
基于Hadoop的工業大數據存儲分析系統
2020-08-16 13:53:29范旭輝
科技創新與應用 2020年23期
范旭輝


摘? 要:工業大數據具有規模龐大、業務復雜等的特點,為數據存儲、查詢和分析計算帶了難度。為了優化工業大數據存儲管理,提高系統存儲、查詢、分析效率,利用基于Hadoop技術針對業務庫和實時監控數據庫的存儲管理進行優化。系統設計業務庫的集群化同步存儲架構,基于Maxwell組件將MySQL業務庫數據實時同步到HBase,實現業務庫的讀寫分離、提高數據查詢和數據分析的效率;其次,基于Kafka和Flink對業務庫同步數據進行實時計算處理,實現高并發數據寫入場景下的低延遲響應;最后,實驗進行了HBase和MySQL的性能對比測試,結果表明本系統在大規模數據場景下具有更好的計算效率表現,能夠有效進行工業大數據分析存儲。
關鍵詞:工業大數據;Hadoop;Flink;HBase
中圖分類號:TP311.13? ? ? 文獻標志碼:A? ? ? ? ?文章編號:2095-2945(2020)23-0018-04
Abstract: Industrial big data has the characteristics such as large scale and complex business, which makes it difficult for data storage, query, analysis and calculation. In order to optimize the storage management of industrial big data and improve the efficiency of system storage, query and analysis, the storage management of business database and real-time monitoring database is optimized based on Hadoop technology. The system designs the clustered synchronous storage architecture of the business library. Based on the Maxwell component, the MySQL business library data is synchronized to HBase in real time to achieve the read-write separation of the business library, improve the efficiency of data query and data analysis. Based on Kafka and Flink, real-time calculation and processing of synchronous data in the business database are carried out to realize low latency response in the scenario of high concurrent data writing. Finally, the experiment conducted a performance comparison test of HBase and MySQL, which shows that the system has better calculation efficiency performance in large-scale data scenarios, and can effectively analyze and store industrial big data.
Keywords: industrial big data; Hadoop; Flink; HBase
引言
工業數據的存儲分析是工業信息化應用、推進智能制造的前提和基礎[1],然而工業數據的海量性、增量性為其的存儲管理帶來了難度,同時也對數據存儲的可拓展性、高效性提出了高要求[2]。目前,大多工業信息系統[3-4]通過結構化數據庫如MySQL等進行數據存儲。面對頻繁讀寫的應用服務,有研究[4]通過備份同步業務庫,實現讀寫分離的架構,從而減輕數據庫壓力。然而,這種存儲管理方式對于復雜業務表的數據分析方面并不友好,需要通過垂直切分或者水平切分進行數據查詢。
