考慮時間序列關聯的大壩監測異常數據清洗
2020-07-16 08:18:50鄭霞忠陳國梁
水力發電 2020年4期
鄭霞忠,陳國梁,鄒 韜
(三峽大學水利與環境學院,湖北 宜昌 443002 )
0 引 言
通過分析大壩安全監測數據,評估大壩安全性態,是減少大壩運行風險的重要手段。在監測數據采集過程中,受人為因素、作用環境以及儀器故障等影響,監測數據中不可避免地存在數據異常問題,其中異常數據中粗差的識別與剔除關系到后期大壩安全評估的可靠性。
目前,消減大壩監測數據異常值的方法主要從兩條途徑展開:一是基于假設檢驗辨識異常數值。該類方法假設監測數據中存在異常值,通過均值漂移模型重構監測數據,并計算其與歷史數據間的粗差估計,但受異常值位置的不確定性和最小二乘法的均攤效應影響,數據的整體質量無法保證[1-2]。二是抗差估計,通過構造估值方法控制監測數據與估計值的偏離程度。但該方法普遍存在時效性較差和算法復雜等缺點,不適用于識別由時效性引起的大壩安全監測異常數據[3- 4];并且傳統異常數據清洗方法均是針對單一數據類型,分析數據中的異常值,且過度依賴單一數據變化過程中的突變平滑關系[5],難以甄別異常值是由環境突變還是粗差引起,而由環境突變引起的異常數據是大壩工作狀態的真實反映,不需要進行剔除[6-7]。
考慮到在大壩安全監測過程中,大壩監測的效應量(變形、應力、滲流等)與致因因子(水位、壩體溫度等)間常存在明顯關聯性[8],可利用這些關聯性約束,提高大壩安全監測數據中異常值清洗的準確性。為此,本文提出了一種考慮監測序列間關聯性的數據清洗方法,即通過Apriori算法分析監測序列間的關聯性,篩選強關聯性監測序列,結合DBSCAN算法識別異常數據,根據清洗規則分析辨識異常數據中的粗差,利用粒子群算法(PSO)優化最小二乘支持向量機(LSSVM)數據擬合過程,重構異常數據,從而實現對異常數據的準確清洗。
1 基于關聯規則的監測序列關聯性分析
1.1 關聯規則原理
關聯規則(Association Rules)是數據挖掘技術中常用的算法,主要用于分析數據間的關聯性。根據關聯規則的相關定義[9-10],羅列其中重要概念如下:
(1)事務數據庫。即子集事務的集合,記作C,事務數據庫中子集事務總數記作|C|。
(2)關聯規則。若項集存在A?C,B?C,且A∩B≠?的關系,則表明A→B存在關聯信息,A、B項集為關聯規則中的先導和后繼。
(3)支持度。關聯規則A→B中A∪B項集組合在事務數據庫C中同時出現的概率,記作Psupport(A→B)。ncount(A∪B)為A∪B在事務數據庫C中出現的個數,其數學表達式為
(1)
(4)頻繁項集。若關聯規則的支持度滿足最小支持度要求,則該關聯規則中的項集為頻繁項集。
(5)置信度。在包含項集的子集事務中,同時出現項集B的概率,即項集A發生條件下,項集B的條件概率,其數學表達式為
(2)
(6)序列關聯度和置信度。為分析監測序列間的關聯性,基于關聯規則的分析原理,本文定義監測序列關聯度和置信度數學表達式。對于監測序列A和B,若它們之間蘊含有關聯規則,且其中存在n條關聯規則Xi→Yi滿足最小支持度要求,則關聯度和置信度表達式分別為
(3)
(4)
監測序列關聯性分析過程中,關聯度越高,則表明序列間關聯性越強;為分析序列關聯性的可信度,引入置信度概念衡量關聯規則可信程度,監測序列的置信度趨近1,表明關聯規則具有較高的可信度。若監測序列的關聯規則中的支持度和置信度均滿足最小閾值0.5的參數要求,則稱該組序列為強關聯性序列;否則認為序列間關聯性較弱或不存在關聯。
