基于深度學習的個性化對話內容生成方法
2020-05-21 07:39:56郝少陽張秋韻於志文
圖學學報 2020年2期
王 豪,郭 斌,郝少陽,張秋韻,於志文
基于深度學習的個性化對話內容生成方法
王 豪,郭 斌,郝少陽,張秋韻,於志文
(西北工業大學計算機學院,陜西 西安 710072)
人機對話系統是人機交互領域一個非常重要的研究方向,開放域聊天機器人的研究受到了廣泛關注。現有的聊天機器人主要存在3個方面的問題:①無法有效捕捉上下文情境信息,導致前后對話內容缺乏邏輯關聯。②大部分不具備個性化特征,導致聊天過程千篇一律,且前后對話內容可發生矛盾。③傾向于生成“我不知道”、“對不起”等無意義的通用回復內容,極大降低用戶的聊天興趣。本研究中利用基于Transformer模型的編解碼(Encoder-Decoder)結構分別構建了通用對話模型和個性化對話模型,通過編碼歷史對話內容和個性化特征信息,模型可以有效捕捉上下文情境信息以及個性化信息,實現多輪對話過程,且對話內容符合個性化特征。實驗結果表明,基于Transformer的對話模型在困惑度(perplexity)和F1分數評價指標上相比于基線模型得到了一定的提升,人工評價顯示模型可以正常進行多輪交互對話過程,生成內容多樣性高,且符合給定的個性化特征。
深度學習;對話系統;聊天機器人;個性化;上下文感知
1 背景知識
人機對話系統是人機交互領域一個非常重要的研究方向,形式多樣的對話系統正處于蓬勃發展階段。文本生成,即自然語言生成,是實現對話系統的關鍵技術,可以利用各種不同類型的信息,如文本、圖像等,自動生成流暢通順、語義清晰的高質量自然語言文本。2003年BENGIO等[1]將神經網絡語言模型應用于文本生成任務中,利用神經網絡進行語言建模,為了解決自然語言中的長期依賴問題,2010年MIKOLOV等[2]利用RNN建立語言模型,提出了循環神經網絡語言模型RNNLM,顯著提高了語言模型的準確性。之后RNN及其各種變體如長短時記憶網絡(long short-term memory, LSTM)開始成為自然語言處理技術中最常用的方法。而最近提出的Transformer模型[3]成功解決了RNN模型中存在的一些問題,引發了一輪又一輪的研究熱潮。
社交聊天機器人,即能夠與人類進行共情對話的人機對話系統,是人工智能領域持續時間最長的研究目標之一。聊天機器人若想與用戶建立情感聯系,必須具有幾種能力,首先是上下文情境整合能力,在聊天過程中考慮各種情境信息來產生相應的回復內容,增加用戶的真實交互感。同時聊天機器人必須擁有前后一致的個性化人格,如年齡、性別等,如果這些特征發生變化,很容易讓用戶產生剝離感。最后是對話內容必須具有多樣性,不能總是產生“我不知道”、“是的,沒錯”這種通用回復,否則用戶極易產生厭倦。
為了解決這些問題,本文構建了基于情境的個性化對話內容生成模型。對話過程中考慮上下文情境信息和考慮個性化特征信息,并采用多種優化方法增加生成回復內容的多樣性,生成上下文連貫一致且符合個性化特征的高質量對話內容。本文的主要工作內容和貢獻包括以下幾個方面:
