分布式存儲中一種新的低修復帶寬的Hitchhiker碼
2020-07-13 06:17:58胡金平李貴洋江小玉韓鴻宇
小型微型計算機系統 2020年7期
胡金平,李貴洋,江小玉,周 悅,韓鴻宇
(四川師范大學 計算機科學學院,成都 610101)
1 前 言
海量數據的增加導致存儲系統應具有低價格和可擴展的優良特性.相比傳統的集中式存儲[1],分布式存儲系統[2]利用廉價的商用PC機和成熟的網絡技術,形成了成本低廉且易擴展的存儲系統.為保證數據的可靠性,分布式存儲系統常利用多副本[3]和糾刪碼[4,5]這兩種容錯技術.前者較成熟且最簡單,但空間利用率低;后者以其高容錯能力,高空間利用率等優點得到學術界和工業界的關注,并廣泛應用到Hadoop[6]、GFS[7]、Azure[8]等各大分布式存儲系統中.
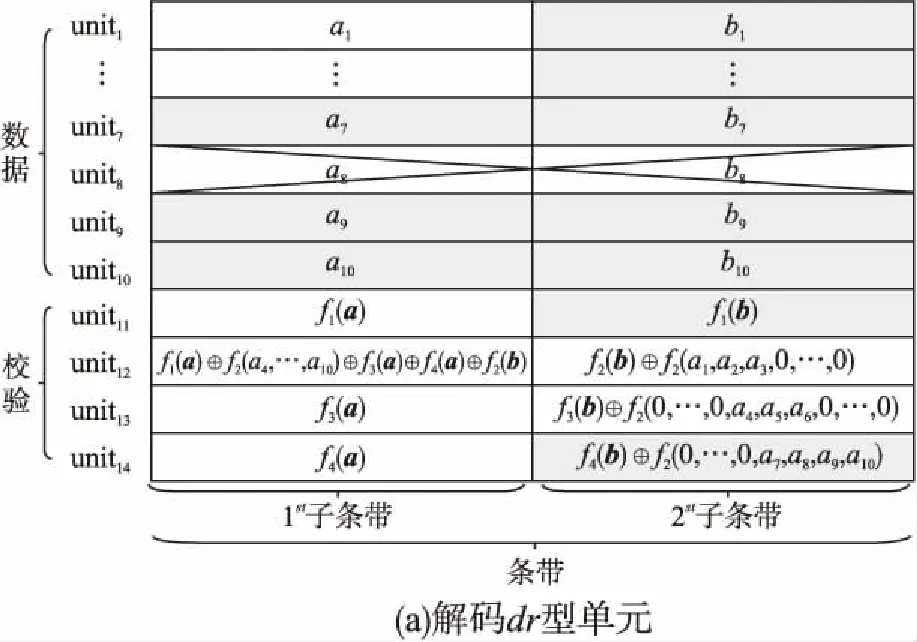
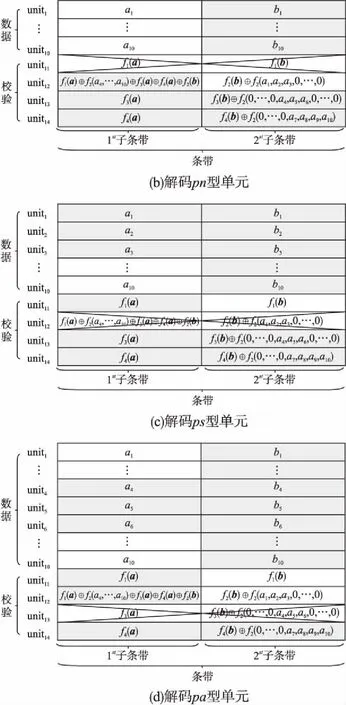
Reed-Solomon Codes[9,10]是具有MDS[11]性質的糾刪碼,能夠達到理論上的最高容錯能力和最低的存儲代價,但存在修復成本高昂的問題.為了降低修復帶寬,目前常用的有兩種降低修復帶寬的方式.一是Rashmi等人[12]提出了Piggybacking設計架構,其中將易于工程實現的雙條帶MDS碼命名為Hitchhiker[13]碼,并給出了三種Hitchhiker碼的構造方案,適用于各種(k,r)參數配置.二是Gopalan 等人[14-16]分別提出了局部修復性編碼(Locally Repairable Codes),簡稱LRC.它通過添加局部校驗來減少磁盤I/O,從而降低修復成本.目前RS碼、LRC和Hitchhiker碼都廣泛應用于各大分布式存儲系統中.例如:RS(6,3),RS(8,4),RS(10,4)分別應用到了Google文件系統[17]、Baidu Atlas云平臺[18]和Facebook存儲系統[19]中,在Hadoop分布式文件系統提供多種參數的RS(k,r)碼[20]供用戶選擇;LRC應用在Azure和Hadoop中[21,22],兩者的編碼方式有稍許差異;(10,4)-Hitchhiker已部署在Hadoop文件系統中.