1.2 監測序列符號化及關聯分析流程
為滿足關聯分析中Apriori算法運算要求,需要對監測序列進行符號化處理。首先,使用滑動窗口L對原始監測序列截取子序列;然后,對子序列進行線性擬合,并對線性方程的斜率值進行標準化處理,使其均處于[-1,1]區間內;最后,依據符號轉換規則,對子序列進行符號化處理,符號轉換規則如表1所示。
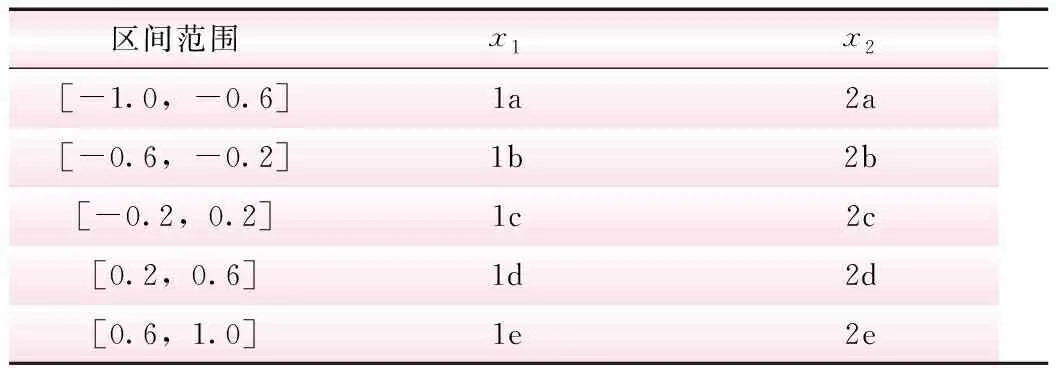
表1 序列符號化表示
符號化處理后的監測序列運用Apriori算法計算其支持度和置信度,根據參數閾值要求,篩選頻繁項集并計算序列關聯度與置信度,最終輸出強關聯性的監測序列。監測序列關聯性分析流程如下:①根據滑動窗口長度截取子序列,并進行符號化處理。②利用Apriori算法選取關聯規則中的頻繁項集。③利用式(3)、(4)計算序列間的關聯度及置信度,輸出強關聯性的監測序列。
1.3 監測序列關聯性分析實例
選取某拱壩15號壩段垂線監測徑向位移和上游水位過程線的歷史數據,數據采集從2013年5月4日開始至2018年6月10日截止,圖1為原始監測數據圖像;數據樣本長度為Ldata=890,設置滑動窗口L=10,得到89個子序列;根據符號轉換規則對序列進行符號化處理,利用Apriori算法進行關聯性計算,結果見表2。
由表2可知,15號壩段垂線測點的徑向位移監測序列和上游水位序列間關聯度和置信度均滿足最小閾值0.5的要求,徑向位移監測序列和上游水位序列間存在強關聯性,與圖1中序列監測直觀結果一致,在后續監測異常數據處理中可結合序列間的關聯性進一步分析。
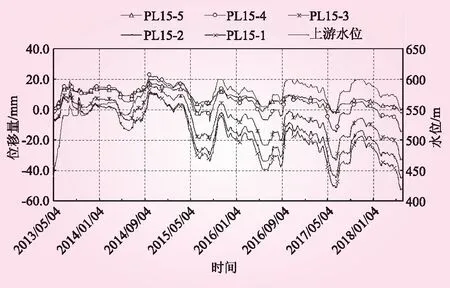
圖1 上游水位和15號壩段徑向位移過程線
表2 上游水位和15號壩段徑向位移關聯性結果
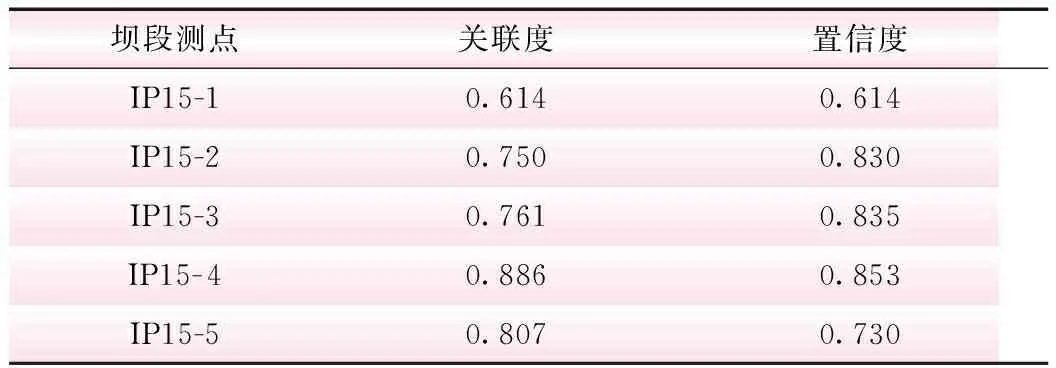
壩段測點關聯度置信度IP15-10.6140.614IP15-20.7500.830IP15-30.7610.835IP15-40.8860.853IP15-50.8070.730
2 大壩監測數據異常檢測和數據清洗
2.1 數據異常值檢測
監測過程中的異常數據與正常數據間存在一定的相異程度,在空間中表現為不同形狀的簇群。為剔除大壩安全監測數據中的異常數據,使用基于密度聚類的DBSCAN算法識別序列中異常數據。該算法在數據聚類過程中具有良好的抗噪性能,能夠在多維空間數據中克服噪聲影響,并識別出任意形狀的相似簇群[11]。DBSCAN算法檢測時間序列的異常值流程如下:①在數據庫中隨機選取一數據點;②檢查數據點是否為核心對象,若是以該點為核心,形成簇群;③否則標記該點為噪聲點,重新尋找(跳轉步驟1)。
2.2 大壩監測序列數據清洗流程及規則
數據清洗是對序列中的異常值點進行剔除和重構,根據產生異常點的原因,異常點可以歸納為傳感數據異常和大壩狀態異常兩類。傳感數據異常指在數據在采集、傳輸過程出現誤差,導致數據異常,該類異常數據屬于數據監測過程的粗差,必須對其進行剔除和重構,以實現數據清洗目的;大壩狀態異常指的是環境突變等原因使得大壩工作狀態出現異常,在監測數據中表現為監測效應量出現突變或極值,該類異常點數據反映了大壩的異常工作性態,數據清洗過程中需將其識別出來,并對大壩安全性態進行分析。
