跨傳感器異步遷移學習的室內單目無人機避障
2020-07-28 01:24:10薛喜地楊學博孫維超于興虎高會軍
宇航學報 2020年6期
李 湛,薛喜地,楊學博,孫維超,于興虎,2,高會軍,3
(1. 哈爾濱工業大學智能控制與系統研究所,哈爾濱 150001;2. 哈爾濱工業大學寧波智能裝備研究院,寧波 315201;3. 哈爾濱工業大學機器人技術與系統國家重點實驗室,哈爾濱 150001)
0 引 言
近年來,各種類型的無人機在軍民領域得到了廣泛的成功應用,從巡查航拍到自主協作、分布式定位建圖等[1-2],都大幅提高了人們的工作效率。小型多旋翼無人機體積小、機動性高等特點使其在包括室內的各種復雜環境中執行多種任務。因此,在復雜陌生環境中實現自主智能導航,則能夠充分利用其高機動性多自由度的特點,執行大量地面移動機器人無法完成的任務,如地面擁擠情況下的物資傳遞、快速巡查追蹤等[3-4]。然而,無人機的高性能自主導航算法的研究非常具有挑戰性,在環境結構不確定、光線不穩定,以及室內存在具有形態差異大、行走方向隨意性高的行人等場景下,如何實現自主穩定導航一直是該領域的難點之一。
目前,基于模型的方法[5-6]是無人機自主決策導航的常用手段,但其效果過度依賴于對無人機自身動態及其所處環境的精確建模。同時,對環境和自身建模的計算量巨大,且對建模時存在的模型誤差難以進行補償。對于初次到達的陌生環境,更是需要重新進行一系列的建模工作,使得該類算法應用范圍較為狹窄。
與此不同,自然界的生物則通過不斷與環境進行交互,并且獲得環境的反饋來強化生物的某項能力。例如動物的行走、捕獵、群體協作等能力,均是在不斷試錯的過程中來持續改善和提升自身的決策策略與技能。該類型學習過程的特點是無需對環境進行精確建模,僅通過與環境的不斷交互來持續改進策略,即為強化學習算法[7]的核心思想。可以看出,強化學習屬于端到端的學習類型,即輸入一個環境狀態,直接輸出一個決策動作。
然而,由于強化學習應用于無人機導航決策領域的時間較短,現有研究存在的主要問題有:1)強化學習策略的遷移問題:目前強化學習最關鍵的環節是仿真環境,如果仿真環境里建立的幾何模型和物理模型能夠足夠逼近現實世界,那么在仿真環境里訓練好的策略直接移植到實物無人機上即可獲得一致的效果。但建模誤差通常難以避免,因此仿真環境訓練得到的策略遷移到實物無人機上的效果并不理想。文獻[8]提出一種仿真數據與現實數據相融合的方法(Generalization through simulation, GTS),將仿真環境下訓練得到的卷積層與現實數據訓練得到的全連接層拼接在一起,使得仿真模型與現實環境得到一定程度上的統一。但該方法仍存在策略遷移造成的性能降低,如其在仿真環境下無人機的運行軌跡比較平直,而遷移到實物之后卻比較扭曲。因此,強化學習策略從仿真環境移植到實物,仍存在一系列需要開展深入研究的遷移學習問題。2)在有行人場景下采用無深度信息單目視覺感知的避障性能有待提高:單目無深度信息的攝像頭具有成本低、重量輕、使用門檻低等特點,在小型無人機上應用日趨廣泛,但由于無深度信息,以及行人的多樣性及高動態性,使采用單目視覺實現室內有行人環境的端到端導航具有較高挑戰性。現有基于單目視覺的無人機室內導航方法,大多數都是在無人的室內環境下進行實驗,這也就導致該類算法在實際環境中的實用性不足。前述GTS算法是目前基于強化學習的無人機自主導航方向較為前沿的研究,但其依舊是在無行人干擾的環境下進行實驗。
