基于改進(jìn)萬有引力算法的KELM瓦斯涌出量預(yù)測(cè)
2020-06-02 04:42:14王居堯王凱君
煤 2020年5期
關(guān)鍵詞:模型
王居堯,王凱君
(潞安礦業(yè)集團(tuán)公司,山西 長(zhǎng)治 046204)
瓦斯涌出異常特征對(duì)煤礦瓦斯等災(zāi)害預(yù)警指標(biāo)的研究具有極其重要的理論與實(shí)際意義。陳亮[1]對(duì)河南、貴州等地的礦井掘進(jìn)期間的瓦斯涌出規(guī)律進(jìn)行分析發(fā)現(xiàn),掘進(jìn)工作面瓦斯涌出受掘進(jìn)速度、地質(zhì)構(gòu)造、瓦斯含量、煤層厚度及煤體強(qiáng)度等影響十分顯著,導(dǎo)致瓦斯涌出表現(xiàn)出多種動(dòng)態(tài)特征。目前,很多非線性的瓦斯涌出量預(yù)測(cè)方法得到應(yīng)用,并且顯示出了較好的性能。比如,神經(jīng)網(wǎng)絡(luò)法、灰色系統(tǒng)法、遺傳規(guī)劃法、基因表達(dá)式程序設(shè)計(jì)法[2]等。但是對(duì)于這種非線性系統(tǒng)預(yù)測(cè)問題,預(yù)測(cè)模型規(guī)模急劇增大,運(yùn)行時(shí)間變長(zhǎng),而且瓦斯涌出量受到的影響因素多且具有一定的相關(guān)性[3],存在復(fù)雜非線性和大量擾動(dòng)成分,導(dǎo)致輸入信息存在重疊部分和無效的干擾成分[4],降低預(yù)測(cè)模型的準(zhǔn)確度。
考慮眾多復(fù)雜的影響因素最終的作用結(jié)果都會(huì)體現(xiàn)在綜采工作面瓦斯?jié)舛葦?shù)據(jù)上,最后會(huì)形成一個(gè)具有時(shí)序性的隨機(jī)過程,瓦斯參量時(shí)間序列信息必然按照其數(shù)據(jù)順序和數(shù)據(jù)大小蘊(yùn)含大量有關(guān)系統(tǒng)動(dòng)態(tài)演化過程的痕跡和特征信息[5]。瓦斯參量時(shí)間序列中先前狀態(tài)的信號(hào)特征必然包含其后續(xù)狀態(tài)發(fā)展變化的趨勢(shì)特征信息。近年來,很多學(xué)者已經(jīng)把時(shí)間序列分析方法應(yīng)用到礦井瓦斯相關(guān)參量的預(yù)測(cè)問題中,如王栓林等[6]對(duì)煤礦安全監(jiān)控系統(tǒng)采集的瓦斯?jié)舛刃蛄羞M(jìn)行分析,運(yùn)用時(shí)間序列分析法建立了突出危險(xiǎn)前兆信息獲取模型;黃凱峰[7]提出了煤礦安全監(jiān)測(cè)監(jiān)控系統(tǒng)瓦斯?jié)舛犬惓P盘?hào)辨識(shí)算法,建立了安全監(jiān)測(cè)監(jiān)控系統(tǒng)瓦斯?jié)舛犬惓P盘?hào)模型。