基于機器學習方法的油井日產油量預測
2020-06-16 05:24:26劉巍劉威谷建偉
石油鉆采工藝 2020年1期
劉巍 劉威 谷建偉
中國石油大學(華東)石油工程學院
油井產量動態預測對認識油藏、改善油井工作制度、編制科學合理的開發調整方案具有重要指導意義。油藏數值模擬是油田產量預測最常用方法,但其準確性依賴于高質量的歷史擬合和準確的地質建模。歷史擬合耗時長,工作量大,同時前期建模過程需要大量地質資料、流體物性資料和動態開發資料。為克服數值模擬計算這一缺陷,利用機器學習方法[1-2]建立了油井產量預測模型,依托現場易獲得的開發動態參數實現產量的快速準確預測[3-4]。
利用機器學習算法建立產量預測模型簡便實用,許多學者通過BP神經網絡[5-8]和支持向量機(SVM)[9]等機器學習方法來實現油井產量的動態預測。其應用結果表明,該類基于數據挖掘思想的油田產量預測方法具有很好的應用價值。但這些傳統的機器學習方法構造的是一種點對點的映射,忽略了產量隨時間的變化趨勢和數據間的前后關聯性[10]。長短期記憶神經網絡(LSTM)是一種改進的循環神經網絡(RNN)[11],具有自循環結構,上一時刻的輸入會影響當前時刻的輸出,同時通過 “門”結構,選擇性遺忘對當前時刻不重要的“經驗”,記憶重要時刻的“經驗”知識,從而具備較長時間范圍內的記憶功能[11]。基于該方法預測產量能準確反映其變化趨勢,更適合產量時序預測。
基于廣泛應用于時序數據學習和預測的長短期記憶神經網絡(LSTM)來預測油井產量,能保留先前的產量信息并傳遞到后續時間節點的產量預測,充分考慮生產動態數據的變化趨勢和前后關聯性,更深層次挖掘數據間的潛在規律,預測結果更為準確可靠,符合實際產量變化情況。
1 原理與方法
1.1 MDI 特征選擇
準確選取影響油井產量的主要特征參數,對于提高模型的泛化能力和預測精度具有重要意義。基于決策樹模型的特征選擇準則——平均不純度減少(MDI),計算每個特征對樹模型預測誤差的平均減少程度,并將該值作為特征重要性的度量依據。在決策樹生成策略中,分類樹和回歸樹的生成都是選擇某個特征,并計算該特征對決策樹的不純度的減少程度來選擇特征作為決策樹的節點。因而,在決策樹的訓練過程中可以保存每個特征平均減少了多少不純度,用來衡量這個特征的重要程度。對于分類問題,通常采用基尼不純度或者信息增益,對于回歸問題,可以采用方差或者其他合理的不純度衡量方法。采用特征對于決策樹模型預測誤差的變化大小來度量特征參數的重要性,計算過程如下。
假設存在m個特征(x1,x2,···,xm),利用這m個特征和觀測值yo所構成的數據集訓練隨機森林(RF)模型。訓練前RF 模型初始預測誤差es為

在RF模型的生成過程中,依次給模型增加特征節點。當選定并添加特征節點xi時,得到RF 模型的預測誤差ei。因而特征xi對于響應變量y的重要性可用MDI值(MDIi)定義為

