面向二類區分能力的干擾熵特征選擇方法
2020-06-06 02:06:58曾元鵬王開軍
計算機應用 2020年3期
曾元鵬,王開軍,林 崧
(1. 福建師范大學數學與信息學院,福州350007; 2. 福建師范大學數字福建環境監測物聯網實驗室,福州350007)
(*通信作者電子郵箱wkjwang@qq.com)
0 引言
特征選擇是數據挖掘的預處理步驟,旨在通過刪除不必要特征,以達到降低算法復雜度、提高算法性能的目的。特征子集的評價準則或啟發式確定后,特征選擇問題從某種意義上來說就是在特征空間中搜索最優特征子集問題[1]。
近年來,使用信息熵方法[2]來進行特征選擇越來越成為廣大研究者的研究熱點。文獻[1]提出將粗糙集相對分類信息熵作為適應度函數實施粒子群算法進行特征選擇;文獻[2]采用基于互信息的近鄰熵進行近似的最近鄰前向搜索來選擇特征(Neighborhood Entropy Feature Selection,NEFS),并通過優化索引結構提出單索引近鄰熵特征選擇(Single-indexed Neighborhood Entropy Feature Selection,SNEFS)方法來選擇更好的分類特征。互信息在相關性分析上有計算簡單、可解釋性強特點,因此基于互信息的特征選擇方法被廣泛應用于特征選擇[3]。相關性最大冗余性最小特征選擇(feature selection based on Max-Relevance and Min-Redundancy,MRMR)算法[4]計算待選特征與類別的互信息、待選特征與已選特征間的平均互信息,以兩者的差值是否為最大值來決定該特征可否加入最優特征子集中;但是該方法沒有對特征數據在類別上的分布情況作出合適判斷,無法體現出數據的混亂情況。與MRMR方法類似的還有文獻[5]提出的特征排序方法,度量特征間的獨立和冗余程度,考慮了特征子集中不同特征間的多變量關系。文獻[6]運用了互信息將特征進行排序,將排序后的特征逐個加入特征子集進行分類,去掉每次可以正確分類的樣本,從而避免信息的冗余。聯合互信息(Joint Mutual Information,JMI)方法[7]選取信息增益最大的特征作為第一個特征;接著計算待選特征的信息增益;然后,計算在已選特征子集條件下,待選特征與類別的條件互信息均值;最后,將兩者之和最大的待選特征加入已選特征子集;該方法在不同類別數據的區分能力上存在欠缺。與該方法部分類似的有文獻[8]提出在特征和類別之間的聯合最大信息熵方法度量特征子集并用粒子群優化方法來搜索最優特征子集。Relief方法[9]提出先隨機選取一個樣本點,并從同類中尋找最近的樣本,再尋找最近的非同類樣本計算其距離,如果同類距離較小,則認為該特征對區分不同類別樣本更有能力,增加該特征的權重;該方法以近鄰的方式去判斷二類的區分性,未從數據分布的整體情況進行考慮。文獻[10]提出以相對分類信息熵作為適應度函數度量特征子集的重要性,使用遺傳算法搜索最優特征子集;文獻[11]假設特征之間相互獨立,使用特征與標簽集合之間的信息增益來衡量特征與標簽集合之間的重要程度,然后采用信息增益閾值選擇特征。文獻[12]在K-近鄰互信息的基礎上將其擴展至高維,并采用前向搜索和后向交叉相結合的形式來獲得最優強相關特征子集。文獻[13]利用模糊等價關系將互信息推廣至模糊互信息,接著計算該模糊度量下的候選與已選特征的相關關系,最后采用最大最小準則與前向貪婪算法來選出最優特征子集。