本文提出將核極端學(xué)習(xí)機(jī)(Extreme Learning Machine with Kernels,KELM)以及萬有引力算法(Gravitational Search Algorithm,GSA)相結(jié)合建立瓦斯涌出量預(yù)測(cè)模型,在結(jié)合方式和算法方面進(jìn)行了優(yōu)化改進(jìn),提高預(yù)測(cè)模型的預(yù)測(cè)精度和預(yù)測(cè)效率,為瓦斯涌出量預(yù)測(cè)提供研究依據(jù),為煤礦瓦斯災(zāi)害的防治提供新的方法,提高煤礦瓦斯災(zāi)害的防治水平。
核極端學(xué)習(xí)機(jī)網(wǎng)絡(luò)因?yàn)橐肓撕撕瘮?shù),所以無需設(shè)定隱含層節(jié)點(diǎn)數(shù),但是需要確定核函數(shù),而核函數(shù)的參數(shù)對(duì)核極端學(xué)習(xí)機(jī)的性能有很大影響,核極端學(xué)習(xí)機(jī)不能自動(dòng)設(shè)定核參數(shù)[8],需要人為設(shè)定,故本文采用改進(jìn)的萬有引力算法對(duì)核極端學(xué)習(xí)機(jī)的核參數(shù)進(jìn)行尋優(yōu),以確保核極端學(xué)習(xí)機(jī)的性能最優(yōu)。將核極端學(xué)習(xí)機(jī)與改進(jìn)的萬有引力算法相結(jié)合建立基于改進(jìn)萬有引力算法—KELM的瓦斯涌出量預(yù)測(cè)模型(IGSA-KELM瓦斯涌出量預(yù)測(cè)模型)。首先將輸入樣本作為KELM網(wǎng)絡(luò)的輸入量,然后采用改進(jìn)的萬有引力搜索算法對(duì)KELM網(wǎng)絡(luò)的核參數(shù)和輸出權(quán)值尋優(yōu),優(yōu)化KELM網(wǎng)絡(luò)的性能。
1 萬有引力算法基本理論及改進(jìn)方法
萬有引力搜索算法(Gravitational Search Algorithm,GSA)[9-10]是受物理學(xué)中牛頓引力理論啟發(fā)而提出的一種元啟發(fā)式算法,具備全局優(yōu)化能力強(qiáng)、流程簡(jiǎn)單易行等優(yōu)點(diǎn),在非線性問題的處理中更能凸顯其優(yōu)越性。萬有引力算法會(huì)高效的搜尋到核極端學(xué)習(xí)機(jī)的最優(yōu)參數(shù),提高模型的預(yù)測(cè)精度和效率。但是其仍然存在易陷入局部極值和早熟收斂的缺陷,故本文對(duì)萬有引力算法進(jìn)行改進(jìn),以提高算法的尋優(yōu)性能,滿足瓦斯涌出量預(yù)測(cè)的需求。
1.1 核極端學(xué)習(xí)機(jī)