依次添加剩余特征,直至遍歷完所有特征時,停止決策樹的生長,同時得到其余特征參數的MDI值。一般而言,與油井產量無關的特征參數,其MDI值較小。但是,當特征間存在協同作用時(如:同時選定特征a、b時模型的預測精度比單獨選定特征a或b時的高),會導致其中一個特征的重要性偏低。因而,首先依據各個特征參數的MDI值,以從大到小順序對特征進行排序。進而剔除MDI值較小的特征,觀察該特征對模型預測精度的影響。若預測精度保持不變,則可認定該參數為冗余的無效特征;若模型的預測精度變化較大,則說明該特征與候選特征中的特征存在協同作用,保留該特征。根據MDI 值從小到大順序繼續剔除特征,重復上述過程直至無候選特征為止,從而可剔除特征集中的無效特征參數。此時,保留的特征參數即為與油井產量最相關的有效特征參數。基于上述方法篩選出來的有效特征參數結合油井產量數據構成標準數據集,用于LSTM 模型的訓練和測試。
1.2 LSTM 神經網絡原理
傳統BP神經網絡輸入和輸出相互獨立,無法考慮先前時刻的輸入對當前時刻輸出的影響,因此不能有效處理時序數據問題。RNN 具有自循環結構,可將先前時刻處理的信息傳遞給下一時刻計算輸出,從而給網絡賦予了“記憶能力”,使RNN 的輸出不僅受到當前輸入影響,還受過去所有步驟輸入影響[12]。RNN的這一優勢使其成為解決序列問題時最自然的神經網絡結構,計算過程如下
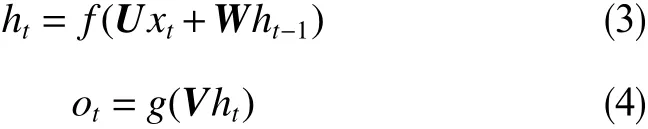
其中,ht為t時刻隱藏層狀態;U為輸入層權重系數矩陣;xt為t時刻輸入;W為隱層神經元之間權重系數矩陣;ot表示t時刻輸出;V為輸出層權重系數矩陣;f和g分別表示輸入層和輸出層的激活函數。
參數矩陣W在每次計算中被共享,所以在狀態傳遞過程中相當于乘以Wt。當訓練的序列較長時(即t較大),Wt可能趨向于0或無窮大,即梯度消失或爆炸。對于1個時間序列,先前時刻信息的記憶都會以指數級的速度被遺忘,最終導致長距離的信息很難在網絡中傳遞。LSTM是一種改進的循環神經網絡,可以很好地解決長時依賴問題,更適合油井產量的時序預測。
LSTM和普通的RNN 相比,增加了遺忘門、輸入門、輸出門和記憶單元,網絡結構如圖1所示。

圖1 LSTM 網絡結構Fig.1 Structure of LSTM network
遺忘門可控制上一時刻隱藏層狀態的遺忘程度,ft取值為0時表示無信息通過,取值為1表示信息完全通過,保留這一時刻的記憶。數學表達式為

輸入門首先通過sigmoid 層決定哪些值用來更新,然后通過一個tanh 層生成新記憶候選值并決定新記憶寫入長期記憶的程度。數學表達式為

將記憶單元保留的舊記憶狀態Ct?1與新的候選值結合,并由遺忘門輸出值ft和輸出門的計算結果it分別決定舊記憶狀態和新信息被遺忘和保留的程度,更新記憶單元狀態,數學表達式為

輸出層通過sigmoid 層得到一個初始輸出,并結合tanh 層決定模型最終的輸出值。表達式為

上述式(6)~(10)中, σ表示sigmoid 層激活函數;ft表示t時刻遺忘門的輸出;Wf、bf分別表示遺忘門權重和偏置項;it表示t時刻輸出層的輸出;Wi、bi分 別表示輸入門權重和偏置項;WC、bC分別表示tanh 層的權重和偏置項;Wo、bo分別表示輸出層的權重和偏置項;Ct表示記憶單元在t時刻的狀態;ot意義與式(4)相同;表示t時刻tanh 層的輸出;tanh 表示激活函數。
LSTM通過門控制器和新的記憶單元,在RNN原有短期記憶上保留了長期記憶,對長序列的理解分析能力大幅度提高,能更好地適應具有長時依賴特征的時序預測問題。油井產量變化具有較強的前后關聯性,利用LSTM神經網絡能更有效學習和挖掘產量數據變化規律,實現產量的準確預測[13-14]。因此,采用LSTM 建立產量預測模型更合適。
1.3 模型評價指標
在測試集上評價預測模型的泛化能力,即模型的產量預測效果。采用的預測效果評價指標主要包括:決定系數R2、平均相對誤差 δr、均方誤差 δa。
決定系數R2計算公式為

平均相對誤差也作為模型訓練的代價函數,其公式為

均方誤差計算公式為

式中,yi為第i個樣本或第i時刻實測產量,t/d;N為樣本個數為LSTM模型在i時刻或第i個樣本處產量預測值,為實測產量平均值,t/d。
1.4 基于MDI特征選擇的LSTM 產量預測模型
基于MDI特征選擇的LSTM 油井日產油量預測模型主要包括以下步驟:① 對構建的數據集劃分為訓練集、驗證集和測試集,分別用于模型的訓練、超參數調優和模型預測效果評價;② 對輸入特征基于MDI 方法分析各個變量的重要性,篩選出油井日產油量的影響因素,剔除掉無關特征;③為了消除特征之間量綱差異給模型帶來的誤差,并加快模型訓練速度,對各個輸入特征進行歸一化處理,建立標準的機器學習數據集;④在訓練集上對LSTM 模型進行訓練,并在驗證集上,通過網格搜索確定LSTM的最優超參數,得到最終的預測模型;⑤在測試集上對比模型預測結果與實際值的差距,測試LSTM模型的預測效果。基于MDI特征選擇的LSTM油井日產油量預測方法的流程圖如圖2所示。

