基于時效性的爬蟲調度
2020-07-14 00:27:42韓瑞昕
軟件導刊 2020年1期
關鍵詞:搜索引擎
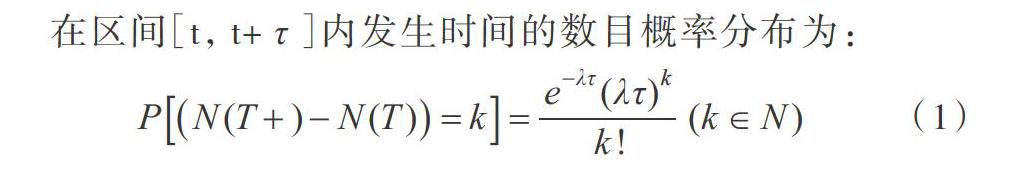
摘 要:搜索引擎作為互聯網信息獲取的入口,實現高效、準確的信息獲取非常重要,爬蟲作為搜索引擎的上游,其重要性不言而喻,特別是大數據時代信息更新頻繁,如何在第一時間獲取新聞是實現爬蟲時效性的重要因素。為了充分利用有限資源,提升帶寬利用率,設計一種基于歷史數據預測的爬蟲調度算法。該算法通過抓取網站歷史,更新頻次積累數據,使用隨機森林回歸建立模型,并在系統中實現爬蟲調度。實驗結果表明,該策略在抓取新鏈的命中率上提升了46%,平均成本降低了11%,平均抓取延時降低了14%。
關鍵詞:搜索引擎;爬蟲調度;回歸預測;隨機森林
DOI:10. 11907/rjdk.191420
開放科學(資源服務)標識碼(OSID):
中圖分類號:TP301
文獻標識碼:A
文章編號:1672-7800(2020)001-0108-05
0 引言
在過去20年里,網絡數據規模增長非常迅速,現已全面進入大數據時代,從基礎行業到尖端行業,大數據無處不在[1]。搜索引擎作為互聯網的一大入口,其重要性尤為凸顯,搜索引擎需要從外部網絡獲取數據進行加工處理,通常由網絡爬蟲作為其上游抓取全網數據[2-4]。互聯網上每天都有大量新網頁產生,如何高效、準確地抓取到最新數據成為一項挑戰。如果爬蟲不能及時抓到突發事件或者相關內容抓取不全,則搜索引擎無法建庫和收錄,導致用戶無法及時搜索到目標內容,則該技術將面臨淘汰。
搜索引擎的4個評價指標為“快、準、新、全”[5-6]。“快”指搜索速度快,用戶等待時間越短越好;“準”指搜索相關性高,返回的結果大部分應是用戶需要的;“新”指時效性,返回的結果需盡快收錄最新文章;“全”指網頁覆蓋率,應當盡可能多地覆蓋全網數據。爬蟲第一時間抓取到頁面才能讓搜索引擎第一時間索引并展示相應內容,因此本文主要針對時效性進行研究。
1 通用爬蟲技術
爬蟲指按照一定規則,自動抓取互聯網信息的程序[7]。爬蟲通常分為通用爬蟲和垂直爬蟲,通用型爬蟲設置好抓取的范圍和目標,達到目標就停止爬取,一般信息較多,覆蓋點比較全但需要清除一些垃圾站點;垂直型爬蟲只關注與特定主題相關的內容或者屬于特定行業的數據,這樣減少了不必要的資源浪費,而且還縮短了網頁抓取時間[8]。兩者根據使用場景的不同各有優缺點,架構區別主要表現在選擇鏈接上。爬蟲從預先設置好的種子頁面開始抓取,之后抽取鏈接擴展鏈接庫,然后根據廣度或者深度優先深入抓取,盡可能多地覆蓋網頁[9-10]。
1.1 基本爬蟲框架
