的實體,在實際應用中需要識別某類實體而不是具體的某個實體,如“建筑物/辦公樓”可以當成一個實體,而不是某個具體地址的樓房。特定領域中的實體類別較多,而且分類更細,傳統的命名實體識別方法無法對特定領域實體進行準確地識別與標注。
實體類別預測可以看作分類任務,其目的是將已識別出的候選實體分類到預定義的實體類別中。一般采用有監督學習的方法從標注語料中抽取實體特征,訓練分類器然后進行實體類別預測,但是這種方法仍然存在如訓練語料不平衡和機器學習算法偏見等問題[6]。此外,相比于通用領域,特定領域語料(如財稅法規和案例)中的實體識別和標注還面臨2個方面的挑戰,一為特定領域缺少相關的標注語料和資源,二為目前的實體識別工具主要適用于通用領域,應用于特定領域時效果不理想。
本文構建細粒度的領域類別集和訓練語料,并研究適用于特定領域的實體識別方法和細粒度實體標注方法。
1 相關工作
文獻[7]提出一種基于卷積神經網絡聯合模型的細粒度實體標注方法,以對知識庫進行擴充。該方法取得了較好的效果,但它是面向通用領域的實體標注,標注模型無法利用領域實體的特征,而且文獻中沒有關于實體邊界識別方法的描述。
在實體邊界識別研究中,早期學者多使用詞性標注和句法依存關系將名詞短語作為候選實體[8],這種方法只能識別形式比較規范的實體。目前,比較通用的方法是將實體識別看成序列標注任務,構建標注器(如條件隨機場模型),通過特征模板訓練實體特征,以對實體邊界進行標注[9-10]。近年來,研究人員開始使用深度學習模型進行序列標注,并已取得較好的效果[11-13]。但是這些方法主要應用于通用領域,針對特定領域實體識別的相關研究還相對較少。
實體標注首先需要定義一組實體類別集,文獻[10]從知識庫Freebase中定義了一組包含112個類別標簽的扁平化實體類別集FIGER。文獻[8]進一步將FIGER的類別集組織成一種層次結構以對實體進行類別標注。文獻[14]提出一個包含505個類別標簽的5層深度的層次化類別集,該類別集的定義借鑒知識庫YAGO、Wikipedia和WordNet的結構。目前,在財稅領域幾乎沒有可用的相關資源,需要研究領域知識特征并定義領域實體標注集。
實體標注方法多數采用分類算法,文獻[10]使用了線性分類器對實體類別進行預測,特征集包括詞法、上下文、聚類等特征。文獻[14]利用SVM分類器對實體進行分類,使用字符、語法、詞典、上下文等特征。文獻[8]使用局部分類器和扁平分類器進行分類,并對比測試了兩者的分類效果,特征集選用實體的詞法、句法及文檔主題特征。由于領域實體的特殊性和復雜性,單一的分類器通常泛化能力較差,難以取得令人滿意的效果。
本文提出一種針對特定領域的實體識別與標注方法。定義財稅領域實體標注集,通過遠程監督的方法構建針對實體識別和細粒度實體標注任務的語料集。對傳統基于詞向量的方法進行改進,提出一種字符特征與詞向量相結合的方法并構建神經網絡模型,提高領域實體的識別效果。根據領域實體類型多樣、結構復雜的特點,提出一種基于集成學習的層次分類算法,以進行實體類別標注。
2 研究方法
2.1 問題定義
