
Spark平臺加權分層子空間隨機森林算法研究
2020-05-28 09:36:21荊靜祝永志
軟件導刊 2020年3期
荊靜 祝永志


摘 要:如何在各式大數據中更快更準確地挖掘有用信息是研究熱點。隨機森林算法作為一種重要的機器學習算法,適用于大部分數據集。隨機森林算法可以并行運行,這是隨機森林算法處理大數據集時的優勢。將隨機森林算法應用在大數據處理框架Spark上,提高了隨機森林算法處理大數據集時的速度。首先對隨機森林進行參數調優,找到當前數據集的最優參數組合,采用隨機森林模型對特征進行重要度計算,篩選掉噪聲數據;然后采用卡方檢驗對數據集的特征進行分層,實現分層子空間隨機森林并驗證準確率和袋外精度;最后在傳統分層子空間隨機森林基礎上對分層子空間進行加權改進。實驗證明改進后的隨機森林算法準確率提高了3%,袋外估計精度提高了1%。
關鍵詞:隨機森林;Spark;大數據處理;特征選擇
DOI:10. 11907/rjdk. 191691
中圖分類號:TP312 ? 文獻標識碼:A ??????????????? 文章編號:1672-7800(2020)003-0120-05
Research of Random Forest Algorithm Using Weighted Stratified Subspace
Based on Spark Platform
JING Jing,ZHU Yong-zhi
(School of Information Science and Engineering,Qufu Normal University,Rizhao 276826,China)
Abstract:How to find useful information out of all kinds of big data faster and more accurately becomes an import problem in the time. As an important machine learning algorithm, random forest algorithm is flexible and suitable for most data sets. The random forest algorithm can run in parallel,this is an advantage when dealing with large data sets. The application of random forest algorithm to big data processing framework Spark can greatly improve the speed of running and processing big data of random forest algorithm. Firstly,the parameter of the random forest were optimized to find the optimal combination of parameters of the current data set. The importance of features are calculated to delete the useless feature by random forest model. Then, chi-square test is used to stratify the features of the data set to achieve the verification accuracy and out-of-bag accuracy of random forest using stratified subspace. Finally, on the basis of the traditional random forest using stratified subspace, the stratified subspace is improved by weighting. The experimental results show that the improved random forest algorithm improves the prediction accuracy by 3% and the out-of-bag estimation accuracy by 1%.