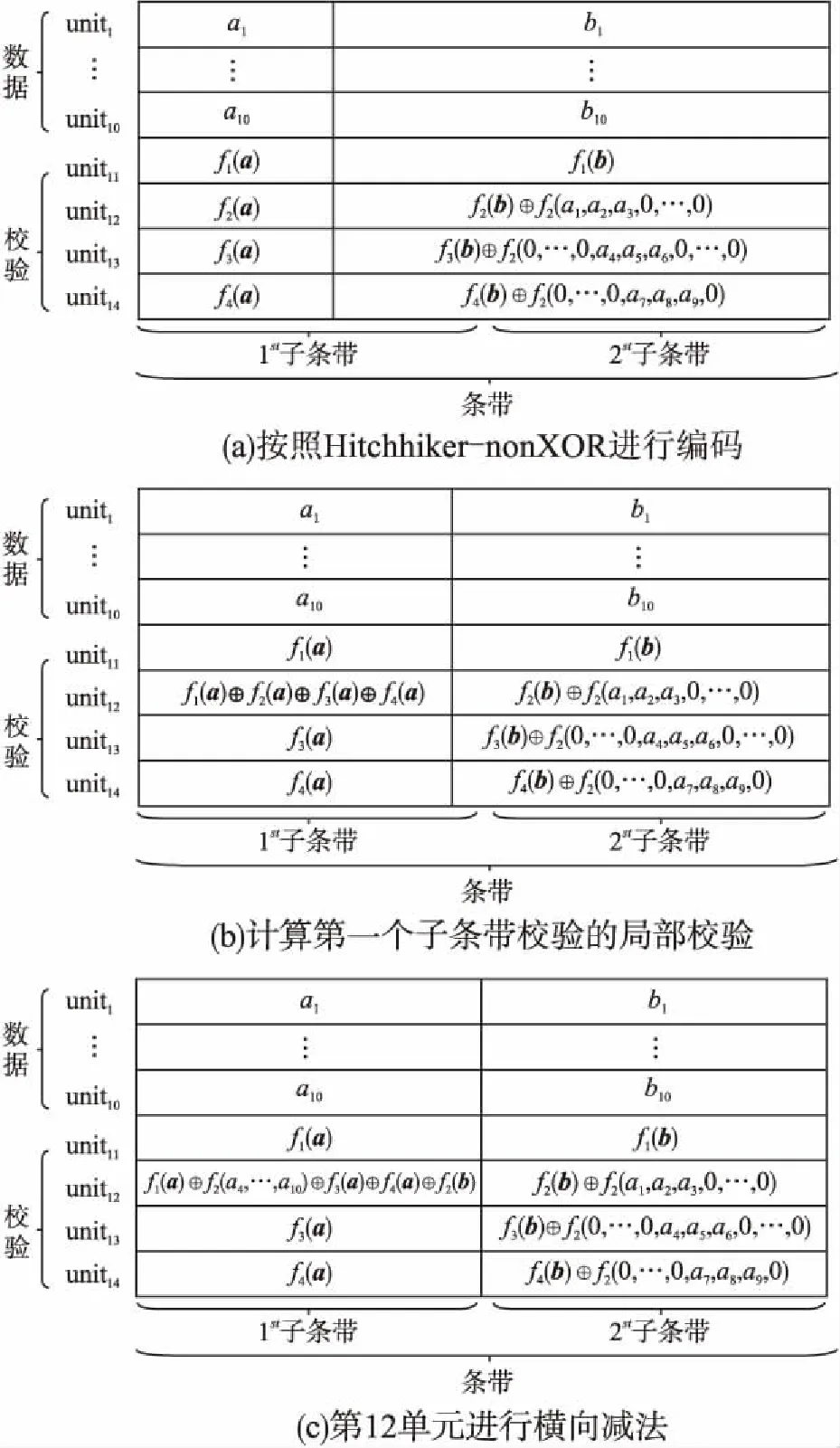
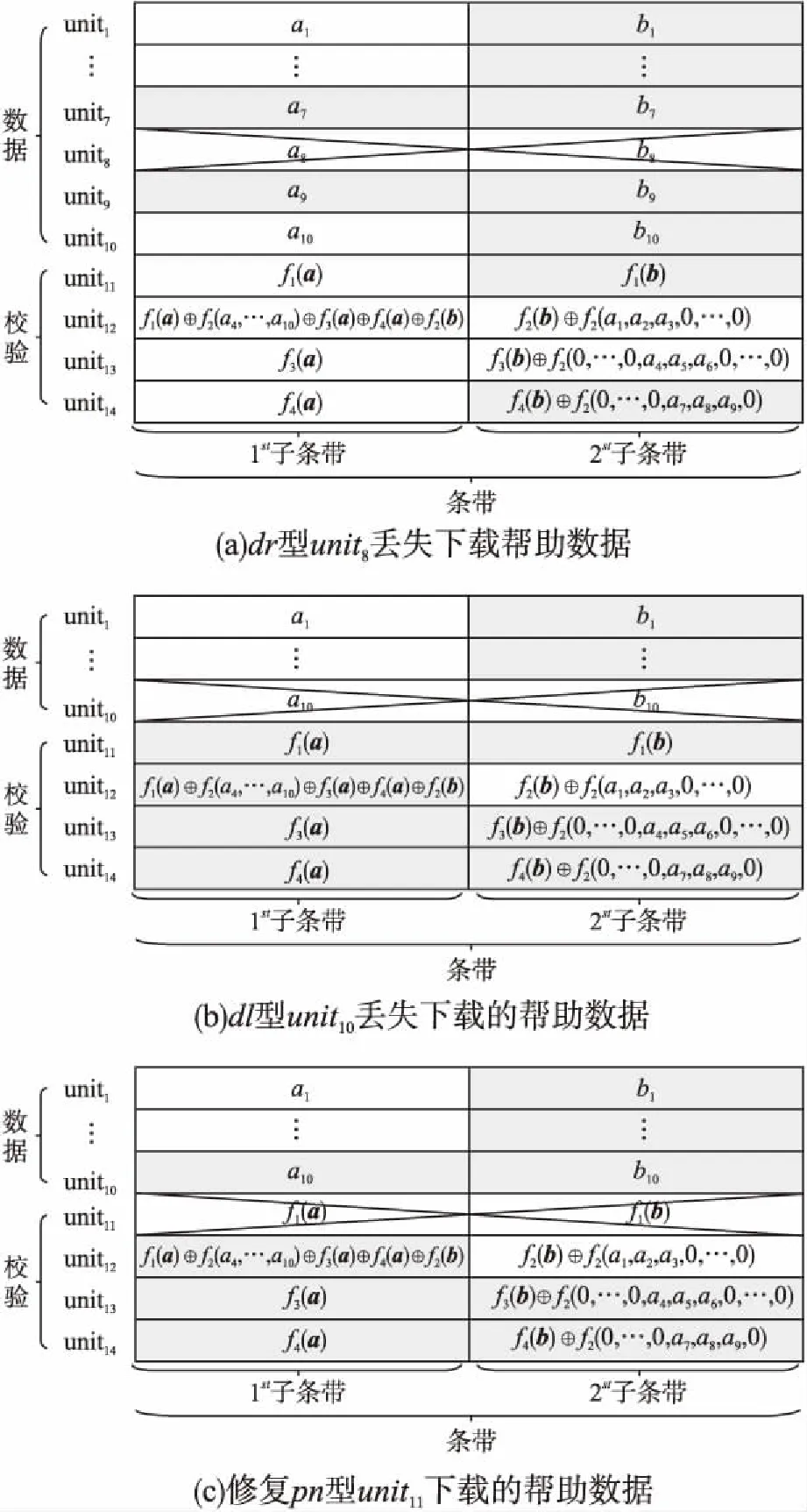
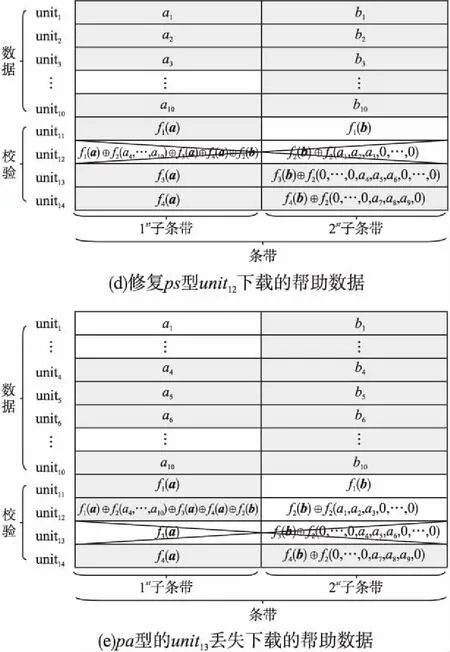
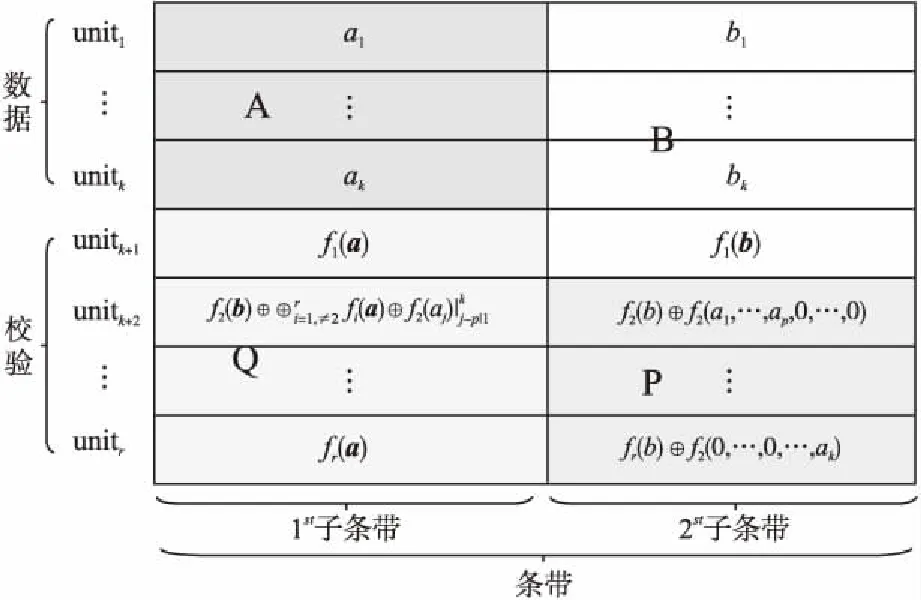
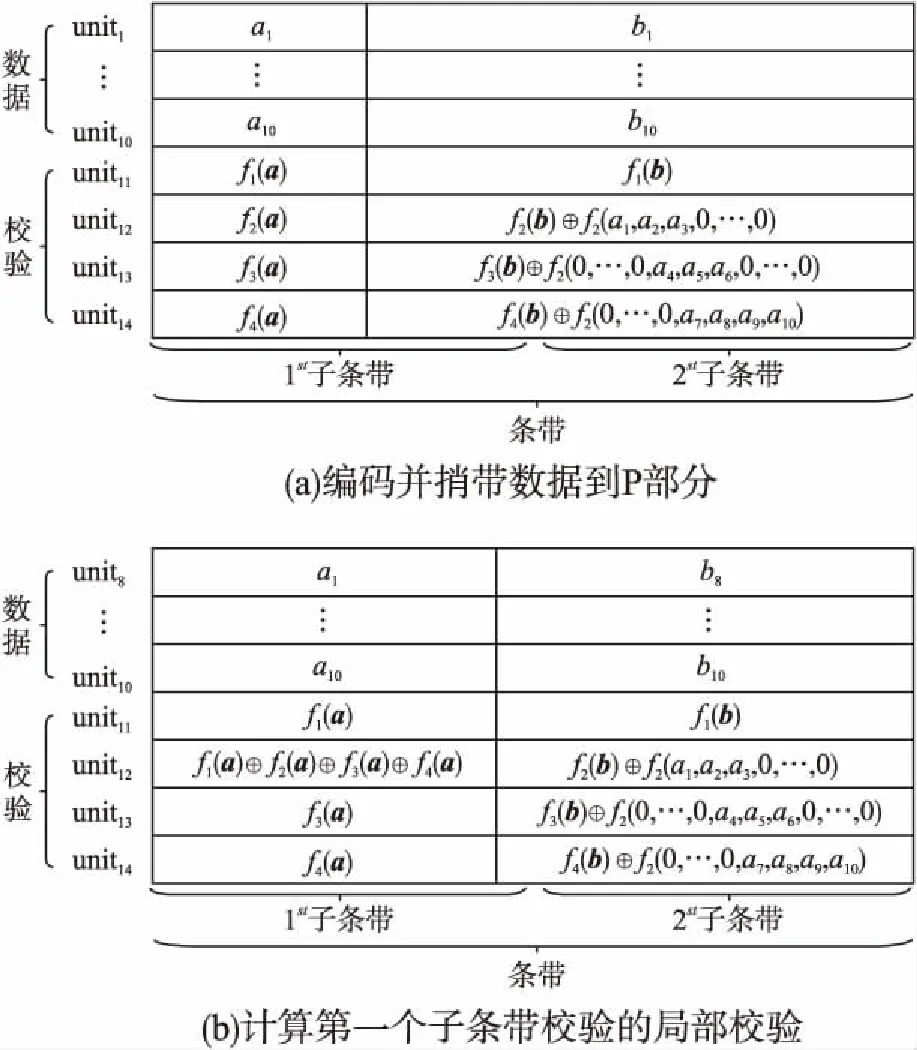
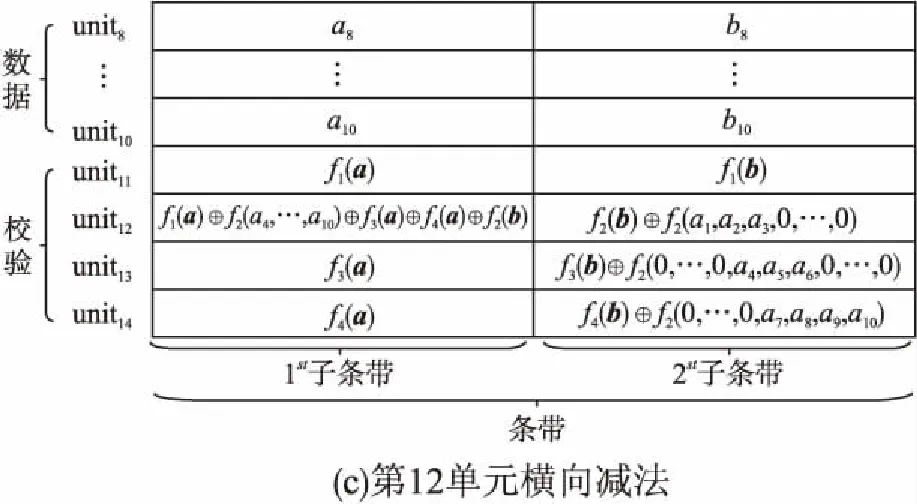
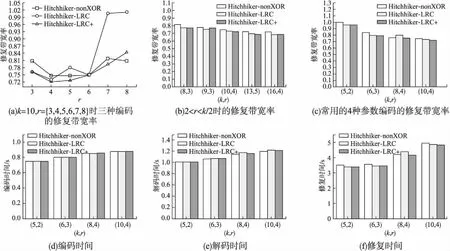
目前Hitchhiker碼只針對系統單元的修復進行了優化,而對校驗單元未做處理.LRC雖能顯著的降低單節點失效的修復帶寬,但由于增加了額外的存儲開銷,從而破壞了MDS性質.針對該問題,本文借鑒LRC中的信息位局部性的思想,構造出兩種Hitchhiker碼與LRC相結合的新編碼,并命名為——Hitchhiker-LRC和Hitchhiker-LRC+.它們既沒有增加額外的存儲空間又降低數據單元和校驗單元的修復帶寬,達到整體修復帶寬優于原Hitchhiker碼.本文首先給出了將LRC碼加入到Hitchhiker碼的校驗單元中的理論基礎.其次,提出了Hitchhiker-LRC和Hitchhiker-LRC+的主要思想和編解碼方法.然后,對新提出的編碼的修復帶寬率、編碼時間和解碼時間進行了理論的分析,并討論了參與局部校驗的數量l與修復帶寬率關系.最后,實驗證明了在2≤r 首先參數列表,如表1所示. 表1 參數表 Table 1 Parameter list 參數意 義n單元總數k存放原始數據單元的個數r校驗單元數量l參與局部校驗的數量pk與r-1的商,每個校驗中附加的數據的個數qk與r-1的余數,每個校驗附加后剩下的數據的個數δ修復每個單元所需的幫助數量之和δ-修復每個單元所需的平均下載量γ修復失效單元的平均下載量占原數據總量的百分比 其次給出相關性質與定義. 性質1.將原始數據分為等大小的k份,進行編碼產生r(r=n-k)個校驗,將數據擴大到n份并存儲到不同的n個節點上.任何k份數據都能恢復全部的n個節點中的數據.稱這種性質為MDS性質. 定義1(單元).單元即units,代表某個節點中在同一個編碼區域中的數據. 定義2(條帶).條帶即stripe,代表同一組編碼的n個units的集合,n個units由k個原始數據單元和r個校驗數據單元組成.子條帶為一個條帶分為多個子條帶,用substripe表示. 局部修復編碼(LRC)是以存儲資源換取帶寬資源的MR[23]碼,由Gopalan、Oggier、Papailiopoulos等人分別提出.C.Huang 等人提出的金字塔碼[24]在Azure云中得到應用.結果顯示:LRC碼有效的減少了磁盤I/O開銷,從而降低單節點失效的修復帶寬.圖1為LRC(10,6,2)的編碼,稱由全部數據單元產生的校驗p1,p2為全局校驗,由部分數據單元產生的校驗lp1,2,lp2,1為局部校驗.通常局部校驗與全局校驗有一定的數量關系.