一種分類(lèi)型矩陣數(shù)據(jù)的初始聚類(lèi)中心選擇算法
2020-05-20 10:22:48曹付元余麗琴
計(jì)算機(jī)工程 2020年5期
關(guān)鍵詞:定義
田 璐,曹付元,余麗琴
(1.山西大學(xué) 計(jì)算機(jī)與信息技術(shù)學(xué)院,太原 030006; 2.計(jì)算智能與中文信息處理教育部重點(diǎn)實(shí)驗(yàn)室,太原 030006)
0 概述
在數(shù)據(jù)挖掘中,多數(shù)算法的輸入是由n個(gè)對(duì)象組成的一個(gè)集合,每一個(gè)對(duì)象對(duì)應(yīng)一條記錄且被多個(gè)屬性所描述[1]。然而在實(shí)際應(yīng)用中,一個(gè)對(duì)象的描述常常不止一條記錄,通常由多條記錄描述的對(duì)象稱(chēng)為矩陣型對(duì)象,由矩陣型對(duì)象構(gòu)成的數(shù)據(jù)集稱(chēng)為矩陣數(shù)據(jù)集,即由包含多條記錄的對(duì)象組成的數(shù)據(jù)集。例如,在超市購(gòu)物時(shí),每個(gè)用戶購(gòu)買(mǎi)的商品不僅種類(lèi)不同,而且在購(gòu)買(mǎi)同一種商品時(shí),購(gòu)買(mǎi)的商品數(shù)量和頻率也不相同。通常,可以根據(jù)人們購(gòu)買(mǎi)一個(gè)商品的數(shù)量和頻率來(lái)預(yù)測(cè)該用戶是否喜歡這個(gè)商品。因此,矩陣數(shù)據(jù)蘊(yùn)含了豐富的用戶行為特性,對(duì)于行為分析具有重要的價(jià)值[2]。
在實(shí)際生活中,矩陣數(shù)據(jù)廣泛存在于通信、超市、銀行、保險(xiǎn)以及各大電子商務(wù)應(yīng)用領(lǐng)域。為了給用戶提供更好的服務(wù),需要挖掘這種數(shù)據(jù)中潛在的有用信息并加以利用。然而,在實(shí)際應(yīng)用中大部分矩陣型數(shù)據(jù)沒(méi)有標(biāo)記,如果給全部數(shù)據(jù)進(jìn)行標(biāo)記,需要耗費(fèi)大量的人力物力,代價(jià)昂貴。通過(guò)無(wú)監(jiān)督學(xué)習(xí)來(lái)對(duì)這類(lèi)型數(shù)據(jù)進(jìn)行分析是一種最直觀的方法,其中聚類(lèi)是無(wú)監(jiān)督學(xué)習(xí)中一種最廣泛的應(yīng)用。文獻(xiàn)[3]提出了k-mw-modes聚類(lèi)算法來(lái)處理分類(lèi)型矩陣數(shù)據(jù),該算法定義了一個(gè)新的相似性度量公式來(lái)計(jì)算兩個(gè)分類(lèi)型矩陣對(duì)象之間的距離,并且給出了一種新的啟發(fā)式方法去選擇類(lèi)中心。但是該算法是在隨機(jī)選取初始類(lèi)中心之后,通過(guò)不斷地迭代更新聚類(lèi)中心實(shí)現(xiàn)數(shù)據(jù)的劃分,容易受到不同初始類(lèi)中心對(duì)聚類(lèi)結(jié)果的影響。為了找到一個(gè)更好的解決方案,該類(lèi)型算法需要多次使用不同的初始類(lèi)中心來(lái)重新運(yùn)行。此外,隨機(jī)初始化類(lèi)中心的方法只有在類(lèi)的個(gè)數(shù)較少且至少有一個(gè)隨機(jī)初始化結(jié)果接近于一個(gè)好的解決方案時(shí)才有效。因此,初始類(lèi)中心的選擇對(duì)劃分聚類(lèi)算法是非常重要的,有必要發(fā)展一種面向分類(lèi)型矩陣數(shù)據(jù)的初始類(lèi)中心選擇算法以獲得更好的聚類(lèi)效果。
