基于RF?SMOTE?XGboost下的銀行用戶個人信用風險評估模型
2020-08-14 09:59:10張雷王家琪費職友羅帥隋京岐
現代電子技術 2020年16期
關鍵詞:特征提取
張雷 王家琪 費職友 羅帥 隋京岐
摘要: 大數據時代下,用戶信用數據中的高維稀疏特征與樣本不平衡現象日益顯著。為處理高維特征,文中采用隨機森林(RF)從Filter和Wrapper角度進行特征提取,并用SMOTE算法對訓練集樣本做采樣處理。模型訓練階段使用粒子群優化算法對XGboost模型做分類精度提高。最后,采用一開源銀行數據集提供的數據進行實例驗證。結果表明,相較于一般的GBDT模型和網格搜索法,所建立的模型在評估時具有更好的精度與收斂性。
關鍵詞: 信用風險評估; SMOTE算法; 特征提取; 采樣處理; XGboost; 實例驗證
Abstract: In the era of big data, the imbalanced phenomenon between high?dimensional sparse features and samples in user credit data is increasingly obvious. In order to deal with high?dimensional features, RF (random forest) is used in this paper to extract the features by Filter and Wrapper methodes, and SMOTE algorithm is used to perform sampling processing of the training set samples. In the model training stage, particle swarm optimization algorithm is used to improve the classification accuracy of XGboost model. The data provided by Xiamen International Bank is used for example verification. The results show that, in comparison with the common GBDT model and grid search method, the model established in this paper has better accuracy and convergence in evaluation direction.