本文的主要貢獻為:1)針對強化學習策略遷移問題,提出一種基于跨傳感器遷移學習的全新框架,使得遷移到實際環境中的策略對比現有方法具有更好的泛化性能。2)為進一步提高室內有行人環境下的單目無深度信息避障性能,提出了一種異步深度神經網絡結構,通過規劃器與行人信息的結合,解決現有方法由于行人形態差異過大造成的策略不穩定問題,使得在不具備深度信息的情況下,仍能夠實現在室內有行人時的有效、穩定避障。實驗結果表明了該方法的有效性和可行性。
1 仿真環境和任務介紹
1.1 仿真環境
本文基于Cyberbotics公司研發的Webots仿真平臺對無人機在室內環境下的三維自主避障任務進行仿真,強化學習系統的框圖如圖1所示,虛擬仿真環境如圖2所示。在Webots仿真器中進行強化學習訓練,涉及到其中的三個高級組件:1)場景樹:在場景樹里配置物理引擎的仿真步長、無人機、三維環境等信息,用以仿真“世界”的搭建;2)控制器:用以搭建無人機的底層控制以及強化學習算法,控制無人機的運動;3)監督器:用以監控仿真環境的運行,以及根據控制器在強化學習訓練時發出的重置環境指令重置環境。同時,Webots仿真環境提供了一系列Python的接口函數,方便研究人員直接控制仿真環境里現有的無人機模型。本文深度強化學習所用到的深度學習框架為Pytorch框架。
在圖1中,“控制器”模塊和“強化學習”模塊共同組成一個智能體(即無人機的“大腦”),該智能體從“無人機仿真環境”中獲取環境狀態觀測之后,給出一個決策動作去作用于“無人機仿真環境”模塊,而“無人機仿真環境”模塊返回給智能體相應決策動作所產生的環境狀態改變,如此構成了一個完整的強化學習經典反饋框架。為使仿真環境更加接近現實環境,本文在仿真環境搭建了一個類似室內走廊場景的虛擬環境,如圖2中的(a)圖和(b)圖所示。仿真所用到的小型無人機如圖2(c)所示,為Webots平臺內置無人機模型,在仿真環境里可以通過接口函數獲取電機轉速、陀螺儀、加速計、氣壓計、GPS定位等數據,用于后續算法開發。
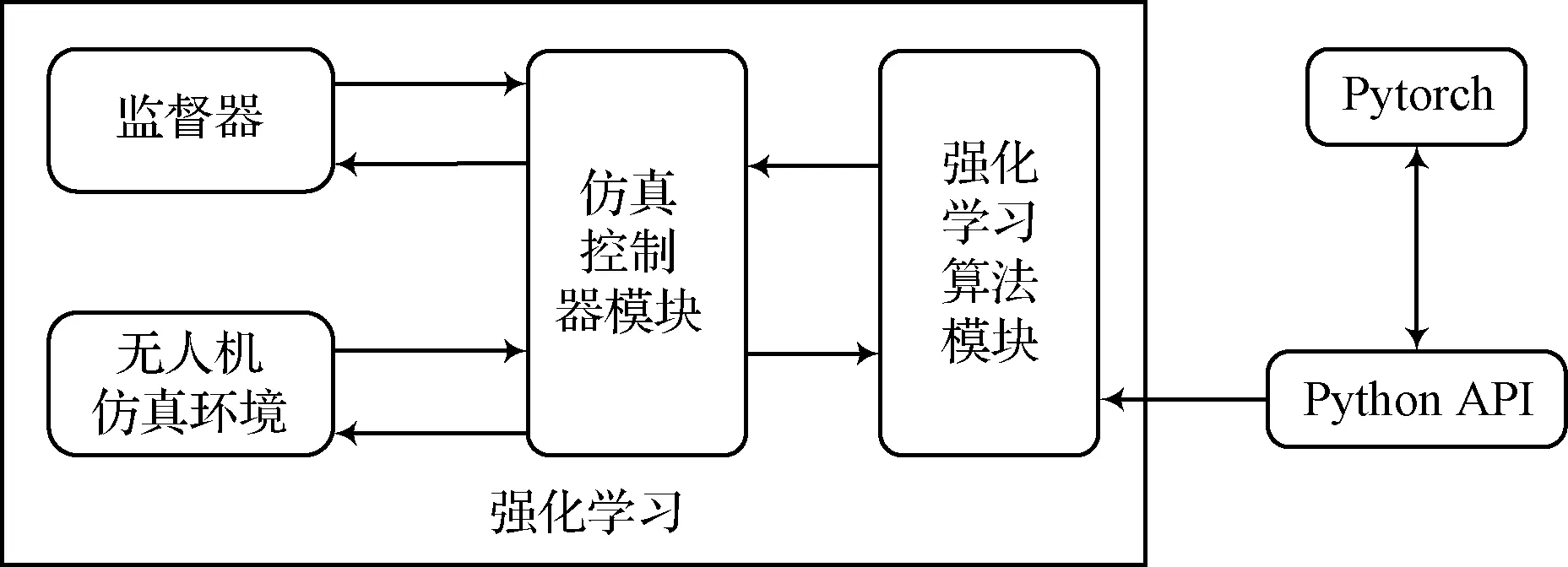
圖1 強化學習系統Fig.1 Reinforcement learning system

圖2 三維仿真環境Fig.2 3D simulation environment