針對(duì)分類(lèi)型矩陣數(shù)據(jù),本文根據(jù)屬性值的頻率定義了矩陣對(duì)象的密度和矩陣對(duì)象間的距離,擴(kuò)展了最大最小距離算法,在此基礎(chǔ)上,提出一種面向分類(lèi)型矩陣數(shù)據(jù)的初始類(lèi)中心選擇算法(An Initial Cluster Center Selection Algorithm for Categorical Matrix Data,IC2SACMD)。
1 相關(guān)工作
聚類(lèi)是數(shù)據(jù)挖掘中一個(gè)非常重要的研究方向,也是無(wú)監(jiān)督學(xué)習(xí)中使用最廣泛的一種方法[4]。聚類(lèi)算法是基于數(shù)據(jù)的內(nèi)部結(jié)構(gòu)來(lái)尋找觀察樣本的自然集群。在實(shí)際應(yīng)用中,聚類(lèi)算法也是一種尋找不同用戶群最普遍的方法,使用案例主要包括細(xì)分客戶、新聞聚類(lèi)、異常點(diǎn)檢測(cè)[5]和網(wǎng)絡(luò)識(shí)別等。在k-type聚類(lèi)算法中,初始類(lèi)中心的選擇至關(guān)重要。根據(jù)數(shù)據(jù)類(lèi)型的不同,初始類(lèi)中心的選擇算法可分為數(shù)值型數(shù)據(jù)和分類(lèi)型數(shù)據(jù)初始類(lèi)中心選擇算法。針對(duì)數(shù)值型數(shù)據(jù),研究人員提出幾種解決初始化類(lèi)中心問(wèn)題的方法[6-8]。相應(yīng)地,針對(duì)分類(lèi)型數(shù)據(jù),研究人員提出了多種解決初始類(lèi)中心的方法[9-11]。最常見(jiàn)的方法是從數(shù)據(jù)集中選擇前k個(gè)不同的對(duì)象作為初始類(lèi)中心。為了避免隨機(jī)選擇初始類(lèi)中心對(duì)聚類(lèi)結(jié)果的影響,文獻(xiàn)[9]將由每個(gè)屬性下頻率最高的屬性值組成的向量作為初始類(lèi)中心。雖然文獻(xiàn)[9]提出的方法使初始中心多樣化,但是對(duì)于初始k個(gè)中心的選擇還沒(méi)有給出統(tǒng)一的準(zhǔn)則。文獻(xiàn)[10]提出一種基于密度和距離的方法,通過(guò)計(jì)算對(duì)象自身的密度及對(duì)象間的距離來(lái)選取初始類(lèi)中心。雖然該方法一定程度上避免了離群點(diǎn)、初始類(lèi)中心過(guò)于密集的問(wèn)題,但是在計(jì)算密度的過(guò)程中沒(méi)有考慮到不同屬性之間的差異、數(shù)據(jù)對(duì)象作為聚類(lèi)中心的準(zhǔn)確性以及第一個(gè)類(lèi)中心的選取可能為全部數(shù)據(jù)集正中間的一個(gè)數(shù)據(jù)對(duì)象。文獻(xiàn)[11]提出了一種新的初始化類(lèi)中心的方法,雖然考慮到數(shù)據(jù)對(duì)象作為類(lèi)中心聚類(lèi)的不精準(zhǔn)性,并且避免了第一個(gè)類(lèi)中心可能位于全部數(shù)據(jù)集正中間的一個(gè)密度最大值點(diǎn)的情況,但是在計(jì)算密度過(guò)程中,采用對(duì)象間的平均距離作為相似度,該算法也沒(méi)有考慮到不同屬性間的差異性。以上初始類(lèi)中心算法都應(yīng)用于每個(gè)對(duì)象僅由一個(gè)特征向量描述的數(shù)據(jù)集,目前筆者尚未發(fā)現(xiàn)針對(duì)分類(lèi)型矩陣數(shù)據(jù)在選擇初始類(lèi)中心方面的相關(guān)工作。
