基于CNN與SVM結合的融合特征人臉識別研究
2020-06-08 01:55:13梁晴晴
現代信息科技 2020年19期
關鍵詞:人臉識別


摘? 要:針對目前人臉識別在樣本量、魯棒性等方面所受的局限,提出一種基于CNN和SVM的人臉識別模型。通過構建CNN模型進行訓練,對原始圖像提取來自CNN不同深度的特征圖,并將其進行加權融合。將融合后的特征作為最終特征輸入SVM多分類器進行分類。實驗結果顯示,對于小樣本數據集以及面部遮擋、光照變化數據集,特征的融合對模型精度提升明顯,且與傳統模型比較本方法識別精度更高。
關鍵詞:卷積神經網絡;支持向量機;特征融合;人臉識別
Abstract:In view of the limitations of face recognition in terms of sample size and robustness,a face recognition model based on CNN and SVM is proposed. By constructing CNN model for training,feature maps from different depths of CNN are extracted from the original image,and weighted fusion is performed. The fused features are input into SVM multi classifier as final features for classification. The experimental results show that for small sample data sets,face occlusion and illumination change data sets,the fusion of features can significantly improve the accuracy of the model,and the recognition accuracy of this method is higher than that of the traditional model.
Keywords:convolution neural network;support vector machine;feature fusion;face recognition
0? 引? 言
人臉識別通過人的臉部特征信息進行身份識別,其作為生物特征識別的一個重要方面,有著識別友好,特征易得等特點。正因為人臉識別獨有的特性,使得它在刑事偵查、身份驗證、視頻監控等許多方面都有著廣泛的應用。
國內外學者提出的人臉識別算法也頗多。李潤青[1]提出一種改進的2D2DPCA與SVM相結合的人臉識別分類方法,有效減少運算量和訓練時長,同時減低光照對識別的影響。張偉[2]等提出一種基于Gabor小波和LBPH算法的實時人臉識別算法,基于ARM平臺實現人臉識別系統。任飛凱[3]提出了結合LBP和數據擴充的LECNN方法,有效地提高了CNN人臉識別的準確率。谷歌[4]提出基于深度神經網絡的FaceNet,直接學習從原始圖像到歐式距離空間的映射,將歐式空間里的距離度量與人臉相似度對應。
近年來,隨著深度學習的發展,越來越多的深度學習技術[5-9],特別是CNN被更多的應用在人臉識別中。相較于傳統技術,深度學習學習能力強,泛化能力好,但也存在對樣本量要求大,易過擬合等問題。
因此,作者提出一種基于CNN和SVM的人臉識別算法,將CNN強大的學習能力與SVM多分類器對小樣本的適用性相結合,為本校未來在人臉識別方面的應用提供參考。通過深層卷積神經網絡提取人臉特征,將網絡不同深度提取的特征融合,使特征在高度抽象的同時兼顧底層細節信息,增加分類特征包含的信息量。最后使用更適合小樣本分類的SVM算法進行分類。