值得注意的是,在仿真環境里并未直接采用單目相機作為傳感器,而是采用激光雷達作為傳感器,是因為仿真環境里采集到的相機圖像不夠逼近現實,將會大幅降低遷移效果。同時為方便模型搭建,本文將Webots內置的激光雷達模型直接連接于無人機上方,但將其重量參數設置為零,因此不會對飛行控制帶來額外問題,如圖2(c)所示。同時,為與后續實際環境下采集數據所用的RPLidar A2型激光雷達參數保持一致,這里將仿真環境里的激光雷達的刷新頻率設置為15Hz。此外,為了實現從激光雷達到單目視覺的跨傳感器遷移學習,本文將仿真環境和現實環境下的單線激光雷達的可視范圍均限制在無人機正前方的180°范圍內,從而與攝像頭的視野范圍基本保持一致。
1.2 任務介紹
本文所涉及的實驗任務可描述為:首先,在1.1節所述的仿真環境中,結合深度強化學習方法,訓練得到一個穩定的初級避障策略。無人機在仿真建筑物中自主漫游,將其最主要的目標設定為“存活”的更久。其次,在現實環境中,結合上述初級避障策略來進行跨傳感器的遷移學習,使其能夠更好的適應現實環境。特別地,現實環境與仿真環境的一個明顯差異是現實環境中存在行人這一不確定因素,因此在遷移過程中還需要研究提高有行人場景下的避障策略的穩定性和適應能力。
2 深度強化學習和遷移學習結合的室內無人機避障
2.1 基于DDPG算法的室內無人機避障
近些年來深度強化學習算法取得了顯著進展,其中“深度”指的是強化學習結合了深度神經網絡,其優勢在于其能夠通過上百萬甚至千萬的參數實現強大的擬合與泛化能力。因此將強化學習的訓練參數以深度神經網絡的形式擬合,極大的擴寬了強化學習的應用范圍。本文采用深度確定性策略梯度[9]強化學習算法(Deep deterministic policy gradient, DDPG),其網絡結構如圖3所示。該算法結合了Q-Learning強化學習算法和深度學習的優勢,是一種基于策略梯度(Policy gradient)的學習算法。DDPG算法為離線策略(Off-policy)類型的算法,具有經驗回放(Memory replay)機制,該機制類似于人類在跟外界環境交互的過程中儲存起來的記憶。每次訓練時隨機在記憶池里抽出一定數量(Batch size)的樣本來訓練,類似于人類的“反省”,有了經常的“反省”,算法對于歷史數據的利用將更加充分,有利于得到效果更優的策略。
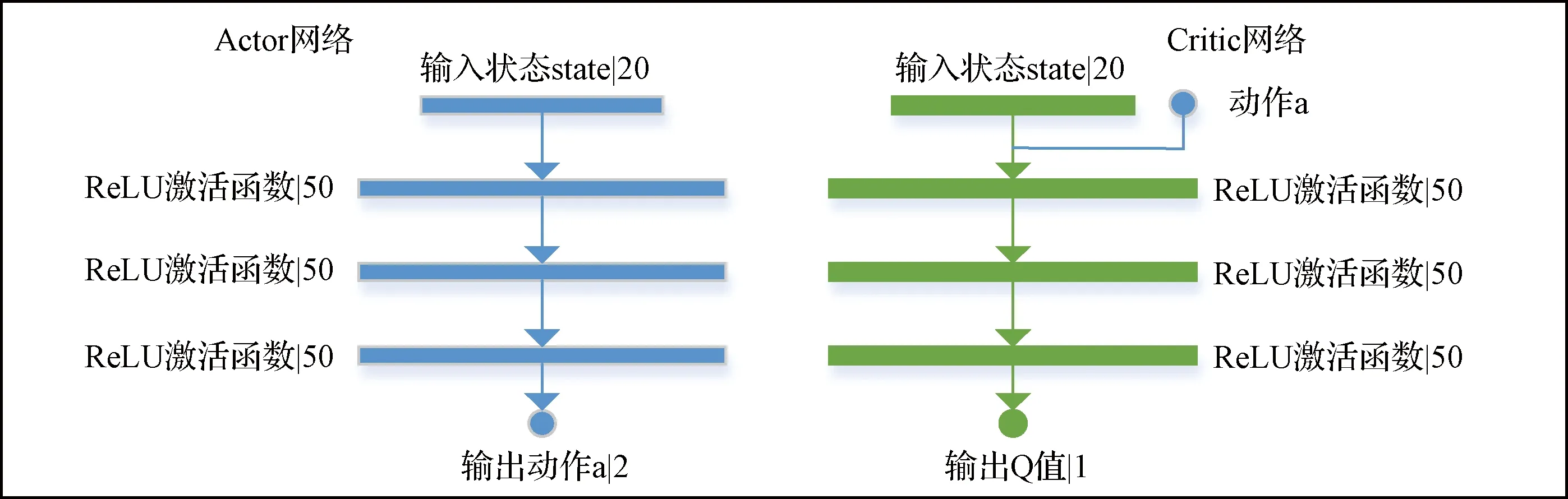
圖3 本文的DDPG算法網絡結構示意圖Fig.3 Schematic diagram of DDPG algorithm network structure for this work
DDPG網絡結構上不考慮后期的優化因素,可以看作是由兩個深度網絡構成,其中一個是表演者(Actor),從環境獲取狀態信息s,輸出執行動作a;另一個是評論者(Critic),其結合環境的狀態信息s以及表演者輸出的動作a,輸出一個評分。因此兩個網絡構成了對抗競爭的關系,其中表演者的目標是要最大化評論者的評分,評論者的目標時最小化自己給出評分的變化率(旨在使其策略穩定下來)。因此當DDPG算法訓練收斂之時,表演者可以針對當前環境給出一個比較優秀的動作,而評論者也可以給出一個比較準確的評分。因此表演者網絡和評論者網絡的代價函數如式(1)所示。其中la和lc分別為表演者網絡和評論者網絡的代價函數,表演者最大化評論者的評分q,也就是要最小化-q。表演者最小化狀態值函數的變化量。