圖2基于MDI 特征選擇的LSTM 日產油量預測方法的流程圖Fig.2 Flow chart of LSTM daily oil production prediction method selected on the basis of MDI characteristic
2 實例應用
2.1 樣本選取
選取某油田25FLW 井區為研究對象,其位于東營渤中凹陷,油藏埋深1 395~1 455 m,油氣成藏條件優越,石油地質儲量為517×104t。該油藏從1999 年投入開發,至今已有25口油井和15口注水井,選取其中1個井區作為產量預測的研究對象。該井區包含5口生產井(25FLW-1,25FLW-2,25FLW-3,25FLW-4,25FLW-5)和4口注水井(25FLW-11,25FLW-12,25FLW-13,25FLW-14)。根據油藏工程師經驗,影響油井產量的因素主要包括4類:第1類是當前油井的井口壓力,原始含水飽和度,泵排量,生產時間,含水率;第2類是周圍油井的產液量;第3類是周圍注水井的井口壓力和注水量;第4類是油藏剩余可采儲量。收集和整理這5口生產井從投入開發至2018年11月的上述4 類特征參數和日產油量數據,并分別以6∶2∶2的比例將各生產井的數據集劃分為訓練集、驗證集、測試集。
2.2 數據預處理
對統計和整理好的油田現場數據進行清洗和處理。數據的清洗工作主要包括清除數據中的異常點,補全缺失數據,保證整個生產時段內數據的完整性和有效性。同時,為加快模型訓練速度和提高預測精度,對收集的數據進行歸一化處理,其公式如下
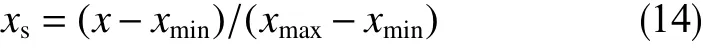
式中,x表示待歸一化的參數,xmin、xmax分別表示參數的最大值和最小值。
2.3 特征選擇
基于MDI 特征選擇方法,分析各個靜態特征參數和動態特征參數對于油井產量的重要性,以油井25FLW-1 為例,各個特征重要性計算結果如圖3所示。
圖3坐標縱軸表示各特征參數,橫軸表示特征參數對產量的重要性程度。井區剩余可采儲量和25FLW-1井的井口壓力對該井產量影響較大,而產量與該井原始含水飽和度、泵排量無關。由于這些參數在25FLW-1 井生產過程中幾乎一直保持為定值,對產量的變化沒有任何貢獻,因而在建立該井產量預測模型過程中可剔除該類特征。同時,根據特征的MDI值從小到大順序,逐次排除特征參數,剔除掉對模型預測精度沒有影響的冗余特征,則此時剩下的特征參數為影響油井產量有效特征。最終基于MDI 特征分析結果和特征篩選過程,剔除掉了25FLW-11井的原始含水飽和度、泵排量、井口壓力和25FLW-13井注水量這4個變量,確定有效特征參數共14個,作為LSTM模型輸入變量。
2.4 模型訓練和超參數調優
根據確定的有效特征參數與油井日產油量構成的訓練集,基于Adam 學習算法,對LSTM神經網絡進行訓練,優化神經網絡的各個權重系數;在驗證集上通過網格搜索,確定模型最優網絡結構參數:
epochs=750;batch_size=35;time_step=10; hidden_nodes=30。訓練過程中模型損失函數隨訓練次數的變化過程如圖4。可以看出,模型的損失函數隨訓練次數增加而逐漸減小并趨于穩定,且訓練集與驗證集的損失函數非常接近,說明LSTM預測模型沒有出現過擬合或欠擬合的現象,模型具有較好的泛化能力,可用于25FLW-1井的日產油量預測。