1? 基于CNN和SVM的融合特征人臉識別算法框架
研究表明,大型的深層神經網絡,具有較強的學習能力,對于圖像分類具有較大優勢。但對小樣本圖像數據使用深層神經網絡容易出現過擬合、泛化能力弱等問題。而SVM是一類按監督學習方式對數據進行分類的廣義線性分類器,有較強的泛化能力,且更適用于小樣本集。為了提升對小樣本人臉數據的分類精度,本文將CNN與SVM結合。CNN的不同層所包含的信息不同,低層包含細節信息,高層含有抽象的類別信息[10,11]。網絡主要分為三部分,首先,構建CNN,訓練網絡提取圖像特征。其次,將不同深度的特征融合作為最終的分類特征。最后,將分類特征輸入SVM進行人臉識別。
1.1? 特征提取網絡
為了更好地提取人臉圖像的特征,構建包含6個卷積層、3個池化層、3個全連接層的CNN。以提取ORL人臉數據集特征為例,網絡結構如表1所示。
1.1.1? 前向傳播
對CNN進行權值的初始化,輸入圖像依次經過卷積層、池化層、全連接層向前傳播得到最終的輸出值。以ORL人臉數據集特征提取網絡為例,本文定義網絡的輸入大小為64×64×3,卷積層C1和卷積層C2的卷積核大小為3×3,卷積步長為1,經過兩層卷積得到64個64×64的人臉特征圖,卷積后使用ReLU激活函數。之后進入池化層P1,使用2×2大小的滑動窗口,步長為2對特征圖進行最大池化操作,對特征降維得到64個32×32的特征。經過同上相同結構的三部分后,得到256個8×8的特征圖。將特征圖打平成一維向量輸入全連接層,向量經過三個全連接層,最終得到一個40維的特征向量。
1.1.2? 反向傳播
對包含N個人,共n張人臉圖像的樣本集使用交叉熵損失函數計算誤差,其中,tki為樣本k屬于類別i的概率,yki為CNN對樣本k預測為類別i的概率,交叉熵損失函數表達式為:
本文通過Adam優化算法對CNN參數進行更新。Adam優化算法是一種一階優化算法,收斂速度快,訓練高效,能根據數據迭代地更新神經網絡參數。定義待優化參數為w,目標函數為f(w),初始學習率為α。迭代優化過程中,在第s個epoch中計算目標函數對當前參數的梯度gs=▽f(ws)。根據歷史梯度計算一階和二階動量,一階動量為:
1.2? 特征融合
1.2.1? 單層特征合并
運用1.1節中的CNN進行訓練,在得到較高準確率后,保存CNN模型,利用訓練好的模型學習人臉特征。本文選取池化層P2和P3層作為子特征層。其中P3是除全連接層之外的最高層,包含高度抽象的類別信息,而P2處于卷積神經網絡的中間層,相較于P3屬于低層,包含人臉圖像的細節信息。
首先,將人臉圖像輸入訓練好的CNN模型當中,分別獲取P2層和P3層的特征。其中P2層包含128個16×16的特征圖,P3層包含256個8×8的特征圖。
隨后分別對來自不同深度的特征進行降維。將來自P2層的維度為16×16×128的特征圖進行縱向合并,轉換為16×16×1的特征圖FP2。將來自P3層的維度為8×8×256的特征圖進行縱向合并,轉換為8×8×1的特征圖FP3。合并方式為:
其中,Fk為合并后的特征圖,k=P2或P3。fi為第i個通道的特征圖。z為通道總數,處理P2層特征時z=128,處理P3層特征時z=256。
1.2.2? P2層和P3層的特征融合
為了使合并后的P2層特征FP2和P3層特征FP3進行融合,需要將特征大小進行歸一化。本文選擇將P3層的特征圖從8×8轉換為16×16。常見的圖像歸一化方法包括最近鄰插值法、線性插值法、區域插值法。其中,最近鄰插值法效果較好且計算簡便,因此本文選取最近鄰插值法對特征尺寸進行歸一化。
