緊湊的神經網絡模型設計研究綜述*
2020-09-13 13:53:18夏應清
計算機與生活 2020年9期
郎 磊,夏應清
華中師范大學物理科學與技術學院,武漢 430079
1 引言
近年來,卷積神經網絡(convolutional neural networks,CNN)在計算機視覺[1-6]、自然語言處理[7-9]、數據挖掘[10-12]等領域獲得廣泛的應用,并取得了優秀的表現。這些技術上的突破與龐大的數據量和強大的計算資源密切相關。例如,AlexNet[13]在自然圖像識別領域取得了突破性進展,它使用了約120萬張圖像在多個運算設備上進行訓練。從那時起,人們意識到CNN的性能要優于其他方式,進而對其性能的需求不斷提高。與此同時,CNN的計算復雜度以及存儲需求也急劇增加,如VGG[14]、GoogleNet[15]等網絡需求100 MB以上的儲存空間和上億次的計算操作。
由于配備了豐富的內存資源和計算單元的GPU和CPU集群的出現,可以在較為合理的時間內訓練出功能更強大的CNN。與此同時,人們在無人駕駛[16]、無人機[17]、智能手表[18]、智能眼鏡[19]等移動設備取得了巨大的進步,在這些設備上部署CNN模型的需求變得愈發強烈。可是,這些設備在存儲能力、計算單元和電池電量等資源上顯得十分匱乏,因此在低成本環境中使用CNN模型成了真正的挑戰。
當前的關鍵問題是如何在不顯著降低網絡性能的情況下為移動端或嵌入式設備配置有效的神經網絡模型。為了解決這個問題,在過去的幾年時間里,提出了許多壓縮與加速模型的方法[20-23]。本文主要對緊湊的神經網絡模型設計這種方法進行詳細的探討和敘述。
2 網絡壓縮與加速
從模型是否預先訓練的角度,網絡模型加速與壓縮方法可分為以下兩大類,分別是神經網絡的壓縮和緊湊的神經網絡設計。
2.1 神經網絡壓縮
通過對現有的預先訓練網絡模型進行壓縮,變成一個輕量級的神經網絡,有以下四種不同的方法。
(1)網絡修剪(network pruning)刪除了深度網絡中不重要或不必要的參數,提高了網絡參數的稀疏性,修剪后的稀疏參數需要較少的磁盤存儲空間,且省略了網絡中不重要參數計算,降低了網絡的計算復雜度[24-28]。
(2)低秩分解(low-rank decomposition)利用矩陣或張量分解技術估計并分解深度模型中的原始卷積核,通過分解4D卷積核張量,可以有效地減少模型內部的冗余性,從而降低網絡的參數和計算量[29-30]。
(3)網絡量化(network quantization)將計算程序中使用的浮點數由32 bit或者64 bit存儲大小替換為1 bit、2 bit的方式,減少程序內存占用空間,以此來減少計算復雜度和參數占用內存大小[31-32]。
(4)知識蒸餾(knowledge distillation)使用大型深度網絡訓練一個更加緊湊的神經網絡模型,即利用大型網絡的知識,并將其知識遷移至緊湊模型中[33]。
這些方法可以有效地將現有的神經網絡壓縮成較小的網絡。但它們的性能很大程度上依賴于給定的預先訓練的網絡模型,沒有架構層面的改進,無法進一步提高準確性。
2.2 緊湊的神經網絡設計
緊湊的神經網絡設計方法并未對預先訓練網絡模型進行壓縮,而是直接設計出具有較小計算復雜度和參數量的新型網絡。如何設計一個緊湊的神經網絡是近年來的研究熱點。
采用不同的空間卷積運算方式構建一個精確而輕量級的網絡,是常用的設計方法。例如:在NIN[34]模型中提出了網絡內嵌網絡的架構,利用1×1卷積來增加網絡容量,同時保持整體計算復雜度較小。GoogleNet中使用平均池化層代替了全連接層,減少了網絡模型的存儲需求。SqueezeNet[35]利用1×1卷積和分組卷積方法,在AlexNet上實現了約50倍的壓縮,并且具有相當的精度。MobileNetV1[36]中提出了深度可分離卷積方法,并將該方法應用得很好,模型比VGG-16模型縮小了96.8%,且速度快27倍;Mobile-NetV2[37]是在MobileNetV1的基礎之上添加了殘差結構和線性瓶頸結構。ShuffleNetV1[38]利用分組卷積和Channel Shuffle的方法縮減網絡模型大小,提高運行效率。ShuffleNetV2[39]是對ShuffleNetV1的網絡結構的進一步的改進。ESPNetV2[40]提出深度可膨脹可分離卷積,且對ESPNetV1[41]模型結構進行通用化改進,運行效率高,模型小,準確度強。
此外,采用移位運算和卷積運算相結合的方式同樣可構建出較為緊湊且強大的網絡模型,例如:ShiftNet[42]采用移位運算與逐點卷積相結合的方式,構建出一個緊湊的網絡模型。As-ResNet[43]使用主動移位代替深度可分離卷積運算,并針對移位卷積運算設計了主動移位層(active shift layer,ASL),提高了模型學習和運行的效率,減少了參數量。FE-Net[44]中稀疏移位層(sparse shift layer,SSL)是對ASL層的改進,消除了無意義的移位操作,進一步加快了模型運行的速度。
緊湊的神經網絡設計原則雖有不同,但其均是設計特殊的結構化運算核或緊湊計算單元,減少模型的參數量,降低計算復雜度。本文主要對緊湊神經網絡模型設計的相關技術進行進一步的討論,并選取近3年提出的6種緊湊神經網絡模型進行學習和比較,分析各自性能特點,同時對實現輕量化的方法進行總結。6種模型分別是MobileNetV2、ShuffleNetV2、ESPNet-V2、ShiftNet、As-ResNet和FE-Net。其中MobileNetV2是MobileNetV1的改進版,ShuffleNetV2的網絡結構也是基于ShuffleNetV1的網絡結構,ESPNetV2是對ESPNetV1進行通用化的結果,FENet的基礎運算方式是基于ShiftNet和As-ResNet的基礎運算方式改進而來的。這4類網絡在實現輕量化的方法上具有極高的參考價值。
3 緊湊的神經網絡
緊湊的神經網絡模型設計,是指參考現有的神經網絡結構,改變基本運算方法,并重新設計網絡結構,以此設計出參數量少、運算復雜度低的新型網絡。本文首先對基礎運算方式進行介紹,根據運算方式的不同,將模型設計分為基于空間卷積運算的模型設計和基于移位卷積運算的模型設計,并分別介紹了3個典型網絡模型。
3.1 基本運算
在神經網絡中,基本運算單元主要的作用是聚合空間信息,提取局部特征值。空間卷積運算和移位卷積均可實現該功能,下面主要針對這兩種基本運算單元進行描述。
3.1.1 空間卷積運算
常用的空間卷積運算主要有標準卷積、分組卷積(group convolution)、逐點卷積(pointwise convolution)和膨脹卷積(dilated convolution)。標準卷積是一種有效提取空間信息特征的運算方式,一般使用卷積核遍歷空間中的每一個區域,對重合區域內的值進行求和,再加偏激值后,得到輸出空間的特征圖,其結果與每個通道特征都有關。假設W×H為輸入輸出特征圖的空間尺寸,M為輸入特征的通道數,N為輸出特征的通道數;卷積核尺寸為K×K×M,數量為N計算如圖1所示。

