基于堆疊泛化的設計模式檢測方法*
2020-09-23 07:32:06張家晨王洪媛
軟件學報 2020年6期
馮 鐵 , 靳 樂 , 張家晨 , 王洪媛
1(吉林大學 計算機科學與技術學院,吉林 長春 130012)2(吉林大學 軟件學院,吉林 長春 130012)3(符號計算與知識工程教育部重點實驗室(吉林大學),吉林 長春 130012)
設計模式通過標識對象、對象間的合作及責任分配來揭示設計機理,表明基于某種經驗的、在特定的上下文中解決一個普遍設計問題的可復用體系結構[1,2].設計模式已經被廣泛地應用在各種軟件和工具庫的設計與實現中.設計模式檢測旨在從現有的軟件設計文檔或源代碼當中識別所使用的設計模式實例,它不僅對于幫助維護人員理解軟件系統的設計動機和原理、恢復軟件設計和改善軟件的可維護性具有重要意義,而且有助于軟件體系結構的恢復和發現,同時也是評估軟件質量的一個重要依據.
由于設計模式的應用大多是基于意圖的,并未嚴格限制模式的具體實現,加之不同開發者對于設計模式的理解不一,這使得模式的實現千變萬化.目前,設計模式檢測主要存在以下問題:(1) 變體的檢測效果不理想;(2) 結構相同意圖不同的模式難以區分;(3) 行為型設計模式的檢測復雜;(4) 組合爆炸問題依然突出.正是因為這些問題的存在,設計模式檢測仍然是軟件工程領域的一個重要的研究內容.
機器學習是人工智能領域的重要分支,它是使用經驗來提高計算性能或做出準確預測的計算方法[3].機器學習技術適用于設計模式檢測的原因如下:首先,設計模式檢測活動本身就是對眾多候選模式實例進行預測的過程,這符合機器學習的應用背景;其次,設計模式變體的檢測與機器學習無需硬編碼的特點相適應;最后,機器學習對語義信息的描述,有助于區分結構相同而意圖不同的模式.
對于行為型設計模式的檢測,目前主要的方法是借助于動態分析[4-6],但是動態分析一般要求目標項目完整可運行,這在實際中有時候是不可行的;另外,監控候選模式實例的運行需要生成相應的測試用例,如果手工生成,必然費時費力,如果自動生成,又難以做到有效的路徑覆蓋.如果能夠充分利用靜態代碼分析技術,將對模式的檢測研究深入到方法內部,并嘗試用機器學習的方式去刻畫模式的行為特征,就可以較大程度地降低行為型設計模式檢測的難度.
本文提出一種新的設計模式檢測方法,結合面向對象度量和模式微結構(以下簡稱度量和微結構)并使用典型的機器學習算法來實現設計模式的檢測.針對每種設計模式,本文分別用度量和微結構(micro-structure,簡稱MS)訓練出一個分類器,然后采用模型堆疊的方式訓練出最終的分類器,從而實現對該設計模式的檢測.
本文的主要貢獻如下:(1) 提出了用多視圖(設計模式度量視圖和設計模式微結構視圖)堆疊泛化的方法來解決設計模式檢測問題;(2) 定義了模式必備微結構來縮減搜索空間,從而避免組合爆炸問題;(3) 對于檢測出的模式實例,除給出角色映射外,還能給出具體的方法映射.最終實驗表明,本文提出的方法在變體的識別、行為型設計模式的檢測以及組合爆炸問題的解決等方面均有明顯提升.
本文第1 節介紹本文相關工作.第2 節定義度量和微結構以及相關的基本概念與原理.第3 節詳細介紹基于堆疊泛化的設計模式檢測方法.第4 節在5 種設計模式上進行實驗,通過實驗數據的對比分析,驗證所提方法的有效性.第5 節對本文的工作進行總結并對未來工作展望.
1 相關工作
自從GoF 等人提出軟件設計模式概念以來[1],許多學者對設計模式的自動化檢測進行了研究,提出了很多種設計模式檢測方法.這些方法在所用技術、分析類型、所面向的源代碼或模式的中間表示、是否精確匹配、是否完全自動化、是否面向特定模式、實驗的信息項和指標等方面各不相同.接下來,本文從所用技術方面對一些具有代表性的方法進行歸納和介紹.
有些設計模式檢測方法是基于相似度計算的[7,8].例如,Tsantalis 等人利用圖的相似性算法實現了設計模式的檢測[7],該方法不僅能夠識別模式變體,而且還能夠有效地解決模式檢測過程中的組合爆炸問題(利用了設計模式大都包含繼承層次這一事實).簡單來說,該方法將設計模式角色之間的各種關系用鄰接矩陣來表示,然后從源碼中提取所有的繼承層次,接著在模式查找階段,用繼承層次中的類去映射設計模式的各個角色,然后提取出這些角色類之間的各種關系矩陣,最后利用矩陣之間的相似性算法得到一個最終的相似度,如果相似度超過了事先選擇的閾值,那么就找到了一個設計模式實例.該方法的缺點是對某些行為型設計模式的檢測效果不好,同時空間復雜度也很高.
有些設計模式檢測方法是基于圖理論的[9-11].例如,Yu 等人從設計模式的子模式出發,將設計模式檢測問題映射為圖論中的圖同構問題[9].他們定義了十幾種能夠表示設計模式結構特征的子模式.對于一個待檢測系統,他們首先將系統源碼和子模式用類關系有向圖來表示,然后從系統源碼的類關系有向圖中找到和子模式的類關系有向圖同構的子圖,通過參照設計模式結構特征模型來組合這些子圖,從而得到候選模式實例.為了追蹤設計模式行為方面的特征,他們使用方法簽名模板來過濾不符合條件的候選模式實例.他們方法的缺點是沒有對子模式進行過濾,從而子模式挖掘和子模式組合的時間復雜度很高.另外,他們僅僅使用方法簽名來追蹤設計模式的行為特征,這顯然是不夠的.
還有一些設計模式檢測方法是基于本體的[12-14].例如,Dietrich 等人使用Web 本體語言(OWL)來形式化地定義設計模式和其相關概念[12].他們開發了一款原型工具,該工具以設計模式的形式化描述和待檢測的Java 項目為輸入,輸出待檢測項目中該設計模式的實例.由于該方法采用的是準確匹配,因此很難對設計模式的變體進行檢測.最后,他們提出可以去掉或弱化某些約束,從而實現模糊匹配,但是他們并未針對具體模式說明哪些約束可以被去掉或弱化.
最后,基于機器學習的設計模式檢測方法也有很多[15-17],其中具有代表性的檢測方法是下面3 個:
Alhusain 等人首次嘗試了只使用機器學習的方法來實現設計模式的檢測[15].他們的訓練數據集是由MARPLE[18],SSA[7],WOP[12],FINDER[19]等4 種模式檢測工具投票產生的.他們的模式檢測方案包括兩個階段:在第1 階段,他們通過特征選擇算法為每個模式角色選擇一個特征子集,然后根據該特征子集和相應的分類模型來確定每個模式角色的候選類,從而減小了模式的搜索空間;在第2 階段,每種設計模式都有一個單獨的分類器,該分類器使用表示角色類之間關系的特征作為輸入.最后他們在JHotDraw 項目上進行了實驗,但是結果并不是很理想.
Zanoni 等人也將機器學習技術應用到了設計模式檢測當中,他們開發了一個名叫MARPLE 的Eclipse 插件,該插件可以從Java 源代碼當中抽取設計模式[16].MARPLE 插件包括3 個主要模塊:(1) 信息檢測引擎,負責構建系統模型;(2) Joiner,負責從系統模型里面抽取設計模式候選實例;(3) Classifier,負責分類Joiner 的結果,把候選實例分類為正確的模式實例和錯誤的模式實例.他們為每種設計模式都找到了最佳的聚類算法和分類算法.他們方法的缺點是訓練數據集需要人工產生,而人工產生數據集會受主觀因素影響;Joiner 的召回率并不是100%;有效性和訓練集大小的關系有待進一步驗證;并未考慮系統庫和第三方庫中的代碼.
Chihada 等人從面向對象度量的角度給出了設計模式的檢測方法[17].他們的檢測方法分為兩個階段:設計模式組織階段和設計模式檢測階段.在設計模式組織階段,他們從專家那里獲取設計模式實例,然后通過實例計算特征向量,最終生成訓練數據集,并學習出分類器.在設計模式檢測階段,它們首先補充源碼圖(由類圖轉化而來),也即讓子類繼承父類的各種關系,然后從源碼圖中枚舉出候選實例,并從中過濾掉不包含抽象類或接口類的實例,然后用第1 階段的分類器進行分類,從而判斷候選實例是不是真正的模式實例.該方法的缺點是只考慮了設計模式的度量信息.
總體來講,上述工作在一定程度上解決了設計模式檢測問題,但或多或少存在前面提到的4 個問題.因此本文從這些問題出發,結合度量和微結構,提出了一種新的機器學習檢測方法.該方法不僅能夠提高變體的檢測效果,而且對組合爆炸問題的解決也有很大貢獻.同時,該方法嘗試從微結構的角度去刻畫模式的行為特征,對于行為型設計模式的檢測效果也有明顯提升.
2 面向對象度量與微結構
本節給出基于堆疊泛化的設計模式檢測方法相關的兩個概念(面向對象度量和微結構)的定義及表示方式,并列出了本文所使用的度量列表和微結構列表,著重定義了5 種方法類微結構以及相應的檢測方法.
2.1 面向對象度量
通過有效的特征選擇算法為每種設計模式找到合適的面向對象度量特征集,是基于堆疊泛化的設計模式檢測方法的重要步驟之一.面向對象度量通過定量地估算面向對象系統的設計特性,如類的繼承深度、對象間耦合、方法內聚程度等,來預測測試的復雜性、發現系統中的錯誤和促進軟件的模塊化,它在一定程度上衡量了軟件的設計質量.另一方面,設計模式是設計經驗的總結和提煉,設計模式實例的應用是改善設計質量的一個有效手段,從而針對設計模式實例的相關度量值也會呈現出一定的規律性.目前已經有許多學者利用面向對象度量進行了設計模式的檢測研究[17,20-22],這些度量包括C&K 度量[23]、Lorenz 度量[24]、Tegarden 度量[25]、Hitz&Montazeri 度量[26]以及Briand 度量[27]等.面向對象度量可以分為屬性級別的度量、方法級別的度量、類級別的度量(以下簡稱類度量)和系統級別的度量,用于設計模式檢測的主要是類級別的度量.
通過對GoF 的23 個設計模式的觀察和理解,表1 所示的面向對象度量在刻畫和標識設計模式實例方面具有重要作用,因此本文選擇表1 所示的69 種類度量并通過POM Tests 工具[21]來計算相應度量值.
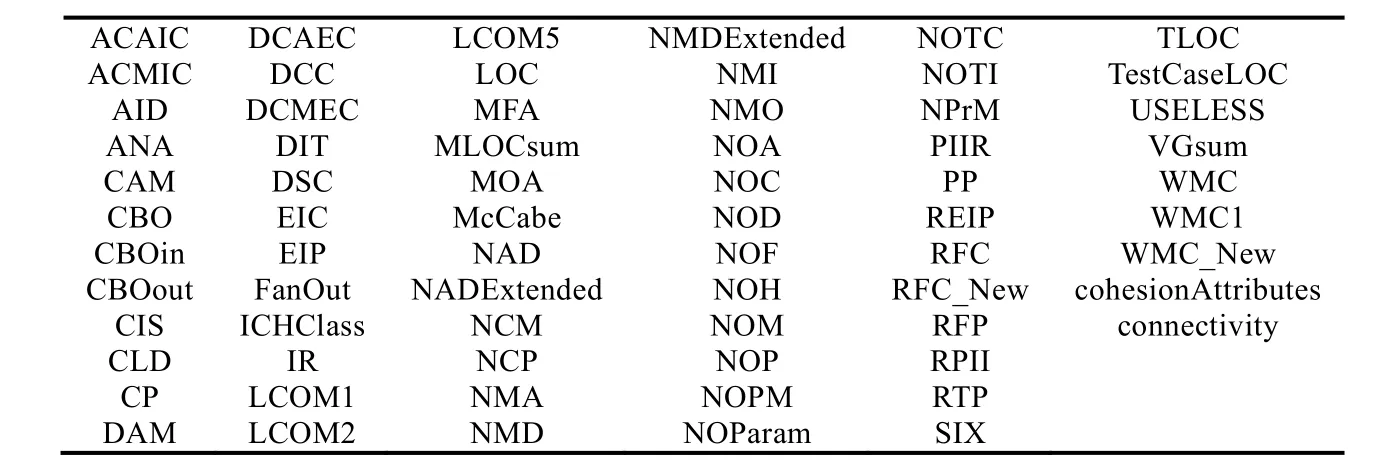
Table 1 Metrics used in this paper表1 本文選取的度量列表
舉例來講,AID 表示一個類的平均繼承深度(考慮多繼承),它可以用來衡量一個類的抽象程度.一般而言,設計模式中的抽象角色類都具有較小的AID 值.CBO 表示一個類和其他類之間的耦合程度,CBOin 表示入耦合,CBOout 表示出耦合,設計模式是設計經驗的總結和提煉,它的角色類之間一般不會有太高的耦合程度.NOC表示一個類的直接子類個數,NOC 越大,則代碼的重用越好,但是抽象性減弱.
定義 1(類度量表示(class metric representation),簡稱 CMR).類度量表示由一個三元組構成:CMR=(classA,metric,value).其中,classA表示某個具體的類,metric表示某個類度量,value表示classA的metric度量值.
2.2 微結構
設計模式微結構是指類或對象之間的靜態或動態關系,作為設計模式的組成部分,它具有更小的粒度,每個設計模式的意圖可以通過組合微結構的意圖進行表達.定義合理的特征選擇算法為每種設計模式找到微結構特征集,是基于堆疊泛化的設計模式檢測方法的另一個重要步驟.Fontana 等人認為,子模式[28]、元素模式[29]、微模式[30]以及他們自己所提出的設計模式線索[31]都屬于設計模式微結構范疇,并且也證實了微結構和設計模式檢測之間的密切關系[32].隨后,他們基于微結構給出了一種新的設計模式檢測方法[16].不過,雖然提出了微結構這一術語,但卻沒有給出明確的定義.同時,他們也認為現有的微結構對設計模式檢測來講并不是完備的.本文將對微結構進行了明確定義,并提出幾種新的微結構.
微結構可以分為兩種:方法類微結構和非方法類微結構.其中:方法類微結構描述設計模式中包含的方法方面的信息,比如子模式中的Overriding Method[28]、元素模式中的Create Object[29]以及設計模式線索中的Multiple Redirections in Family[31]等;而非方法類微結構描述設計模式的角色類以及相關屬性方面的信息,如Association,Inheritance,Private Self Instance 等.
定義2(微結構).表示類或對象之間的靜態或動態的關系,每個微結構由三元組表示:MS=(classA/instance,classB/instance,relationalMask).其中,classA/instance和classB/instance表示該微結構的兩個參與類或對象,而relationalMask表示它們之間的關系Mask值.對于方法類微結構,它是一個對應于classA/instance的比特向量,如果classA/instance的第n個方法和classB/instance之間體現了這種微結構關系,那么relationalMask的相應位置置1;對于非方法類微結構,若classA/instance和classB/instance存在這種微結構關系,則relationalMask置1.
為解決目前大多數基于機器學習的設計模式檢測方法只能給出角色映射,而不能給出具體方法映射的問題,在定義方法類微結構時,本文采用比特向量記錄相關微結構出現的位置和數目.一旦找到一個設計模式實例,就可以通過相關微結構元組中的比特向量以及它們之間的位運算來找到對應的方法映射.
圖1 所示的Java 代碼中包含了一個對象適配器模式的實例,其中,Contact 接口類扮演對象適配器模式的Target 角色,Employee 類扮演對象適配器模式的Adaptee 角色,ContactAdapter 類扮演對象適配器模式的Adapter角色.該模式實例中存在一個 Overriding Method 微結構(ContactAdapter,Contact,01011).其中,01011 表示ContactAdapter 的第2、第4 和第5 個方法是對Contact 的覆寫.該模式實例中還存在另一個Delegation 微結構(ContactAdapter,Employee,01010).其中,01010 表示ContactAdapter 的第2 和第4 個方法是對Employee 的委托.通過對這兩個微結構中的比特向量做與運算,也即01011&01010=01010,就能找到該對象適配器模式的方法映射.與運算值01010 表示ContactAdapter 的第2 和第4 個方法對應對象適配器模式的Request(·)方法.