在金字塔碼中,全局校驗與局部校驗的數量關系如公式(1)所示. px=lpx,1+lpx,2+…+lpx,y (1) 它是將全局校驗拆分成y個局部校驗.存儲時,其中的一個局部校驗不存儲,達到節省存儲空間的目的.那么圖1中的p1=p1,1+p1,2,p2=p2,1+p2,2,其中p1,1和p2,2不存儲. 圖2 Hitchhiker(10,4)與RS(10,4)編碼的結構 3.1.1 編碼過程 Hitchhiker-LRC的編碼主要分為三步:一是按照Hitchhiker-nonXOR的編碼.二是利用LRC的思想對第一個子條帶中的校驗單元求局部校驗,并將結果存放在已通過局部校驗的形式捎帶在第二個子條帶的校驗的位置之上.三是利用橫向減法來存儲第一步中需要捎帶在第一個子條帶的校驗單元中的數據.現以例子敘述Hitchhiker-LRC的編碼過程.如圖3所示,其中l=r=4. 第1步,按照Hitchhiker-nonXOR的方式進行編碼,計算p=3,q=1,如公式(2)所示. (2) 可知在unit12-14的第二個子條帶中分別存儲3個數據,在unit12的第一個子條帶中存儲1個數據.如圖3(a)所示. 3.1.2 解碼過程 圖3 Hitchhiker-LRC(10,4)編碼示意圖 第1步為根據丟失單元位置,判斷丟失的單元的類型.如算法1中Step 1所示. 第2步為解碼數據單元或解碼校驗單元. 解碼數據單元利用Hitchhiker-nonXOR中的捎帶法則或者校驗單元,其思想為:利用MDS性質恢復第二個子條帶中的bx,接著用第一個子條帶中的LRC和橫向減法來恢復ax.需用到丟失的數據單元unitx和附加在第幾個校驗單元的臨時變量p′,其中p′為: (3) 修復dr型的方法與原Hitchhiker相同;修復dl需先利用MDS性質恢復bx,再利用校驗單元中第一個子條帶中的LRC和橫向減法來恢復ax.如算法1中Step 2所示. g=xmod(k-2) (4) 對ps而言,需下載捎帶在該校驗第二個子條帶的數據,計算恢復第二個子條帶的數據.第一個子條帶的修復同樣利用LRC的修復方式.最后,修復pa類型的第二個子條帶與ps相同;不同之處在于修復第一個子條帶,由于橫向減法的原因,會少下載unitk+i|i∈{3,…,r}中的第一個數據.如算法1中Step 3所示. 算法1.Hitchhiker-LRC的解碼算法 輸入:unitx|x∈{1,…,k}、type、p、q、dr、dl、pn、ps、pa. Step 1.判斷丟失單元的類型.臨時變量p′. 執行公式(3); SWITCH(TRUE) CASEx∈[1,p×(r-1)]:type=dr;BREAK; CASEx∈[p×(r-1)+1,k]:type=dl;BREAK; CASEx=k+1:type=pn;BREAK; CASEx=k+2:type=ps;BREAK; CASEx∈[k+3,k+r]:type=pa;BREAK; DEFAULT:error;BREAK; Step 2.解碼數據單元. 