極端學(xué)習(xí)機(jī)[11-12](Extreme Learning Machine,ELM) 是一種單隱層前饋神經(jīng)網(wǎng)絡(luò) (Single-hidden Layer Feedforward Neural Networks,SLFNs),由Huang G.B等人在2004年用來解決回歸問題時(shí)提出的,主要針對(duì)傳統(tǒng)神經(jīng)網(wǎng)絡(luò)方法訓(xùn)練速度慢、反向感知機(jī)(Back Propagation,BP)網(wǎng)絡(luò)效率低且易陷入局部極值等問題而提出的。把迭代求解隱層輸出權(quán)值的方式變?yōu)榍蠼饩€性方程組的方式[13],克服了傳統(tǒng)機(jī)器學(xué)習(xí)算法的缺陷,提供更好的整體性能,更快地學(xué)習(xí)速度和更低的計(jì)算成本。KELM引入了非線性映射效果更好的核函數(shù)理論,具有更加強(qiáng)大的函數(shù)逼近能力,通過設(shè)定合適的核參數(shù),能夠提高算法的穩(wěn)定性和識(shí)別率,具備更高的精度,更快地學(xué)習(xí)速度和更強(qiáng)大的泛化能力。
核極端學(xué)習(xí)機(jī)在極端學(xué)習(xí)機(jī)的基礎(chǔ)上引入了核函數(shù),雖然解決了極端學(xué)習(xí)機(jī)對(duì)隱含層節(jié)點(diǎn)數(shù)選擇、初始權(quán)值和閾值設(shè)定的隨機(jī)性等問題,降低了算法的不穩(wěn)定性,提高了算法的預(yù)測(cè)精度和效率,但是核極端學(xué)習(xí)機(jī)也因此增加了對(duì)核參數(shù)的依賴性,只有選定合適的核參數(shù)才可以保證核極端學(xué)習(xí)機(jī)的穩(wěn)定性和預(yù)測(cè)的精度及效率。本文采用改進(jìn)的萬有引力算法來優(yōu)化核極端學(xué)習(xí)機(jī),對(duì)核極端學(xué)習(xí)機(jī)的核參數(shù)和輸出權(quán)值進(jìn)行尋優(yōu),以提高本文建立模型對(duì)瓦斯涌出量預(yù)測(cè)的精度和速度。
1.2 萬有引力算法原理
萬有引力算法模仿了物體間的萬有引力作用,用于解決優(yōu)化問題,主要包含四個(gè)特征屬性:粒子位置、慣性質(zhì)量、主動(dòng)引力質(zhì)量以及被動(dòng)引力質(zhì)量。粒子位置向量由所要尋優(yōu)的參數(shù)構(gòu)成,質(zhì)量最大的粒子位置最好,即是所要尋優(yōu)參數(shù)的最優(yōu)解。
萬有引力算法的流程如圖1所示。
1.3 萬有引力算法的改進(jìn)
萬有引力算法具備全局優(yōu)化能力強(qiáng)、流程簡(jiǎn)單易行等優(yōu)點(diǎn),在實(shí)際問題中能得到很好的運(yùn)用,在非線性問題的處理中更能凸顯其優(yōu)越性,已經(jīng)成功應(yīng)用于工程和其他領(lǐng)域的許多問題中,但是作為智能算法的一員,萬有引力算法也存在易陷入局部極值和早熟收斂的缺陷。為克服上述缺點(diǎn),采用反向?qū)W習(xí)機(jī)制(Opposition Based Learning, OBL)來初始化GSA的初始種群,使初始種群分布更加均勻,引入Tent混沌映射提高種群的多樣性,促進(jìn)GSA算法的探索與開發(fā)能力。
