面向物聯網的能耗感知虛擬網絡映射算法
2020-05-20 10:21:58趙季紅吳豆豆季文君
計算機工程 2020年5期
趙季紅,吳豆豆,曲 樺,季文君
(1.西安郵電大學 通信與信息工程學院,西安 710121; 2.西安交通大學 電子與信息工程學院,西安 710049)
0 概述
物聯網(Internet of Things,IoT)[1]是物物相連的互聯網,為滿足萬物互聯的需求,基礎設施提供商(Infrastructure Provider,InP)依據網絡虛擬化技術[2-3],在多樣化現有網絡的同時共享基板上的異構網絡架構,為多個服務提供商(Service Provider,SP)提供資源。隨著業務的增加,節點間規模龐大的數據交換愈加頻繁,因此,在虛擬網絡映射[4-5]時,合理高效地完成底層物理網絡資源分配、減少網絡能源消耗、降低網絡運維成本并構建綠色節能的網絡,成為相關學者關注的熱點問題之一。
目前,關于節能的虛擬網絡映射算法[6-8]研究較多。其中,文獻[9-10]以最小化底層工作節點的鏈路為目標,采用虛擬網絡映射算法(EA-VNE)降低能源消耗。但大量虛擬請求的到來會增加映射排斥率,減少收益。文獻[11]以最小化節點與鏈路能耗為目標,建立能耗模型,并通過能耗感知虛擬網絡映射啟發式算法(EA-VNEH)求解模型。該算法適應于節點異構網絡,但其將所有網絡資源的能耗視為相等,在實際應用中不可行。文獻[12]提出一種基于流量擬合模型的自適應能量感知VNE方法,通過有選擇地整合底層網絡資源并關閉鏈路,從而保證QoS約束并實現節能。但是該算法采用整數線性規劃求解問題,映射時間較長。文獻[13]出于生態考慮,提出一種綠色能量感知混合虛擬網絡映射算法,其將VN部署到與最小排放因子相關聯的扇區資源上,該方法旨在解決能源效率和資源整合問題,但對各地區能源類型進行調查會相對困難。以上虛擬網絡節能映射算法在互聯網場景下達到了較好的節能效果,但無法適用于物聯網中節點異構性更突出,初始狀態、能量消耗速率不同等能耗特性。
本文針對物聯網環境下節點異構性與鏈路時效性特點,提出一種改進的能耗感知虛擬網絡映射算法(Modified-EA-VNE)。在虛擬網絡映射之前根據不同業務的服務類型對虛擬請求做拆分處理,依據能耗模型,采用混合整數線性規劃方法將虛擬節點映射至同類型且能耗最小的物理節點上,并通過改進的K最短路徑算法為不同時延下的鏈路分配合適的資源。
1 問題描述與能耗模型
1.1 問題描述