下載bi|i∈{1,…,k}{x},f1(b)得到bx; IFtype==drTHEN 下載ai|i∈{p×p′+1,…,p×p′+p}{x}、fp′+2(b)?f2(ai)|i∈{p×p′+1,…,p×p′+p}得到ax. ELSE IFtype==dlTHEN 下載unitk+i|i∈{1,…,r}的第一個子條帶、unitk+i|i∈{3,…,r}的第二個子條帶和ai|i∈{p×p′+1,…,p×p′+q}{x},得ax. END IF Step 3.解碼校驗單元,臨時變量g. 下載bi|i∈{1,…,k}得到fxmodk(b); IFtype==pnTHEN 再下載unitk+i|i∈{1,…,r}{xmodk}的第一個子條帶、unitk+i|i∈{3,…,r}的第二個子條帶和ai|i∈{p×p′+1,…,p×p′+q}{x},計算得到fxmodk(a). ELSE 執行公式(4); 下載ai|i∈{g×p+1,…,g×p+p},得unitx|x∈{0,…,k}的第二個子條帶.再下載unitk+i|i∈{1,…,r}{xmodk}的第一個子條帶和ai|i∈{p×(r-1)+1,…,p×(r-1)+q}{x}. IFtype==psTHEN 下載unitk+i|i∈{3,…,r}的第二個子條帶即可. ELSE IFtype==paTHEN 下載unitk+i|i∈{4,…,r}的第二個子條帶,得fxmodk(a). END IF END IF 以(k=10,r=4,p=3,q=1)為例,描述5種單元丟失后的解碼方式,如圖4所示.若dr型unit8丟失,需下載幫助數據如圖4(a)所示.修復dl型unit10,下載的幫助數據如圖4(b)所示.修復pn型unit11,下載的幫助數據如圖4(c)所示.修復ps型unit12,下載的幫助數據如圖4(d)所示.若pa型的unit13丟失,下載的幫助數據如圖4(e)所示. 圖4 5種不同類型的解碼 3.2.1 Hitchhiker-LRC+的架構 隨著r的增加,參與LRC的校驗增加,修復時需要的幫助單元也會增加.因此利用LRC來修復的校驗單元和余下的q個數據單元都會受此影響.為了減少r增大對修復帶寬率的影響,使r取值范圍更廣,滿足目前的參數配置,提出了第二種編碼Hitchhiker-LRC+.它將所有的數據捎帶在第二個子條帶,避免余下的q個數據受校驗增加的影響,達到降低其修復帶寬率的目的.它雖不能保證數據單元的最優修復,但能降低整體的修復度帶寬率.其架構如圖5所示. 圖5 Hitchhiker-LRC+的架構 3.2.2 編碼過程 編碼過程包括計算校驗并分配捎帶數據、第一個子條帶求LRC和橫向減法三步.后兩步的方式與Hitchhiker-LRC相同,不同之處為第一步中的數據捎帶分配.其如算法2所示. 算法2.Hitchhiker-LRC+的數據分配算法 輸入:k、r、p、A. Step 1.計算p,q的值. 執行公式(2). Step 2.附加p×(r-1-q)數據到前r-1-q校驗上. FORi=0;i pi=pi?f2(ap×i+1,ap×i+2,…,ap×i+p) END FOR Step 3.