面向Android惡意應用靜態檢測的特征頻數差異增強算法*
2020-06-22 12:50:04李向軍魏智翔王科選肖聚鑫
計算機工程與科學 2020年6期
李向軍,孔 珂,魏智翔,王科選,肖聚鑫
(1.南昌大學軟件學院,江西 南昌 330047;2.南昌大學計算機科學與技術系,江西 南昌 330031)
1 引言
Android已經占據了智能手機操作系統的大量市場份額,據Statcounter統計,2019年8月Android占據了全球移動操作系統市場份額的76.23%[1],至2019年,Google Play應用數量超過250萬[2]。惡意軟件開發者把大量惡意軟件進行偽裝上傳至Google Play 或第三方市場。2018全年,360互聯網安全中心累計監測移動端惡意軟件感染量約為1.1億人次[3]。Android應用程序的安全性檢測已成為網絡安全領域的熱點研究問題之一。
根據Android惡意應用的特征性質,檢測方法可分為靜態檢測、動態檢測和動靜混合檢測[4]。3種檢測方法中,靜態檢測的研究更廣泛。靜態檢測是指通過靜態特征進行惡意應用檢測,該方法可以在軟件未安裝之前對應用程序進行識別,提前預防惡意行為的發生。靜態特征通過對APK(Android Application Package)反編譯后,通過相關文件獲取,相比于動態特征的獲取,較為方便,不浪費用戶系統資源。靜態特征的提取通常會獲取大量的特征信息,其中大部分為冗余特征,因此特征選擇是十分必要的工作。而傳統的特征選擇算法不完全適用于Android惡意應用檢測的靜態特征選擇,如無法去除非典型特征,偏重惡意典型特征,在非平衡數據上對惡意應用識別準確率不良。
本文主要貢獻:在分析卡方校驗、信息增益、FrequenSel等特征選擇算法不足的基礎上,給出了良性特征、惡意特征、良性典型特征、惡意典型特征和非典型特征等定義,提出了一種適用于Android惡意應用靜態檢測的特征選擇算法——特征頻數差異增強FDE(Frequency Differential Enhancement)算法。平衡數據集和非平衡數據集上的實驗結果表明,FDE算法可有效去除靜態特征中的非典型特征,篩選出更有效特征。同時,引入權重損失函數彌補不平衡數據的缺陷,可有效提高惡意應用的識別準確率。
2 研究現狀
目前,Android惡意應用檢測3類方法中,相比于動態檢測、動靜混合檢測2種方法,靜態檢測方法的研究和應用更為廣泛。
靜態檢測需要對APK進行反編譯,從各類文件中提取信息,如權限、API信息等。Felt等[5]評價了權限機制的可用性,研究得出了惡意應用存在過度敏感權限申請問題。Nix等[6]使用API調用序列對惡意應用進行檢測,在深度置信網絡上檢測準確率達到95.7%。Mclaughlin等[7]使用卷積神經網絡CNN(Convolutional Neural Network)從原始操作碼序列中學習惡意應用的特征,召回率達到96.29%。Yerima等[8]提取權限信息作為數據特征,開發和分析了基于貝葉斯分類的主動式機器學習方法,展示了高精度的檢測能力。Wang等[9]集成了5種分類算法,使用11種類型的靜態特征識別良性應用和惡意應用,準確率高達99.39%。Shabtai等[10]使用了APK大小、特征數量等非主流特征。
