基于聚類分析的網絡輿情主題提取
2020-06-04 09:39:03程小剛安夢佳郭韌
計算機時代 2020年5期
程小剛 安夢佳 郭韌


摘? 要: 網絡輿情具有時效性強、傳播迅速、涉及方面雜而廣、意見指向性特征明顯、泛娛化特征明顯等特點。因此,提出對LDA輸入數據采用TF-IDF算法加強特征詞篩選的方法。選取 “巴黎圣母院大火”事件,采集作為網絡輿情重要來源的微博數據,進行LDA建模,引入TF-IDF算法進行特征詞的篩選,能較準確地分析出該事件的主題分布。
關鍵詞: 網絡輿情; 主題提取; LDA; TF-IDF
Abstract: Network public opinion has the characteristics of strong timeliness, rapid dissemination, wide and miscellaneous involved aspect, obvious directional feature of opinion, and obvious characteristics of pan-entertainment. Therefore, TF-IDF algorithm is proposed to enhance the feature word filtering for LDA input data. Select "Notre Dame Fire in Paris" event, collect micro-blog data, which is an important source of public opinion on the network, model it with LDA, and introduce TF-IDF algorithm to select the feature words, it is found that the subject distribution of the event can be analyzed more accurately.
0 引言
相對傳統輿情,網絡輿情傳播互動更加迅捷,影響擴散更敏感,帶有網友的主觀性,直接以多種形式發布在互聯網上。各類社交平臺的出現,緩解了網民在網絡信息上作為傳播者和受傳者角色上的不平等,網民可以發布和傳播一手信息,網絡信息的真實性失去嚴格的把控,大量偏差甚至虛假信息橫行網絡,而網民的情緒又極易被煽動,若無法針對輿論事件及時作出反應,就會出現一些不理智的言論,可能加速事件惡化,讓相關單位的公信力受挫。及時、準確地收集輿論信息,提取出輿情事件的主題,并針對主題給出具有針對性、行之有效的解決方案,不僅能夠為未來相關主題事件的解決做準備,更提高了解決效率,遏制了事件的惡化。網絡輿情的研究主要集中在網絡輿情概念理論、傳播特征及途徑、輿情傳播影響因子、輿情引導策略等[1-2]方面,利用云計算、相關算法、聚類技術進行網絡輿情的熱點發現、情感分析、觀點挖掘、監測模式分析、主題演化等[3-4]的研究。網絡的開放性讓人們越來越容易表達自己,網絡輿情的監測控制變得重要。準確發現和提取網絡輿情的主題,對輿情的監測和疏導有著積極的意義。
1 主題提取模型和算法
判斷兩篇文檔是否相關,通常不僅僅取決于其在字面上的詞語重復程度,還很大程度上取決于文本中所隱含的主題是否類似。在文本創作中,作者通常先確定文章的主旨,再根據要涉及到的每個主題,選取相應詞匯,以突出主題、構成文章。在文本挖掘中,可模擬文本創作過程,先從主題集合中選取一些主題,再從每個主題下選取一些詞語,這些詞語構成了最終的文檔。對一篇文檔判斷其主題分布,便是上述過程的逆過程。而也是由上述過程可知判斷一篇文檔的主題分布,關鍵便是得到文檔-主題分布、主題-詞分布。LDA(潛在狄利克雷分配主題)模型針對每篇文檔,文檔-主題矩陣、主題-詞矩陣都是不確定的,通過貝葉斯方法估計詞分布和主題分布的兩個未知量,提高了文檔處理的靈活性。