附加(p+1)×q個數據到P中的后q個校驗上. FORi=r-1-q;i pi=pi?f2(ap×i+1,ap×i+2,…,ap×i+p,ap×i+p+1) END FOR 首先按照公式(2)計算p,q的值;其次給P中的前r-1-q個校驗附加p個A中的數據;然后給P中的后q個校驗附加p+1個A中的數據;最后保證每一次附加的數據都是Q中后r-1個校驗中的同一個校驗的局部校驗.按照上訴方法k個數據將完整的捎帶在p中的校驗上. 以(k=10,r=4)作為編碼的例子,其中l=r=4.第1步計算校驗并分配捎帶數據.按照RS(10,4)的編碼方式計算校驗,將10個數據編碼得到4個線性無關的校驗.接著按照算法2來分配捎帶的數據,其中p=3,q=1,即P中的前2個校驗存儲3個A中的數據,最后一個校驗存儲4個A中的數據.如圖6(a)所示.第2步和第3步的編碼方式與Hitchhiker-LRC相同,不再贅述,分別如圖6(b)、圖6(c)所示. 3.2.3 解碼過程 與Hitchhiker-LRC相比,Hitchhiker-LRC+的解碼過程相對簡單.A和B中數據的恢復只與校驗P有關,與校驗Q無關;同理,校驗的恢復只與校驗Q和P中捎帶的A中的數據有關,與A中其他數據無關.由于所有的數據都捎帶在P中,所以數據的解碼只有一類,同Hitchhiker-LRC,將其稱為dr型.校驗單元同樣還是pn型、ps型和pa型這三類.數據單元和校驗單元的解碼方法均可按照算法1中的方法解碼.對數據單元而言,沒有dl類型,因此在算法1中的Step 1進行類型比較時,不需判斷數據單元的類型,其均為dr類型.由于前r-1-q個校驗與后q個校驗中捎帶的數據量不同,因此下載A中數據的數量不同.前p×(r-1-q)個數據單元的恢復與算法1中的dr相同;后q×(p+1)個數據單元的恢復則需多下載一個幫助的數據,由原來的p-1增加到現在的p.即將原來的ai|i∈{p×p′+1,…,p×p′+p}{x}替換成現在的ai|i∈{p×p′+1,…,p×p′+p+1}{x},將原來的fp′+2(b)?f2(ai)|i∈{p×p′+1,…,p×p′+p}替換成現在的fp′+2(b)?f2(ai)|i∈{p×p′+1,…,p×p′+p+1}.對校驗單元而言,三種類型都不需下載A中余下的q個數據,即不需要下載ai|i∈{p×p′+1,…,p×p′+q}{x}(pn所需)和ai|p×(r-1)+1,…,p×(r-1)+q}{x}(ps和pa所需). 圖6 Hitchhiker-LRC+(10,4)編碼示意圖 當單元失效時,修復該單元的平均下載量占原數據總量的百分比,稱為修復帶寬率γ. (5) (6) 圖7 Hitchhiker-LRC+(10,4)解碼方式 其中δ為總修復下載量,是修復每個單元所需下載的幫助數量之和. δ=δsys+δpar (7) 4.1.1 Hitchhiker-nonXOR (8) 4.1.2 Hitchhiker-LRC (9) 4.1.3 Hitchhiker-LRC+ (10) 讓參與編碼的碼字都在有限域GF(2t)內,為方便分析,假設加法或減法的時間復雜度為O(t),乘法的時間復雜度為O(t2)[25].