
結(jié)合Inception模塊的卷積神經(jīng)網(wǎng)絡圖像分類方法
2020-05-28 09:36:21齊廣華何明祥
軟件導刊 2020年3期
齊廣華 何明祥


摘 要:針對現(xiàn)有卷積神經(jīng)網(wǎng)絡模型參數(shù)量大、訓練時間長的問題,提出了一種結(jié)合VGG模型和Inception模塊特點的網(wǎng)絡模型。該模型通過結(jié)合兩種經(jīng)典模型的特點,增加網(wǎng)絡模型的寬度和深度,使用較小的卷積核和較多的非線性激活,在減少參數(shù)量的同時增加了網(wǎng)絡特征提取能力,同時利用全局平均池化層替代全連接層,避免全連接層參數(shù)過多容易導致的過擬合問題。在MNIST和CIFAR-10數(shù)據(jù)集上的實驗結(jié)果表明,該方法在MNIST數(shù)據(jù)集上的準確率達到了99.76%,在CIFAR-10數(shù)據(jù)集上的準確率相比傳統(tǒng)卷積神經(jīng)網(wǎng)絡模型提高了6%左右。
關(guān)鍵詞:卷積神經(jīng)網(wǎng)絡; Inception模塊; 全局平均池化; 卷積核; 圖像分類
DOI:10. 11907/rjdk. 192501
中圖分類號:TP301 ? 文獻標識碼:A??????????????? 文章編號:1672-7800(2020)003-0079-04
Convolutional Neural Network Image Classification Method Combined
with Inception Module
QI Guang-hua, HE Ming-xiang
(College of Computer Science and Engineering, Shandong University of Science and Technology, Qingdao 266590, China)
Abstract: Aiming at the problem that the existing convolutional neural network model has large parameters and long training time, we propose a network model combining VGG model and inception module. By combining the characteristics of the two classical models, the model increases the width and depth of the network model, uses a smaller convolution kernel and more nonlinear activation, and increases the network feature extraction ability while reducing the parameter quantity. The average pooling layer replaces the fully connected layer, avoiding the over-fitting problem that is easily caused by too many parameters of the full-connected layer. Experimental results on the MNIST and CIFAR-10 datasets show that the accuracy of this method on the MNIST dataset is 99.76%. The accuracy on the CIFAR-10 dataset is about 6% higher than the traditional convolutional neural network model.
Key Words: convolutional neural network; inception module; global average pooling; convolution kernel; image classification
0 引言