Keywords: credit risk assessmen; SMOTE algorithm; feature extraction; sampling processing; XGboost; example verification
0? 引? 言
作為現代金融體系的核心,商業銀行在市場經濟、貨幣政策方面有著不可取代的重要作用,尤其是在我國的經濟形勢下,商業銀行的意義更加突出。
《巴塞爾新資本協議》中寫到:“信用風險、市場風險和操作風險是商業銀行面臨的主要風險,其中信用風險是最核心、最復雜的風險。”信貸業務中客戶的違約率上升等對國內商業銀行的利潤造成威脅,而且,大數據時代的到來導致用戶屬性特征數量呈現高維稀疏發展趨勢,樣本數據不平衡且數據量龐大。那么如何處理高維稀疏特征以及樣本不平衡問題進而提高評估信用風險的精度已經引起國內學術界、從業人員及監管部門的廣泛關注。早期,G B Fernandes使用傳統的Logitic回歸作為信用風險評估的主流方法,易操作,但是信用評估準確度不足,難以取得良好的預測結果[1]。之后,肖文兵等人將支持向量機用于信用風險評估并在交叉驗證中尋找到最優核函數,提高分類準確率,但是支持向量機面對小樣本數據擁有良好的處理精度,卻難以處理大數據,無法滿足現在的需求[2]。閆靜提出使用CNN卷積神經網絡處理高維稀疏信用數據,但是現在的大多評估數據以列向量的形式存在,不能滿足卷積神經網絡的數據格式需求[3]。同時ZHU Y等比較了中小型企業信用風險預測的六種方法[4],發現集成學習有著更為理想的準確率,但是機器學習大多基于平衡數據集處理,不平衡數據集對學習器分類存在影響[5?12]。
基于此,本文提出基于集成樹模型下的XGboost算法,優先對高維稀疏特征進行特征重要性排序,排除易導致過擬合的無用特征。通過采樣方法合成少量樣本,平衡數據集,并且通過粒子群算法以XGboost模型的AUC值為目標函數做參數調優。實驗結果表明,相較于一般的GBDT算法,模型的評估精度與穩定性顯著提高。
1? 混合式高維稀疏特征處理
特征工程中有Filter,Wrapper,Embedded也就是過濾式、包裹式、混合式三種方法來進行特征選取。本文正是基于Filter和Wrapper的理念,通過隨機森林模型,根據更換特征對評估精度的影響初步判斷指標的重要性。在模型的初期對特征過濾處理,以此所生成的特征更具有代表性,通過隨機森林(Random Forest,RF)模型經由自主采樣法,有放回地從樣本集中抽取[m]個樣本,抽取[n]次,對這[n]個樣本集建立學習器。隨機森林是在決策樹的基礎上,每次隨機選擇包含[k]個屬性的子集,在其中選取一個最優屬性用于劃分,通過對[k]的控制保證了隨機性,一般選擇[k=log2 d]([d]為總屬性數)。隨機森林面對高維數據時可以更快地給出特征值的重要性,具體算法流程如下:
1) 建立隨機森林模型,根據[n]組袋外數據(Out of Bag,OOB)對隨機森林中的每一個決策樹子模型性能測試,記為[errori (i=1,2,…,n)]。
2) 在保證其余決策樹特征分布不變的情況下,對[n]組袋外數據的第[i]組特征添加噪聲干擾,再次計算每棵樹此時的[Errori (i=1,2,…,n)]。
3) 特征的重要性與前后兩次添加噪聲干擾后的誤差變化平均值呈正相關,因此對第[j]個屬性,其特征重要性公式如下:
4) 基于重要性對特征排序、選擇。
2? 模型優化
2.1? 過采樣平衡樣本
在不平衡數據中,往往稱呼數量多的樣本為負樣本,反之則為正樣本,而機器學習中的分類算法大多基于平衡樣本。為了解決樣本不平衡問題,主要是從數據的不同采樣方法克服,有欠采樣、過采用以及混合采樣,而本文所建立的模型正是基于改進的SMOTE過采樣方法,通過生成少量樣本,解決樣本不平衡問題。SMOTE方法通過產生新的少類合成樣本,并且控制新的生成樣本的數量與分布實現樣本平衡,它可以有效地控制因為樣本不平衡而導致的分類器過擬合問題,比傳統的樣本復制法更貼合數據。
下面對SMOTE方法中用到的參數做簡單的定義:
定義1:令數據集中的少量樣本集合為[xi (i=1,2,…,n)],假設每個樣本集有[m]個屬性,則對于[xi ]的第[j]個屬性即表示為[xij (j=1,2,…,m)],同理,對于負樣本集合,令其為[yi (i=1,2,…,N)],且每個屬性表示為[yij (j=1,2,…,m)]。
定義2:[NE_Pi ]表示為[xi]的同類K?近鄰, [NE_Pi =ne_pikk=1,2,…,K],那么對于其異類K?近鄰樣本集合可以定義為[NE_Ni =ne_nikk=1,2,…,K],同時定義近鄰候選集合為[CANDi=candikk=1,2,…,K],只有當樣本屬于近鄰候選集合時才能參與合成新的樣本,[d(i,k)]表示同類K?近鄰樣本[ne_pik]與[xi]的距離。
至此,SMOTE方法原理可舉例說明,對于樣本[x1],令[x2∈NE_Pi],則對于新的合成樣本[e1],其有[m]個屬性[e11,e12,…,e1m],對于任意的[e1j]有公式:
以此,可以對[m]個屬性值依次合成,從而產生一個新的少類樣本[e1]。重復上述過程,當達到過采樣率后即可停止。
2.2? XGboost算法