動態檢測需要對應用進行安裝,獲取系統調用、網絡流量等信息。早期研究者缺乏對惡意應用行為模式的認識,把手機能量的消耗作為評判依據[11]。隨著對動態信息的研究,研究者獲得了更有代表性的動態特征。Martinelli等[12]在CNN上建立了一個基于系統調用的檢測應用程序,準確率在85%~95%。Vinod等[13]針對系統調用研究了數種動態特征選擇算法。Liang等[14]通過將系統調用序列視為文本來設計端到端惡意軟件識別模型,準確率達93.1%,F-1值為86.57%。柯懂湘等[15]使用隨機森林算法對行為日志中的惡意行為進行識別與分類,該方法對惡意行為分類的平均準確率達到96.8%。
動靜混合檢測是指將動態特征和靜態特征相結合的檢測方法。Fang等[16]對靜態檢測的結果進行動態檢測,在XGBoost算法上達到94.6%的檢測精度。Alshahrani等[17]把權限、組件信息、系統調用進行結合,實現了可運行在用戶設備上的識別器,準確率達到95%。Xu等[18]將靜態信息轉換為矢量,動態信息轉換為圖形特征集,組合構建了混合分類器,準確率達到93.4%。Vinayakumar等[19]使用基于多種網絡拓撲的長短期循環神經網絡對混合特征進行處理,準確率最高為94.2%。
基于靜態特征的Android惡意應用檢測方法使用的特征種類眾多。DREBIN[20]中使用了硬件組件、請求權限、應用程序組件、過濾意圖、限制API調用、使用權限、可疑API調用、網絡地址等8種靜態特征。Zhang等[21]使用了權限、API、組件、字符串4種特征。Luo等[22]只用了API調用信息。分析可見,多數基于靜態特征的應用檢測研究中,權限和API是最常用的特征。研究者針對靜態特征檢測使用的分類算法各有不同,Wang等[23]使用了支持向量機、隨機森林、K最近鄰3種傳統的機器學習算法。Arshad等[24]使用了隨機森林算法建立了三級混合惡意軟件檢測模型。深度學習算法也受到很多研究者青睞[25,26]。分類算法種類繁多,針對不同問題有不同的處理效果。
基于權限和API的靜態檢測中,Android系統要求應用權限信息必須公開,通過權限使用情況,一定程度上可以判斷是否為有惡意行為。權限特征聲明在AndroidManifest.xml文件中,可以通過對APK的反編譯得到。API特征存在于.smali文件中,攻擊者想要實現某一惡意行為,必須使用相應的API,所以API信息在惡意軟件靜態檢測中是非常重要的特征。權限與API信息相比,API信息的數量遠遠大于權限的數量,因為API不僅限于Google提供的,開發者也可以使用自己編寫的API,導致API數量龐大。API數量雖多,但大部分的API信息是無用的,并不具有識別惡意應用的功能。
靜態檢測提取特征信息后,有研究者使用卡方校驗、信息增益等傳統方法[27,28]進行特征選擇。Zhao等[29]在傳統算法的基礎上提出FrequenSel算法進行特征選擇。面對靜態特征選擇,這些算法都存在一些不足,如非典型特征排名過高,偏重惡意典型特征,重復選擇同一特征。很少有研究者對Android惡意應用檢測靜態特征選擇算法進行研究,多數研究者選擇傳統的特征選擇算法或人工特征選擇,部分研究者不進行特征選擇。
3 特征頻數差異增強算法
傳統特征選擇算法,如FrequenSel(Fre)[29]、卡方校驗Chi(Chi-square test)[30]、信息增益Info(Information divergence)[31]等,應用在Android惡意應用檢測領域存在一定的不足。其中,卡方校驗和信息增益特征選擇算法在特征分值計算過程中會賦予不利于辨別良性和惡意應用的非典型特征高排名。FrequenSel特征選擇算法在特征選擇過程中注重惡意特征的比例,忽略了特征的原始規律,并且在選擇良性特征和惡意特征時會重復選擇同一特征。為了彌補以上缺點,本文提出一種新的特征選擇算法——特征頻數差異增強算法FDE。