本文主要關注中文財稅領域的實體識別與標注問題。定義一組領域實體類別集,從非結構化的領域文本中識別出領域實體,并對實體所屬的類別進行預測,最后根據標注結果將識別出的實體加入到現有知識庫中。上述過程形式化表示為:輸入領域文檔集D={d1,d2,…,di,…,dn}、領域知識庫Kd以及從知識庫中定義的一組類別集T={t1,t2,…,ti,…,tn},需要從領域文本中識別出實體E={e1,e2,…,ei,…,el},同時判斷每個實體ei的標注類別Tm={tj,tj+1,…,tk}(可以有多個類別)。標注條件使用F=E·T{0,1}表示,f(e,t)=1表示實體指稱e標注為類別t,將實體e更新到知識庫中。
如財稅案例中的一個句子“[2018年3月]時間[新豐機械公司]企業將公司持有的一幢[寫字樓]商業建筑[出租]事件,[租金]收入每年為[3 000萬元]金額”。通過實體識別,抽取出句中的實體“寫字樓”,計算學習函數f(寫字樓,商業建筑)值為1,將實體“寫字樓”標注為“物品/財產/建筑/商業建筑”,這些標注信息可以用于稅務分析(商業建筑與非商業建筑有不同的稅率)。
本文實體識別與標注方法的總體系統框架如圖1所示。根據領域知識庫構建實體標注類型集,并使用遠程監督的方法構建用于實體識別與標注的語料庫。使用深度學習的方法學習訓練語料中領域實體特征,確定新實體邊界。通過集成學習的方法對實體類別進行預測,作為相應概念的實例并進行標注,最后根據類別標簽將新的實體加入到知識庫中。
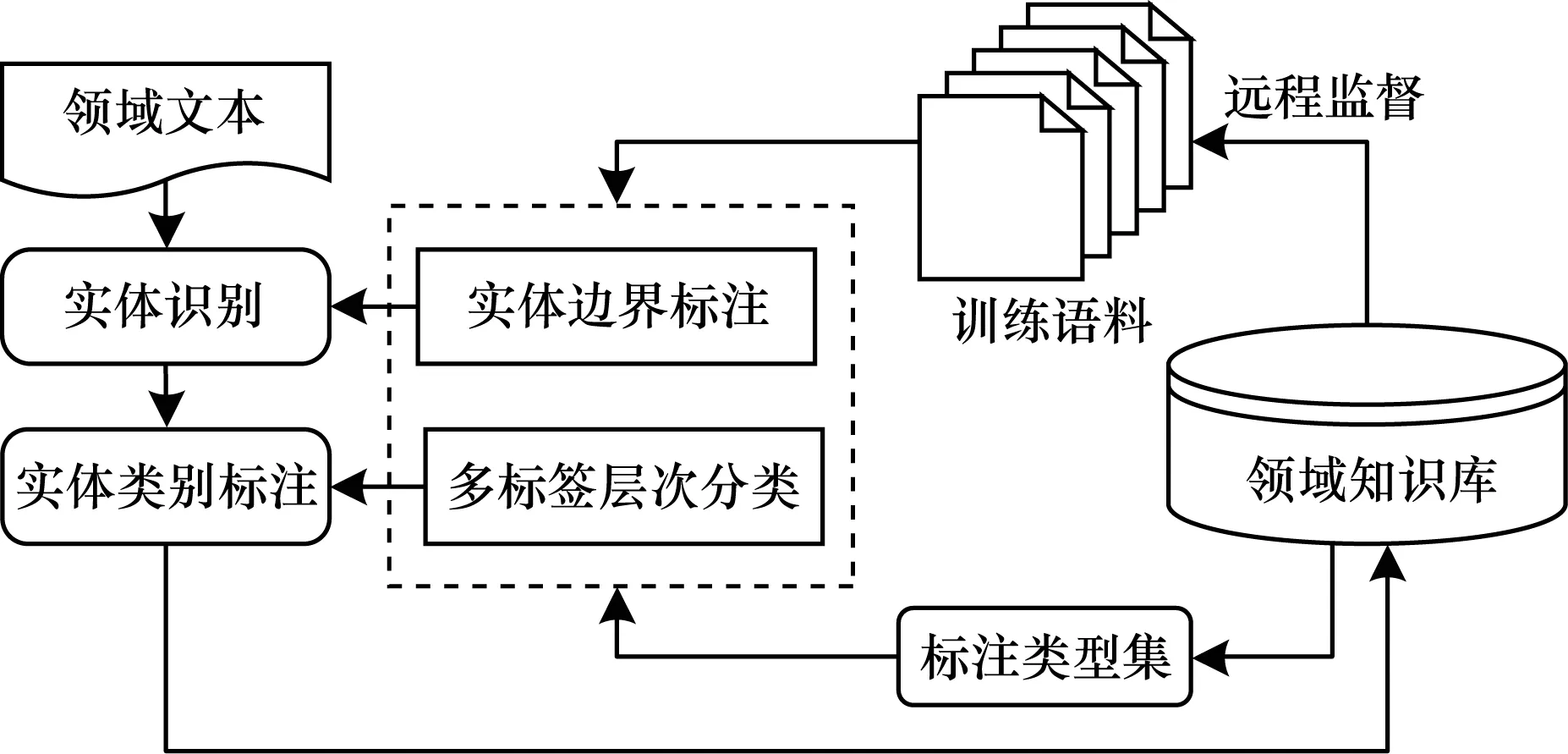
圖1 實體識別與標注方法總體系統框架
Fig.1 Overall system framework of entity recognition and tagging method
2.2 財稅領域知識庫
文獻[15]使用半自動化方法構建財稅領域知識庫,構建過程如圖2所示。由領域專家確定領域中的基本概念和概念間的關系,同時參考現有本體中與財稅相關的知識結構,建立頂層本體;使用規則和統計相結合的方法進行術語抽取和關系抽取;通過專家驗證將抽取的概念和關系加入到頂層本體中。目前,財稅知識庫包含1 326個概念、2 326個關系及23 543個實例。
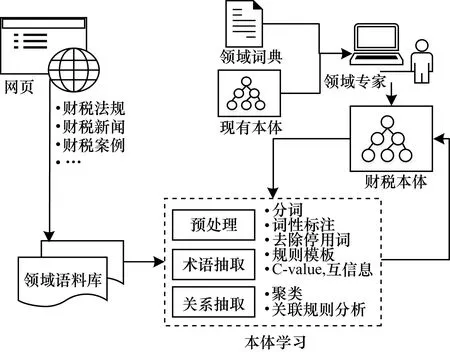
圖2 財稅領域知識庫構建過程
Fig.2 Procedure of knowledge base construction in the fiscal and taxation domain
2.3 標注集和語料庫構建
2.3.1 實體標注集
由于知識庫中的概念多且復雜,有些概念下的實例過于稀少,因此對所有的實體進行類別標注難度較大。為了構建合理的實體標注類型集,本文綜合考慮類型的多樣性、流行度及其在領域中的重要程度,以保證每個類別都有一定數量的實例。本文選取實例數大于15的本體類交給領域專家進行評估,最后確定了263個重要類別,并根據知識庫的結構進行組織,形成7個頂級類別、256個子類、最大深度為4的層次類別集合,標注集示例如圖3所示。
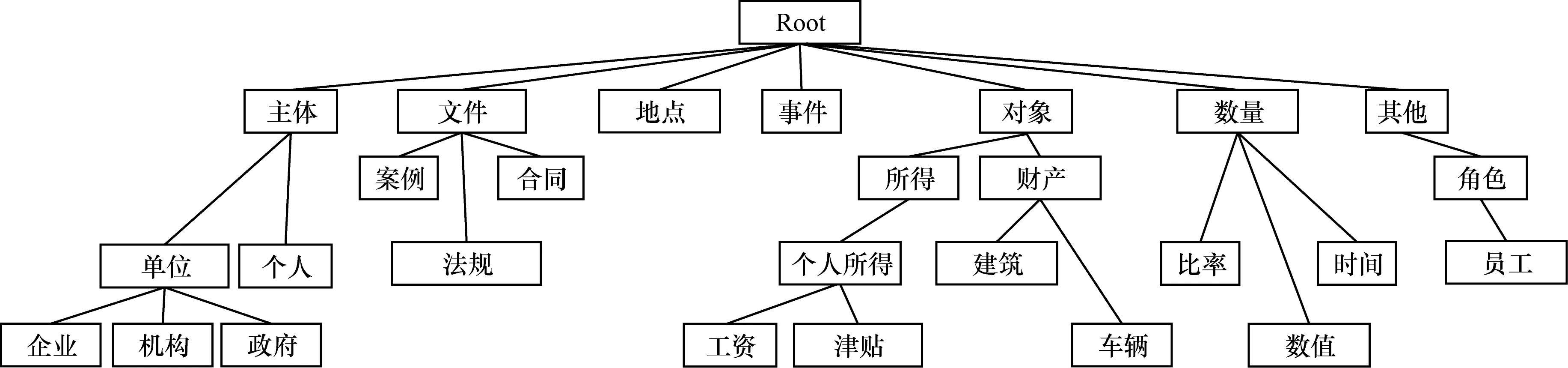
