基于卷積神經網絡的群眾留言分類
2020-09-03 02:25:54代耀彬朱燕燕黃雙華
無線互聯科技 2020年12期
代耀彬,朱燕燕,黃雙華
(河海大學,江蘇 南京 210098)
網絡問政平臺是互聯網時代下政府為群眾提供服務的主要平臺,也是政府與群眾信息交流的主要方式。目前,大部分電子政務系統仍是依靠人工進行數據整理,不斷攀升的文本數據量對相關部門的工作帶來了極大的挑戰,如何快速對群眾的留言進行分類成為當前的熱點問題。深度學習在圖像分類上有著較好的分類效果,不少學者開始研究深度學習算法在短文本分類上的應用[1]。本文擬通過使用卷積神經網絡,實現對于群眾留言信息的快速分類。
1 模型架構與診斷結果
本文所設計的基于卷積神經網絡群眾留言分類模型主要包括3個方面:數據的預處理、建立模型、結果診斷,整個模型架構流程如圖1所示。

圖1 模型架構流程
1.1 數據預處理
本文實驗所用到的數據集來自相關政務網站上的群眾留言,數據集主要包括群眾的留言信息和工作人員對留言進行的分類。留言主要分為勞動與社會保障、環境保護、商貿旅游、城鄉建設、衛生計生、教育文體、交通運輸7大類。
首先,采用簡易數據增強(Easy Data Augmentation,EDA)技術[2]對文本進行數據增強,減少類別分布不均衡的影響。得到了82 872條留言數據。其次,對增強后的數據集進行分詞與停用詞處理。最后,通過TF-IDF算法提取留言文本的關鍵詞,形成關鍵詞庫。TF和IDF的計算公式如(1—2):
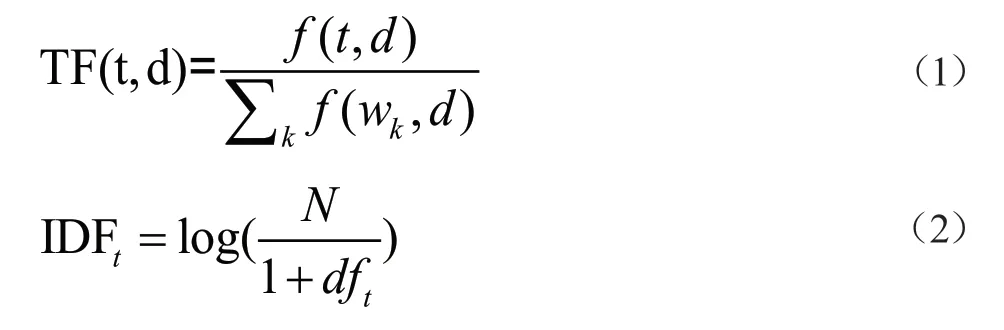
其中,f(t,d)表示詞條t在文檔中出現d出現的次數,dft表示語料庫中包含詞條t的文檔數量,N表示語料庫中全部的文檔數量。