將P3層特征圖FP3大小表示為Fh×FW,目標圖像的大小為Th×TW,高度和寬度的縮放比例分別為hr=Fh/Th和Wr=FW/TW。目標人臉圖像(X,Y)處的像素值就等于原圖像中(X×Wr,Y×hr)處的值。將圖像在原圖基礎上擴大二倍,最近鄰插值法的效果如圖1所示。
對合并后的P2層特征FP2和P3層特征FP3進行尺寸歸一化后,FP2和FP3的尺寸都變成了16×16的一維矩陣。將來自不同深度的特征結合,保留高層高度抽象的類別信息與低層的細節信息,有助于提升分類的精度。因此將FP2和FP3進行加權融合,形成最終的特征,公式如下:
1.3? SVM分類
研究表明,SVM具有穩健性和稀疏性,分類效果好,且適用于小樣本。因此在對特征進行融合后,為了提升模型對于小樣本的泛化能力,取得更好的分類效果,選擇用SVM分類器對特征進行分類。
SVM屬于監督學習方法,其決策邊界是對樣本數據求解的最大邊距超平面。SVM最初僅用于二分類問題,當處理多分類問題時需要構造合適的多分類器。構造SVM多分類器的方法包括一對多法和一對一法。一對多法在訓練時依次將某類樣本歸為一類,其余樣本歸為一類。當有l個類別的樣本時,共構造出l個SVM。分類時將未知類別信息的樣本劃分為具有最大分類函數值的類別。一對一法是在任意兩個類別之間設計一個SVM分類器,對于l個類別的樣本需要設計l(l-1)/2個SVM分類器。分類時將未知類別信息的樣本劃分到得票最多的類別,這里采用一對一法實現SVM多分類。
在選擇適當的模型參數后,將1.2節中得到的特征F輸入到SVM多分類器中進行分類,得出最終的人臉識別結果。
2? 實驗與結果分析
2.1? 實驗環境與目的
本實驗環境為Intel(R) Core(TM) i5-6200U CPU @ 2.30 GHz處理器,8 GB運行內存。編程環境為Python 3.7,深度學習基于TensorFlow 2.0框架。分別在ORL人臉數據集和Cropped AR人臉數據集上驗證本文方法的有效性。
ORL人臉數據集中包含40人的人臉圖像,包括男性和女性,每人10張圖像,共400張。圖像大小為64×64。本文對ORL人臉數據集進行歸一化處理,并對圖像設置數字分類標簽,標簽范圍為0至39。如圖2所示,同一個人的人臉圖像有表情和角度的變化。通過此數據集評估本文方法對小樣本集的適應性。
Cropped AR人臉數據集中共包含1 300張人臉圖像。其中有50個不同人的人臉圖像,每人26張圖像。包含在不同光照、不同表情、不同面部遮擋的下的圖像,如圖3所示,由于光照、面部表情以及面部遮擋的影響,使得Cropped AR人臉數據集的識別難度比ORL人臉數據集更大。因此,通過此數據集評估本文方法對不同光照、表情、面部遮擋的魯棒性。
分別通過對比兩個數據集在CNN模型、CNN+SVM模型、特征融合的CNN+SVM上的分類效果,探究模型融合對分類效果的影響以及特征融合對模型分類效果的影響。同時將本文模型與其他人臉識別模型對比,證實本文模型的有效性。
2.2? 實驗流程
2.2.1? ORL人臉數據集實驗流程
將ORL人臉數據集中的400張圖像按照7:3的比例分割為訓練集和測試集,其中訓練集280張圖像,測試集120張圖像。
訓練階段,將訓練集人臉圖像輸入到本文構建的CNN模型中,設置batch size為40,epochs為100,對CNN進行訓練并保存,特征提取網絡的驗證集準確率隨epochs變化的曲線如圖4所示。
利用訓練好的CNN模型提取訓練集圖像在其不同深度的特征FP2和FP3。通過最近鄰插值法將FP2和FP3的尺寸進行歸一化后,將兩個特征進行加權融合,作為最終的分類特征。經實驗證明,當加權系數a=0.7時,特征融合效果最好。之后將訓練集的最終分類特征輸入SVM多分類器進行訓練,將此模型用于最終分類。其中采用一對一方法實現SVM多分類,核函數為線性核函數,目標函數的懲罰系數C為0.9。