(1) 利用基于Transformer模型構建通用對話模型。通過編碼歷史對話內容,有效捕捉上下文情境信息,實現多輪對話過程。
(2) 調整通用對話模型結構,編碼階段加入個性化特征信息,構建個性化對話模型,有效捕捉其特征,生成符合個性化特征且前后保持一致的對話內容。
(3) 利用標簽平滑、帶有長度懲罰的多樣化集束搜索等算法解決模型傾向于生成通用性回復的問題,豐富生成內容的多樣性。
2 相關工作
近年來,人機對話系統備受學術界和工業界的關注,創建一個自動人機對話系統為人類提供特定的服務或與人類進行自然交流不再是一種幻想[4]。
SORDONI等[5]基于RNN構建了一個端到端回復生成模型,通過編碼歷史對話,捕捉上下文情境信息,生成連貫一致的對話內容。VINYALS等[6-7]利用了LSTM進行對話模型的構建。盡管LSTM在一定程度上緩解了長距離依賴問題,但是實際應用過程中仍有可能遇到更長的上下文內容,文獻[8]提出多層循環編解碼模型(hierarchical recurrent encoder-decoder, HRED),將編碼過程分為2個層次,分別編碼單詞序列和句子序列,得到上下文表示向量,指導解碼過程。實驗表明,多層編碼結構可更有效地捕捉上下文信息。不同的上下文語境對生成回復內容有著不同的影響,SHANG等[9]引入了注意力機制(attention mechanism),通過計算不同時刻上下文的權重,決定上下文內容在回復中的表達程度,取得了更好的效果。
雖然RNN的天然序列結構適合進行自然語言處理的任務,但其嚴格的線性結構會導致訓練過程中容易發生梯度消失或爆炸問題,而且難以進行并行訓練,這在大規模應用場景中是一個很嚴重的問題。為了解決這些問題,Google在2017年提出了一種新的序列建模模型-Transformer模型[3]。該模型一經提出,就在NLP領域引起了極大的反響,其拋棄了RNN中的序列結構,整個模型完全由Attention模塊構成,有效地解決了長距離依賴問題和并行計算能力差的問題。Transformer模型可以高效地捕捉文本序列的語義信息,在語義特征提取能力、長距離特征捕獲能力、任務綜合特征抽取能力都遠超過RNN模型[10]。最近相當火爆的大型預訓練模型如GPT模型[11]、BERT模型[12]的基本結構均為Transformer,在多種自然語言處理任務中創造出極佳的成績,其出眾的能力顯而易見。
純數據驅動的端到端對話系統無法考慮個性化特征,不能給用戶沉浸式的交互體驗[13]。LI等[14]提出個性化回復生成模型,使用類似詞嵌入的方式將用戶編碼到高維隱空間中,以指導回復生成過程。LIU等[15]提出了個性化回復生成模型,通過用戶的交互對話內容來隱式學習用戶的個性化特征。LUO等[16]提出了基于記憶網絡(memory network)的個性化目標驅動型對話系統,編碼用戶個性化特征,同時利用全局記憶單元存儲相似用戶對話歷史,生成更加符合用戶個性化的內容。現有的聊天機器人研究中還存在著一些不足,如何更加高效地捕捉上下文情境信息、保持一致的個性化特征、以及生成更加多樣性的回復內容,仍是目前亟待解決的問題。