Fig.1 An instance of object adapter pattern圖1 一個對象適配器模式的實例
定義3(微結構的維度(dimension of micro-structure)).指定微結構所關聯的類或對象的個數.對于定義2所定義的微結構,如果classA/instance與classB/instance相同,則稱該微結構的維度為1;否則,稱該微結構的維度為2.
定義4(返回類型微結構(return type)).如果類A中存在一個方法m,m的返回類型為類B,則稱類A到類B存在返回類型微結構.返回類型微結構可以表示為三元組(classA,classB,ReturnTypeMask),其中,ReturnTypeMask是對應于classA的比特向量,如果classA的第n個方法的返回類型為classB,那么ReturnTypeMask的相應位置置1.顯然,比特向量ReturnTypeMask的基數就是classA到classB的返回類型微結構的數目.
定義5(多通知微結構(multi-notify)).如果類A中存在某個包含循環的方法m,并且循環體內存在對類B的返回類型為空的方法的調用,則稱類A到類B存在多通知微結構.多通知微結構可以表示為三元組(classA,classB,MultiNotifyMask),其中,MultiNotifyMask是對應于classA的比特向量.如果classA的第n個方法的內部有一個循環,并且循環體內有對classB的返回類型為空的方法的調用,那么MultiNotifyMask的相應位置置1.
定義6(參數化通知微結構(parameterized notify)).如果類A的某個方法m內存在對類B的帶參數且返回類型為空的方法的調用,則稱類A到類B存在參數化通知微結構.參數化通知微結構可以表示為三元組(classA,classB,ParameterizedNotifyMask),其中,ParameterizedNotifyMask是對應于classA的比特向量.如果classA的第n個方法內有對類B的帶參數且返回類型為空的方法的調用,那么ParameterizedNotifyMask的相應位置置1.
定義7(參數依賴微結構(parameter dependence)).如果類A存在某個方法m,m的參數表中包含類型為類B的參數,則稱類A到類B存在參數依賴微結構.參數依賴微結構表示為三元組:
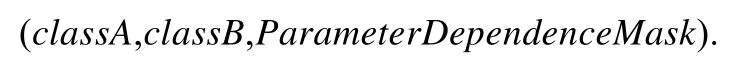
其中,ParameterDependenceMask是對應于classA的比特向量,如果classA的第n個方法的參數表中包含classB類型的參數,那么ParameterDependenceMask的相應位置置1.
定義8(返回靜態自身實例微結構(static self instance returned)).如果類A存在某個方法m,m的返回類型為staticclassA,則稱類A 存在返回靜態自身實例微結構.顯然,該微結構是針對單個類而言的1 維微結構.返回靜態自身實例可以表示為三元組:
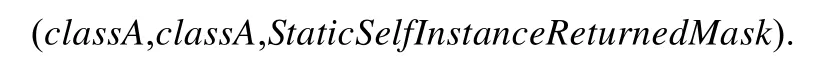
其中,StaticSelfInstanceReturnedMask是對應于classA的比特向量.如果classA的第n個方法的返回類型為static classA,那么StaticSelfInstanceReturnedMask的相應位置置1.
為了在工廠方法模式、單例模式、對象適配器模式、組合模式以及觀察者模式上進行實驗,本文初步選用了16 種微結構,具體情況見表2.