測試階段,將測試集輸入保存好的CNN中提取特征。利用與測試集相同的方法得到融合特征,輸入訓練好的SVM多分類器得出分類結果,并與訓練集的真實標簽對比得出準確率。
將訓練集人臉圖像輸入到本文構建的CNN模型中,對CNN進行訓練并保存。通過訓練好的CNN提取測試集和訓練集人臉圖像在其不同深度的特征FP2和FP3。通過最近鄰插值法將FP2和FP3的尺寸進行歸一化后,將兩個特征進行加權融合,作為最終的分類特征。
利用訓練集得到的融合特征完成對SVM多分類器的訓練,其中SVM分類器采用一對一法,核函數為線性核函數,目標函數的懲罰系數C為0.9。將測試集得到的融合特征輸入SVM分類器,將預測結果與圖像的真實標簽對比得出最終的分類準確率。
2.2.2? Cropped AR人臉數據集實驗流程
將Cropped AR數據集中的1 300張圖像按照7:3的比例分割為訓練集和測試集,其中訓練集910張圖像,測試集390張圖像。
訓練階段,將人臉圖像輸入到構建好的特征提取網絡,由于Cropped AR數據集的數據量更大,因此在每個MaxPooling層之前加上batch normalization層,加速網絡訓練。設置batch size為32,epochs為30,對CNN進行訓練并保存,特征提取網絡的驗證集準確率隨epochs變化的曲線如圖5所示。
剩余實驗流程同ORL人臉數據集實驗流程。
2.3? 實驗結果分析
2.3.1? ORL人臉數據集實驗結果分析
2.3.1.1? 特征融合的有效性實驗
在ORL人臉數據集上,將基礎的CNN+SVM分類模型與輸入融合特征的CNN+SVM分類模型作對比,探究特征融合對模型分類的提升效果,實驗結果如表2所示。
從實驗結果可以看到,對于ORL人臉數據集,特征融合對模型分類精度的提升顯著。基礎CNN+SVM模型的輸入特征是未經融合的特征。從CNN中不同深度的提取出的特征具有不同的特性,深層特征更加抽象,具有更抽象的類別信息,而淺層特征更加具象,具有更多的細節信息。因此,在經過特征融合后,分類特征將包含更多有用的分類信息,有助于提升分類精度。
2.3.1.2? 與其他模型的效果對比實驗
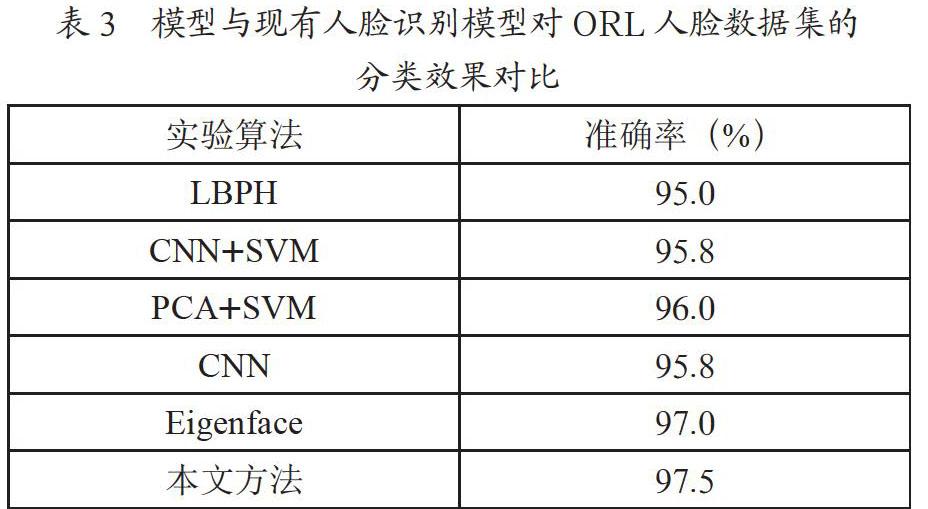
將本文模型與其他現有人臉識別方法進行對比,探究本文方法的有效性,實驗結果如表3所示。
根據實驗結果發現,與目前一些現有的人臉識別方法相比,本文模型在ORL人臉數據集上的識別率更高,說明分類模型建立效果良好。可見,本文模型對小樣本人臉數據效果較好。
2.3.2? Cropped AR人臉數據集實驗結果分析
2.3.2.1? 特征融合的有效性實驗
在Cropped AR人臉數據集上,分別使用CNN+SVM分類模型、輸入融合特征的CNN+SVM分類,探究特征融合對分類效果的影響,實驗結果如表4所示。
從實驗結果可以看出,對于Cropped AR人臉數據集,特征融合對于分類效果提升顯著。在對特征融合后,分類特征兼具細節信息和高度分類信息,更有利于最終的分類。
2.3.2.2? 與其他模型的效果對比實驗
將本文方法與其他人臉識別方法在Cropped AR人臉數據集的分類效果作對比,實驗結果如表5所示。
與目前的主流人臉識別算法比較,本文的準確率更高。因此,在面對光照不同、面部姿態不同、存在面部遮擋的人臉數據集時,本文方法依然具有魯棒性,能降低光照、姿態以及面部遮擋的影響,獲得較高的準確率。
3? 結? 論
構建卷積神經網絡模型將CNN的學習力與SVM對小樣本的適用性結合。首先,使用CNN對原始人臉圖像進行特征提取,將來CNN不同深度的特征進行提取并加權融合,最終使用SVM分類器進行分類。將淺層特征的細節信息與深層特征的抽象類別信息結合,提升了分類精度,證實了特征融合的有效性。通過在小樣本人臉數據集以及有光照、面部表情、面部遮擋變化的人臉數據集上的實驗驗證模型,實驗結果表明,本文方法在處理人臉圖像分類問題上取得了較好的效果。