3 Transformer模型結構
本文利用了Transformer模型進行非目標驅動型對話系統即聊天機器人的構建,且實現了與用戶進行開放域內的對話。Transformer模型的本質上是編-解碼架構,模型的整體結構如圖1所示。

圖1 Transformer模型整體結構圖
其中編碼和解碼模型分別由6個編碼器和解碼器組成。每個編碼器和解碼器的結構分別如圖2所示。編碼過程中,數據首先經過自注意力(Self-attention)模塊得到加權之后的特征向量,再經過前饋神經網絡得到輸出。解碼器比編碼器中多了編-解碼注意力模塊,用于得到解碼階段當前時刻輸出與編碼階段每一時刻輸入之間的相關關系。
自注意力機制是Transformer模型最核心的部分,捕捉一個序列自身單詞之間的依賴關系,根據上下文信息對句子中的單詞進行編碼,使得單詞向量中蘊含豐富的上下文信息。計算過程中,輸入序列的每個單詞的詞嵌入向量分別與3個權重矩陣相乘得到對應的、及向量,然后將當前單詞的向量與輸入序列中其他單詞的向量作點積運算得到相關程度,進行歸一化后的結果再通過Softmax激活函數得到概率分布,最后將概率分布作為權重值對每個單詞的向量進行加權,得到當前時刻單詞的向量表示,即

4 個性化對話模型設計
4.1 通用對話模型
本文實驗過程中首先進行通用對話模型的設計與實現開放域多輪日常對話過程。本文中設計的通用對話模型基于編-解碼結構,其中編碼端和解碼端分別由Transformer編碼器和解碼器組成。模型的整體結構如圖3所示。

圖3 通用對話模型結構圖
編碼端和解碼端的層數均為12層,為了考慮上下文情境信息,在編碼階段,將歷史對話內容編碼,其中可能包含多個句子序列,每個序列獨自輸入模型,與當前時刻輸入共同作用影響解碼階段的預測輸出。
4.2 模型輸入編碼
利用詞嵌入方法Word2vec,將輸入對話數據轉換為詞向量,維度為512維。由于Transformer模型沒有捕捉序列數據的能力,因此利用位置編碼(Positional Embedding)的編碼序列中單詞位置信息,使模型可以區分序列中不同位置的單詞。位置編碼的向量維度與詞嵌入向量的維度相同,通過式(2)和(3)進行單詞的位置編碼,即
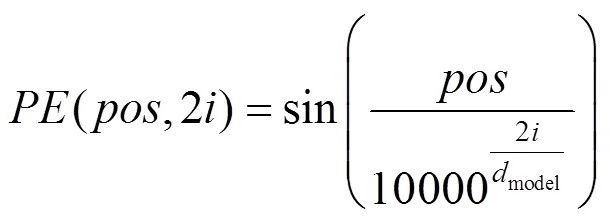

其中,為單詞的位置;為單詞的維度。得到序列中每個單詞的位置編碼之后,將其值與單詞的詞向量做加和操作,得到每個單詞的輸入向量。
4.3 多頭注意力機制
在自注意力機制的基礎上,模型中提出了多頭注意力(multi-head attention)機制,每個自注意力模塊稱為一個注意力頭。多頭注意力機制的計算過程中,首先對輸入序列經過個不同的注意力頭進行計算,然后將這個不同的特征矩陣按列拼接為一個特征矩陣,再通過一個全連接層,壓縮為與單個注意力頭維度相同的矩陣,得到多頭注意力模塊輸出結果。計算如下


