基于對比注意力機制的跨語言句子摘要系統
2020-05-20 10:22:42殷明明史小靜俞鴻飛段湘煜
計算機工程 2020年5期
殷明明,史小靜,俞鴻飛,段湘煜
(蘇州大學 自然語言處理實驗室,江蘇 蘇州 215006)
0 概述
句子摘要是將源端句子中的主要思想進行抽取和概況,并以摘要短語的形式呈現。句子摘要系統通過快速瀏覽句子以獲取其中的主要信息,再對該信息進行重寫生成相對應的摘要短語。在已有研究中,多數學者主要是針對單語進行句子摘要[1-2],即源端句子和目標端摘要短語屬于同種語言,但基于單語的形式嚴重阻礙了人們快速獲取不同語言文本中所包含的主要信息。與基于單語的句子摘要任務不同,現實中跨語言的句子摘要缺少大量的平行語料以供使用,屬于零樣本學習問題。在大規模單語句子摘要系統的平行語料和神經機器翻譯系統的跨語言平行語料基礎上,可將兩個系統相結合以解決該零樣本學習問題。
由于單語的句子摘要系統存在大規模的平行語料,因此采用神經網絡構建序列到序列(seq2seq)的模型。在平行語料中,源端序列是長句子文本,目標端是與之對應的摘要短語。該系統利用編碼器將源端序列編碼成固定維度的向量空間,再通過解碼器解碼出具體的摘要短語。神經網絡的廣泛使用使得神經機器的翻譯性能有了顯著提升[3-4]。目前,主流的神經機器翻譯方法[5-6]主要包括基于循環神經網絡(Recurrent Neural Network,RNN)的神經機器翻譯方法[7-8]、基于卷積神經網絡(Convolution Neural Network,CNN)的神經機器翻譯方法[9]和基于完全注意力機制的神經機器翻譯方法(Transformer)[7],其中Transformer在各類數據集上的表現上相比于其他方法具有明顯優勢。
早期學者對于跨語言摘要任務的研究主要利用抽取和壓縮的方法。通過從原文檔中抽取關鍵的句子進行翻譯,再采用壓縮方法刪除翻譯譯文中最不相關的信息。單純抽取和壓縮得到的摘要短語不能安全包含源句中的主要含義。在近期研究中,文獻[8]提出利用神經網絡構建序列到序列的跨語言句子摘要系統,將單語平行語料中目標端的摘要短語通過神經機器翻譯系統翻譯成另外一種語言的摘要短語,與源端長句共同構建跨語言的偽平行語料對。在此基礎上借鑒神經機器翻譯中的“老師-學生”框架[6],將單語句子生成式摘要模型作為“老師”,跨語言句子生成式摘要模型作為“學生”。
本文借鑒回譯思想[10-11],將單語句子摘要平行語料中的源端通過神經機器翻譯系統翻譯成另外一種語言,與句子摘要平行語料中真實目標端的摘要短語構成跨語言的偽平行語料。另外,句子摘要將從源端長句中抽取出的主要信息以摘要短語的形式進行呈現,然而,源端和目標端句子長度存在較大差異。在序列到序列模型中傳統注意力機制主要是使目標端獲取與源端最相關的信息,但在句子摘要生成過程中,由于較短目標端摘要短語需從較長的源端獲取最相關的信息,因此源端和目標端句子長度的不匹配使得傳統注意力機制不再適用于此類情況。為解決該問題,本文提出對比注意力機制,通過該機制使目標端可從源端中獲取最不相關的信息。
1 相關工作
1.1 單語的句子摘要
針對單語的句子摘要問題,學者提出一些基于統計模型和神經網絡的方法。由于基于統計模型的方法需構建大規模單語句子摘要的平行語料,因此基于神經網絡的方法逐漸成為主流方式。文獻[12]采用帶有注意力機制的循環神經網絡構建序列到序列的句子摘要系統,學者們在此基礎上進行了深入研究,例如文獻[13]融入豐富的語言學信息以擴大詞典,文獻[14]增強了摘要主題,文獻[15]對編碼器添加選擇門機制。在文檔級別的摘要任務中,文獻[16]將原始文本轉化為相應的抽象語義表示圖,再通過語義字典過濾抽象語義表示圖中的冗余信息。文獻[17]提出融合Doc2Vec模型、K-means算法和TextRank算法的自動提取摘要系統。