Fig.1 Standard convolution calculation圖1 標準卷積計算
分組卷積是對標準卷積的一種變形,最早在Alex-Net中出現,解決了硬件資源有限的問題。輸入特征圖在通道上被分成G組,這種分組僅在深度上進行劃分,每組通道數為M/G。卷積核的深度變成M/G,而卷積核的大小并不需要改變,此時卷積核的數量變為N/G。經過卷積運算后,將不同組的內容進行拼接起來,最終輸出通道仍為N。相對于標準卷積,分組卷積的參數量縮小1-1/G,計算量降低為1/G。分組卷積雖然大大降低了計算復雜度和參數量,但是其僅聚合了組內的空間信息,組間“信息流通不暢”。
逐點卷積是一種特殊的標準卷積運算,卷積核K值為1。逐點卷積主要用于改變輸出通道的特征維度,且能夠有效地“混合”通道間的信息,解決了分組卷積中存在的“信息流通不暢”的問題。
膨脹卷積是一種特殊的卷積運算,改變了卷積核的計算方式[45]。膨脹卷積引入了膨脹率r,用于表示擴張大小,即卷積核中值與值之間的間隔,如圖2為不同膨脹率的3×3卷積計算示意圖。r=1時為標準卷積核;r=2時,可看出卷積核的內容并未發生改變,僅改變了卷積運算時,卷積核所感受的圖像視野大小,中間空著的像素并未參與具體運算。因此其對計算復雜度和參數值大小并未發生變化。在相同計算條件下,膨脹卷積運算擁有更寬的視野,可以捕捉到更長的依賴關系,非常適用于需求寬視野小卷積核的計算。膨脹卷積主要用于增強信息間的關聯度,防止信息的丟失。

Fig.2 3×3 convolution calculations at different expansion rates圖2 不同膨脹率下的3×3 卷積計算
3.1.2 移位卷積運算
目前,常用的移位卷積運算主要有標準移位、分組移位(grouped shift)、主動移位(active shift)和稀疏移位(sparse shift)。標準移位如圖3所示,標準移位由兩個步運算完成,分別是移位運算和逐點卷積運算。移位運算是將通道向一個方向進行移位,移位內核中存儲移位方向信息。逐點卷積運算主要是對移位運算后的信息進行“混合”。與深度卷積不同,移位運算本身不需要參數或浮點運算,它僅是一系列內存方面操作,而逐點卷積運算占用了大部分的參數和浮點運算操作。

Fig.3 Standard shift operation圖3 標準移位運算
分組移位是對標準移位的一種變形,其關系類似于分組卷積與標準卷積,操作方式如圖4(a)所示。將通道劃分為若干組,其中每組通道采用同一方向的移位運算,然后進行逐點卷積運算。分組移位具有較少的參數量和移位空間,能夠有效地加速網絡訓練。分組移位最早在ShiftNet中出現,用于解決搜尋最佳位移值計算量過大的問題。
主動移位是標準移位量化形式的另一種體現,相較于分組移位而言,通道移位的可能性更多,對通道間信息的“混合”程度更高。操作方式如圖4(b)所示,每個通道均進行了移位運算,且移位方向更多,后由逐點卷積運算“混合”通道信息。假設M為輸入特征的通道數量,Dk為水平和垂直最大移位量,主動移位運算有種移位可能性。在網絡訓練中,需要計算所有可能性下的輸出特征圖,找出最佳移位值,這需要極大的計算量,而且主動移位運算將在網絡中多次使用,網絡訓練所需計算成指數上升。在As-ResNet中,采用水平移位參數α和垂直移位參數β表示移位方向,同時提出了α和β可微的方法,最終實現移位參數可學習的目的,提高了網絡訓練的速度。
稀疏移位是一種特殊的主動移位,將移位通道劃分為兩部分,一部分進行移位運算,而另一部分保持不變,其操作方式如圖4(c)所示。稀疏移位中并非所有的通道都參與移位運算,僅有部分特殊通道參與了移位運算,而后進行逐點卷積運算。假定參與移位運算的通道數量為M′,其中M′<M,移位內核的數量同樣由M降低至M′,稀疏移位運算有種移位可能性,極大地縮小了搜尋范圍,降低了網絡的參數量。與主動移位相比,稀疏移位減少了不必要的操作,降低了參數量。此外,解決了較多移位運算會造成重要信息丟失的問題,保證了信息的完整度。在FE-Net中,引入移位懲罰因子實現稀疏移位運算,降低了網絡的參數,提高了網絡運行的效率。