圖3 財稅實體標注集示例
類別集合中包括7個大類:
1)主體(Agent):對客體有認識和實踐能力的對象,主要包括單位和個人。
2)物體(Object):任何能夠被感知或客觀存在的東西,在財稅領域主要指征稅的對象,如所得、貨物、服務、財產、資源等。
3)文件(Document):意識或思想的書面表達形式,財稅領域中主要涉及法規、案件、合同、票據、報表等。
4)事件(Event):在特定時間和地點發生的可觀察到的事件,如購買、出售、出租、租賃等。
5)地點(Location):描述地理信息,如國家、省、區域等。
6)數量(Quantity):事物的多少、比例、大小、貨幣等。
7)其他不屬于前6類的實體,如角色、稅種、行業等。
2.3.2 訓練集
標注的語料主要為財稅案例集,財稅案例中一般為某類涉稅行為及其處理方法的文本描述,其中包含了大量的領域實體。此外,解釋型的法規中也包含了一些重要實體,為了更全面地獲取實體信息,本文同時選取了部分解釋型法規。
本文標注語料的過程使用文獻[16]提出的遠程監督方法,該方法會產生一些噪音數據,為了提高訓練集的質量,本文使用多種啟發式規則對標注語料進行清理。首先針對標注有多個同級類型的實體,刪除同級類型標注,只保留其父類型,其次刪除標注類型與預定義類型不一致的實體標注,最后刪除出現次數少于設定閾值的實體。
2.4 基于字詞特征結合的實體識別
相比于傳統的命名實體,中文財稅領域的實體識別面臨以下挑戰:
1)包含的實體數量和種類多。
2)待識別的實體可能會由許多單詞修飾,導致實體的邊界難以劃分。
3)財稅領域語言沒有統一的命名方式,因此,待識別的實體可能會有多種表述方式,這些實體的特征通過手工方式通常難以準確提取。
基于以上原因,本文使用基于深度學習的策略提取實體特征,結合CRF模型對財稅領域的實體進行識別。在基于深度學習的實體邊界識別研究中,詞向量被證明能夠在一定程度上提高淺層機器學習方法的效果[12,17-18]。但是,詞向量無法對字符級的特征進行很好地表示,原因是中文的字和詞都具有一定的語義信息,相同的字組成不同順序的詞語,其語義可能差別很大。因此,研究基于字的信息可以獲取更多的實體特征,進而提高實體識別的準確率。但是,基于字的特征由于窗口大小的限制,導致其獲取信息的能力有限。另外,中文詞語具有特殊的含義,僅使用字的特征也無法高效關聯出字詞之間的聯系。
本文綜合考慮實體的字符特征及詞特征,對實體邊界進行識別,如圖4所示,模型整體框架共由三部分組成:
1)獲取輸入句子的詞向量表示,對每個詞獲取其中每個字的向量,字向量再組成詞的字向量矩陣,通過卷積神經網絡(Convolutional Neural Network,CNN)對字向量矩陣進行卷積和池化,獲取每個詞的字特征。
2)對每個詞的字向量和詞向量進行拼接,將拼接結果輸入雙向長短時記憶(Bidirectional Long Short-Term Memory,BLSTM)網絡進行實體識別。
3)由CRF層對BLSTM層的輸出進行解碼,得到最優的標記序列。
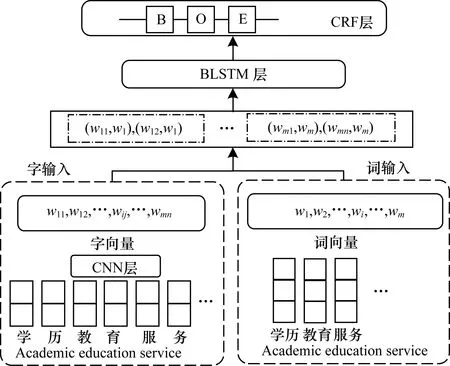