2 k-mw-modes算法
k-mw-modes算法是面向分類(lèi)型矩陣數(shù)據(jù)的k-type聚類(lèi)算法,主要由3個(gè)部分組成:1)聚類(lèi)中心的表示;2)將對(duì)象分配到聚類(lèi)中;3)更新聚類(lèi)中心。該算法定義了兩個(gè)矩陣對(duì)象之間的距離公式,給出一種更新類(lèi)中心的方法。
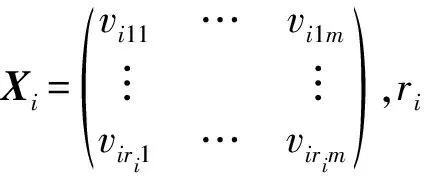
2.1 矩陣對(duì)象間的距離
給定兩個(gè)矩陣對(duì)象Xi和Xj,每個(gè)對(duì)象由m個(gè)分類(lèi)型屬性{A1,A2,…,Am}來(lái)描述,則Xi和Xj的距離公式定義為:
(1)
其中:
(2)
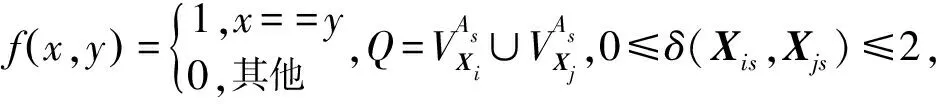
2.2 多加權(quán)模式聚類(lèi)中心
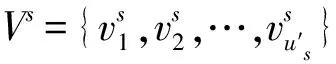
(3)
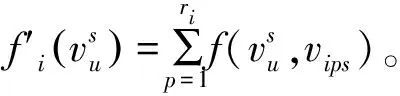
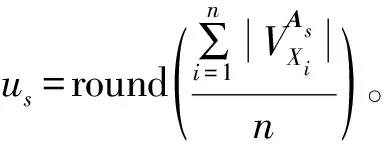
k-mw-modes算法對(duì)分類(lèi)型矩陣數(shù)據(jù)進(jìn)行了聚類(lèi),但是該算法隨機(jī)選取初始類(lèi)中心,沒(méi)有考慮到隨機(jī)初始類(lèi)中心的不穩(wěn)定性以及必須至少存在一種較優(yōu)的初始類(lèi)中心選擇才會(huì)得到有效的聚類(lèi)結(jié)果。
3 初始類(lèi)中心選擇算法
目前許多專(zhuān)家學(xué)者提出了多種方法來(lái)度量數(shù)據(jù)對(duì)象間的內(nèi)聚性[10-12]。最常見(jiàn)的一種方法是使用數(shù)據(jù)對(duì)象與全部數(shù)據(jù)對(duì)象之間的平均距離來(lái)測(cè)量數(shù)據(jù)對(duì)象的密度[12],因?yàn)槠浜?jiǎn)單且沒(méi)有參數(shù)。而對(duì)于矩陣數(shù)據(jù)集,對(duì)象Xi對(duì)應(yīng)ri條記錄,并且每個(gè)對(duì)象在每條屬性上有多個(gè)屬性值,即vips表示對(duì)象Xi在As屬性上的第p個(gè)屬性值,則需要考慮到同一屬性上不同記錄之間的差異性。因此,本文根據(jù)屬性值的頻率來(lái)定義對(duì)象的平均密度。
3.1 基本定義
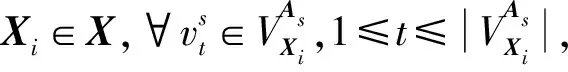
(4)
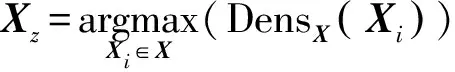
為便于理解,下文給出一個(gè)計(jì)算矩陣對(duì)象的平均密度示例,如表1所示。

表1 矩陣對(duì)象的平均密度
根據(jù)式(3)計(jì)算出在每個(gè)屬性上各個(gè)記錄值的權(quán)重。
在A1屬性上:

在A2屬性上:
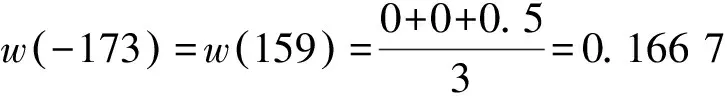
在A3屬性上:
根據(jù)式(4)計(jì)算每個(gè)對(duì)象的平均密度如下:
DensX(X1)=w(42)+w(-198)+w(-191)+
w(-109)+w(-142)+
w(-110)=2.333 3
DensX(X2)=w(42)+w(-198)+w(-191)+