Fig.4 Different shift operations applied to feature maps圖4 應用于特征圖的不同移位操作
3.2 基于空間卷積的模型設計
MobileNetV2、ShuffleNetV2和ESPNetV2均是對基礎模型的空間卷積運算改進而成的。因此,本節主要對空間卷積運算進行分析,進而給出合適的構建塊,最終給出整體網絡結構,并總結模型特點。
3.2.1 MobileNetV2
MobileNetV2[37]是Google公司為移動設備和嵌入式視覺應用提出的一個尺寸小、延遲低的卷積神經網絡,是MobileNetV1的改進版。整體網絡沿用了MobileNetV1的深度可分離卷積作為基礎運算單元,從而實現較低參數量和計算量。
標準卷積可分解成一個深度卷積和一個逐點卷積,這就形成了深度可分離卷積。假設H×W×M表示輸入特征,輸出特征為H×W×N,標準卷積核如圖5(a)所示,標準卷積層參數量為K2MN,標準卷積的計算復雜度為K2MNHW。深度卷積核如圖5(b)所示,深度卷積運算的計算復雜度為K2MHW,參數量為K2M。深度可分離卷積從參數量和計算復雜度方面均有了明顯的下降。

Fig.5 Standard convolution kernel and depthwise separable convolution kernel圖5 標準卷積核和深度可分離卷積核
此外,MobileNetV2在結構上借鑒了ResNet[46],并進行了以下兩方面改進:一是引入了線性瓶頸結構,即刪除了在低維度輸出層后所連接的非線性激活層,保證了信息的完整性;二是引入了反向殘差結構。采用先“升維”再“降維”的方式,保證了特征信息的有效傳遞。
MobileNetV2基本構建塊是具有反向殘差的深度可分離卷積塊,該基本構建塊的詳細結構如圖6,首先通過1×1卷積層,對其輸入通道維度升高;隨后使用深度可分離卷積混合信息;最后經過1×1卷積運算降低維度。

Fig.6 Basic building blocks of MobileNetV2圖6 MobileNetV2的基本構建塊

Table 1 MobileNetV2 architecture表1 MobileNetV2整體網絡結構
MobileNetV2整體網絡結構如表1所示。其中t表示模型的核心構建塊中的擴展因子,c為輸出通道數,n為每層重復運行的次數,s為重復計算中第一次的步長,其余步長均為1。MobileNetV2中使用ReLU6作為非線性激活函數,在低精度計算時具有較高的魯棒性。模型訓練時,利用Batch Normalization[47]和Dropout[48]避免了梯度消失和退化的問題。
MobileNetV2創新點在于采用MobileNetV1的深度可分離卷積作為基礎運算單元,降低了模型的大小,引入了線性瓶頸和反向殘差結構,保證了信息的完整性,有效地解決了梯度消失等問題。但在應用中存在一定局限性,網絡尺寸大小應高于一定數值,即網絡通道數量不應設置過少,否則會導致信息傳遞過程中丟失過多信息,進而大幅度降低精確度。
3.2.2 ShuffleNetV2
ShuffleNetV2是曠視科技提出的一種高效的CNN模型,和MobileNetV2一樣適用于移動端的輕量級網絡模型。網絡同樣采用深度可分離卷積作為基礎運算單元。
ShuffleNetV2構建模塊如圖7所示。對于步長為1的模塊,引入了一種名為通道分片(channel split)的運算方法,該方法將輸入通道一分為二,其中一部分向下直接傳遞,另一部分進行卷積運算,將二者結果進行合并,且后不加ReLU操作,輸出信息前進行Channel Shuffle操作,增加通道之間的信息交流。對于步長為2的采樣模塊,該層需要將通道數量翻倍,即直接將輸入通道傳向兩個部分,最后結果進行合并。

Fig.7 ShuffleNetV2 basic building blocks圖7 ShuffleNetV2基礎構建模塊
ShuffleNetV2中Channel Shuffle操作主要是為了解決不同組卷積間信息交流不暢的問題。如圖8(a)所示,輸入特征被分為3組,若存在3組卷積,組與組之間信息并無交流,影響了模型的表達能力,因此需要增加組件信息交流的機制。圖8(b)中所示,對不同組卷積后的特征圖進行“重組”操作,這樣同樣可以完成組間信息交流的目的,但是Channl Shuffle采取的“重組”策略更為優秀,即按照一定規律進行重組,具體實現如圖8(c)所示。ShuffleNetV2整體網絡結構如表2所示。
ShuffleNetV2的創新點在于采用了Channel Shuffle操作,來提高組間的信息交換。此外,提出了輕量級網絡結構設計的四項實用準則:一是輸入通道數與輸出通道數保持相等可以最小化內存訪問成本;二是分組卷積中使用過多的分組會增加內存訪問成本;三是網絡結構太復雜(分支和基本單元過多)會降低網絡的并行程度;四是元素級別的操作消耗不能夠忽視。但ShuffleNetV2模型對內存訪問效率提出了更高的需求,內存訪問效率直接影響Channel Shuffle的運行速度,進而改變網絡預測快慢。

Fig.8 Channel Shuffle圖8 Channel Shuffle操作

Table 2 ShuffleNetV2 architecture表2 ShuffleNetV2整體網絡結構
3.2.3 ESPNetV2
ESPNetV2是對應用于語義分割的卷積神經網絡ESPNetV1進行通用化后推出的網絡結構。該網絡的核心構建模塊是EESP單元,它使用可膨脹可分離卷積來代替標準卷積運算。深度可膨脹可分離卷積(depthwise dilated separable)通過將標準卷積分解為兩層,來實現過濾器的輕量化:一是深度可膨脹可分離卷積引入了膨脹率r,該參數能夠有效提高卷積運算的感受野(receptive field);二是逐點卷積學習輸入的線性組合,降低了計算成本。假設輸入通道數為M,輸出通道數為N,卷積核大小為K×K。深度可膨脹可分離卷積計算復雜度是標準卷積的1/N+1/K2倍。表3中提供了不同類型卷積之間的比較。其中EFF代表的是有效感受野值,g為分組的數量,Kr=(K-1)×r+1。

