開源社區中Issue解決過程的參與者推薦方法
2020-09-02 06:52:22劉曄暉趙海燕陳慶奎
小型微型計算機系統 2020年9期
劉曄暉,趙海燕,曹 健,陳慶奎
1(上海理工大學 光電信息與計算機工程學院 上海市現代光學系統重點實驗室光學儀器與系統教育部工程研究中心,上海 200093)2(上海交通大學 計算機科學與技術系,上海 200030)
E-mail:1092778656@qq.com
1 概 述
互聯網已經從內容發布發展到了用戶創建內容的時代[1],出現了許多社交媒體包括博客、網絡論壇、社交、照片和視頻共享社區等.與此同時,出現了許多互助社區,如StackOverflow平臺,在這樣的社區上,用戶之間可以互相幫助[2].在這些潮流的推動下,基于互聯網進行開源軟件開發得到了蓬勃發展,開源項目平臺如Github上集聚了大量的開源項目.
問題追蹤器已成為現代軟件開發項目中必不可少的協作工具[3],它們可以用于注冊和跟蹤新功能請求、開發任務和錯誤等.在開源項目如Github中,每個人都可以在項目的問題跟蹤器上打開一個新問題,而問題解決過程的參與者可能直接來自于項目的核心團隊成員或者是對該項目感興趣的外部貢獻者.等待相應的人員來解決問題的過程并不總是迅速的,這將導致問題處理不夠及時甚至長久得不到解決,因此出現了一系列研究[4-8]旨在推薦能夠解決該問題的專家.一般來說,這些方法將過去類似問題的回答者作為推薦對象,因此,其推薦的質量依賴于所選擇的衡量問題相似性或者相關性的屬性.這種依據過去的直觀經驗進行推薦的方法在新問題上是無法奏效的.
將創建的問題分配給合適的解決者將使開源項目的開發進程加快,因此我們設計了參與者推薦系統,以便在Github中預測適當的參與者.我們的方法利用熵值法對開發者畫像中的特征進行個性化權重計算,結合問題的文本語義和開發者的社交關系進行推薦.
我們的工作貢獻如下:首先分析了影響開發者參與問題積極性的影響因素,根據這些影響因素構建開發者畫像,提出一種混合評論者推薦方法,該方法同時結合基于社交網絡和信息檢索的方法.我們在Github上的五個流行項目驗證了18215個問題.結果表明,我們的混合方法優于其他單獨的方法.
2 相關工作
Github上,開源軟件的開發過程由5個步驟組成的工作流[9]組成:
1)討論問題:討論項目的一個新功能,商定需要做什么,主要是許多開發人員就一個新的功能或需要修改的功能進行溝通,并最終確定要增加或修改什么樣的功能;
2)指定事務:為討論出的功能創建一個分支;
3)執行事務:在指定事務工作流中創建的分支上建立一個功能分支以使其工作;
4)審查事務:功能完成后推送到遠程端,通過pull request進行代碼審查;
5)問題解決后迭代:在審查中發現問題,進行問題討論,直到問題被解決.代碼合并到主分支.可以看出,問題討論和解決在其中具有重要作用.
最近針對開源軟件中的問題解決過程,很多學者進行了研究.HomwitZ等人證實朋友比陌生人更愿意也更有效地解答問題[10].Morris等人的研究發現,在小規模的研討中,很多參與者的問題都是被關系緊密的朋友解決的,而且友誼的緊密程度是對回答問題的一種激勵因子,每種親密程度的人群都會樂意回答問題[11,12].Tian等人提出了一種基于多種屬性推薦評論者的方法,將用戶的活躍度與文本相似度等元素考慮進去,發現用戶活躍度是評論者推薦最重要的屬性[13].de Lima Júnior 等人用不同的分類算法對請求合并的屬性進行評估,發現請求的時間間隔、文本的相似度以及社交關系對推薦評論者的影響更大[14].Rath等人發現,基于代碼的信息檢索對開發人員有積極影響[15].Ponzanelli等人考慮了開發人員已經咨詢或研究的內容,通過相似度計算為信息檢索提供上下文支持[16].Adaji等人將社交網絡用語Stack Overflow中,從而幫助社交網絡開發人員建立有說服力的問答社區,并改善現有的社交平臺[17].