Table 2 Micro-structures used in this paper表2 本文選取的微結構列表
需要說明的是:本文微結構的檢測是在Java 字節碼級別上進行的,檢測工具使用了ASM 框架(一個Java 字節碼操作和分析框架).
3 設計模式檢測方法
本節首先給出該方法的總體框架,接著定義一些基本概念,然后利用定義好的概念對設計模式檢測過程中的算法進行形式化描述,最后提出一種新的組合爆炸問題的解決方法.
3.1 設計模式檢測框架
如圖2 流程所示(圖中某些概念見第3.2 節),設計模式檢測方法分為兩個階段:第1 個階段是模型訓練階段,第2 個階段是模式識別階段.基本思想是,結合度量和微結構進行設計模式檢測.通過為每種設計模式找到合適的度量分類器和微結構分類器,進而訓練出堆疊分類器,然后用這些分類器對一個候選的模式實例進行分類,從而預測候選的模式實例是不是真正的模式實例.
設計模式檢測相關的度量和微結構是設計模式的兩個獨立視圖,目前還無人提出同時考慮這兩個視圖的檢測方法.另外,因為每個視圖最適合的分類器可能不同,如果簡單地將兩個視圖的特征混合到一起之后再訓練出一個分類器,那么就有可能丟失這種差異性.因此,本文針對每個視圖單獨訓練分類器,然后再進行模型堆疊.