1.2 跨語言的句子摘要
早期學者未對跨語言句子摘要進行較多研究,而是主要關注于跨語言文檔級別的摘要研究。文獻[18]對原文檔中句子進行打分,選擇最優句子進行翻譯形成摘要,并且基于抽取式摘要模型設計兩個圖,圖中包含雙語的信息。文獻[19]利用翻譯和解析信息引入雙語概念和特征,生成跨語言多文檔摘要。文獻[8]利用“老師-學生”框架完成跨語言句子摘要模型的訓練過程,而本文摒棄了復雜的“老師-學生”框架,通過對比注意力機制來彌補傳統注意力機制的不足,從而加強跨語言的句子摘要能力。
2 跨語言句子摘要系統
2.1 基準模型
在實驗中,本文選擇標準Transformer模型作為單語句子摘要模型和神經機器翻譯模型。Transformer與循環神經網絡及卷積神經網絡不同,其完全基于注意力機制實現。在該模型中包含編碼器-解碼器結構,編碼器將源端序列信息編碼成固定維度隱藏層向量,解碼器從源端隱藏層向量中解碼出具體的目標端序列,編碼器與解碼器之間通過注意力機制實現連接。
Transformer中主要采用縮放的點乘注意力機制,具體公式如下:
(1)
其中,Q、K、V分別為問題向量、關鍵字向量和值向量,dk為向量K的維度,激活函數softmax返回在向量V上的權重概率分布,函數Attention(Q,K,V)生成與當前時刻最相關的上下文信息。
在整個Transformer模型中,縮放的點乘注意力機制主要應用如下:
1)自注意力機制(Self-Attention),在編碼器端和解碼器端都采用自注意力機制。在編碼器端,向量Q是源端序列中當前位置的隱藏層向量,而向量K和向量V為整個源端序列中所有位置隱藏層向量組成的向量矩陣。與編碼器端不同,在解碼器端的序列是從左向右依次解碼,對于當前位置而言后面位置的信息不可見。因此,在解碼器端對于向量矩陣K和向量矩陣V當前位置往后的信息需要通過掩碼矩陣進行掩碼,而向量Q與編碼器端相同,為目標端序列當前位置的隱藏層向量。
2)編碼器-解碼器注意力機制(Encoder-Decoder Attention),與傳統序列到序列模型中的注意力機制類似,通過目標端當前位置的信息獲取源端序列中最相關的信息。向量Q為解碼器端當前位置的隱藏層向量,向量K和向量V為編碼器中源端序列中所有位置隱藏層向量組成的向量矩陣。
另外,在上述兩種注意力機制中都采用多頭的注意力機制。將向量Q、向量K和向量V切分成更小維度的向量,通過不同視角獲取多樣的注意力信息。切分的維度等于最初向量維度的1/h,其中h為切分的頭數目。具體地,將向量Q、向量K和向量V維度設置為512維,分為8個頭,即每個向量被分為8份,每一份為64維。在此基礎上將每一個頭的向量通過式(1)計算注意力信息,最終將各頭的注意力信息進行拼接再次映射成512維,具體公式如下:
MultiHead=Concat(head1,head2,…,headh)WO
(2)
(3)
2.2 管道方法
單語句子摘要系統是一個端到端的實現方式,即給定源端輸入后通過模型得到具體的摘要短語輸出,但是對于跨語言句子摘要任務而言不存在類似的端到端系統。因此,本文通過兩步方式實現跨語言句子摘要。首先預訓練一個單語摘要系統和一個翻譯系統,然后將兩個系統結合生成最終的跨語言摘要系統。具體實現過程有如下兩種方式:
1)先摘要-后翻譯,記作Pipeline-ST。給定具體語言的源端句子,先通過單語摘要系統生成同語言的摘要短語,再使用翻譯系統將生成的摘要短語翻譯成另一種語言的摘要短語。
2)先翻譯-后摘要,記作Pipeline-TS。與上述方法相反,先將具體語言的源端句子使用翻譯系統翻譯成另一種語言,再對該句子使用單語句子摘要系統生成最終的摘要短語。
2.3 回譯方法
由于大規模的單語句子摘要平行語料的存在,使得基于神經網絡的單語摘要系統得到廣泛應用,但是跨語言句子摘要不存在任何相關的平行語料,因此在實驗過程中本文借鑒機器翻譯中的回譯方法,通過此方法構建偽語料以供使用。
在機器翻譯領域,訓練模型需要使用大量的平行語料,通常構建平行語料需要花費巨大的人力物力,但是現實中存在大量的單語語料,因此可通過回譯方法將單語語料翻譯成與平行語料中源端相同語言的文本,構成具備真實目標端的偽平行語料,然后使用該偽語料對原有的平行語料進行數據擴充。
本文采用回譯思想,借用機器翻譯系統將單語句子摘要的平行語料中的源端翻譯成另一種語言,構成具有虛假源端和真實目標端的跨語言句子摘要的偽平行語料。與文獻[8]方法不同,本文將單語句子摘要平行語料中的目標端通過機器翻譯系統生成另一種語言文本,形成由真實源端和虛假目標端共同構成的跨語言句子摘要的偽平行語料。
本文實現了從中文句子到英文摘要短語的過程,使用預訓練的英文到中文的神經機器翻譯系統將英文單語句子摘要語料中的源端翻譯成中文文本,再與該數據中英文目標端構成跨語言句子摘要的偽平行語料,如圖1所示。其中,實線框表示真實數據,虛線框表示偽數據,實線雙箭頭表示真實平行語料,虛線雙箭頭表示偽平行語料,NMT表示使用機器翻譯模型進行翻譯。
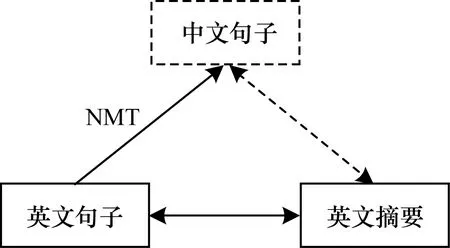
圖1 回譯過程
2.4 對比注意力機制
與機器翻譯不同,句子摘要任務中需保留源端序列中的主要信息,并過濾次要信息。文獻[15]在編碼器中添加選擇門機制,通過選擇門機制過濾源端序列中的次要信息。本文在Transformer基準系統上添加對比注意力機制來獲取源端序列中不重要的信息。
本文將序列到序列結構中的編碼器-解碼器注意力機制定義為傳統注意力機制,用來獲取源端序列中的主要信息。如圖2所示,標準Transformer結構包含編碼器、解碼器以及傳統編碼器-解碼器注意力機制,對比注意力機制包含注意力轉換(Attention Transfer)、反向注意力(Opponent Attention)和反向概率分布(Opponent Probability)。除此之外,Transformer模型結構中通常采用的是多層疊加結構,前一層的輸出作為下一層的輸入,其中Nx表示N層相同結構的疊加,但在反向注意力結構中只采用一層結構。本文將αc定義為傳統注意力機制的注意力權重,具體公式如下:
(4)
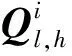
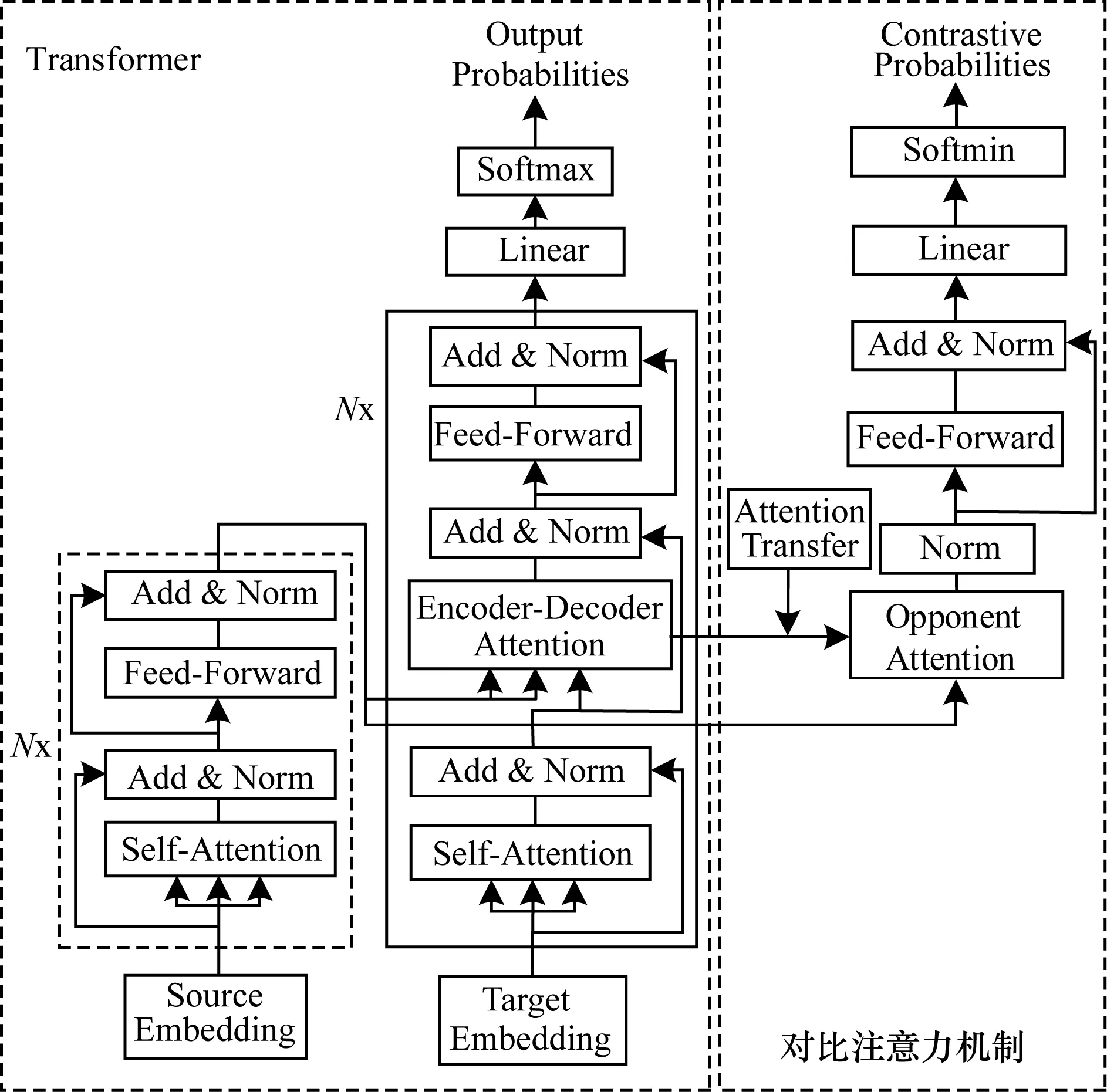
圖2 對比注意力機制的模型結構
將αo定義為對比注意力機制的注意力權重,對比注意力機制通過傳統注意力機制轉換而來,具體公式如下:
αo=softmax(α′c)
(5)
Attentiono(Q,K,V)=αoVL,h
(6)
