基于推薦系統在量化選股中的應用
2020-06-22 08:35:54三亞學院信息與智能工程學院宣哲鵬駱銷奇董浩王義蒙誠新張晶
河北農機 2020年5期
三亞學院信息與智能工程學院 宣哲鵬 駱銷奇 董浩 王義 蒙誠新 張晶
想在海量的數據信息中找到自己需要的信息,或者信息的制造者要讓其信息在海量的信息中快速被搜索出來,就要用到推薦系統。從量化選股中的應用來說,推薦系統挖掘用戶與所選股票數據之間的關系,在大量的股票數據中找到用戶可能感興趣的股票,并針對用戶生成個性化推薦以滿足個性化需求。那么,用戶在面對大量的股市信息時,不能快速在這些信息中找到有用以及與其相關的信息,本文提出推薦系統應用在股票推薦中,對基本面數據、技術分析數據、新聞資訊等多項指標進行檢測與匯總,結合用戶平時的偏好,為用戶智能推薦符合需求的股票。
1 推薦系統發展
推薦系統的興起與互聯網的發展緊密相關。推薦系統的自動化協同過濾系統最早可以追溯到1994 年,明尼蘇達大學計算機系的GroupLens 研究組設計了名為GroupLens 的新聞推薦系統。該工作組不僅首次提出了協同過濾的思想,并且為推薦問題建立了一個形式化的模型,給隨后幾十年推薦系統的發展帶來了巨大影響。該研究組后來創建了MovieLens 推薦網站,一個推薦引擎的學術研究平臺,其包含的數據集是迄今為止推薦領域引用量最大的數據集。
2 推薦系統主要研究內容
推薦系統結構一般包括用戶信息獲取和建模、推薦算法研究、推薦系統的評價問題。推薦系統根據股票用戶的興趣需求信息和推薦對象的模型和特征信息匹配,使用相對應的推薦算法進行計算,找到推薦給股票用戶可能感興趣的股票數據信息。
2.1 用戶信息獲取和建模
推薦系統通過獲取信息與用戶交互的系統的轉化,將數據挖掘技術應用到信息獲取中,挖掘股票用戶的內含的隱性需求數據信息。
2.2 推薦算法研究
根據股票用戶對個性化推薦的實現接受和認可,設計出準確及高效的個性化推薦算法,內容的推薦和協同過濾是最主要的兩種推薦算法,為了克服各算法的缺點,將各種推薦方法混合使用,以提高推薦精度和覆蓋率。
2.3 推薦系統的評價問題
為了使股票用戶接受推薦系統,對推薦系統作客觀綜合的評價,推薦出來的結果的準確性、可信性是非常重要的。
3 StockRanker 算法量化選股
3.1LSTM Networks 是遞歸神經網絡(RNNs)的一種,LSTM在股票預測中對小數據集效果很好,可容納時間序列的記憶效應,如持久性、均值回歸等
在深入學習中,長短期記憶LSTM可類比于ARIMA 長期短期記憶模型。LSTM對RNN 進行了結構上的修改,來避免長期依賴問題。LSTM在股票預測中通常分為兩類應用:(1)把LSTM輸出結果看成單信號從而對個股做回測。(2)把LSTM預測結果看作選擇時的信號,與另外的選股模型相結合做回測。
3.2 用戶在面對大量的股市信息時,不能快速在這些信息中找到有用以及與其相關的信息,StockRanker 算法是專為選股量化而設計的,核心算法主要是list- wise 排序學習和梯度提升樹GBDT