Key Words:random forest; Spark; big data processing; feature selection
0 引言
大數據具有數據量大、類型多樣和價值密度低等特點,如何在大數據中快速且準確地挖掘信息成為亟待解決的問題。決策樹算法作為一種經典的數據挖掘算法,既可作為分類算法,又可作為回歸算法,但是單一的決策樹在處理數據時容易產生過擬合問題,因此在2001年出現了隨機森林算法。對運行在單機上的隨機森林算法研究已經相對成熟,近年來的研究是將隨機森林并行運行以提高其性能。Apache Spark是大數據機器學習中最受歡迎的平臺之一,它受益于分布式架構和自動數據并行化。Apache Spark MLlib為各種機器學習任務提供支持,包括回歸、降維、分類、聚類和規則提取[1]。
文獻[2]將隨機森林算法應用在Spark平臺,并在投票時根據不同決策樹預測準確度對其進行加權,有效提高了算法準確度。但是對于具有高維特征的大數據,隨機森林在處理數據時運行時間過長,而且噪聲數據也會對結果準確率產生影響;文獻[3]在Spark平臺上運用隨機森林算法進行特征選擇,對冗余數據和噪聲數據進行篩選,并采用方差分析和后向序列選擇進行降維,提高了隨機森林算法的準確度。但方差分析和后向序列選擇方法在進行特征篩選時,要自身把握度量標準,因而容易將有用特征刪除;文獻[4]針對不平衡大數據提出一種啟發式自舉抽樣方法,結合保險大數據在Spark平臺上實驗,證明具有良好性能。但其只針對保險大數據集進行改進,只對某一類大數據集有效;文獻[5]提出了一種基于Flayed邊界點的隨機森林算法,這種算法在處理具有離散連續屬性的樣本時可降低時間復雜度;文獻[6]提出了基于粗糙集的隨機森林算法,將粗糙集理論應用于特征選擇中,但是仍然無法完全消除噪聲數據的影響;文獻[7]提出用分層子空間方式處理高維大數據,將特征分為強特征層和弱特征層,然后在不同的特征層進行取樣,預測結果準確率有一定提高。但是其對不同層采用了等比例方式進行采樣,也容易產生噪聲數據。本文首先在Spark平臺上對隨機森林算法進行參數調優,采用特征評估方法對特征進行重要度計算,并刪除噪聲特征,然后對傳統分層子空間進行實驗,驗證其準確率。針對傳統分層子空間等比例抽樣所得結果受噪聲數據影響較大從而影響準確度的不足,對分層子空間進行加權,并對加權分層子空間隨機森林的準確率與原始分層子空間隨機森林算法準確率進行比較,發現加權抽樣時所得結果最優。實驗證明經過加權的隨機森林算法準確率提升了3%,袋外估計準確率也有提升。
1 隨機森林算法
隨機森林(Random Forest,RF)是一種組合分類器,它首先訓練多棵決策樹,訓練完成后將其組合成隨機森林模型,然后運用隨機森林模型進行預測。隨機森林應用廣泛,如用于預測疾病風險[8]、遙感社區[9]和保險[10]等等。
1.1 決策樹
決策樹(decision tree)指以樹的形式進行分類預測的模型。決策樹在節點劃分時就是要尋找一種最純凈的劃分方法,在數學中稱之為純度,分裂屬性使得孩子節點的數據劃分得最純。
1.1.1 熵
熵(entroy)表示數據的混亂程度,熵與混亂程度呈正比,熵變大時混亂程度也變高。
定義1:對類別為隨機變量X的樣本集合D,假設X有k個類別,每個類別的概率為[CkD],其中[Ck]表示類別k的樣本個數,[D]表示樣本總數,則樣本集合D的熵公式如下:
1.1.2 基尼值
定義2:設[pi]為類別i在樣本D中出現的概率,基尼指數公式如下:
基尼指數被定義用來衡量節點純度,基尼指數與純度成反比關系,即基尼指數變大時節點純度會變低。
決策樹理解起來比較簡單,但是它可能會出現過度分割樣本空間問題,導致決策樹算法復雜度很高,并且會出現過擬合。為了解決這些問題,針對決策樹缺點提出隨機森林算法。隨機森林算法是對決策樹算法的一種集成,可以有效避免過擬合。