現有方法主要測量備選特征和類別之間的信息熵來篩選最優特征,但沒有評價某個特征在類別區分上的能力和貢獻大小,這造成所選特征的緣由是模糊的、不清晰的。本文方法的好處是對某個特征區分不同類別數據的能力給出了一個明確的評價指標,使得挑選某個特征具有明確的依據和含義。本文提出了一種面向二類區分能力的干擾熵方法(Interference Entropy of Two-Class Distinguishing,IET-CD),對每個特征下兩類數據的相互干擾程度采用干擾熵值進行量化,使用干擾熵指標作為不同類別數據區分能力的評價指標,當干擾熵值越小,說明該特征的二類區分能力強,反之則弱,為尋找二類數據區分明顯的特征提供了方法。
1 干擾熵方法的相關定義
給定具有n個m維樣本的二類數據集D=[d1,d2,…,dm],含有正類(A 類)樣本X和負類(B 類)樣本Y。對于數據集D中的di(i≤m)維(特征)上的數據,以樣本均值u1較小的一類為正類,樣本均值u2≥u1的一類為負類,k個正類樣本記為X={X1,X2,…,Xk},n-k個負類樣本記為Y={Y1,Y2,…,Yn-k},正、負類樣本的取值范圍為[Xmin,Xmax]與[Ymin,Ymax],在正類范圍內出現的負類樣本為Y+={Xmin≤,…,≤,j≤n-k,Y+?Y,在負類范圍 內的出現正類樣本為X-={Ymin≤,…,≤Ymax},l≤k,X-?X。
定義1 混合條件概率。在正類數據取值范圍內,出現正類樣本X概率為P(X)=k/(k+j),出現負類樣本Y+的概率為P(Y+)=j/(k+j),則正負類樣本出現的聯合概率為P(X,Y+),出現負類樣本Y+的混合條件概率為P(Y+|X),公式如下:
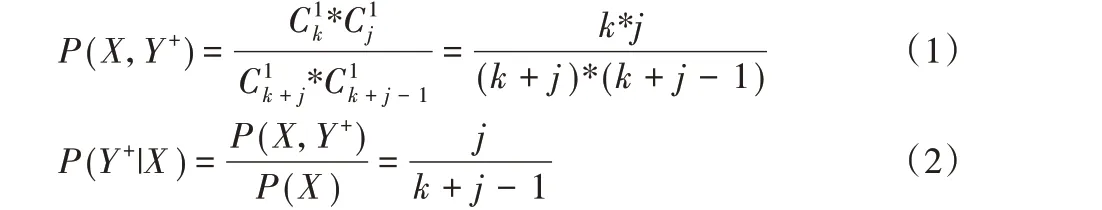
定義2 樣本歸屬正類的概率。設在正類數據范圍出現負類樣本點(i= 1,2,…,j),混淆區域為[,Xmax];負類數據 范 圍 出 現 正 類 樣 本 點(i= 1,2,…,l),混 淆 區 域 為[Ymin,Xi-]。統計在正類混淆區域內的r個正類樣本和t個負類樣本,正、負類樣本出現在混淆區域的概率分別記為P(A*)=r/(r+t)、P(B*)=t/(r+t)。負類樣本在正、負類數據的高斯概率密度下屬于正、負類的概率記為P()、P(),則樣本歸屬正類概率記為P(),類似地計算出樣本歸屬負類概率P(),公式定義如下:
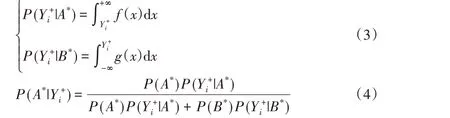
其中:f(x)是具有均值u1和標準差σ1的正類數據高斯函數,g(x)是具有均值u2和標準差σ2的負類數據高斯函數。
在上述混合條件概率P(Y+|X)和樣本歸屬正類的概率P()的基礎上,設計混淆概率。
1.2 方法 對照組為常規護理,指導戒煙,預防感冒等。實驗組患者在此基礎上實施圍手術期呼吸運動訓練。告知患者圍手術期呼吸運動訓練的目的和必要性、從而取得患者的配合。訓練自患者入院開始每日指導練習。
