融合主題信息和卷積神經(jīng)網(wǎng)絡(luò)的混合推薦算法
2020-08-06 08:28:12田保軍房建東
計(jì)算機(jī)應(yīng)用 2020年7期
田保軍,劉 爽,房建東
(1.內(nèi)蒙古工業(yè)大學(xué)信息工程學(xué)院,呼和浩特 010080;2.內(nèi)蒙古工業(yè)大學(xué)數(shù)據(jù)科學(xué)與應(yīng)用學(xué)院,呼和浩特 010080)
(*通信作者電子郵箱ngdtbj@126.com)
0 引言
隨著互聯(lián)網(wǎng)信息的指數(shù)型增長(zhǎng),用戶的選擇更加多樣化,這樣雖能更好地滿足用戶需求,但是快速查詢所需要的信息變得越來(lái)越困難。為了幫助用戶擺脫困境,推薦系統(tǒng)[1]應(yīng)運(yùn)而生,其中協(xié)同過(guò)濾推薦[2]和基于內(nèi)容的推薦[3]是當(dāng)前推薦系統(tǒng)的兩種主流技術(shù),但這兩種方法都存在著諸多缺點(diǎn)。其中,數(shù)據(jù)稀疏性是傳統(tǒng)的協(xié)同過(guò)濾模型存在的主要問(wèn)題[4],而基于內(nèi)容的推薦獲取的又是淺層特征,不能很好地描述用戶與項(xiàng)目的行為[5],導(dǎo)致推薦精度不高。深度學(xué)習(xí)模型恰好能夠提取到深層次的特征,將深度學(xué)習(xí)能夠?qū)W習(xí)到的稠密、連續(xù)、多層次的用戶和項(xiàng)目的特征,例如:近鄰關(guān)系、主題關(guān)系以及用戶的評(píng)論和標(biāo)簽信息等[6-9],與協(xié)同過(guò)濾推薦融合,使得混合推薦系統(tǒng)不僅具有傳統(tǒng)推薦方法的簡(jiǎn)單、可解釋性強(qiáng)等優(yōu)點(diǎn),而且使得推薦精度更高。目前,傳統(tǒng)的推薦算法與深度學(xué)習(xí)算法進(jìn)行結(jié)合已經(jīng)成為越來(lái)越多的研究者關(guān)注的研究熱點(diǎn)[10]。
Kim 等[11]提出了基于卷積矩陣因子分解(Convolutional Matrix Factorization,ConvMF)模型,利用卷積神經(jīng)網(wǎng)絡(luò)(Convolutional Neural Network,CNN)處理項(xiàng)目的文本信息,學(xué)習(xí)到項(xiàng)目的隱特征,融入到通過(guò)PMF 模型分解的評(píng)分矩陣中,提高了評(píng)分預(yù)測(cè)的準(zhǔn)確性。但是該方法僅僅根據(jù)評(píng)論的原始文字來(lái)提取項(xiàng)目的連續(xù)全局特征,忽略了文檔中顯著的主題特征信息。Liu 等[12]提出了一種改進(jìn)的基于主題模型隱狄利克雷分布(Latent Dirichlet Allocation,LDA)的協(xié)同過(guò)濾算法。該算法根據(jù)用戶項(xiàng)目評(píng)分矩陣建立LDA 模型,獲取用戶多個(gè)顯著特征單獨(dú)表示信息,得到用戶項(xiàng)目選擇概率矩陣,然后按照項(xiàng)目屬性對(duì)項(xiàng)目集進(jìn)行聚類,根據(jù)聚類結(jié)果對(duì)矩陣進(jìn)行裁剪。實(shí)驗(yàn)結(jié)果表明,主題模型可以有效地提高推薦的精度。張敏等[13]將評(píng)論信息引入推薦系統(tǒng)中,提出棧式降噪自編碼器(Stacked Denoising AutoEndoder,SDAE)與隱含因子模型(Latent Factor Model,LFM)相結(jié)合的混合推薦方法,進(jìn)一步地提升了推薦模型對(duì)潛在評(píng)分預(yù)測(cè)的準(zhǔn)確性。Hyun等[14]提出了一個(gè)可擴(kuò)展評(píng)論感知的推薦方法SentiRec(Sentic Reccommendation),它在建模用戶和項(xiàng)目時(shí)被引導(dǎo)結(jié)合評(píng)論的情感。該方法分兩步:第一步將每篇評(píng)論編碼成一個(gè)固定大小的評(píng)論向量,這個(gè)向量經(jīng)過(guò)訓(xùn)練以體現(xiàn)評(píng)論的觀點(diǎn);第二步根據(jù)向量編碼的評(píng)論生成推薦。實(shí)驗(yàn)結(jié)果表明,該方法不僅優(yōu)于現(xiàn)有的神經(jīng)網(wǎng)絡(luò)推薦方法,而且推薦效果優(yōu)于僅僅考慮評(píng)論上下文連續(xù)特征的方法。Chen 等[15]提出了一種聯(lián)合神經(jīng)協(xié)同過(guò)濾推薦系統(tǒng)的方法,它是一種將深度特征學(xué)習(xí)和深度交互建模與關(guān)聯(lián)矩陣相結(jié)合的聯(lián)合神經(jīng)網(wǎng)絡(luò)。深度特征學(xué)習(xí)基于用戶-項(xiàng)目評(píng)分矩陣,通過(guò)深度學(xué)習(xí)架構(gòu)提取用戶和項(xiàng)目的特征表示,聯(lián)合訓(xùn)練使深度特征學(xué)習(xí)和深度交互建模過(guò)程相互優(yōu)化,從而提高推薦性能。