(1)
DDPG算法同一般強化學習算法一樣,具有狀態空間(State space)、動作空間(Action space)、回報函數(Reward function)三大要素,而這三大要素隨著不同任務而變化。本文所設計的三要素如下。
1) 狀態空間:本文的強化學習算法在仿真環境里進行訓練,利用單線激光雷達作為環境感知傳感器,因此狀態空間定義為單線激光雷達的一系列深度值數組,本文對其180°范圍內的數據進行降采樣,每隔9°采樣一次,組成一個長度為20的數組。此時激光雷達數據儲存格式如式(2)所示。其中s表示狀態空間,D表示新的激光雷達數據。li表示表示降采樣后的第i個激光雷達射線對應的深度值。
s=D=[l1,l2,…,l18,l19,l20]
(2)
動作空間:DDPG強化學習策略可以輸出連續的動作空間,而本文設定沒有全局定位信息,因此將動作空間a分解為無人機的線速度v和偏航角速度w,如式(3)所示。值得注意的是,神經網絡往往比較適合處理-1~1之間的數據,因此在這里將無人機的線速度和角速度均映射到[-1, 1]區間。
a=[v,w]
(3)

(4)
(5)
2.2 跨傳感器強化學習策略的遷移
本文2.1節詳細敘述了無人機使用單線激光雷達作為傳感器在仿真環境下訓練得到穩定的初級避障策略,本節進一步研究從只使用激光雷達傳感器的初級避障策略,到只使用單目視覺的實物無人機避障策略的跨傳感器遷移學習方法。整體算法框架如圖4所示
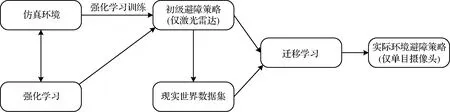
圖4 整體算法結構圖Fig.4 The overall algorithm structure diagram of this work
遷移學習包含眾多類型的算法,其中比較實用的一種類型是模仿學習[10-13],其核心思想為在遷移學習新策略過程中,存在一個專家策略來不斷地指導新策略,在遷移學習訓練的過程中,目標是縮小新策略與專家策略之間的差距。因此,模仿學習屬于有監督學習。
專家策略的獲取方法有多種,例如監督學習、半監督學習、無監督學習等等。本文研究的核心問題在于將仿真環境訓練得到的策略遷移到實際環境當中,因此采用2.1節訓練得到的初級避障策略作為專家策略,屬于無監督學習類型。
如圖5所示,在進行遷移學習訓練之前,需要用攝像頭以及激光雷達傳感器在如圖6所示的現實環境中采集數據,并利用上述專家策略來對數據集進行自動標注。在采集數據集過程中,攝像頭圖片數據與單線激光雷達數據在每個程序周期里進行對齊及同步,實現兩種傳感器數據的逐幀綁定。

圖6 現實世界環境示意圖Fig.6 Schematic of the real world environment