通常爬蟲架構主要模塊為調度模塊、抓取模塊、下載模塊、頁面分析模塊、鏈接選擇模塊、存儲模塊,所有模塊組合起來形成一個閉環,流程架構如圖1所示。
調度模塊( Scheduler)從鏈接選擇模塊(Selector)接受鏈接并將它們分散到一天均勻抓取,交給抓取模塊( Fetch-er)處理抓取參數和控制抓取策略,下載模塊(Downloader)獲取鏈接后從互聯網下載網頁回傳給分發模塊進行處理,然后交給頁面分析模塊( Extractor)抽取相關信息,如頁面摘要、時間因子、垃圾信息、鏈接信息等,再根據策略寫入網頁庫(Pages),新鏈接去重后寫入鏈接庫(Linkbase),鏈接選擇模塊根據鏈接深度決定是否選擇相關鏈接,至此整個流程形成一個持續抓取的閉環[11-13]。
1.2 時效性
爬蟲主要從抓取種子頁面獲取新網頁,新聞列表頁是最典型的種子頁面,搜索引擎時效性主要體現在新聞類網頁上,第一時間抓取到最新的新聞是搜索引擎最重要的功能,所以對一些更新頻繁的頁面,爬蟲也會頻繁抓取,但高頻次的抓取會讓對方網站承受比較大的壓力,導致對方封禁爬蟲,而且這種做法對自身帶寬要求比較高,網頁并不是隨時會更新,若大量訪問卻提取不出新鏈接,則浪費帶寬資源。因此提出時效性問題,對抓取頻次進行精細化控制,需在壓力和時間上作出平衡決策[14-16]。
網頁內容大部分都是人為編輯發布的信息,因此規律和不確定性同時存在。白天信息更新比較頻繁,夜間更新較少;一個欄目的編輯者可能是不同的人,發文時間每天可能不同;突發事件會導致信息更新頻繁,節假日會導致信息更新較少。頻次控制最先實現的是使每個種子頁面用固定的間隔進行抓取,這樣爬蟲能開始初步工作,但是上述問題不能得到解決,這就需要動態地進行頻次控制,對于網頁更新的變化規律,相關學者經過研究發現,泊松過程是描述這種變化規律的最佳模式[17-18]。
泊松過程( Poisson Process)是一種在實踐中常被使用的計數隨機過程,描述特定現象發生次數隨時間變化的規律。如果計算在某一段時間內出現的隨機點數目,該數目也是隨機的,且隨著這段時間延伸的不斷變化,該變化過程為伴隨著隨機點過程的計數過程[19]。
泊松過程有3個特點:時間(或空間)上的均勻性、未來變化與過去變化沒有關系(即獨立增量性)、普遍性。
稱去非負整數的隨機過程[t,t+r]為強度(或速率)為入的泊松過程,如果滿足:①N(0)=0;②N(t)為平穩獨立增量過程;③對任意的0≤s
在區間[t,t+r]內發生時間的數目概率分布為:
在式(1)中,參數A是一個正數和固定參數,稱作抵達率(或強度)。所以給定在區間[t,t+r]內發生時間的數目,則隨機變數N(T+)-N(T)呈現泊松過程,參數為λτ。
2 基于時效性的調度算法