智能化信息時代的到來,使得人工智能與機器學習技術(shù)得到了飛速發(fā)展。卷積神經(jīng)網(wǎng)絡[1](Convolution Neural Network,CNN)作為深度學習最常用的模型之一,由于具有良好的特征提取能力和泛化能力,在圖像處理、目標跟蹤與檢測、自然語言處理、場景分類、人臉識別、音頻檢索、醫(yī)療診斷等諸多領域獲得了巨大成功。
隨著如LeNet-5[2],AlexNet,VGGNet[3]等一系列經(jīng)典CNN模型的提出,模型的深度和復雜度也隨之增加,網(wǎng)絡模型的參數(shù)也變得龐大,模型運行也消耗了更多時間。文獻[4]討論了在特定復雜度和時間中,CNN模型的深度、特征數(shù)、卷積核等因素平衡問題。通過增加卷積層數(shù)量增加網(wǎng)絡深度,使得模型在分類任務上更有優(yōu)勢;文獻[5]、文獻[6]的研究表明,CNN模型中從卷積層到全連接層存在大量冗余參數(shù),并且全連接層的參數(shù)量約占90%。剔除不重要的參數(shù)節(jié)點以及卷積核,可以達到精簡網(wǎng)絡結(jié)構(gòu)的目的,減少參數(shù)進而有效緩解過擬合現(xiàn)象[7]的發(fā)生,同時減少網(wǎng)絡訓練時間,提升網(wǎng)絡模型的健壯性;文獻[8]提出了Inception模塊,利用3種類型的卷積操作(1×1,3×3,5×5),增加了CNN深度,同時減少了參數(shù),提升了計算資源利用率。
基于以上背景,本文提出結(jié)合Inception模塊的卷積神經(jīng)網(wǎng)絡圖像分類方法,利用若干個較小的卷積核替代一個較大的卷積核,通過增加卷積層獲取深層次信息,同時讓幾種類型的卷積核并聯(lián)提取圖像特征,增加了網(wǎng)絡深度、寬度并減少了參數(shù),同時提升了算法效率。本文利用全局平均池化層(Global Average Pooling[9])替換全連接層以防止過擬合,采用批歸一化[10](Batch Normalization,BN)操作加速收斂過程,增強模型學習能力。
1 卷積神經(jīng)網(wǎng)絡模型
1.1 VGG-Net
VGG-Net在 ILSVRC-2014中的優(yōu)秀表現(xiàn),證明增加網(wǎng)絡深度可以影響網(wǎng)絡模型最終性能。VGG-Net的一個改進是利用幾個連續(xù)的小卷積核替代AlexNet中的較大卷積核。在給定的相同感受野[11]下,由于小卷積核的代價較小,卷積核的堆疊也增加了非線性激活次數(shù),以進行更深層的特征學習,因此利用連續(xù)的小卷積核[12]是更優(yōu)選擇。例如在VGG中使用3個3×3卷積核代替1個7×7卷積核,7×7的參數(shù)為49個,3個3×3的參數(shù)是27個。這樣保證在具有相同感受野的條件下,提升網(wǎng)絡深度,同時使用3次非線性函數(shù)而不是1次,這樣增加了函數(shù)判別能力,減少了參數(shù)數(shù)量,在一定程度上提升了神經(jīng)網(wǎng)絡效果。
1.2 Inception模塊
VGG-Net的泛化性能非常好,常用于圖像特征抽取和目標檢測候選框生成等。VGG的最大問題就在于參數(shù)數(shù)量,簡單地堆疊較大卷積層非常消耗計算資源,VGG-19 基本上是參數(shù)量最多的卷積網(wǎng)絡架構(gòu)。由于信息位置的巨大差異,為卷積操作選擇合適的卷積核大小較為困難。信息分布全局性好的圖像偏好較大的卷積核,信息分布比較局部的圖像偏好較小的卷積核。非常深的網(wǎng)絡更容易過擬合,將梯度更新傳輸?shù)秸麄€網(wǎng)絡很困難。為了使網(wǎng)絡變寬,而不是更深,Inception模塊由此而生。它沒有像 VGG-Net 那樣大量使用全連接網(wǎng)絡,因此參數(shù)量非常小。
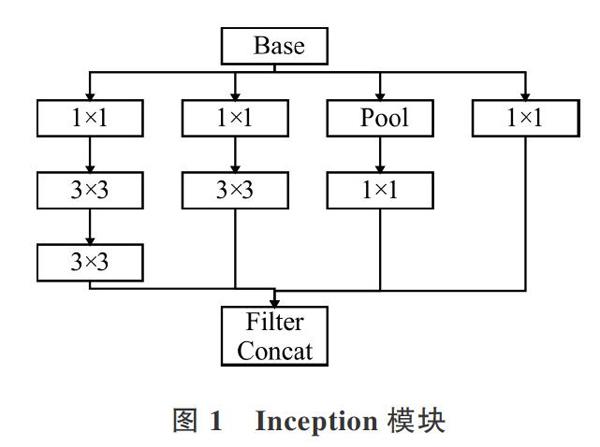
GoogLeNet最大的特點是使用了Inception模塊,如圖1所示,利用 1×1、3×3 或 5×5 等不同的卷積運算與池化操作獲得輸入圖像的不同信息,并行處理這些運算并結(jié)合所有結(jié)果將獲得更好的圖像特征。同時,為了降低計算成本,在3×3和5×5卷積層之前添加相較于3×3和5×5卷積廉價很多的 1×1 卷積層,以限制輸入信道數(shù)量。
2 卷積神經(jīng)網(wǎng)絡改進方法
2.1 模型寬度與深度