FDE算法旨在排除非典型特征,遵循特征的原始規律進行特征選擇。算法從特征最本質的角度,即各特征在良性應用與惡意應用中出現的頻率角度,進行分析設計。應用數據集上數據的非典型特征和典型特征呈現的特點是:良性典型特征只在良性應用中大量出現,惡意典型特征只在惡意應用中大量出現。非典型特征在良性應用和惡意應用中大量出現,或只少量出現在良性應用或惡意應用中。因此,以特征在良性應用和惡意應用中出現的頻數差異數和總樣本數量的比值作為評價特征的標準,設計特征評價公式如下所示:
(1)
其中,Nm表示包含特征fi的惡意應用數量,Nb表示包含特征fi的良性應用數量,Tm表示惡意應用的總數量,Tb表示良性應用的總數量。
特征評價公式先計算特征在良性應用與惡意應用中出現次數的差值絕對值,再用差值絕對值除以總樣本數。其特點是:(1)可計算得出每個特征的分值,每個特征的分值作為特征選擇的依據。(2)可有效對非典型特征進行甄別。根據非典型特征和典型特征的特點分析,通過式(1)的計算,非典型特征的S值較小,典型特征的S值較大,因此可有效去除非典型特征,篩選出更有效的特征。同時,該公式是從特征最原始的規律角度設計,不會干預惡意典型特征所占比例。
為有效篩選特征,給出如下相關定義:
定義1(良性特征) 對于某個特征fi,其在良性應用中和在惡意應用中出現的次數記為二元組counti=(Nb,Nm),若Nb>Nm,則稱其為良性特征。
定義2(惡意特征) 對于某個特征fi,其在良性應用中和在惡意應用中出現的次數記為二元組counti=(Nb,Nm),若Nm>Nb,則稱其為惡意特征。
定義3(良性典型特征) 若某特征fi為良性特征,即counti=(Nb,Nm),其中Nb>Nm,且滿足:
(2)
則稱其為良性典型特征。
定義4(惡意典型特征) 若某特征fi為惡意特征,即counti=(Nb,Nm),其中Nm>Nb,且滿足:
(3)
則稱其為惡意典型特征。
定義5(非典型特征) 若某特征fi滿足以下2個條件之一,則稱其為非典型特征。
(1)counti=(Nb,Nm),且:
(4)
即該特征在良性應用中出現的次數較少,在惡意應用中出現的次數幾乎為0,或其在惡意應用中出現的次數較少,在良性應用中出現的次數幾乎為0。
(2)counti=(Nb,Nm),且:
(5)
即該特征在良性應用和惡意應用中都大量出現,但出現的次數差的絕對值很小。
根據上述定義,特征頻數差異增強算法FDE的思路為:首先,統計總樣本數量以及各特征在良性應用和惡意應用中出現的次數;然后,按照式(1)計算每個特征的S值,并按照定義3~定義5進行特征選擇。算法偽代碼如下所示:
算法1特征頻數差異增強算法FDE
輸入:特征集合F,閾值ɑ。
輸出:新的特征集合F′。
1.Tm←CountMalware;
2.Tb←CountBenign;
3.Fori←1toF.Size()do
4.Nm←CountInMalware(fi);
5.Nb←CountInBenign(fi);
6.S←|Nb-Nm|/(Tb+Tm);
7.IfS≥αthen
8.F′←fi;
9.endif
10.endfor