實際上,一個(k,r)的MDS碼,生成一個校驗或修復一個系統節點需要k次乘法和k-1次加法.分析每種編碼的編碼時間復雜度和平均解碼時間復雜度. 4.2.1 編碼的時間復雜度 a)Hitchhiker-nonXOR共有2r個校驗,其生成有三步,分為捎帶前、捎帶和橫向減法.捎帶前即為產生一個(k,r)的MDS碼,那么生成2r個校驗的時間復雜度為O(2r(kt2+(k-1)t)).第二步為捎帶,每個節點捎帶p個數據,可看做(p,1)的MDS碼,時間復雜度為O(pt2+(p-1)t).其計算的結果還需與捎帶位置的校驗相加.一共有r-1個節點需捎帶數據,因此,捎帶的時間復雜度為O((r-1)(pt2+pt)).剩下的橫向減法的時間復雜度為O(t).所以,Hitchhiker-nonXOR的編碼時間復雜度為O(2r(kt2+(k-1)t)+(r-1)(pt2+pt)+t). b)Hitchhiker-LRC的是在Hitchhiker-nonXOR橫向減法之前多了求局部校驗這一步,其余步驟相同.一共有r個校驗參與,也就是把r個校驗相加,其時間復雜度為O(r-1).所以Hitchhiker-LRC的編碼時間復雜度為O(2r(kt2+(k-1)t)+(r-1)(pt2+pt)+t+r-1). c)Hitchhiker-LRC+與Hitchhiker-LRC的不同點在于捎帶的方式.該方式是前r-1-q個校驗捎帶的是p個數據,后q個校驗捎帶的是p+1個數據.可分別看做(p,1)的MDS碼和(p+1,1)的MDS碼,再加上與捎帶位置的校驗的加法的時間復雜度,得到捎帶的時間復雜度為O((r-1)(pt2+pt)+q(t2+t)).所以,Hitchhiker-LRC+的編碼時間復雜度為O(2r(kt2+(k-1)t)+(r-1)(pt2+pt)+q(t2+t)+t+r-1). 4.2.2 解碼的時間復雜度 解碼分為數據單元和校驗單元,其中第一個子條帶與第二個子條帶也分開計算. (11) (12) (13) Hitchhiker-LRC和Hitchhiker-LRC+兩種編碼的修復帶寬率都會隨著r的增加漸漸次于原Hitchhiker碼.歸其原因為兩種編碼都讓第一個子條帶中的全部校驗都參與了局部校驗的計算.若想讓r的增大不直接影響修復帶寬率,可讓參與局部校驗的數量l隨著r的增加而減少.這樣在修復某一個校驗單元的時,下載的幫助節點變少.當然,如果參與局部校驗的數量太少,采用LRC的方式降低校驗節點的修復帶寬也不明顯.因此對于任意一個(k,r)的參數取值,都存在l,使得兩種編碼的修復帶寬達到最優,其中2≤l≤r.通過分析Hitchhiker-LRC+的解碼過程,得到l動態變化后的總修復下載量δhl+如公式(14)所示. (14) 其中k,r,q,p已知,且k>0,2≤r 本文在HDFS-RAID中實現了Hitchhiker-LRC和Hitchhiker-LRC+兩種編碼,通過策略的方式添加到HDFS中,稱這兩種策略分別為HDFS-HHLRC和HDFS-HHLRC+.根據實驗結果,對比分析Hitchhiker-nonXOR、Hitchhiker-LRC和Hitchhiker-LRC+這三種編碼的修復帶寬率. 