使用VGG16模型的前三層卷積,即3×3卷積核和2×2池化層的組合,卷積層使用大小相同的卷積核對圖像進行特征提取,緊跟的池化層將處理過的圖像進行高度和寬度壓縮,達到縮小圖像的目的。通過增加卷積池化層不斷加深網(wǎng)絡結(jié)構(gòu),進而增強圖像特征提取能力。
利用Inception模塊,設計一種具有優(yōu)良局部拓撲結(jié)構(gòu)的網(wǎng)絡,即對輸入圖像并行地執(zhí)行多個卷積運算或池化操作,并將所有輸出結(jié)果拼接為一個非常深的特征圖。由于1×1、3×3 或 5×5 等不同的卷積運算與池化操作可以獲得輸入圖像的不同信息,并行處理這些運算并結(jié)合所有結(jié)果以獲得更好的圖像表征。在同一層級上運行該具備多個尺寸的濾波器,增加了網(wǎng)絡寬度。
2.2 GAP
在卷積神經(jīng)網(wǎng)絡初期,通過卷積池化層后總是需要接一個或幾個全連接層,最后輸入到Softmax層進行分類。其特征是全連接層的參數(shù)非常多,使模型本身變得非常臃腫。Lin等[8]提出使用GAP替代全連接層的思路,該方法取代了擁有大量參數(shù)的全連接層,直接實現(xiàn)了參數(shù)降維。GAP在結(jié)構(gòu)上對整個網(wǎng)絡作正則化進而防止過擬合,允許輸入任意大小的圖像,重新整合空間特征信息,進而使算法擁有更強的魯棒性。
2.3 自適應學習率
在機器學習中,為了得到最優(yōu)權(quán)值,需要構(gòu)建利用代價損失函數(shù),并選用合適的優(yōu)化算法得到最小函數(shù)損失值。本文選用隨機梯度下降算法[13](Stochastic Gradient Descent,SGD)和Adam學習率自適應算法[14]相結(jié)合的方式更新學習速率。
SGD算法在計算下降最快的方向時,每次只隨機選擇一個樣本更新模型參數(shù),而不是掃描全部樣本集。因此加快了迭代速度,計算量也有所降低,并且可以進行在線更新。SGD相關(guān)公式如下:
式中,θ代表參數(shù)權(quán)值,▽θ 代表梯度,J(θ)代表損失函數(shù),α表示學習率。如果學習率過小,算法需要經(jīng)過較多的迭代次數(shù)才能找到最優(yōu)解,收斂速度會大幅度下降,更有可能陷入局部最優(yōu)解。如果學習率過大,雖然會加快訓練速度,但也加大了跳過最優(yōu)解的幾率,可能出現(xiàn)在最優(yōu)解兩側(cè)來回跳躍的情況反而找不到最優(yōu)解。由此可以看出,學習率是決定梯度下降算法是否有效的關(guān)鍵因素。
SGD能夠收斂于最優(yōu)解,但是相對而言它可能花費的時間更長,并且容易陷入局部極小值點,甚至鞍點。為了使學習率更好地適應SGD,本文選擇Adam算法作為自適應學習速率SGD優(yōu)化算法。該算法利用梯度的一階矩陣和二階矩陣動態(tài)調(diào)整參數(shù)學習率、校正后的學習率,使每一次迭代都有一個確定范圍,并且使參數(shù)更新比較平穩(wěn)。θ 參數(shù)更新如式(2)所示。
式中,[v]和[m]分別是對代價函數(shù)求梯度的一階矩陣及二階矩陣。
2.4 改進模型
改進后的網(wǎng)絡模型如圖2所示。設F0(X)=X+η為第一層輸入,F(xiàn)i(X)為第i層輸出,*為卷積操作,Wi和bi 分別表示卷積層的權(quán)重與偏置。
第一層使用Inception模塊,使用包括1×1、3×3、2個3×3共3種不同尺度大小的卷積核增加網(wǎng)絡寬度,提取更多特征,此外還執(zhí)行最大池化,所有子層的輸出最后會被級聯(lián)起來,并傳送至下一個模塊。針對數(shù)據(jù)集較小的情況,決定將層數(shù)降為32層,每種尺度大小的卷積核個數(shù)為8個。其中,W11=3×3×8,W12=3×3×8,W13=1×1×8,W14=1×1×8。
第二層使用VGG網(wǎng)絡的3個卷積池化層,利用Conv+BN+ReLU+maxpool組合,64、128和256個3×3卷積核的卷積層以及2×2池化層,不斷縮小圖像高度和寬度,提高了網(wǎng)絡深度,學習了更深層的更多特征。使用ReLU[15]激活函數(shù),避免梯度消失;增加BN操作進行歸一化,加快網(wǎng)絡訓練。各層輸出表示為:
第三層使用全局平均池化層替代全連接層,有效減少了參數(shù)數(shù)量,可以很好地減輕過擬合發(fā)生。
3 實驗結(jié)果與分析
3.1 實驗平臺與數(shù)據(jù)