綜上所述,利用深度學(xué)習(xí)技術(shù)、融合多源異構(gòu)數(shù)據(jù)成為提高推薦系統(tǒng)準(zhǔn)確性的一種重要方法,但是已有相關(guān)研究還存在很多問(wèn)題。其中,從項(xiàng)目評(píng)論信息提取的項(xiàng)目特征面臨著艱巨的問(wèn)題就是輔助數(shù)據(jù)的表示,輔助數(shù)據(jù)表示還存在著單一性和準(zhǔn)確性不高問(wèn)題。
針對(duì)以上問(wèn)題,本文提出了一種基于隱狄利克雷分布(LDA)與CNN 的概率矩陣分解推薦模型(Probability Matrix Factorization recommendation model based on LDA and CNN,LCPMF)。該模型綜合考慮項(xiàng)目評(píng)論文檔的主題信息與深層語(yǔ)義信息,分別使用LDA 主題模型和文本卷積神經(jīng)網(wǎng)絡(luò)對(duì)項(xiàng)目評(píng)論文檔建模,獲取項(xiàng)目評(píng)論文檔的顯著潛在低維主題信息及全局深層語(yǔ)義信息,接著通過(guò)線性加權(quán)組合得到項(xiàng)目隱因子矩陣,最后融合到PMF 概率矩陣分解PMF 模型中,產(chǎn)生預(yù)測(cè)評(píng)分進(jìn)行推薦。通過(guò)實(shí)驗(yàn)將本文提出的新推薦模型LCPMF 與經(jīng)典的PMF、協(xié)同深度學(xué)習(xí)(Collaborative Deep Learning,CDL)與ConvMF 等模型進(jìn)行實(shí)驗(yàn)結(jié)果對(duì)比,驗(yàn)證了本文提出模型的可行性和有效性。
1 相關(guān)理論
1.1 基本概率矩陣分解
基于矩陣分解的推薦模型是隱含語(yǔ)義模型的一種方法,屬于基于模型的協(xié)同過(guò)濾算法[16],概率矩陣分解模型是協(xié)同過(guò)濾的算法中最具代表性且廣泛使用的,它的基本思想是通過(guò)分解評(píng)分矩陣再重構(gòu)的方式補(bǔ)全評(píng)分矩陣中的不可觀測(cè)值,具體來(lái)說(shuō),首先構(gòu)建“用戶-項(xiàng)目”矩陣R并將其分解為兩個(gè)低維的矩陣U、矩陣V的乘積方式,然后通過(guò)U和V的內(nèi)積來(lái)重構(gòu)新的評(píng)分矩陣,這樣原始的評(píng)分矩陣R中沒(méi)有評(píng)分的項(xiàng)目也有了相應(yīng)的評(píng)分,將用戶已經(jīng)評(píng)分的項(xiàng)目剔除掉,根據(jù)“重構(gòu)”出的分值對(duì)剩余項(xiàng)目的評(píng)分進(jìn)行排序即可得到最終的項(xiàng)目推薦列表,其目標(biāo)函數(shù)為:
其中:Rij為真實(shí)評(píng)分;UTi Vj為預(yù)測(cè)評(píng)分;λU與λV為正則化參數(shù),用來(lái)防止過(guò)擬合;n與m分別代表n個(gè)用戶與m個(gè)項(xiàng)目;Iij為指示函數(shù),有評(píng)分時(shí)為1,沒(méi)有評(píng)分時(shí)為0。
在推薦系統(tǒng)中,真實(shí)的用戶對(duì)項(xiàng)目的評(píng)分矩陣通常是非常稀疏的,例如Amazon 數(shù)據(jù)集的稀疏度為0.03%,這導(dǎo)致推薦的預(yù)測(cè)評(píng)分準(zhǔn)確率較差。針對(duì)概率矩陣分解模型中數(shù)據(jù)稀疏和準(zhǔn)確性問(wèn)題,引入了輔助信息——項(xiàng)目評(píng)論文檔,優(yōu)化概率矩陣分解模型,從而緩解用戶評(píng)分的稀疏性。
1.2 主題模型
LDA 是一種文檔主題生成模型,也稱為一個(gè)三層貝葉斯概率模型,包含詞、主題和文檔三層結(jié)構(gòu)。所謂生成模型,就是說(shuō),認(rèn)為一篇文章的每個(gè)詞都是通過(guò)“以一定概率選擇了某個(gè)主題,并從這個(gè)主題中以一定概率選擇某個(gè)詞語(yǔ)”這樣一個(gè)過(guò)程得到。文檔到主題服從多項(xiàng)式分布,主題到詞服從多項(xiàng)式分布[17]。因此,由同一主題下某個(gè)詞出現(xiàn)的概率,以及同一文檔下某個(gè)主題出現(xiàn)的概率,兩個(gè)概率的乘積,可以得到某篇文檔出現(xiàn)某個(gè)詞的概率,如圖1所示。
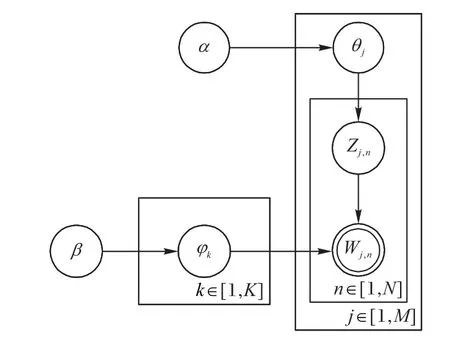
圖1 LDA主題模型結(jié)構(gòu)Fig.1 LDA topic model structure
因此在LDA模型中,一篇文檔生成的方式如下:
1)從狄利克雷分布α中取樣生成文檔j的主題分布θj;
2)從主題的多項(xiàng)式分布θj中取樣生成文檔j第n個(gè)詞的主題Zj,n;
3)從狄利克雷分布β中取樣生成主題Zj,n對(duì)應(yīng)的詞語(yǔ)分布φk;
4)從詞語(yǔ)的多項(xiàng)式分布φk中采樣最終生成詞語(yǔ)Wj,n。
在推薦系統(tǒng)的研究中,有學(xué)者將主題模型用于基于隱因子模型的推薦算法中,但是當(dāng)輔助信息稀疏時(shí),它不能夠獲取有效以及充分的輔助數(shù)據(jù)表示,提升的效果有限。