文本經數據預處理之后,成為一系列對文檔主題有貢獻的詞,每個詞的對主題的貢獻率不同。TF-IDF算法便是用來評估詞匯在所在文檔中的重要程度,算法結果是得出每個詞的權重。詞權重不僅取決于其在文章中出現的次數多少,還取決于該詞常見與否。當某個詞較為少見卻在一篇文章中出現頻繁時,那么該詞很可能反映了該篇文章的特點。算法步驟如下。
第一步,計算詞頻。TF=某詞在文章中出現的次數/文章的總詞數。
第二步,計算逆文檔頻率,用于衡量該詞在所分析的語言環境中的常見程度。IDF=log(文檔集D的文檔總數/(包含該詞的文檔數+1))。一個詞在所分析的語言環境中越常見,則IDF值越小。
第三步,計算TF-IDF。TF-IDF=詞頻(TF)× 逆文檔頻率(IDF)。
2 網絡輿情主題模型構建
網絡輿情的時效性較強,對主題提取的及時性有著較高的要求,網絡輿情所涉及的民眾角度多而雜,口語化表達較多,構建的LDA模型時需加強數據輸入的代表性。TF-IDF算法能夠計算出每個特征詞的權重,值較小的詞則對文檔主題的貢獻率較低,如不去除必然影響主題提取的準確率。在數據預處理階段引入TF-IDF算法對分詞結果進行過濾,使其轉化為更具代表性的特征詞。
2.1 語料庫構建
語料庫是由文檔集提取而來,一個好的文檔集中每篇文檔涉及的主題較為廣泛,不僅利于事件主題提取的準確性,還提高了訓練出的LDA模型的在事件類型的適用性。結合網絡輿情表現形式,將某一網絡熱點事件的輿情在文本形式上分為兩大類:字數超800字的文章式分析型和字數較少的短文本評論型,參與范圍較廣的是后者,若想更廣泛更全面了解民意,其更具主題提取價值。
網絡輿情無論發布在哪個網站平臺,人們針對某一特定事件的態度及評論的方式總是不變的,不同之處僅在于由于不同網站轉發回復形式不同,使得采集的原始數據的預處理過程有些相異之處。多數微博用戶所發博文內容字數不超過500字,屬于短文本評論型,可在微博上選取10位以上微博博文內容“時事評論純度高”,即博文內容涉及其他無關輿情主題較少的時事評論人,每個評論人所有博文內容構成一篇文檔,以此構成文檔集。采取這些時評人的微博內容用以訓練模型不僅由于其涉及面廣,而且因為該文本內容在表達形式上接近網友評論,同時這些時評人具有一定的權威性,其表達的觀點較普通大眾更為準確客觀,更利于主題分類。
2.2 事件文檔構建
網民參與度較高的表現為短文本評論,其表現為熱門新聞下的評論、熱門帖子或博文下的跟帖評論、單獨開帖發表觀點等。而對于所分析事件文檔構建,若要更真實地了解民意,需主題提取的更有效,應抓取事件熱門新聞下的評論數據,或用于表達個人觀點的微博博文數據等。前者是客觀的新聞內容及評論區,其合情合理地成為輿論觀點聚集地,后者毋庸置疑亦是屬于輿情的重要來源。這兩者納入同一篇文檔即構成所分析事件的輿情數據。
2.3 網絡輿情主題模型
LDA模型是基于貝葉斯模型的,如圖1所示。
θd表示第d篇文檔的主題分布,用向量表示,θd,k表示第k個主題在第d個文檔中的比例;Zd表示第d篇文檔的主題分布全體,Zd,n表示文檔中第n個詞的主題;Wd表示第d篇文檔的全體特征詞,Wd,n是第d個文檔中第n個詞;N表示第d篇文檔的特征詞總數,d篇文檔構成要生成的文檔集D;K代表所有主題的集合,βk表示第k個主題中詞的分布;α、η表示語料參數,p (θd|α)表示參數為α時第d篇文檔的主題分布,p(βk|η)表示參數為η時第k個主題中詞的分布。
LDA是在PLSA的參數上引入先驗分布并進行貝葉斯改造所形成的,而LDA的Dirichlet先驗分布則體現在語料參數α、η上:α代表文檔中隱含主題之間的先驗參數,η代表主題內部詞語分布的先驗參數,二者均服從Dirichlet分布。根據Xing Wei和W. Bruce Croft[5]等的研究,先驗參數α、η可由經驗確定,α=50/T、η=0.01,其中T為主題個數。LDA的聯合概率公式為:
3 輿情主題分析及實證研究
3.1 微博輿情數據采集和處理
3.1.1 數據采集