實驗選取的數(shù)據(jù)集為手寫數(shù)字識別數(shù)據(jù)集MNIST和一般物體圖像數(shù)據(jù)集CIFAR-10。本文實驗主要在Intel(R)Core(TM)i5-6300HQ CPU2.30 GHz+Nvidia GeForce GTX960M GPU+8G內(nèi)存配置的服務器上進行,另外采用基于Python語言的TensorFlow4.2深度學習框架對不同數(shù)據(jù)庫進行訓練與測試。
3.2 實驗結(jié)果對比
3.2.1 MNIST數(shù)據(jù)集實驗分析
MNIST數(shù)據(jù)集包含訓練樣本60 000個,測試樣本??? 10 000個的手寫數(shù)字圖像,其中每張圖像大小為28×28。設置epoch為100,batch 為200,每個epoch需要訓練100次,總迭代訓練次數(shù)為10 000次。卷積層步長設置為1,池化層步長設置為2,用反向傳播算法調(diào)整網(wǎng)絡權(quán)值,用交叉熵函數(shù)衡量訓練損失,利用自適應學習率對訓練集樣本進行學習提取,采用Adam優(yōu)化算法進行網(wǎng)絡訓練,訓練結(jié)果如表1所示。經(jīng)過 100 次迭代準確率已達到 99.64%,參數(shù)總數(shù)相比也有大幅度減少。
為了進一步驗證模型有效性,與近幾年手寫字符識別方法進行對比,實驗結(jié)果如表2所示。文獻[16]通過減少全連接層參數(shù),識別準確率為99.29%;文獻[17]通過融合卷積神經(jīng)網(wǎng)絡使準確率達到99.10%;文獻[18]通過PCA和K-臨近算法使識別準確率達到99.40%;文獻[19]在隱藏層設置SVM輔助分類器提高學習效率,使識別準確率達到99.61%;文獻[20]通過改進的LeNet-5模型準確率達到99.36%。如表2所示,本文方法識別準確率高于其它文獻方法,降低了手寫數(shù)字識別錯誤率。
3.2.2 CIFAR-10數(shù)據(jù)集實驗結(jié)果分析
網(wǎng)絡模型泛化能力越強,表明模型普適性越強,對未知數(shù)據(jù)集的處理能力就越強;否則,模型泛化能力越差。為了進一步驗證模型有效性,模型繼續(xù)在CIFAR-10數(shù)據(jù)集上進行實驗。CIFAR-10數(shù)據(jù)集由50 000個訓練圖像和10 000個測試圖像組成,共10個類,每個類有6 000個彩色圖像,每張彩色圖像大小為32×32。
用本文提出的模型在數(shù)據(jù)集上進行實驗,與傳統(tǒng)CNN模型進行對比,實驗結(jié)果如表3所示。
表3列出了本文改進卷積神經(jīng)網(wǎng)絡模型在數(shù)據(jù)集上的測試結(jié)果,通過圖4改進模型與傳統(tǒng)CNN模型的損失值對比,可以直觀地看出本文模型在圖像分類識別上的優(yōu)勢,從側(cè)面展示了改進模型在不同圖像識別環(huán)境中具有一定適應能力。
4 結(jié)語
本文根據(jù)VGGNet和Inception模塊,提出了一種卷積神經(jīng)網(wǎng)絡模型,通過加大網(wǎng)絡寬度和深度增強特征提取能力,通過對每層輸入進行Batch Normalization,用Relu激活函數(shù)、SGD自適應學習率算法和Adam優(yōu)化算法加快學習速度,卷積核疊加和全局平均池化層減少了參數(shù)數(shù)量,最后輸入到Softmax層中進行分類。本文在MNIST數(shù)據(jù)集和CIFAR-10數(shù)據(jù)集上與一些傳統(tǒng)CNN模型進行了對比實驗,結(jié)果表明,本文網(wǎng)絡模型在兩個數(shù)據(jù)集上的準確率相對更高,擁有更好的魯棒性和泛化能力。同時,由于實驗中所使用的數(shù)據(jù)集較小,訓練樣本數(shù)量和種類限制對實驗結(jié)果有一定影響。因此下一步工作中,將擴大數(shù)據(jù)集以驗證本模型在圖像分類中的有效性。
參考文獻:
[1]LECUN Y, BOSER B E, DENKER J S, et al. Handwritten digit recognition with a back-propagation network[C]. Advances in neural information processing systems, 1990:396-404.