1.3 卷積神經(jīng)網(wǎng)絡(luò)
卷積神經(jīng)網(wǎng)絡(luò)(CNN)通常應(yīng)用于計(jì)算機(jī)視覺(jué)領(lǐng)域做圖像分類、檢測(cè),以及自然語(yǔ)言處理等任務(wù)[18-19]。近年來(lái),卷積又被引入推薦系統(tǒng),并取得了很好的效果。網(wǎng)絡(luò)結(jié)構(gòu)由嵌入層、卷積層、池化層和輸出層這四個(gè)部分構(gòu)成,可以隱式地從訓(xùn)練數(shù)據(jù)中進(jìn)行學(xué)習(xí)特征,如圖2所示。
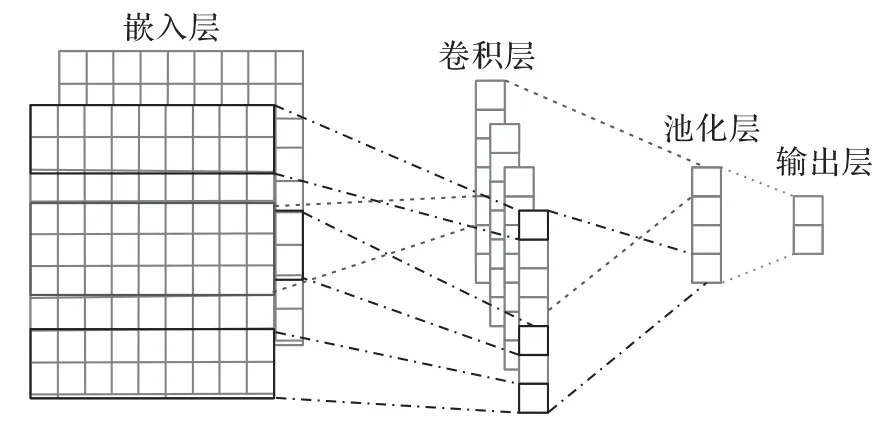
圖2 卷積神經(jīng)網(wǎng)絡(luò)結(jié)構(gòu)Fig.2 Convolutional neural network structure
在之前的推薦系統(tǒng)研究中,也有學(xué)者將卷積神經(jīng)網(wǎng)絡(luò)用于基于隱因子模型的推薦算法中,它可以學(xué)習(xí)用戶或者項(xiàng)目的隱藏特征,如Kim 等[11]使用卷積神經(jīng)網(wǎng)絡(luò)學(xué)習(xí)項(xiàng)目評(píng)論文檔中的隱特征,然后使用學(xué)習(xí)到的特征與PMF 結(jié)合用于推薦,雖然神經(jīng)網(wǎng)絡(luò)學(xué)習(xí)到了項(xiàng)目文檔的深層語(yǔ)義信息,但它同樣忽略了項(xiàng)目文檔的顯著主題特征表示,不能獲取項(xiàng)目文檔的多層描述,導(dǎo)致了項(xiàng)目評(píng)論文檔特征表示提取的不全面。
2 LCPMF算法描述
本章主要從以下三個(gè)方面介紹基于LDA 與CNN 的概率矩陣分解推薦算法(LCPMF)。
1)介紹融合CNN 與LDA 的具體思想過(guò)程(LDA and CNN,LC)模型,并通過(guò)分析項(xiàng)目評(píng)論文檔生成項(xiàng)目文檔的潛在特征表示;
2)介紹融合LDA與CNN的概率圖模型,描述PMF模型和融合模型LC結(jié)合的主要思想,建立被優(yōu)化之后的項(xiàng)目特征條件概率。
3)給出模型優(yōu)化之后的目標(biāo)函數(shù)以及求解過(guò)程。
2.1 融合主題和卷積神經(jīng)網(wǎng)絡(luò)的評(píng)論文本建模
已有的相關(guān)性研究中從項(xiàng)目評(píng)論文檔提取的項(xiàng)目特征表示還存在著單一性和準(zhǔn)確性不高問(wèn)題。綜合考慮評(píng)論主題特征與深層語(yǔ)義信息,本文首先使用word2vec與Glove構(gòu)建詞向量模型,它可以快速地構(gòu)建單詞的詞向量模型[20],把原先的詞嵌入到一個(gè)新的空間,能有效地表征詞的語(yǔ)義信息。建立詞向量模型之后,分別使用LDA 主題模型和文本卷積神經(jīng)網(wǎng)絡(luò)對(duì)項(xiàng)目評(píng)論文檔建模。
2.1.1 評(píng)論文檔LDA建模
LDA 是一種基于概率模型的主題模型算法,用來(lái)識(shí)別文檔中隱含的主題信息。LDA主題模型雖然忽略了特征之間的聯(lián)系,但是可以獲取項(xiàng)目評(píng)論文檔的多個(gè)顯著特征單獨(dú)表示。使用LDA 構(gòu)建項(xiàng)目評(píng)論文檔潛在主題表示,在項(xiàng)目評(píng)論文檔數(shù)據(jù)集中,每一行為一個(gè)項(xiàng)目的所有評(píng)論,每一個(gè)項(xiàng)目的評(píng)論代表了一些主題所構(gòu)成的一個(gè)概率分布,而每一個(gè)主題又代表了很多單詞所構(gòu)成的一個(gè)概率分布,從而將文本信息轉(zhuǎn)化為了易于建模的向量信息。針對(duì)于每個(gè)項(xiàng)目的評(píng)論文檔,從項(xiàng)目評(píng)論的全部主題分布中提取其中一個(gè)項(xiàng)目評(píng)論主題分布,從被抽到的項(xiàng)目主題下的單詞分布中提取一個(gè)單詞,直至遍歷整個(gè)評(píng)論文檔中的每個(gè)單詞,LDA 認(rèn)為每篇文檔是多個(gè)主題混合而成,而每個(gè)主題可以由多個(gè)詞的概率表征,主題模型LDA的核心公式為:
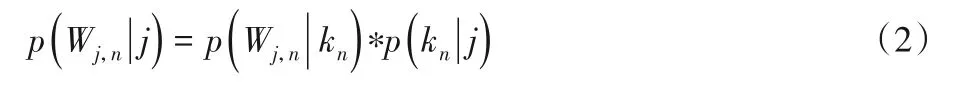
其中:Wj,n表示項(xiàng)目評(píng)論j中的第n單詞;kn表示單詞對(duì)應(yīng)的主題。本文生成項(xiàng)目評(píng)論文檔-主題向量過(guò)程如下:
步驟1 輸入為項(xiàng)目評(píng)論文檔Yj,對(duì)每一篇項(xiàng)目評(píng)論文檔,Yj從項(xiàng)目主題分布中抽取一個(gè)主題。
步驟2 從已經(jīng)被抽到的項(xiàng)目主題所對(duì)應(yīng)的單詞分布中抽取一個(gè)單詞。
步驟3 重復(fù)步驟1~2直至遍歷文檔中的每一個(gè)單詞;最后輸出主題模型、主題詞文檔、詞概率文檔、文檔主題文檔、主題概率文檔。
