
基于改進IPSO-BP算法的CAM編程切削參數預測*
2020-06-21 08:17:02李俊銘吳居豪龍耀武陶建華
機電工程技術 2020年5期
關鍵詞:模型
李俊銘,吳居豪,何 軒,龍耀武,陶建華※
(1.廣州大學機械與電氣工程學院,廣州 510006;2.廣州市德慷軟件有限公司,廣州 510620)
0 引言
計算機輔助制造(CAM)是指在計算機上對零件進行編程加工,生成數字控制指令(NC)使機器進行自動加工的軟件系統,是機床加工不可或缺的部分。使用CAM軟件進行編程加工時,除了根據模具特征編寫合適的加工策略,還需依據各類機床、刀具等加工信息選用合適的切削參數[1-2]。由于制造業(yè)高級技術人才缺乏,人員流動加劇,技術水平參差不齊,影響制造企業(yè)的生產效率和產品質量[3]。近年來,對自動計算機輔助加工規(guī)劃(ACAPP)的需求不斷增加,加工參數預測是重要環(huán)節(jié)之一[4]。傳統的參數預測通過試切實驗結合專家規(guī)則進行參數推薦,時間和經濟成本大,難以適應模具行業(yè)多變的加工需求。近年來,有不少研究基于支持向量機(SVM)、BP(Back Propagation)等算法通過采集機床運行過程中震動、電流及聲音等信號,對加工參數實時調整[5-7]。由于硬件兼容性問題,這類方法對機床型號有嚴格限制,難以大范圍推廣。
本文采用基于歷史加工數據進行參數預測的技術解決方案。收集并篩選滿足企業(yè)加工要求的CAM歷史項目文件,對CAM軟件進行二次開發(fā)獲取相關加工信息,包括選用機床、策略、刀具相關信息及對應的切削參數。用IPSO-BP算法建立并不斷更新參數預測模型,實現針對不同加工信息的切削參數(軸切深、徑切深、轉速、進給)預測。在復雜加工編程的應用場景中,上百條刀路對應的切削參數自動由軟件生成并輸入CAM系統中,編程人員只需要檢查數據的合理性,從而提升加工編程的效率和編程質量。
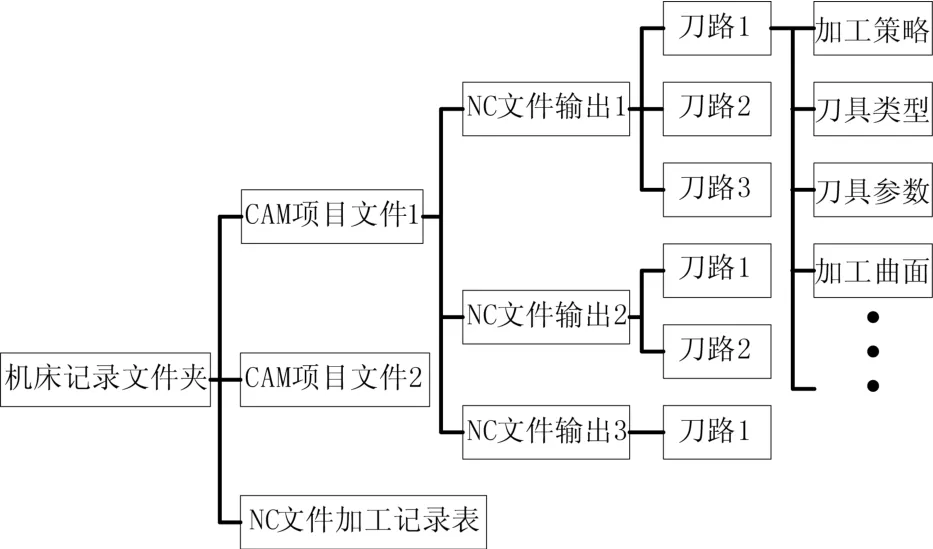
圖1 CAM項目文件數據結構
1 CAM軟件數據提取與處理
1.1 數據提取
為了獲取加工數據信息與對應的切削參數,選用模具行業(yè)中常用的CAM軟件Power MILL結合VB語言進行二次開發(fā)[8],調用CAM軟件的應用程序接口(API)運行宏命令提取刀路中包含的信息。CAM項目文件的數據結構如圖1所示。由圖可知CAM項目文件中保存多條NC文件信息,存在不同NC包含相同刀路的情況,通過過濾重復刀路避免采集重復數據信息。當數據樣本中出現切削參數不同,其他加工信息均相同時,只保留數值最大的切削參數,從而保證樣本中的切削參數是可靠而且高效的。具體提取步驟如圖2所示。