為解決物聯網環境下的能耗問題,本文提出一種改進的能耗感知虛擬網絡映射算法,該算法根據業務的服務類型將每個到來的虛擬請求拆分為若干個小拓撲,并將拆分后的虛擬請求映射至滿足其要求的能耗最小的物理節點上。其中,每個虛擬節點與CPU容量約束相關聯,每條虛擬鏈路與帶寬容量和所需延遲相關聯,每個物理節點與CPU剩余值和識別節點能源類型的地理位置相關聯,每條物理路徑(連接2個物理節點)與剩余帶寬容量和延遲相關聯。
1.2 網絡拓撲
1.3 能耗模型
虛擬網絡請求映射至物理網絡的節點時,總能耗PN定義為[14]:
(1)
其中,Nw表示需要從未激活狀態變為激活狀態的宿主節點數量,Pb表示節點的基礎功耗,Pl表示轉發節點的能耗,Uutil(nj)表示節點映射所需的CPU利用率。
虛擬網絡請求映射至物理網絡的鏈路時,總能耗PL定義為[14]:
PL=NwPn+Nn(Pb+Pn)+d(u,i)α
(2)
其中,Pn是一個值為恒定常量的鏈路功耗[15],Nn表示需要從未激活狀態變為激活狀態的轉發節點數量,d(u,i)表示節點u到節點i的路徑距離,α表示距離因子。
1.4 虛擬網絡映射數學模型
在建立虛擬網絡映射能耗模型時,以最小化總能耗為目標函數,并滿足虛擬網絡資源的每個約束,根據混合整數線性規劃方法對虛擬網絡映射問題進行建模。目標函數為:
min (PN+PL)
(3)
約束條件為:
(4)
?j∈Nv,Ddis(Lloc(j),Lloc(Mn(j)))≤D(j)
(5)
?i∈Ns,?j∈Nv,Ggenre(j)=Ggenre(i)
(6)
(7)
(8)
(9)
(10)
(11)
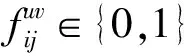
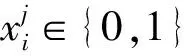
2 算法設計
本文虛擬網絡映射算法包括虛擬請求拆分、節點映射以及鏈路映射[16]3個部分。
2.1 虛擬網絡請求拆分
由于物聯網對實時性具有較高的要求,因此在虛擬網絡映射中需要考慮鏈路的時延問題。為了降低映射過程的復雜性并考慮鏈路的延遲特性,本文根據時延約束,對到來的虛擬網絡請求做拆分處理,將每個虛擬請求大拓撲拆分為一組虛擬請求小集群,在后續的節點與鏈路映射中,并行處理分割后的虛擬請求,縮短映射運行的時間。上述拆分基于虛擬鏈路Flagf(lv)的服務類型,每條鏈路用f(lv)做標記以區分該鏈路對時延的要求。在鏈路映射中,基于該拆分結果為每條虛擬鏈路分配滿足其服務類型的物理鏈路。如圖1所示,根據業務的需求將虛擬網絡拓撲圖拆分成S-V1和S-V2 2個小拓撲圖。
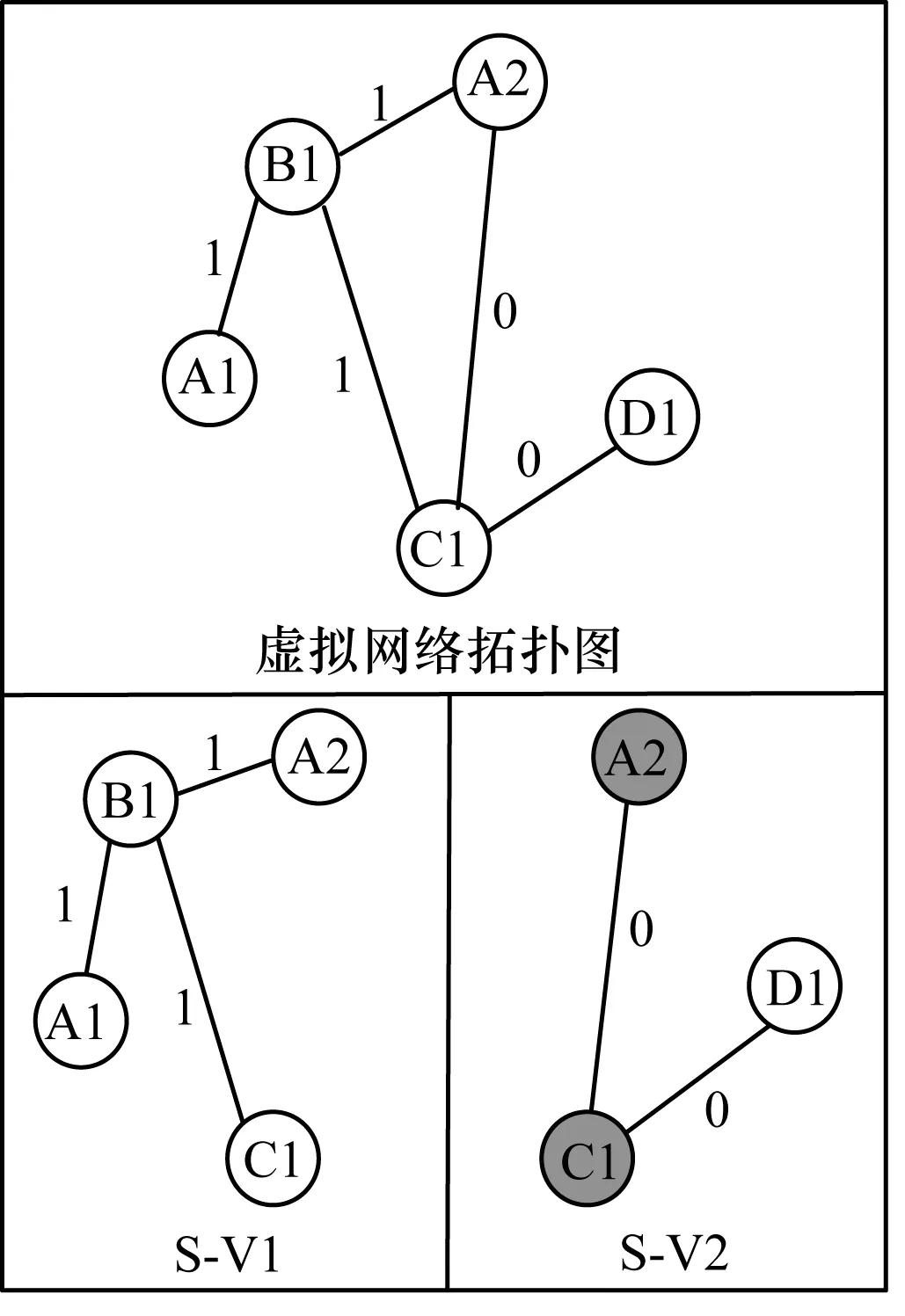
圖1 虛擬請求拆分示意圖
在圖1中,S-V1的f(lv)=1表示該拓撲圖具有延遲屬性,S-V2的f(lv)=0表示該拓撲圖具有帶寬屬性,其中,有灰色標記的2個節點為之前S-V1所映射過的節點,不再考慮其節點映射問題。虛擬請求拆分過程偽代碼如算法1所示。