本文實驗過程中,編碼和解碼端的多頭注意力層均包含12個注意力頭,整合方式不是標準Transformer模型中的方式,而是求所有注意力頭的對應維度上的平均值,以減少降維過程中信息的損失并加速模型訓練。
4.4 個性化對話模型
通用對話模型可以進行多輪的對話,但過程中未考慮個性化信息。沒有個性化特征的聊天機器人在對話過程中可能會產生語義不一致的現象,如前文提及自己為學生,而后文卻在上班。使其用戶產生剝離感,易使用戶意識自己在跟一個虛假的機器人聊天,難以建立長期的情感聯系。為解決此問題,本文設計了個性化對話模型,通過賦予聊天機器人個性化特征,使其可以根據自身的特征產生合適的回復內容,提升用戶的聊天交互體驗。
本文設計的個性化對話模型是基于編-解碼框架,其中編碼端和解碼端分別由Transformer模型的編碼器和解碼器組成,具體層數設置均與通用對話模型相同。與之不同的是,個性化對話模型需要考慮個性化特征信息,并在模型的輸入部分添加個性化信息進行編碼,模型編碼階段結構如圖4所示。

圖4 個性化對話模型結構圖
編碼過程除了對當前用戶輸入和歷史對話進行編碼,最關鍵的部分是對個性化特征信息進行編碼,本文中的個性化特征指一組對人物進行描述的句子信息,編碼后的個性化特征向量與當前輸入和歷史對話內容共同指導解碼階段的回復生成過程。
解碼過程中,編-解碼注意力模塊可以確定當前時刻用戶輸入、歷史對話內容以及個性化特征信息對當前時刻輸出的影響程度。通過綜合考慮上下文情境信息和個性化特征信息,個性化對話模型可以生成與上下文連貫一致并且符合特定的個性化特征的回復內容。
4.5 模型優化
4.5.1 標簽平滑算法
在Seq2seq模型的訓練過程中,通常通過最小化句子序列的負對數似然概率優化模型,即

但該訓練過程會強迫模型進行非零即一的預測以區分真實數據和生成內容,降低模型的泛化性能。標簽平滑(label smoothing)算法通過類似正則項的作用使模型對其預測結果降低自信以解決此問題。利用一個與當前輸入無關的先驗分布來平滑預測目標的分布函數,通常采用所有的單詞的均勻先驗分布。標簽平滑等價于在負對數似然函數的基礎上添加一個KL散度項,即計算先驗分布與模型預測輸出概率之間的距離,即

通過防止模型將預測值過度集中在概率較大的類別上,從而降低通用回復出現的概率,增加生成回復內容的多樣性。
4.5.2 長度懲罰的多樣化集束搜索算法
集束搜索算法是Seq2seq模型解碼階段常用的一種算法,其參數為解碼過程在每個時刻選擇概率最高的個單詞作為輸出。通過在每個時刻選擇概率最高的個單詞,該算法最終生成個概率最高的句子序列,并使其最大化,從而生成更加合理的結果,提高生成句子的質量。
由于一個句子序列的概率由多個單詞的概率累乘得到,生成的句子序列越長,累乘得到的概率值可能就會越小,因此集束搜索算法傾向于生成較短的句子。Google提出了長度懲罰方法解決這個問題[17],通過降低短序列的概率值,提高長序列的概率值,使模型有更多的機會生成較長的序列,即