大數據存儲系統HBase是一種分布式的列式數據庫,針對復雜業務的分析具有天然的優勢,被廣泛地應用在數據存儲和分析過程中[5-8]。然而,HBase的存儲應用很難直接切入到現有系統中,或是需要將整套技術方案推翻重來。同時,不同于普通應用系統,工業數據因其特殊的應用場景會產生大量的實時監控數據[2],如設備、儀表、定位等。這些實時增量不斷增長的時序數據為數據存儲的效率提出了要求。此外,在數萬臺機器毫秒級監控的場景中,服務器每秒需要處理GB級的數據,傳統通過負載均衡進行實時計算的處理方式已經達到瓶頸。
為此,本文提出了一種工業大數據存儲管理與分析系統,基于Hadoop平臺構建數據存儲平臺,通過Maxwell實時讀取MySQL的數據日志寫入Kafka消息隊列,并通過Flink消費處理同步到HBase,在不影響當前系統業務庫的同時提高數據查詢和存儲管理效率。
1 相關工作
1.1 Hadoop平臺簡介
從狹義上來說,Hadoop[5-8]是一個由Apache基金會所維護的分布式系統基礎架構,而從廣義上來說,Hadoop通常指的是它所構建的Hadoop生態,包括Hadoop核心技術以及基于Hadoop平臺所部署的大數據開源組件和產品。這些組件實現大數據場景下的數據存儲、分布式計算、數據分析、實時計算、數據傳輸等。
Hadoop的核心技術:HDFS、MapReduce、HBase被譽為Hadoop的三駕馬車,更為企業生產應用帶來了高可靠、高容錯和高效率等特性。其中,HBase是一個可伸縮、分布式、面向列的數據庫,和傳統關系數據庫不同,HBase提供了對大規模數據的隨機、實時讀寫訪問,同時,HBase中保存的數據可以使用MapReduce來處理,它將數據存儲和并行計算完美地結合在一起。
1.2 Flink引擎簡介
Flink[9]是一個基于內存計算的分布式計算框架,通過基于流式計算模型對有界和無界數據提供批處理和流處理計算。在實時計算方面,相比于開源方案Storm和Spark Streaming,Flink能夠提供準實時的數據計算,并能夠將批處理和流處理統一,實現“批流一體”的整體化方案。這種架構使得Flink在執行計算時具有較低的延遲,Flink被譽為繼Hadoop、Spark之后的第三代分布式計算引擎。
1.3 Maxwell簡介
Maxwell是一個能實時讀取MySQL二進制日志binlog、并生成json格式的消息,作為生產者發送給Kafka、RabbitMQ、Redis、文件或其它平臺的應用程序。目前,常用的binlog解析工具還有canal、MySQL_streamer,canal由Java開發,性能穩定,但需要自己編寫客戶端來消費canal解析到的數據;MySQL_streamer由Python開發,但其技術文檔比較粗略,對開發過程并不友好。
2 系統總體設計
系統架構設計:為了實現大規模工業數據的高效存儲,設計基于Hadoop的工業大數據存儲管理系統總體架構,共包括前端集群、后端業務集群和數據計算集群,具體存儲系統架構如圖2所示。
系統主要采用前端界面和后端業務分離的思想,在前端集群中,由Nginx負責請求的反向代理和負載均衡,分別指向靜態文件服務器或Web服務器,實現網頁相關界面的顯示與交互。前端集群通過遠程調用的方式與后端業務集群進行通信,實現相關業務操作、MySQL數據庫交互操作、數據計算與結果緩存到Redis等操作。對于后端業務操作中的數據計算環節則由數據計算集群負責,如:實時同步業務庫、設備數據實時計算等。
在數據計算集群中部署了Hadoop平臺(HDFS、HBase、Yarn)以及Flink、Kafka、Zookeeper等組件。其中HDFS負責進行底層數據的存儲,具體由HDFS的DataNode進行文件分片多備份存放,由NameNode進行元數據管理和文件操作管理,同時通過Zookeeper注冊兩個NameNode并實時監控狀態,防止一方故障立即切換到另一個,從而保證NameNode的高可用性。HBase負責對同步業務庫和時序數據庫進行存儲,由HMaster管理多個RegionServer進行數據維護和查詢,底層由HDFS進行存儲。對于實時計算部分通過Kafka Broker接受Kafka生產者生產的實時消息,再通過Kafka消費者Flink進行處理計算,其中Kafka的生產、消費進度由Zookeeper進行記錄。Flink不僅提供實時計算,同時提供離線批量計算,其計算過程通過Yarn申請計算資源,具體由ResourceManager管理資源并分配到NodeManager上進行計算。
3 工業大數據存儲管理系統
3.1 基于Maxwell的業務庫同步設計
為了緩解基礎業務庫的讀寫壓力,提高復雜業務表的查詢分析效率,系統利用Maxwell實時監聽MySQL的binlog日志,然后解析成json格式發到消息隊列Kafka,再通過Flink消費Kafka數據存儲到HBase,從而供其他后端分析業務進行讀取、查詢。基于Maxwell的業務庫同步設計具體過程如圖3所示。
其具體實現步驟如下:
(1)編輯MySQL配置文件my.cnf,開啟binlog功能;