其中,α′c是將傳統注意力權重αc中最大的權重值重新賦值為-inf,使其經過激活函數softmax后使αo對應的權重變為0。將傳統注意力機制轉換為對比注意力機制的主要目的是將傳統注意力機制中與源端最相關信息在對比注意力機制中變為最不相關信息。VL,h和KL,h是相同的向量矩陣,為編碼器端最后一層的第h個頭對應的源端所有位置的隱藏層向量組成的向量矩陣。在此方法中,傳統注意力機制獲取源端與目標端最相關的信息,而對比注意力機制則獲取目標端與源端序列中最不相關的信息。
具體地,在Transformer基準系統中主要包含6層相同的子結構,并且每一層包含8個頭的傳統注意力機制。本文通過分析跨語言摘要偽平行語料在基準系統上每一層每一個頭的傳統注意力對齊情況,發現第5層的第7個頭的傳統注意力對齊效果最佳。因此,在實驗過程中將第5層的第7個頭的傳統注意力機制轉換為對比注意力機制,即將所對應的注意力權重分布中最大的權重重新賦值為-inf。除此之外,Transformer基準系統是6層子結構,但是在對比注意力機制中僅有一層結構。
2.5 訓練與解碼
Transformer結構中除了注意力機制還需要經過層正則化(Layer Normalization)、殘差連接(Residual Connection)、前饋網絡(Feed Forward)和激活函數softmax,最終得到候選詞的概率分布。具體地,給定一對平行語料,其中,源端X={x1,x2,…,xn},目標端Y={y1,y2,…,ym}。在訓練過程中,通過激勵傳統注意力機制獲取源端最相關信息并生成目標端候選詞的最大化概率Pc(yi|y[1:(i-1)],X)。
在傳統注意力機制中,通過激活函數softmax激勵模型獲取源端序列中的最相關信息,但是在對比注意力機制中需懲罰最相關信息,從而獲得不相關信息。因此,在對比注意力機制中將傳統注意力機制中的激活函數softmax替換成softmin,具體公式如下:
z1=LayerNorm(Attentiono)
(7)
z2=FeedForward(z1)
(8)
z3=LayerNorm(z1+z2)
(9)
Po(yi|y[1:(i-1)],X)=softmin(Wz3)
(10)
其中,W是模型訓練參數。激活函數softmin和訓練目標分別如下:
(11)
L=loga(Pc(yi|y[1:(i-1)]))+
λloga(Po(yi|y[1:(i-1)]))
(12)
其中,λ為平衡因子。在解碼時,模型通過束搜索尋找最大化函數L。
3 實驗結果與分析
本文實現了一個中文句子到英文摘要短語的系統。訓練集主要使用單語句子摘要的平行語料和英中機器翻譯的平行語料。由于不存在跨語言句子摘要的測試集,將單語句子摘要的平行語料中的源端英文句子通過人工翻譯為中文句子,構成標準的{中文句子,英文摘要短語}測試集。
3.1 數據集
單語句子摘要的平行語料使用的是帶有注釋的Gigaword[20],對該數據的處理方式與文獻[12]一致,將每一篇文章的第一句作為源端句子與該篇文章的標題構成平行語料對。經處理后該數據集中共包含約380萬對的訓練集,8 000對驗證集和1 951對測試集。另外,也使用DUC-2004[21]作為測試集,該數據中包含500篇文檔,每一篇文檔對應4種人工生成的摘要。
本文還使用英文到中文的機器翻譯系統。訓練該系統使用的英中平行語料是從LDC中抽取的125萬句英中平行語句對,其中包括LDC2002E18、LDC2003E07、LDC2003E14、LDC2004T07、LDC2004T08和LDC2005T06中的議會議事錄部分。選擇NISTMT02、NISTMT03、NISTMT04、NISTMT05、NISTMT08作為測試集,NISTMT06作為驗證集。