本部分主要介紹基于時效性的調度算法,通過挖掘網頁歷史數據建模,并提出算法評價方法。
2.1 時效性調度算法
互聯網信息更新很頻繁,對于網頁更新的變化規律,可以通過歷史數據挖掘得來。該算法流程如圖2所示。
整個算法分為4個部分:①歷史數據積累;②抽取發布時間;③對歷史數據建模;④應用調度模塊。詳細過程如下:
(1)歷史數據積累。首先爬蟲系統正常運行一段時間,網頁調度算法按默認的間隔抓取,記錄下調度時間和首次抓取時間,保存到網頁庫。
(2)抽取網頁發布時間。爬蟲系統在運行一定時間后,會累積下大量網頁數據,其中正文頁面通常會有文章發布時間,即使沒有,也能通過算法計算出大概文章時間。設正文頁面的父頁面上次調度時間為Tlast,本次調度時間為T now,頁面發布時間T page,可以得出結論Tlast
(3)歷史數據建模。網頁包含發布時間后,即可把同一個種子頁面擴散出去的頁面聚類在一起,根據每個聚類的組,通過隨機森林回歸進行建模,得到種子頁面時效性模型。其中未能抽取出發布時間的頁面和數量過小,不進行模型構建。
(4)應用調度模塊。時效性模型建立好后,在調度時先查詢是否包含有模型,若有則根據模型計算出調度頻率,按照頻率抓取種子頁面。
2.2 隨機森林回歸
隨機森林( Random Forest,RF)是一種基于集成學習( Ensemble Learning)的算法,屬于Bagging類型,通過組合多個弱分類器,并經過投票或者取平均值,使最終模型結果有比較好的精度,并具有良好的泛化性能。隨機森林采用的弱分類器是分類與回歸樹( Classification and Regres-sionrree,CART),既可以用于分類,也可以用于回歸,本文采用隨機森林回歸算法[20],算法描述如下:
(1)為每顆決策樹產生訓練集,使用Bagging抽樣方法生產讓訓練數據有一定的差異性。一般使用無權重抽樣算法,每次抽取過程隨機,之后把結果放還至原樣本里,則抽出來的子集會有重復,能解決局部最優解的問題。
(2)設訓練樣本有N個特征,從樣本中隨機選取其中M個特征,從單顆決策樹開始,從M個特征中最優的特征進行分裂,直到所有訓練樣本在該節點上均為同一類為止。
(3)重復以上兩個步驟,建立K棵決策樹,此時將待預測的樣本輸入決策樹,把所有預測結果進行加權后作為最終結果。因為這些決策樹之間并沒有耦合關系,通常采取并行方式進行處理,所以隨機森林算法速度大幅提高。
2.3 歷史數據建模
爬蟲系統在運行一定時間后,會累積大量網頁數據,其中正文頁面通常會有文章發布時間,即使沒有,也能通過算法計算出大概文章時間。設正文頁面的父頁面上次調度時間為Tlast,本次調度時間為T now,頁面發布時間T page,可以得出結論Tlast< Tpage≤T now。如果Tlast不存在,說明頁面的父頁面是首次調度,不能確認該頁面出現時間。如果T now一T last<1h,則可以把文章發布時間約等于兩次調度的中間值。