圖4 基于字詞特征結合的深度神經網絡模型
Fig.4 Deep neural network model based on the combination of character and word characteristics
CNN中的卷積層對數據的局部特征具有較好的描述能力,通過池化層可以抽取出局部特征中最具代表性的內容[17]。CNN的結構主要包括字向量表、卷積層和池化層,如圖5所示。首先字向量表將詞中的字轉化成對應的字向量并組成詞的字向量矩陣,以長度最大的詞為準,在詞的左右兩端補充占位符(padding)使所有字向量矩陣的大小一致,模型訓練時字向量表通過反向傳播算法進行更新;然后在卷積層對詞的字向量矩陣進行卷積操作提取詞的局部特征,卷積核大小為T(可以提取詞周圍T個詞的特征);最后通過池化操作對特征進行壓縮獲得詞的字向量。

圖5 字級CNN模型
LSTM模型的門結構可以有選擇地保存上下文信息[19],本文利用BLSTM網絡結構,分別采用順序和逆序對每個句子進行計算,得到2個不同的隱層表示,再將相應時刻輸出的結果拼接得到最終的隱層表示。對句子各個位置進行標注時沒有利用已經標注過的信息,因此,接入CRF層進行標注。CRF層通過分析相鄰標簽的關系得到全局最優的標記序列,從而進行句子級的序列標注[20]。對于句子S=w1,w2,…,wi,…,wn,通過訓練得到BLSTM層輸出大小為N×K的矩陣P,其中,N為詞數,K為標簽種類。設pij為句中第i個詞第j個標簽的概率,則模型對句子序列y={y1,y2,…,yn}的預測概率為:
(1)
其中,A為轉移矩陣,大小為K+2(包含句子開始和結束標記)。整個序列的打分等于各個位置的打分之和,可以利用此前已經標注過的標簽為一個位置進行標注。使用Softmax歸一化句子標記序列為y的概率如下:
(2)
其中,YX為可能標記的集合。模型訓練使用最大化似然函數,則標記序列的似然函數為:
(3)
通過式(3)得到合理的輸出序列,然后通過Viterbi算法預測輸出整體最優路徑:
(4)
在模型訓練時,使用RMSprop作為優化器,能夠取得比隨機梯度下降SGD模型更快的訓練速度(學習率設為0.002),在BLSTM輸入和輸出部分增加dropout(值為0.5),可以減輕過擬合現象[21]。
2.5 基于集成學習的實體標注
對已識別出的實體進行語義類別預測的過程可以看作層次分類問題,分類過程允許有多條標簽路徑以及部分標簽深度(實體的標簽路徑可以以非葉子類別結束)。
2.5.1 層次分類
層次分類問題是機器學習領域中的一個重要研究課題,該問題的求解方法主要分為平面分類法、局部分類法及全局分類法3種[22],各方法的對比如表1所示。

表1 層次分類方法對比
由于本文的實體標注任務需要滿足多標簽和部分標簽深度,為了方便分析各類別的實體特點,本文采用局部分類法獲取實體的類別標簽。標注過程如圖6所示,首先為類別層次中除Root節點外的每個節點訓練一個二分類器(圖中用虛線框表示),然后對候選實體進行自上而下的分類,由每個類別上的分類器判斷實體是否屬于當前類別。