XGboost(Extreme Gradient boosting)是一種集成樹模型,其本身的稀疏感知算法對于處理稀疏數據具有先天性的優勢。同時,其目標函數中加入了正則化項,可以有效地避免過擬合。對于分類問題,XGboost不同于隨機森林的委員會原則,而是通過利用殘差多次迭代擬合最終值,對于精度有顯著的提高[13]。
現對XGboost算法的原理進行說明。假設有數據集[D=xi,yi (i=1,2,…,n)],[xi]表示第[i]個樣本的屬性集,[yi ]表示第[i]個樣本所屬類別,那么則會有:
式中:[yl]表示模型的預測值;[yi]表示該樣本的實際值;[K]表示樹的數量;[fk]表示第[k]棵樹模型;[T]表示該棵樹葉子節點的數量;[w]表示在每棵樹葉節點的分數;[λ]表示超參數。XGboost模型的訓練過程如下:
式中,[yl(t)]表示第[t]輪的模型預測值,其保留[t-1]輪的模型預測并且在此基礎上加入了一個新的函數。因此,第[t]輪的目標函數為:
通過泰勒展開式,取其前三項并且移除最小項,可將目標函數轉化為:
2.3? XGboost算法參數優化
數據集本身存在不平衡,因此本文創新性地將模型的AUC值作為優化目標,通過粒子群算法(Particle Swarm Optimization,PSO)尋找到最優值。首先在空間中設計一群僅有速度和位置屬性的粒子,速度代表粒子移動的快慢,位置表示為三維向量(學習率rate、樹深度depth、最小葉節點權重weight),代表XGboost模型的三個超參數。每個粒子都會在空間中單獨地搜尋最優解,并將其標記為個體極值,對整個粒子群做極值比較,找到最優值作為整個粒子群當前的全局最優解,粒子群中的其余粒子根據擁有最優值的粒子的位置和速度對自己進行調整,迭代公式如下:
式中:[xi]表示該粒子當前的位置,且有[xi=xi1,xi2,xi3];[vi]表示第i個粒子的速度;[c1],[c2]表示學習因子,一般設置為2;[Pbesti]表示局部最優值點;[Gbesti]表示全局最優解;[ω]是慣性權重,用于平衡全局搜索能力和局部搜索能力。粒子通過上述的公式對自己的位置和速度實現迭代,逐步向最優點逼近。
2.4? XGboost模型實現流程
本文所建立的RF?SMOTE?XGboost個人信用風險評估模型具體流程可以分為四部分:數據預處理、SMOTE補充數據集、參數優化、模型測試與評估,具體步驟如下:
1) 獲取數據,對數據做過歸一化處理,對原始數據集中的缺失數據做處理,考慮到異常值在個人信用數據中存在且客觀合理,故不對異常值處理。同時考慮到高維稀疏特征的特點,先排除個人化易導致過擬合的特征,然后選擇使用RF對特征值重要性進行排序,選取重要性較高的特征,得到數據集[S′]。