步驟4 先對(duì)每個(gè)主題下對(duì)應(yīng)的單詞分別進(jìn)行詞向量表示,并與對(duì)應(yīng)的概率進(jìn)行相乘;然后進(jìn)行加權(quán)得到主題詞向量表示。
步驟5 對(duì)每個(gè)文檔下的主題概率與主題詞向量進(jìn)行乘積表示,加權(quán)得到文檔主題向量表示。
步驟6 輸出項(xiàng)目評(píng)論文檔潛在主題表示向量。
2.1.2 評(píng)論文檔CNN建模
卷積神經(jīng)網(wǎng)絡(luò)CNN 模型雖然不能挖掘項(xiàng)目評(píng)論文檔中關(guān)鍵性和代表性信息,但是它可以獲取全局信息以及上下文的之間的聯(lián)系。CNN模型中的多層卷積可以獲取項(xiàng)目評(píng)論文檔中詞語(yǔ)之間的相互關(guān)聯(lián),并學(xué)習(xí)到項(xiàng)目的全局信息以及上下文的之間的聯(lián)系,繼而得到項(xiàng)目的隱表示,具體過(guò)程如下所示:
1)嵌入層。
本文實(shí)驗(yàn)的項(xiàng)目評(píng)論文檔的最大長(zhǎng)度max-length設(shè)置為300,每個(gè)單詞的詞向量維度為200 維,組成詞向量矩陣如式(3)所示。
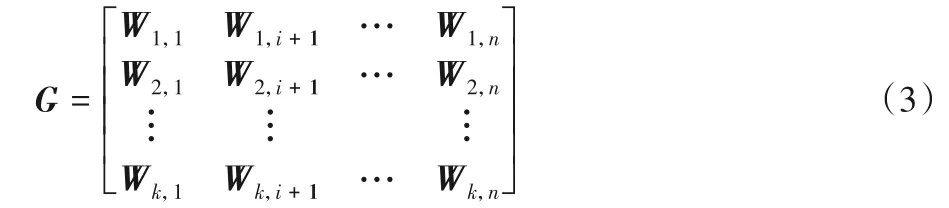
其中:W1,i為詞向量;G表示由詞向量組成的矩陣。
2)卷積層。
在卷積層中,對(duì)詞向量矩陣G提取特征,卷積中使用的滑動(dòng)窗口大小分別為3、4、5,得到不同文本卷積神經(jīng)網(wǎng)絡(luò)的卷積操作可以用式(4)表示:

其中:A表示某個(gè)卷積核上的激活值;wi,j是權(quán)重;relu為本文采用的激活函數(shù);G表示卷積層的輸入詞向量矩陣。
經(jīng)過(guò)以上的卷積操作,卷積層的輸出公式如下:

其中,A為經(jīng)過(guò)不同卷積核形成的項(xiàng)目評(píng)論文檔新特征,作為卷積池化層的輸入。
3)池化層。
池化層采用最大池化,池化的大小為(300-滑動(dòng)窗口+1) ×1,每一個(gè)卷積核對(duì)應(yīng)一個(gè)值,把這些值拼接起來(lái),就得到一個(gè)表征該句子的新特征量。
4)輸出層。
在輸出層中,將新特征量映射成最后的項(xiàng)目隱特征表示。利用卷積神經(jīng)網(wǎng)絡(luò)將原始的項(xiàng)目評(píng)論文檔轉(zhuǎn)換成項(xiàng)目特征向量,輸出項(xiàng)目評(píng)論文檔的深層語(yǔ)義表示矩陣,用式(6)向L維空間進(jìn)行映射:
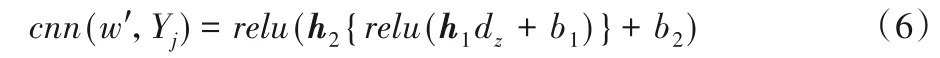
其中:h1、h2為映射矩陣;b1、b2為偏置;dz為池化層的輸出;Yj為卷積神經(jīng)網(wǎng)絡(luò)的輸入;w'為卷積神經(jīng)網(wǎng)絡(luò)的參數(shù),最后卷積神經(jīng)網(wǎng)絡(luò)的輸出維度要與概率矩陣分解PMF 模型中的隱特征向量維度相等。
2.1.3 融合LDA和CNN獲取項(xiàng)目的多層次表示
使用LDA 模型和CNN 模型獲取相同維度的項(xiàng)目潛在低維主題信息及深層語(yǔ)義信息之后,考慮了項(xiàng)目評(píng)論文檔局部的潛在的主題特征,同時(shí)也注意到推薦也會(huì)受到項(xiàng)目評(píng)論的全局的深層語(yǔ)義影響。為了同時(shí)綜合考慮兩者的關(guān)系,使用線性函數(shù)將兩者關(guān)聯(lián)起來(lái),加權(quán)整合主題信息及語(yǔ)義信息得到新的項(xiàng)目評(píng)論文檔特征,如式(7)所示:
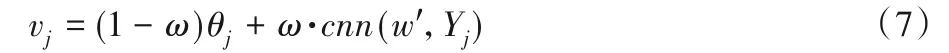
其中:cnn(w',Yj)為經(jīng)過(guò)卷積神經(jīng)網(wǎng)絡(luò)CNN 處理得到的文檔的特征;θj為通過(guò)主題模型LDA 提取的文檔的主題特征;ω為權(quán)重。LDA主題模型可以獲取項(xiàng)目評(píng)論文檔多個(gè)顯著特征單獨(dú)表示,忽略了特征之間的聯(lián)系,而CNN中不能挖掘文檔中關(guān)鍵性和代表性信息,但是可以獲取全局信息以及上下文的之間的聯(lián)系。通過(guò)線性函數(shù)將兩者結(jié)合起來(lái),得到新的項(xiàng)目評(píng)論文檔向量,對(duì)于項(xiàng)目評(píng)論文檔,既考慮了項(xiàng)目評(píng)論文檔的局部信息,又考慮了項(xiàng)目評(píng)論文檔的全局信息,得到項(xiàng)目評(píng)論文檔的多層次表示,解決項(xiàng)目評(píng)論文檔特征提取不全面問(wèn)題。接下來(lái),將兩個(gè)模型融入概率圖模型PMF中。
2.2 融合主題和卷積神經(jīng)網(wǎng)絡(luò)的概率圖模型
針對(duì)傳統(tǒng)的協(xié)同過(guò)濾算法中數(shù)據(jù)稀疏性和推薦結(jié)果不準(zhǔn)確性問(wèn)題,提出了基于LDA 與CNN 的概率矩陣分解推薦模型(LCPMF)。
2.2.1 構(gòu)建模型LCPMF