Fig.2 Design pattern detection method based on metrics and micro-structures圖2 度量和微結構相結合的設計模式檢測方法
3.2 基本概念定義
為了方便描述模型訓練算法和模式檢測算法,本文給出如下符號和定義:
設計模式(design pattern,簡稱DP).DP 是23 種基本的設計模式之一或未來出現的其他設計模式.后續算法將采用此標記.
定義9(角色映射(role map),簡稱RM).角色映射是一個設計模式角色和角色類之間的對應關系,可以表示為二元組RM=(Role,Class).
舉例來講,對于QuickUML2001 項目中存在的一個工廠方法模式實例,存在以下4 個角色映射:
定義10(模式實例(pattern instance),簡稱PI).模式實例包括角色映射集合RoleMaps和該實例的類別標簽Label,可以表示為PI=(RoleMaps,Label).其中,Label∈{CORRECT,INCORRECT}.Label=CORRECT表示該實例是一個正確的模式實例,或稱為正實例;Label=INCORRECT表示該實例不是一個正確的模式實例,或稱為負實例.
定義11(正負模式實例庫(positive and negative pattern instances repository),簡稱PNPIR).正負模式實例庫包括該實例庫對應的設計模式DP和該設計模式的正負實例的集合,可以表示為二元組:
定義12(度量知識庫(metrics repository),簡稱MR).度量知識庫是一個面向對象度量的集合.
舉例來講,本文采用的度量知識庫MR={ACAIC,ACMIC,AID,…,connectivity}(完整列表見表1).需要說明的是,度量知識庫并不是一成不變的,可以根據模式檢測的需要進行不斷地更新.
定義13(微結構知識庫(micro-structure repository),簡稱MSR).微結構知識庫是一個設計模式微結構的集合.
舉例來講,本文采用的微結構知識庫MSR={Overriding Method,Create Object,Return Type,…,Static Self Instance Returned}(完整列表見表2).需要說明的是,之所以選擇這么少的微結構,是因為本文想先在5 種設計模式上進行實驗,以驗證所提方法的有效性.未來為了檢測其他的設計模式,這個微結構知識庫肯定會包括更多的內容.
定義14(設計模式度量特征(design pattern metric feature),簡稱DPMF).設計模式度量特征是一個三元組,可以表示為DPMF=(Role,Metric,Value).其中:Role是設計模式的某個角色;Metric是度量知識庫中的某個度量;Value是該度量特征的具體數值,它等于角色Role對應的角色類的Metric度量值.
定義15(設計模式微結構特征(design pattern micro-structure feature),簡稱DPMSF).設計模式微結構特征是一個四元組,可以表示為DPMSF=(Role1,Role2,Microstructure,Value).其中:Role1 和Role2 是設計模式的的兩個角色;Microstructure是微結構知識庫中的某個微結構;Value是該微結構特征的具體數值,它等于Role1 對應的角色類→Role2 對應的角色類的Microstructure微結構的數目.
另外,本文是在Weka 平臺上進行實驗的,用到的特征選擇算法有CfsSubsetEval,CorrelationAttributeEval,InfoGainAttributeEval,PrincipalComponents 和ReliefFAttributeEval,用一個集合來表示:FSASet={CfsSubsetEval,CorrelationAttributeEval,InfoGainAttributeEval,PrincipalComponents,ReliefFAttributeEval}.
同時,采用RandomForest,LibSVM,J48 等15 種常見的有監督學習算法,用一個集合來表示:

3.3 3個模型訓練算法
在模型訓練階段,相關分類器的訓練算法可以描述如下.
度量分類器訓練算法以度量知識庫、某種設計模式以及相應的正負模式實例庫為輸入,通過為實例庫中的每個實例計算所有的度量特征,從而生成該設計模式的度量分類器的訓練數據集.最后,通過遍歷特征選擇算法和分類算法找到最適合該設計模式的度量特征集和度量分類器.具體算法見表3.

Table 3 Metric classifier train algorithm表3 度量分類器訓練算法
本文為設計模式dp的所有角色類計算所有的度量值.假設設計模式dp有n個角色,度量知識庫mr有m個度量,那么訓練數據集就有n×m個特征,外加一個分類標簽.CMeFV 以設計模式的角色類和度量為輸入,計算該角色類的相應度量特征值.第15 行的循環條件表示遍歷FSASet 和CASet,從而找到使得分類效果最好的特征選擇算法和有監督學習算法.其中,algo1 和algo3 分別表示某種特征選擇算法,它們以訓練數據集為輸入,通過在訓練數據集上進行特征選擇,輸出選擇的特征子集;algo2 和algo4 分別表示某種分類算法,它們以訓練數據集和特征子集為輸入,通過訓練,輸出相應的分類器.
f1Measureof(*)表示括號內分類器在CORRECT 類別上的F1-Measure值.
微結構分類器訓練算法以微結構知識庫、某種設計模式以及相應的正負模式實例庫為輸入,通過為實例庫中的每個實例計算所有的微結構特征,從而生成該設計模式的微結構分類器的訓練數據集.最后,同樣通過遍歷特征選擇算法和分類算法找到最適合該設計模式的微結構特征集和微結構分類器.具體算法見表4.
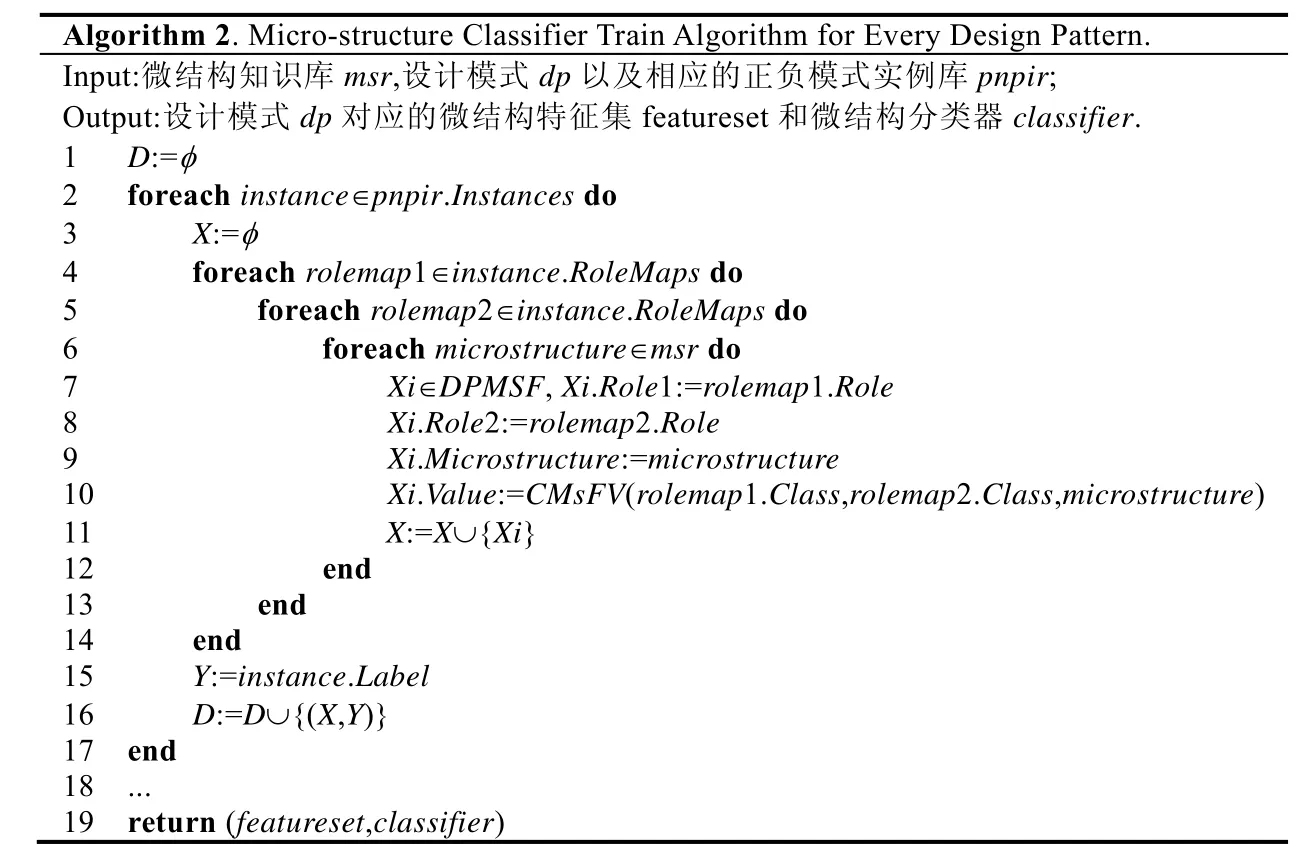
Table 4 Micro-structure classifier train algorithm表4 微結構分類器訓練算法
CMsFV 以設計模式的兩個角色類和微結構為輸入,計算這兩個角色類的相應微結構特征值.第18 行省略的部分同表3 的第14 行~第19 行.
堆疊分類器訓練算法以某種設計模式以及相應的正負模式實例庫、度量特征集、度量分類器、微結構特征集和微結構分類器為輸入,通過為實例庫中的每個實例計算相關的度量特征和微結構特征,從而生成該設計模式的堆疊分類器的初始訓練數據集;然后,通過十折交叉的方法計算每個樣本的度量分類器預測值和微結構分類器預測值,并將這兩個值作為新的特征添加到樣本當中;最后,通過遍歷分類算法找到最適合該設計模式的堆疊分類器.具體算法見表5.

