基于機器學習算法的圖書館書目協同推薦系統
2020-07-23 08:54:49劉巖
現代電子技術 2020年14期
劉巖


摘? 要: 為了向讀者推薦更多感興趣的書目,提高讀者對圖書館書目推薦的滿意程度,文中提出基于機器學習算法的圖書館書目協同推薦系統。依托系統整體架構設計和實時協同推薦模塊設計,完成系統的硬件設計;通過書目間相似度的計算和數據庫設計,完成系統的軟件設計,實現圖書館書目協同推薦系統的設計。結果表明,基于機器學習算法的圖書館書目協同推薦系統相比于傳統協同推薦系統,讀者的滿意程度提升了77%,讀者可以閱覽更多感興趣的書目。
關鍵詞: 圖書館書目; 協同推薦; 系統設計; 機器學習算法; 滿意程度; 對比驗證
中圖分類號: TN911?34; UP181? ? ? ? ? ? ? ? ? 文獻標識碼: A? ? ? ? ? ? ? ? ? ? ? ?文章編號: 1004?373X(2020)14?0180?03
Library bibliographic collaborative recommendation system based on
machine learning algorithm
LIU Yan
(Zhengzhou University of Light Industry, Zhengzhou 450000, China)
Abstract: A library bibliographic collaborative recommendation system based on machine learning algorithm is proposed to recommend more interested books to readers and improve reader satisfaction with bibliographic recommendation in libraries. The hardware design of the system is completed based on the design of overall system architecture and real?time collaborative recommendation module, the software design of the system is completed by means of the calculation of similarity between bibliographies and database′s design, and thus the design of collaborative recommendation system for library bibliography is realized. The results show that, in comparison with the traditional collaborative recommendation system, the reader satisfaction of the library bibliography collaborative recommendation system based on machine learning algorithm has increased by 77%, and readers can read more interested books.
Keywords: library bibliography; collaborative recommendation; system design; machine learning algorithm; satisfaction degree; comparison verification
0? 引? 言
圖書館書目協同推薦是指在機器學習算法的背景下,利用相似度計算的方式向讀者推薦相關書目。主要有兩種形式,分別是基于讀者的協同過濾和基于書目的協同過濾,基于讀者的協同過濾是根據讀者對書目的瀏覽記錄或購買行為,向讀者推薦相似書目的過程;基于書目的協同過濾是根據圖書館書目的被瀏覽記錄或被購買行為,向讀者推薦相似書目的過程[1]。協同推薦與機器學習之間有著密切的聯系,協同推薦需要利用大量的機器學習數據,對系統的儲存能力有很高的要求,機器學習算法為實現圖書館書目的協同推薦帶來了可能性。機器學習算法在協同推薦系統中的應用是最廣泛的,主要應用在電子商務領域和社交媒體領域,在高校圖書館領域的應用相對較少。圖書資源是圖書館中一種比較傳統的資源類型,圖書館協同推薦系統主要是利用讀者的檢索歷史、書目瀏覽歷史以及借閱歷史等相關數據,來為讀者提供推薦[2]。傳統的圖書館書目協同推薦系統是利用讀者的檢索詞匯和鏈接點擊行為,來構建讀者的興趣偏好,采用合適的方式將合適的書目在合適的時間推薦給讀者。本文在總結現有協同推薦系統不足的基礎上,考慮到圖書館環境的特殊性,提出基于機器學習算法的高校圖書館書目協同推薦系統。