算法1虛擬請求拆分算法

1.令Gr=Gv,i=1,Gv(i)=0
2.while 任意一條鏈路Lr≠φ do
3.lv(u,v)∈Lr,u∈Nr,v∈Nr
4.將Gr分配給Gv(S-V(i)),并標記分配節點Flag{u,v}
5.for與Gr相連接的其他鏈路lv(u′,v′)∈Lr
6.if (f(u′,v′)=f(u,v)|u′∈Nv(i) & v′∈Nv(i))
7.將新鏈路分配給Gv(S-V(i)),并標記Flag{u′,v′}
8.end if
9.end for
10.Lr=Lr-Lv(i)
11.i=i+1
12.end while
2.2 節點映射
由于物聯網底層是一個自組織網絡,因此針對節點異構性問題,本文依據節點的類型對底層資源進行分類。虛擬節點只能映射至同類型的物理節點上,從而避免開啟無關類型的節點。這種資源整合的方式可以減少底層資源的浪費,進而達到節能的目的。在節點映射階段,基于最小能耗和最接近剩余容量原則,將虛擬節點映射至同類型且能耗最小的物理節點上,本文將節點的資源能力[17]定義為:
(12)
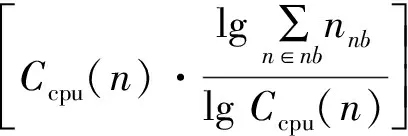
Ω(nv)={ns|Ccpu(nv)≤Ccpu(ns)&
Ddis(Lloc(nv),Lloc(ns))≤D(ns),
ns∈Ns}
(13)
映射節點的綜合資源能力為:
CCR(ns)=lg (NNR(ns)·PN(ns)+γ)
(14)
其中,γ→0,避免式(14)中對數函數內部出現0的情況。
節點映射算法通過將每個虛擬節點映射到能耗最小且滿足CPU需求的最少資源量的物理節點上,以降低網絡映射的能耗,提高物理資源的利用率。如圖2所示,將虛擬請求S-V2映射至底層網絡,首先考慮CPU為10的節點D2,然后選擇具有最少但足夠的CPU資源的物理節點作為候選節點,最后比較節點類型,將虛擬請求D2映射至物理節點D1上,并計算物理節點D1的剩余資源量。算法偽代碼如算法2所示,與以往的能耗感知映射算法相比,該算法通過將虛擬請求映射至CCR最小但滿足CPU要求的物理節點上,可有效節省能耗,提高物理資源的利用率。
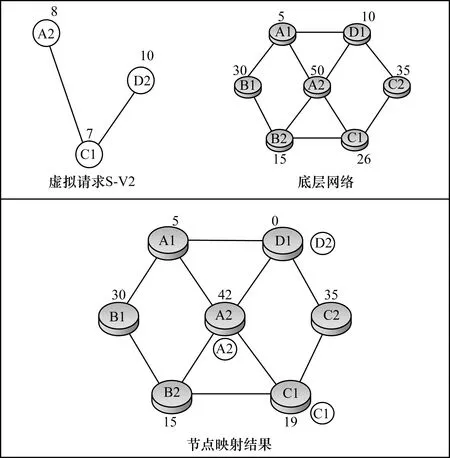
圖2 虛擬節點映射示意圖
算法2節點映射算法

輸出NodeMappingList,并作為鏈路映射的輸入參數
1.for 每一個虛擬節點nv∈Nvdo
2.計算虛擬節點nv的資源能力NNR(nv)
3.end for
4.將虛擬節點nv按資源能力NNR(nv)降序排列,并將結果存入 VNL中