1.2 隨機森林
定義3:假設數據集為D={Xi,Yj},Xi∈R,Yi∈{1,2,…,C},隨機森林是在數據集上以M個決策樹{g(D,θm},m=1,2,…,M}為基分類器進行集成學習后得到的一個組合分類器。
隨機森林算法創建過程分為3個步驟:①劃分訓練樣本子集;②訓練隨機森林;③預測。隨機森林算法的隨機性體現在它不僅在取樣時采用隨機取樣,在特征選擇時也是隨機抽取,然后從中采用最佳屬性進行分裂。
1.2.1 卡方檢驗
卡方檢驗是衡量兩個變量相關性的一種檢驗方法[11]。
定義4:對于數據集D,使用[X={x1,?,xk}]表示樣本,使用[Y={y1,?,yq}]表示類別,使用[A={A1,?,AM}]表示特征,而對于每一個特征,假設特征[Ai]有p個不同取值,當[Ai=al]時, [Y=yj(j=1,?,q)]的D子集大小為[vallj],特征[Ai]與類別之間的信息量公式如下:
其中,[vallj]為觀察頻數,即表示為實際發生的頻數,[tlj]為期望頻數。期望函數取值為:
特征和類別之間的相關性越強,特征分類新事物的能力也越強,因此將卡方檢驗應用在隨機森林算法的特征選擇中,檢測特征與類別之間的關系。根據相關性將特征劃分為強特征和弱特征層,在進行特征選擇時在不同層進行抽樣,增強單棵樹的分類強度,不增加樹之間的相關性。
傳統的分層子空間隨機森林算法在不同層進行等比例取樣,能保證結果最優。
1.2.2 隨機森林特征評估
大數據價值很高,但也有許多問題,其中最重要的是降維,特別是特征選擇[12]。對高維樣本進行降維方法有多種,如T-test檢測、序列后向選擇[13]等,本文采用隨機森林模型進行特征篩選,特征評估衡量標準為Gini指數變化量。
定義5:特征Xi在節點m上的重要性即節點m分枝前后的Gini指數變化量,其公式如下:
其中GIl和GIr分別表示以特征m進行分裂后左右兩個孩子節點的Gini指數。
在使用卡方檢驗將特征子空間分層后,對每個特征進行特征評估得到一個評估值,對層內每個特征的重要度進行累加得到層的權重。
定義6:設每層有r個特征[Ai](i=1,…r),定義層權重公式為:
1.2.3 袋外估計
袋外數據(OOB,out-of-bag)即未被抽取到的訓練數據[14]。對隨機森林每棵樹而言,建樹時采用隨機并且有放回地進行抽取,所以每棵樹大約有1/3的數據未被抽到,這些數據稱為袋外數據。因為未參與建模過程,因此用這些數據對隨機森林模型進行評估結果較為可信。
使用袋外數據進行評估得到的正確率稱為袋外正確率。袋外估計可以作為泛化誤差估計的一部分,使得隨機森林算法不再需要交叉驗證。
1.3 隨機森林算法特點
現實生活中的大多數數據分析都是分類和回歸問題,而隨機森林算法既可作為分類算法,又可作為回歸算法。近年來隨機森林算法廣受歡迎,應用在各種領域,如銀行、股票市場和醫藥行業等等。隨機森林在處理各種問題時發揮著強大的優勢,它的優點主要有:①具有良好的準確率;②訓練速度快,能夠運行在大數據集上;③能夠處理高維特征樣本;④可以評估特征在模型中的重要程度;⑤可以在模型生成過程中取得真實誤差的無偏統計;⑥容易并行化。
2 Spark
2.1 Spark介紹
因為數據量超過了單機所能處理的極限,所以用戶需要新的架構將計算擴展到多個節點進行,以應對不同工作負載的新集群編程模型數量的飛速增長[15]。Spark自2010年發布以來已成為最活躍的大數據處理計算引擎,廣泛應用在金融、生物技術和天文學等多個領域[16]。
Spark基于彈性分布式數據集(RDD)[17]。RDD是一種可并行計算的集合,它不可變并且可被分區,可以由存儲的數據或其它RDD生成,是最基本的數據抽象。RDD?有轉化和行動兩種類型操作,轉化操作主要由一個已知RDD轉化為一個新的RDD。行動操作在應用一組操作后將記錄/值返回給主程序。這兩個操作之間的主要區別在于它們何時以及如何應用于數據。
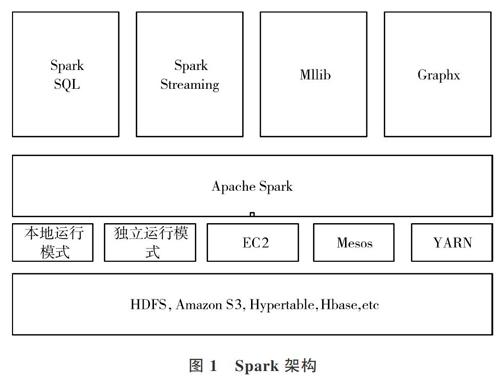