w(-190)+w(-199)+
w(-142)+w(-102)=2.000 0
DensX(X3)=w(40)+w(42)+w(-191)+
w(-173)+w(-159)+
w(-142)+w(-63)=1.333 5
可得出對(duì)象X1的平均密度最大。
定義2給定數(shù)據(jù)對(duì)象Xi∈X(Xi≠Xz),Xi作為類(lèi)中心的代表能力定義為:
Pro_Repre(Xi)=DensX(Xi)×d(Xi,Xz)
(5)
圖1中的數(shù)據(jù)集被分為兩類(lèi),Xz為密度最大值對(duì)象,其處于兩個(gè)類(lèi)的邊界處,所以不能很好地代表一個(gè)類(lèi),則需尋找一個(gè)自身密度大的對(duì)象,且與Xz距離最遠(yuǎn),如圖1中E1,相對(duì)于一個(gè)虛擬類(lèi)中心C1,E1并不能充分地表示類(lèi)簇,因此不將E1作為初始類(lèi)中心,而應(yīng)該在E1周?chē)x擇一個(gè)合適的虛點(diǎn)C1作為初始類(lèi)中心。
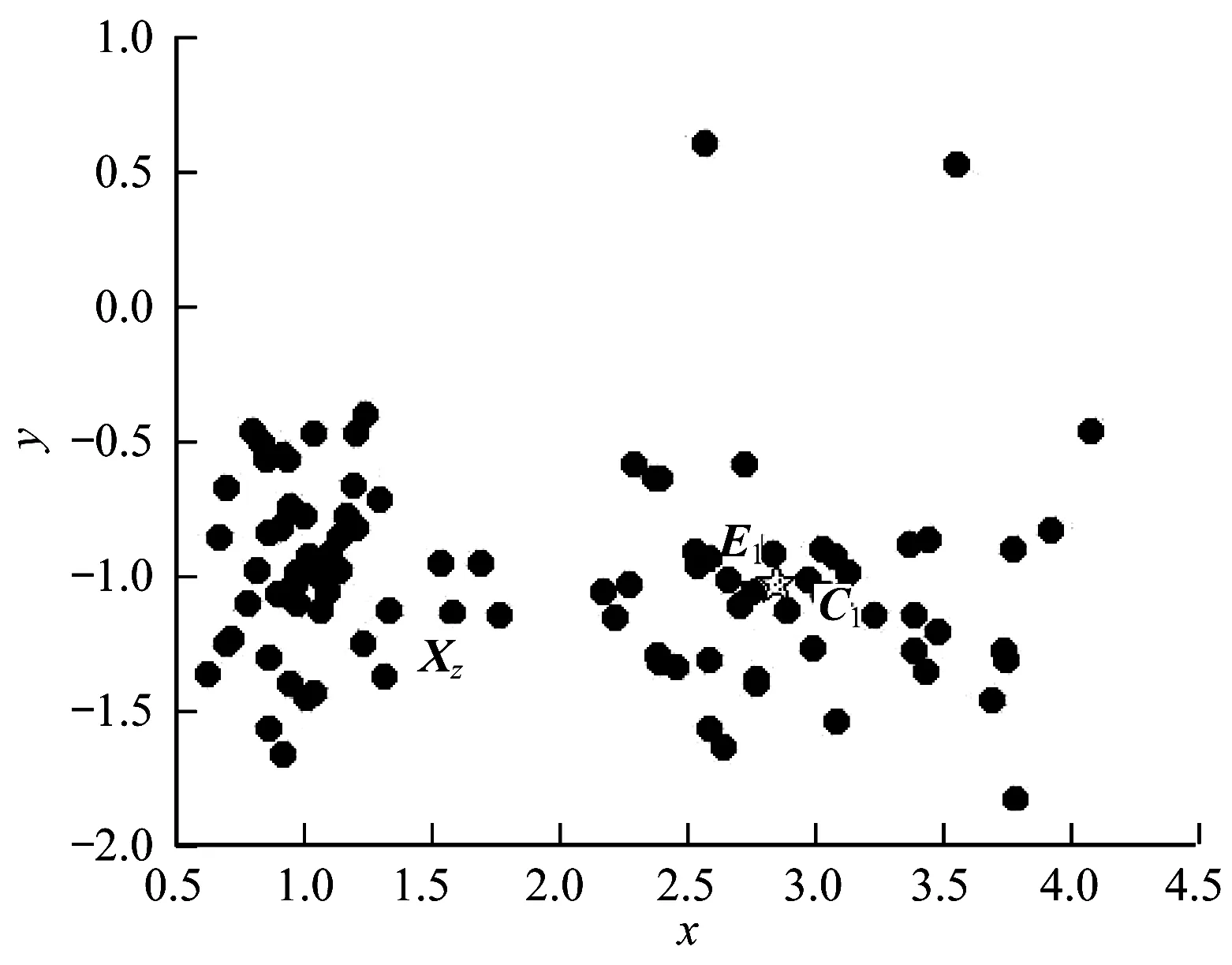
圖1 E1作為類(lèi)中心差的情況
本文基于所選的類(lèi)中心代表能力最強(qiáng)的點(diǎn)E1來(lái)構(gòu)造多個(gè)候選對(duì)象集合,通過(guò)每個(gè)集合可以得到一個(gè)虛點(diǎn)作為候選類(lèi)中心。下面給出候選對(duì)象集合的定義和求取候選類(lèi)中心的定義。
定義3設(shè)Ca_Sets(1≤s≤m)是第s個(gè)候選對(duì)象集合,被定義為:
Ca_Sets={Xi∈X|d(Xi,E1)≤s}
(6)
根據(jù)式(3),可以計(jì)算出Ca_Sets的類(lèi)中心cas。令Ca_Cluster1={ca1,ca2,…,cam}。
對(duì)于任意的兩個(gè)矩陣對(duì)象Xi和Xj,滿足0≤δ(Xis,Xjs)≤1,且0≤d(Xi,Xj)≤m。因此,可以根據(jù)對(duì)象與E1的距離得到m個(gè)候選對(duì)象集合,第s個(gè)集合Ca_Sets是由與E1的距離小于等于s的對(duì)象構(gòu)成的。隨著屬性s的增加,Ca_Sets集合中的對(duì)象數(shù)也會(huì)逐漸增加。也就是說(shuō),cas+1會(huì)比cas包含更多的對(duì)象信息。因?yàn)楫?dāng)s=m時(shí),Ca_Sets=X,此時(shí)cas是全部數(shù)據(jù)對(duì)象聚類(lèi)得到的一個(gè)候選類(lèi)中心。可見(jiàn)Ca_Sets包含過(guò)多的對(duì)象會(huì)削弱cas對(duì)第一個(gè)類(lèi)的代表性。可見(jiàn)對(duì)于s的取值,并不是越大越好。
采用Microsoft Excel 2016軟件對(duì)實(shí)驗(yàn)數(shù)據(jù)進(jìn)行分析及制圖,并采用SPSS18.0和Design-Expert 8.0.5對(duì)數(shù)據(jù)進(jìn)行統(tǒng)計(jì)分析,顯著水平p<0.05。
若只考慮DensX(cas)最大,則只能說(shuō)明cas周?chē)従訉?duì)象數(shù)最多,但不能保證cas與E1距離最近以及不能避免cas是邊界點(diǎn),因此還需要考慮到d(cas,E1),并且保證cas與密度最大值對(duì)象Xz距離最遠(yuǎn)。