圖5 激光雷達和攝像頭安裝結構示意圖Fig.5 Lidar and camera fixed structure diagram
值得注意的是,激光雷達的刷新頻率為15 Hz,因此將攝像頭的圖片采樣周期也強制同步至15 Hz。從另一個角度分析,如采樣頻率過高,采集到的數據在短時間內的相似度很高,則會占用過多的計算資源且意義不大。
采集得到的數據集格式為一系列(I,L)數據對,其中I為圖片數據,L為激光雷達數據。圖片大小為640×480,格式為RGB。采集數據完畢之后,對數據集進行離線處理。利用2.1節中訓練得到的初級避障策略作為專家策略,輸入數據集中的激光雷達數據,專家策略輸出一系列決策動作a來作為圖片數據集的標簽,這也就實現了遷移學習過程中的自動標注。處理后的新數據集格式為(I,B),其中B為專家策略輸出的一系列決策動作a,用來當作圖片數據集的標簽。
最后,遷移學習利用上述離線處理得到的新數據集來訓練深度網絡,也就實現了跨傳感器強化學習策略的遷移學習。深度神經網絡采用的是性能優良的Resnet18深度神經網絡,同時,Pytorch深度學習框架提供了Resnet18網絡的部署實現模板,使用非常方便。因此,本文在其模板網絡結構后添加了規格為(256, 128, 16)的三層全連接層,網絡最終有兩個輸出,分別是無人機的給定線速度v和給定偏航角速度w。
在訓練時,網絡的一個批次數據大小采用的是128,代價函數采用經典的均方誤差,如式(7)所示。其中l為網絡的整體代價函數,lv為回歸線速度v部分的子代價函數,lw為回歸給定偏航角速度w部分的子代價函數,兩個子代價函數的具體表達式如式(7)和(8)所示。
l=lv+lw
(6)
(7)
(8)
3 基于異步深度網絡的有行人環境優化
本文第2節提供了本次工作所設計的跨傳感器遷移學習的詳細內容,實現了在室內無人環境下的無人機自主導航避障。然而,室內經常會有形態差異大、行走方向隨意性大的行人群體存在,這將導致2.2節所述方法得到的避障策略在有行人時表現出與行人交互不友好、路徑不穩定等問題。
導致上述遷移學習策略在有行人場景下表現不佳的原因可以追溯到以下兩點:1)Resnet18網絡在有行人場景下的泛化能力不足,源自于其網絡結構較為簡單所帶來的弊端;2)從上述遷移學習擬合得到的策略可以看出,遷移學習得到的策略依舊為端到端決策類型的策略,而端到端策略的優勢在于研究人員不必去詳細研究其計算過程,只需關心該策略的輸入和輸出即可,輸入一張圖片即可輸出一個決策動作。但同時也帶來一個很嚴重的問題,即輸入一張帶有行人的原始圖片數據,神經網絡的“注意力”可能會更多地聚焦在室內的建筑物環境上,而在行人身上投入較少的“注意力”,這也會導致無人機在有行人場景下與行人交互不友好,甚至為了保持與建筑物的安全距離而撞到行人。