Spark提供一系列組件支持數據處理。Spark shell提供多個API使得交互式數據分析更方便快捷。Spark SQL提供交互式查詢。Spark streaming用于處理實時數據組件,提供流式數據計算;Mllib庫支持數據分析等,包含大量機器學習算法[18];GraphX對圖計算提供支持。這些組件提供給用戶的都是jar包,使用時無需部署、維護等復雜操作,在Spark平臺上可直接使用,充分體現了Spark的通用性。Spark可以獨立安裝使用,也可與其它平臺配合使用。Spark架構如圖1所示。
2.2 基于Spark的隨機森林算法
由于隨機森林算法基于多個獨立樹定義,因此可以直接并行隨機森林方法并更快地將其實現,其中許多樹在不同的核上并行構建[19]。隨機森林模型如圖2所示。
基于Spark的隨機森林建模過程:①從hdfs讀取訓練數據集并將其設置為廣播變量,壓縮為一個forest列表;②將不同的訓練樣本子集分發給不同的從機進行決策樹訓練。主機從各個從機收集訓練完成的子森林組合成隨機森林,將測試集分成一定大小的塊并分發給從機進行預測,主機收集并返回預測結果。
基于Spark平臺的隨機森林主要對訓練過程和預測過程進行并行化[20],這樣不僅增大了可處理的數據量,也加快了運行速度。
3 實驗
3.1 實驗數據與環境
本文采用Semeion手寫字數據集,該數據每個記錄代表一個手寫字,有256個特征。實驗環境為Windows上的ubuntu虛擬hadoop集群,集群包含3個節點,采用HDFS存儲文件,集群管理器為YARN,編程語言為Python。
3.2 實驗結果與分析
將數據集以7∶3拆分為訓練集和測試集。對隨機森林進行參數調優,包括控制樹的數量和選擇合適的特征比例兩個方面,實驗準確率如圖3所示。
分別選取隨機森林規模為10,50和100,特征選取比例分別為0.1,0.5和0.8進行實驗。從實驗結果可以看出,當特征比選為0.5時,隨機森林預測準確度達到最高,當特征比例選擇更大時,準確率不升反降,此時準確率可能受到噪聲數據的影響。對隨機森林規模選取進行測試,發現隨著隨機森林規模的變大準確率也會上升,但對于當前數據而言,隨機森林規模在50和100的準確率并未增長,反而增加了程序運行時間,所以對特定數據集選取合適的森林規模對算法性能有很重要的影響。
對數據集進行特征評估操作,將評估結果歸一化,對每個特征評估出一個重要度,所有特征重要度相加為1,計算出一些特征為0的噪聲特征,將這些特征刪除。有效降維使算法的準確度和運行時間都有提升,有利于提升算法性能。
降維后開始進行分層子空間隨機森林實驗。該實驗分3組進行,分別為:①強弱特征層等比例抽樣;②僅在強特征層抽樣;③僅在弱特征層抽樣。驗證3組實驗結果準確率,如圖4所示。
從實驗結果可以看出,強特征層和弱特征層的結果相差較大,在強特征層進行抽樣時的實驗結果優于等比例抽樣,所以在強弱特征層進行等比例抽樣算法有待優化。
對不同層進行特征重要度計算,然后記為層重要度,根據重要度比例進行抽樣,實驗結果與原始結果對比見圖5。
從實驗結果可以看出,加權后的分層子空間隨機森林算法較原始隨機森林算法準確度有所提升,袋外準確度也有提升。
由以上實驗可知,優化后的隨機森林算法預測精度有一定提升,有效降維減少了算法運行時間,提高了算法性能。將優化后的隨機森林算法應用在Spark平臺上,可對大數據進行高效處理。
4 結語
本文首先對隨機森林進行參數調優,找到最合適的參數組合。在調參過程中發現過大的特征比使噪聲對隨機森林準確率有明顯影響;然后使用隨機森林模型對數據集進行特征評估,去除掉一些噪聲數據,對篩選后的特征進行卡方檢驗操作,將特征分為強弱特征層;分層后對不同層進行權重計算,按照權重比例取樣,訓練隨機森林模型,進行分類預測。實驗結果表明隨機森林預測準確度明顯提升,袋外正確率也有一定提升。
本文在進行特征分層時沒有考慮冗余數據影響,因為特征維度較大,冗余數據的計算量也較大。下一步將研究一種優化的冗余特征處理方式。
參考文獻:
[1]ASSEFI M,BEHRAVESH E. Big data machine learning using Apache Spark MLLIB[C]. 2017 IEEE International Conference on Big Data (Big Data).? IEEE, 2017: 3492-3498.