定義4令Xz(Xz∈X)為密度最大值對(duì)象,E1∈X(E1≠Xz)為第一個(gè)類(lèi)中心代表能力最強(qiáng)的點(diǎn),cas(cas∈Ca_Cluster1)為第一個(gè)類(lèi)的第s個(gè)候選類(lèi)中心,則cas作為類(lèi)中心的能力為:
Pro_Center(cas)=DensX(cas)+d(cas,Xz)-d(cas,E1)
(7)
令C1=argmaxcas∈Ca_Cluster1Pro_Center(cas),則C1為第一個(gè)類(lèi)中心,即在候選類(lèi)中心集合中選擇一個(gè)離密度最大的對(duì)象Xz最遠(yuǎn)、自身密度最高,且更接近于E1的候選類(lèi)中心作為新的類(lèi)中心。因?yàn)樗x擇對(duì)象的密度越大意味著其周?chē)従訉?duì)象數(shù)越多,此外離密度最大值點(diǎn)越遠(yuǎn)意味著其成為每個(gè)類(lèi)邊界點(diǎn)的可能性越小,并且需更加接近于類(lèi)中心代表能力最強(qiáng)的點(diǎn)。圖2為第一個(gè)類(lèi)中心生成過(guò)程。
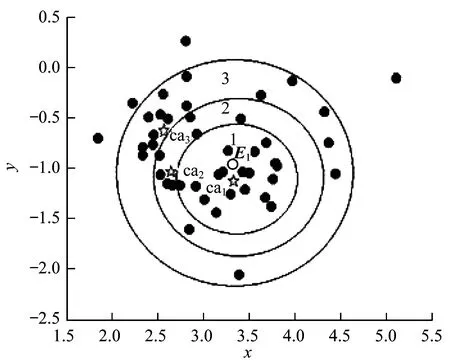
圖2 第一個(gè)類(lèi)中心的生成過(guò)程
從圖2可以看出,空心點(diǎn)表示生成的第一個(gè)類(lèi)中心代表點(diǎn)E1。根據(jù)式(6)生成多個(gè)候選集合Ca_Sets,其中圈1中的對(duì)象表示集合Ca_Set1中包含的對(duì)象,同理,圈2和圈3分別表示Ca_Set2和Ca_Set3中包含的對(duì)象,且Ca_Set3?Ca_Set2?Ca_Set1。圖2中的五角星是生成的3個(gè)候選類(lèi)中心{ca1,ca2,ca3}。根據(jù)定義4得出第一個(gè)新的類(lèi)中心為ca1,記為C1。
定義5給定Xi∈X,k′∈{2,3,…,K},則第k′個(gè)類(lèi)中心代表能力定義為:
(8)
其中,Ck表示第k個(gè)類(lèi)中心。取Pro_Repre(Xi)的最大值所對(duì)應(yīng)的對(duì)象作為第k′個(gè)類(lèi)中心代表能力最強(qiáng)點(diǎn),即:
Ek′=argmaxXi∈X,Xi?{E1,E2,…,Ek′-1}Pro_Repre(Xi)
則cas(cas∈Ca_Clusterk′)作為第k′個(gè)類(lèi)中心的能力為:
Pro_Center(cas)=DensX(cas)+
(9)
其中,Ck′=argmaxcas∈Ca_Clusterk′Pro_Center(cas)為第k′個(gè)類(lèi)中心。對(duì)于其他類(lèi)中心的選擇,本文考慮到對(duì)象與所選出的類(lèi)中心之間的距離,距離越大說(shuō)明該對(duì)象與選出的其他類(lèi)中心差異越大,能很好地代表一個(gè)類(lèi)中心,同時(shí)采用最大最小距離算法用于計(jì)算其他類(lèi)中心。
3.2 算法流程
算法實(shí)現(xiàn)流程如下:
算法1IC2SACMD 算法
輸入X:由m個(gè)屬性描述的n個(gè)對(duì)象矩陣數(shù)據(jù)集;K:聚類(lèi)個(gè)數(shù)
輸出數(shù)據(jù)集X的K個(gè)初始類(lèi)中心C={C1,C2,…,CK}
1.初始化:C = φ;
2.fork′=1to K,do
3.if(k’==1)
4.根據(jù)式(3)和式(4)計(jì)算數(shù)據(jù)集X所有對(duì)象的平均密度,找出密度最大值的對(duì)象記為Xz;