本文根據新增數據量每一小時計算一次,每個頁面一天有24個時段的數據,共統計了30天的數據,得到720項數據,每項都為時段內的新增頁面數,抽取部分數據,算法步驟如下:
Input:網頁庫Pages的源數據,Output:網站標識與時間戳集合S
for page in Pages
//提取page的鏈接和發布時間
url,
publish_time←extract( page)
//如果publish_time不存在或者超過30天就跳過
if publish_time not exist or publish_time+ 30days< now then
coniinue
end if
//分離出域名和路徑
host,
path← splitHostAndPath(url)
//分離第一級path
patho ←splitFirstPath( path)
//組合出主鍵
key←host+“一”+path0
//在S集合中S[key]中加入新的發布時間
appendTimeToData(S,key, publish_time)
end for
//遍歷S集合
for key,value in S
//如果網站的新增數據小于閾值不進行后續分析
if size of value< 1000 then
if“一”in key then
//如果包含第一級path,嘗試去掉重新加入S集合
host←splitHostFromKey( key)
appendTimesToData(S,host, value)
end if
//從S集合中刪除網站
deIKeyFromData(S,key)
continue
end if
//對S集合的發布時間集合進行排序
sort( value)
end for
//產出網站標識一發布時間集合的數據集
return S
把上述數據繪制成時間一新增數據量圖(見圖4),可以觀察到每天更新頻率。
為了更清晰地觀察到數據整體趨勢,把時間數據的y軸累加,可以得到圖5,對比上下兩個圖可以觀察到很明顯的新增趨勢,并且有一定的周期性,每天白天為數據更新高發時段,并且在這些圖中有4段更新平緩的區域,對應這30天的4周周末,于是把每天的小時數和每周的周數當作回歸模型自變量。
每個種子頁面均可生成如表1的數據,該數據為模型的訓練數據。其中,hO-h23為每天的時段,w0-w6為每周的周數,均為自變量,value為新增數據量,是模型數據的因變量。
2.4 調度算法評價方法