第1~2行統計惡意樣本和良性樣本數量;第3~10行執行循環,統計每個特征在良性應用和惡意應用出現的次數,然后計算每一個特征的S值,根據定義3~定義5選取符合條件的特征。其中不同的閾值ɑ取值會產生不同數量的特征。
由算法描述可見,FDE算法只需統計每個特征出現在良性應用和惡意應用中的數量,計算每個特征的S值,并依據相關定義進行特征選擇。相比于FrequenSel、卡方校驗、信息增益等算法,FDE算法特征評價簡便,特征選擇依據更加合理,計算消耗低且時間代價呈線性,運行時間增幅與樣本輸入規模增幅成固定比例。由算法步驟可知,第1~2行執行次數和問題規模無關,僅執行2次,第3~10行執行次數隨問題規模n變化,其執行次數最少為5n,最多為6n。故算法計算復雜度僅和樣本數量相關,算法最好情況和最壞情況的時間復雜度均為O(n)。
4 實驗結果與分析
本文通過3組實驗來驗證FDE算法的目標效果和性能。第1組實驗展示5個特征使用FDE算法的詳細計算過程和結果,驗證FDE算法是否可達到有效去除非典型特征的目標。第2組實驗是在理想平衡數據集上驗證不同特征數量下FDE算法的有效性,以及相比其他特征選擇算法的優越性。第3組實驗是在非平衡數據集上驗證FDE算法選擇特征的有效性,以及相比其他特征選擇算法的優越性。其中,為解決正負樣本不平衡情況下各算法組合對惡意樣本識別準確率較低的問題,引入權重損失函數,以降低誤報率。
4.1 實驗數據集與預處理
在Google Play應用市場下載5 000個良性應用,VirusShare下載5 000個惡意應用,通過Androidguard反編譯得到AndroidManifest.xml和.smali文件,提取權限和API調用信息。10 000個應用構成平衡數據集,共提取14 610個特征,按7∶3比例劃分訓練集和測試集。非平衡數據集中良性與惡意應用比例為5∶1,共提取13 789個特征,按10∶1劃分訓練集和測試集。原始特征為權限信息和API信息,需將特征信息數字化,樣本中如果包含該特征則該欄特征信息為1,否則為0。表1展示了少量權限信息的特征數字化。

Table 1 Examples of individual sample feature digitization 表1 個別樣本特征數字化示例
4.2 評價指標
TP(True Positive):將正類預測為正類;
TN(True Negative):將負類預測為負類;
FP(False Positive):將負類預測為正類;
FN(False Negative):將正類預測為負類。
準確率:
(6)
精確率:
(7)
召回率:
(8)
誤報率:
(9)
F-1:
(10)
均值:
(11)
方差:
(12)
ROC(Receiver Operating Characteristic)曲線:ROC曲線是以假正率(FPR)和真正率(TPR)為軸的曲線,設定不同的判定正負樣本閾值,可以得到不同的TPR和FPR點對。將一系列點對連接成平滑的曲線,則為ROC曲線。TPR和FPR的定義見式(8)和式(9),其中TPR=Recall。
4.3 FDE算法目標效果驗證
設計FDE算法的目的是為了去除非典型特征,選擇更有效的特征。為驗證FDE算法是否達到設計目的,從14 610個特征中選取5個特征進行計算和分析。表2展示了5個特征的特征信息及FDE算法計算結果。
詳細計算過程如下所示:
步驟1統計惡意樣本和良性樣本數量Tm=5000和Tb=5000。
步驟2分別統計5個特征在惡意樣本和良性樣本中出現的次數Nm和Nb。
步驟3根據式(1)計算5個特征的S值。