2) 對于原始數據集中,按8∶1∶1比例作為訓練集、驗證集、測試集,對訓練集和驗證集正負樣本的比例做初步了解,并且運用SMOTE對少量樣本進行合成,生成新集合[S′]。
3)對于[S′],將其劃分為訓練集[S′train]與驗證集[S′test],多次抽取小樣本,分別為[S′train1],[S′train2],…,[S′trainm]。
4) 隨機產生N組解,每組解是一個三維的向量,其包含XGboost的三個超參數,即學習率([rate])、樹的最大深度([max_depth]),以及最小葉子節點樣本權重([min_child_weight]),以XGboost模型的AUC值作為適應度函數[f]。
5) 通過PSO迭代,尋找到最小誤差的適應度函數,并且記錄下此時的最優參數向量([rate],[max_depth],[min_child_weight])。
6) 將訓練好的XGboost模型代入剩余的25%數據做檢驗,評判此時的AUC值,并且與GBDT的預測精度做對比。
3? 實證分析
3.1? 實驗數據
為了驗證本文所建立的RF?SMOTE?XGboost模型在個人信用風險評估方面的精確度與穩定性,本文實驗數據采用了一開源銀行數據集所提供的個人數據信用基本數據,包括用戶個人基本信息以及還款情況。基本情況見表1。
為了提高模型評估精度,避免過擬合,排除id,certId,dist等多項無用特征,對certValidBegin,certValidStop兩項相減并且做歸一化處理,將數據集按8∶1∶1的比例分為訓練集、驗證集和檢驗集。對訓練集、驗證集做SMOTE過采樣處理,依托訓練集及訓練模型,并且從驗證集上隨機抽取1 000例,計算模型的AUC值,以此為目標函數,訓練參數。
3.2? 特征選擇
本文所選擇的數據集存在高維系數特征,故先刪去冗余且極易導致模型過擬合的數據后,通過RF即隨機森林模型對模型的特征重要性做評估,如圖1所示。根據特征重要性,選擇排名在前20的屬性,如圖2所示。
3.3? 模型優化與結果分析
在模型訓練過程中,模型參數的選擇對于模型評估時的精確度有著決定性作用。使用粒子群算法對三個超參數的調節——學習率[rate]、最大深度[max_depth]以及最小葉節點樣本權重[min_child_weight],達到模型優化的功能目的,提高XGboost模型的預測精度。由數據集原本的正負樣本比例可得,正負樣本比例失衡,而機器學習算法的分類器大多基于平衡數據集。因此,本文先對數據集做SMOTE過采樣平衡,見圖3。由圖3可得,樣本比例由0.73%變為50%,并開始模型的訓練。