1? 圖書館書目協同推薦系統硬件設計
由于圖書館書目的協同推薦需要利用大量的機器學習數據,才能保證將用戶偏好的書目推薦給讀者。首先設計了系統的邏輯架構,圖書館書目協同推薦系統的邏輯系統架構分為存儲層、協同推薦層、業務層和邏輯層[3]。系統的邏輯體系結構如圖1所示。
協同推薦層的設計是整個系統的核心,可以加快圖書館書目協同推薦系統的響應速度,其中管理器的設計可以加強書目信息的管理,使書目信息順利傳輸到Hadoop集群中,并在集群中顯示出書目的評分情況和瀏覽情況,將瀏覽數據儲存在集群中,作為下一次推薦的參考[4]。
系統的業務層設計是將協同推薦層和系統的應用層緊密聯系在一起,共同完成讀者在系統上的請求。業務層中計算機設計可以驗證讀者的身份信息,驗證后將讀者的信息上傳到服務器中[5],然后將書目推薦給讀者。服務器設計可以實現用戶的登錄、注冊、信息驗證,以及對圖書館書目的管理上包括圖書的詳細信息和推薦等。
將業務層和協同推薦層分開,可以增強系統的通用性,將存儲層與協同推薦層分開,可以降低系統的耦合性,使協同推薦層不用考慮書目數據的容災問題。如果系統的存儲服務器出現故障,在其他服務器上重啟即可,不需要考慮書目數據的遷移情況,提高了系統的可用性。
以上以確保系統穩定運行為目的,設計系統的邏輯體系架構,以二次推薦為目的,設計Hadoop集群架構,完成系統的整體架構設計;并結合系統實時協同推薦模塊設計,實現系統的硬件設計[6?8]。
2? 圖書館書目協同推薦系統軟件設計
2.1? 計算書目間的相似度
在機器學習算法中,給定書目瀏覽量數據集[T=x1,y1,x2,y2,…,xn,yn∈X×Yt],對任意兩本書的瀏覽記錄[vi]和[vj],定義兩個特征量之間的距離度量為[δvi,vj],利用距離可以找到與數據集中瀏覽記錄相近的書目[9]。再根據讀者已經選擇過的書目內容信息,將與讀者曾經選擇過的相似書目推薦給讀者。相似度的計算會抽取圖書館所有書目的特征詞匯來描述書目,并構建圖書館書目配置文件,利用讀者已經選擇過的書目信息特征詞匯,來描述讀者對不同類型書目的興趣,構建讀者配置文件,通過將書目配置文件與讀者配置文件之間的相似度加以比較,向讀者推薦與讀者配置文件相似的書目。
在計算圖書館書目之間的相似度時,采用的是對讀者的不同特征關鍵詞的相似度函數[10],再將相似度函數進行組合,并賦予它們相應的權重[11],計算出書目之間的相似度:
[SimX,Y=i=1mwiSimXi,Yi]? ? ? ?(1)
式中:[SimX,Y]表示讀者選中的書目與目標書目之間的相似度;[wi]表示讀者在特征詞i上的權重系數;[SimXi,Yi]表示讀者在特征詞匯i上的相似度。
對于有層次書目,屬性的相似度為[12]:
[SimX,Y=11+ρx,y]? ? ? ? ?(2)
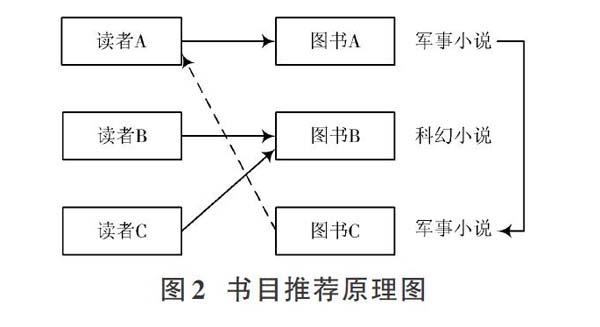
機器學習算法的書目推薦原理如圖2所示。
將每一種書目的屬性描述出來才能計算出書目之間的相似度,簡單地說就是從圖書館書目的題材類型開始描述。假設讀者A喜歡A類型書目,讀者B和讀者C喜歡B類型的書目,根據書目間的信息描述可以確定,書目A和書目C會被協同推薦系統認為兩者是具有相似度的書目,因為他們的在題材類型上都屬于軍事小說;由于讀者A喜歡A類型圖書,那么協同推薦系統就會向A讀者推薦與書目A相似度高的書目C。
2.2? 數據庫設計
由于圖書館書目協同推薦系統具有較大的儲存數據量,在計算書目之間的相似度時,會使計算量和計算難度加大,因此數據庫的設計將書目的瀏覽記錄加以分類,降低相似度計算的難度。數據庫的設計主要分為非關系型數據庫和數據表的結構設計。在系統數據庫中,要根據書目的瀏覽信息,將瀏覽次數多的書目推薦給讀者,需要共享的信息有讀者基本信息、書目信息、書目瀏覽信息以及書目申請信息等[13]。文中讀者基本信息、書目信息和書目申請信息不做過多設計,下面只設計數據庫中的書目瀏覽信息表,如表1所示。
系統的管理員可以根據數據庫中的書目瀏覽記錄,將瀏覽次數多的書目推薦給讀者,為讀者減少尋找的時間[14]。根據讀者已經選擇過的書目內容信息,將與讀者曾經選擇過的相似書目推薦給讀者,計算出目標書目與讀者選擇書目之間的相似度,完成書目之間相似度的計算。依托系統數據庫的E?R圖,設計書目瀏覽信息表,系統可以根據書目的瀏覽記錄向讀者推薦書目,完成系統數據庫的設計,從而實現系統的軟件設計。
3? 對比實驗
3.1? 準備階段
實驗數據來自于某一大學圖書館,從圖書館數據庫中隨機抽取985個讀者,按照上述實驗方式進行實驗。設定讀者預推薦感興趣的書目(10本),觀察實驗結果。