大壩監測數據清洗流程及規則如下:
(1)使用Apriori算法分析大壩監測效應量間的關聯規則及關聯程度。
(2)對弱關聯性的效應量利用DBSCAN算法識別異常點,跳轉步驟4對異常數據進行重構。
(3)對蘊含強關聯規則的監測序列,利用DBSCAN算法進行異常數據識別,并對比分析兩組關聯序列中異常數據出現時刻。若檢測結果中異常數據位于兩組序列的相同時刻,則認為該點異常為環境變量引起與其相關聯的大壩監測效應量的變化,屬于大壩狀態異常數據類型;當異常點單獨出現在個別序列的某一時刻,該類異常數據屬于傳感異常。考慮到當數據異常波動較小時,序列異常數據檢測過程中DBSCAN算法中可能會出現遺漏,利用PSO-LSSVM模型預測強關聯序列中的另一組序列數據,分析關聯序列中是否出現異常數據檢測的遺漏項。若預測結果與采樣原數據間存在較大偏差,表明原始監測數據在采集過程出現誤差,該數據點為異常數據識別的遺漏項,根據關聯序列中同時出現異常數據的判別規則,認為該異常點屬于大壩狀態異常數據;若預測偏差較小,表明相關聯的一組序列并未出現異常數據檢測的遺漏項,異常數據單獨出現在序列中,最終甄別該異常點為傳感數據異常,需要對該數據進行清洗。
(4)利用PSO-LSSVM模型對序列進行預測,重構異常數據。
2.3 基于PSO-LSSVM的數據異常值清洗
考慮到最小二乘支持向量機(LSSVM)在擬合非線性、大體量數據的優勢[12-13],本文采用LSSVM模型對大壩監測序列進行擬合,重構異常數據,實現數據的清洗。同時,為保證LSSVM模型和核函數中參數設置的客觀性,利用粒子群算法優化參數計算。LSSVM模型中參數計算的目標函數為
(5)
式中,ω為權向量;θ為誤差向量;γ為懲罰因子,且γ>0。
考慮徑向基核函數常被用于處理非線性映射關系,將其作為LSSVM的核函數。
(6)
式中,ωi為Lagrango乘子;xi、xj為任意兩個樣本。
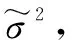
3 案例分析
3.1 無關聯監測序列清洗案例分析
對15號壩段垂線測點PL15-3的切向位移監測數據與上游水位數據進行關聯性分析,發現兩者間關聯程度較低,不存在強關聯規則。以15號壩段垂線測點PL15-3的切向位移監測數據為例,進行無關聯性序列異常數據清洗。該測點切向位移監測序列區間為2013年5月4日~2018年1月4日,樣本長度為813。為驗證本文模型的有效性,對原始數據人為加入異常,分別在第70~80數據點間添加高斯白噪聲,第340個數據點加入異常,第400個數據點剔除數據,異常化處理后序列見圖2。
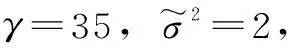
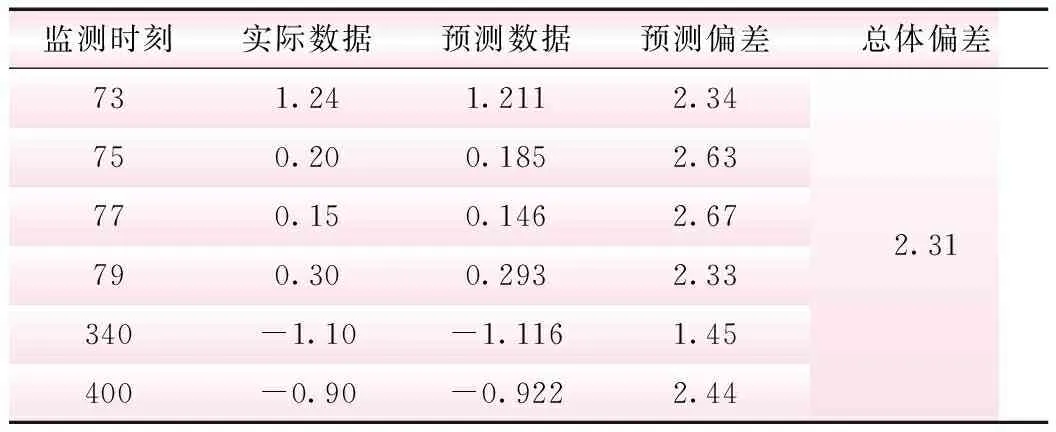
表3 異常點清洗結果
為驗證本文數據預測模型的準確性,針對第77個數據點,選取傳統BP神經網絡模型、小波神經網絡模型及支持向量機模型進行預測比較,其預測結果偏差分別為2.85%、3.58%、2.98%,均大于本文模型預測偏差,驗證了本文所提出模型的準確度。
3.2 強關聯性監測序列清洗案例分析