通過token詞典將關鍵詞列表轉換為數字列表。對文本中單詞出現的次數做統計并排序,從而將每一條留言的文本分詞列表替換成數字列表,截長補短,使得所有記錄的關鍵詞序列的長度為50。針對82 872條留言記錄,最終得到一個82 872×50的數組,為模型做數據準備。最后,利用分層抽樣的方法,抽取70%數據作為訓練集,30%作為測試集。
1.2 模型建立
卷積神經網絡是一種帶有卷積結構的深度神經網絡,卷積結構大大減少了深層網絡占用的內存量,全值共享有效減少了網絡的參數個數,緩解了過擬合問題。本文使用基于Tensorflow的keras深度學習框架,搭建了兩層卷積神經網絡,提高了神經網絡的準確率。卷積層和池化層是卷積神經網絡特征提取的核心模塊,采用自適應矩估計算法(Adaptive moment estimation,Adam)對網絡中的權重參數逐層反向調節[3],使得損失函數值最小,通過不斷迭代訓練提高神經網絡的精度。模型的流程如圖2所示。
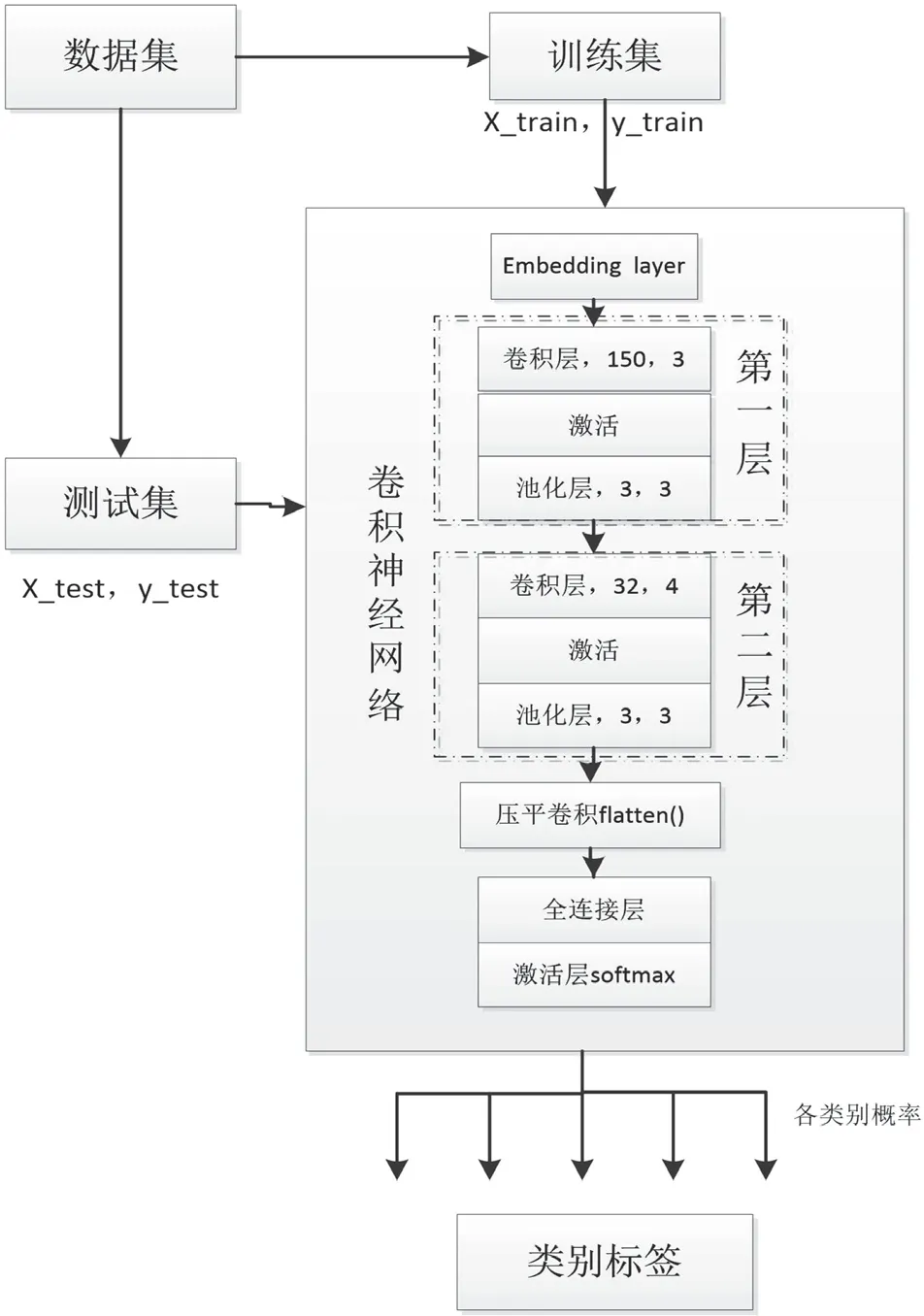
圖2 模型建立流程
(1)embedding層。直接初始化embeddings,基于語料通過訓練模型網絡來對embeddings進行更新和學習,從而將輸入的數字列表轉換為詞向量。
(2)卷積層。經過embedding層之后,每一條留言記錄(留言詳情)由高質量特征線性表示,將其輸入卷積層,對輸入數據進行特征提取。實驗過程中,第一層的卷積核大小為3,第二層卷積核的大小為4。采取relu函數作為激勵函數不斷迭代。
(3)池化層。進行降維操作,降低文本的向量維度,也是一層特征選取和信息過濾,由池化大小、步長和填充控制來確定池化區域,實驗過程中,針對兩層池化層,取池化大小pol_size=3,步長stride=3,填充控制padding=same。
(4)全連接層。神經網絡的最后一層,采用全連接層的方式,第二層K_max池化層處理后的文本特征向量經過矩陣的concat和reshape之后變成一維數組,送入Softmax分類器,計算類別概率,預測輸出分類標簽。