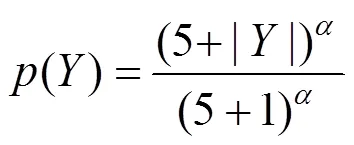
在實驗過程中取值為0.6。
集束搜索算法中存在的另一個問題為生成的個句子的差異性不大,多樣性較低。通過將生成結果進行分組,組間加入相似性懲罰來降低生成多個結果的相似性,迫使模型生成更加多樣化的內容,減少通用回復的出現。
5 實驗驗證
5.1 數據收集與處理
實驗過程利用了2個對話數據集。首先是DailyDialog數據集[18],其中共包含13 118組多輪對話,平均每組對話中包括8輪對話過程。按照8∶1∶1的比例對該數據集進行切分得到訓練集、驗證集和測試集,劃分結果見表1。在訓練數據中平均每組多輪對話為7.7輪。
第2個數據集是Persona-Chat個性化對話數據集[19],其中共包含1 155組個性化信息,每組中至少包含5句個性化描述,如“我是一個藝術家。我有4個孩子”。其中共包含10 981組多輪對話,平均每組多輪對話包含14.9輪對話。按照8∶1∶1的比例對數據集進行切分得到訓練集、驗證集和測試集,劃分結果見表2。
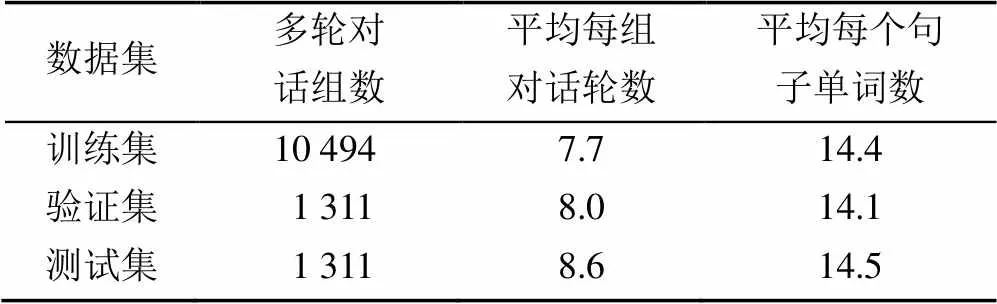
表1 DailyDialog數據集切分結果

表2 Persona-Chat數據集切分結果
5.2 評價指標
5.2.1 困惑度
困惑度(Perplexity)指標可以用來衡量一個概率預測模型預測樣本的好壞程度,困惑度越低代表模型的性能越好,即

其中,Y為一個句子序列中的第個單詞。
5.2.2 F1分數(F1-Score)
F1分數是分類問題的一個衡量指標,是精確率(precision)和召回率(recall)的調和平均數,即
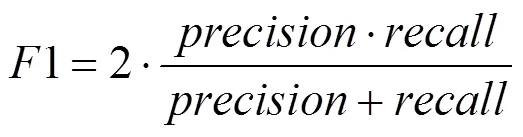
F1分數計算過程中,根據預測句子與目標句子序列的單詞匹配程度計算精確率和召回率,F1分數越高說明模型預測句子序列的準確度越高,模型的性能越好。
5.3 參數設置
利用DailyDialog數據集訓練通用對話模型,并利用Adam優化器優化加入了標簽平滑正則項的對數似然函數。訓練批次大小設置為128,學習率設置為6.25e-5,當梯度值大于5時進行梯度裁剪。利用Dropout機制防止過擬合現象的發生,概率為0.1。利用Persona-Chat數據集訓練個性化對話模型,開始時直接加載通用對話模型初始化參數,然后進行模型的訓練,參數設置與通用對話模型相同。
5.4 實驗結果
5.4.1 通用對話模型實驗對比分析
實驗過程采用了3個基線模型:①基于RNN的Seq2seq模型,直接將所有歷史對話進行編碼;②添加了Attention機制的Seq2seq模型;③HRED模型[8],將上下文對話信息分層編碼,且利用雙向RNN結構,加入了Attention機制。對比實驗結果見表3和表4。

表3 通用對話模型困惑度對比實驗結果

表4 通用對話模型F1分數對比實驗結果