我們先利用開源社區問題解決過程人員參與積極性的影響因素對開發者構建畫像,利用熵值法計算不同開發者對問題特征的的個性化權重,然后結合信息檢索和社交網絡對問題進行建模.問題的標題以及描述信息能夠直接體現提問者的疑問和主題,所以我們把訓練集中的問題當做歷史文本信息,測試集中的問題的標題和描述作為查詢,構建推薦系統.
3 問題解決參與者推薦算法
3.1 基于信息檢索的問題解決參與者推薦
基于信息檢索的方法是當前一種流行的bug分配算法,旨在匹配開發人員的技術焦點.首先我們根據標題和描述信息生成每個問題的核心內容.通過刪除在此過程之前預定義的停用詞,我們獲得了每個問題的核心關鍵字,并形成一個語料庫.其次,我們根據TF-IDF算法(公式(1))生成每個問題的問題向量.
(1)
其中,t代表一個特定的關鍵字,freq(t,issue)表示在Issue文檔中issue出現關鍵字t的次數,Tissue′表示issue中的所有關鍵字.
當測試集中出現一個問題時,我們使用余弦相似度計算每個問題之間的關系(公式(2)).每個問題的向量由整個語料庫中的關鍵字形成.
(2)
根據公式(1)和公式(2)我們總結了開發人員之前參與過的問題與目標問題之間的關系(公式(3)).
relation(d,issue)=∑issue′∈Issuedsimilarity(issue,issue′)
(3)
其中d代表開發者,Issued表示開發人員之前參與過的問題集.
因此,當目標問題出現時,計算每個開發者和目標問題之間的關系,然后按降序對結果進行排名,并推薦top-N個結果.
3.2 基于評論網絡的問題解決參與者推薦
我們認為同一個項目中開發人員具有相同的興趣,因此我們在研究的項目中建立了一個評論網絡.在給定項目中,評論關系的結構是多對多模型,一個問題可以被多個開發人員評論.
我們將評論網絡定義為一個帶權重的有向圖Gcn=〈V,E,W〉,其中定點V表示開發者集合,節點之間的關系集合用邊E表示,如果節點vj至少評論了vi提出的一個問題,那么從vi到vj就會有一條邊eij.權重集合W反映了邊的重要程度,邊eij的權重wij可以通過公式(4)來評估.
(4)
其中,k是由vi提交的問題的總數,并且w(ij,q)是與某個問題q相關的權重.Qc是一個經驗值(設置為1.0),用于評估每個評論對問題的影響,并且m是由vj在相同的問題中提交的評論的總和.當評論者vj在同一問題中發表多個評論(m≠1)時,他的影響因子又衰減因子λ(設定為0.8)控制.元素t(ij,q,n)是對應評論的時間敏感因子,計算如下:
(5)
其中timestamp(ij,q,n)是評論者vj在問題q中評論的日期,starttime和endtime分別表示一個問題提出的時間和最終被關閉的時間.