Table 5 Stacked classifier train algorithm表5 堆疊分類器訓練算法

Table 5 Stacked classifier train algorithm (Continued)表5 堆疊分類器訓練算法(續)
CMeF 以設計模式的實例和度量特征為輸入,計算相應的設計模式度量特征;CMsF 以設計模式的實例和微結構特征為輸入,計算相應的設計模式微結構特征;RandDiv 以折數10 和訓練數據集為輸入,輸出隨機劃分的10個訓練數據子集;ReTrainClassifier 以度量/微結構特征集、度量/微結構分類器以及重新訓練用的數據集為輸入,利用度量/微結構分類器的分類算法重新訓練分類器;classify 以某個分類器和將要分類的樣本的特征向量為輸入,輸出相應樣本的類別標簽,也即CORRECT 或INCORRECT.第28 行省略的部分代表遍歷CASet,從而找到最適合設計模式dp的堆疊分類器classifier.
3.4 設計模式檢測算法
在模式識別階段,本文的設計模式檢測算法可以描述如下.
設計模式檢測算法以待檢測系統的所有類(包括接口)、待檢測的設計模式以及相應的度量特征集、度量分類器、微結構特征集、微結構分類器、堆疊分類器為輸入,首先計算系統所有類的度量信息和微結構信息,然后生成候選實例,接著對每個候選實例計算度量特征和微結構特征,然后分別用度量分類器和微結構分類器進行分類,最后將兩個分類器的預測結果作為新的特征再用堆疊分類器進行分類,從而預測候選實例是不是真正的模式實例.具體算法見表6.
CalcMe 以待檢測系統的所有類和設計模式的度量特征集為輸入,為每個類計算度量特征集中所涉及到的所有度量,輸出待檢測系統的度量信息,它可以看作是類度量表示(CMR)的集合;DetectMs 以待檢測系統的所有類和設計模式的微結構特征集為輸入,檢測微結構特征集中所涉及到的所有微結構,輸出待檢測系統的微結構信息,它可以看作是微結構的集合;GenCandIns 以待檢測系統的所有類以及待檢測的設計模式為輸入,通過執行本文的候選實例生成算法,輸出待檢測系統中相應設計模式的候選實例的集合;CMeF2/CMsF2 以候選實例、將要計算的度量特征/微結構特征以及待檢測系統的度量信息/微結構信息為輸入,通過簡單檢索,輸出相應候選實例的相應度量特征/微結構特征.
需要說明的是:為了避免組合爆炸,本文的候選實例生成算法在考慮設計模式繼承層次信息的基礎之上加入了一些自己的考量,它的過程可以簡單描述如下:(1) 從待檢測系統中檢測出所有的繼承層次;(2) 根據設計模式所包含的繼承層次信息,從待檢測系統中枚舉出候選模式實例;(3) 過濾掉那些不包含設計模式之必備微結構的候選實例(模式必備微結構是指正確模式實例必須具備的微結構,它是候選實例被評估為正確實例的必要非充分條件).本文是依據GoF 等人給出的定義以及經驗數據來定義模式必備微結構的,不會對設計模式檢測的正確率與召回率產生影響.舉例來講,對于工廠方法模式,GoF 等人給出的定義是,“定義一個用于創建對象的接口,讓子類決定實例化哪一個類.”[1].顯然,ConcreteCreator 對 Creator 的 Overriding Method 微結構和ConcreteCreator 對Product 類別的Create Object 微結構就是兩個必要的微結構,因為它們是工廠方法模式定義的隱含信息.

Table 6 Design pattern detection algorithm表6 設計模式檢測算法
以上便是本文所提方法的全部.為了豐富正負模式實例庫,可以對堆疊分類器的分類結果進行人工檢測,并把相應的實例添加到正負模式實例庫中.
4 實驗評估
為了評估所提方法的有效性,本文進行了相關實驗:在模型訓練階段,為實驗的每個設計模式找到了合適的度量特征集和微結構特征集,并在此基礎上訓練出了度量分類器、微結構分類器和堆疊分類器;在模式識別階段,在7 個開源項目上進行了實驗,并且和現有的兩種工具進行了對比分析.
4.1 模型訓練評估
目前可用的度量和微結構有很多,可以使用的分類算法也有很多.對于設計模式檢測這一問題,本文的思路是:盡可能生成更多的候選度量特征和候選微結構特征,然后再進行特征選擇和分類算法選擇,通過遍歷特征選擇算法和分類算法,從而為每種設計模式找到合適的特征集和分類器.現階段可用的模式實例庫主要包括P-MARt[33],DPB[34]和Percerons[35]等,本文通過抽取MARPLE 項目[16]中的訓練樣本和網絡搜集的一些訓練樣本構造正負模式實例庫.具體情況見表7.
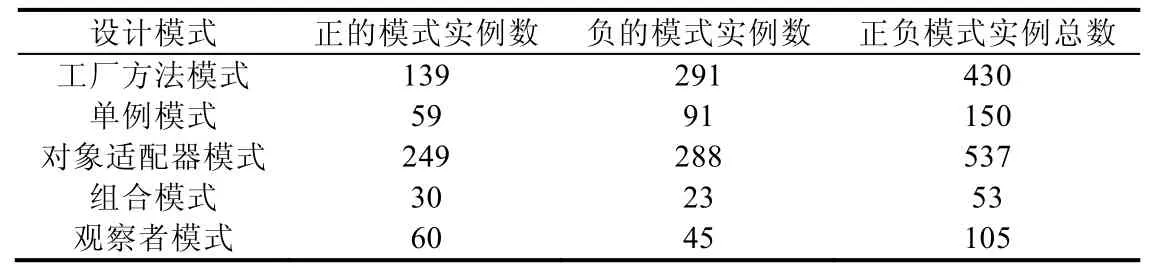
Table 7 PNPIR used in this paper表7 本文用到的正負模式實例庫的情況
在表7 中,正的模式實例數是指正確的模式實例個數,即正樣本的個數;負的模式實例數是指不正確的模式實例個數,即負樣本的個數.對于設計模式檢測來講,什么樣的正負樣本比例最合適,并沒有先驗的知識.本文正負模式實例的比例初步控制在1:3 以內.