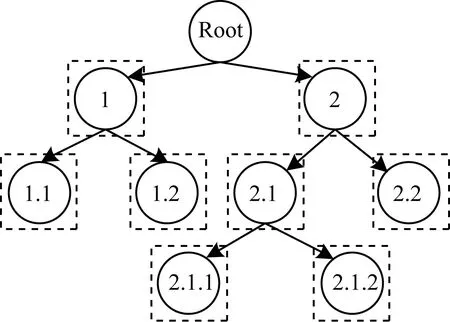
圖6 自上而下的局部分類法
在層次分類過程中,很多類別實例非常少,即訓練樣本數量在類別間分布不平衡,因此,容易導致數據過擬合問題。傳統的單個分類器方法在解決不平衡分類問題時性能通常會下降,得到的分類器具有偏向性。為了解決該問題,本文使用集成學習方法,根據分類器的差異度選擇多個分類器進行集成,以提高分類的準確性。
2.5.2 集成學習
集成學習的目的是根據樣本訓練多個分類器以對數據集進行預測,解決單個分類器訓練數據量小、假設空間小和局部最優解的問題,從而提高整體分類的泛化能力,降低分類誤差[23]。
集成學習的方法主要有Bagging和Boosting 2種,前者的個體分類器間不存在強依賴關系,可以并行執行,后者個體分類器之間有強依賴關系,需要串行執行[6,24]。在實際任務中,由于Boosting算法會出現過擬合現象,導致分類結果比單個分類器還差,因此,本文采用Bagging算法進行分類器集成。Bagging是基于數據隨機重抽樣的分類器構建方法,對于給定訓練集D,其每次訓練時根據均勻概率從D中有放回地抽取樣本di,使用di訓練基分類器Ci,在采樣T次后,訓練得到T個分類器C1,C2,…,Ct。對待測樣本x,分別用T個分類器進行預測,通過多數投票的方法H(x)輸出分類結果。由于訓練樣本為有放回地隨機抽取,對訓練集中的實例選擇沒有偏重,增加了集成學習的差異度,從而提高了分類的泛化能力。此外,算法在不穩定點處使用類似于平滑處理的方法,能夠提升不穩定分類算法的精度。Bagging算法詳細過程如下:
算法1Bagging算法
輸入training datasetD={(x1,y1),(x2,y2),…,(xn,yn)},Base classifierC,Number of learning roundsT

Iterative process:
For t=1toT;
Dt=Bootstrap(D);//a bootstrap sample from D
h(t)=C(Dt)//train a classifier Ctfrom Dt
傳統Bagging算法使用一個簡單弱分類器,通過處理數據集產生多個差異性分類器。本文對該算法進行改進,將迭代算法中分類器的對象從單個算法擴充到不同的分類算法。分類算法的選擇使用了文獻[25]中分類器差異性評估的方法,選擇支持向量機、邏輯回歸及多層感知機3種分類器進行集成,對于每個分類器的分類結果采用簡單投票法[6]確定最終類別。
2.5.3 特征選擇
在分類任務中,特征選取是一個很重要的步驟[26]。對于實體的分類特征,本文參考文獻[5,14]中關于實體特征的描述,此外還考慮實體所在句子中的臨近動詞特征、實體本身的詞向量特征以及實體所在文檔的主題特征,實體標注特征集如表2所示。

表2 實體標注特征集
3 實驗結果與分析
3.1 評估指標
對于實體識別測試,本文使用準確率、召回率及F值進行評估,三者的計算方式如下:
(5)
(6)
(7)
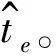