Table 3 Comparison of different convolution EFF values表3 不同卷積EFF值對比
下面具體介紹ESPNetV2的核心構建模塊EESP(extremely efficient spatial pyramid of depthwise dilated separable convolutions)單元,其結構如圖9所示。步長為1的EESP單元如圖9(a),首先是1×1分組卷積,然后是3×3的深度可膨脹可分離卷積,緊接著使用層次特征融合(hierarchical feature fusion,HFF)對結果進行融合,有效地消除由膨脹卷積引起的gridding artifacts[49-50]問題。對于帶有Stride的EESP單元如圖9(b),在原有EESP基礎上,將深度可膨脹可分離卷積的步長設置為2,并對輸入通道進行3×3平均池化,所得結果和輸出進行拼接;此外,將輸入圖像進行P次3×3平均池化,然后進行3×3卷積和1×1卷積,最后結果與拼接特征圖相加。其中每個卷積層表示的含義如下:Conv-n,n×n標準卷積;GConv-n,n×n組卷積;DConv-n,n×n膨脹卷積;DDConv-n,n×n深度膨脹卷積;括號內表示的分別為輸入通道數、輸出通道數和膨脹率。
ESPNetV2的整體網絡結構如表4所示,為了增加網絡深度,該網絡會重復使用EESP單元。在EESP單元之后使用batch normalization和PReLU[51],但最后一次卷積運算除外。在實驗中,將膨脹率r與EESP單元中分組數g設置為正比關系,其感受野隨著g增大而增大。同時限制了每個空間感受野維數,以此減少梯度消失問題的出現。

Table 4 ESPNetV2 architecture表4 ESPNetV2整體網絡結構
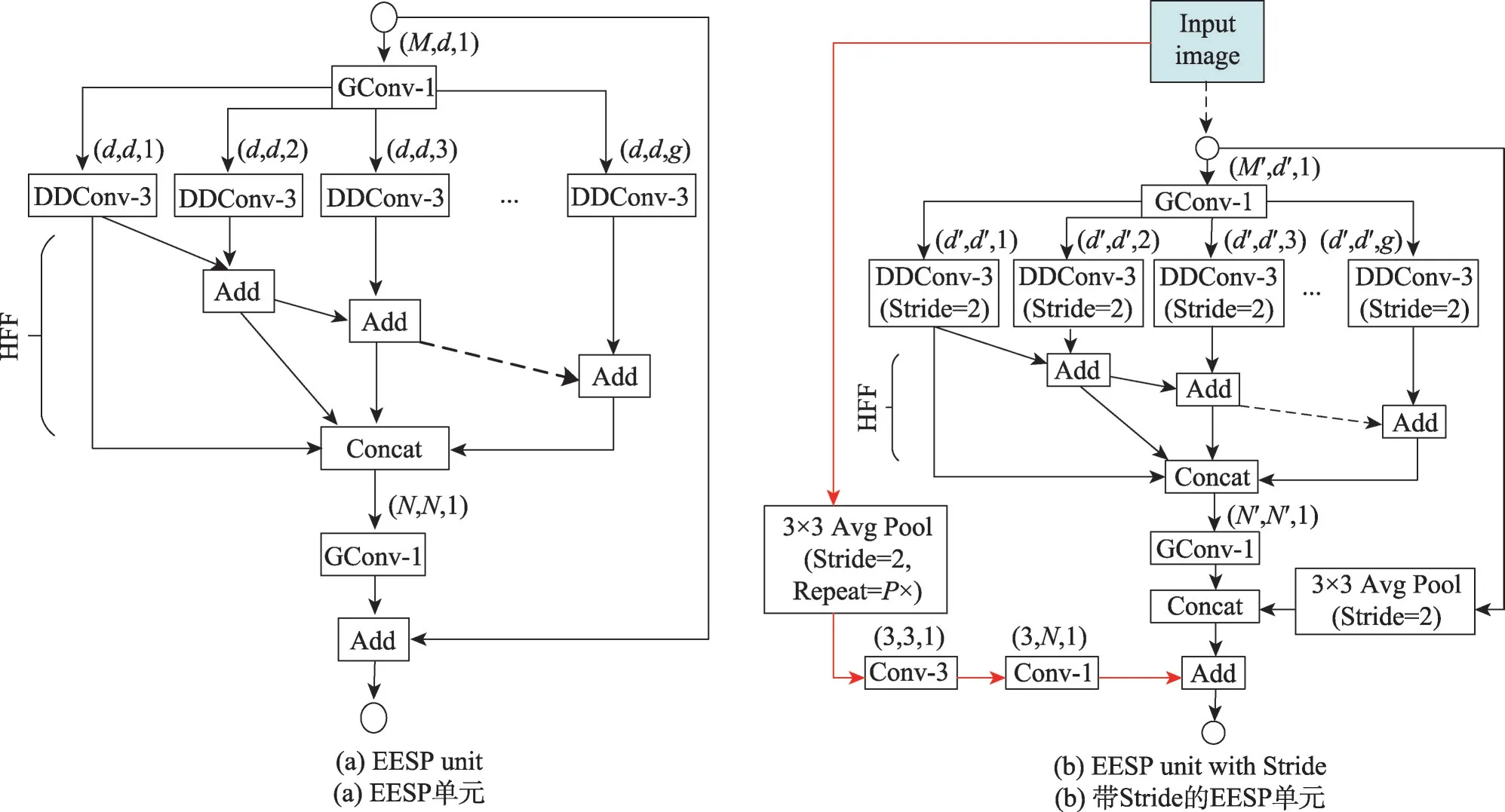
Fig.9 ESPNetV2 basic building blocks圖9 ESPNetV2的基礎構建塊
ESPNetV2創新點在于提出了深度可膨脹可分離卷積代替深度可分離卷積的方法,并采用層次特征融合(hierarchical feature fusion,HFF),消除gridding artifacts問題,降低了網絡計算復雜度,提高了網絡的感受野。但在應用中,膨脹率r不會隨著輸入圖像分辨率的大小而改變,需要根據經驗設置膨脹率數值大小。
3.3 基于移位卷積的模型設計
ShiftNet、As-ResNet和FE-Net是將基礎模型中空間卷積運算替換為移位卷積運算改進而成,采用不同的移位卷積運算,但其網絡結構均由基礎構建塊組合而成。因此本節同樣從基礎運算、核心構建塊和整體網絡結構三方面進行分析,并對模型特點進行總結。
3.3.1 ShiftNet
ShiftNet是由伯利克大學的研究人員提出的一種無參數、無FLOP的移位運算代替空間卷積運算的一種新型網絡結構。此網絡結構的核心構建模塊是CSC(conv-shift-conv module)。CSC模塊是對殘差單元模塊的改進,使用分組移位替換了常用的空間卷積運算。
分組移位是一種特殊的標準移位,具有較少的移位內核。對于標準移位而言,給定移位內核大小為Dk,通道大小為M,有種移位內核的可能性。在此狀態空間上搜索最佳移位內核成本過高,因此采用分組移位方式,將M個通道平均分為組,每組通道采用同一種移位方向,大大減少了狀態空間,提高了移位搜尋的效率。
CSC結構如圖10所示,首先輸入特征通過逐點卷積進行處理,然后執行移位運算,重新分配空間信息,最后使用逐點卷積來混合通道間的信息。其中,在兩個逐點卷積運算前均進行了Batch Normalization和ReLU非線性激活函數。參照ShuffleNetV1中核心構建塊的設計特點,若步長為1時,即輸入和輸出的尺寸相同,采用加性操作進行連接;若步長為2,即輸出通道數翻倍,對輸入特征圖進行平均池化,二者結果采用通道級聯進行連接。其中,移位運算的內核大小用于控制模塊的感受野;膨脹率d表示為“膨脹移位”后數據采樣的空間間隔,類似于膨脹卷積。