本文采取多種驗證方法進行評估,一是對預測結果進行隨機交叉驗證,其次是對順序新數據的驗證,最后是應用本文算法預測調度的對比分析。前兩種驗證使用R2Score進行判斷,其公式如式(2)所示,可以衡量模型預測能力優劣。
第二種驗證方法是選擇數據尾部的數據再次計算R2的值,即可判斷預測模型誤差。
常規調度算法是間隔性抓取,不同需求選取不同的抓取間隔,本文把間隔分為10s、20s、30s、1 m、2m,5m、10m、30m、1h、2h幾種情況計算,可按3個維度評判:①每次抓取記為一次成本,統計總成本;②抓取時間與網頁真實出現的差值,最后算出方差;③準確度,單次抓取得到新鏈接標記為抓取準確,總結后可算出最后的準確度。
經過改進的算法僅關注成本,但命中率或延遲不是最優,因為在定間隔抓取中,高頻次會導致成本高、命中率與延遲低。而低頻次的抓取通常可以實現低成本、高命中率與高延遲。新算法的3項指標并不能看出明顯優勢,因此本文把3項指標量化后加權得到公式(4),其中設抓取成本為cost,命中次數為hit,總延遲為delay,加權結果為W。
3 實驗結果及分析
實驗使用Python開發的一套爬蟲框架,主要在鏈接選擇模塊和調度模塊進行時效性驗證,其它模塊僅保留基礎功能。實驗環境為單實例1CIC的Docker集群,出口帶寬保證抓取在lOs內返回。
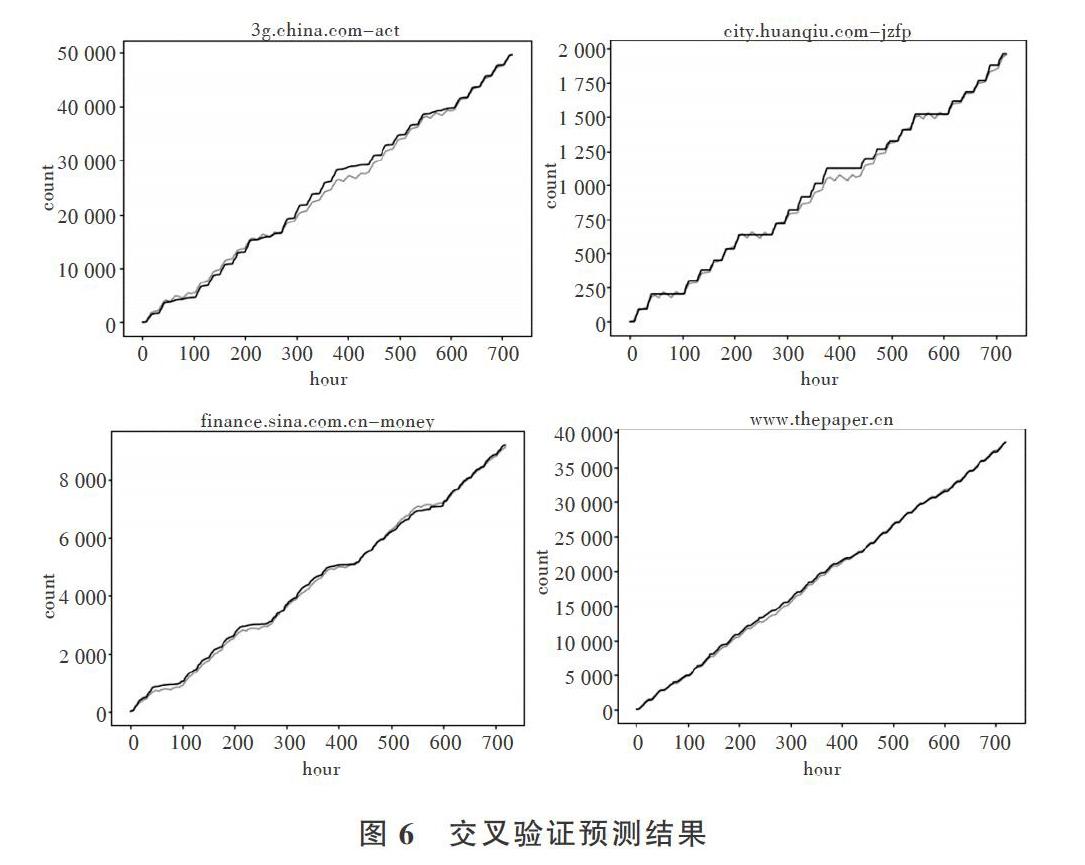
通過隨機森林進行預測后,分別使用交叉驗證和新數據驗證,得到表2的結果。
R2-Score的準確度不太穩定,但是集中在0.6-0.9左右,交叉驗證后可以看到趨勢基本吻合,如圖6所示。
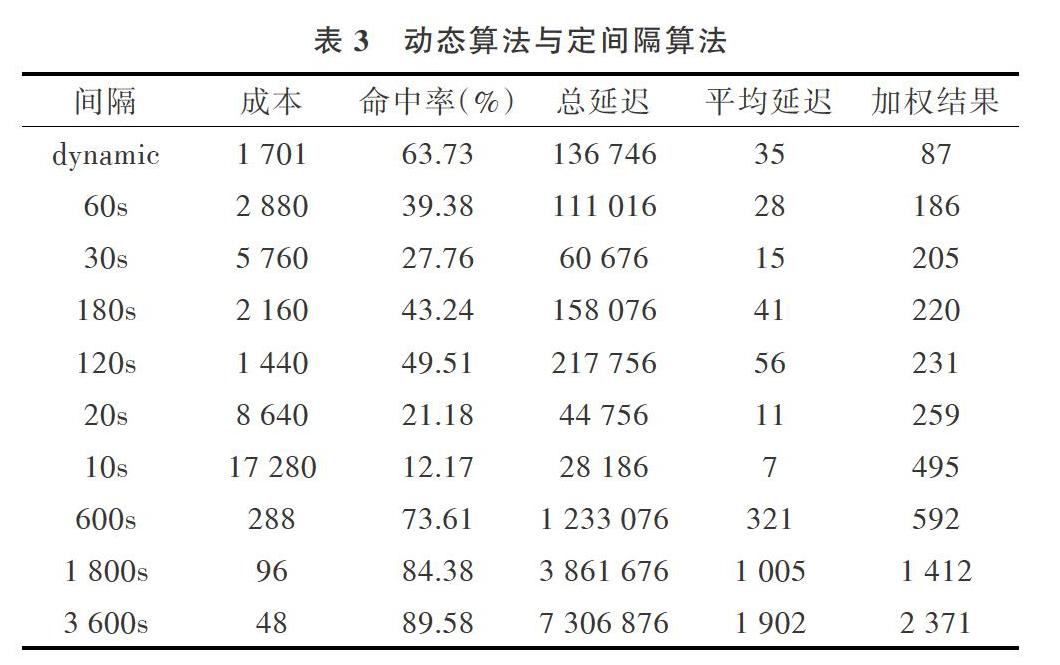
把預測結果經過動態調度算法處理后應用于調度模塊,經過幾種固定間隔和動態調度算法的對比,得到表3所示數據,成本上中間數為2 160,動態調度算法為1 701,減少了11%的成本;命中率上中間數為43%,動態調度算法為63%,提升了46%;平均延遲中間數為41,動態調度算法為35,降低了14%的延遲。可以看到,這些指標均超過平均水平,并且加權后的結果優于其它方法。
4 結語
本文針對爬蟲調度的時效性問題,提出一種根據歷史數據指導新數據調度抓取的算法。與傳統定間隔抓取相比,該算法在成本、命中率、平均延遲上均高于平均水平,很好地提高了實際抓取過程中的抓取效率,并且算法運行速度較快,由于采用比較基礎的回歸算法,所以針對實際抓取場景可在相對低成本下引入,使網絡開銷大幅降低。但是,該算法在應對突發性增長時還不夠靈活,需進一步改進。
參考文獻:
[1]程學旗,靳小龍,王元卓,等.大數據系統和分析技術綜述[J].軟件學報,2014,25(09):1889-1908.
