藏文自動組卷系統(tǒng)中試題消重方法研究
2020-06-04 09:39:03德格加
計算機(jī)時代 2020年5期
德格加

摘? 要: 在計算機(jī)自動組卷系統(tǒng)中,試卷中試題的互異性是評價自動組卷系統(tǒng)性能的一個重要指標(biāo),而試題的互異性或相似度是由多個參數(shù)共同決定的。根據(jù)藏文試題的結(jié)構(gòu)特點(diǎn),提出了一種試題相似度的計算方法,力求提升自動組卷系統(tǒng)的組卷性能。
關(guān)鍵詞: 自動組卷; 藏文試題; 相似度; 組卷性能
Abstract: In the automatic test paper system, the test paper's mutuality is an important index to evaluate the performance of the system, and the test paper's mutuality or similarity is determined by multiple parameters. According to the structural characteristics of test paper in Tibetan, a method of calculating the similarity of questions in test paper is proposed to strive to improve the performance of automatic test paper system.
Key words: automatic generating of test paper; test question in Tibetan; similarity; performance of test paper generating
0 引言
隨著計算機(jī)技術(shù)的迅速發(fā)展,各種計算機(jī)輔助教學(xué)軟件相繼開發(fā)問世,作為教學(xué)輔助系統(tǒng)中最重要的組成部分,試題管理和組卷系統(tǒng)是人們研究的重要領(lǐng)域之一,在日常教學(xué)活動中發(fā)揮著積極的作用[1]。而評價一個組卷系統(tǒng)的性能不僅考慮整個系統(tǒng)的組卷效率、試卷的適應(yīng)度,系統(tǒng)的健全性和可擴(kuò)展性,還需考慮一個最重要的指標(biāo),即試卷中試題的互異性。
1 重復(fù)試題的消重法
理工科類試題的題型具有多樣性,有純文字?jǐn)⑹觯袌D形,有表格,以及多種形式混合等多種出題形式。文字?jǐn)⑹鲋幸詳?shù)學(xué)式子和專業(yè)符號居多,而且數(shù)學(xué)式子和符號是用專用的軟件編輯的[2],這對利用計算機(jī)處理該類試題增加了很大難度。在自動組卷系統(tǒng)中試題之間的相似性是通過試題的各屬性的相似度來綜合評定的,本文通過試題關(guān)鍵詞的相似度、試題所含知識點(diǎn)和題型三個指標(biāo)的相似度來綜合評定試題的相似度,具體計算公式如下:
2 試題關(guān)鍵詞的相似度Txtsim的計算方法
2.1 試題題干預(yù)處理
試題關(guān)鍵詞的相似度計算中首先對試題中的文字描述性內(nèi)容進(jìn)行分詞處理,文章中所采用的分詞算法是基于字典的機(jī)械分詞算法—雙向匹配分詞方法,該分詞算法的優(yōu)點(diǎn)是分詞效率高,易于實(shí)現(xiàn),而缺點(diǎn)也是很明顯的,分詞準(zhǔn)確性依賴于分詞字典,字典的完備性直接影響分詞性能[3],所以傳統(tǒng)的分詞字典已無法滿足對這類文本的分詞要求,需要用專用的分詞詞典或?qū)Ψ衷~詞典進(jìn)行擴(kuò)充。根據(jù)該方法對“