5.對(duì)于除Xz之外的其他對(duì)象,根據(jù)式(5)計(jì)算每個(gè)對(duì)象的代表能力Pro_Repre(Xi)=d(Xz,Xi)×DensX(Xi);
6.獲得第一個(gè)類(lèi)中心代表能力最強(qiáng)的點(diǎn)E1=argmaxXi∈X,Xi≠XzPro_Repre(Xi);
7.根據(jù)式(6)得出候選對(duì)象集合Ca_Sets(1≤s≤m);
8.通過(guò)候選對(duì)象集合得到候選類(lèi)中心集合Ca_Cluster1;
9.對(duì)于集合Ca_Cluster1中的每個(gè)候選類(lèi)中心,根據(jù)式(7)計(jì)算Pro_Center(cas)=DensX(Cas)+d(Cas,Xz)-d(Cas,E1);
10.獲得第一個(gè)類(lèi)中心C1=argmaxcas∈Ca_Cluster1Pro_Center(cas);
11.else
12.for i=1to n,do
13.根據(jù)式(8)求得Xi作為第k′個(gè)類(lèi)中心的代表能力Pro_Repre(Xi);
14.end for
15.獲得第k′個(gè)類(lèi)中心代表能力最強(qiáng)的點(diǎn)Ek′=argmaxXi∈X,Xi?{E1,E2,…,Ek′-1}Pro_Repre(Xi);
16.for k=1to(k′-1),do
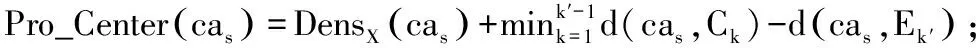
18.endfor
19.獲得第k′個(gè)類(lèi)中心Ck′=argmaxcas∈Ca_Clusterk′Pro_Center(cas);
20.end if
21.C=C∪Ck′;
22.end for
23.return C.
4 實(shí)驗(yàn)結(jié)果與分析
為驗(yàn)證本文算法的有效性,在7個(gè)不同的真實(shí)數(shù)據(jù)集上進(jìn)行實(shí)驗(yàn)。對(duì)數(shù)據(jù)集進(jìn)行簡(jiǎn)單介紹,給出實(shí)驗(yàn)所需評(píng)價(jià)指標(biāo),將算法與其他方法進(jìn)行比較,并對(duì)實(shí)驗(yàn)結(jié)果進(jìn)行分析。
4.1 實(shí)驗(yàn)數(shù)據(jù)
本文實(shí)驗(yàn)使用了7個(gè)真實(shí)的數(shù)據(jù)集,其中musk[13]數(shù)據(jù)集是從UCI上下載,其余數(shù)據(jù)集是由Veronika Cheplygina整理[14]存放在(http://www.miproblems.org)網(wǎng)站上。mutagenesis[15]和musk是由藥物活性預(yù)測(cè)問(wèn)題引起的,在這些數(shù)據(jù)集上,可將每個(gè)分子的每個(gè)形狀看作一個(gè)特征向量,由多個(gè)形狀構(gòu)成的分子看作一個(gè)矩陣對(duì)象。mutagenesis根據(jù)難易程度分為兩種,即文中的mutagenesis1和mutagenesis2。ucsb_breast[16]是一個(gè)圖像數(shù)據(jù)集,可以從網(wǎng)址(http://www.bioimage.ucsb.edu/research/biosegmentation)上下載。elephant和tiger是從(http://www.cs.columbia.edu/~andrews/mil/datasets.html)下載的圖像數(shù)據(jù)集[17],可將每張圖片的一個(gè)分割部分看作一個(gè)特征向量,則多個(gè)分割部分合成的圖片就是一個(gè)矩陣對(duì)象。component[18]是從(http://www.biocreative.org/tasks/biocreative-i/task-2-functional-annotations/)下載的一個(gè)文本數(shù)據(jù)集,可以將每個(gè)段落看作一個(gè)特征向量,多個(gè)段落組成的一個(gè)文本就是一個(gè)矩陣對(duì)象。表3給出全部數(shù)據(jù)集的相關(guān)信息。