參考文獻:
[1] 李潤青.基于PCA改進與SVM相結合的人臉識別算法研究 [D].昆明:昆明理工大學,2018.
[2] 張偉,程剛,何剛,等.基于Gabor小波和LBPH的實時人臉識別系統 [J].計算機技術與發展,2019,29(3):47-50.
[3] 任飛凱.基于卷積神經網絡人臉識別研究與實現 [D].南京:南京郵電大學,2019.
[4] SCHROFF F,KALENICHENKO D,PHILBIN J. FaceNet:A unified embedding for face recognition and clustering [C]//Proceedings of 2015 IEEE Conference on Computer Vision and Pattern Recognition,IEEE,2015:815-823.
[5] 黃振文,謝凱,文暢,等.遷移學習模型下的小樣本人臉識別算法 [J].長江大學學報(自然科學版),2019,16(7):88-94.
[6] 章東平,陳思瑤,李建超,等.基于改進型加性余弦間隔損失函數的深度學習人臉識別 [J].傳感技術學報,2019,32(12):1830-1835.
[7] SIMONYAN K,ZISSERMAN A. Very Deep Convolutional Networks for Large-Scale Image Recognition [J].Computer Science,2014,66(11):1556-1568.
[8] JIN X,TIAN X Y.Face alignment in-the-wild:A Survey [J].Computer Vision and Image Understanding,2017(162):1-22.
[9] GLOROT X,BORDES A,BENGIO Y. Deep Sparse Rectifier Neural Networks [C]//Proceedings of the 14th International Conference on Artificial Intelligence and Statistics,2011:315-323.
[10] 尹紅,符祥,曾接賢,等.選擇性卷積特征融合的花卉圖像分類 [J].中國圖象圖形學報,2019,24(5):762-772.
[11] 翁雨辰,田野,路敦民,等.深度區域網絡方法的細粒度圖像分類 [J].中國圖象圖形學報,2017,22(11):1521-1531.
作者簡介:梁晴晴(1997.10—),女,漢族,河南鄭州人,碩士研究生,研究方向:調查與大數據分析。
猜你喜歡
作文中學版(2022年1期)2022-04-14 08:00:34
學生天地(2020年31期)2020-06-01 02:32:06
電子制作(2019年14期)2019-08-20 05:43:34
中國交通信息化(2018年1期)2018-06-06 07:29:55
電子制作(2017年17期)2017-12-18 06:40:55
中國公共安全(2017年7期)2017-10-13 08:18:26
電子制作(2017年1期)2017-05-17 03:54:46
中國公共安全(2017年9期)2017-02-06 03:05:32
現代工業經濟和信息化(2016年6期)2016-05-17 05:36:23
華東理工大學學報(自然科學版)(2015年2期)2015-11-07 09:16:51