1.3節中序列關聯性分析實例中已論證了15號壩段PL15- 4測點垂向位移監測數據與上游水位序列間存在強關聯性,在本節中以這兩組監測序列為案例,進行強關聯序列間的數據清洗。利用DBSCAN算法識別兩組監測序列間的數據異常點和缺失點,若待清洗數據點為傳感數據異常,則利用基于PSO-LSSVM模型進行數據重構。
(1)兩組關聯序列數據采集時間段均為2013年5月4日~2018年6月10日,采集間隔時均為2 d采集一次。利用算法同時對兩組序列進行異常數據檢測,發現在第76、107、411、512、536、619、744、887個數據點處兩組監測序列同一時刻均出現異常數據。已知測點PL15- 4垂向位移監測數據與上游水位序列間存在強關聯性,若在同一時刻出現異常數據,根據清洗規則,認為該類數據是由環境發生較大變化時所引起大壩狀態變化,為大壩狀態異常數據。該類異常數據為大壩工作性態的真實反映,不需要進行清洗,必要時可發出監測預警。
(2)第二類異常點為單獨出現在測點PL15- 4垂向位移監測序列中的異常數據點。對第二類異常數據點進一步區分,判斷相關聯的序列在同一時刻的數據是否為異常數據遺漏項。根據關聯數據清洗流程,對關聯序列中的另一組數據上游水位進行預測,計算預測偏差。上游水位在第66、368、482數據點預測偏差分別為10.87%、3.94%、1.37%。第368、482數據點的預測偏差較小,表明上游原始監測數據正常,非異常數據檢測的遺漏項,從而判斷測點PL15- 4垂向位移監測序列在第368、482數據點的異常數據為傳感器異常,需要對其進行數據清洗;上游水位在第66個數據點預測偏差為10.87%,大于10%的誤差閾值,說明DBSCAN算法異常數據檢測過程中將其遺漏,該點數據應為上游水位傳感器異常數據。根據關聯序列異常數據判斷條件可知,認為測點PL15- 4垂向位移監測序列在第66個數據點為大壩異常數據,不需要進行數據清洗,應對該點大壩工作狀態進行進一步分析。
4 結 論
本文提出考慮監測效應量間關聯性的異常數據清洗方法,并結合大壩典型位移監測數據進行了實例分析,得到如下結論:
(1)考慮監測異常數據中可能包含外界環境引起監測效性量突變,結合異常數據成因,細分異常數據類型,過濾不需清洗大壩狀態異常數據。
(2)引入PSO計算LSSVM模型及核函數中相關參數,克服參數設置的主觀性,與常用序列預測方法比較,PSO-LSSVM模型能進一步提高數據擬合精度。
(3)利用大壩安全監測數據間的關聯性特點,將關聯規則結果運用到異常數據分析過程中,并結合PSO-LSSVM模型,提高了數據清洗的準確性。
猜你喜歡
小獼猴智力畫刊(2022年3期)2022-03-29 01:09:42
新世紀智能(數學備考)(2021年9期)2021-11-24 01:14:30
當代陜西(2021年17期)2021-11-06 03:21:36
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:26:14
當代陜西(2019年15期)2019-09-02 01:52:00
幸福(2018年33期)2018-12-05 05:22:42
學苑創造·A版(2018年11期)2018-02-01 06:29:20
Coco薇(2017年11期)2018-01-03 20:59:57
讀者(2017年5期)2017-02-15 18:04:18
暨南學報(哲學社會科學版)(2016年9期)2017-01-15 13:52:02