處理好樣本平衡后,經由PSO對XGboost模型進行參數調優,一共迭代了1 214次,最終在[rate] =0.05,[max_depth] =4,[min_child_weight] =6處模型的準確率達到最大值,相較于一般的網格搜索法迭代2 300次以上且易陷入局部最優,粒子群算法展現出了更好的全局搜索能力與處理速度,如圖4所示。
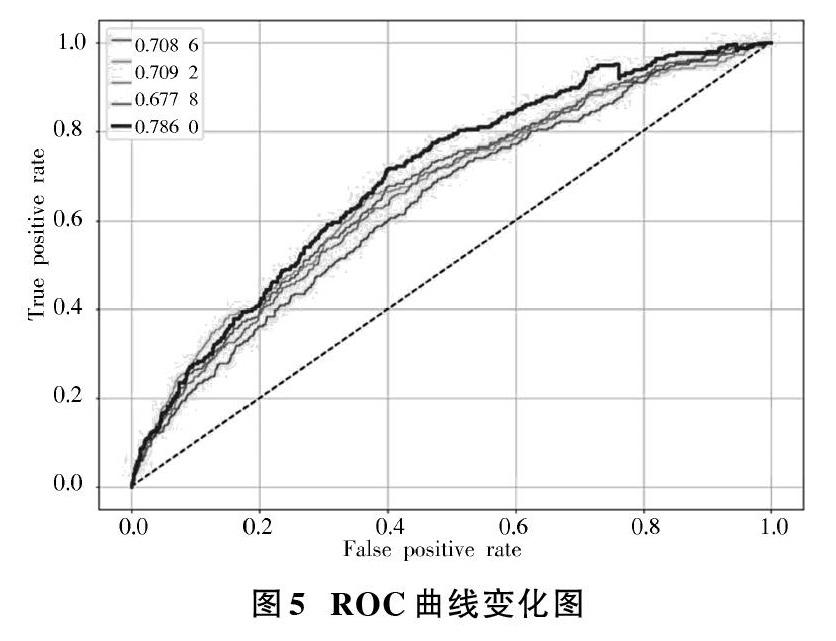
圖5為兩種模型的ROC曲線變化圖,在ROC空間中,ROC曲線越靠近坐標軸的左上方表示模型分類的效果越精準。ROC曲線與[x]軸的面積稱為AUC值,AUC值介于[0,1]之間。AUC值越大,代表模型的性能越高。由圖5可得,GBDT模型經過參數調優訓練后的AUC值為0.701 9,而XGboost的訓練圖為0.786 0,提高了12%,與未經過PSO訓練XGboost模型的0.677 8相比提高了16%。
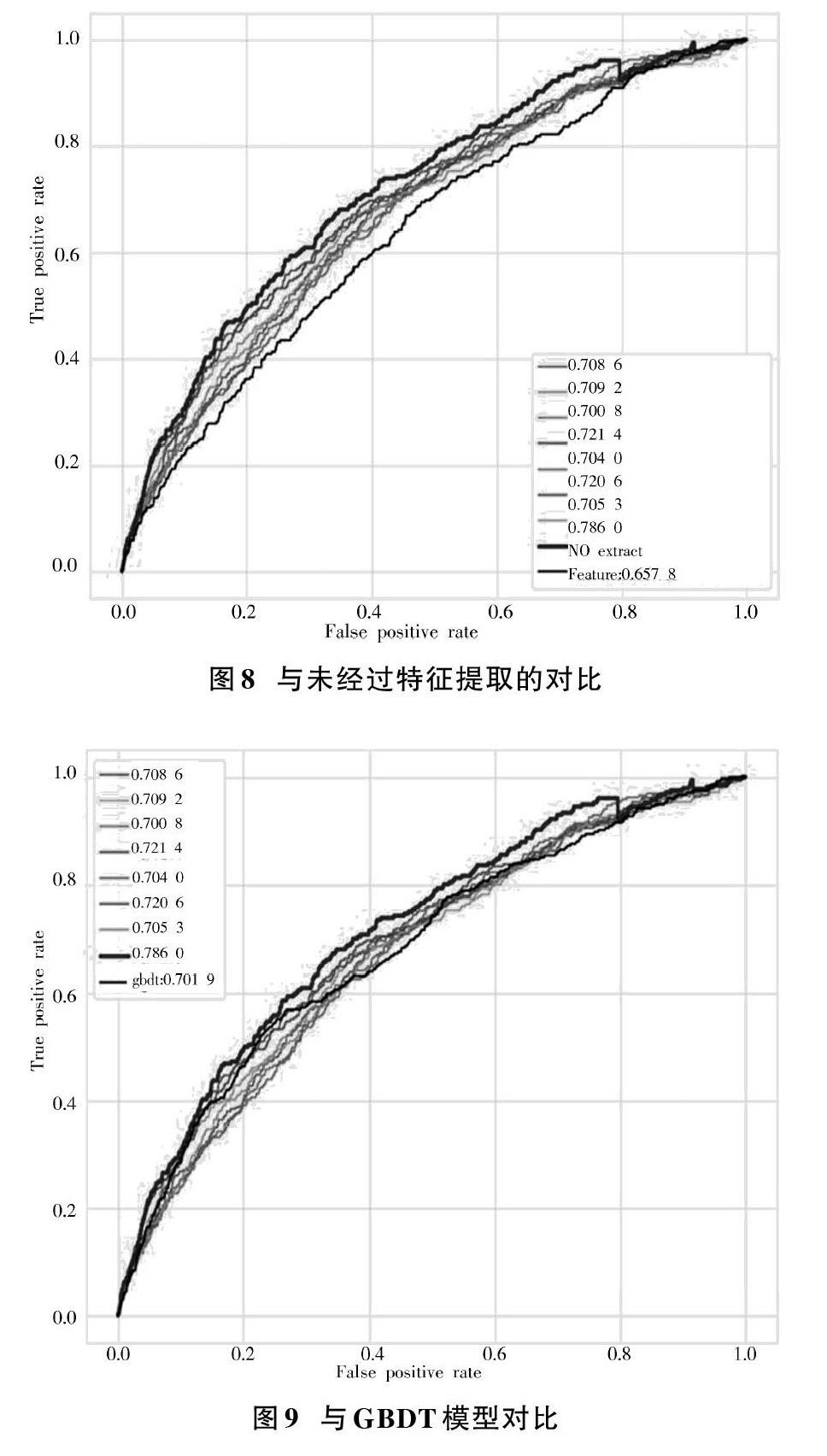
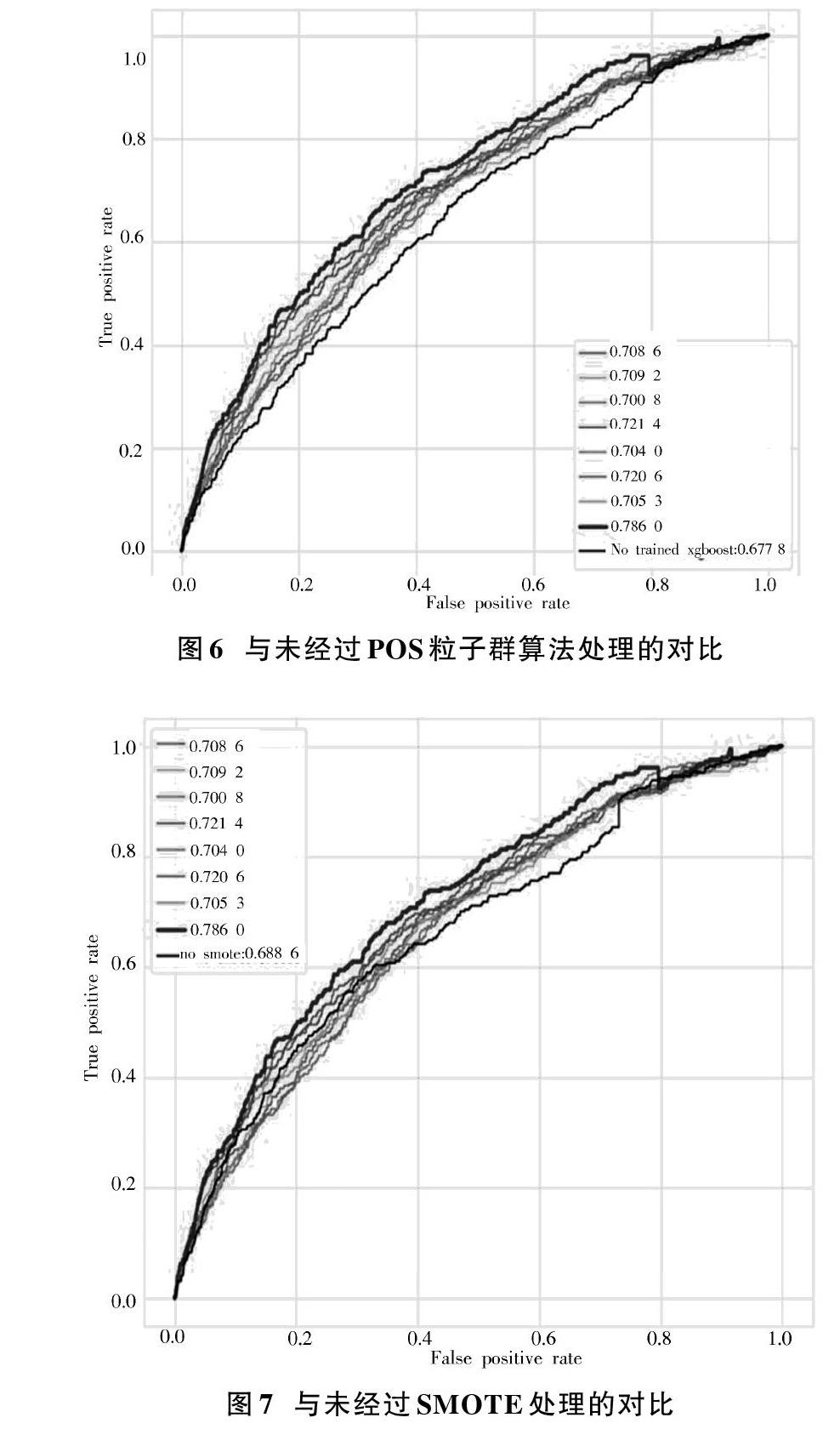
為了驗證本文所建立的RF?SMOTE?XGboost模型的性能,本文分別以未經過PSO粒子群算法做參數調優下的XGboost模型的性能、未經過SMOTE處理的XGboost模型的性能、未經過特征提取的模型性能以及同種情況下的GBDT模型的性能做對比,見圖6~圖9。
為了驗證模型所做的過采樣處理以及特征提取對于模型性能提高的價值,同上所述,分別做其ROC曲線圖,未經過SMOTE處理的AUC值為0.688 6,經過對比發現,本文所建立模型的0.786 0,同比提高14%。未經過特征提取下的模型AUC值為0.657 8,經過對比發現,本文所建立模型同比提高19%。
4? 結? 語
本文提出一種基于RF?SMOTE?XGboost下的銀行用戶個人信用風險評估方法。通過隨機森林在大規模數據分類問題上的精度和魯棒性評判出來的特征重要性更準確;并且通過SMOTE處理數據分布問題上的正負樣本比例的過大差距;同時創新性地以模型的AUC值作為粒子群算法優化的目標函數,以此應對不平衡樣本。實驗結果表明,相較于未作樣本平衡處理、未作特征提取、未經由參數尋優以及同等情況下的GBDT模型,本文所建立的模型具有更好的評估效果,而且與網格搜索法相比,函數收斂時間更短,全局最優搜索能力更強,是一種有效的銀行用戶個人信用風險評估模型。
參考文獻
[1] FERNANDES G B, ARTES R. Spatial dependence in credit risk and its improvement in redit scoring [J]. European journal of operational research, 2016(2): 517?524.