利用網絡爬蟲技術,通過八爪魚數據采集器實現數據爬取。語料庫數據方面,選取了10個權威時事評論人:陳迪Winston、連鵬、敬一山、唐有訟、陳純Camus、石述思、喬凱文、楊文戰律師、呂頻、韓東言。這10個時評人的關注事件角度均較為廣泛,涉及醫療、教育、國際關系、女性權利、刑事、科技生活等眾多能夠引起廣泛輿論討論的方面。本文對該10個時評人微博主頁中2019年內的微博數據進行了爬取,共抓取10054條有效微博博文數據。
輿情事件數據方面,選取“巴黎圣母院大火”事件。當地時間2019年4月15日下午6點50分左右,法國巴黎圣母院發生大火,整座建筑損毀嚴重,這座擁有人們集體記憶的“全人類的偉大遺產之一”受到如此重創,新聞一出,輿論嘩然。利用八爪魚通過微博關鍵字“巴黎圣母院大火”的搜索,共搜集1000條微博數據,6557條評論數據。
3.1.2 數據預處理
對爬取到的數據進行標準化、結構化,轉化為LDA模型可輸入的數據形式。數據預處理過程主要包括三個階段:對提取到的內容做分詞處理——去除分詞結果中的無用詞——TF-IDF算法提取特征詞。
⑴ 文本分詞:對于英文分詞來說,基本只需要按照空格基于區分,而中文分詞將一個個漢字組成的序列切割成一個個單獨的詞,也即將一個連續的字序列按照一定的規范重新組合成一系列詞的過程。中文文本之間不但是彼此連續的,而且還有常用詞、詞性、成語等許多語法現象,需要借助一些特定的中文分詞模塊。本文采用Python中jieba分詞工具。
⑵ 去停用詞:分詞結果中存在較多無意義的符號,與其他詞相比沒有具體的實際含義,但由于在磁盤中占用空間較大,為提高檢索效率,可將其剔除。在文本處理中,一旦遇到該類詞就停止處理,將其扔掉。停用詞一般包括英文字符、數學字符、數字、標點符號、使用頻率很高的單漢字等。本文引入來自于網絡的較為全面的停用詞表對分詞結果進行處理,其內容涵蓋了哈工大停用詞、四川大學機器智能實驗室停用詞庫、百度停用詞等常見的停用詞表,分詞表共含1893個詞符。在python中對前一步分詞結果,引入停用詞表進行處理后。
過濾掉停用詞后,事件文本數據中仍存在大量詞匯,詞匯數目過多,輸入到LDA模型中,產生的文檔-詞匯矩陣映射到向量空間時,信息過多、維數過大,不利于事件輿情主題提取的及時性和有效性。
⑶ TF-IDF提取特征詞:通過在python中編寫TF-IDF函數,共提取了前300個關鍵詞。得關鍵詞及其權重值如圖2所示。
3.2 LDA實證建模及結果分析
在Python中引入gensim包,調用其LdaModel方法,輸入已經預處理好的文檔集作為corpus語料庫、文檔-詞矩陣轉化而來的數據字典及所欲得到的主題個數。輸入得主題個數能夠直接影響LDA模型的好壞,通過困惑度(perplexity)確定LDA模型主題個數:
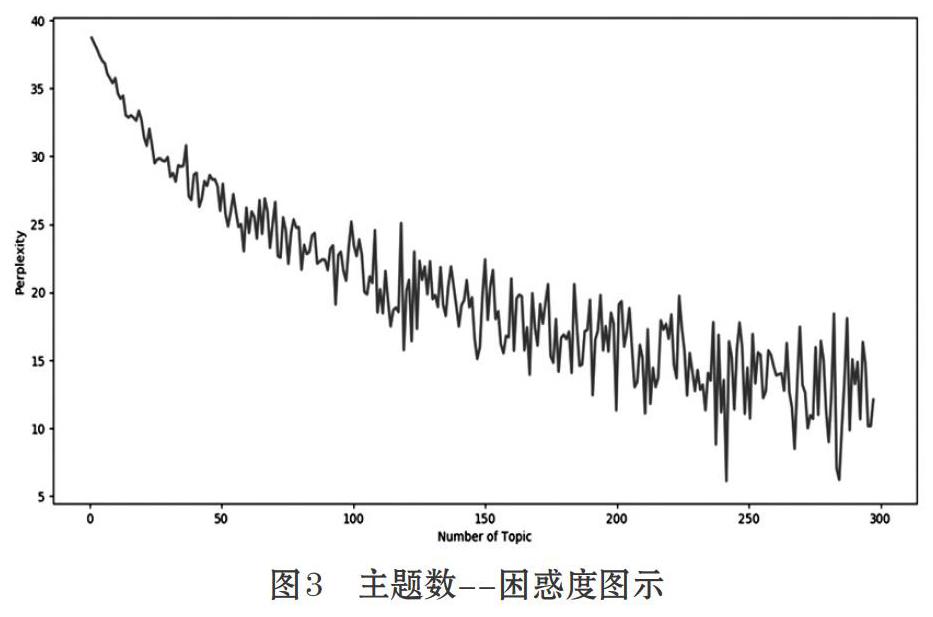
其中,分母為測試集總長度,即文檔集所有詞匯數,p(w)指測試集中每個單詞出現的概率,,p(z|d)指每個文檔中每個主題的概率,p(w|z)指每個詞匯在該主題下的概率。困惑度越低,說明LDA模型建的越好,而必然主題數越多,文檔所屬主題的不確定性也即困惑度越低。但主題數目過多,不但主題提取失去意義,更是容易出現模型的過擬合。由于對所分析事件最終共提取300個關鍵詞,對LDA模型主題數從1-300的困惑度均進行了計算,通過Python完成上述過程,并對計算結果繪制了折線圖。如圖3所示。
主題數在178個附近時,困惑度達到最小,而>178,困惑度趨于平緩。然而,當將topic-number=178輸入LDA模型時,得到的主題-詞匯矩陣中存在大量主題的詞匯相同,出現過擬合現象,經過主題數調整,最終確定topic-number=20時,困惑度最低且無過擬合現象。將新文檔帶入LDA模型,得到的主題分布如圖4所示。
選取其中幾個話題進行分析:
Topic2:作為全人類共同文化遺產的巴黎圣母院,如今被燒得幾乎沒了屋頂,大多數人表示痛心難過,更是希望法國政府徹底調查出起火原因,加強文物保護。