(8)
2)Macro:計算每個實體的準確率及召回率。
(9)
3)Micro:計算總體的準確率與召回率。
(10)
其中,P為準確率,R為召回率。
3.2 實驗設置
本文實驗使用的實體識別和標注語料庫包括了1 000個財稅法規和3 000個財稅案例,通過遠程監督的方法標注文本中的實體及其類別信息,選取其中800個法規及2 200個案例作為訓練集,然后由領域專家通過標注平臺人工標注200個法規及800個案例作為測試語料。語料基本統計信息如表3所示,標注示例如圖7所示。
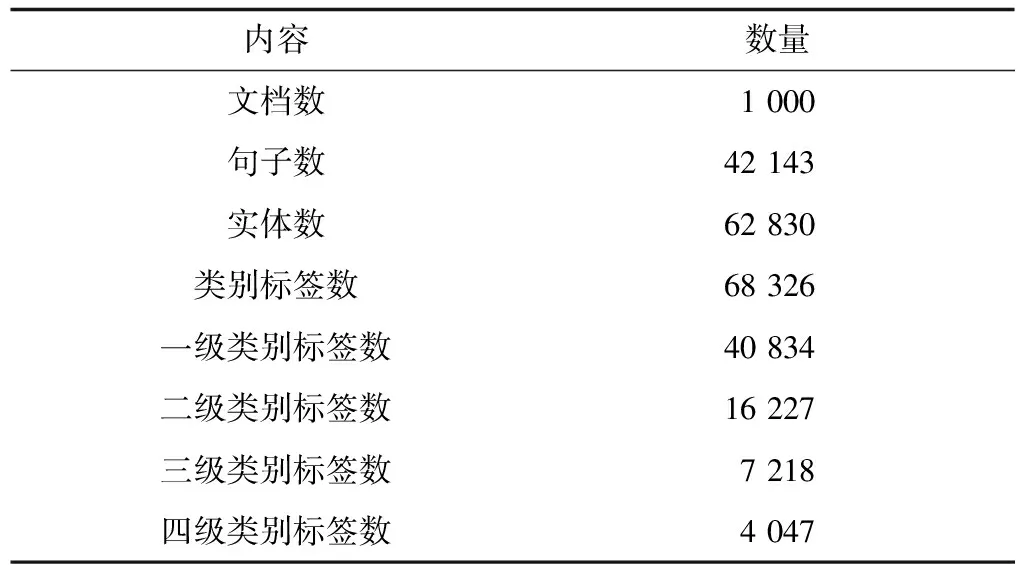
表3 語料統計信息

語料[2010年5月]份,[藍天建筑安裝公司]的經營業務如下:銷售[建筑裝飾材料]銷售額[82萬元],取得的[增值稅專用發票]的進項稅額[10.8萬元]標注信息2010年5月:數量/時間藍天建筑安裝公司:主體/單位/企業建筑裝飾材料:物體/貨物增值稅專用發票:文檔/票據82萬元,10.8萬元:數量/金額
圖7 實體標注示例
Fig.7 Example of entity tagging
3.3 結果分析
3.3.1 實體識別評估
本文在語料處理時使用BIOES(Begin,Inside,Other,End,Single)方法代替BIO來標記實體,這樣能夠清楚地表示和劃分語料中待識別的領域實體邊界[27]。深度神經網絡模型在整個語料集上的實體識別結果如表4所示(W表示詞特征,C表示字符特征)。
表4 不同方法的實體識別結果對比
Table 4 Comparison of entity recognition results of different methods %
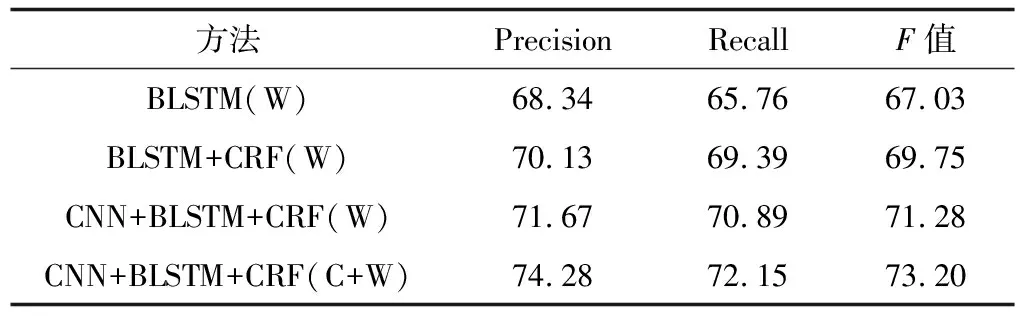
方法PrecisionRecallF值BLSTM(W)68.3465.7667.03BLSTM+CRF(W)70.1369.3969.75CNN+BLSTM+CRF(W)71.6770.8971.28CNN+BLSTM+CRF(C+W)74.2872.1573.20
為了驗證CRF模塊的有效性,將BLSTM+CRF與BLSTM模型進行對比,從表4可以看出,增加CRF模塊后實體識別的準確率、召回率、F值均有所提高,主要原因是CRF能夠利用相鄰標簽的關系對序列進行全局標注,提高對較長及帶有修飾詞匯的財稅實體的識別效果。對比CNN+BLSTM+CRF和BLSTM+CRF模型發現,CNN模塊對實體抽取結果也有一定程度的提高,這是因為CNN模塊抽取的字向量能夠表示實體的形態特征。最后對比基于詞向量的方法和基于字詞向量相結合的方法,結果表明,相比基于詞向量的方法,字向量與詞向量相結合的方法在準確率、召回率和F值上分別提高了2.61%、1.26%和1.92%,這是由于字詞向量相結合的方法將實體的詞特征和字符特征進行組合,得到了更豐富的特征表示,對于長度較長、帶有修飾詞匯的實體以及罕見實體(如“長期股權投資”),其識別性能較高。