定義3 混淆概率。在正類范圍內,負類樣本被誤認為是正類樣本的混淆概率P(+)為混合條件概率和樣本歸屬正類的概率的乘積,即:
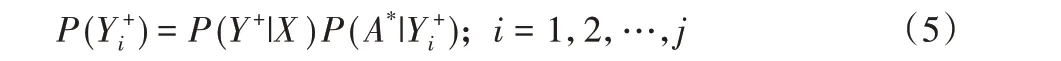
定義4 類間干擾熵。在正類范圍內,正類干擾熵H(Y+)為每個負類樣本點的干擾熵之和;類似地,在負類范圍內,負類干擾熵H(X-)為每個正類樣本點的干擾熵之和。類間干擾熵H(Y+,X-)定義如下:
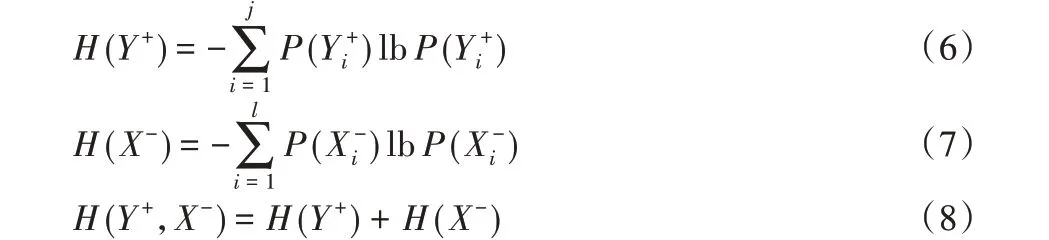
對于二值的離散型特征,設計如下的定義用于計算混淆概率。
定義5 離散特征混合條件概率。對于取值為0、1的離散型特征,設該特征上正類樣本集A中值為0和1的樣本個數分別為a0和a1,且a0≥a1,負類樣本集B中值為0和1的樣本個數分別為b0和b1。則值為0的樣本x屬于正、負類的概率分別為PA(x=0)=a0/(a0+a1)、PB(x=0)=b0/(b0+b1),則值為1的樣本x屬于正、負類的概率分別為PA(x=1)=a1/(a0+a1)、PB(x=1)=b1/(b0+b1)。在A中出現值為1和0樣本的混合條件概率分別為P(x=1|A)=a1/(a0+a1)、P(x=0|A)=a0/(a0+a1);同 理 有P(x=1|B)=b1/(b0+b1)和P(x=0|B)=b0/(b0+b1)。
定義6 離散特征的混淆概率和干擾熵。設一個特征上正類樣本子集A有a0≥a1,則值為1的樣本的混合條件概率與樣本歸屬于正類的概率的乘積稱為混淆概率P()=P(x=1|A)PA(x= 1),同理有混淆概率P(B)=P(x=0|B)PB(x=0)。則干擾熵定義為H(A-,B+)=H(B+)+H(A-),其中H(B+)=
2 面向二類區分能力的干擾熵方法
面向二類區分能力的干擾熵方法以類間干擾熵來衡量該特征所包含的兩類數據混淆情況。對于二類數據集中的某一維度/特征,若類間干擾熵大,說明兩個類別的數據混合程度大,二類區分性弱;若小,說明兩個類別的數據混合程度小,二類區分性強。
當負類樣本出現在正類數據范圍內時,正負樣本的數據范圍出現重疊,使二類數據的區分度減弱。正類數據范圍內的負類樣本數量對特征二類區分能力的影響采用定義1 或5的混合條件概率進行量化計算。
混合條件概率衡量了在正類數據范圍內混入負類樣本的數量情況,樣本歸屬正類的概率考慮到混入的負類樣本歸屬于正類的程度,將上述概率的乘積作為兩類數據的混淆情況的量化,通過定義3或6的公式得到相應的混淆概率。
評價一個特征的二類區分能力的干擾熵方法步驟如下:
依據上文的定義,對于連續型數據有:
1)選擇數據集D中的一個特征,分別計算正、負類樣本的取值范圍,統計正類范圍內的負類樣本。
2)計算正類數據范圍內正、負類出現的概率P(X)、P(Y+),聯合概率P(X,Y+),以及混合條件概率P(Y+|X)。
3)在正類數據范圍內,計算樣本歸屬正類的概率P()。對稱地,在負類數據范圍內,計算樣本歸屬負類的概率P()。