圖2 CAM項目數據采集流程
1.2 信息提取及參數選擇
從CAM軟件中采集數據時,既要保證數據能夠客觀反映影響切削參數(軸切深、徑切深、轉速、進給)的各種條件,又要控制特征數量防止數據稀疏導致訓練模型過擬合。擬合歷史項目的切削參數設置需要從加工編程的角度出發(fā)。針對CAM編程特點,提出加工特征評價體系,具體分為加工類型、策略類型、機床性能、刀具類型和刀具參數5個大類影響因素[9],如圖3所示。
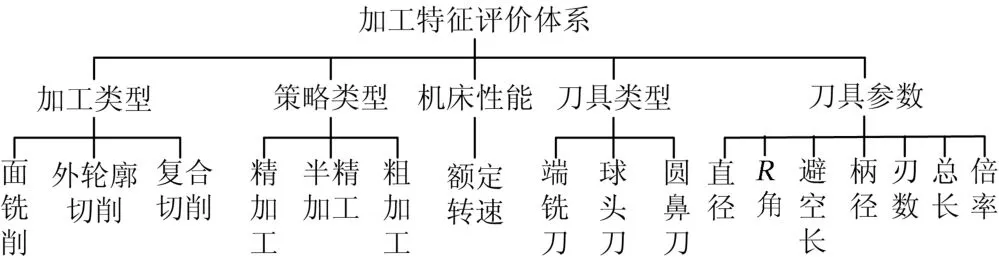
圖3 加工特征評價體系
針對評價體系中各特征的數據結構和相互聯系,將特征分為離散型數據和連續(xù)型數據進行數據預處理。其中加工類型、策略類型和刀具類型均為離散型數據,使用獨熱編碼(one-hot)對特征進行向量化分析[10]。考慮到一般企業(yè)將刀具參數作為公式進行處理,將各刀具參數作為連續(xù)型數據,分別進行歸一化操作,保證數據量綱一致[11]。
2 預學習IPSO-BP網絡訓練模型
切削參數預測是一個多維特征的非線性擬合問題。BP具有高度的非線性和優(yōu)秀的擬合能力,非常適合解決這種多維非線性問題。但由于BP網絡自身缺點,提高精度會導致擬合速度下降,并更容易陷入局部最小值點[12]。IPSO粒子群算法具有很強的全局尋優(yōu)能力,并且運算效率高,適合與BP網絡兩者優(yōu)勢互補。
2.1 訓練BP神經網絡
對于一個切削參數預測模型,輸入層和輸出層需要體現不同加工特征與選用切削參數的關聯。輸入層以加工特征評價體系為標準,將預處理后的加工類型、策略類型、機床性能、刀具類型和刀具參數5類共18維數據特征作為輸入的18個神經元X=(X1,X2,…,X18);輸出層以對應的軸切深、徑切深、轉速、進給作為輸出的4個神經元Y=(Y1,Y2,Y3,Y4)。考慮到輸入維數較多,中間設置兩層隱含層學習特征,通過多次前向傳播和后向傳播的學習過程訓練合適的權重ω=(ω1,ω2,…,ωN)預測切削參數。網絡的模型結構如圖4所示。
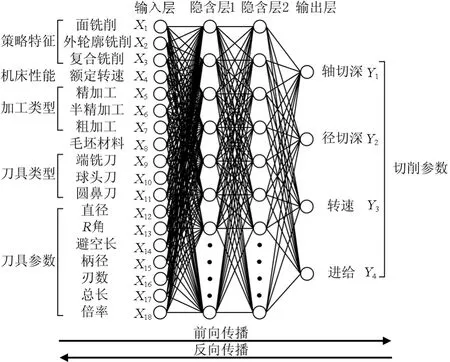
圖4 網絡模型結構
前向傳播的計算過程如式(1)所示:

式中:netin代表網絡中每個節(jié)點上一層節(jié)點的輸出值;netout節(jié)點進行計算后的輸出值;對隱含層1,netin=X,對于輸出層,netout=Y′,代表切削參數在這次前向傳播的預測值;在隱含層1、隱含層2的計算過程中F=F1(X);輸出層的計算過程中F=F2(X)。
反向傳播的計算過程如式(2)和式(3)所示:

式中:通過對模型預測的切削參數y′與歷史數據中切削參數y2和誤差E求導,獲取最小的梯度方向,更新各單元間權重ω′i;lr為更新的學習率。
2.2 改進IPSO粒子群算法
為了快速找到全局權值最優(yōu)值,運用IPSO粒子群算法。先初始化一定數量的BP網絡權重值 ω=(ω1,ω2,…,ωn)作為粒子。將粒子輸入進BP網絡前向傳播中計算網絡權重為當前粒子的權重值時對應誤差E,并依據結果尋找每個粒子的歷史損失最小的權重 pbest和種群中最小的權重gbest,從而計算權重變更速度矢量并更新權重值[13]。粒子權重值更新流程如圖5所示。

圖5 粒子權重值更新流程
訓練方式如下:
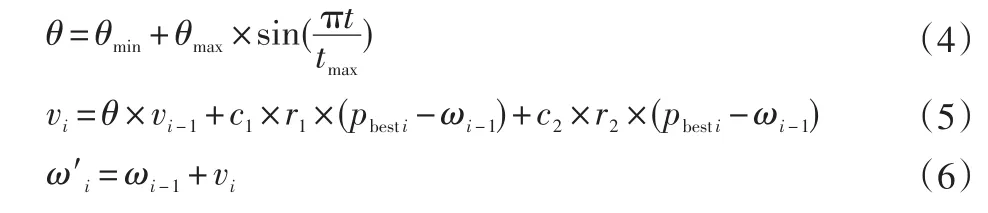
式中:vi、ωi分別為第i個粒子在迭代t+1次后的權重變化速度矢量和權重值;pbesti為迭代t次后的粒子最佳位置;gbesti為迭代t次后的種群最佳位置;θ為慣性權重;θmin為基本慣性權重;θmax為衰減慣性權重;tmax為最大迭代次數;t為當前學習次數;c1和c2為學習因子;r1和r2為0~1之間的隨機數。
2.3 限制權重范圍改進IPSO
由于IPSO與BP訓練原理不同,IPSO訓練出來的權重數值分布有較大差異。對切削參數預測模型進行更新的過程中,可能權值范圍發(fā)生較大改變,部分切削參數預測準確率下降。所以在第一次訓練時需要進行一次預學習探索ωIPSO合理分布范圍,對IPSO的速度矢量和權重值按BP網絡結構分層限制。公式如下:
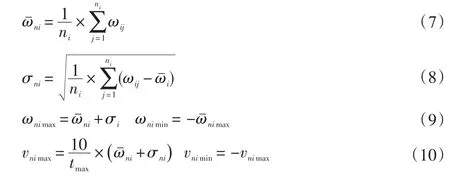
式中:ni對應BP不同層之間的權重,n1對應輸入層與隱含層1的權重,n2對應隱含層1與隱含層2的權重,n3對應隱含層2與輸出層的權重;ωˉni為該組權重的平均值;ωnimax與ωnimin分別對應該組權重的最大最小值;vnimax與vnimin分別對應該組權重對應速度矢量的最大最小值;tmax為IPSO最大迭代次數。
權重范圍的訓練結果如表1和表2所示,同一數據集和超參數下不同算法損失誤差變化曲線如圖6所示。