圖4訓練集和測試集損失函數隨訓練次數的變化過程Fig.4 Variation of the loss function of training set and testing set with the training times
2.5 產量預測與分析
以25FLW-1井為例,利用訓練好的LSTM產量預測模型,預測25FLW-1油井在2018年6月21日—11月1日的日產油量,與實際監測數據對比,部分結果如表1,平均相對誤差為4%,滿足工程計算要求。整個測試集上的產量預測值與實際值對比結果如圖5,LSTM 模型預測的油井日產量與實測產量高度一致,模型預測效果評價指標有:決定系數R2=0.78,平均相對誤差δr=0.04,均方誤差δa=1.07。結果均表明基于LSTM的產量測模型準確掌握了產量變化趨勢和前后關聯性,能準確預測油井未來日產量變化。因此,LSTM 日產油量預測模型可用于礦場應用,且該模型可用于該井區和油田其他生產井的日產油量預測,根據給定的數據集進行機器學習,深度挖掘數據中隱藏的控制機制,得到適用于每口生產井的LSTM 日產油量預測模型。

表1 25FLW-1井產量預測值與實際值對比Table 1 Comparison between the predicted production of Well 25FLW-1 and the actual value
基于訓練好的模型,可進行注采方案快速評估。當改變注水井注入量時,根據LSTM預測模型,可快速預測相應控制條件下的產量,實現注采方案合理性的快速判斷和調整。以25FLW-1井為例,保持其他生產參數不變,改變注水井25FLW-11的注水量,根據訓練好的LSTM 模型預測油井25FLW-1的日產油量變化,如圖6所示。從結果可看出,增大25FLW-11井的注水量能有效提高25FLW-1井的產油量,這一結果可用于快速判斷注采方案的合理性,調整和優化注采方案。或用于診斷油井是否出現故障,即當產量沒達到預期值時,可考慮檢查采油設備等儀器是否出現故障。
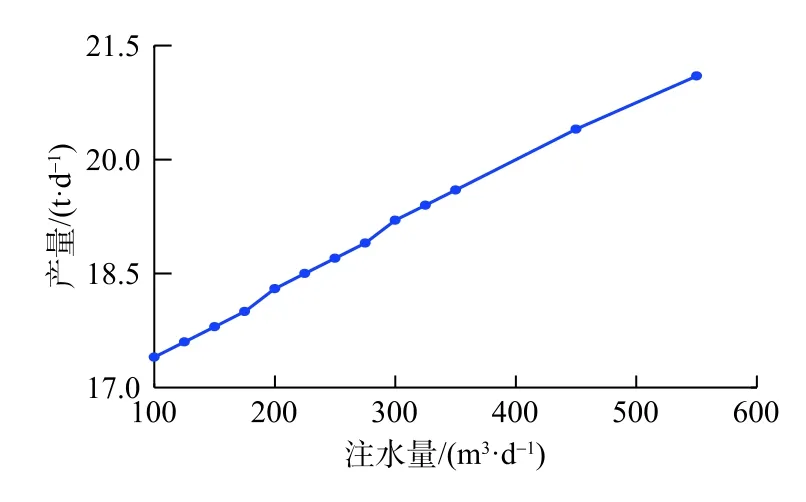
圖6 25FLW-1井產量隨注水量的變化關系Fig.6 Variation of Well 25FLW-1’s productionwith water injection rate
3 結論和建議
(1)建立了一個基于LSTM網絡的油田產量預測模型,利用現場簡便易得的開發動態數據和地質參數即可實現油田產量的快速準確預測。
(2)基于MDI的特征選擇算法能夠有效篩選出影響油井產量的主要因素,有助于認識油井產量與各因素之間的相關關系,同時為降低模型復雜度、提高模型泛化能力奠定基礎。
(3)建立的產量預測模型能快速有效預測油田產量,可進一步應用于油藏開發的生產優化研究,為后期注采參數的優化調整提供依據。
(4)可以進一步考慮停井、生產工藝和增產措施等因素對產量的影響改善模型。同時,可將建立的方法進一步應用于油井產水量和氣油比等生產指標的預測,實現油氣田多生產指標的快速預測。
猜你喜歡
礦山安全信息(2022年40期)2022-04-07 02:16:52
當代水產(2021年10期)2021-12-05 16:31:48
今日農業(2020年20期)2020-11-26 06:09:10
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
聚氯乙烯(2018年9期)2018-02-18 01:11:34
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
作文周刊·小學一年級版(2016年27期)2017-06-03 23:21:17
新湘評論·下半月(2016年4期)2016-05-05 22:12:41
新湘評論·下半月(2016年4期)2016-05-05 22:12:41