在實驗過程中,從Gigaword數據的驗證集中隨機抽取2 000個句對,并將該句對中的源端使用人工翻譯成對應的中文作為跨語言句子摘要系統的驗證集。同時,將Gigaword數據集中的測試集和DUC-2004數據中的源端翻譯成對應中文,作為本文跨語言句子摘要任務的標準測試集。除此之外,為實驗公平起見,參照文獻[8]方法使用大規模的中文短文本摘要平行語料LCSTS[22],該語料主要從新浪微博上收集整理,其中,訓練集包含約240萬對平行語料,測試集包含725對平行語料。
3.2 實驗參數
本文英中翻譯系統和句子摘要系統中都使用Transformer作為基本結構,具體代碼實現基于Fairseq。該結構中編碼器和解碼器都設為6層,其中多頭注意力機制使用8個頭,詞向量及隱藏層維度都設置為512維,Adam優化器,初始學習率為0.000 5,β1=0.9,β2=0.99,ε=10-9,其他參數與文獻[7]相同。在單語句子摘要系統中,共享編碼器和解碼器中的詞向量。解碼時使用束搜索方法,束搜索寬度設置為12,最大句長設置為50。
在實驗過程中,采用BPE[23]技術處理語料中的低頻詞問題,BPE大小設置為32 000。在單語句子摘要任務中源端和目標端使用聯合BPE的方式。另外,對于人工翻譯得到的中文文本,首先使用分詞工具Jieba進行分詞,然后使用BPE進行處理。
3.3 評測標準
本文使用ROUGE[24]作為評測腳本。對于Gigaword測試集,測試其全長度的F值得分,其中包括ROUGE-1(R-1)、ROUGE-2(R-2)和ROUGE-L(R-L)。在DUC-2004測試集上,文獻[8]提出使用全長度的F值作為評測標準。因為召回率得分與生成序列的長度相關,所以為公平起見使用全長度的F值得分作為評測標準,本文也采用該評測方法。
3.4 實驗結果
3.4.1 超參數確定
在實驗過程中的主要超參數是式(12)中的平衡因子λ,其用于平衡傳統注意力機制和對比注意力機制,如果λ越大,則系統生成候選詞的概率分布越偏向于對比注意力機制。本文分別設置λ為0.2、0.4和0.6,根據其對應模型在驗證集上的具體表現選擇最終的λ。如表1所示,當λ取0.4時在驗證集上的ROUGE得分最高,因此本文系統中λ設定為0.4。
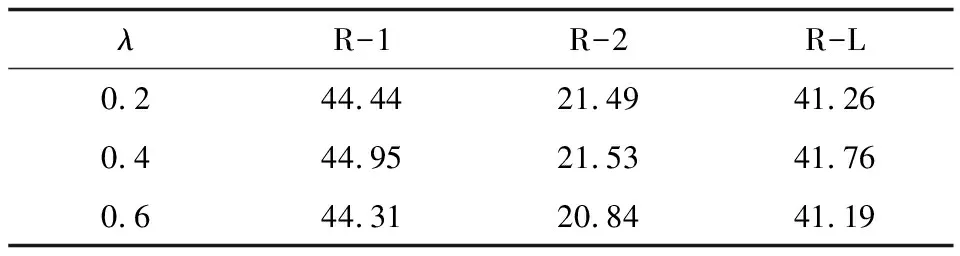
表1 不同平衡因子λ時的ROUGE得分
3.4.2 對比注意力機制中的K值確定
在對比注意力機制中,將傳統注意力的權重分布中最大的K個值重新賦值為-inf,使其在對比注意集中經過再次softmax后所對應的權重值變為0,即在傳統注意力權重中最相關的信息在對比注意力機制中變為次要信息。在此基礎上,分析對比注意力機制選取不同K值在驗證集上的ROUGE得分。如表2所示,當K值取1時對比注意力機制在驗證集上表現最優。因此,在本文實驗中將K值設置為1。

表2 不同K值時的ROUGE得分
3.4.3 單語句子摘要系統實驗結果
Transformer模型在神經機器翻譯領域取得顯著成效,但是其在摘要任務中尚未有深入的研究。本文使用Transformer作為句子摘要基準系統,實驗結果表明該系統在單語句子摘要測試集上性能表現較好。
如表3所示,ABS[12]和ABS+[12]使用注意力機制的循環神經網絡構建單語句子摘要;SEASS[15]通過在編碼端增加選擇門機制,對源端信息進行選擇性編碼;Actor-Critic[14]在序列到序列的模型基礎上引入增強學習方法;FactAware[25]利用開放式信息抽取和依存關系來描述源端文本中的信息。本文在Transformer結構的基礎上,對訓練集采用BPE預處理,定義為Transformer-BPE,其在Gigaword和DUC-2004測試集上均達到較高的水平,并且在跨語言句子摘要中采用相同的處理方法。