OBL生成初始種群的步驟如下:①確定初始種群個(gè)數(shù)為隨機(jī)生成初始種群(即第一組候選解),計(jì)算每個(gè)個(gè)體的適應(yīng)度值;②生成反向估計(jì)值,得到第二組候選解并適應(yīng)度值;③將兩組候選解按照個(gè)體適應(yīng)度值的大小排序,取前個(gè)粒子構(gòu)成問題的解空間,即GSA初始種群。
TENT混沌映射產(chǎn)生混沌序列步驟如下:①將種群迄今搜索到的最優(yōu)解歸一化到(0,1)區(qū)間內(nèi),令其等于初值x0,即k=0;②迭代產(chǎn)生混沌序列X,k自增1;③當(dāng)達(dá)到最大迭代次數(shù)時(shí)則停止迭代,保存X序列;④將序列X反歸一化載波到原解空間,得到新解;⑤比較新舊解的適應(yīng)度值,留下性能更好的解。
2 基于改進(jìn)萬有引力算法的KELM瓦斯涌出量預(yù)測(cè)模型
目前,對(duì)于核參數(shù)和輸出權(quán)值還沒有具體且有效的設(shè)定依據(jù),故采用改進(jìn)的萬有引力搜索算法來智能選取最佳的核參數(shù)和輸出權(quán)值,對(duì)KELM神經(jīng)網(wǎng)絡(luò)進(jìn)行優(yōu)化,以保證模型預(yù)測(cè)的準(zhǔn)確性。
將核極端學(xué)習(xí)機(jī)與改進(jìn)的萬有引力算法相結(jié)合建立基于改進(jìn)萬有引力算法—KELM的瓦斯涌出量預(yù)測(cè)模型(IGSA-KELM瓦斯涌出量預(yù)測(cè)模型)。首先將輸入樣本作為KELM網(wǎng)絡(luò)的輸入量,然后采用改進(jìn)的萬有引力搜索算法對(duì)KELM網(wǎng)絡(luò)的核參數(shù)和輸出權(quán)值尋優(yōu),優(yōu)化KELM網(wǎng)絡(luò)的性能。
基于改進(jìn)萬有引力算法—KELM的瓦斯涌出量預(yù)測(cè)模型的主要流程如下:①搜集整理數(shù)據(jù),得到原始輸入樣本數(shù)據(jù);②按照貢獻(xiàn)率確定P個(gè)主成分,主成分個(gè)數(shù)P等于KELM網(wǎng)絡(luò)的輸入節(jié)點(diǎn)個(gè)數(shù),初始化核極端學(xué)習(xí)機(jī);③利用改進(jìn)的萬有引力搜索算法對(duì)KELM網(wǎng)絡(luò)的核參數(shù)和輸出權(quán)值進(jìn)行尋優(yōu),將尋優(yōu)結(jié)果映射到網(wǎng)絡(luò)模型的核參數(shù)和輸出權(quán)值;④將訓(xùn)練集作為KELM網(wǎng)絡(luò)的輸入訓(xùn)練核極端學(xué)習(xí)機(jī);⑤計(jì)算網(wǎng)絡(luò)誤差,若滿足條件,繼續(xù)步驟⑥,否則返回步驟③;⑥將測(cè)試集輸入到核極端學(xué)習(xí)機(jī),進(jìn)行測(cè)試分析。