步驟4根據特征選擇標準,選擇S值大于或等于0.1的特征,5個特征中有3個特征的S值大于0.1。
表2中非典型特征Landroid/net/SSLSessi-onCache和Landroid/graphics/Typeface經FDE算法計算,分值較低,與其他典型特征分值差距較大,排名第4位和第5位,不在選取特征范圍之內。后續使用卡方校驗方法對上述5個特征進行分值計算,結果顯示非典型特征Landroid/net/SSLSessionCache分值排名第3位。計算結果表明,FDE算法能達到有效去除非典型特征的目的。
4.4 平衡數據集實驗結果與分析
給定平衡數據集,將FDE算法中ɑ設置為不同值,驗證不同特征數量時FDE算法的有效性,以及相比其他算法的優越性。ɑ取值分別為0.1,0.15,0.2和0.25,產生的特征數量分別為778,566,398和233。將經過特征選擇后的不同數量特征放入SVM、KNN、CNN、Bayes、決策樹DT(Decision Tree)5種分類器中進行實驗對比,其中,由于CNN的特性,在平衡數據集上有關CNN實驗結果皆取500次迭代的平均值作為實驗結果。各分類器實驗結果如圖1所示。
圖1a展示了各分類器準確率的變化。由圖1a可見,隨著特征數量的增加,多數分類器的準確率都呈上升趨勢。其中,SVM分類器的效果最優,準確率最高值達98%,CNN分類準確率略低于SVM的,Bayes分類效果最差,準確率最高值僅為93.30%。DT分類準確率呈現上下波動狀況,與KNN分類準確率基本接近。
圖1b展示了各分類器在778個特征上的ROC曲線(不含CNN算法,原因在于CNN取500次迭代平均值,無法生成其ROC曲線)。ROC曲線能夠綜合反映一個分類器的好壞,4種分類器ROC曲線中,最靠近左上方的是SVM的曲線,DT和KNN的曲線基本重合,Bayes的曲線最靠近右下方。實驗結果表明,5種分類器中最適合FDE特征選擇的是SVM分類器,效果最差的是Bayes分類器。

Table 2 Instance data and calculation analysis of FDE algorithm表2 實例數據及FDE計算分析

Figure 1 Experimental results of FDE algorithm’s effectiveness with different features number圖1 不同特征數量時FDE算法的有效性實驗結果
為比較FDE算法和其他特征選擇算法的性能差別,選擇卡方校驗、信息增益、FrequenSel和FDE算法在SVM、KNN、CNN 3種分類器上進行實驗對比,實驗結果如圖2所示。由于FrequenSel無法自主選擇特征數量,經參數調整特征數量最低為930個,將單獨把FrequenSel選擇的930個特征和卡方校驗、信息增益、FDE等選擇的778個特征作比較。
圖2展示的實驗結果中,SVM+Chi表示為SVM算法結合卡方校驗特征選擇算法所得的實驗結果,后續圖表中相關表示具有同種含義。由圖2a可知,FDE在各特征數量選擇上的準確率都優于卡方校驗和信息增益特征選擇算法的。圖2b和圖2c所示為召回率和F-1值實驗結果,由于對CNN的準確率取500次迭代的平均值,所以無法得出其具體的召回率和F-1值。在召回率上FDE沒有表現出絕對優勢,卡方校驗與SVM的組合擁有最高的召回率,但在KNN分類器上,FDE的召回率基本優于其他2種算法的。在F-1值上,FDE算法與SVM的組合擁有最高值,且各特征數量上的F-1值優于其他特征選擇算法的。