5.for VNL中的每一個虛擬節點nvdo
6.構建候選節點集合且每個ns滿足虛擬節點的CPU資源和位置約束
7.if Ω(ns)≠φ then
8.for Ω(ns)中的每一個候選節點nsdo
9.計算CCR(ns)的值
10.end for
11.將ns按照CCR(ns)的值降序存入NodeList中
12.if Ggenre(nv(i))=Ggenre(ns(j)) then
13.將虛擬節點nv映射至CCR最小且滿足約束的物理節點ns上,并將結果集存入NodeMappingList中
14.end if
15.計算CPU剩余資源Ccpu(ns)=Ccpu(ns)-Ccpu(nv)
16.end if
17.end for
18.節點映射結束
2.3 鏈路映射
針對虛擬鏈路映射,通常采用K最短路徑算法[18-19],但在物聯網環境下,需通過傳感器實時、準確地傳遞物體的信息,對網絡資源的能耗以及鏈路的實時性要求較高。因此,在鏈路映射階段,本文通過整合鏈路映射過程中的能源消耗和鏈路延遲等因素,設計一種能耗優先且滿足鏈路延遲的K最短路徑算法。
如圖3所示,虛線箭頭表示2個節點之間的路徑,虛擬網絡中的x/y/z分別表示帶寬/時延閾值/是否對時延敏感。將虛擬請求S-V1映射至底層物理鏈路,首先根據節點映射算法確定映射成功的物理節點,然后依據帶寬需求優先選取資源需求量較高的虛擬鏈路進行映射。對于虛擬鏈路luv∈Lv,采用K最短路徑算法計算最短路徑集合φ(luv),且對于任意路徑Ppath∈φ(luv),需滿足虛擬鏈路luv的帶寬需求以及延遲容量,最后通過計算鏈路能耗PL,將虛擬鏈路luv映射至能耗最小的路徑上。
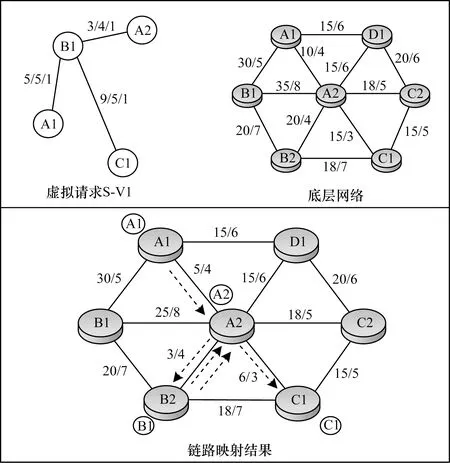
圖3 虛擬鏈路映射示意圖
鏈路映射算法偽代碼如算法3所示,與傳統算法相比,該算法考慮鏈路的時延問題,提高了算法的延展性,能夠更廣泛地適用于物聯網場景。在鏈路映射過程中,針對不同延遲需求的鏈路進行分開處理,可縮短鏈路映射的運行時間,降低網絡映射與鏈路映射的成本,從而增加映射收益。
算法3鏈路映射算法
輸出LinkMappingList,并計算評價指標
NodeMappingList
1.將虛擬鏈路按帶寬需求降序排序,并將結果存入鏈表VLL中
2.for VLL中的每條虛擬鏈路luvdo
3.采用K最短路徑算法計算底層節點的最短路徑集合φ(lij),且對于任意路徑Ppath∈φ(lij)
4.if φ(lij)=φ then
5.Return 映射失敗
6.else
7.for φ(lij)中的每一條最短路徑Ppathdo
9.end for
10.switch (待映射鏈路lr(flag)) do