因此,本文提出一種基于異步深度網絡的神經網絡結構來改善有行人情況下的無人機避障性能,該異步網絡結構如圖7所示。從圖中可以看出,異步網絡結構具有兩個分支,左側分支為Resnet8深度網絡,右側分支為YOLO v3-tiny深度網絡[14-16],兩個分支網絡的輸出最終匯聚到一起,經過四個全連接隱藏層,最終輸出的決策動作分別是無人機的給定線速度v和給定偏航角速度w。其中“異步”指的是,為了提高整個網絡在前向傳播時的計算速度,本文將resnet18和YOLO v3-tiny兩個分支分別放置在兩個子線程下進行運算,最終兩個線程的計算結果在主線程上匯總,再將匯總起來的計算結果經過四個全連接隱藏層的計算后輸出結果。
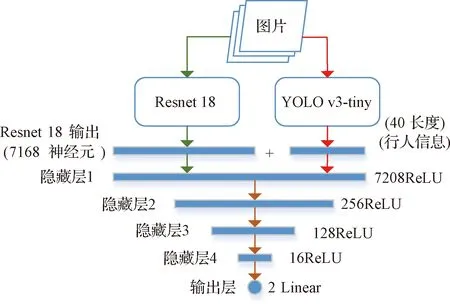
圖7 異步網絡結構示意圖Fig.7 Schematic diagram of asynchronous network
YOLO v3系列網絡借鑒了殘差網絡結構[17-19],形成層數更深的神經網絡,有著更強大的擬合能力。同時其采用多尺度檢測的圖像金字塔[20-21]機制,提升了預測框的平均重合率(mAP)以及對體積較小物體的檢測性能。而YOLO v3-tiny為YOLO v3網絡的簡化版,犧牲部分預測準確率以及回歸精度來很大程度上提升網絡的前向傳播速度。YOLOv3-tiny的前向傳播速度甚至可以達到YOLO v3網絡的10倍左右,易于在輕量級移動設備上使用。
該網絡結構的特點是利用YOLO v3-tiny網絡卓越的分類能力,將環境中的行人信息提取出來,再與Resnet18的結構融合后進行綜合決策,這也解決了本節開頭所述的兩大問題。值得注意的是,本文所使用的YOLO v3-tiny網絡為利用Coco數據集進行預訓練過的網絡,因此可以直接使用YOLO v3-tiny網絡來提取行人信息。
其中YOLO v3-tiny網絡輸出行人預測向量信息(對于每個行人輸出一個預測框),該向量格式如式(9)所示,pi表示第i個行人的圖像中預測框的位置信息,其中xti,yti表示第i個行人預測框在圖像中的左上角坐標,同樣xbi,ybi表示第i個行人預測框在圖像中的右下角坐標。最終行人向量信息如式(10)所示,其中pi表示第i個行人的預測框信息。這里取行人個數上限為10個人,因為對于一般情況室內同一視野內同時近距離出現超過10個人的可能性非常小,換而言之,若近距離人數超過10個則當前環境非常擁擠,無人機幾乎無法在這種場景下飛行。若當前視野內人數不足10個人時,則該行人向量末端用0補齊。同樣地,該異步網絡訓練時的代價函數等配置與2.2節所述一致。
pi=(xti,yti,xbi,ybi)
(9)
f=(p1,p2,…,p9,p10)
(10)
4 實驗結果及分析
4.1 仿真環境下強化學習訓練結果分析
強化學習訓練的回報函數曲線如圖8所示,從圖中可以看出無人機在仿真環境中隨著訓練時間的增加,其與環境交互所獲得的回報也越來越多,最終趨于平穩,在宏觀上表現為無人機穩定在建筑物內無碰撞飛行,這也從正面驗證了本文2.1節所設計回報函數的合理性。硬件設備為GTX 1080Ti GPU、i7 8700 K CPU,訓練所花費時長約為3.7 h。
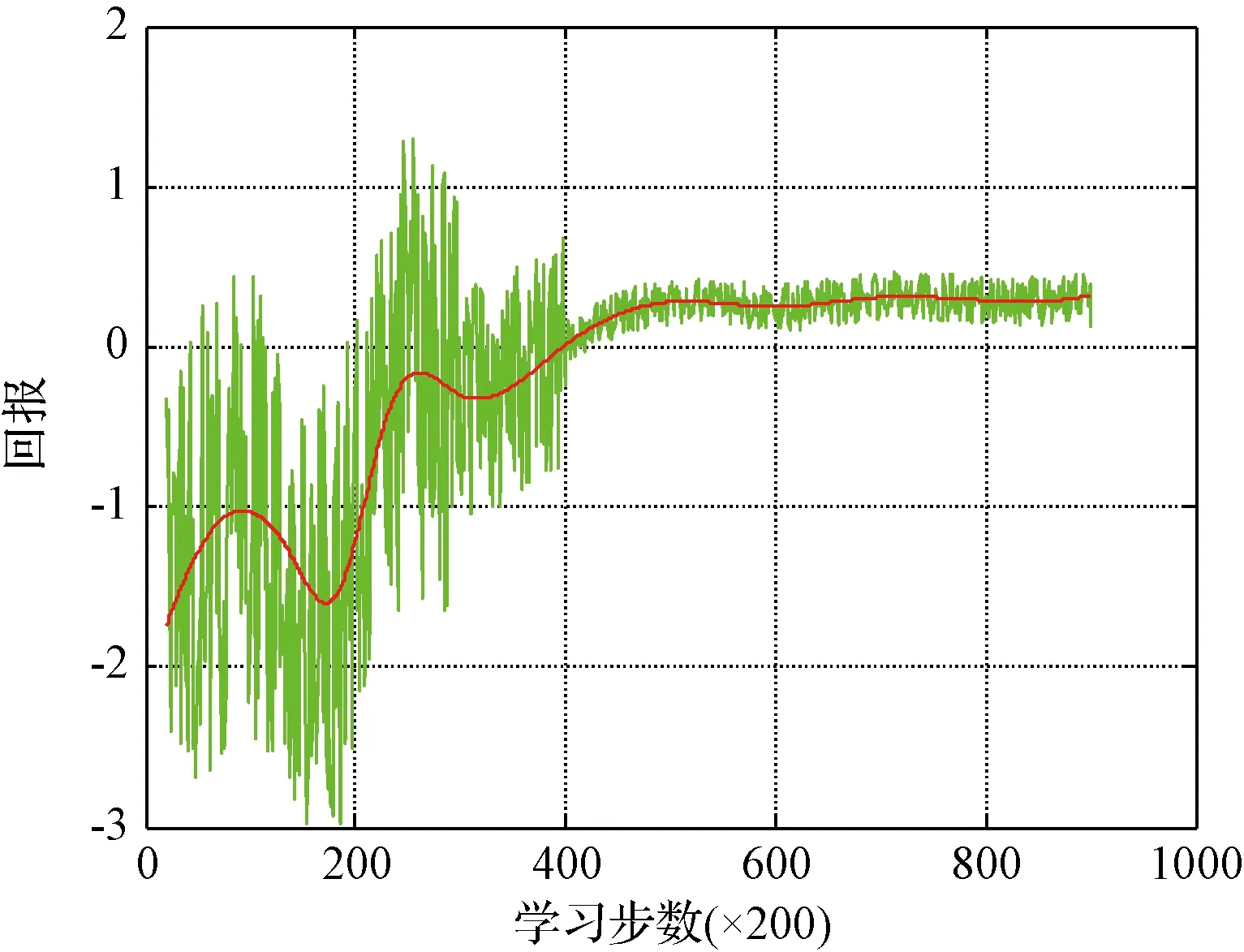