利用基于詞向量的方法及基于字詞向量相結合的方法,在財稅領域對各類別中的實體(包括主體、文件、物體、事件、地點、數量及其他類別)進行識別,識別結果如表5所示。

表5 各類別中的實體識別結果
從表5可以看出,主體、文件、地點和數量類實體的識別準確率、召回率和F值相對較高,而物體類實體識別效果較差,這是因為物體類實體比其他類別中的實體更加復雜,而且有些子類中的實例相對較少。在物體類實體中,相比詞向量方法,字詞向量相結合的方法性能提高最明顯,原因是物體類別中的實體平均長度較長,字向量的加入提供了更多子詞的特征。此外,本文進一步分析實體識別錯誤的情況,發現錯誤的原因很大程度上是由于訓練語料中缺乏對相關類型實體的標注或者標注錯誤。因此,下一步考慮使用主動學習的方法,發現錯誤率較高的實體類型中的實例即交由專家標注,以提高實體識別的整體效率。
3.3.2 實體標注評估
在整個語料庫中,分別利用本文集成學習方法、邏輯回歸、支持向量機及多層感知機方法對實體進行標注。其中,邏輯回歸的正則參數設為0.3,支持向量機的參數C設為0.05,多層感知機的隱含層大小設為100,集成學習使用的迭代次數設為30。訓練過程中類別標簽下的實例為正樣本,其兄弟節點的實例為負樣本,測試結果(F值)如表6所示。
表6 不同方法的實體標注測試結果
Table 6 Testing results of entity tagging of different methods %
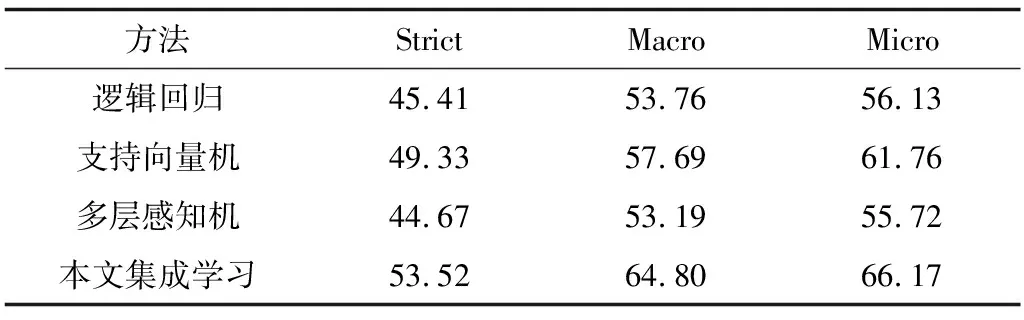
方法StrictMacroMicro邏輯回歸45.4153.7656.13支持向量機49.3357.6961.76多層感知機44.6753.1955.72本文集成學習53.5264.8066.17
從表6可以看出,相比單個分類器的方法,集成學習在Strict、Marco及Micro上的F值均有明顯提高。在各類方法中,Strict上的F值相對其他兩項指標明顯偏低,這是因為在上一步實體識別的過程中產生了很多錯誤的候選實體。Macro上的F值比Micro略低,原因是實體類型層結構中部分底層的類別實例較少,產生了長尾效應。進一步對標注錯誤的情況進行分析發現,標注錯誤的情況比較集中,某些類別的標注準確率較低,很大程度上是由于這些類別中訓練數據不足。
各不同層級類別標簽的標注結果如圖8所示,為了簡單起見,本文僅統計標注結果Micro上的Precision、Recall、F值,使用的方法為本文集成學習方法。從圖8可以看出,層次越深的類別,實體標注的效果越差,原因是高級別的類別具有更多的實例,類別之間的區分更明確,而層次結構較低的類別實例較少,實體的特征區別不明顯,甚至對于有些類別,人工標注可能也難以判斷。
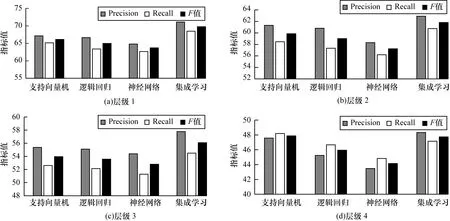
圖8 各層級實體標注實驗結果
本文對頂級類別中實體標注的實驗結果進行統計和分析,結果如圖9所示。從圖9可以看出,在數量和地點類別中,標注的準確率、召回率及F值明顯高于其他類別,這是因為這些類別中的實體特征更為明顯。相對地,物體類別的標注效果最差,原因是該類別中包含的子類更多,種類更為復雜。因此,下一步需要根據物體類別中的實體來選擇更有效的特征進行分析測試。