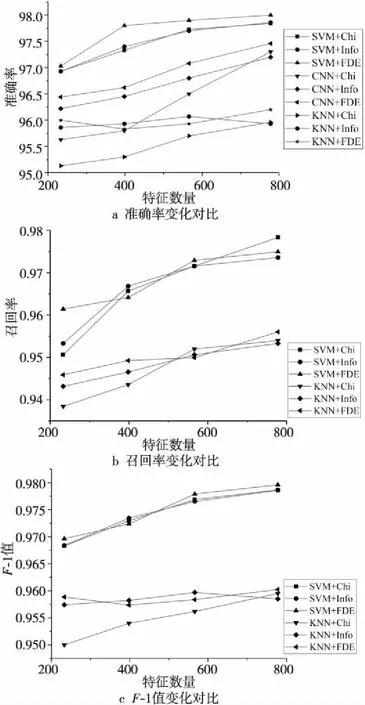
Figure 2 Experimental results of FDE algorithm with other feature selection algorithms圖2 FDE算法與其他特征選擇算法對比實驗結果
表3給出了FDE算法與FrequenSel、卡方校驗、信息增益等算法在SVM、CNN、KNN 3種分類器上的比對實驗結果。FrequenSel特征選擇算法在SVM和CNN上的準確率都是最低的,在KNN上的準確率高于卡方校驗和信息增益的,但低于FDE的。在召回率及F-1值上,FrequenSel在KNN上有較好表現,但在SVM上均最差。從3種評價指標的最高數值來看,FDE算法優于FrequenSel算法。
同時,為更詳細地比較各特征選擇算法對分類的影響,本文從分類概率值角度,驗證分析了在SVM分類器上FDE與其他特征選擇算法對分類概率值的影響。實驗中選取了平衡數據測試集中的1 522個惡意樣本和1 478個良性樣本,對各特征選擇算法在SVM分類器上的分類概率值進行了驗證分析。首先,選擇表現最優異的SVM分類器,然后統計SVM結合不同特征選擇算法的分類概率值,計算出均值和方差。通過均值分析分類概率值的整體大小,通過方差分析分類概率值的離散程度。
表4展示了在SVM分類器上各特征選擇算法對分類概率值的影響結果。在良性測試樣本上SVM+FDE的分類概率值的均值略低于SVM+Chi的,方差略高于SVM+Chi的。在惡意測試樣本上SVM+FDE的均值最高,方差最小。結合召回率說明SVM+FDE傾向于惡意類別的識別,SVM+Chi在良性樣本的識別上效果要略好于SVM+FDE。雖然SVM+Chi在良性測試樣本上的分類概率值的均值和方差最優,但在惡意測試樣本上的分類概率值的均值和方差都是最差的。良性樣本和惡意樣本的分類概率值匯總計算后得出,SVM+FDE擁有最高的均值和最低的方差,所以SVM+FDE的分類概率值更大、更穩定,FDE對分類的影響效果更好。

Table 3 Experimental results of FDE algorithm,FrequenSel algorithm,Chi-square test algorithm and Information divergence algorithm on SVM,CNN and KNN 表3 FDE與FrequenSel、卡方校驗、信息增益等算法在SVM、KNN、CNN 3種分類器上的比對實驗結果

Table 4 Average value and variance of classify probability values of FDE and other feature selection algorithms on SVM表4 FDE與其他特征選擇算法在SVM上分類概率值的均值和方差
表5中對比了SVM+FDE與其他4位研究者文章中的實驗結果。實驗結果表明,與FDE結合效果最好的SVM分類器的準確率、F-1值都高于其他4篇文獻的方法,但在召回率上略有不足。