圖8 回報函數曲線Fig.8 Reward function data
4.2 跨傳感器遷移學習訓練結果分析
網絡的擬合能力對比分析:跨傳感器遷移學習、采用分段動態學習率,下降曲線如圖9(a)曲線所示。動態學習率使得網絡梯度在每個訓練階段都以相對比較合適的下降速度來更新網絡參數,防止網絡下降過慢或者梯度爆炸。訓練所用的硬件設備與4.1節所述一致,數據集總量為100,000數據樣本,將整個數據集訓練200次總耗時約為20 h。從圖9中左側圖片的曲線(“*”形狀)可以看出,隨著訓練的進行,損失函數不斷收斂,最終趨于0附近。這表明該異步網絡結構有足夠的能力擬合有行人環境下的數據集。而單獨Resnet18的損失函數下降曲線如圖9左側圖片中的藍色曲線(“-”形狀)所示,可以看出單獨Resnet18網絡訓練該數據集最終也能逐漸趨于收斂,但其擬合精度的瓶頸比較明顯,最終的擬合精度要比異步深度網絡低。
網絡的前向傳播速度的對比分析:圖9(b)表示在幾次室內導航任務中深度網絡的平均輸出幀率,其中曲線(“*”形狀)表示雙線程運行異步網絡的輸出幀率曲線變化,曲線(“-”形狀)表示單線程運行異步網絡的輸出幀率隨時間變化曲線。綜合兩條曲線可以明顯看出基于雙線程運行的幀率大致為單線程的2倍。這意味著雙線程運行的網絡前向傳播速度有顯著提高。本次實驗也在NVidia公司的TX2單板計算機上測試了該異步網絡的平均幀率,其結果是25.7 Hz,這意味著在機載計算環境中亦可以保證實時性。
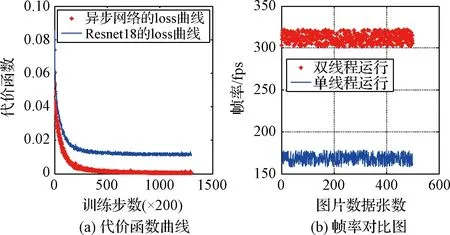
圖9 代價函數下降曲線及網絡幀率對比圖Fig.9 Cost function decline curve and network frame rate comparison chart
異步網絡在室內有行人實際場景中的泛化能力分析:為了檢驗該異步深度網絡在有行人環境下的泛化能力,在實際有行人的室內環境中進行了飛行測試,部分飛行軌跡圖如圖10所示。其中實線軌跡是本次研究所設計算法的無人機飛行軌跡,虛線軌跡是GTS算法的在實物上復現的飛行軌跡。通過對比軌跡可以發現實線軌跡幾乎是全程在以最大安全裕度在飛行,同時在有行人的情況下也能夠非常穩定和平滑度軌跡避開行人。而虛線軌跡相對比較扭曲和不平滑,最終虛線曲線在“行人”文字標記處碰撞到行人而導致任務結束。從而綜合以上可以得出,本文所設計的異步網絡在有行人環境下具有較好的泛化能力和軌跡穩定性。
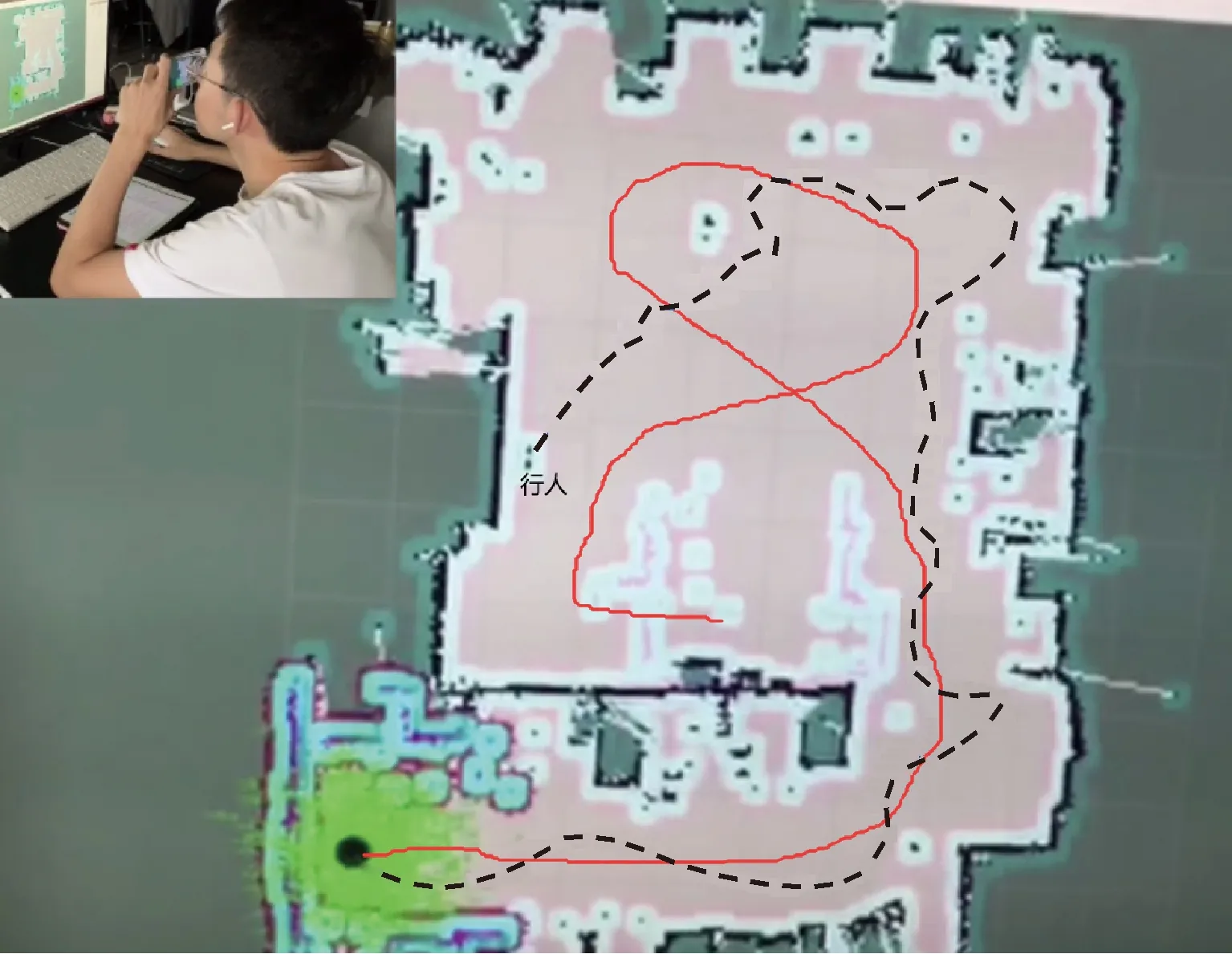
圖10 無人機飛行軌跡對比圖Fig.10 Comparison chart of UAV flight trajectory