3 瓦斯涌出量預(yù)測(cè)應(yīng)用效果分析
采用某煤礦的實(shí)際數(shù)據(jù)(18個(gè)樣本)進(jìn)行實(shí)驗(yàn)分析。由于影響瓦斯涌出量的因素很多,這里選取了掘進(jìn)工作面瓦斯絕對(duì)涌出量的13個(gè)影響因素,分別是煤層瓦斯含量(X1)、煤層深度(X2)、煤層厚度(X3)、煤層傾角(X4)、采高(X5)、工作面長(zhǎng)度(X6)、推進(jìn)速度(X7)、工作面采出率(X8)、鄰近層瓦斯含量(X9)、鄰近層厚度(X10)、層間距(X11)、層間巖性(X12)、開采強(qiáng)度(X13),將這些影響因素作為瓦斯涌出量的特征指標(biāo),用主成分分析法對(duì)這13個(gè)影響因素的樣本數(shù)據(jù)進(jìn)行處理,并結(jié)合改進(jìn)的萬有引力算法建立基于IGSA-KELM的瓦斯涌出量預(yù)測(cè)模型,實(shí)現(xiàn)對(duì)掘進(jìn)工作面的絕對(duì)瓦斯涌出量Y的預(yù)測(cè)。部分實(shí)驗(yàn)數(shù)據(jù)如表1所示。
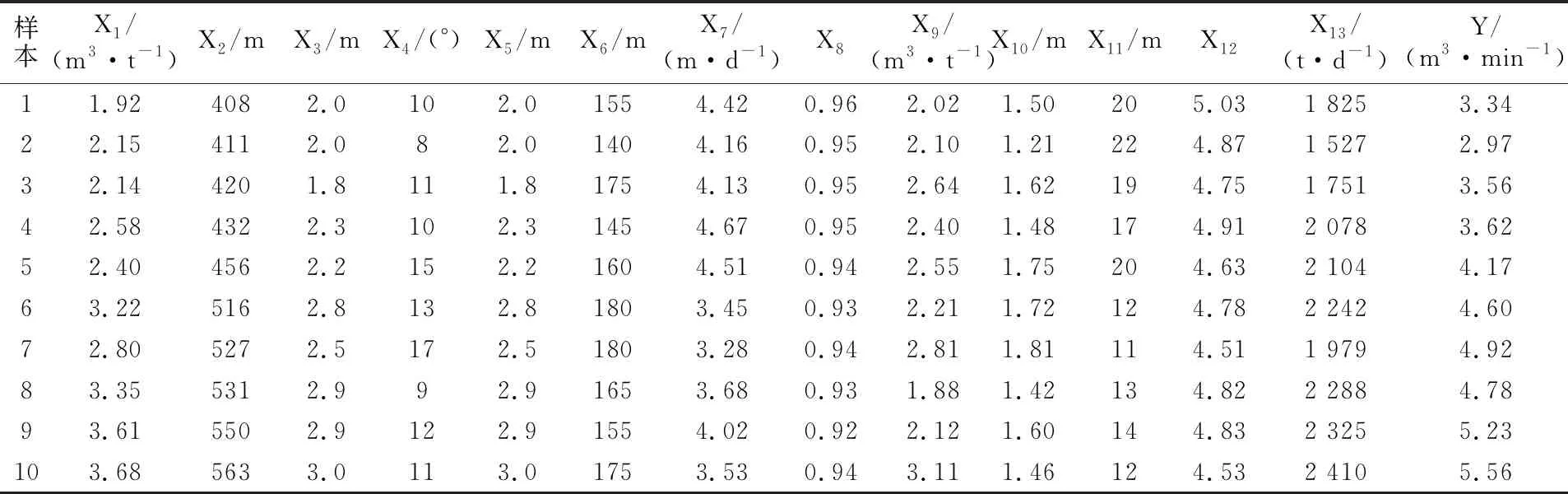
表1 瓦斯涌出量影響因素原始數(shù)據(jù)
3.1 數(shù)據(jù)標(biāo)準(zhǔn)化處理

表2 原始數(shù)據(jù)平均值和標(biāo)準(zhǔn)差
3.2 主成分的確定
根據(jù)主成分分析的步驟,數(shù)據(jù)標(biāo)準(zhǔn)化處理后,要求出協(xié)方差矩陣及其特征根和特征向量,根據(jù)方差貢獻(xiàn)率確定主成分。特征根的計(jì)算結(jié)果如表3所示。
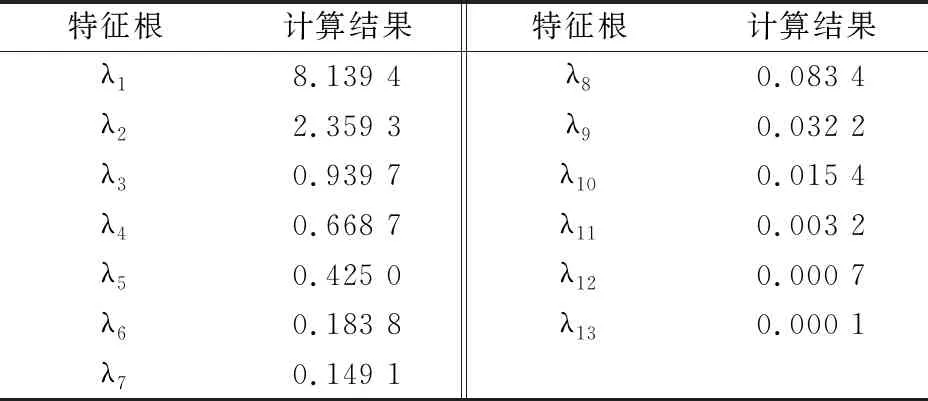
表3 特征根計(jì)算結(jié)果
本文選取前五個(gè)主元作為KELM網(wǎng)絡(luò)的輸入向量。
3.3 KELM網(wǎng)絡(luò)參數(shù)的確定
網(wǎng)絡(luò)模型共有三層:一個(gè)輸入層,一個(gè)隱含層,一個(gè)輸出層。上節(jié)根據(jù)主成分分析選定五個(gè)主成分,因此設(shè)定KELM網(wǎng)絡(luò)有五個(gè)輸入節(jié)點(diǎn),分別對(duì)應(yīng)五個(gè)主成分。KELM網(wǎng)絡(luò)模型的目的是預(yù)測(cè)瓦斯涌出量,因此本文有一個(gè)輸出節(jié)點(diǎn),即瓦斯涌出量。將確定主成分后的18個(gè)樣本的前15個(gè)作為訓(xùn)練集,后3個(gè)作為測(cè)試集。將15個(gè)訓(xùn)練樣本及其結(jié)果輸入到模型中進(jìn)行訓(xùn)練,同時(shí)建立GSA-KELM和PSO-KELM瓦斯涌出量預(yù)測(cè)模型,將這三種模型進(jìn)行比較,用測(cè)試樣本來驗(yàn)證所建立模型的預(yù)測(cè)效果。