表3 實(shí)驗(yàn)中使用的數(shù)據(jù)集
因?yàn)槿鄙俟_(kāi)的分類(lèi)型矩陣數(shù)據(jù)集,且已有的分類(lèi)型矩陣數(shù)據(jù)集的維度較低,對(duì)于計(jì)算屬性間距離有比較大的影響,所以本文用數(shù)值型矩陣數(shù)據(jù)集來(lái)驗(yàn)證提出算法的有效性。由于數(shù)值型數(shù)據(jù)的屬性值是連續(xù)的,因此需要對(duì)其進(jìn)行離散化處理。對(duì)于musk數(shù)據(jù)集,數(shù)據(jù)的屬性值是整數(shù)型,可以認(rèn)為是離散型數(shù)據(jù),則只需對(duì)除musk數(shù)據(jù)集之外的其余數(shù)據(jù)集進(jìn)行歸一化處理,歸一化公式定義為:
(10)
然后將歸一化后的數(shù)據(jù)集進(jìn)行均勻離散化處理,將其平均分成10份,相對(duì)應(yīng)的值分別設(shè)置為{1,2,…,10}構(gòu)成了實(shí)驗(yàn)所需數(shù)據(jù)集。
4.2 評(píng)價(jià)指標(biāo)
為評(píng)價(jià)本文提出的初始類(lèi)中心算法的有效性,使用5個(gè)評(píng)價(jià)指標(biāo),即精度(AC)、查準(zhǔn)率(PR)、召回率(RE)、標(biāo)準(zhǔn)互信息(NMI)[19]和調(diào)整蘭德指數(shù)(ARI)[20]評(píng)價(jià)算法的優(yōu)劣[3]。
4.3 結(jié)果分析
為驗(yàn)證本文提出的初始類(lèi)中心選擇算法的有效性,將該算法與一種隨機(jī)初始化Random算法[3]進(jìn)行了比較,并與另外兩種典型的初始類(lèi)中心選擇算法CAOICACD算法[10]和BAIICACD算法[11]也進(jìn)行了比較。對(duì)于初始類(lèi)中心算法IC2SACMD、CAOICACD和BAIICACD,只需聚類(lèi)一次即可。而對(duì)于實(shí)驗(yàn)中的Random算法,由于該算法采取隨機(jī)初始化類(lèi)中心,則需要對(duì)每個(gè)數(shù)據(jù)集進(jìn)行50次聚類(lèi),將其均值作為最終的結(jié)果。由于目前在分類(lèi)型矩陣數(shù)據(jù)上的相關(guān)工作較少,本文選用了針對(duì)普通分類(lèi)型數(shù)據(jù)比較典型的兩種初始類(lèi)中心選擇算法CAOICACD和BAIICACD來(lái)進(jìn)行比較,因此需要將本文中的7個(gè)真實(shí)的數(shù)據(jù)集進(jìn)行簡(jiǎn)單處理,即先將矩陣數(shù)據(jù)集進(jìn)行了壓縮,每個(gè)矩陣對(duì)象用頻率最高的屬性值來(lái)表示。在新生成的數(shù)據(jù)集中,一個(gè)對(duì)象只有一條記錄,然后將后兩種算法在新生成的數(shù)據(jù)集中進(jìn)行實(shí)驗(yàn)。本文實(shí)驗(yàn)結(jié)果如表4所示,其中,表中加粗字體為不同算法針對(duì)每個(gè)數(shù)據(jù)集在不同評(píng)價(jià)指標(biāo)上的最優(yōu)結(jié)果。