算法首先使用基于線性關(guān)系的LDA 主題模型與CNN(LC模型)提取項(xiàng)目評(píng)論文檔多層次特征表示Yj;然后將多層次特征應(yīng)用于項(xiàng)目的隱因子V中,其中LDA 主題模型輸出與CNN輸出都與PMF的隱因子個(gè)數(shù)相同;最后,使用用戶的隱因子U和物品的隱因子V重構(gòu)評(píng)分矩陣R,如圖3所示。
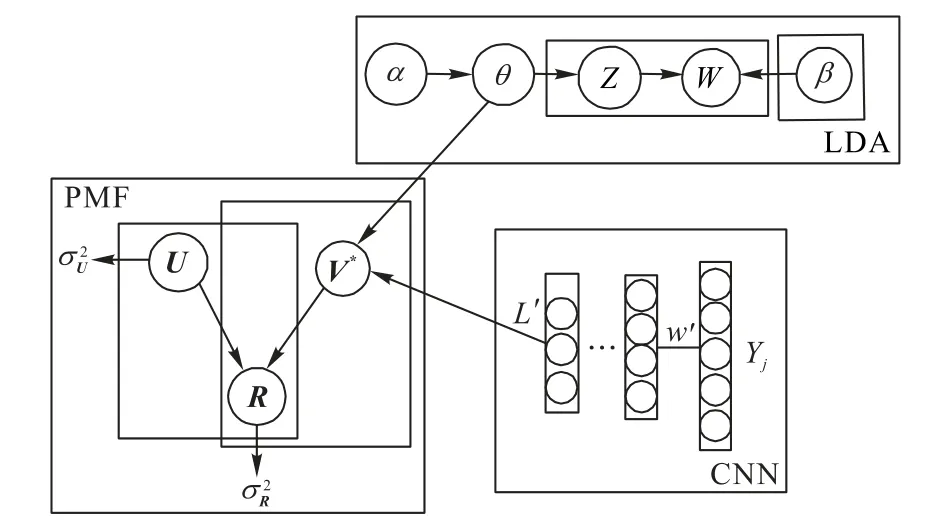
圖3 LCPMF概率圖Fig.3 Probability diagram of LCPMF
圖3中,R為評(píng)分,U、V分別為用戶與項(xiàng)目特征,θj為主題分布,Yj為卷積神經(jīng)網(wǎng)絡(luò)的輸入,w'為權(quán)重,L'為卷積神經(jīng)網(wǎng)絡(luò)的輸出。
對(duì)于傳統(tǒng)的概率矩陣分解模型PMF,用戶對(duì)項(xiàng)目的評(píng)分Rij的條件概率分布為:
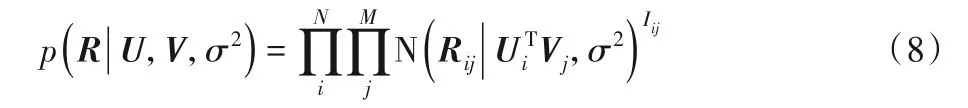
其中:Rij服從均值為μ、方差為σ2的高斯正態(tài)分布的概率密度函數(shù);Iij是指示函數(shù),如果有評(píng)分為1,否則為0。
同時(shí)假設(shè)用戶隱特征均服從μ=0、σ2=σ2U的高斯先驗(yàn)。
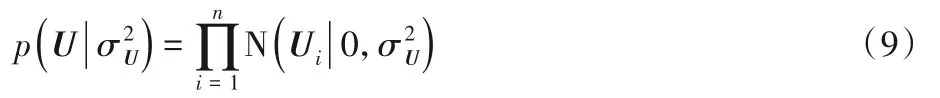
和傳統(tǒng)PMF 算法中不同的是:項(xiàng)目的隱特征向量不再由高斯分布生成,而是由四個(gè)變量構(gòu)成,分別是:項(xiàng)目評(píng)論文檔Yj,卷積神經(jīng)網(wǎng)絡(luò)權(quán)重w',主題分布θj,高斯噪聲ρj。因此,被優(yōu)化之后的項(xiàng)目隱特征的條件概率表達(dá)式為:
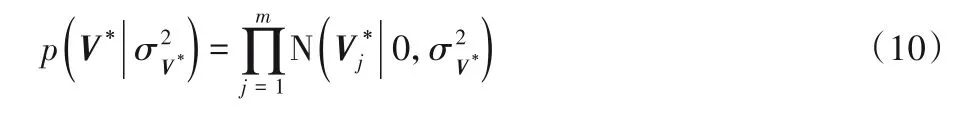
其中V*的構(gòu)成如下所示:
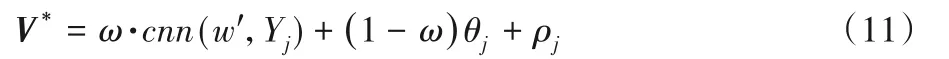
V*表示融合LDA與CNN的項(xiàng)目特征向量,對(duì)于所有項(xiàng)目評(píng)論文檔運(yùn)用LDA生成的主題分布服從θj~Dirichlet(α)。
令卷積神經(jīng)網(wǎng)絡(luò)w'與高斯噪聲ρj也服從高斯分布:

從LC 模型提取的項(xiàng)目評(píng)論文檔的多層次表示特征向量作為項(xiàng)目的隱因子,其中項(xiàng)目的隱因子滿足均值為ω·cnn(w',Yj)+(1-ω)θj,方差為ρj的高斯分布。
2.2.2 模型優(yōu)化
為了優(yōu)化用戶隱因子的提取、項(xiàng)目偏差變量和LC的隱向量,使用最大后驗(yàn)估計(jì),根據(jù)貝葉斯公式可得:
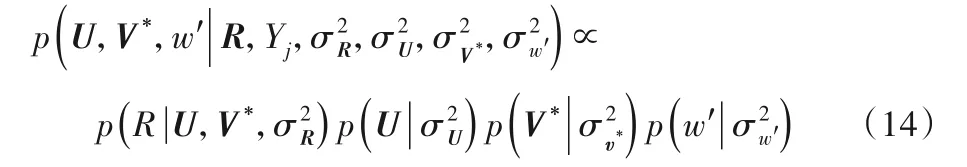
其中:U、V*分別代表用戶和優(yōu)化之后的項(xiàng)目;R代表評(píng)分矩陣;Yj為卷積神經(jīng)網(wǎng)絡(luò)與主題模型的輸入,ω代表衡量卷積神經(jīng)網(wǎng)絡(luò)與主題模型的權(quán)重系數(shù)。
對(duì)式(14)取對(duì)數(shù),可得最終的目標(biāo)函數(shù)如下所示:
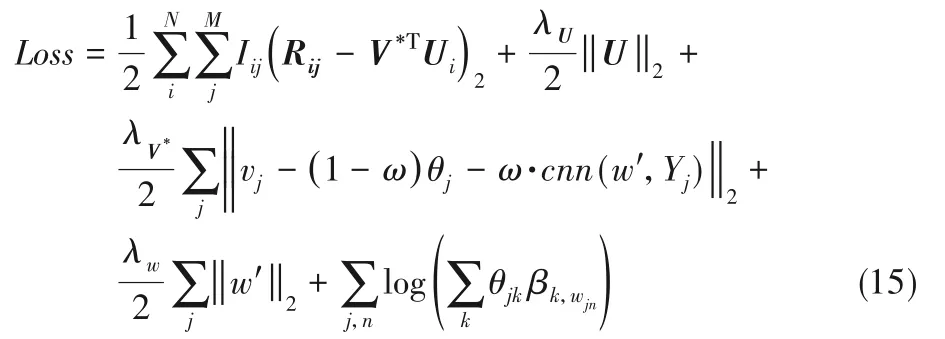
其中:Rij為處理之后的原始矩陣;(ω·cnn(w',Yj)+(1-ω)θj)TU為預(yù)測(cè)評(píng)分;U、V*各代表用戶與項(xiàng)目的特征;w'為卷積神經(jīng)網(wǎng)絡(luò)的權(quán)重;Yj為卷積神經(jīng)網(wǎng)絡(luò)的輸入;wkn代表單詞;K為主題;θjk為第j個(gè)項(xiàng)目的主題分布,且,。
根據(jù)Loss 損失函數(shù)進(jìn)行求解時(shí),采用梯度下降法對(duì)用戶隱向量和項(xiàng)目隱向量進(jìn)行更新。更新表達(dá)式如下:
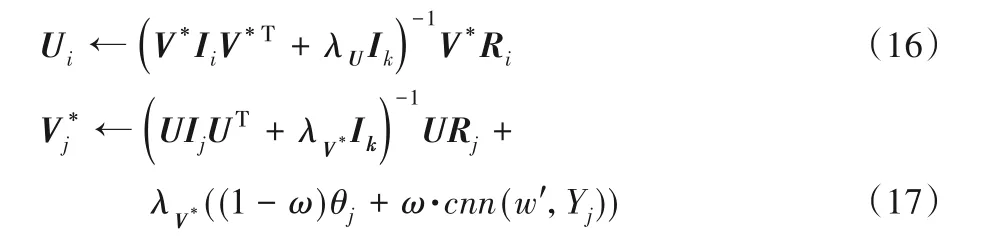
其中:Ik為對(duì)角矩陣;λU與λV*為正則化參數(shù)。式(17)中影響項(xiàng)目的潛在向量為CNN 模型與LDA 模型融合之后的項(xiàng)目評(píng)論文檔特征。在給定U和V*之后,根據(jù)優(yōu)化之后的項(xiàng)目隱特征向量與輸入時(shí)的項(xiàng)目特征隱向量的誤差,采用誤差反向傳播算法更新卷積神經(jīng)網(wǎng)絡(luò)的參數(shù)。
2.2.3 算法總體流程
基于LCPMF的推薦算法流程如下所示。

3 實(shí)驗(yàn)與結(jié)果分析
3.1 實(shí)驗(yàn)環(huán)境
采用 GPU Tesla P100-PCIE-12GB;操作系統(tǒng)為Ubuntukylin-16.04-desktop-amd64;編程環(huán)境使用Pycharm 2018.3.1 x64;開(kāi)發(fā)語(yǔ)言為Python 2.7;深度學(xué)習(xí)框架為Keras 2.2.4;后端使用TensorFlow 1.8.0。
3.2 實(shí)驗(yàn)評(píng)價(jià)標(biāo)準(zhǔn)