4)計算正類數據范圍內的負類樣本被誤認為是正類樣本的混淆概率P()。對稱地,在負類數據范圍內,計算正類樣本被誤認為是負類樣本的混淆概率P()。
5)依據混淆概率計算類間干擾熵H(Y+,X-)。
對于離散型數據,類似地依據上文的定義計算混淆概率和類間干擾熵。
3 實驗分析
為了檢驗本文IET-CD 方法的有效性,利用IET-CD 方法計算每個特征的類間干擾熵,按熵值從小到大排序,選取熵值小(二類區分程度大)的特征組成特征子集,將該特征子集用于評價一個特征二類區分能力的實驗。類似地,5 個對比方法——NEFS、SNEFS、MRMR、JMI、Relief特征選擇算法也給出特征排序結果,取排序位置最前的幾個特征組成特征子集,用于二類區分能力的分析。
實驗選取3個UCI(University of California Irvine)[14]數據集Sonar、WDBC(Wisconsin Diagnostic Breast Cancer)、Ionosphere和4k20lap 模擬基因表達數據集[15]進行測試,其中4k20lap1_2是4k20lap 數 據 集 中 的 第1 和2 類 組 成。Sonar、WDBC、Ionosphere、4k20lap1_2數據集的對應的樣本數分別是208、569、351、134,特征數分別為60、30、34、20,類別數均為2。本實驗的特征選擇算法(IET-CD)的實現代碼由作者使用Python語言編寫。對比方法相關性最大冗余性最小方法(MRMR)、聯合互信息方法(JMI)、Relief 程序來源于Matlab 的FEAST(FEAture Selection Toolbox)工具箱,這3個方法參數均采用工具箱默認參數。NEFS與SNEFS算法代碼來源于文獻[2],并設定特征近鄰參數為4。最后選取各方法所得前5個最優特征進行實驗。
本實驗通過計算特征的干擾熵來衡量該特征中兩類數據的分離/重疊程度,干擾熵值越小,特征區分能力(分離程度)越好。使用特征的數據散點圖來驗證以干擾熵值作為評判標準的特征區分能力的正確性,橫坐標表示樣本編號,縱坐標表示樣本值。
在不同的數據集上對5個不同的特征選擇算法所選特征的進行干擾熵的計算,實驗結果包含對應的數據集、特征選擇算法、所選特征中前5個特征的編號,所選特征對應的熵值,用于對比的配對特征、本文方法獲勝情況,見表1。圖1 和圖2 列出Sonar、WDBC對比特征散點圖用于驗證本文方法的正確性。
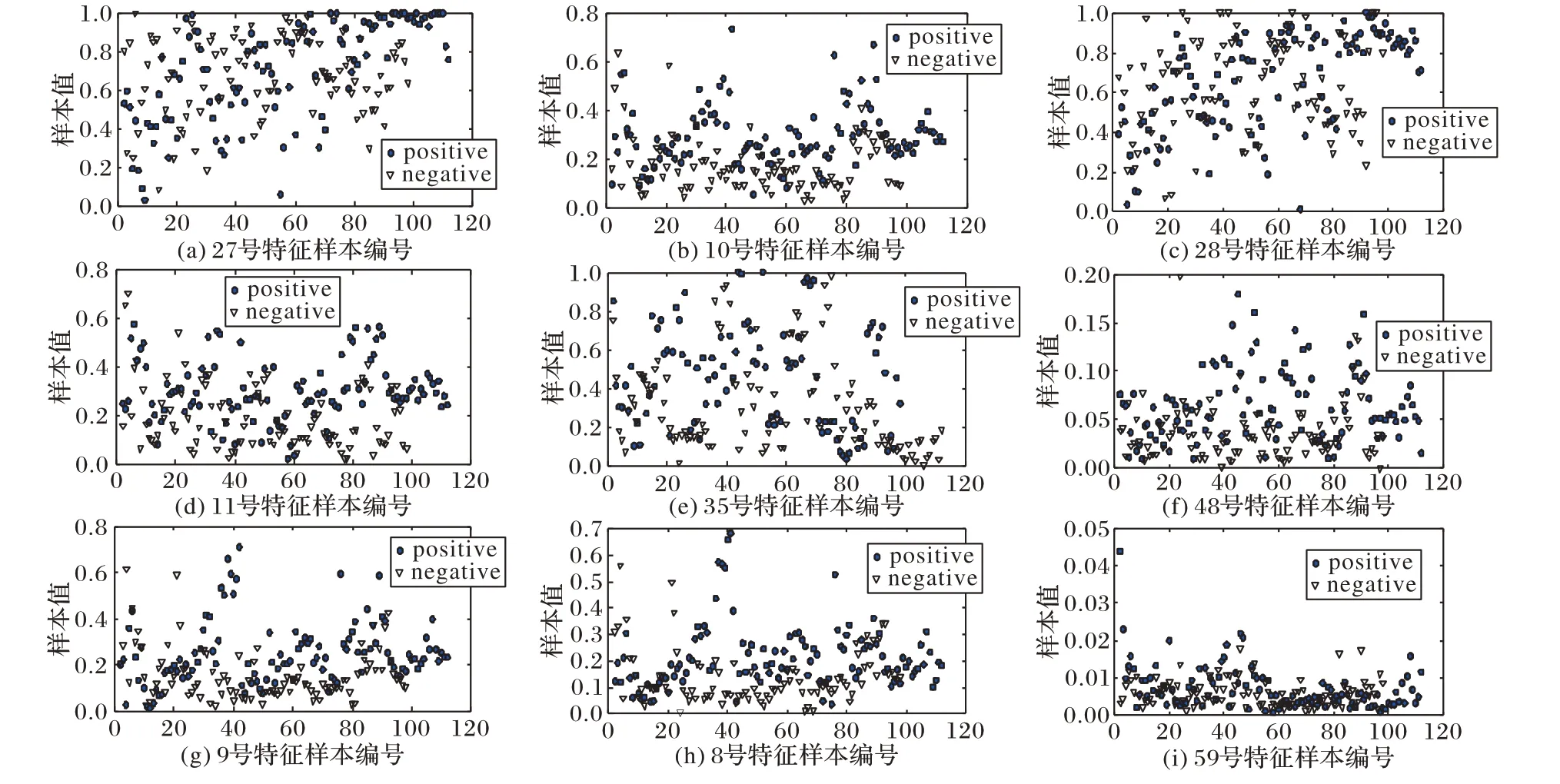
圖1 Sonar數據集對比特征的散點圖Fig. 1 Scatter plot of contrast features comparison on dataset Sonar

表1 4個數據集上各方法所選特征的二類區分能力對比Tab. 1 Two-class distinguishing ability comparison of selected features of each method on four datasets

圖2 WDBC數據集對比特征的散點圖Fig. 2 Scatter plot of contrast features comparison on dataset WDBC