小結:(1) 5種分類算法驗證實驗上的結果表明,FDE算法是有效可行的。(2) 與FrequenSel、卡方校驗、信息增益等特征選擇算法的對比實驗結果說明,SVM+FDE擁有最高的準確率和F-1值,但SVM+Chi的召回率最高。召回率只是單方面地反映對正樣本的識別準確度,但準確率和F-1值更能綜合反應方法的好壞,且FDE算法對分類概率值的影響較好。這表明FDE算法有效且優于其他算法。(3) FDE算法的不足之處為:對良性樣本的識別比其他算法略差,即召回率略低。導致這種情況的原因有2種可能:一是FDE算法設計的目的是去除非典型特征,選擇有利于識別惡意應用的特征,從而導致對惡意應用識別效果較好,對良性應用的識別效果較差。二是由于本文只使用了權限和API信息作為特征,僅依據這2種特征可能不能全面地分辨良性應用與惡意應用。
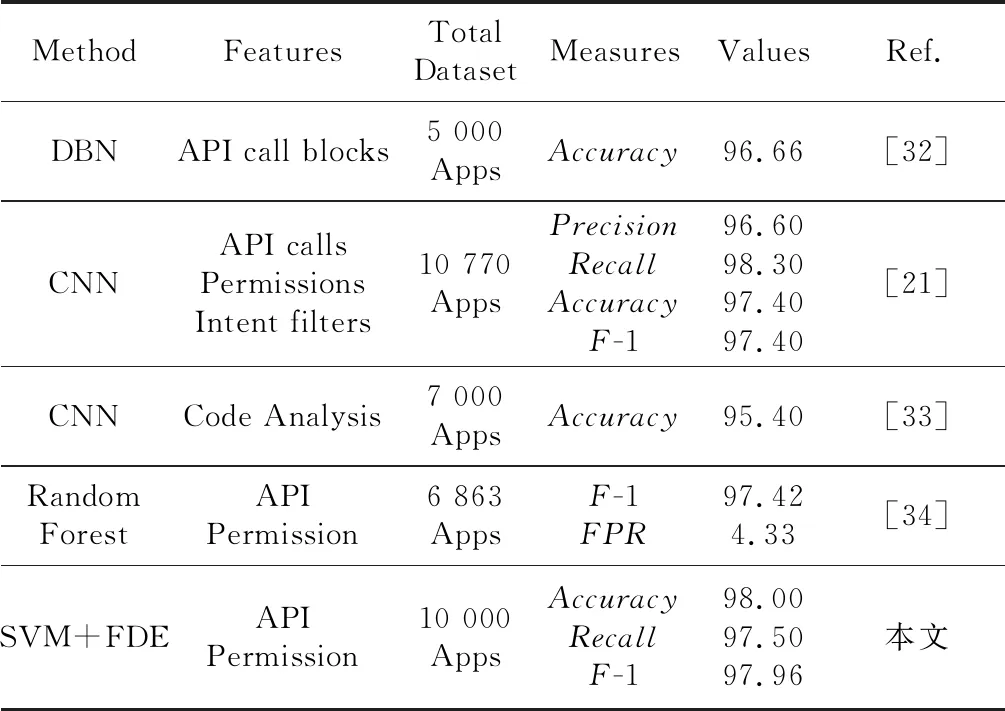
Table 5 Comparison of the method in this paper with other methods表5 本文方法與其他方法比較
4.5 非平衡數據集實驗結果與分析
為模仿良性應用數量遠超出惡意應用數量的真實應用軟件環境,本文在10 000個應用的基礎上,刪除4 000個惡意應用,形成正負樣本比為5∶1的非平衡數據集。重新進行特征提取后獲得13 789個特征,使用FDE算法進行特征選擇,共選擇1 062個特征。與平衡數據集選擇的778個特征作比較,其中有709個特征重合,權限類特征重復率為零。實驗訓練集包含3 850個應用,測試集共2 150個樣本。
首先,設計實施了非平衡數據上FDE算法特征選擇有效性驗證和FDE算法與其他特征選擇算法性能比對實驗。實驗中,卡方校驗、信息增益、FrequenSel皆重新進行特征選擇,并分別在SVM和CNN分類器上進行實驗比較,實驗結果如表 6所示,其中所有CNN實驗均運行5次,每次迭代150次,每次運行結果取值于最后一次的迭代結果,統計5次運行的結果。
表6中,Accuracy-max為最高準確率,Accur-acy-aver為平均準確率,M-Accuracy為惡意樣本識別準確率。實驗結果表明,當正負樣本比例不平衡時,各特征選擇算法效果均有所降低。在CNN實驗中,FDE算法的最高準確率和平均準確率最高,最高值為96.56%,平均值為96.35%。且對惡意樣本識別效果最好,最高值達到93.85%,平均值達到93.72%。在SVM分類器上,FDE算法的效果略低于信息增益特征選擇算法的。同時,對比了各特征選擇算法進行特征提取的時間,結果表明,FDE算法的時間遠遠少于卡方校驗和信息增益的,略少于FrequenSel的特征提取時間。以上分析表明,FDE算法在非平衡數據集上同樣有效,且相比其他特征選擇算法具有一定的優勢。
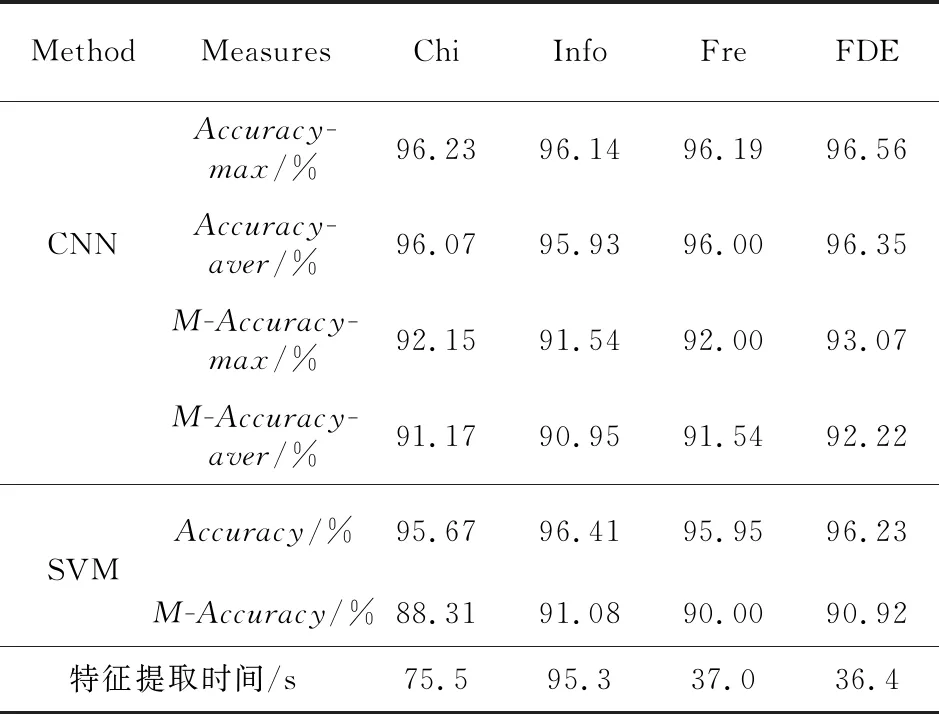
Table 6 Experimental results on unbalanced data sets表6 非平衡數據集上實驗結果
其次,注意到由于正負樣本的不平衡,使得各算法組合對惡意樣本的識別準確率明顯低于對良性樣本的識別準確率。由于特征良性或惡意判斷問題可理解為二分類問題,為解決惡意樣本識別準確率低的問題,引入權重損失函數。
以交叉熵函數作為損失函數,計算公式如下所示:

(13)
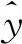
考慮到樣本的不平衡性,在損失函數中賦予不同類別不同的權重,改進式(13)得權重損失函數如下所示:
(14)