為了評(píng)估模型的總體性能,采用均方根誤差(Root Mean Square Error,RMSE)、平均絕對(duì)偏差(Mean Absolute Error,MAE)作為評(píng)價(jià)標(biāo)準(zhǔn)。通過(guò)預(yù)測(cè)值和真實(shí)值之間的差距來(lái)反映推薦模型的好壞,MAE與RMSE值越小,代表著推薦結(jié)果的精度就越高。本文采用上述兩種方式進(jìn)行,具體計(jì)算式如下:
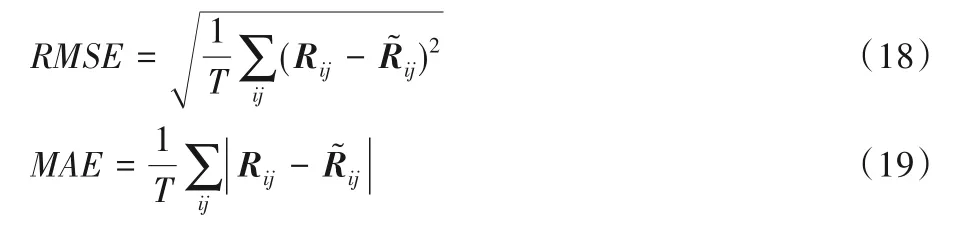
其中:T表示測(cè)試集評(píng)分記錄數(shù);Rij表示用戶i對(duì)項(xiàng)目j的真實(shí)評(píng)分;表示用戶i對(duì)項(xiàng)目j的預(yù)測(cè)評(píng)分值。
3.3 實(shí)驗(yàn)結(jié)果分析
本文中采用的數(shù)據(jù)集為Movielens 1M、Movielens 10M 和Amazon 真實(shí)數(shù)據(jù)集。數(shù)據(jù)集中包括用戶項(xiàng)目的打分。Amazon 數(shù)據(jù)集包含評(píng)論文檔。Movielens 數(shù)據(jù)集中的評(píng)論文檔從IMDB數(shù)據(jù)集中獲取,數(shù)據(jù)集詳細(xì)描述如表1所示。
將實(shí)驗(yàn)數(shù)據(jù)集按照8∶1∶1 的比例分為訓(xùn)練集、驗(yàn)證集與測(cè)試集,分別計(jì)算MAE的值和RMSE的值。
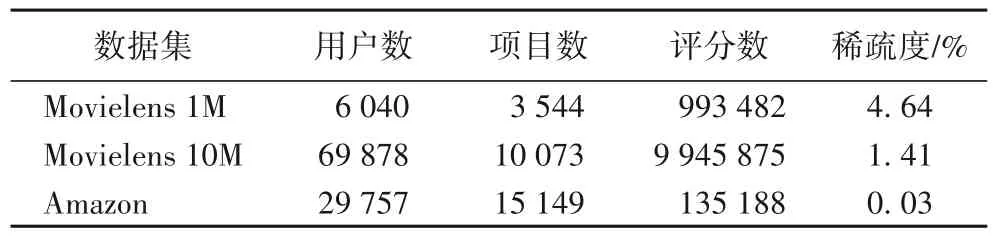
表1 實(shí)驗(yàn)數(shù)據(jù)集詳細(xì)描述Tab.1 Detailed description of experimental datasets
本文主要考慮以下幾個(gè)主要參數(shù)對(duì)算法的影響:
1)卷積與主題模型的權(quán)重ω對(duì)模型的影響。
首先,評(píng)測(cè)卷積與主題模型的權(quán)重ω對(duì)模型的影響,參考ConvMF 和深度學(xué)習(xí)在自然語(yǔ)言處理中的研究,假定K=5,α=0.5,β=0.01,L=50,λU=90,λV*=10。
分析參數(shù)ω對(duì)實(shí)驗(yàn)評(píng)價(jià)標(biāo)準(zhǔn)RMSE 值的影響,實(shí)驗(yàn)結(jié)果如圖4 所示。從圖4中可以得出:在確定主題LDA 模型參數(shù)K=5,α=0.5,β=0.01,隱特征向量維度L=50,正則化參數(shù)λU=90,λV*=10的情況下,RMSE的值將隨著ω的值先下降再升高,當(dāng)ω=0.5時(shí)達(dá)到最小,之后再增加。
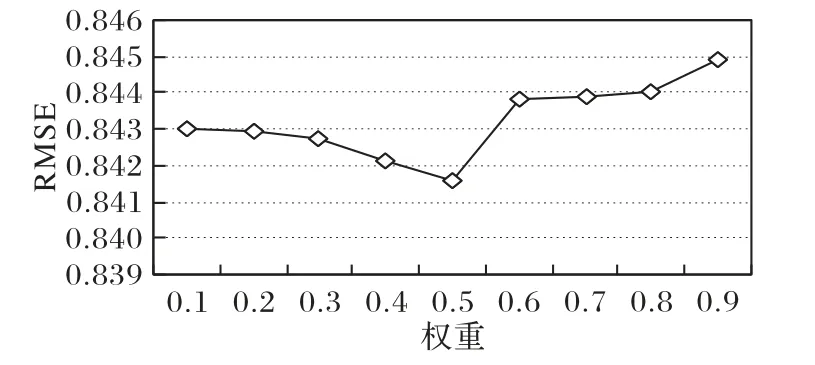
圖4 參數(shù)ω對(duì)RMSE的影響Fig.4 Influence of parameter ω on RMSE
分析參數(shù)ω對(duì)實(shí)驗(yàn)評(píng)價(jià)標(biāo)準(zhǔn)MAE 值的影響,實(shí)驗(yàn)結(jié)果如圖5所示。從圖5中可以得出:MAE的值隨著權(quán)重參數(shù)ω的增加是先下降,之后一直升高,在項(xiàng)目隱向量特征中,LDA 主題特征占據(jù)較小的權(quán)重相較CNN 語(yǔ)義特征占據(jù)較小的權(quán)重時(shí),前者推薦精度較好,但是當(dāng)ω=0.5時(shí),RMSE 與MAE 取最小值。
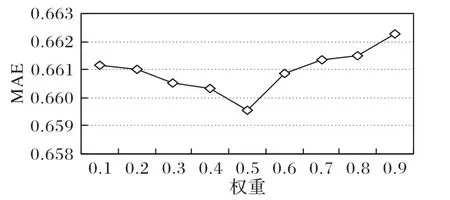
圖5 參數(shù)ω對(duì)MAE的影響Fig.5 Influence of parameter ω on MAE
通過(guò)以上兩組實(shí)驗(yàn),可以看出CNN 與LDA 提取項(xiàng)目評(píng)論文檔的特征表示具有差異性和互補(bǔ)性;而且,利用這一點(diǎn)將它們的特征表示融合之后,獲取項(xiàng)目文檔多層次的表示,提升了推薦系統(tǒng)的準(zhǔn)確性,解決了項(xiàng)目評(píng)論文檔特征提取不全面問(wèn)題。
2)正則化參數(shù)λU與λV*對(duì)模型的影響。
通過(guò)上述實(shí)驗(yàn),在ω=0.5的情況下,RMSE 與MAE 取得最小值。因此,在同樣條件下,采用此參數(shù)調(diào)節(jié)正則化參數(shù)λU與λV*的實(shí)驗(yàn)。從表2中可以看出,當(dāng)λV*=10時(shí),隨著λU的不斷增大,RMSE 和MAE 在不斷減小;當(dāng)λU=90時(shí),RMSE 與MAE 取得極小值。當(dāng)λU=90時(shí),λV*不斷增大時(shí),RMSE 和MAE 反而增高了,說(shuō)明當(dāng)λU=90,λV*=10時(shí),RMSE 與MAE 達(dá)到最小值。
3)LDA主題個(gè)數(shù)K對(duì)模型的影響。
通過(guò)上述實(shí)驗(yàn),在λU=90,λV*=10的情況下,RMSE與MAE取得最小值,因此,在相同條件下,采用此參數(shù)進(jìn)行主題個(gè)數(shù)K的最優(yōu)取值實(shí)驗(yàn),K值采用0、5、10、15、20、25。