Fig.10 ShiftNet kernel building block CSC圖10 ShiftNet的核心構建塊CSC
ShiftNet的整體網絡架構如表5所示。為了進一步壓縮模型,ShiftNet采用擴展因子ε控制中間通道的數量,其方法與MobileNet中寬度因子α相似,控制每個基礎構建塊的大小,表5中描述的架構稱為ShiftNet-A。對于更小的網絡架構ShiftNet-B和ShiftNet-C而言,ShiftNet-B是將所有CSC模塊中的通道數量減少2;ShiftNet-C則是把ShiftNet-A組{1;2;3;4}中使用CSC模塊數量更改為{1;4;4;3},通道數量變更為{32;64;128;256}。
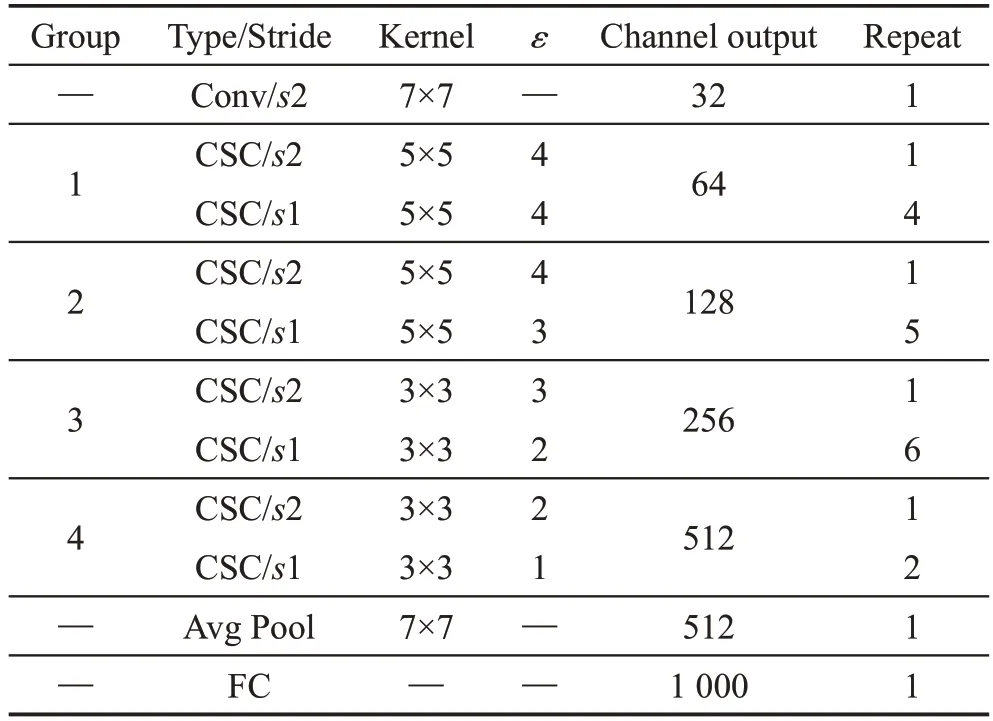
Table 5 ShiftNet architecture表5 ShiftNet整體網絡結構
ShiftNet創新點在于提出了使用移位運算和逐點卷積代替空間卷積完成聚合空間信息的方法,利用移位運算本身不需要參數和計算的優勢,有效地減少了計算復雜度和參數量。同時,為了提高網絡的訓練效率,采用了分組移位的方法,減少了狀態空間的大小。此外,網絡的基礎模塊引入擴展因子ε,用于均衡網絡大小和準確度。但ShiftNet在實際應用中仍有限制,模型訓練時間相對較長,而且訓練結果未必為最優值。
3.3.2 As-ResNet
ShiftNet采用移位運算和逐點卷積代替空間卷積的方式,減少計算復雜度和參數量。但網絡中移位量采用啟發式進行分配,網絡訓練時間較長且優化困難,并不能達到網絡壓縮最優的目的。參照反向傳播算法的特點,結合ShiftNet的標準移位,提出了主動移位,并應用于ResNet網絡,形成新型網絡As-ResNet。其網絡主要對基礎運算方式進行改進。
不同于標準卷積運算,主動移位將卷積運算解構為兩個操作步驟進行實現,分別是移位運算和逐點卷積運算。其具體解構卷積如圖11所示,觀察標準卷積運算基本構成,標準卷積等價于逐點卷積的總和,利用移位輸入代替卷積核參與運算,最后共享移位輸入,形成這種運算方式。該運算方式具有較少的計算量和內存訪問,但是在移位方向僅有一個的情況下,運算的性能會大打折扣。為了保證移位輸入具有較高的性能,設計了主動移位層(ASL)。ASL使用深度移位方法,為每個通道引入移位參數α和β,并提出了α和β可微的方法,即在運算中,將α和β的整數約束放寬為實值,并放寬對雙線性插值的移位運算。因此,該方法的參數具有可學習的能力,通過反向傳播算法進行優化,以達到計算速度更快、網絡更小的目的。
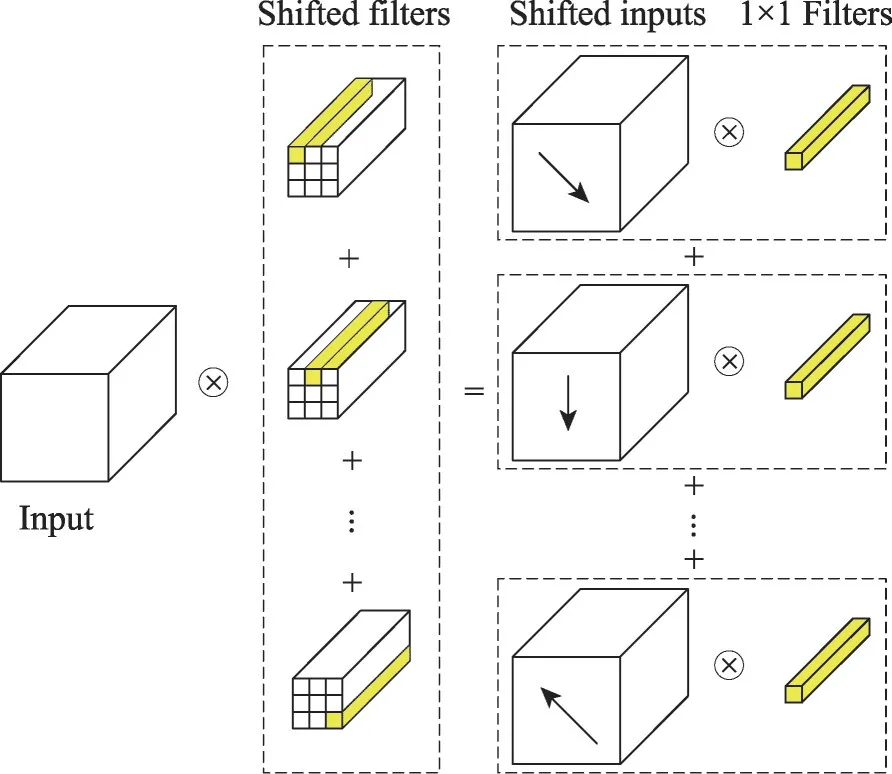
Fig.11 Deconstructed convolution圖11 解構卷積示意圖
As-ResNet的整體網絡結構如表6所示,其中基礎構建塊是由BN-ReLU-1×1 Conv-ASL-BN-ReLU-1×1 Conv順序構成,與ShiftNet中CSC模塊相似,n為重復運行該層的次數,s為步長。網絡整體結構僅在第一層使用了空間卷積運算。隨著網絡深度的增加,輔助層的數量增多,為了進一步控制網絡的大小和準確性,采用與MobileNet、ShuffleNet同樣的方法,加入了基本寬度參數w,控制輸出通道數。