實驗部署在分布式系統集群中(Hadoop),集群中由1個NameNode節點和19個DataNode節點組成.所有的節點運行在Ubuntu16.04系統和JDK1.8中,其中每個節點配置2個8核Intel 2.5GHz處理器,48G RAM,2T硬盤和2GB/s以太網卡.實驗數據為500個640M文件,保持默認HDFS的數據塊大小64M,編碼有限域選擇GF(28)設置不同(k,r)參數來分析三種編碼的修復帶寬率. 通過實驗,并結合4.1節中的公式,觀察k與r的關系.圖8(a)描繪在k=10,r={3,4,5,6,7,8}時,三種編碼 Hitchhiker-nonXOR、Hitchhiker-LRC和Hitchhiker-LRC+的修復帶寬率.將Hitchhiker-nonXOR碼作為修復帶寬率的上界,不難看出,當2≤r 圖8(b)描述的是當2 圖8(c)是工業界中常用的參數配置(k,r)=(5,2),(6,3),(8,4),(10,4)時Hitchhiker-nonXOR、Hitchhiker-LRC和Hitchhiker-LRC+修復帶寬率對比圖.圖8(c)中可發現Hitchhiker-LRC+始終保持最低.在參數(k,r)=(5,2),(6,3)時Hitchhiker-LRC和Hitchhiker-LRC+碼相比于Hitchhiker-nonXOR的修復帶寬率都降低了4.2%.在參數(k,r)=(8,4)時,Hitchhiker-LRC因r的增加,修復帶寬率高于Hitchhiker-nonXOR和Hitchhiker-LRC+;Hitchhiker-LRC+的修復帶寬率最低,相對于Hitchhiker-nonXOR降低了2.5%,相對于Hitchhiker-LRC降低了5.2%.在(k,r)=(10,4)時,Hitchhiker-LRC相比于Hitchhiker-nonXOR降低了1.7%;而Hitchhiker-LRC+碼相比于Hitchhiker-nonXOR降低了2.5%. 圖8(d)是工業中常用的參數配置(k,r)=(5,2),(6,3),(8,4),(10,4)時Hitchhiker-nonXOR、Hitchhiker-LRC和Hitchhiker-LRC+編碼時間開銷.三種編碼在這四種參數配置上的時間開銷相互持平,在(k,r)=(5,2)時Hitchhiker-LRC和Hitchhiker-LRC+比Hitchhiker-nonXOR高0.0056%.在(k,r)=(6,3)時Hitchhiker-LRC和Hitchhiker-LRC+比Hitchhiker-nonXOR高高0.0067%,在(k,r)=(8,4)時,Hitchhiker-LRC比Hitchhiker-nonXOR高0.006%;Hitchhiker-LRC+比Hitchhiker-nonXOR高0.29%.在(k,r)=(10,4)時,Hitchhiker-LRC比Hitchhiker-nonXOR高0.0047%;Hitchhiker-LRC+比Hitchhiker-nonXOR高0.12%. 