分析主題個(gè)數(shù)K對(duì)實(shí)驗(yàn)評(píng)價(jià)標(biāo)準(zhǔn)RMSE 值的影響,實(shí)驗(yàn)結(jié)果如圖6 所示。從圖6中可以看到,當(dāng)K=0時(shí),只利用CNN 提取了項(xiàng)目評(píng)論的全局的深層語(yǔ)義影響,也就是經(jīng)典的ConvMF 模型,但此時(shí)的RMSE 達(dá)到最大值,效果最差。圖中的折線呈現(xiàn)出先下降再上升的趨勢(shì),當(dāng)主題個(gè)數(shù)K=5時(shí),RMSE達(dá)到最小值。
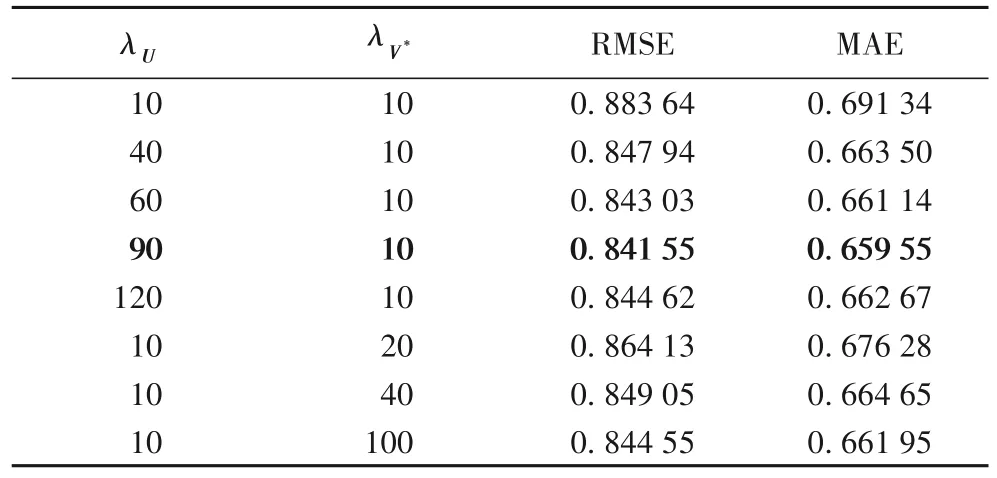
表2 參數(shù)λU與λV*對(duì)RMSE、MAE的影響Tab.2 Influence of parameter λU and λV*on RMSE and MAE
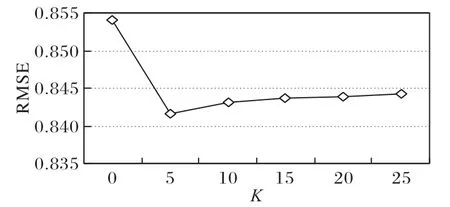
圖6 參數(shù)K對(duì)RMSE的影響Fig.6 Influence of different parameter K on RMSE
分析主題K對(duì)實(shí)驗(yàn)評(píng)價(jià)標(biāo)準(zhǔn)MAE 值的影響,實(shí)驗(yàn)結(jié)果如圖7所示。從圖7中可以得出:MAE的值隨著主題個(gè)數(shù)K的先下降再升高,同時(shí)在K=5時(shí),MAE取最小值。
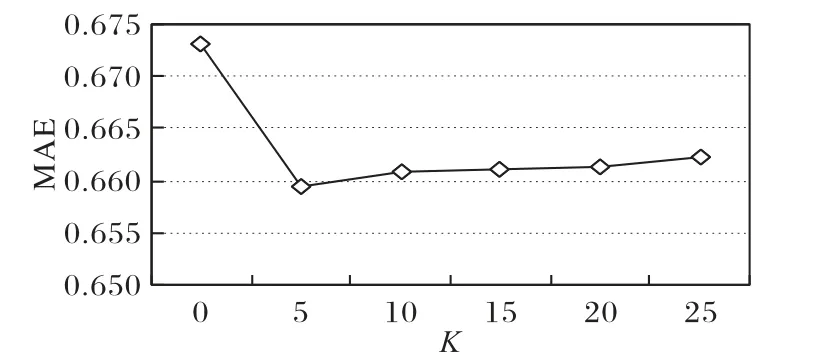
圖7 參數(shù)K對(duì)MAE 的影響Fig.7 Influence of different parameter K on MAE
通過(guò)以上兩組實(shí)驗(yàn),使用線性函數(shù)加權(quán)整合主題信息及語(yǔ)義信息得到新的項(xiàng)目評(píng)論文檔特征,可以明顯地提高推薦的準(zhǔn)確性,證明了綜合考慮LDA 提取的評(píng)論文檔的主題特征和CNN提取的評(píng)論文檔全局特征兩者的關(guān)系是可行的。
4)隱特征維度L對(duì)模型的影響。
通過(guò)上述實(shí)驗(yàn),在主題個(gè)數(shù)K=5 的情況下,RMSE 與MAE取得最小值,因此,在相同條件下,采用此參數(shù)進(jìn)行對(duì)隱特征維度L值的實(shí)驗(yàn),隱特征維度L分別采用25、50、75、100。
分析隱特征維度L對(duì)實(shí)驗(yàn)評(píng)價(jià)標(biāo)準(zhǔn)RMSE 值與MAE 值的影響,實(shí)驗(yàn)結(jié)果如表3 所示。從表3中可以看到:當(dāng)隱特征維度L為25時(shí),雖然花費(fèi)時(shí)間較短,但是RMSE 與MAE 的值較高,準(zhǔn)確度較低;當(dāng)隱特征維度L為75和100時(shí),雖然RMSE和MAE的值與50維度時(shí)相差不大,但是訓(xùn)練時(shí)間效率上遠(yuǎn)超過(guò)50 維。最后,綜合考慮時(shí)間效率和準(zhǔn)確度的因素,將隱特征維度L=50時(shí)作為維度選擇的最優(yōu)值。
5)項(xiàng)目文檔最大長(zhǎng)度max-length對(duì)模型的影響。
通過(guò)上述實(shí)驗(yàn),在隱特征向量維度L=50 的情況下,RMSE 與MAE 取得最小值,因此,在相同條件下,采用此參數(shù)進(jìn)行對(duì)項(xiàng)目文檔最大長(zhǎng)度max-length的實(shí)驗(yàn),項(xiàng)目文檔最大長(zhǎng)度max-length分別采用50、100、200、300、350。
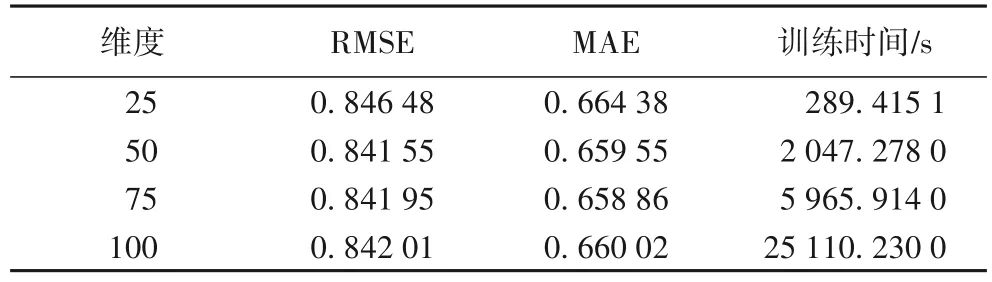
表3 參數(shù)L對(duì)模型性能的影響Tab.3 Influence of parameter L on model performance
分析項(xiàng)目文檔最大長(zhǎng)度max-length對(duì)實(shí)驗(yàn)評(píng)價(jià)標(biāo)準(zhǔn)RMSE值與MAE值的影響,實(shí)驗(yàn)結(jié)果如表4所示。從表4中可以看到:當(dāng)項(xiàng)目文檔最大長(zhǎng)度max-length較小時(shí),RMSE 與MAE 的值較高,準(zhǔn)確度較低;當(dāng)項(xiàng)目文檔最大長(zhǎng)度max-length逐漸增大時(shí),RMSE與MAE的值也逐漸降低,當(dāng)項(xiàng)目文檔最大長(zhǎng)度max-length達(dá)到350時(shí),RMSE 與MAE 的值反而又開(kāi)始增大了。所以,當(dāng)項(xiàng)目文檔長(zhǎng)度max-length=300時(shí),RMSE 與MAE達(dá)到最優(yōu)。
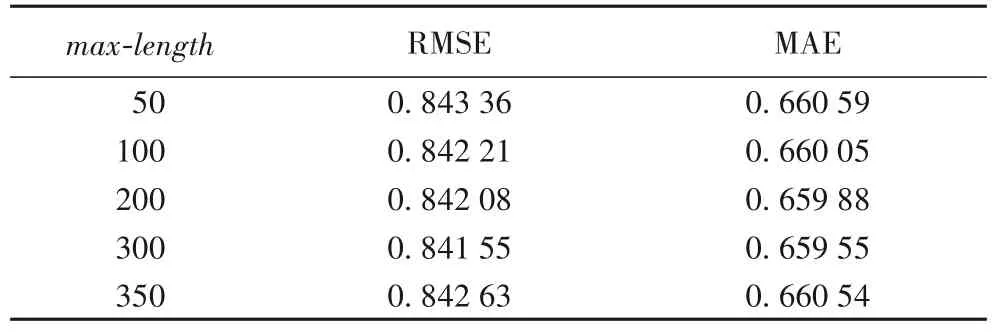