Table 6 As-ResNet architecture表6 As-ResNet整體網絡結構
As-ResNet的創新點在于使用主動移位替代空間卷積,并以此設計了主動移位層(ASL),將移位運算量化為具有參數的函數,而且可以通過反向傳播來學習移位量,能夠模仿各類型卷積運算。但As-ResNet中移位運算依靠于內存操作,其直接影響網絡運行效率,選用合適的硬件設備十分重要。
3.3.3 FE-Net
移位卷積運算是一種有效的超越深度可分離卷積的方法,在ShiftNet和As-ResNet中均有了較好的成效,但它的實現方式仍是一大難題,即內存移動。因此,FE-Net提出了基于稀疏移位層(SSL)的卷積神經網絡構建方法,即使用稀疏移位運算代替標準卷積,具體實現方法為:在損失函數中,給移位操作添加懲罰項,去除無用的移位操作。隨后,采用量化感知的移位學習方法,使移位運算可微,確保了移位卷積的可學習性。最后,為了最大程度發揮SSL的作用,FE-Net重新設計了基礎構建塊,并對網絡體系結構進行相應的改進。
FE-Net的核心構建塊FE-Block(fully-exploited computational block)是網絡的重要組成部分,其結構如圖12所示。在這個構建塊中,每次基本計算僅有一部分特征參與其中。對于不同的計算塊,參與計算的特征圖數量會隨著計算的深入逐漸增加。對于具有n=3個基本單元的計算塊,輸入特征圖被均勻劃分為2n-1部分,第m個計算塊進行計算時,有2m-1部分參與其中。FE-Block的基本計算單元如圖13所示,圖13(b)主要用于核心構建塊中使用,但對于每個計算塊的最后一個計算單元,使用圖13(a)來更改下一個計算塊的通道數量,或者使用圖13(c)進行空間向下采樣。

Fig.12 FE-Block:FE-Net kernel building block圖12 FE-Net的核心構建塊FE-Block

Fig.13 FE-Block basic calculation unit圖13 FE-Block的基本計算單元
FE-Net的整體網絡結構如表7所示,其中t表示基礎運算單元中,第一個1×1卷積輸入通道的擴展率;該運算塊重復n次,輸出通道數為c,步長為s。為了進一步平衡網絡的大小和準確率,網絡中引入了寬度因子作為超參數。
FE-Net的創新點在于引入了SSL,能夠快速準確地建立神經網絡,減少了無意義的移位操作;隨后采用量化感知的移位學習方法,保證移位卷積的可學習性,同時避免了推理過程中的插值;最后根據SSL的特點,設計了一個緊湊的神經網絡。FE-Net尺寸不能設置過小,該方式不僅導致稀疏層無效化,而且影響信息傳遞的完整性。