2 評測標準及實驗結果分析
本文采用F-score方法對模型進行評價,根據分類結果建立混淆矩陣(見表1)。針對該模型,計算出各分類的精確率、召回率、F1值如表2所示。
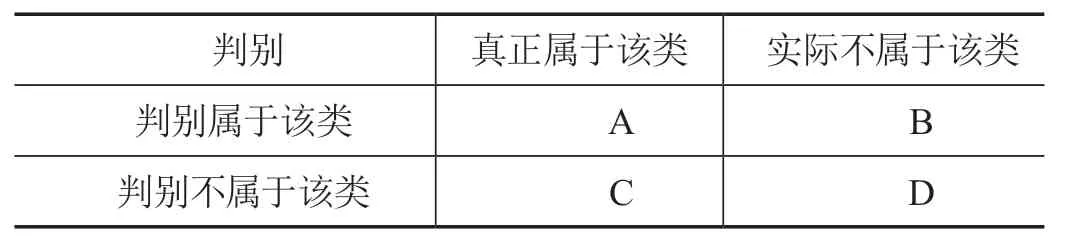
表1 分類結果混淆矩陣
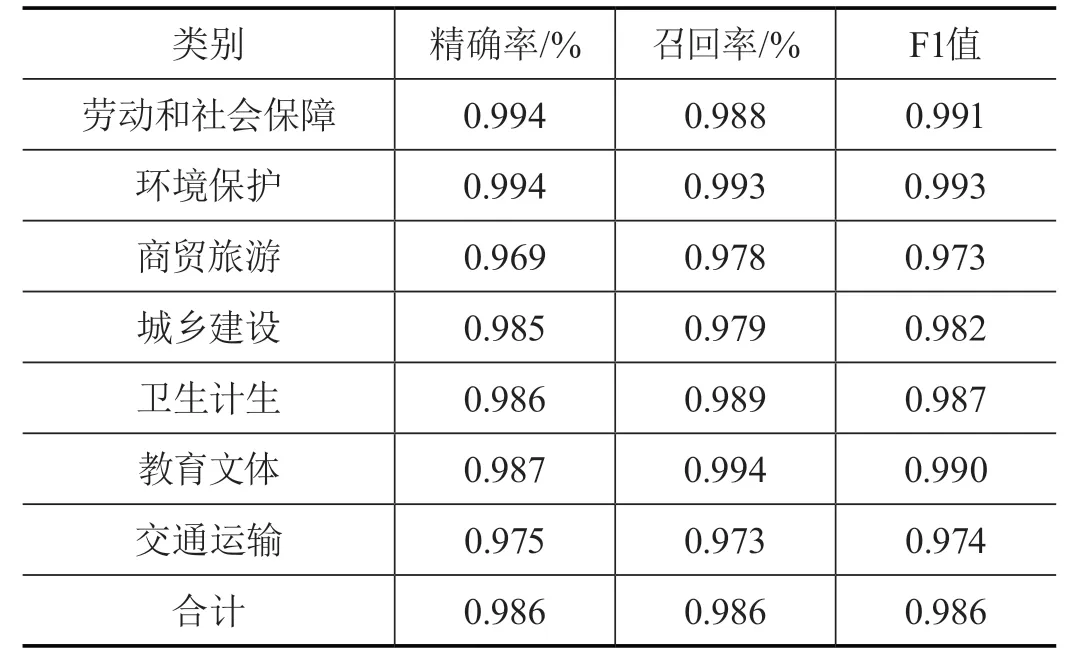
表2 模型分類效果評價
可知,模型的綜合預測效果達到了95%以上,而一般傳統的機器學習模型的準確率在85%以下,對于數據量大、特征難以提取的文本數據,用深度學習的算法更為合適。用測試集中的數據進行預測,隨機選取5個類別,從實驗結果可知,原始數據集的標簽和預測標簽的結果一致。
3 結語
通過對群眾留言的研究,本文提出了一種基于卷積神經網絡的群眾留言分類模型,并利用大量的文本數據進行驗證,經驗證取得了很好的分類效果。
猜你喜歡
當代陜西(2021年6期)2021-07-22 06:48:48
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
當代陜西(2021年1期)2021-02-01 07:18:22
制造技術與機床(2019年10期)2019-10-26 02:48:08
中學生數理化·七年級數學人教版(2019年4期)2019-05-20 10:06:32
電子制作(2018年18期)2018-11-14 01:48:06
中學生數理化·七年級數學人教版(2018年6期)2018-06-26 08:36:06
雜文月刊(選刊版)(2018年9期)2018-05-14 10:44:56
人大建設(2018年1期)2018-04-18 11:29:59
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