Fig.3 Observer pattern[1]圖3 觀察者模式[1]
下面以觀察者模式為例,介紹特征選擇和算法選擇的結果.觀察者模式的類圖如圖3 所示.從圖3 中可以看出:觀察者模式應該有4 個角色,分別是Subject,ConcreteSubject,Observer,ConcreteObserver.但是在實際應用中,經常存在ConcreteSubject/ConcreteObserver 角色缺失或和相應的父類合并的情況.不過,無論如何總會有一個Subject 類別的角色和一個Observer 類別的角色,因此對于觀察者模式的檢測而言,可以只考慮一個Subject 類別的角色和一個Observer 類別的角色,從而如果找到了這樣一個組合,那么剩下缺失或合并的角色很容易就能通過檢查它們所在的繼承層次來發現.
表8~表10(只顯示前5 項數據)是觀察者模式3 個分類器的訓練結果.
從表8 可以看出:不進行特征選擇,并且使用RandomForest 算法進行模型訓練時,所取得的F1-Measure 最高.從表9 可以看出:使用ReliefFAttributeEval 進行特征選擇,并且使用RandomCommittee 算法進行模型訓練時,所取得的F1-Measure 最高.從表10 可以看出,觀察者模式的堆疊分類器應該采用RandomForest 算法.

Table 8 Training results of observer pattern’s metric classifier表8 觀察者模式度量分類器的訓練結果
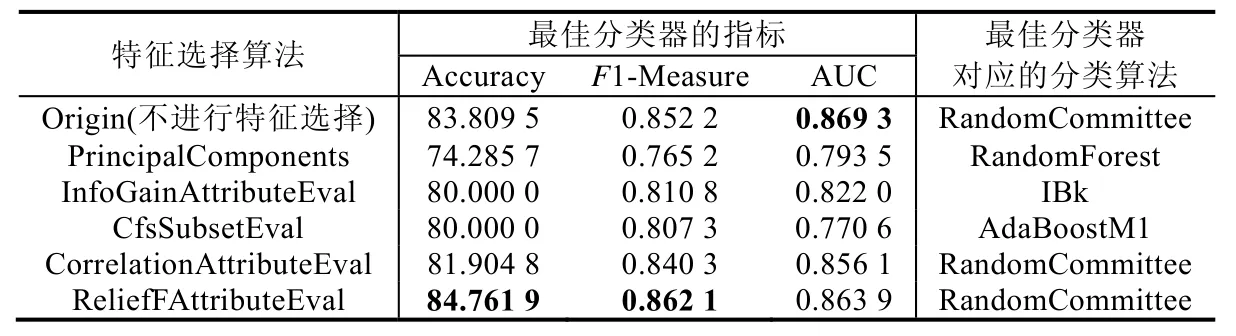
Table 9 Training results of observer pattern’s micro-structure classifier表9 觀察者模式微結構分類器的訓練結果

Table 10 Training results of observer pattern’s stacked classifier表10 觀察者模式堆疊分類器的訓練結果
表11 顯示了觀察者模式的微結構特征列表,它是對觀察者的候選微結構特征進行特征選擇的結果.另外,因為從表8 可以看出:在訓練度量分類器的時候,不進行特征選擇并且使用RandomForest 算法訓練時就已經取得了最好的分類效果,而且好于用CorrelationAttributeEval 進行特征選擇后再訓練的結果,所以這里并沒有給出觀察者的度量特征列表.從表11 可以看出:對于觀察者模式,它的微結構特征集包括14 個特征(表中的1 表示相應位置的微結構特征被選中).需要說明的是:在使用ReliefFAttributeEval 進行特征選擇時,本文使用0 作為ReliefF 評估值的閾值.另外,從表11 還可以看出:本文新提出的5 種方法類微結構中,有4 種與觀察者模式的檢測有關.
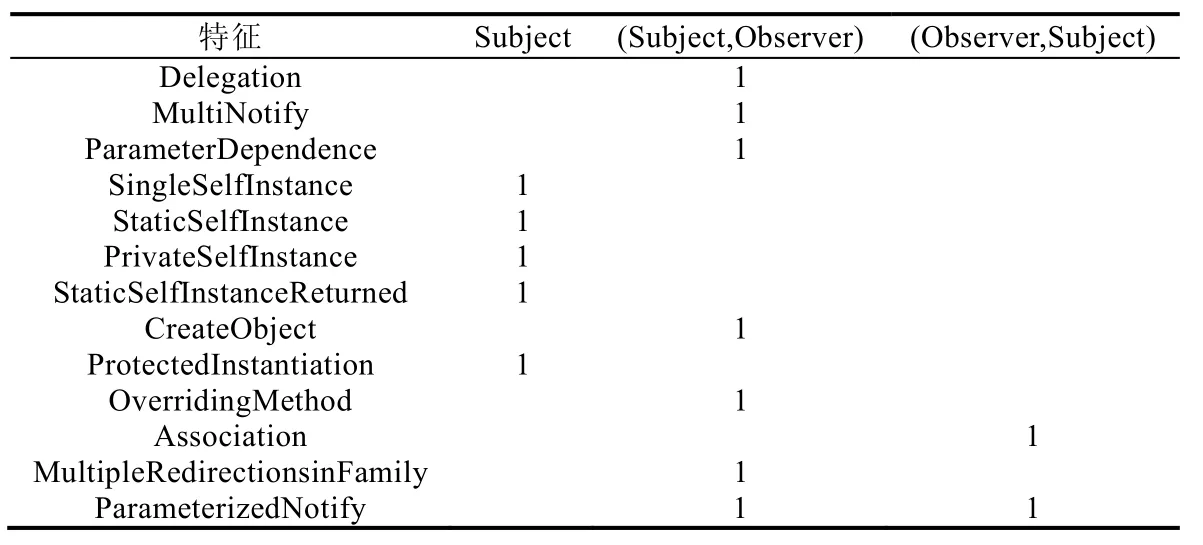
Table 11 List of micro-structure features of observer pattern表11 觀察者模式的微結構特征列表
4.2 模式識別評估
在模式識別階段:首先,對待檢測的系統進行預處理,也即計算待檢測系統的度量信息和抽取待檢測系統的所有微結構;其次,根據微結構信息生成候選實例;再次,計算候選實例的度量特征和微結構特征;最后,用相應的度量分類器、微結構分類器和堆疊分類器進行分類,從而預測一個候選實例是否為真正的模式實例.
本文首先在JHotDraw v5.1,JRefactory v2.6.24 和JUnit v3.7 這3 個開源項目上進行了實驗,正如第3 節所述,為了避免組合爆炸,本文在考慮設計模式繼承層次信息的基礎之上,加入了設計模式必備微結構的考量.對于工廠方法模式,具體情況見表12.