表1 權重平均值

表2 權重標準差

圖6 訓練損失誤差變化曲線
從表1和表2可看出,經過預學習環(huán)節(jié)后BP網絡各層權重的平均值與標準差均與單純訓練BP網絡得到的結果更為接近,說明預學習能有效提高IPSO權重計算的性能。從圖6對比也證明經過預學習環(huán)節(jié)后模型收斂速度大幅提高,也避免誤差反彈的情況。
2.4 模型訓練流程
模型訓練具體訓練步驟如下:
(1) 在第一次訓練時,先將BP權重 ω=(ω1,ω2,…,ωN)初始化為均值為0,方差為1。對加工特征信息X=(X1,X2,…,X18)和對應切削參數Y=(Y1,Y2,Y3,Y4)分別用不同的超參數進行測試,通過減少循環(huán)次數控制學習時間。由此找到損失最小的超參數組合和各層權重的分布范圍。
(2)根據權重分布情況限定粒子群算法中權重的分布范圍。隨機生成一定數量的權重作為粒子,依次代入BP前向傳播中計算損失E。每次訓練中對單個粒子歷史損失最小的權重更新 pbest,對種群中最小的的權重更新gbest,并更新速度矢量和權重。

圖7 預測模型訓練流程圖
(3)將BP的權重設為IPSO算出的最佳權重值再進行訓練,只調整學習率lr,不改變隱含層節(jié)點數量。直到預測誤差滿足要求后保存切削參數模型。
預測模型的整體訓練流程如圖7所示。
3 仿真結果與分析
仿真數據集采用從收集模具企業(yè)2018年保存的CAM項目文件中提取2 000組數據。選擇其中1 600組作為模型的訓練數據,200組作為模型驗證數據,200組作為模型測試數據。訓練結果如表3所示。
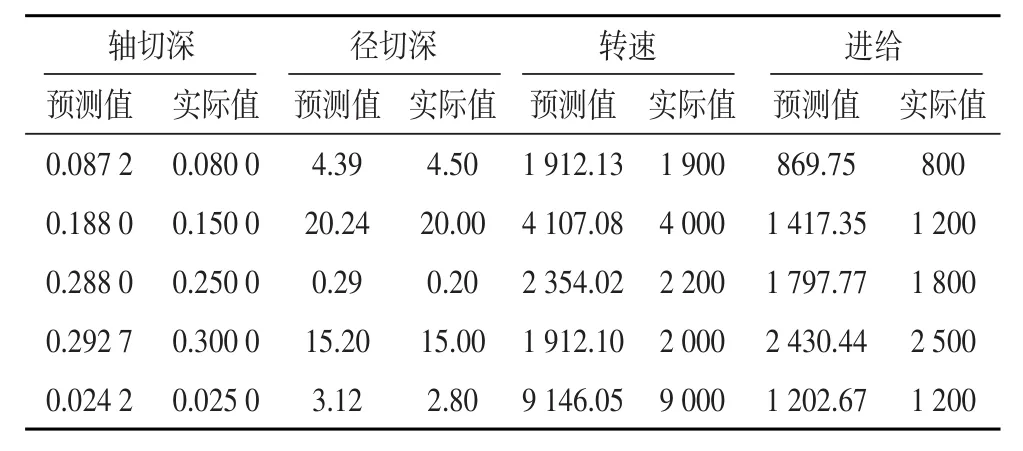
表3 預測結果表
從預測參數對比可知,各項的預測值與經驗判斷出來的切削參數基本一致,平均相對誤差在2%~5%之間,滿足加工的參數要求,可導入CAM中進行刀路編程。也有極少局部點出現較大誤差,其相對誤差最高在20%左右。雖然滿足加工安全條件但可能影響加工質量,需要編程人員適當調整。通過采集更多的歷史項目數據,可以進一步提高預測精度。
4 結束語
針對切削參數預測問題,本文提出一種基于改進IPSO-BP的切削參數預測方法。通過對CAM項目文件進行數據采集,提取歷史加工特征及切削參數。利用改進IPSO算法優(yōu)化BP神經網絡參數,并與其他預測模型的測試結果對比,該方法可以取得更高的預測精度和穩(wěn)定性。在自動計算機輔助加工規(guī)劃的參數規(guī)劃領域具有一定的應用價值。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
網絡安全與數據管理(2022年1期)2022-08-29 03:15:20
導航定位學報(2022年4期)2022-08-15 08:27:00
中學生數理化·中考版(2022年8期)2022-06-14 06:55:24
新世紀智能(數學備考)(2021年9期)2021-11-24 01:14:36
成都醫(yī)學院學報(2021年2期)2021-07-19 08:35:14
新世紀智能(數學備考)(2020年9期)2021-01-04 00:25:14
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
光學精密工程(2016年6期)2016-11-07 09:07:19