股票市場和圖像識別、機器翻譯等機器學習場景有很大不同。StockRanker 算法能夠充分考慮三者的不同并根據不同的特點,可以同時對全市場3000 支股票的數據進行計算,并預測出股票的大致波動。結合用戶平時的偏好,為用戶智能推薦符合其需求的股票。StockRanker 算法中的排序學習被廣泛應用于監督學習方法,比如推薦系統的候選產品、用戶排序,搜索引擎的文檔排序,機器翻譯中的候選結果排序等;StockRanker 算法梯度提升樹(GBDT),有多種算法可以用來完成排序學習任務,比如SVM、邏輯回歸、概率模型等;StockRanker開創性地將排序學習和選股結合,并取得顯著的效果。
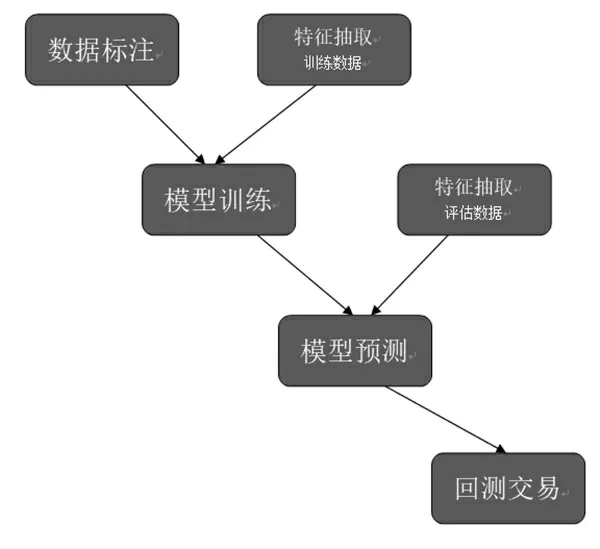
StockRanker 的結構圖
4 推薦系統算法的優化
推薦系統廣泛應用于為股票用戶推薦個性化需求的推薦。一般由基礎數據、推薦算法系統、前臺展示對用戶的歷史數據進行處理。以股票用戶訪問頁面、股票的瀏覽、交易的下單、選股的收藏等多維度信息為基礎數據;個性化訴求的推薦有多個算法組成的推薦模型是推薦系統算法系統的主要依據;前臺展示即通過用戶的客戶端系統的響應,返回與之相關的股票推薦信息。
協同過濾算法是在推薦領域中最廣泛的算法應用,被稱為基于用戶行為的推薦算法,其算法不需要預先獲得用戶或股票的特征數據,僅依賴用戶的所使用過歷史行為數據并對其進行建模,最后推薦給股票用戶。基于用戶的協同過濾、基于股票的協同過濾、隱語義模型等是協同過濾算法的主要內容。統計學方法對數據進行分析是基于用戶和股票的協同過濾,因此也被稱為基于內存的協同過濾或基于鄰域的協同過濾。推薦系統中的用戶協同過濾算法獲得了極大的成功,但其算法本身有局限性。股票的協同過濾算法與用戶的協同過濾算法基本類似。該算法以用戶對股票或者信息的偏好為依據,發現各個股票之間的相似度,根據用戶的瀏覽歷史所顯現的偏好信息,將類似度高的股票推薦給用戶。隱語義模型是采用機器學習等算法、學習數據得出模型,再進行預測和推薦。
5 總結
目前,深度神經網絡發展迅速,為量化選股推薦系統提供了新的特征提取、排序方法,越來越多的推薦引擎將深度神經網絡與傳統的推薦算法相結合,用于解決數據稀疏、推薦排序等問題,深度神經網絡和推薦系統的結合將是推薦系統未來的主要研究方向。讓大多數用戶接受量化選股推薦系統,需要提高推薦選股結果的準確性、可信性,如何斷定推薦結果的準確性,如何將推薦結果展示給股票用戶以及如何獲取用戶的評價,及在推薦算法研究中對克服各自的缺點將各種推薦方法混合使用都是需要深入研究的問題。
猜你喜歡
中學生數理化·七年級數學人教版(2022年11期)2022-02-14 07:14:12
科普童話·學霸日記(2020年1期)2020-05-08 16:45:11
小天使·一年級語數英綜合(2019年2期)2019-01-10 11:57:30
兒童繪本(2018年5期)2018-04-12 16:45:32
中華手工(2017年2期)2017-06-06 23:00:31
商用汽車(2016年11期)2016-12-19 01:20:16
商用汽車(2016年6期)2016-06-29 09:18:54
商用汽車(2016年4期)2016-05-09 01:23:12
創業家(2015年5期)2015-02-27 07:53:25
中外會展(2014年4期)2014-11-27 07:46:46