表4 參數(shù)max-length對(duì)RMSE和MAE的影響Tab.4 Influence of parameter max-length on RMSE and MAE
6)LCPMF與其他不同模型在不同算法的對(duì)比。
將本文所提出的LCPMF,與4 種經(jīng)典模型:PMF 模型、使用深度學(xué)習(xí)SDAE 與PMF 結(jié)合的推薦模型(CDL)、使用CNN與PMF 結(jié)合的推薦模型(ConvMF),分別在Movielens 1M、Movielens 10M 和Amazon 三種數(shù)據(jù)集上,進(jìn)行了實(shí)驗(yàn)評(píng)價(jià)標(biāo)準(zhǔn)RMSE值的比對(duì),如表5所示。
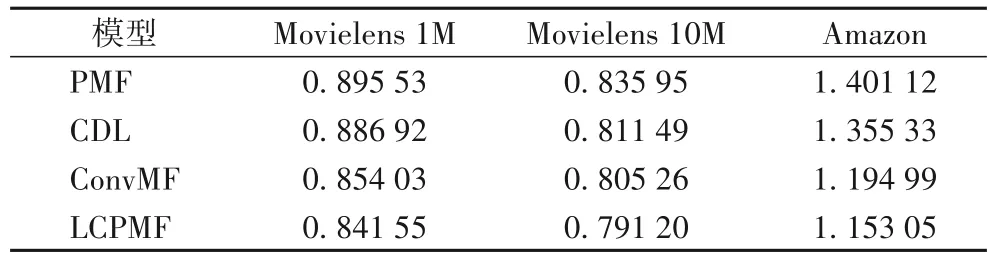
表5 不同算法在不同數(shù)據(jù)集下的RMSE對(duì)比Tab.5 RMSE comparison of different algorithms on different datasets
本文的模型LCPMF 在Movielens 1M、Movielens 10M 和Amazon 三種數(shù)據(jù)集與PMF、CDL、ConvMF 模型的實(shí)驗(yàn)評(píng)價(jià)標(biāo)準(zhǔn)MAE值比對(duì),如表6所示。
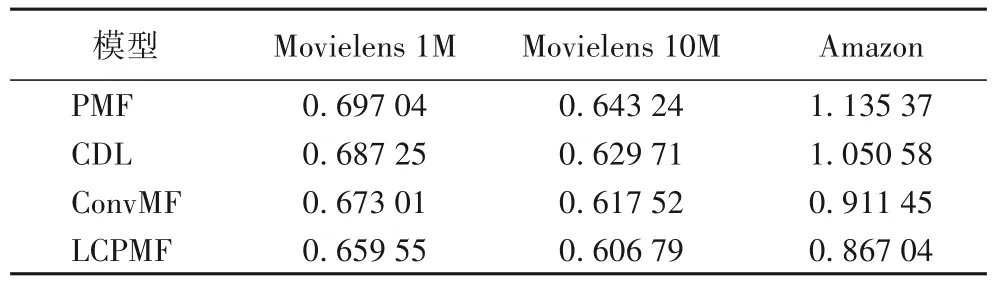
表6 不同算法在不同數(shù)據(jù)集下的MAE對(duì)比Tab.6 MAE comparison of different algorithms on different datasets
從表5 與表6中可以看出,與經(jīng)典的PMF 模型、CDL 模型和ConvMF 模型相比,本文提出的算法在不同數(shù)據(jù)集中無(wú)論是RMSE 還是MAE 都有明顯降低。相較PMF、CDL、ConvMF模型,所提推薦模型LCPMF 的均方根誤差(RMSE)和平均絕對(duì)誤差(MAE)在Movielens 1M 數(shù)據(jù)集上分別降低了6.03%和5.38%、5.12% 和4.03%、1.46% 和2.00%,在Movielens 10M 數(shù)據(jù)集上分別降低了5.35%和5.67%、2.50%和3.64%、1.75%和1.74%,在Amazon 數(shù)據(jù)集上分別降低17.71%和23.63%、14.92%和17.47%、3.51%和4.87%。這表明本文提出的基于LDA 與CNN 的概率矩陣分解推薦模型(LCPMF)是有效的,融合LDA 和CNN 的方法可以更準(zhǔn)確地獲得用戶評(píng)論的特征表示,進(jìn)一步提高推薦算法的準(zhǔn)確性。
4 結(jié)語(yǔ)
本文提出了一種基于LDA 與CNN 的概率矩陣分解推薦模型(LCPMF)。該模型綜合考慮評(píng)論主題與上下文信息,通過(guò)結(jié)合卷積輸出的上下文特征和主題模型LDA 提取的主題特征,并使用權(quán)重系數(shù)決定兩個(gè)特征定義新文檔的影響程度,在一定程度上解決了數(shù)據(jù)稀疏和項(xiàng)目文本隱特征向量提取特征欠缺的問(wèn)題,突出了用戶對(duì)項(xiàng)目的偏愛(ài)程度,提高了推薦的準(zhǔn)確性。在三種公開(kāi)真實(shí)的數(shù)據(jù)集Movlens 1M、Movlens 10M和Amazon 上進(jìn)行實(shí)驗(yàn),使用MAE 和RMSE 指標(biāo)作為評(píng)價(jià)標(biāo)準(zhǔn),將本文模型與經(jīng)典的模型PMF、CDL、ConvMF 進(jìn)行對(duì)比,實(shí)驗(yàn)結(jié)果表明本文提出的模型在推薦質(zhì)量上都有明顯的提高,驗(yàn)證了該模型在推薦系統(tǒng)中的可行性與有效性。由于本文僅僅優(yōu)化了項(xiàng)目隱特征向量的表示性問(wèn)題,并沒(méi)有對(duì)用戶的隱特征向量進(jìn)行優(yōu)化,下一步可針對(duì)該問(wèn)題進(jìn)行研究。
猜你喜歡
童話王國(guó)·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
數(shù)學(xué)小靈通·3-4年級(jí)(2024年2期)2024-05-15 02:02:28
中學(xué)生數(shù)理化·七年級(jí)數(shù)學(xué)人教版(2020年10期)2020-11-26 08:24:50
世界科學(xué)技術(shù)-中醫(yī)藥現(xiàn)代化(2020年2期)2020-07-25 02:05:36
數(shù)學(xué)物理學(xué)報(bào)(2020年2期)2020-06-02 11:29:24
瘋狂英語(yǔ)·新策略(2019年10期)2019-12-13 08:43:28
當(dāng)代陜西(2019年10期)2019-06-03 10:12:04
數(shù)學(xué)小靈通·3-4年級(jí)(2017年9期)2017-10-13 08:10:54
光學(xué)精密工程(2016年6期)2016-11-07 09:07:19
核科學(xué)與工程(2015年4期)2015-09-26 11:59:03