11.case 0
12.if b(luv)≤b(lij) then
13.將虛擬鏈路luv映射至物理鏈路lij上,并將結果存入LinkMappingList中
14.case 1
15.if b(luv)≤b(lij) & d(luv)≥d(lij) then
16.將虛擬鏈路luv映射至物理鏈路lij上,并將結果存入LinkMappingList中
17.end switch
18.計算帶寬剩余資源b(ls)=b(ls)-b(lv)
19.end if
20.end for
21.鏈路映射結束
3 仿真結果與性能分析
在本文仿真中,由GT-ITM[20]生成設定的網絡拓撲,通過NS2[21]中的Tk工具生成可視化的網絡拓撲,對本文算法以及2種基于能耗感知的虛擬網絡映射算法進行對比,在底層物理資源使用數量、虛擬網絡請求能耗、映射時間以及底層網絡收益開銷比等方面驗證算法的性能。
3.1 仿真環境設置
本文通過GT-ITM生成網絡拓撲,具體實驗參數如表1所示,其中,虛擬節點與物理節點間的連通率均為50%,式(3)中的距離因子設置為0.5,K最短路徑算法中K的取值為5。針對節點的異構性特點,令Pb=150 W,Pm=300 W,Pn=15 W。每次實驗運行時間為30 000個時間單位,約有1 200個虛擬網絡請求到達,并運行10次實驗,取平均值作為最終結果。
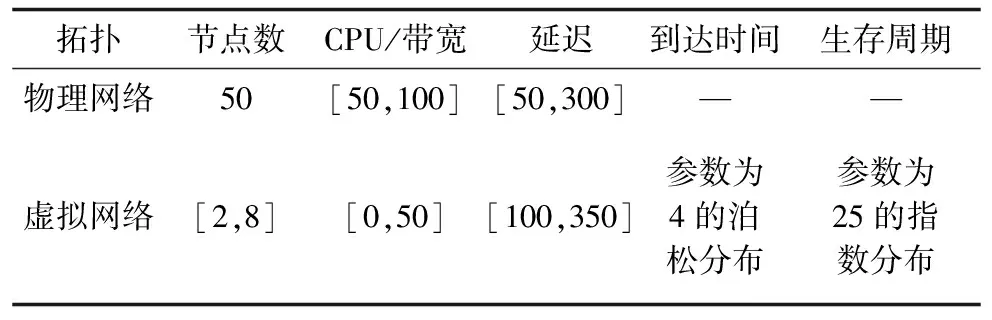
表1 實驗參數設置
3.2 性能分析
3.2.1 評價指標
本文實驗評價指標具體如下:
1)虛擬網絡請求平均能耗:
(15)
其中,E(i)為第i個虛擬請求消耗的能量,N為虛擬請求的個數。
2)收益開銷比:
(16)
其中,AT為時間T內接收的虛擬請求數量,R(i)和CCost(i)分別表示虛擬請求i的收益和成本,兩者具體定義如下:
(17)
(18)
3.2.2 結果分析
為了評估本文Modified-EA-VNE映射算法的性能,本節將其與EA-VNE、EA-VNEH兩種算法進行比較。EA-VNE算法以最小化底層網絡工作節點與鏈路數量為目標,在節點映射階段采用貪婪算法,鏈路映射階段采用最短路徑算法。EA-VNEH主要考慮節點能耗的異構特性,通過建立能耗模型使節點和鏈路均映射至新增能耗最小的底層網絡中。本節從工作節點和鏈路數量、虛擬網絡請求映射時間、映射所花費的能耗以及物理網絡收益開銷比等方面對算法進行比較。
1)工作節點與鏈路數量