其中,W0為第1個類別的權重,W1為第2個類別的權重。若W0值較高,W1值較低,第1類中的樣本被錯分時,權重損失函數值比無權重的損失函數值更大,而第2類中的樣本被錯分時,對損失值的影響較小。因此,影響網絡傾向于學習某些類而降低損失值。對于多分類的問題,同樣可以使用這種賦予權重的方式來讓網絡傾向于某些類。
實驗中,采用FDE+CNN組合的方法驗證引入權重損失函數的效果。圖3展示了FDE+CNN組合方法下各權重誤報率和準確率變化情況,其中,良性類別權重為BW,惡意類別權重為MW。誤報率可以反映測試集中惡意樣本被錯分為良性應用的比例。
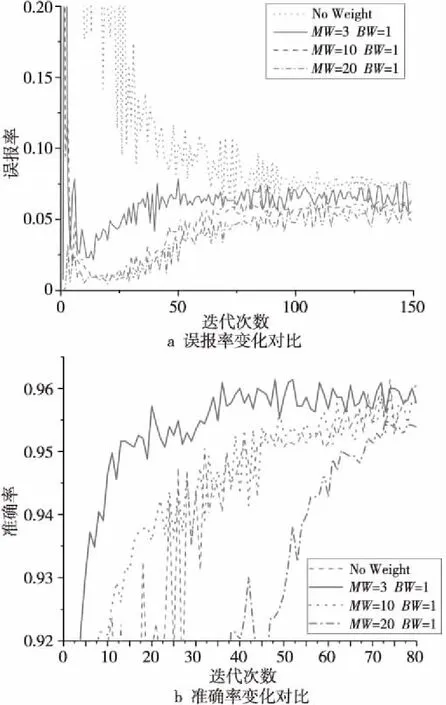
Figure 3 Weight adjustment experimental results of FDE+CNN combination method圖3 FDE+CNN組合方法的權重調整實驗結果
由圖3a和圖3b可見,隨著迭代次數的增加,誤報率呈現先下降后升高的趨勢,且隨著惡意樣本類權重數值的增大,誤報率整體呈下降趨勢,但準確率呈先上升后下降的趨勢。這表明惡意類別權重數值增大可以減少誤報率,但權重超過一定數值,會降低整體準確率。
因此,經多次權重參數調整,最終權重取值確定為MW=3,BW=1。此權重下惡意樣本識別準確率為94.31%,整體準確率為96.37%。相比于表6中未考慮權重損失函數的實驗結果,惡意樣本識別準確率得到提高,整體準確率和平均值相近,但對良性樣本的識別率有所下降。
該實驗結果表明:(1)在非平衡數據集上FDE算法同樣有效,且相比于其他特征選擇算法,具有整體準確率高、善于識別惡意應用、特征提取時間短等特點。(2)針對非平衡數據中惡意應用識別率較低的問題,引入權重損失函數,賦予惡意應用類別高權重可提高對惡意應用的識別準確率。
5 結束語
本文針對Android惡意應用靜態檢測提出了一種新的特征選擇算法FDE,其目的是為了解決已有特征選擇算法在檢測中存在的不足,以篩選出更有效的特征,提高檢測的準確率。FDE算法從特征最本質的角度篩選有效特征,去除非典型特征,從大量特征中選取少量特征作為分類算法的輸入,減少模型訓練時間與特征提取時間。理論分析和實驗結果表明,FDE算法是有效可行的,且相比于其他特征選擇算法具有自身的優勢。但是也反映出,FDE算法還存在需要改進完善之處:對非典型特征做的限定略顯粗糙,可能會使一些典型特征被限定為非典型特征,且實驗中分類器在召回率上的表現略有不足。未來值得進一步探討的方向有:(1)新特征[35 - 37]或有效特征的組合方法。有研究者發現僅靠權限和API信息2種特征并不能全面地檢測惡意應用,可以挖掘更具有代表性的特征進行惡意應用檢測。(2)對抗攻擊的深度學習檢測方法研究。隨著深度學習的廣泛應用[38],有研究者利用深度學習的脆弱性實現了針對基于深度學習的對抗攻擊。(3)基于Android的其他惡意行為檢測,如釣魚網站檢測[39]等。
猜你喜歡
小獼猴智力畫刊(2022年9期)2022-11-04 02:31:42
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
小哥白尼(趣味科學)(2019年6期)2019-10-10 01:01:50
當代陜西(2019年10期)2019-06-03 10:12:04
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
發明與創新(2016年38期)2016-08-22 03:02:52
太空探索(2016年5期)2016-07-12 15:17:55