從表1可知,在Sonar數據集上,10號特征比11號特征的干擾熵值小,反映出10號特征二類區分能力強,通過對比圖1中的數據散點圖,可看出10號特征比11號特征的數據重疊區域小,驗證了干擾熵值小其二類區分能力強。對11號特征與59號特征進行對比,11號特征獲勝,在圖1數據散點圖中也反映了11號特征數據重疊區域小,混淆程度小,說明本文IET-CD方法的性能優于對比方法。
WDBC 數據集上的27 號和22 號特征,Ionosphere 數據集上的6 號和4 號特征的情況與Sonar 數據集上的48 號和9 號特征情況相似,兩個特征的干擾熵值相差較小,說明兩個特征的二類區分能力相近,通過相應的散點圖反映的結果可以看出,特征的數據重疊情況相近,驗證了干擾熵值相近的兩個特征的二類區分能力相似,故對比結果表現相同。對表1 中的WDBC數據集上的5號與20號特征對比,20號特征獲勝,說明20 號特征的二類區分能力強,從圖2 的數據散點圖可看出20號特征的數據重疊區域小,逆向驗證了20 號特征干擾熵值小,5 號特征干擾熵值大,以此證明干擾熵值能正確反映二類數據的區分程度。
表1 中的Ionosphere 數據集和4k20lap1_2 模擬基因數據集仍以相同的方式進行對比,故不再一一列出對應的散點圖。因為4k20lap1_2模擬基因數據集的部分特征二類樣本混淆數量較少,所以在該數據集上反映出的特征干擾熵值也相對較小,符合干擾熵的定義。4k20lap1_2 模擬基因數據集的3 號特征比15 號特征的干擾熵值小,表明3 號特征的二類分區能力強。因3 號特征的不同類別數據分離情況較好,15 號特征的不同類別數據混合程度比3號特征混亂,故3號特征的區分能力勝過15 號特征。由表1 中的配對特征的對比結果可看出,3號特征的區分能力勝過15號特征,其特征對應的干擾熵值能正確反映二類數據的區分程度。其他特征類似對比,并通過散點圖可驗證其結論的正確性。
4 結語
本文通過計算特征的二類干擾熵來進行數據區分能力的判斷從而進行特征選擇,選出區分能力較好的特征。干擾熵值越小區分能力越強,干擾熵值越大區分能力越弱,該方法能有效篩選二類混合程度大、區分度不明顯的特征,發現二類區分能力好的特征,為識別特征的二類區分能力提供了評價指標。
猜你喜歡
發明與創新(2022年30期)2022-10-03 08:40:56
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
人大建設(2018年6期)2018-08-16 07:23:10
文理導航·科普童話(2017年5期)2018-02-10 19:42:14
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
Coco薇(2016年2期)2016-03-22 02:42:52
小星星·閱讀100分(低年級)(2015年10期)2015-10-22 08:30:04
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年4期)2015-05-19 14:47:56