(2)創建Maxwell用戶并賦權限;
(3)啟動Kafka集群;
(4)修改Maxwell的config.properties文件,配置MySQL數據庫連接信息、配置producer類型為Kafka、配置Kafka集群連接信息和topic、配置同步業務庫信息;
(5)啟動Maxwell,開始監聽;
(6)創建Flink消費Kafka任務,對Maxwell產生的數據進行實時處理寫入HBase。
3.2 基于Kafka和Flink的實時計算
對于實時同步的MySQL業務庫binlog數據,Maxwell首先進行解析傳入Kafka消息隊列,然后通過Flink對這些實時產生的業務庫同步數據進行消費,實現寫入HBase中。具體步驟包括:
(1)在Kafka中創建消息訂閱主題“maxwell”,定義副本數2個,分區數9個。Maxwell作為生產者對MySQL的binlog文件進行解析成json格式數據,再發送到“maxwell”這個主題下。
(2)服務器端配置連接信息,包括:Flink流式處理環境、Zookeeper的集群信息、Kafka集群信息、消費者組信息、數據格式等。
(3)通過Kafka Flink Connector API創建線程池對接Kafka,將Maxwell的同步數據實時寫入HBase。通過Flink的DataStream算子的map過程處理每一條消息,分別調用HBase API執行數據寫入操作。
4 系統實現
4.1 集群環境部署
系統在1個主節點、6個計算節點上搭建Hadoop集群,同時部署MySQL主備節點、Kafka、Flink、Maxwell等組件。各節點配置包括:CentOS 7.3 64位操作系統、Intel(R) Xeon CPU 2.4GHz 4Core的CPU、24GB內存、1TB硬盤,Hadoop版本為Hadoop 2.6.0,Flink版本為Flink 1.9.0,MySQL版本為MySQL 5.6。
4.2 性能測試
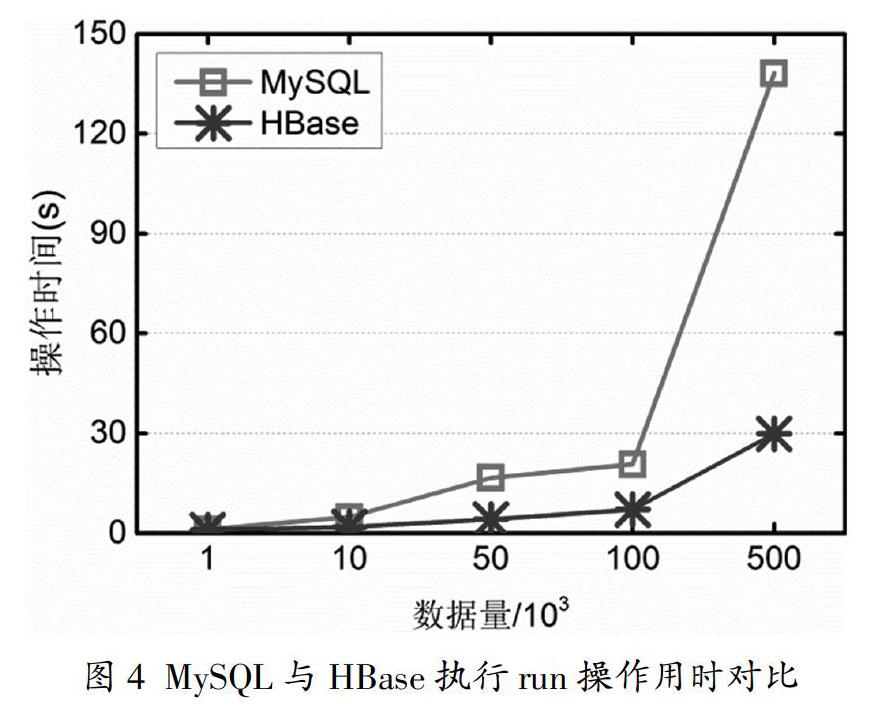
系統采用HBase存儲業務同步庫面向數據查詢和分析,因此,在性能測試方面針對HBase的數據查詢性能進行實驗。如圖4所示為不同數據量情況下執行run操作時MySQL和HBase的耗時對比。
在數據量比較少的情況下,MySQL與HBase所用時間相當,但隨著數據量的增長,HBase和MySQL的處理時間產生越來越大的差距,且HBase具有更低的處理延遲。
如圖5所示為向HBase與MySQL中插入數據時總吞吐量的對比。當數據量較小,MySQL吞吐量較HBase更大;當數據量較大,HBase的吞吐量相比MySQL更優,且隨著插入數據量規模的增大,MySQL的吞吐量逐漸變小并趨于平緩達到瓶頸,而HBase在數據規模增大的同時具有更大的數據吞吐量。因此,在處理大規模數據插入場景中,HBase相較MySQL更具優勢。
5 結束語
本文基于Hadoop技術實現對工業大規模數據進行存儲管理,對業務庫和實時監控數據庫的存儲管理進行優化。設計業務庫的集群化同步存儲架構,對存儲在MySQL中的業務數據進行實時同步到Kafka;基于Flink對業務庫同步數據進行實時計算處理,實現高并發數據寫入場景下的低延遲響應;最后,實驗進行了HBase和MySQL的性能對比測試,結果表明本系統在大規模數據場景下具有更好的計算效率表現,能夠有效進行工業大數據分析存儲。
參考文獻:
[1]劉祎,王瑋.工業大數據時代技術示能性研究綜述與未來展望[J].科技進步與對策,2019,36(20):154-160.
[2]何文韜,邵誠.工業大數據分析技術的發展及其面臨的挑戰[J].信息與控制,2018,47(04):398-410.
[3]黃新波,張瑜,朱波.智能變電設備監控與決策輔助系統數據庫的設計與實現[J].高壓電器,2016,52(03):15-22.
[4]王瀚哲,楊超宇,梁胤程.煤礦作業規程管理系統設計及關鍵技術研究[J].中國煤炭,2014,40(12):71-74+95.
[5]張華偉,陳勇,李海斌,等.基于HBase的工業大數據時序數據存儲實現[J].電信科學,2017,33(S1):21-27.
[6]孟祥曦,張凌,郭皓明,等.一種面向工業互聯網的云存儲方法[J].北京航空航天大學學報,2019,45(01):130-140.
[7]趙亞楠,李朝奎,肖克炎,等.基于Hadoop的地質礦產大數據分布式存儲方法[J].地質通報,2019,38(Z1):462-470.
[8]鄭柏恒,孟文,易東,等.在Hadoop集群下的智能電網數據云倉庫設計[J].制造業自動化,2014,36(19):134-138.
[9]代明竹,高嵩峰.基于Hadoop、Spark及Flink大規模數據分析的性能評價[J].中國電子科學研究院學報,2018,13(02):149-155.