圖2為三種模型的瓦斯涌出量預(yù)測(cè)值與實(shí)際值的對(duì)比曲線。

圖2 瓦斯涌出量預(yù)測(cè)值與實(shí)際值對(duì)比
由圖2可以看出,三種模型總體的預(yù)測(cè)都相對(duì)比較準(zhǔn)確。但I(xiàn)GSA-KELM的預(yù)測(cè)結(jié)果更能逼近瓦斯涌出量的實(shí)際值,具有更好的擬合精度,而且IGSA-KELM神經(jīng)網(wǎng)絡(luò)預(yù)測(cè)模型的最小誤差為0.02,最大誤差為0.09,平均相對(duì)誤差為0.01。因此,IGSA-KELM 神經(jīng)網(wǎng)絡(luò)預(yù)測(cè)模型能更準(zhǔn)確地預(yù)測(cè)出掘進(jìn)面絕對(duì)瓦斯涌出量,得到更高精度的預(yù)測(cè)結(jié)果。
4 結(jié) 語
針對(duì)瓦斯涌出量受其他因素的影響,并且存在著復(fù)雜的非線性關(guān)系,缺少相應(yīng)的歷史監(jiān)測(cè)數(shù)據(jù)分析算法,難以發(fā)現(xiàn)參量發(fā)展變化趨勢(shì),用一般的線性模型很難準(zhǔn)確預(yù)測(cè),本文從瓦斯涌出量模型出發(fā),進(jìn)行基于時(shí)間序列的預(yù)測(cè)方法的研究,提出將核極端學(xué)習(xí)機(jī)及萬有引力算法相結(jié)合,建立瓦斯涌出量預(yù)測(cè)模型,在結(jié)合方式和算法方面進(jìn)行了優(yōu)化改進(jìn),提高了預(yù)測(cè)模型的預(yù)測(cè)精度和預(yù)測(cè)效率,為瓦斯涌出量預(yù)測(cè)提供了新的方法。
猜你喜歡
童話王國(guó)·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
網(wǎng)絡(luò)安全與數(shù)據(jù)管理(2022年1期)2022-08-29 03:15:20
導(dǎo)航定位學(xué)報(bào)(2022年4期)2022-08-15 08:27:00
中學(xué)生數(shù)理化·中考版(2022年8期)2022-06-14 06:55:24
新世紀(jì)智能(數(shù)學(xué)備考)(2021年9期)2021-11-24 01:14:36
成都醫(yī)學(xué)院學(xué)報(bào)(2021年2期)2021-07-19 08:35:14
新世紀(jì)智能(數(shù)學(xué)備考)(2020年9期)2021-01-04 00:25:14
中學(xué)生數(shù)理化·七年級(jí)數(shù)學(xué)人教版(2020年10期)2020-11-26 08:24:50
數(shù)學(xué)物理學(xué)報(bào)(2020年2期)2020-06-02 11:29:24
光學(xué)精密工程(2016年6期)2016-11-07 09:07:19