從表3和表4可看出,基于RNN的Seq2seq 2個模型指標均表現最差,而在添加了Attention機制后結果有了明顯的提升,說明Attention機制對編解碼結構的效果具有明顯的提升作用。而HRED模型通過多層編碼結構考慮了更多的上下文對話信息,使其較雙向RNN結構和Attention機制模型結果有了更進一步的提升。而本文利用的Transformer模型在對比實驗中取得了最好的結果,證明該模型可以產生更加高質量的對話內容。
表5為使用通用對話模型進行對話的示例。可以看出,模型可較為流暢地與人進行開放域的聊天過程,很少生成通用回復,幾乎所有回復中都包含有用的信息,并且可以考慮到上下文信息,整個聊天過程可以有效持續進行。
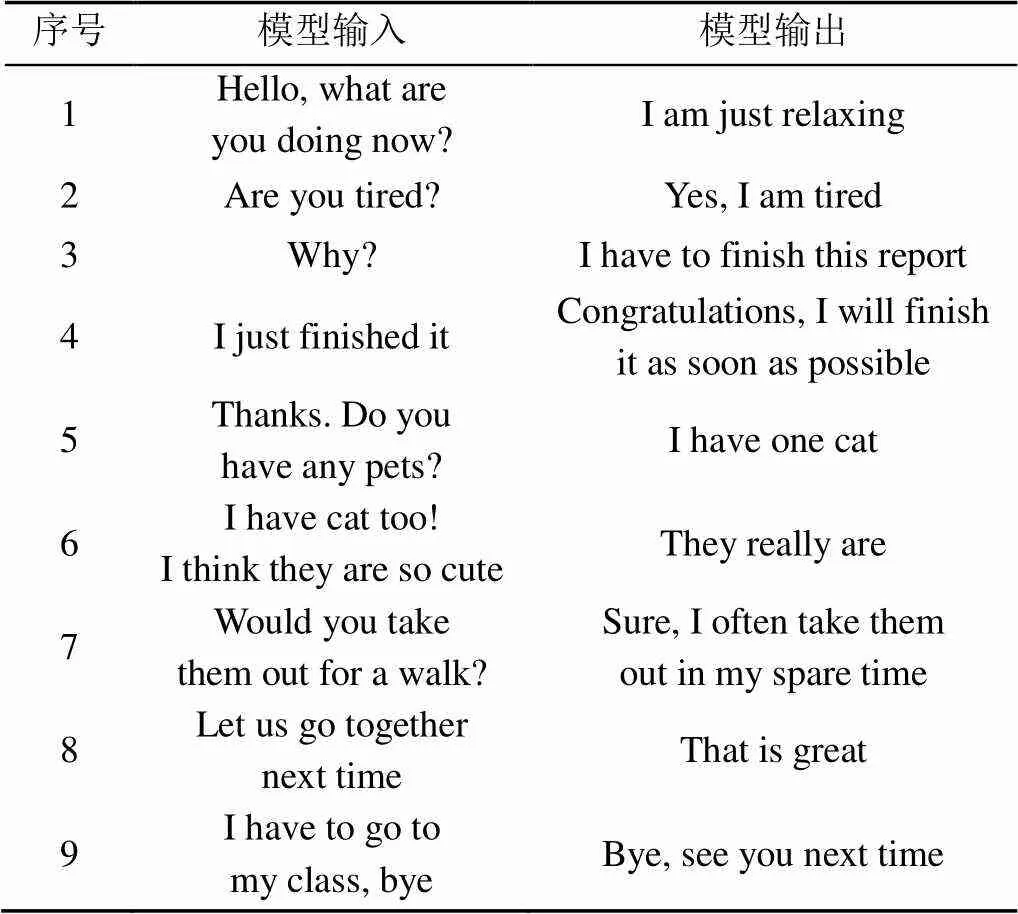
表5 通用對話模型對話示例
5.4.2 個性化對話模型實驗結果
為了體現個性化特征對對話過程的影響,從數據集中隨機抽取一組個性化特征描述,將其賦予聊天機器人作為其個性化特征,驗證聊天機器人能否有效捕捉個性化特征。由于機器評價指標無法判斷對話內容中是否包含個性化特征,因此對于個性化對話模型暫利用人工評價的方法進行評價,通過人工判斷對話過程中模型產生的對話回復是否符合被賦予的特定的個性化特征來評價模型的性能。表6隨機抽取的一組個性化特征描述內容。

表6 隨機抽取的個性化特征
表7為使用個性化對話模型進行對話的示例。可以看到,模型可流暢地與人進行開放域的多輪聊天過程,且考慮到上下文和個性化特征信息,如“我喜歡電子游戲”、“我的頭發是金色的”等信息均符合被賦予的個性化特征。因此,本文設計的個性化對話模型可以很好地融入個性化特征,實現個性化多輪對話過程。

表7 個性化對話模型對話示例
6 總結與展望
本文主要探索了開放域聊天機器人的回復生成技術。模型通過將當前時刻輸入、歷史對話以及個性化特征進行編碼,指導解碼階段的回復生成過程,實現前后連貫的多輪對話,并且保持一致的個性化特征,同時生成內容多樣性較高。實驗結果表明,本文設計的模型在困惑度和F1分數評價指標中取得了對比實驗的最好結果,并且可以與人類進行持續對話過程,前后邏輯保持一致,很少出現通用性回復,并且符合個性化特征。本本實驗過程中直接將所有歷史對話內容進行編碼來實現多輪對話,可能導致模型不能全面而有效地捕捉上下文信息,因此在未來的研究過程中,需要考慮如何更加高效地從長跨度的歷史對話中捕捉有效上下文信息,增強多輪對話能力。直接利用既定的句子形式的個性化特征作為一部分輸入進行編碼是構建個性化對話模型的一種解決方法,但在實際應用過程中卻較難實現,因此如何得到更加通用的個性化特征以及如何利用少量的個性化數據對深度模型進行有效地訓練是今后研究的主要方向。
[1] BENGIO Y, DUCHARME R, VINCENT P, et al. A neural probabilistic language model[J]. Journal of Machine Learning Research, 2003, 3(2): 1137-1155.