表3 單語句子摘要系統的ROUGE得分
Table 3 ROUGE scores of monolingual sentence summary systems
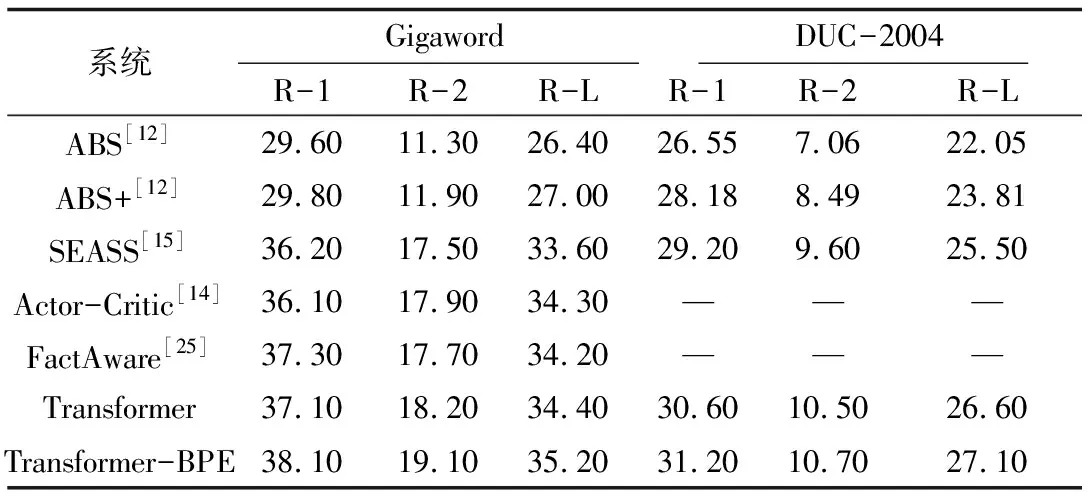
系統GigawordDUC-2004R-1R-2R-LR-1R-2R-LABS[12]29.6011.3026.4026.557.0622.05ABS+[12]29.8011.9027.0028.188.4923.81SEASS[15]36.2017.5033.6029.209.6025.50Actor-Critic[14]36.1017.9034.30———FactAware[25]37.3017.7034.20———Transformer37.1018.2034.4030.6010.5026.60Transformer-BPE38.1019.1035.2031.2010.7027.10
3.4.4 機器翻譯系統實驗結果
在Pseudo-Source方法中,本文將英文的源端通過機器翻譯系統生成對應的中文譯文,因此需提前訓練一個英中的翻譯系統。使用Transformer作為翻譯系統,訓練集是約125萬的LDC中英數據集,測試集分別使用NIST02、NIST03、NIST04、NIST05和NIST08,驗證集是NIST06并使用multi-bleu.perl作為評測腳本。
如表4所示,本文分別呈現了中英(Our Transformer Ch2En)和英中(Our Transformer En2Ch)兩個方向的翻譯得分。在中英翻譯系統中,每個NIST測試集包含4個人工生成的英文參考集。在英中翻譯系統中,將中英的測試集交換語向,同時每個NIST測試集分別測試4個參考集的得分,最后4個參考集的平均得分作為該NIST測試集的最終得分。將本文翻譯系統與Robust Translation[26]系統做對比,該系統是中英翻譯系統,采用與本文相同的訓練集及模型結構,在NIST02測試集上,本文Our Transformer Ch2En系統的得分低于該系統,但在平均得分上本文系統更具優勢。
表4 中英和英中翻譯系統在NIST測試集上的BLEU得分
Table 4 BLEU scores of Chinese-English and English-Chinese translation system on the NIST testing set
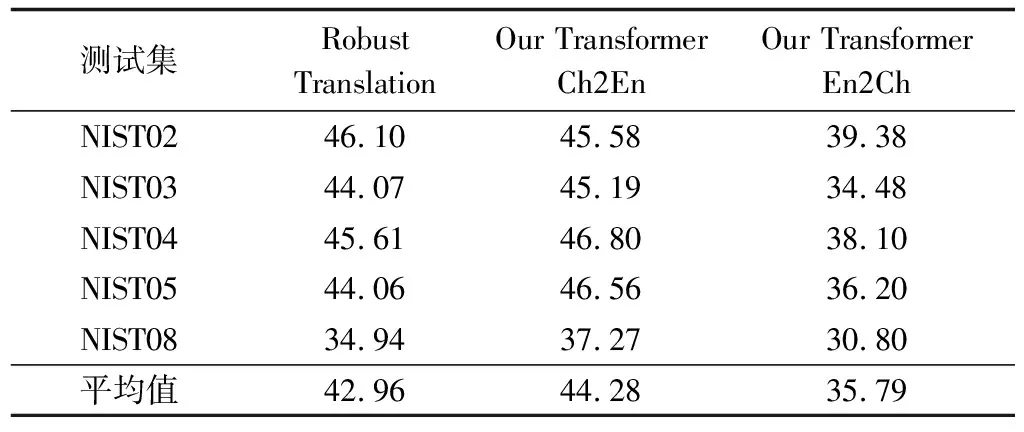
測試集RobustTranslationOurTransformerCh2EnOurTransformerEn2ChNIST0246.1045.5839.38NIST0344.0745.1934.48NIST0445.6146.8038.10NIST0544.0646.5636.20NIST0834.9437.2730.80平均值42.9644.2835.79
3.4.5 跨語言句子摘要系統實驗結果