Table 7 FE-Net architecture表7 FE-Net整體網絡結構
4 網絡性能對比
為了更直觀地分析6個緊湊的神經網絡性能,在ImageNet2012數據集上進行實驗,實驗結果如表8所示,主要參數有模型的參數量、FLOPs和分類準確率。表格按照參數量數值大小分為4組進行對比,即1.2、3.6、6.5和10+Parames/106。與此同時,表格中加入了3個常規網絡在該數據集上運行的參數。在模型訓練時,通過調整超參數,均衡網絡在精度及速度方面的性能,其中超參數多指寬度因子,即各個基礎構建塊間銜接時輸入輸出通道數量,若減少該值大小,網絡精度會有所下降,但預測速度加快。另外,存在部分網絡通過調整網絡中的重要參數,進一步改善網絡的精度和速度,如MobileNetV2的擴展因子t、ESPNetV2的膨脹率r、FE-Net的擴展率等。
分析表8中數據不難看出,在同等模型參數量的條件下FE-Net的分類準確度要高于其他5個網絡框架,而ShuffleNetV2的表現也同樣出彩。將其按照基本運算方式進行分類,即MobileNet、ShuffleNet和ESPNet是基于空間卷積的模型,簡稱為第一類網絡;ShiftNet、As-ResNet和FE-Net是基于移位卷積的模型,簡稱為第二類網絡。
對比第一類網絡模型,在同等計算復雜度的情況下,ShuffleNetV2表現要優于其他兩個網絡結構,且參數量也并無較為明顯的差距。在具體硬件設備上進行測試,ShuffleNetV2預測速度最快,而ESPNetV2的準確度雖略遜于ShuffleNetV2,但其功耗最低,主要由于ESPNetV2網絡結構設計較為簡單,且沒有采用通道混洗的方法,減少了對內存的訪問操作,在保持功耗較低的情況下擁有相當的準確度。