[2] 肖文兵,費奇.基于支持向量機的個人信用評估模型及最優參數選擇研究[J].系統工程理論與實踐,2006(10):73?79.
[3] 王重仁,韓冬梅.基于卷積神經網絡的互聯網金融信用風險預測研究[J].微型機與應用,2017,36(24):44?46.
[4] ZHU Y, XIE C, WANG G J, et al. Comparison of individual, ensemble and integrated ensemble machine learning methods to predict Chinas SME credit risk in supply chain finance [J]. Neural computing & applications, 2017, 28(1): 41?50.
[5] 白鵬飛,安琪,NICOLAAS Fransde,等.基于多模型融合的互聯網信貸個人信用評估方法[J].華南師范大學學報(自然科學版),2017,49(6):119?123.
[6] 于彤,李海東.基于BP神經網絡的客戶信用風險評價[J].現代電子技術,2014,37(10):8?11.
[7] 劉定祥,喬少杰,張永清,等.不平衡分類的數據采樣方法綜述[J].重慶理工大學學報(自然科學),2019,33(7):102?112.
[8] 莫贊,張燦鳳,魏偉,等.基于Bagging集成的個人信用風險評估方法研究[J].系統工程,2019,37(1):143?151.
[9] 吳金旺,顧洲一.基于非平衡樣本的商業銀行客戶信用風險評估:以A銀行為例[J].金融理論與實踐,2018(7):51?57.
[10] 高超,許翰林.基于支持向量機的不均衡文本分類方法[J].現代電子技術,2018,41(15):183?186.
[11] SIRUNYAN A M, TUMAYAN A, ADAM W, et al. An embedding technique to determine ττ backgrounds in proton?proton collision data [J]. Journal of instrumentation, 2019, 14(6): 6032?6038.
[12] YANG Xiong, WU Shusen, L? Shulin, et al. Modification of LPSO structure in Mg?Ni?YAlloy with strontium [J]. Materials science forum, 2019, 941: 869?874.
[13] 王名豪,梁雪春.基于CPSO?XGboost的個人信用評估[J].計算機工程與設計,2019,40(7):1891?1895.
[14] 李眾,王海瑞,朱建府,等.基于蜻蜓算法優化支持向量機的滾動軸承故障診斷[J].化工自動化及儀表,2019(11):910?916.
[15] 林子,黃薏辰,張揚,等.基于支持向量機相關性分析的波浪能發電電力負荷預測[J].南昌大學學報(理科版),2019(5):504?510.
猜你喜歡
艦船科學技術(2022年15期)2022-09-14 09:21:50
電子制作(2019年15期)2019-08-27 01:12:00
電子制作(2018年19期)2018-11-14 02:37:08
自動化學報(2017年7期)2017-04-18 13:41:09
自動化學報(2017年11期)2017-04-04 02:52:58
中國生物醫學工程學報(2017年6期)2017-02-10 05:11:45
廣西科技大學學報(2016年1期)2016-06-22 13:10:38
計算機工程(2015年4期)2015-07-05 08:28:02
機電信息(2015年3期)2015-02-27 15:54:46
機械工程師(2015年10期)2015-02-02 01:13:49