Table 12 Candidate instances of factory method pattern表12 工廠方法模式的候選實例的組合情況
假設待檢測項目有n個類,那么對于k個角色的設計模式,默認情況下,它總共有A(n,k)個候選實例.其中,A(n,k)的計算公式如下:

舉例來講,對于表12 中JhotDraw v5.1,它共有155 個類(不考慮內部匿名類),如果從中產生工廠方法模式(k=4)的候選實例,那么候選實例的個數=A(155,4)=555120720.可以看出:默認情況下,工廠方法模式的候選實例的數量非常大.在考慮工廠方法模式的繼承層次信息后,候選實例的數量減少到322 624,縮減了99%以上(具體過程見Tsantalis 等人的論文[7]);如果再考慮工廠方法模式的必備微結構信息(參見第3.4 節),那么候選實例的數量又會進一步縮減90%以上(最終只剩下4 301 個候選實例).
通常,每種設計模式都對應一個堆疊分類器.對于實驗的5 種設計模式,由于它們在結構上各不相同,因此都分別對應一個堆疊分類器(對于結構相同的設計模式,比如State 模式和Strategy 模式,未來我們準備讓它們共用一個堆疊分類器,訓練的方法和前面提到的差不多,稍加修改即可).模式檢測的過程也就是將一個個候選模式實例分類為CORRECT 或INCORRECT 的過程,因此是二分類問題,對應的混淆矩陣如下.

其中,a+b+c+d等于候選模式實例的個數.由于本文的目的是檢測出正確的模式實例,因此選擇CORRECT類別的準確率作為第一個度量指標,記準確率Precision=a/(a+c),相應的召回率Recall=a/(a+b)本應該作為第2個度量指標,但是考慮到生成的候選模式實例并不一定涵蓋所有正確的模式實例,同時也為了能夠在不同的設計模式檢測方法之間進行比較(基于機器學習的方法和非基于機器學習的方法),因此第2 個度量指標召回率Recall應該等于a/所有檢測方法檢測到的正確的模式實例個數.最后一個度量指標:
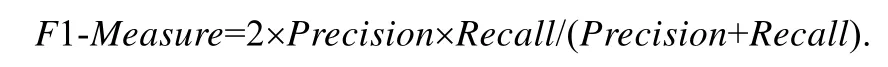
根據前面所提出的設計模式檢測方法,本文開發了設計模式檢測工具OOSdpd 的原型,并且在JHotDraw v5.1,JRefactory v2.6.24 和JUnit v3.7 這3 個開源項目上進行了實驗.之所以選擇這些項目,是因為這些項目大量使用了設計模式,特別是JHotDraw,同時很多設計模式檢測方法也都是以這3 個項目為例進行實驗的,這樣一來就比較容易對比分析.雖然目前有很多種設計模式檢測方法,但是提供檢測工具的卻很少,本文在P-MARt[33],SSA[7]和所提出的方法之間進行比較,具體實驗數據見表13~表15.

Table 13 Experimental data of the JHotDraw project表13 JHotDraw 項目的實驗數據

Table 14 Experimental data of the JRefactory project表14 JRefactory 項目的實驗數據

Table 15 Experimental data of the JUnit project表15 JUnit 項目的實驗數據
一般來講,不同的設計模式檢測方法針對同一項目、同一設計模式的檢測結果也不同,除了方法上的原因之外,還有一個重要的原因,那就是它們選擇的模式出現類型不同[36],也即計數模式實例的方法不同.因此,為了在不同的方法之間進行比較,本文使用如下模式出現類型:FactoryMethod:(Creator,Product),Singleton:(Singleton),Adapter:(Target,Adapter),Composite:(Component,Composite),Observer:(Subject,Observer).另外需要說明的是:P-MARt 和SSA 這兩種檢測方法并不是基于機器學習的,它們的準確率Precision=檢測出的實例中正確的個數/檢測出的實例的總個數,召回率Recall=檢測出的實例中正確的個數/所有檢測方法檢測到的正確的模式實例個數,F1-Measure=2×Precision×Recall/(Precision+Recall).
從表13~表15 的實驗數據來看,本文的方法多數情況下具有較高的準確率和召回率,其中,總數指的是所有檢測方法檢測到的正確的模式實例個數.從圖4 可以看出:對于工廠方法模式、單例模式和對象適配器模式,本文的方法具有更高的F1-Measure(該值是3 個項目的平均值).對于組合模式,3 種方法的檢測結果一樣,因此它們的F1-Measure 也一樣.這是因為實驗的項目中,組合模式的實例很少,每個項目最多只有一個,3 種方法都能輕松應對.對于觀察者模式,本文的方法的F1-Measure 高于SSA,但是比P-MARt 稍低,這主要是因為本文的方法目前尚不支持部分角色類存在于第三方庫中的情況.另外,P-MARt 和SSA 的準確率也并非總是100%的.舉例來講,對于JHotDraw v5.1 中的單例模式,P-MARt 和SSA 都檢測出了兩個單例模式實例CH.ifa.draw.util.Clipboard 和CH.ifa.draw.util.Iconkit,但是本文的方法只檢測到了一個模式實例 CH.ifa.draw.util.Clipboard.實際上,雖然CH.ifa.draw.util.Iconkit 很像單例模式,但它并不是,因為它有一個訪問權限為public 的構造函數,因此它不符合單例模式的要求.

Fig.4 Comparison of detection results on different design patterns圖4 不同設計模式檢測效果對比
圖5 顯示了不同檢測方法針對不同開源項目的檢測效果.需要說明的是:這里的AverageF1-Measure代表對于某個開源項目,5 種設計模式檢測結果的F1-Measure的平均值.從中可以看出:本文的方法多數情況下檢測效果最好,只有在JUnit v3.7 項目上弱于P-MARt.其主要原因還是上面提過的,觀察者模式的檢測效果不如P-MARt.另外,對于SSA 和本文的方法,JHotDraw v5.1 的檢測效果最好,可能的原因有兩個:(1) JHotDraw v5.1 的模式實例占比(模式實例數/項目總類數)更高;(2) JHotDraw 起源于Gamma 的一個教學實例,而他是軟件設計模式概念的提出者之一.最后,從檢測效果的穩定性來看,SSA 和本文的方法更加穩定,而P-MARt 針對不同項目的檢測效果差別很大.

Fig.5 Comparison of detection results on different open source projects圖5 不同開源項目檢測效果對比
上面實驗的項目規模都比較小,而且目前大部分設計模式的檢測研究都集中在這3 個項目上.為了驗證本文的方法在其他項目上的有效性,以及觀察有效性隨著項目規模的變化情況,本文又在ASM v1.4.2(59 個類),Dom4j v1.6.1(189 個類),Guice v3.0(425 個類)和Struts v2.5.14.1(2 742 個類)等4 個開源項目上進行了實驗.其中,ASM 是常用的Java 字節碼操作框架,Dom4j 是十分優秀的XML 解析包,Guice 是幫助代碼實現控制反轉的函數庫,Struts 是基于MVC 的Web 框架.具體實驗數據見表16~表19.
由于P-MARt 實際上是人工標注的實例庫,并沒有提供可用的檢測工具,因此本文的方法只和SSA 工具進行對比.需要說明的是:為了統計方便,對象適配器模式采用了Adapter:(Adapter)模式出現類型.