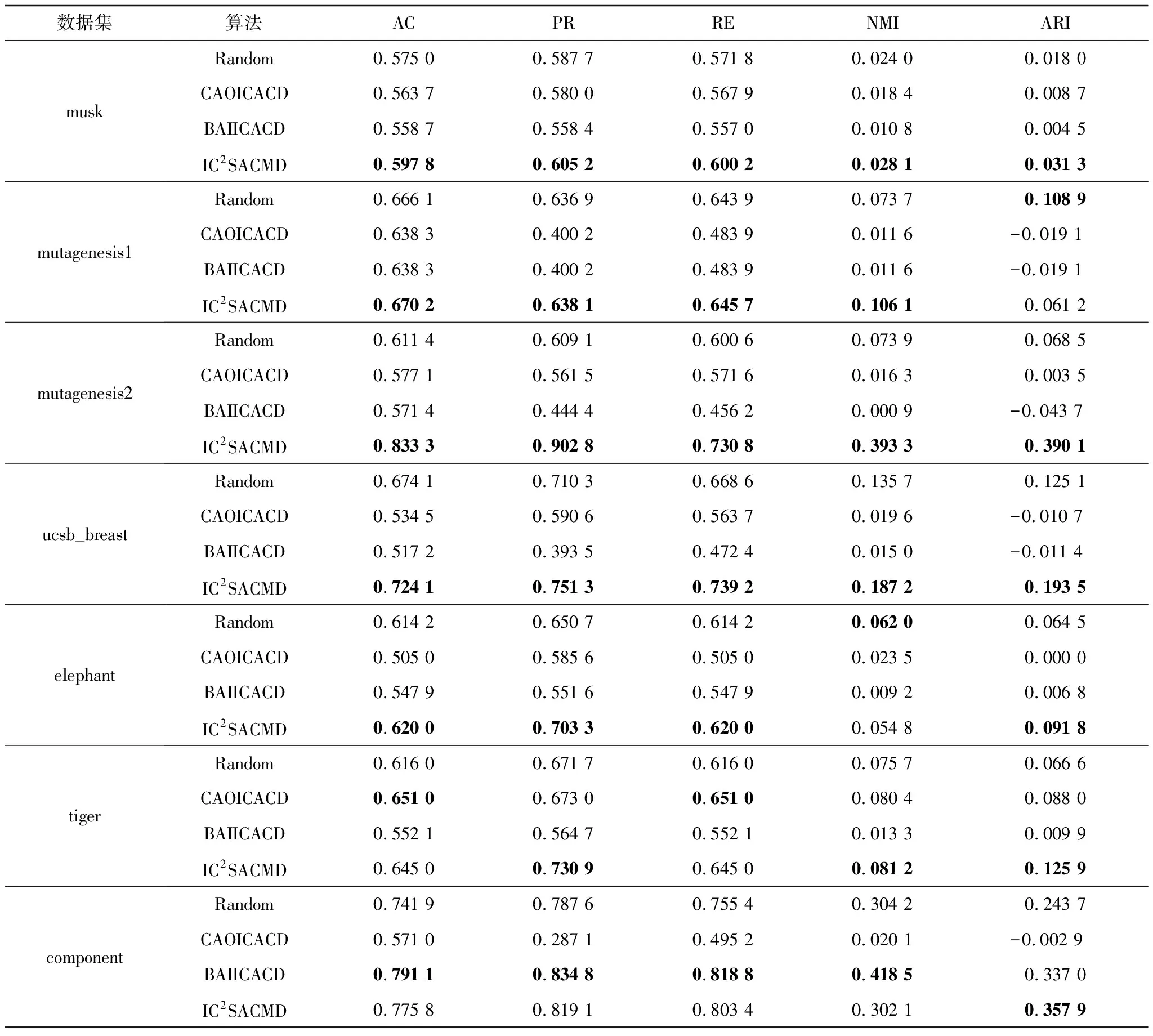
表4 不同算法在各數(shù)據(jù)集上的實(shí)驗(yàn)結(jié)果
從實(shí)驗(yàn)結(jié)果可以看出,在7個(gè)真實(shí)數(shù)據(jù)集上,本文IC2SACMD算法優(yōu)于Random算法、CAOICACD算法和BAIICACD算法,并在5個(gè)評(píng)價(jià)指標(biāo)上都產(chǎn)生了比較好的聚類(lèi)效果,尤其是在mutagenesis2數(shù)據(jù)集上的聚類(lèi)效果顯著,相比Random算法提高了22%的精度,相比ucsb_breast數(shù)據(jù)集提高了5%的精度。而CAOICACD算法和BAIICACD算法在不同數(shù)據(jù)集的5個(gè)評(píng)價(jià)指標(biāo)上的效果相差不大,僅在tiger和component數(shù)據(jù)集上相差比較明顯,特別是BAIICACD算法在component數(shù)據(jù)集上達(dá)到相對(duì)最優(yōu),甚至超過(guò)了本文算法2%的精度,可見(jiàn),BAIICACD算法在component數(shù)據(jù)集上效果更好。但是CAOICACD算法和BAIICACD算法因?yàn)閿?shù)據(jù)集進(jìn)行壓縮時(shí),會(huì)導(dǎo)致許多信息的丟失,以至于精確度較低。
5 結(jié)束語(yǔ)
分類(lèi)型矩陣數(shù)據(jù)在實(shí)際應(yīng)用中廣泛存在。針對(duì)分類(lèi)型矩陣數(shù)據(jù),本文根據(jù)屬性值的頻率定義了矩陣對(duì)象的密度和矩陣對(duì)象間的距離,擴(kuò)展了最大最小距離算法,從而實(shí)現(xiàn)初始類(lèi)中心的選擇,在此基礎(chǔ)上,提出一種面向分類(lèi)型矩陣數(shù)據(jù)的初始類(lèi)中心選擇算法。實(shí)驗(yàn)結(jié)果表明,與傳統(tǒng)初始類(lèi)中心選擇算法相比,該算法具有較優(yōu)的聚類(lèi)效果。在未來(lái)的工作中將結(jié)合半監(jiān)督學(xué)習(xí)來(lái)選擇初始類(lèi)中心。
猜你喜歡
幼兒教育·父母孩子版(2022年4期)2022-05-08 21:35:35
中學(xué)生數(shù)理化(高中版.高考數(shù)學(xué))(2021年3期)2021-06-09 06:09:14
中學(xué)生數(shù)理化(高中版.高二數(shù)學(xué))(2021年12期)2021-04-26 07:43:38
中學(xué)生數(shù)理化(高中版.高二數(shù)學(xué))(2021年2期)2021-03-19 08:54:04
海峽姐妹(2020年9期)2021-01-04 01:35:44
華人時(shí)刊(2020年13期)2020-09-25 08:21:32
VOGUE服飾與美容(2020年9期)2020-09-02 14:47:26
山東青年(2016年1期)2016-02-28 14:25:25
汽車(chē)維護(hù)與修理(2015年6期)2015-02-28 12:16:55
當(dāng)代修辭學(xué)(2014年3期)2014-01-21 02:30:44