圖4、圖5分別表示不同算法中虛擬網絡映射工作節點和鏈路的數量。從中可以得出,EA-VNEH算法所需的底層節點數量最多,Modified-EA-VNE算法最少,主要因為EA-VNEH算法著重考慮物理網絡節點的異構性,將虛擬請求映射至能耗最小的節點上,而Modified-EA-VNE算法在節點映射時采用資源整合的方式且基于最接近剩余容量原則,故所需的節點數最少。但在鏈路映射過程中,由于Modified-EA-VNE算法需考慮鏈路的延遲特性,故工作的鏈路略高于EA-VNE。Modified-EA-VNE算法考慮節點的異構性,將節點分配給同類型的節點,增加了使用同一物理節點作為映射節點的概率,從而導致了資源整合。

圖4 3種算法平均工作節點數量對比
Fig.4 Comparison of average number of working nodes of three algorithms
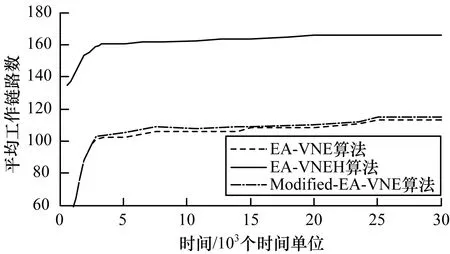
圖5 3種算法平均工作鏈路數量對比
Fig.5 Comparison of average number of working links of three algorithms
2)虛擬網絡請求能耗和映射時間
在物聯網環境下,3種算法所消耗的能耗如圖6所示。從圖6可以看出,Modified-EA-VNE算法的平均能耗約為20.5 kW,較EA-VNE、EA-VNEH分別降低36.90%和18.65%,其原因在于,EA-VNE僅通過最小化工作節點和鏈路實現節能,但是在節點異構的環境中,該方法并不能實現能耗最優化,而另外2種算法均適用于節點異構環境,但由于Modified-EA-VNE算法不僅采用能耗模型,將節點和鏈路映射至能耗最小的底層網絡中,又基于最接近剩余容量原則,使得底層網絡中工作的節點和鏈路數量盡可能少,從而使得能耗最小。3種算法虛擬網絡的映射時間如圖7所示,從圖7可以看出,EA-VNE算法的映射時間最短,約為50 ms,而Modified-EA-VNE所需的時間較長,約為78 ms,其原因在于,EA-VNE和EA-VNEH采用啟發式算法,該算法有效降低了映射所需的時間,而Modified-EA-VNE需考慮節點的異構性以及鏈路的時延特性,映射節點分布較不均勻,且映射節點之間的路徑相對復雜,此外,將VNR拆分為2種類型的子VNR,仿真中只開啟了2個線程,并行處理VNR所減少的映射時間遠小于在選取節點與路徑時所花費的時間。
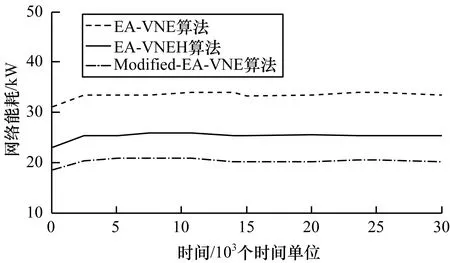
圖6 3種算法虛擬網絡請求平均能耗對比
Fig.6 Comparison of average energy consumption of virtual network request of three algorithms