[2] 周德懋,李舟軍.高性能網絡爬蟲:研究綜述[J].計算機科學,2009,(8):26-29+53.
[3] BRIN S,PACE L.The anatomy of a large-scale hypertextual wehsearch engine [Jl. Computer networks and ISDN systems, 1998. 30 ( 1-7):107-117.
[4]ARASU A, CHO J,GARCIA-MOLINA H, et al. Searching the web[Jl. ACM Transactions on Internet Technology, 2001,1(1):2-43.
[5]張興華.搜索引擎技術及研究[J].現代情報,2004(4):142-145.
[6] 馬志杰.國外搜索引擎評價研究綜述[J].圖書館學研究,2013(2):2—6.
[7]KAUSAR M A, DHAKA V, SINGH S K.Web crawler:a review[J].International Journal of Computer Applications, 2013, 63(2):3 1-36.
[8] 周立柱,林玲.聚焦爬蟲技術研究綜述[J].計算機應用,2005(9):1965-1969.
[9]姜杉彪,黃凱林,盧昱江,等.基于Python的專業網絡爬蟲的設計與實現[J].企業科技與發展,2016(8):17-19.
[10] 李應.基于Hadoop的分布式主題網絡爬蟲研究[J].軟件導刊,2016. 15(3):24-26.
[11] YU J,LI M,ZHANG D.A distributed web crawler model hased oncloud computing[C].Dalian: The 2nd Information Technology andMechatronics Engineering Conference, 2016.
[12]YE F,JINC Z, HUANC Q, et al. The research and implementationof a distributed crawler svstem based on Apache flink [C]. Interna-tional Conference on Algorithms and Architectures for Parallel Pro-cessing, 2018:90-98.
[13]YE F, JING Z, HUANC Q, et al. The research of a lightweight dis-tributed crawling system[C].2018 IEEE 16th International Confer-ence on Software Engineering Research, Management and Applica-tions( SERA), 2018: 200-204.
[14]孟濤,王繼民,閆宏飛.網頁變化與增量搜集技術[J].軟件學報,2006(5):1051-1067.
[15]LIU C,WANG W, ZHANG Y, et al. Predicting the popularity of on-line news based on multivariate analysis[C].2017 IEEE Internation-al Conference on Computer and Information Technology (CIT),2017:9-15.
[16]SHI Z, SHI M, LIN W. The implementation of crawling news pagebased on incremental web cra,vler[C].2016 4th International Confer-ence on Applied Computing and Information Technology/3rd Interna-tional Conference on Computational Science/lntelligence and Ap-plied Informatics/lst International Conference on Big Data, CloudComputing, Data Science & Engineering (ACIT-CSII-BCD) ,2016: 348-351.
[17]CHO J, CARCIA-MOLINA H. The evolution of the web and implica-tions for an incremental crawler[ R]. Stanford, 1999.
[18]徐尚瑜.基于泊松過程的爬蟲調度策略分析[J].現代計算機:專業版,2009,( 12):68-71.
[19] FISCHER W,MEIER-HELLSTERN K.The Markov-modulated Poisson process (MMPP) cookbook [J]. Performance evaluation,1993,18(2):149-171.
[20]BREIMAN L Random forests[ J]. Machine learning, 2001, 45(1): 5-32.
(責任編輯:江艷)
作者簡介:韓瑞昕(1994-),男,北京工業大學信息學部碩士研究生,研究方向為軟件工程與理論。.
猜你喜歡
計算機與網絡(2022年2期)2022-03-17 22:48:16
中國衛生(2015年12期)2015-11-10 05:13:38
警察技術(2015年3期)2015-02-27 15:37:09
新疆大學學報(自然科學版)(中英文)(2014年2期)2014-11-06 07:49:12
技術經濟與管理研究(2014年11期)2014-03-11 17:02:44
科學導報·學術論壇(2013年5期)2013-06-26 05:41:54
百科知識(2012年11期)2012-04-29 08:30:15
中原工學院學報(2011年4期)2011-12-27 09:19:14
微型計算機·Geek(2009年1期)2009-12-15 05:37:32
計算機應用文摘(2009年17期)2009-04-29 00:44:03