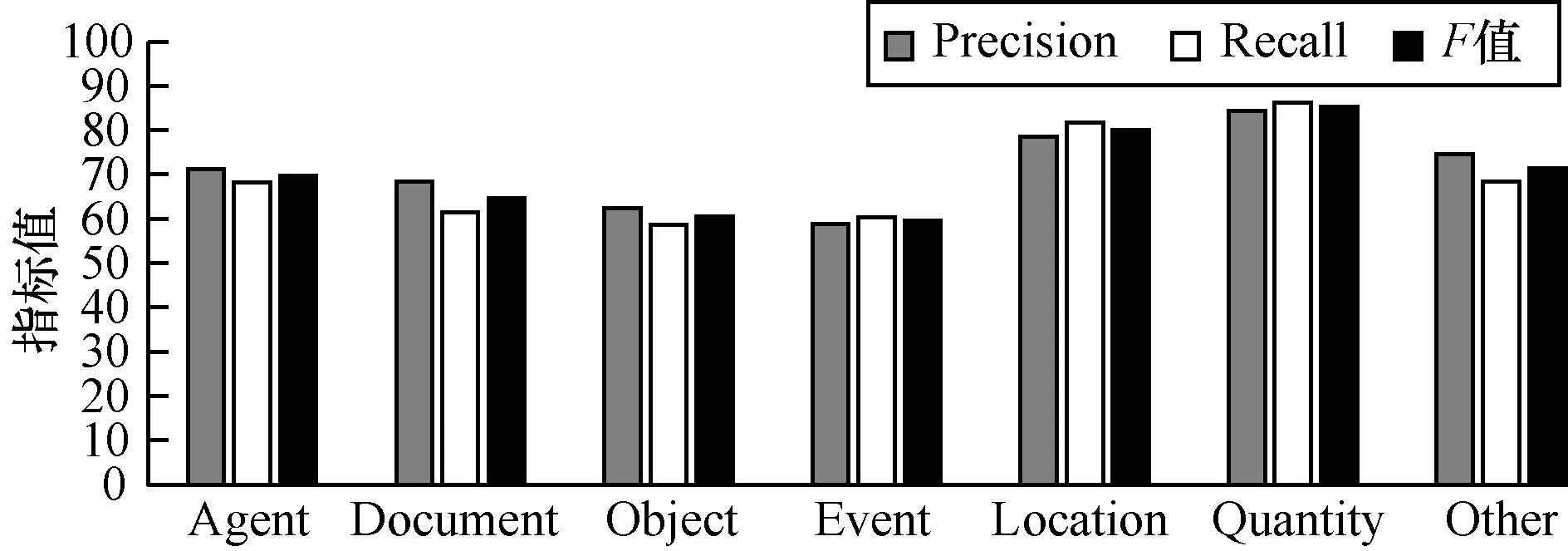
圖9 各頂級類別中的實體標注實驗結果
Fig.9 Experimental results of entity tagging of each top level
本文通過從特征集中刪除某個特征來判斷該特征對實體類別標注結果的影響,評估指標同樣使用Micro上的Precision、Recall、F值,標注方法為本文集成學習方法。從表7可以看出,去除主題特征、臨近動詞特征或詞向量特征后標注結果的準確率、召回率及F值均有不同程度的下降,即主題特征對標注結果具有影響,特別是對于物體、主體類別,原因是一般特征主題都有相應的納稅人和征稅對象類型。臨近動詞的影響主要體現在和特定類型的實體之間一般有固定的關聯關系(例如,在動詞“簽訂(簽字)”后的實體更可能被分類為“合同”類型)。通過實驗結果還可以看出,詞向量特征在預測不常見實體類型時的作用比較明顯。
表7 各類實體特征測試結果
Table 7 Testing results of each type of entity feature %
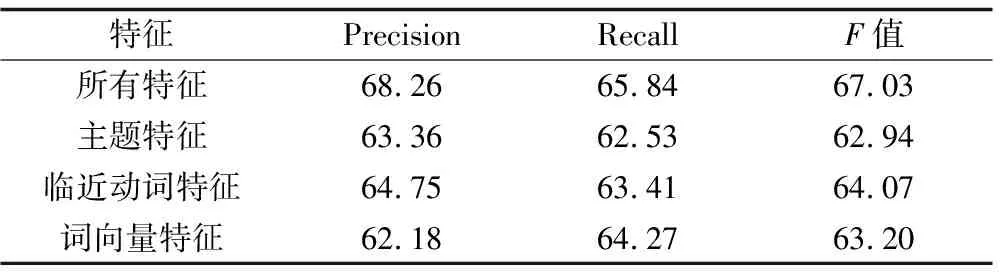
特征PrecisionRecallF值所有特征68.2665.8467.03主題特征63.3662.5362.94臨近動詞特征64.7563.4164.07詞向量特征62.1864.2763.20
4 結束語
本文對財稅領域的實體識別和標注方法進行研究,根據財稅知識庫定義一組領域實體標注集,使用遠程監督方法構建領域語料庫。通過深度學習方法對中文財稅領域的實體識別進行測試,采用基于字向量與詞向量相結合的深度神經網絡模型解決詞向量模型無法描述局部特征的問題。在此基礎上,使用層次分類的方法預測候選實體類別,并提出一種集成學習方法解決數據不平衡和單個分類器偏見的問題。實驗結果表明,該方法具有較高的準確率。下一步將研究和優化集成學習方法,在實體標注的集成方法中測試更多基分類器,如決策樹、樸素貝葉斯、k-最近鄰算法等,進一步優化分類效果,同時研究使用聯合學習方法將2個子任務合并成一個序列標注的問題。
猜你喜歡
數學小靈通·3-4年級(2024年2期)2024-05-15 02:02:28
世界科學技術-中醫藥現代化(2020年2期)2020-07-25 02:05:36
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
兒童故事畫報(2019年5期)2019-05-26 14:26:14
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
Coco薇(2016年2期)2016-03-22 02:42:52
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年7期)2015-08-11 15:03:12
小雪花·成長指南(2015年4期)2015-05-19 14:47:56