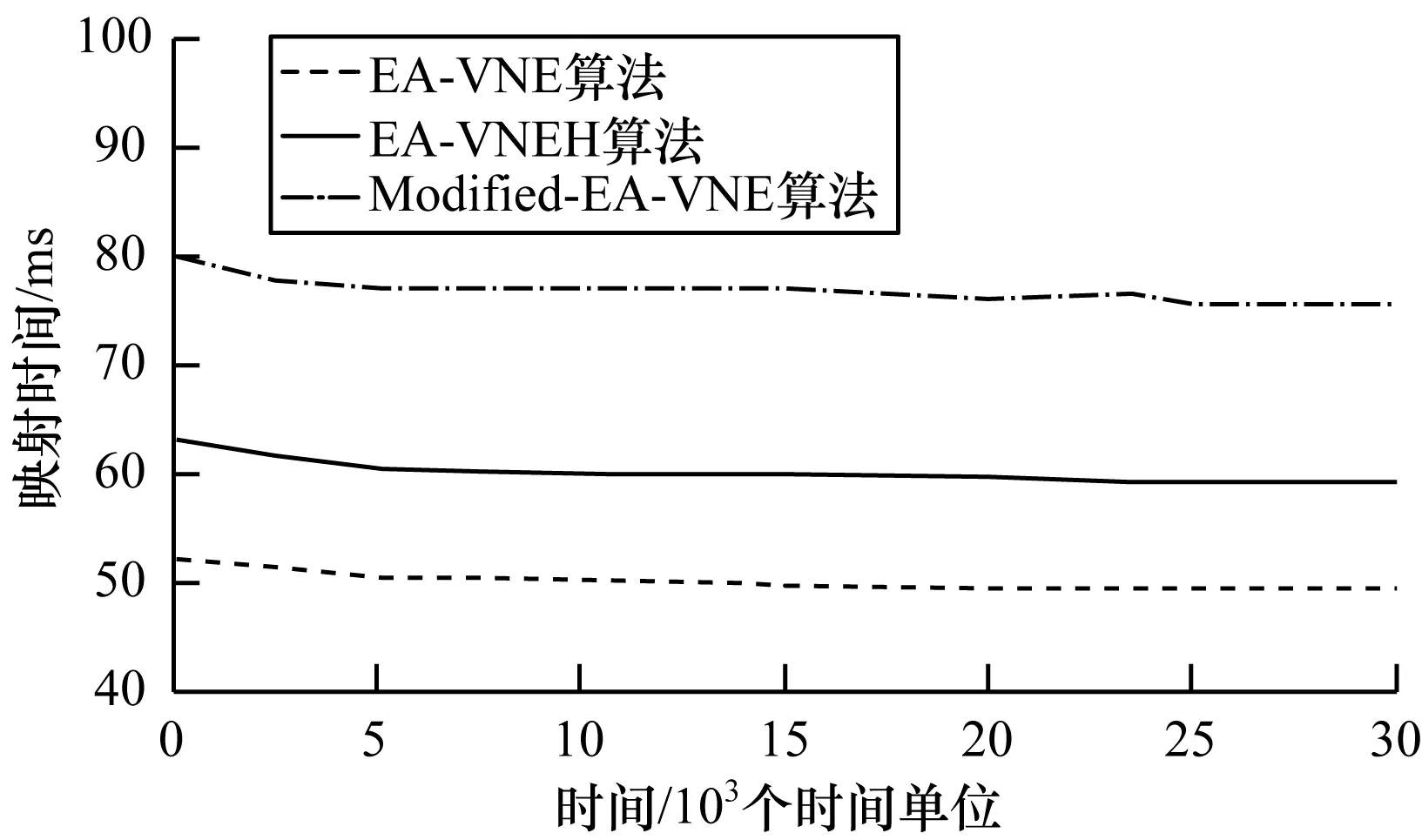
圖7 3種算法虛擬網絡映射時間對比
Fig.7 Comparison of virtual network mapping time of three algorithms
3)收益開銷比
3種算法的物理網絡收益開銷比對比情況如圖8所示。從圖8可以看出,當虛擬請求較少時,由于底層資源比較充足,收益開銷比較高,但隨著資源的逐漸消耗,收益開銷比也隨之下降,最終達到一個穩定的狀態。Modified-EA-VNE算法收益開銷比相對較高的原因在于,該算法在虛擬網絡映射之前根據不同服務類型將虛擬請求做拆分處理,分別對不同的虛擬請求分配資源,提高了虛擬網絡請求的接受率,但由于需將節點分配給同類型的節點,容易產生瓶頸效應,導致其收益開銷比趨于EA-VNEH算法,而EA-VNE算法僅考慮工作節點和鏈路,使得后續節點和鏈路過于擁塞,降低了虛擬網絡映射的成功率。

圖8 3種算法物理網絡收益開銷比對比
Fig.8 Comparison of benefit-expense ratio of physical network of three algorithms
4 結束語
為了解決物聯網環境下的能耗優化問題,同時滿足節點異構性與鏈路時效性的要求,本文設計一種能耗感知虛擬網絡映射算法Modified-EA-VNE。仿真結果表明,與EA-VNE和EA-VNEH算法相比,Modified-EA-VNE算法能夠有效減少虛擬網絡映射的能耗,增加底層網絡資源利用率,提高物理網絡收益,并更細粒度地完成虛擬請求映射。由于實際物聯網的網絡拓撲為動態拓撲,虛擬請求的到達和離開是動態且順序不可預測的,因此下一步將結合節點重映射與路徑分割技術來設計一種合理的調度算法。
猜你喜歡
江蘇安全生產(2023年1期)2023-02-08 05:58:38
井岡教育(2022年2期)2022-10-14 03:11:44
吉林廣播電視大學學報(2021年4期)2022-01-14 02:35:48
云南教育·中學教師(2020年9期)2020-11-16 00:27:58
作文成功之路·小學版(2020年5期)2020-06-11 12:48:26
中學生數理化·八年級物理人教版(2019年9期)2019-11-25 07:33:00
小天使·一年級語數英綜合(2018年11期)2018-11-23 09:47:26
中學生數理化·八年級物理人教版(2017年9期)2017-12-20 08:11:28
資源再生(2017年3期)2017-06-01 12:20:59
中學生數理化·中考版(2017年12期)2017-04-18 12:55:05