[2] MIKOLOV T, KARAFIáT M, BURGET L, et al. Recurrent neural network based language model[EB/OL]. (2020-02-23). http://xueshu.baidu.com/ usercenter/paper/show?paperid=f2fef7f500521c4031ef9794c11c9318&site=xueshu_se.
[3] VASWANI A, SHAZEER N, PARMAR N, et al. Attention is all you need[EL/OL]. [2020-02-23]. https:// www.researchgate.net/publication/317558625_Attention_Is_All_You_Need.
[4] CHEN H, LIU X, YIN D, et al. A survey on dialogue systems: Recent advances and new frontiers[J]. ACM SIGKDD Explorations Newsletter, 2017, 19(2): 25-35.
[5] SORDONI A, GALLEY M, AULI M, et al. A neural network approach to context-sensitive generation of conversational responses[EB/OL]. [2020-02-23].https://www.microsoft.com/en-us/research/publication/a-neural-network-approach-to-context-sensitive-generation-of-conversational-responses/.
[6] VINYALS O, LE Q. A neural conversational model[EB/OL]. [2020-02-23]. http://www.doc88.com/ p-9991503943118.html.
[7] LI J W, GALLEY M, BROCKETT C, et al. A diversity-promoting objective function for neural conversation models[EB/OL]. [2020-02-23].https:// www.microsoft.com/en-us/research/publication/a-diversity-promoting-objective-function-for-neural-conversation-models/.
[8] SERBAN I V, SORDONI A, BENGIO Y, et al. Building end-to-end dialogue systems using generative hierarchical neural network models[C]//Thirtieth AAAI Conference on Artificial Intelligence. New York: CAM Press, 2016: 3776-3883.
[9] SHANG L F, LU Z D, LI H. Neural responding machine for short-text conversation[EB/OL]. [2020-02-23].http://xueshu.baidu.com/usercenter/paper/ show?paperid=6a378dcda923a20f3fb021e4bbb53690&site=xueshu_se.
[10] TANG G, MüLLER M, RIOS A, et al. Why self-attention? a targeted evaluation of neural machine translation architectures[EB/OL]. [2020-02-23]. http:// xueshu.baidu.com/usercenter/paper/show?paperid=1s6v0ts0je6y0gg0u77g0t50ys723028&site=xueshu_se.
[11] RADFORD A, NARASIMHAN K, SALIMANS T, et al. Improving language understanding by generative pre-training[EB/OL]. [2020-02-23]. https://s3-us-west-2. amazonaws.com/openai-assets/research-covers/languageunsupervised/language understanding paper.pdf, 2018.
[12] DEVLIN J, CHANG M W, LEE K, et al. Bert: pre-training of deep bidirectional transformers for language understanding[EB/OL]. [2020-02-23].http://xueshu.baidu.com/usercenter/paper/show?paperid=163v0jq00n460jd0bh1m02b0yd094771&site=xueshu_se&hitarticle=1.
[13] LUO L C, HUANG W H, ZENG Q, et al. Learning personalized end-to-end goal-oriented dialog[EL/OL]. [2020-02-23]. http://xueshu.baidu.com/usercenter/paper/ show?paperid=186j06y09d7j00x05w670tp09v148579&site=xueshu_se.
[14] LI J, GALLEY M, BROCKETT C, et al. A persona-based neural conversation model[EB/OL]. [2020-02-23]. http://xueshu.baidu.com/usercenter/paper/ show?paperid=a94092c9f0f5fcd5f0f694b6a4ee9e99&site=xueshu_se&hitarticle=1.