[2]CHEN J, LI K, TANG Z, et al. A parallel random forest algorithm for big data in a spark cloud computing environment[J]. IEEE Transactions on Parallel and Distributed Systems, 2017, 28(4): 919-933.
[3]SUN K, MIAO W, ZHANG X, et al. An improvement to feature selection of random forests on spark[C]. 2014 IEEE 17th International Conference on Computational Science and Engineering,2014:774-779.
[4]DEL RíO S, LóPEZ V, BENíTEZ J M, et al. On the use of mapreduce for imbalanced big data using random forest[J]. Information Sciences, 2014(285): 112-137.
[5]XY Y. Research and implementation of improved random forest algorithm based on spark[C]. 2017 IEEE 2nd International Conference on Big Data Analysis,2017: 499-503.
[6]羅元帥.? 基于隨機森林和Spark的并行文本分類算法研究[D]. 成都:西南交通大學,2016.
[7]牛志華.? 基于Spark分布式平臺的隨機森林分類算法研究[D]. 天津:中國民航大學,2017.
[8]KHALILIA M,CHAKRABORTY S,POPESCU M. Predicting disease risks from highly imbalanced data using random forest[J].? BMC Medical Informatics and Decision Making, 2011, 11(1): 51-59.
[9]BELGIU M,DRAGUT L.Random forest in remote sensing: a review of applications and future directions[J]. ISPRS Journal of Photogrammetry and Remote Sensing, 2016(114): 24-31.
[10]LIN W, WU Z, LIN L, et al. An ensemble random forest algorithm for insurance big data analysis[J]. IEEE Access, 2017(5): 16568-16575.
[11]張思琪. 基于改進貝葉斯分類的Android惡意軟件檢測[J]. 無線電通信技術,2014,40(6):73-76.
[12]DAGDIA Z C, ZARGES C,BECK G,et al. A distributed rough set theory based algorithm for an efficient big data pre-processing under the Spark framework[C]. 2017 IEEE International Conference on Big Data (Big Data).? IEEE, 2017: 911-916.
[13]RUAN F, QI J, YAN C, et al. Quantitative detection of harmful elements in alloy steel by LIBS technique and sequential backward selection-random forest (SBS-RF)[J]. Journal of Analytical Atomic Spectrometry,2017,32(11): 2194-2199.
[14]馬曉東. 基于加權決策樹的隨機森林模型優化[D]. 武漢:華中師范大學,2017.
[15]ZAHARIA M, XIN R S, WENDELL P, et al. Apache Spark: a unified engine for big data processing[J]. Communications of the ACM, 2016, 59(11): 56-65.
[16]梁彥.? 基于分布式平臺Spark和YARN的數據挖掘算法的并行化研究[D]. 廣州:中山大學,2014.
[17]遲玉良,祝永志. 項目相似度與ALS結合的推薦算法研究[J]. 軟件導刊,2018,17(6):81-84.
[18]唐振坤. 基于Spark的機器學習平臺設計與實現[D]. 廈門:廈門大學,2014.
[19]GENUER R,POGGI J M,TULEAUL C, et al. Random forests for big data[J].? Big Data Research, 2017(9): 28-46.
[20]孫科.? 基于Spark的機器學習應用框架研究與實現[D]. 上海:上海交通大學,2015.
(責任編輯:杜能鋼)
收稿日期:2019-05-13
基金項目:山東省自然科學基金項目(ZR2013FL015);山東省研究生教育創新資助計劃項目(SDYY12060)
作者簡介:荊靜(1995-),女,曲阜師范大學信息科學與工程學院碩士研究生,研究方向為分布式計算、大數據;祝永志(1964-),男,曲阜師范大學信息科學與工程學院教授、碩士生導師,研究方向為并行與分布式計算、網絡數據庫。