將讀者的短期書目信息需求界定為最近一學期內,可能產生于學習相關的書目信息需求。選取圖書館數據集中近4年的書目數據作為協同推薦模塊的數據集。為了區分同一個讀者在不同學期對圖書館書目的偏好值,針對書目的每一條閱覽記錄和借閱記錄,在讀者ID前面加上借閱或閱覽記錄產生時間所對應的學期編號,作為借閱記錄或閱覽記錄新的讀者ID。
3.2? 實驗參數訓練
實驗準備階段完成后,直接根據文中相似度的計算,計算出書目之間的相似度,并獲取到讀者偏好值數據。然后利用讀者對書目的偏好值數據來訓練系統,選擇合適的讀者相似性測度方法以及近鄰數量K。不同的協同推薦系統得到的推薦效果是不同的。
本實驗選用平均絕對偏差來評估圖書館書目的推薦情況,這種方法的原理是選擇圖書館數據集中的一小部分數據作為推薦,剩下的一部分數據作為實驗參照數據集,計算出推薦結果的預計偏好值與參照數據集中的讀者實際偏好值之間的偏差。MAE的值越小,書目推薦的準確度越高,就越可以讓讀者滿意。
3.3? 實驗結果分析
傳統協同推薦系統推薦效果中,有322位讀者獲得2本感興趣的書目,讀者的態度標記為“不滿意”;有345位讀者可獲取 4本感興趣的書目,讀者的態度標記為“一般”;有180位讀者獲取到7本感興趣書目標記為“滿意”;有78位讀者獲得9本感興趣的書目,讀者的態度標記為“非常滿意”。
使用基于機器學習算法的圖書館書目協同推薦系統進行推薦時,有385位讀者獲得9本感興趣的書目,讀者的態度標記為“非常滿意”;有410位讀者獲得7本感興趣的書目,讀者的態度標記為“滿意”;有115位讀者獲得4本感興趣的書目,讀者的態度標記為“一般”;有75位讀者獲得2本感興趣的書目,讀者的態度標記為“不滿意”。經過統計運算得到相應統計圖像如圖3所示。
從實驗結果中可以看出,讀者對傳統協同推薦系統的滿意程度較低,僅僅有78個讀者“非常滿意”,大多數讀者都表示“一般”或“不滿意”的態度,分別占35%和32.7%,“非常滿意”和“滿意”的讀者僅占0.08%和18.3%;而本文設計的協同推薦系統,只有極少部分的讀者持有 “一般”和“不滿意”的態度,大部分讀者都持有“非常滿意”和“滿意”的態度,分別占39.1%和41.6%。因此可以得出本文設計的協同推薦系統可以滿足讀者對圖書館書目的推薦。
4? 結? 語
本文提出基于機器學習算法的圖書館書目協同推薦系統。依托圖書館書目協同推薦系統的硬件設計和軟件設計,實現了圖書館書目協同推薦系統的設計。結果表明,基于機器學習算法的圖書館書目協同推薦系統相比于傳統協同推薦系統,讀者的滿意程度提升了77%。希望本文的研究可以為基于機器學習算法的圖書館書目協同推薦系統提供理論指導。
參考文獻
[1] 汪慧芳.淺析高校圖書館推薦書目工作[J].鄂州大學學報,2017,24(6):58?59.
[2] 肖紅.大數據下的機器學習算法探討[J].通訊世界,2017(6):265?266.
[3] 朱天元.機器學習算法在數據挖掘中的應用[J].數字技術與應用,2017(3):166.
[4] 沈晶磊,虞慧群,范貴生,等.基于隨機森林算法的推薦系統的設計與實現[J].計算機科學,2017,44(11):164?167.
[5] 梁建勝,黃隆勝,徐淑瓊.基于視頻內容檢測的協同過濾視頻推薦系統[J].控制工程,2018,25(2):305?312.
[6] 劉一鷗.基于人工魚群算法的圖書館推薦平臺設計[J].電子設計工程,2017,25(15):6?8.
[7] 馬元元,蔣子規,劉艷飛,等.基于室內定位技術的圖書館推薦算法[J].蘭州理工大學學報,2018,44(2):102?106.
[8] 黃文明,程廣兵,鄧珍榮,等.基于用戶特征的分步協同推薦算法[J].計算機應用研究,2017,34(4):1047?1049.
[9] 朱白.數字圖書館推薦系統協同過濾算法改進及實證分析[J].圖書情報工作,2017,61(9):130?134.
[10] 廖漳.基于協同過濾算法的電影個性化推薦系統設計與實現[J].通訊世界,2017(5):278?279.
[11] 吳國麗,蔣昌睿.基于協同過濾算法的個性化醫療推薦系統設計與實現[J].福建電腦,2017,33(8):107.
[12] 梁建勝,黃隆勝,徐淑瓊.基于視頻內容檢測的協同過濾視頻推薦系統[J].控制工程,2018,25(2):305?312.
[13] 羅亞.基于決策過程的個性化推薦系統設計[J].計算機工程與應用,2017,53(14):105?110.
[14] 張龍昌,張洪銳.數字資源云服務推薦系統設計[J].計算機技術與發展,2017,27(8):139?144.
[15] 馬元元,蔣子規,劉艷飛,等.基于室內定位技術的圖書館推薦算法[J].蘭州理工大學學報,2018,44(2):102?106.