[15] LIU B, XU Z, SUN C, et al. Content-oriented user modeling for personalized response ranking in chatbots[J]. IEEE/ACM Transactions on Audio, Speech and Language Processing (TASLP), 2018, 26(1): 122-133.
[16] LUO L C, HUANG W H, ZENG Q, et al. Learning personalized end-to-end goal-oriented dialog[EB/OL]. [2020-02-23].http://xueshu.baidu.com/usercenter/paper/ show?paperid=186j06y09d7j00x05w670tp09v148579&site=xueshu_se&hitarticle=1.
[17] WU Y H, SCHUSTER M, CHEN Z F, et al. Google’s neural machine translation system: bridging the gap between human and machine translation[EB/OL]. [2020-02-23].http://xueshu.baidu.com/usercenter/paper/ show?paperid=f6aeebc74cba16edb4c8706df0ba9536&site=xueshu_se&hitarticle=1.
[18] LI Y R, SU H, SHEN X Y, et al. Dailydialog: a manually labelled multi-turn dialogue dataset[EB/OL]. [2020-02-23].http://xueshu.baidu.com/usercenter/paper/ show?paperid=52816efb19417f114ed83f7c54b9b6e7&site=xueshu_se&hitarticle=1.
[19] ZHANG S Z, DINAN E, URBANEK J, et al. Personalizing dialogue agents: I have a dog, do you have pets too?[EB/OL].[2020-02-23].http://xueshu.baidu. com/usercenter/paper/show?paperid=f47c6a2d79c51aac36742a4ab6856254&site=xueshu_se&hitarticle=1.
Personalized dialogue content generation based on deep learning
WANG Hao, GUO Bin, HAO Shao-yang, ZHANG Qiu-yun, YU Zhi-wen
(School of Computer Science, Northwestern Polytechnical University, Xi’an Shaanxi 710072, China)
Dialogue system is a very important research direction in the field of Human–Machine Interaction and the research of open domain chatbot has attracted much attention. There are three main problems in the existing chatbots. The first is that they cannot effectively capture the context, which leads to the lack of logical cohesion in the dialogue content. Second, most of the existing chatbots do not have specific personalized characteristics, resulting in the monotony in the chat process, and the dialogue content may be contradictory. Third, they tend to generate meaningless replies such as “I don’t know” or “I’m sorry”, which greatly reduces users’ interest in chat. The Encoder-Decoder framework based on Transformer was used to build the general dialogue model and personalized dialogue model. By encoding the historical dialogue content and personalized feature information, the model could effectively capture the context and the personalized information and realize multi-round dialogue process, generating personalized dialogue content. The experimental results showed that the dialogue model based on Transformer obtained better results on the evaluation metrics of perplexity and F1-score compared to the baseline models. Combined with manual evaluation, it is concluded that our dialogue model is capable of carrying out multi-round dialogues, with high content diversity and in line with the given personalized characteristics.
deep learning; dialogue system; chatbot; personalization; context aware
TP 391
10.11996/JG.j.2095-302X.2020020210
A
2095-302X(2020)02-0210-07
2019-11-19;
2019-12-27
國家重點研發計劃項目(2017YFB1001800);國家自然科學基金項目(61772428,61725205)
王 豪(1996-),男,河南新鄉人,碩士研究生。主要研究方向為人機對話系統。E-mail:wanghao456@mail.nwpu.edu.cn
郭 斌(1980-),男,山西太原人,教授,博士,博士生導師。主要研究方向為普適計算、移動群智感知。E-mail:guob@nwpu.edu.cn
猜你喜歡
科學大眾(2022年11期)2022-06-21 09:20:52
閱讀(快樂英語高年級)(2020年8期)2020-01-08 02:21:16
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
智慧少年·故事叮當(2018年11期)2018-05-14 11:48:18
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
臺聲(2016年2期)2016-09-16 01:06:53
河南科技(2014年23期)2014-02-27 14:19:15
七彩語文·低年級(2011年19期)2011-04-12 00:00:00
海外英語(2006年8期)2006-09-28 08:49:00