各算法無人機飛行測試中的存活時間對比分析:如圖11所示,本次飛行存活測試分別測試了基本DDPG算法、GTS算法、單Resnet18網絡、異步網絡在上述條件下的性能。為了與目前較為有代表性的算法性能做對比,本文分別在室內有行人、室內無行人、室內光線不穩定、陌生室內等幾種環境下對無人機進行飛行存活時長測試。這里“存活時長”定義為從無人機起飛開始計時,在室內漫游飛行至無人機發生碰撞為止所花費的總時長。值得注意的是,為了使得各個算法更有可對比性,本文在做該項測試時盡量保證了各算法的基本條件一致,主要包括室內行人數量、光線、硬件設備、計算平臺等主要因素。對于某一個算法在某一個場景下分別測試多次,最終取平均結果作為最終的參考存活時長。
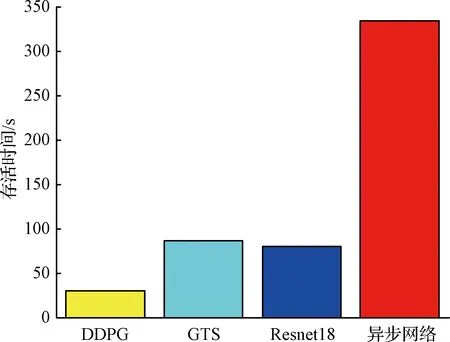
圖11 無人機存活時間對比圖Fig.11 Comparison chart of UAV survival time
從圖11中可以看出,基本DDPG算法的性能最弱,這是由于其仿真環境里的視覺部分遷移到現實世界效果不佳。同時可以看出,單Resnet18網絡與GTS算法的性能幾乎持平,而基于異步網絡結構的算法性能遠超另外三種算法,這也說明了異步網絡結構的算法有著更好的穩定性和更友好的行人交互性能。
值得注意的是,這里的基礎DDPG算法指的是在仿真環境里直接用單目視覺的圖片數據作為狀態輸入,DDPG算法直接輸出決策動作,最后將訓練收斂的策略直接移植到實物上進行測試。
5 結 論
本文首先在Webots仿真環境訓練得到一個穩定的僅使用虛擬激光雷達作為傳感器的初級避障策略;其次通過將真實激光雷達與單目攝像頭圖像數據逐幀綁定來采集現實環境中的數據集,利用上述初級避障策略當作專家策略,實現從虛擬激光雷達到現實單目視覺的跨傳感器遷移學習;最后針對室內有行人的場景設計了一種基于Resnet18網絡和YOLO v3-tiny網絡相結合的異步深度神經網絡結構,改善了單Resnet18深度網絡進行遷移學習時,在有行人室內環境下的避障效果,同時基于雙線程的機制極大加速了深度網絡的前向傳播速度。仿真及實驗結果表明,本文所提出基于跨傳感器異步遷移學習方法能夠在光線不穩定、陌生、有行人的室內環境下,相對于現有工作有著泛化能力更強、軌跡裕度更大、更穩定的優點。
猜你喜歡
中老年保健(2021年12期)2021-08-24 03:30:40
中國傳媒大學學報(自然科學版)(2021年1期)2021-06-09 08:43:00
中學生數理化·七年級數學人教版(2020年11期)2020-12-14 06:59:52
中學生數理化(高中版.高考理化)(2020年2期)2020-04-21 05:32:50
中國生殖健康(2020年6期)2020-02-01 06:28:50
小學生作文(低年級適用)(2019年9期)2019-10-08 08:37:10
藝術品鑒證.中國藝術金融(2018年8期)2019-01-14 01:14:28
藝術品鑒證.中國藝術金融(2018年10期)2019-01-08 02:44:26
中國生殖健康(2019年11期)2019-01-07 01:28:02
藝術品鑒證.中國藝術金融(2018年12期)2018-08-26 06:03:48