[2]LECUN Y, BOTTOU L, BENGIO Y, et al. Gradient-based learning applied to document recognition[J]. Proceedings of the IEEE, 1998, 86(11): 2278-2324.
[3]SIMONYAN K,ZISSERMAN A. Very deep convolutional networks for large-scale image recognition[C]. International Conference on Learning Representations, 2015.
[4]HE K M, SUN J. Convolutional neural networks at constrained time cost[C]. Proceedings of Computer Vision and Pattern Recognition, 2015:5353-5360.
[5]HU H, PENG R,TAI Y W, et al. Network trimming: a data-driven neuron pruning approach towards efficient deep architectures[DB/OL]. https://arxiv.org/abs/1607.03250.
[6]JIN Y, KUWASHIMA S, KURITA T, Fast and accurate image super resolution by deep CNN with skip connection and network in network[C]. International Conference on Neural Information Processing, 2017:217-225.
[7]GONG Y, LIU L, YANG M, et al. Compressing deep convolutional networks using vector quantization[DB/OL]. https://arxiv.org/abs/1607.03250.
[8]SZEGEDY C,LIU W,JIA Y Q,et al. Going deeper with convolutions[C].Proceedings of IEEE Conference on Computer Vision and Pattern Recognition,2015:1-9.
[9]LIN M, CHEN Q, YAN S. Network in network[DB/OL]. https://arxiv.org/abs/1607.03250.
[10]YU N, JIAO P, ZHENG Y. Handwritten digits recognition base on improved LeNet5[C]. The 27th Chinese Control and Decision Conference, 2015:4871-4875.
[11]SPRINGENBERG T,DOSOVITSKIY A,BROX T, et al. Striving for simplicity: the all convolutional net[C]. Proceedings of International Conference on Learning Represenation Workshop Track,2015.
[12]SZEGEDY C,VANHOUCKE V,IOFFE S,et al. Rethinking the inception architecture for computer vision[C]. Proceeding of IEEE Conference on Computer Vision and Pattern Recognition,2016:2818-2826.
[13]王功鵬,段萌,牛常勇. 基于卷積神經(jīng)網(wǎng)絡的隨機梯度下降算法[J]. 計算機工程與設計,2018,39(2):441-445,462.
[14]張爍,張榮. 基于卷積神經(jīng)網(wǎng)絡模型的手寫數(shù)字辨識算法研究[J]. 計算機應用與軟件,2019,36(8):172-176,261.
[15]OSHEA K, NASH R. An introduction to convolutional neural networks[DB/OL]. https://arxiv.org/abs/1607.03250,2015.
[16]YANG Z,MOCZULSKI M,DENIL M, et al. Deep fried convnets[C].? Proceedings of the IEEE International Conference on Computer Vision,2015:1476-1483.
[17]陳玄,朱榮,王中元. 基于融合卷積神經(jīng)網(wǎng)絡模型的手寫數(shù)字識別[J]. 計算機工程, 2017(11):187-192.
[18]顧潘龍,史麗紅. 基于PCA及k-鄰近算法的復雜環(huán)境數(shù)字手寫體識別[J]. 電子技術(shù),2018, 47(10):44-48.
[19]LEE C Y, XIE S, GALLAGHER P, et al. Deeply-supervised nets[C].? Artificial Intelligence and Statistics, 2015:562-570.
[20]王秀席,王茂寧,張建偉,等. 基于改進的卷積神經(jīng)網(wǎng)絡LeNet-5的車型識別方法[J]. 計算機應用研究, 2018, 35(7): 301-304.
(責任編輯:孫 娟)
收稿日期:2019-11-14
作者簡介:齊廣華(1993-),男,山東科技大學計算機科學與工程學院碩士研究生,研究方向為智能信息處理技術(shù);何明祥(1969-),男,山東科技大學計算機科學與工程學院副教授,研究方向為數(shù)據(jù)庫系統(tǒng)、信息處理、人工智能、數(shù)字礦山。本文通訊作者:齊廣華。