圖1 評論網絡示例Fig.1 An example of the comment network
圖1顯示了關于jasmine項目中評論網絡中的一部分示例.v1提交的兩個不同的問題(issue1和issue2)被v2和v3評論過,因此從v1到v2和v1到v3有兩條邊.issue1的starttime為2019-03-11T01:06:18Z,endtime為2019-03-12T01:24:46Z;issue2的starttime為2018-07-07T20:52:04Z,endtime為2019-01-23T01:48:24Z.評估v1和v2之間的關系時,因為v2只評論了issue2,所以公式(4)中的k值為1,w12≈0.742.評估v1和v3之間的關系時,因為v3兩個問題都評論過,所以公式(4)中的k值為2.對于issue1,w(13,2)≈0.988.對于issue2,v3評論過4次,因此m設置為4.第一個時間2018-07-20T00:54:24Z的時間敏感因子可以通過公式4計算得出t(13,2,1)≈0.061,因為一個用戶在相同的問題中的影響越來越小,所以其他的時間敏感因子由λ(=0.8)控制,則w(13,2)可以計算為:Qc×(t(13,2,1)+λ2-1×t(13,2,2)+λ3-1×t(13,2,3))+λ4-1×t(13,2,4)≈1.012.類似的,權重w13=w(13,1)+w(13,2)=2.0.因此,根據相應邊的權重的量化,我們可以預測,與v2相比,開發人員v3與問題提問者v1共享更多的興趣.
我們提出的評論網絡具有如下優點:
·引入時間敏感因子t以保證最近的評論對于邊的權重比舊的評論更有價值
·引入衰減因子λ以保證評論多個問題和值對單個問題評論多次之間的差異值.例如,如果開發人員vj評論了vi提交的5個問題,同時vk評論了vi提出的某一個問題5次,則wij的權重大于wik.
3.3 基于開發者畫像的問題回答者推薦
根據之前研究,開發人員會有偏好的參與一些問題的解決.問題的文本長度(textLen)、是否含有代碼(code)、問題提問者是否是項目貢獻者(role)都會對問題解決的參與積極性有影響.因此在構建開發者畫像前,需要先建立問題特征向量,開發者參與過的多個問題特征向量組成開發者畫像.
熵值法可以用于判斷一個事件的隨機性和無序程度,常被研究人員用來評估事件的關聯性.Lee等人采用熵值法對用戶評分物品的相似性進行度量[18,19].Deldjoo等人使用熵值法去判斷用戶對特征屬性的敏感程度,從而計算推薦系統的公平性[20].Yi等人對用戶瀏覽過的網頁文本提取特征詞,通過熵值法計算相應的權重,提出了基于信息熵的二次聚類推薦算法[21].所以在衡量開發者對問題某一特征的偏好程度時,我們采用熵值法計算不同開發者對問題特征的偏好程度,從而避免人為分配的主觀性帶來的偏差,同時可以根據不同開發者對特征的偏好權重更好的實現個性化推薦.其基本原理是:熵是對信息不確定性的一種度量,熵值越小,所蘊含的信息越大.所以當每個特征屬性的熵值越小,則開發者對該屬性的偏好越強,就應賦予較大的權重.
假定有n個樣本m個屬性,xij表示第i個樣本的第j個屬性的數值(i=1,2,…,n;j=1,2,…,m),熵值法的基本步驟如下:
(i)屬性的歸一化處理:異質指標同質化,由于各項指標的計量單位并不統一,因此在用它們計算綜合指標前,先要對它們進行標準化處理,并令xij=|xij|.由于我們實驗所用屬性都為正向指標,所以其計算方法如公式(6)所示.
(6)
則x′ij為第i個樣本的第j個屬性的數值(i=1,2,…,n;j=1,2,…,m).
(ii)計算第j個屬性下第i個樣本占該指標的比重:
(7)
(iii)計算第j個s屬性的熵值:
(8)
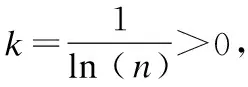
(iv)計算信息熵冗余度(差異):
dj=1-ej,j=1,…,m
(9)
(vi)計算各項指標的權重:
(10)
根據公式(6)-公式(10)可以計算得到某一開發者對問題特征的偏好權重,將目標問題向量化得到的問題向量與開發者的偏好權重向量做點積,即可得到該開發者參與目標問題的得分,記為scoreentropy.