雙向分詞中如果正向和逆向的分詞結(jié)果一致,則選用其中任意一個結(jié)果作為該詞串的最終分詞結(jié)果。若正向和逆向的分詞結(jié)果不相同時,采用最大概率的方法計算P(W1)和P(W2)后,選用其中較大概率的分詞結(jié)果,即。具體概率計算公式如下:
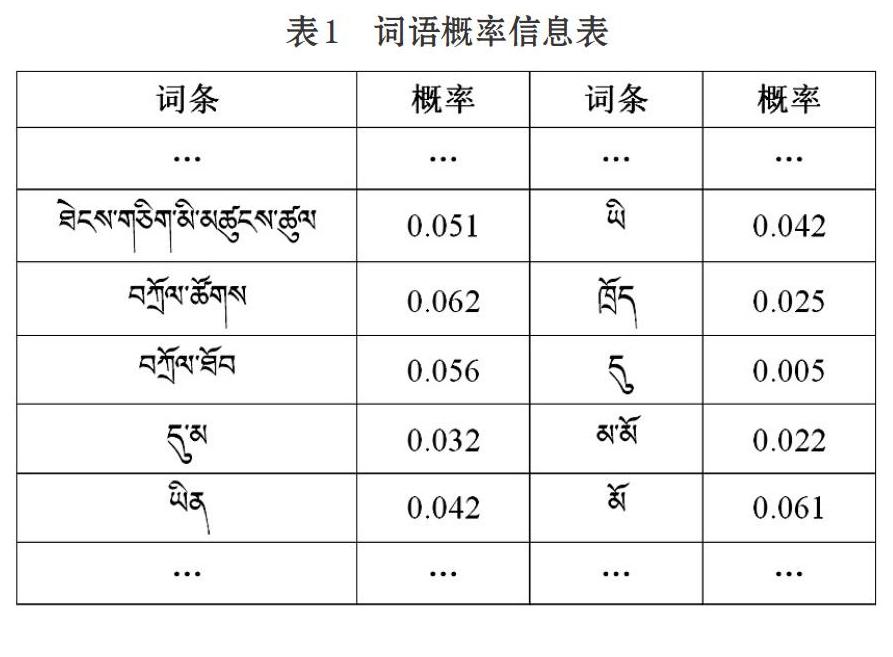
根據(jù)式⑷計算字典中各詞條的頻率,將計算結(jié)果存入詞典中,即分詞詞典中不僅包含各詞條(包括擴(kuò)充的詞條),還包含各詞條的頻率,分詞詞典的結(jié)構(gòu)見表1。
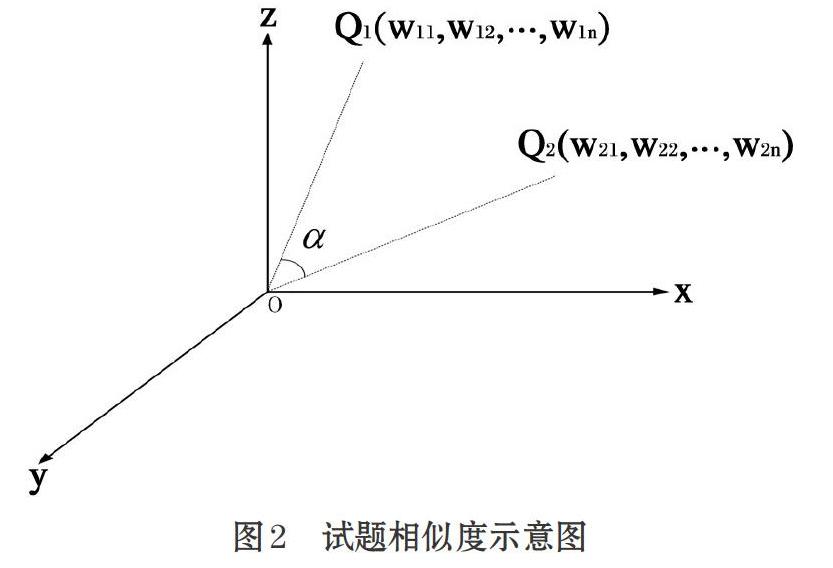
2.2 試題相似度技術(shù)分析
公式⑸計算兩文本的相似性時只考慮了特征詞的頻率,有時候得出的相似度結(jié)果不準(zhǔn)確,如表2中所列出的試題的關(guān)鍵詞為例,通過該公式計算得出試題Q2和Q3的相似度約為0.95,但這兩道題的關(guān)鍵詞分布極不均衡,只有一個公共關(guān)鍵詞,計算結(jié)果與實(shí)際差距較大,因此為了避免出現(xiàn)此類情況,在對傳統(tǒng)的相似度計算公式稍作了修改了改進(jìn)。
其中表示試題Q1和Q2中共有的關(guān)鍵詞個數(shù),表示試題Q1和Q2中關(guān)鍵詞較少的試題的關(guān)鍵詞個數(shù),,這樣新公式中增加了乘項(xiàng),也就是公式⑹在計算兩試題的相似度時既考慮關(guān)鍵詞的詞頻,也考慮了關(guān)鍵詞分布對文本相似性的影響因素。通過新公式計算表2中的試題Q2和Q3的相似度為0.47,這個結(jié)果跟實(shí)際更接近一些。
3 試題知識點(diǎn)相似度KPsim的計算方法
一般而言,試題的相似度不僅跟試題中的關(guān)鍵詞有關(guān),也跟試題中知識點(diǎn)的相似度有關(guān),如果兩個試題中所考的知識點(diǎn)完全一樣,則即使題型,關(guān)鍵詞不同,我們都將其劃為同類試題。本文通過式⑺來計算試題知識點(diǎn)的相似度,若兩個試題q1和q2中所含知識點(diǎn)的集合分別為Q1和Q2,則兩個的相似度用兩個集合的交集和并集的比值來衡量,即:
4 小結(jié)
本章分析了藏文試題自動組卷系統(tǒng)中所涉及到的最底層的處理技術(shù),為了保證組卷的質(zhì)量和性能,避免在同一試卷中出現(xiàn)相同試題的情況,在組卷過程中計算機(jī)對選中的試題間進(jìn)行相似性的比較,所以本章主要分析了試題相似性檢驗(yàn)所用到的分詞和試題相似度的計算方法。分詞中采用了基于字典的分詞方法,為了分詞結(jié)果更準(zhǔn)確,符合數(shù)學(xué)等專業(yè)等學(xué)科的分詞標(biāo)準(zhǔn),文中對分詞詞典做了相應(yīng)的擴(kuò)充。試題相似度計算中采用向量模型的文本相似度計算方法,并對傳統(tǒng)的文本計算公式中增加了特征詞分布影響因素,得到了一個新的計算試題相似性的計算公式,該公式能有效避免相似度低的試題干擾。
參考文獻(xiàn)(References):
[1] 王友仁.題庫系統(tǒng)智能成卷理論和組卷方法研究[J].電子科技大學(xué)學(xué)報,2014.6.
[2] 才項(xiàng)俄日,張有誼.藏語文試卷的智能生成研究與實(shí)現(xiàn)[J].電腦與信息,2015.6.
[3] 祁坤鈺.藏文分詞與標(biāo)注研究[M].甘肅民族出版社,2015.
[4] 洛桑嘎登.藏文自動分詞與詞性標(biāo)注研究[D].中央民族大學(xué)碩士論文,2016.
[5] 李連,朱愛紅,蘇濤.一種改進(jìn)的基于向量空間文本相似度算法的研究與實(shí)現(xiàn)[J].計算機(jī)應(yīng)用于軟件,2012.2.
[6] 鄔明強(qiáng).基于分段融合的藏文文本相似度計算方法研究[D].西北民族大學(xué),2016.