圖8(e)是工業中常用的參數配置(k,r)=(5,2),(6,3),(8,4),(10,4)時Hitchhiker-nonXOR、Hitchhiker-LRC和Hitchhiker-LRC+解碼時間開銷.在參數(k,r)=(5,2)時,Hitchhiker-LRC和Hitchhiker-LRC+的解碼時間開銷略低于Hitchhiker-nonXOR;在(k,r)=(6,3),(8,4),(10,4)時,Hitchhiker-LRC和Hitchhiker-LRC+的解碼時間開銷略高于Hitchhiker-nonXOR. 圖8(f)是工業中常用的參數配置(k,r)=(5,2),(6,3),(8,4),(10,4)時Hitchhiker-nonXOR、Hitchhiker-LRC和Hitchhiker-LRC+修復時間開銷(傳輸時間+解碼時間).根據圖8(f)可知,除了在(k,r)=(8,4)時Hitchhiker-LRC比Hitchhiker-nonXOR的修復時間高,其余參數下Hitchhiker-nonXOR的時間都是最高.實驗證明網絡開銷是Hadoop等平臺的主要瓶頸,增加少量的計算時間,可節省更多的傳輸時間,達到降低整體時間的目的. 圖8 不同k,r的總修復帶寬率、編碼時間、解碼時間和修復時間 本文通過對原Hitchhiker的部分校驗求局部校驗,并讓其存放的位置做橫向減法的方式,構造出兩種新的編碼Hitchhiker-LRC和Hitchhiker-LRC+.這兩種編碼在2≤r2 相關理論基礎
2.1 定義

2.2 LRC
2.3 Hitchhiker碼
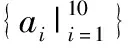
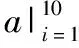

3 改進的Hitchhiker碼
3.1 Hitchhiker-LRC碼

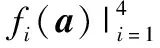
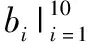
3.2 Hitchhiker-LRC+碼
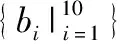
4 理論分析
4.1 修復帶寬率
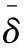
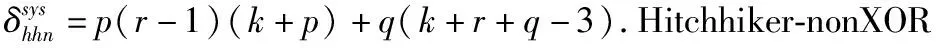
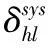
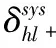
4.2 編碼與解碼的時間復雜度
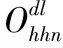
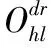
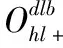
4.3 (k,r)的最優修復帶寬率
5 實驗分析
5.1 實驗平臺
5.2 實驗結果
6 結束語