跨語言句子摘要系統得分如表5所示,其中前兩個系統基于管道方法,其作為跨語言句子摘要的基準系統。Pseudo-Target[8]實現了英文句子到中文摘要的過程,使用的摘要系統是基于LSTM的模型結構,未使用BPE技術處理低頻詞。為實驗公平起見,在Transformer-BPE的基礎上進行Pseudo-Target從中文句子到英文摘要的實現。Pseudo-Target實驗結果差于管道方法,主要原因為:1)Pseudo-Target中構建了目標端的偽語料,使模型訓練過程中不能得到真實生成詞的概率分布P(yi|y[1:(i-1)],X);2)在重現過程中,使用中文摘要語料LCSTS,該語料與Gigaword和DUC-2004具有一定的差異性。
表5 跨語言句子摘要系統的ROUGE得分
Table 5 ROUGE scores of cross-lingual sentence summary systems
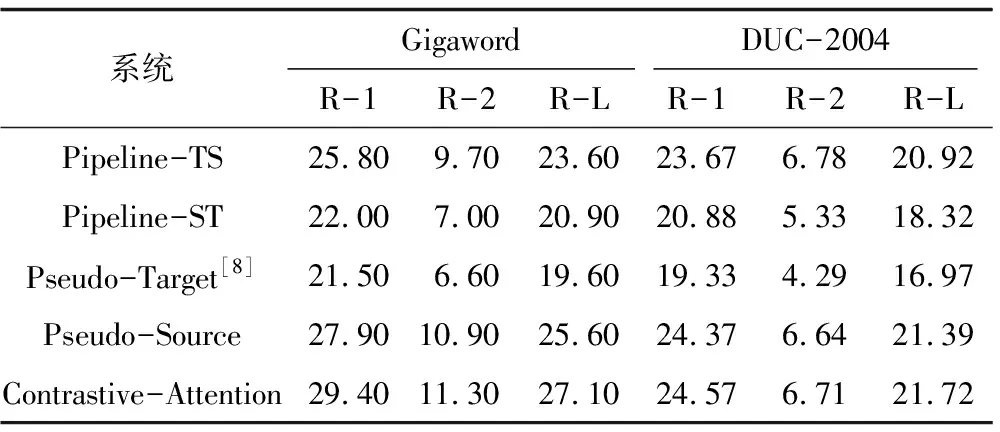
系統GigawordDUC-2004R-1R-2R-LR-1R-2R-LPipeline-TS25.809.7023.6023.676.7820.92Pipeline-ST22.007.0020.9020.885.3318.32Pseudo-Target[8]21.506.6019.6019.334.2916.97Pseudo-Source27.9010.9025.6024.376.6421.39Contrastive-Attention29.4011.3027.1024.576.7121.72
本文提出的基于序列到序列的跨語言句子摘要系統的具體實驗結果如表5中最后兩行所示。Pseudo-Source通過回譯將Gigaword語料中源端通過機器翻譯系統生成對應的中文文本,與該語料中目標端構成了跨語言句子摘要的偽平行語料,用于訓練序列到序列模型。該方法的BLEU得分相對于兩種基準系統有顯著的提升,基準系統主要是通過翻譯系統和摘要系統得到最終結果,兩種系統之間存在一定的差異性,從而導致摘要水平明顯低于序列到序列模型。
在Contrastive-Attention方法中,目標端通過傳統注意力機制獲取源端與之最相關的信息,同時通過對比注意力機制獲取源端最不相關的信息,聯合兩者進行訓練。實驗結果表明,Contrastive-Attention相對于Pseudo-Source有極大的性能提升,達到基于單語句子摘要的平行語料[12]效果。
4 跨語言句子摘要實例
下文列舉了不同句子摘要系統生成的跨語言句子摘要實例如例1、例2所示,將本文跨語言系統生成的例句優于基于管道方法的單語句子摘要系統的結果部分進行加粗。通過例句可以看出本文系統生成的摘要短語明顯優于基于管道方法的單語句子摘要系統,并且短語更加流暢,更加符合人類語言的表述方式。
例1
Ch-Sentence:意大利 左翼 反對派 在 # 月 選舉 失敗 后 , 希望 利用 反對 削減 教育 開支 的 抗議 活動 ,重新 獲得 反對 總理 西爾 維奧 - 貝盧斯科尼 政府 的 主動權 。
En-Sentence:italy’s leftwing opposition,bruised by its election defeat in april,is hoping to take advantage of protests against education spending cuts to regain the initiative against the government of prime minister silvioberlusconi.
Reference:italian opposition seeks to UNK on education protests.