Table 8 Performance comparison of multiple network models on ImageNet2012 dataset表8 多網絡模型在ImageNet2012數據集上性能對比
對于第二類網絡模型,在同等參數量的條件下,FE-Net的分類準確度最優,這主要因為稀疏移位比主動移位和分組移位在空間信息特征提取度高,減少了無用的移位操作,節省了資源。
對比第一類和第二類網絡結構可發現,第二類網絡結構的計算復雜度普遍較高,即FLOPs較高。FLOPs雖然被廣泛應用于比較模型的計算復雜度,并且認為它與時間運行成比例,但在文獻[39,43]均提出,FLOPs僅是衡量模型計算復雜度的間接指標之一。內存訪問成本(memory access cost,MAC)和模型并行度也是影響模型間接計算復雜度的情況之一。此外,第一類的FLOPs主要由深度可分離卷積提供,而第二類的FLOPs主要由1×1卷積提供。文獻[43]對1×1卷積運算和3×3深度可分離卷積的運算效率進行對比,盡管1×1卷積的FLOPs要大很多,但是它的運行效率要遠高于3×3深度可分離卷積。這一點在實驗中得到了驗證,在同等的計算能力設備上,As-ResNet和FE-Net模型在GPU和CPU上的運行速度快于MobileNetV2。
最后,對比緊湊的神經網絡和3個常規網絡的準確度、FLOPs和網絡參數量,常規卷積神經網絡AlexNet、GoogleNet和VGG-16在各個方面的參數都略遜于這6個緊湊的神經網絡,甚至在準確度方面已經遠超于常規網絡。這表明,緊湊的神經網絡設計并不是必須犧牲網絡準確度來獲取更小的網絡模型尺寸的,在降低網絡模型尺寸的同時,也可擁有較高的準確度。
5 緊湊神經網絡設計技巧
本文所列的六個模型對于人工設計緊湊神經網絡架構有著重要的意義,其設計方法典型有效。首先,對這六個模型的設計方法進行梳理和總結,然后得出緊湊神經網絡架構設計的要點,最后討論緊湊神經網路的發展方向。
MobileNetV2使用深度可分離卷積降低了計算復雜度,減少了參數量。此外,引入了反向殘差和線性瓶頸,有效解決了梯度消失的問題,同時極大提高了網絡的準確性,降低了計算復雜度。ShuffleNetV2提出了Channel Shuffle操作,解決了不同組間“信息交流不暢”的問題,提出了輕量級網絡結構設計的四項實用準則。ESPNetV2提出了深度可膨脹可分離卷積,提高了網絡的感受野。采用分層特征融合方法,有效解決了膨脹卷積運算引起的gridding artifacts問題。最終達到分類準確度在同等計算復雜度情況下與ShuffleNetV2基本一致,且具有較低的功耗。
ShiftNet采用分組移位運算,具有較高的運算速度。As-ResNet對ShiftNet的移位操作進行改進,提出了主動移位運算方法,并設計了主動移位層(ASL),使得移位卷積可通過反向傳播學習移位量。FE-Net將稀疏移位應用于卷積神經網路中,是對移位卷積的又一次“升華”,去除了無用的移位操作,極大發揮了移位操作的優勢。
六大緊湊網絡模型對比分析如表9所示,具體從設計技巧、優缺點、應用建議三方面進行介紹。從表9中可以看出,基礎運算直接影響網絡的表現,網絡結構也應根據不同的基礎運算做出相應的調整。在網絡結構設計時,網絡深度并非越深越好。具體應用網絡時,根據網絡特點,選用匹配的硬件器件,并對其做出相應優化。
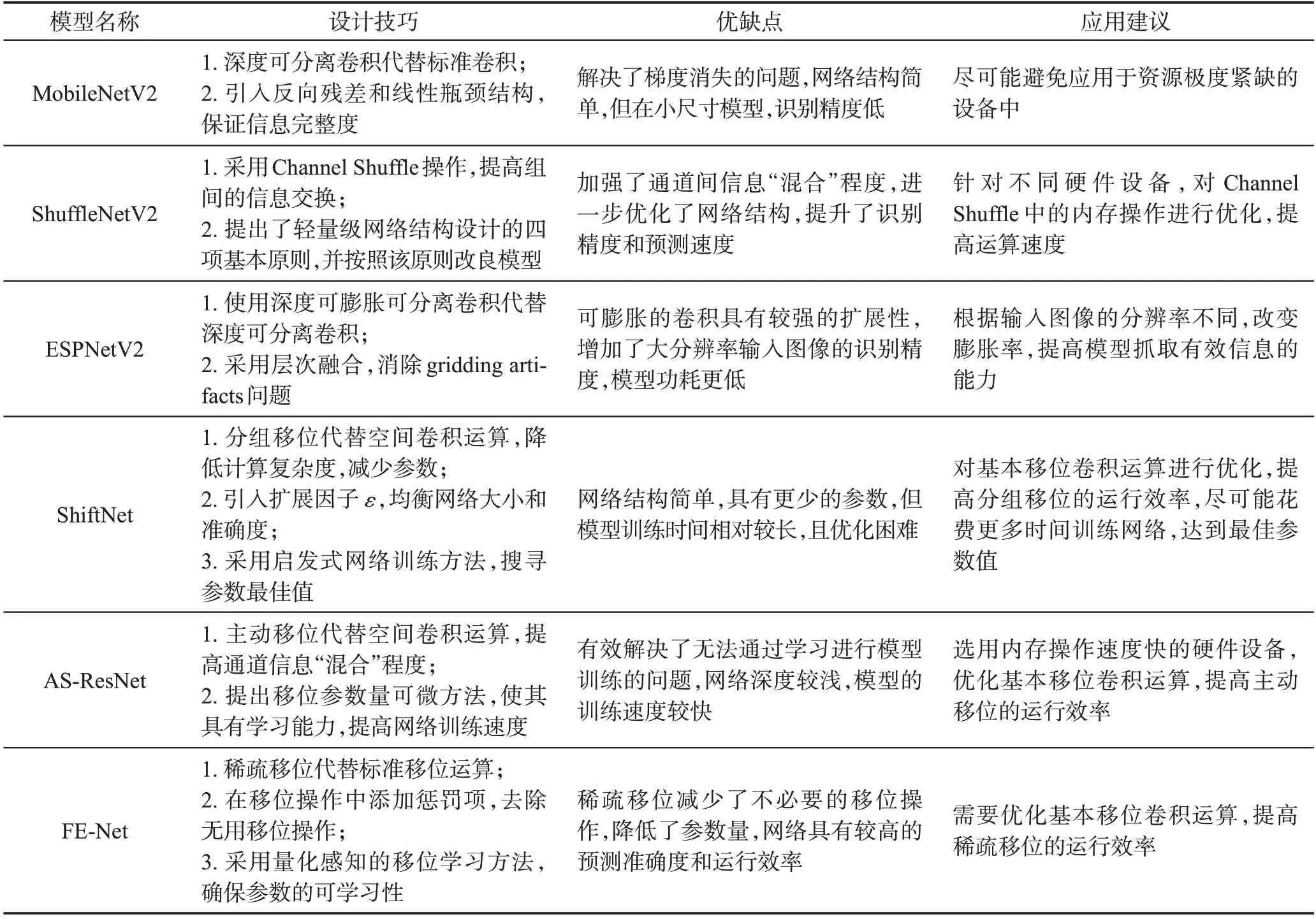
Table 9 Comparative analysis of six compact network models表9 六大緊湊網絡模型對比分析
對比這六個模型設計緊湊神經網絡的方法,殘差單元是緊湊神經網絡模型的重要參考結構。殘差網絡有效地解決了網絡退化和梯度消失問題,在網絡準確度較低的情況下,可以通過增加網絡的深度來提高網絡的性能。這一結構特點有利于緊湊神經網絡模型的設計的集中性,無需考慮網絡深度對其準確度的影響,極大地縮減了模型設計的時間。
再者,采用不同的基礎卷積運算對設計緊湊神經網絡模型設計有很大的提升,MobileNet和Shuffle-Net采用深度可分離卷積作為基礎卷積運算單元,降低了卷積運算計算復雜度,減少了參數量;ESPNet采用深度可膨脹可分離卷積作為基礎卷積運算單元,在深度可分離卷積的基礎上增加了運算的感受野。因此,選用適當的基礎卷積運算對設計緊湊神經網絡模型有著重要意義。
與卷積運算相比,采用標準移位運算同樣能夠實現聚合空間信息的目的,是一種有效的替代方法。標準移位先將輸入信息進行移位運算,重新排列空間信息,后進行逐點卷積,聚合空間信息。標準移位運算在速度上要優于標準卷積運算,且其計算代價與核大小無關。因此,這樣的運算方式有利于緊湊神經網絡模型的設計。
此外,可以采取與其他方法相結合的方式,進一步提高網絡性能。例如,網絡可配備SE模塊(squeezeand-excitation)[52],一般放置于基本構建塊的輸出位置,利用通道間的相關性,強化重要通道的特征,提升準確度。雖然SE模塊可以提高原有網絡的準預測準確度,但會降低一定運行速度。因而,這一方法僅適用于提高網絡準確性,具體使用還需權衡。
另外,神經網絡架構搜索(neural architecture search,NAS)是近年來提出的自動化設計神經網絡的方法,可自動設計網絡結構[53-56]。在網絡架構搜尋前,需要對卷積層、卷積單位和卷積核的大小等參數進行預先設定,隨后使用預設定的參數在一個巨大的網絡空間上搜尋。其中文獻[54-55]對MobileNetV2進行了改進,并取得了良好的效果,但對資源消耗量較大,有一定的局限性。對于資源較為充沛設計人員,不失為一種設計輕量化模型的好方法。
最后,計算復雜度和參數量僅能代表網絡的部分性能優劣,對于緊湊的神經網絡模型性能的測試,應在具體設備上進行測試,比較網絡的性能。與此同時,為了打破算法建模和硬件實現之間的鴻溝,硬件-軟件協同設計方法也將成為未來的發展趨勢。
6 結束語
深度神經網絡在廣泛的應用中得到了優秀的表現,讓神經網絡真正地走向生活中,需要對網絡模型在大小、速度和準確度方面做出平衡,以能夠成功實現網絡運行在資源緊缺的移動端或嵌入式設備。本文首先簡述了網絡壓縮與加速的兩種方法,即神經網絡壓縮和緊湊神經網絡設計。隨后重點介紹了緊湊神經網絡設計的主流方法,并根據不同的基本運算分為空間卷積和移位卷積兩大類。同時,還對這兩大類中典型網絡模型進行了梳理和論述,并且分析了網絡性能的優缺點。最后,總結了緊湊神經網絡設計的技巧,并對其發展方向進行了展望。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·七年級數學人教版(2020年11期)2020-12-14 06:59:52
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
藝術品鑒證.中國藝術金融(2018年8期)2019-01-14 01:14:28
藝術品鑒證.中國藝術金融(2018年10期)2019-01-08 02:44:26
藝術品鑒證.中國藝術金融(2018年12期)2018-08-26 06:03:48
藝術啟蒙(2018年7期)2018-08-23 09:14:18
海峽姐妹(2017年7期)2017-07-31 19:08:17
Coco薇(2017年5期)2017-06-05 08:53:16