由于上述三種方法都側重于問題的不同部分,為了獲得更好的推薦結果,我們綜合以上三種推薦算法進行混合推薦.首先通過scoreentropy給出排名前M個開發者作為候選集,候選集中每個開發者在信息檢索和評論網絡中的貢獻結果根據(公式(11))計算得出.通過累加每種方法的不同結果得到開發者的最終得分,按降序對結果進行排序后,取Top-N作為推薦結果.開發者的得分計算如公式(12)所示.
(11)
scorehybrid(d,issue)=scoreIR(d,issue)+scoreCN(d,issue)
(12)
4 數據及實驗
4.1 問題及評論的數據
我們在Github上選擇了5個流行倉庫(jasmine,realm-cocoa,elixir,metabase和istio),作為我們的研究的基礎.我們獲得了這些倉庫所有的issue信息,包括issue的描述、標題、代碼段以及所有參與該問題的開發者信息等.通過爬蟲我們從項目中獲得了5個項目共18215條issue以及78583條評論,數據集見表1.

表1 jasmine,istio,realm-cocoa,elixir和matabase數據集Table 1 Dataset in jasmine,istio,realm-cocoa,elixir and metabase
4.2 評測指標
為了驗證我們算法的性能,我們采用召回率作為評價指標,計算方式如公式(13)所示.
(13)
其中,Issues表示問題的測試集,R(i)表示根據開發者在訓練集上的行為做出的Top-N推薦列表,T(i)表示實際問題中的用戶列表.
4.3 推薦結果
根據我們的統計,75%的問題最多有兩個人參與討論,假設我們將推薦列表長度約束在10人以內,將覆蓋90%以上的問題,所以我們比較了三種方法在推薦Top-2,Top-4,Top-6,Top-8和Top-10個開發人員時哪種推薦性能更好,結果如表2所示.
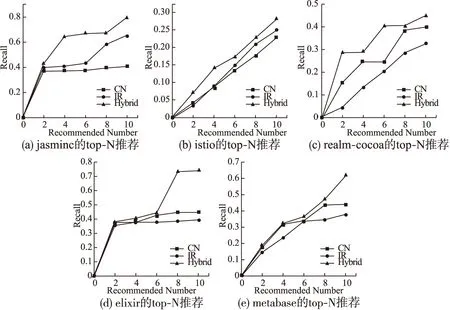
圖2 不同算法下參與者推薦Recall比較Fig.2 Recall comparison of differrnt method about Q&A recommendation
為了更直觀的看出推薦性能的不同,我們將表2轉化成圖2的形式.從圖2(a)可以看出,當推薦2、5、10個評論者時,jasmine基于開發者畫像的混合推薦召回率與其他兩種方法相比是最好的,性能從42.63%到79.49%,類似的結果可以從圖2(b)、圖2(c)、圖2(d)和圖2(e)得出,也就是說混合方法可以彌補其他兩種方法的不足并達到最佳效果.
5 總結和展望
本文旨在深入分析已有問題的參與者推薦方法,并提出一種有效的改進算法.我們詳細描述了用到的模型,并在Github上選擇熱門的項目進行了對比實驗.結果表明,基于開發者畫像的混合推薦可以有效的推薦參與者.同時我們的推薦模型加強了個性化推薦效果,這意味著對于不同的問題,我們的模型可以推薦不同類型的開發人員來解決問題.由于之前我們分析了開源社區解決過程人員參與積極性的影響因素,所以選取的特征促使推薦性能更好.
本文的模型中考慮了問題的某些特征對參與者積極性的影響,但是一些其他特征可能也影響參與者的積極性,例如問題的類別對開發者參與積極性也有影響,每個類別之間存在的差異都會體現技術相關的過程,推薦對該類問題更具有專業知識的開發人員更有助于問題的解決.對于未來的工作,我們計劃基于機器學習分類器為開源項目開發一個細粒度的問答者推薦模型.