Pipline-TS:italy’s left party hopes to gain initiative of government.
Pipline-ST:italian left - wing opposition hopes to regain the government ’s initiative.
Pseudo-Target:italian left wing calls foroppositiontobudgetcuts.
Pseudo-Source:italy’s left seeks to rally opposition to education cuts.
Contrastive-Attention:italianoppositiontoprotestseducationcuts.
例2
Ch-Sentence:周一 早間 交易 中 , 蘭特 對 美元 的 匯率 略有 走軟 , 開盤 于 #.#### / ## 對 美元 的 比價 是 ####年 ## 月 ## 日 收盤 時 的 #.#### / ##% 。
En-Sentence:the rand was slightly weaker against the dollar in early trade here monday,opening at #.#### / ## to the greenback compared to its close friday of #.#### / ##.
Reference:rand slightly weaker against dollar in early trade.
Pipline-TS:foreign exchange rates in malaysia.
Pipline-ST:randt’s exchange rate against us dollar slightly soft.
Pseudo-Target:foreign exchange rates in hongkong.
Pseudo-Source:yuanweakensagainstdollarinearlytrading.
Contrastive-Attention:randweakeragainstdollarinearlytrading.
5 結束語
本文設計一種序列到序列的跨語言句子摘要系統,通過回譯方法構建偽平行語料,解決跨語言句子摘要缺少平行語料的問題,并引入對比的注意力機制捕獲源端與目標端中的不相關信息。實驗結果表明,該系統相比基于管道方法的單語句子摘要系統整體性能有了較大提升。后續將通過無監督學習的方式構建序列到序列的句子摘要模型,進一步提高跨語言的句子摘要質量。
猜你喜歡
工業設計(2022年8期)2022-09-09 07:43:20
軍民兩用技術與產品(2021年10期)2021-03-16 06:05:30
北京測繪(2020年12期)2020-12-29 01:33:58
文苑(2020年4期)2020-05-30 12:35:30
文苑(2018年21期)2018-11-09 01:23:06
小學生作文(中高年級適用)(2018年3期)2018-04-18 01:24:47
家庭影院技術(2017年9期)2017-09-26 03:41:45
華北電力大學學報(社會科學版)(2016年4期)2016-12-01 03:59:30
中國衛生(2015年9期)2015-11-10 03:11:12
少兒科學周刊·少年版(2015年4期)2015-07-07 21:11:17