Table 16 Experimental data of the ASM project表16 ASM 項目的實驗數據

Table 17 Experimental data of the Dom4j project表17 Dom4j 項目的實驗數據
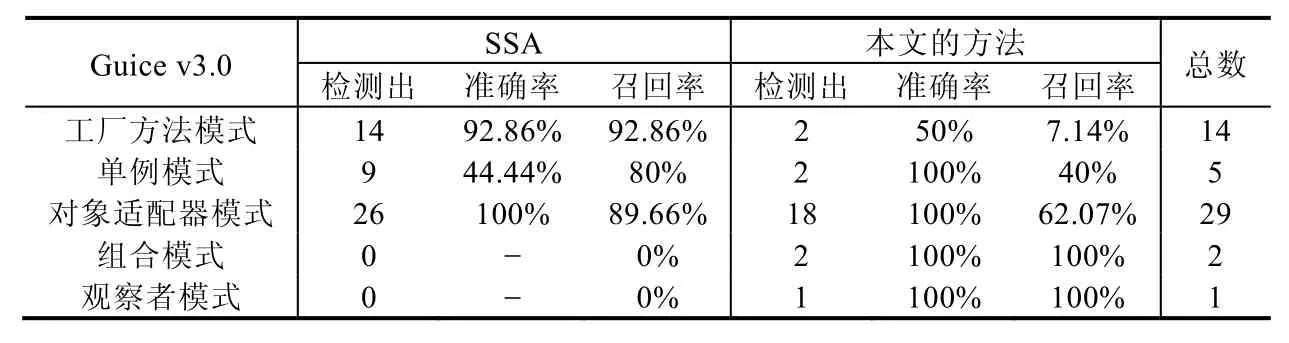
Table 18 Experimental data of the Guice project表18 Guice 項目的實驗數據
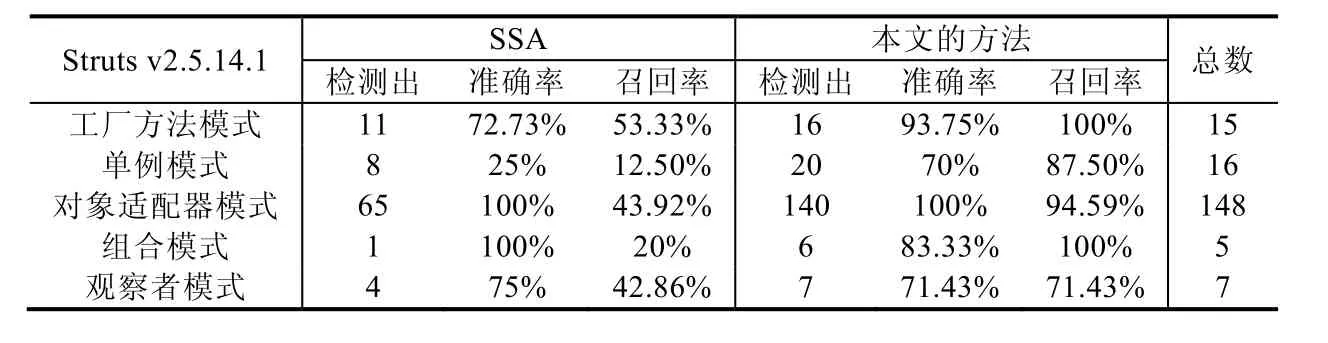
Table 19 Experimental data of the Struts project表19 Struts 項目的實驗數據
從表16 可以看出,本文的方法只在單例模式上弱于SSA.從表17 可以看出,本文的方法在實驗的5 種設計模式上均好于SSA.從表18 可以看出,本文的方法在工廠方法模式上明顯弱于SSA.這主要是因為Guice v3.0 項目中包含了很多內部類實現的工廠方法模式,而本文的方法用的POM Tests 度量計算工具并不支持內部類,因此許多實例沒有檢測出來;另外,對于單例模式,和SSA 相比,本文的方法準確率高,但是召回率低,不過兩者的F1-Measure非常接近.從表19 可以看出,本文的方法在所有模式上均好于SSA.
圖6 顯示的是每種設計模式的平均檢測效果,從中可以看出:本文的方法只在單例模式上弱于SSA,但是差距并不明顯;在組合模式和觀察者模式上,本文的方法明顯好于SSA,這主要是因為本文的方法使用了更多能夠體現模式結構和行為特征的微結構信息.圖7 顯示的是針對不同項目規模,SSA 和本文的方法在5 種設計模式上的平均檢測效果對比,從中可以看出:對于不同規模的項目,本文方法的檢測效果和SSA 的檢測效果都有一定的波動,但是本文方法的檢測效果更加穩定.另外,對于規模比較小的項目(ASM v1.4.2 和Guice v3.0),本文的方法和SSA 相比優勢并不明顯;但是對于規模比較大的項目(Struts v2.5.14.1),本文的方法要明顯好于SSA.因此,從實驗數據來看,本文的方法更加適合規模比較大的項目.
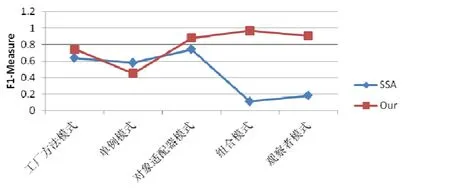
Fig.6 Comparison of detection results on different design patterns圖6 不同設計模式檢測效果對比
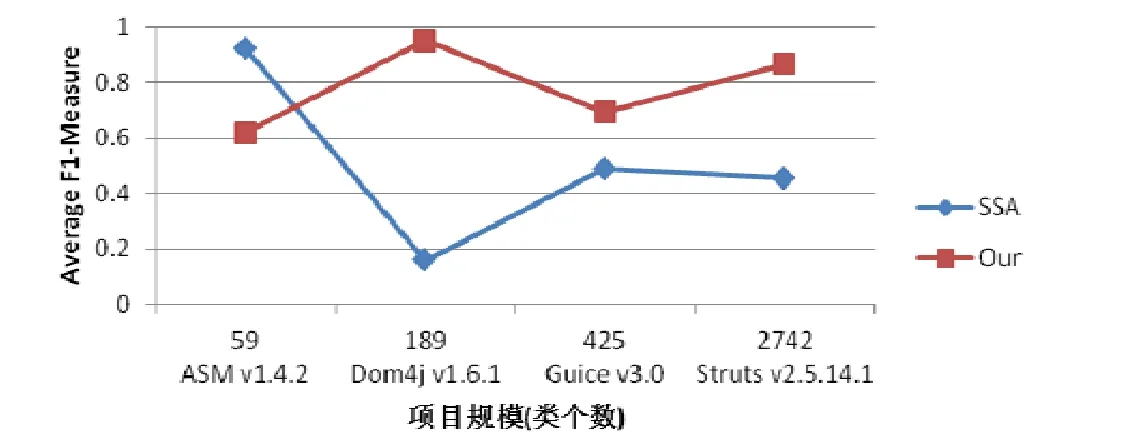
Fig.7 Comparison of detection results on different project scale圖7 不同項目規模檢測效果對比
通過以上兩組對比實驗可以看出,本文的方法和P-MARt 以及SSA 相比,多數情況下具有更高的識別準確率和召回率.對于單例模式,本文的方法還需要進一步改進.對于觀察者模式,本文的方法的檢測效果要明顯好于單純基于結構相似度計算的SSA.
雖然目前有很多種基于機器學習的設計模式檢測方法,但是我們沒能找到任何一款可用的檢測工具,而且這些方法多數也沒有指明所采用的模式出現類型,因此很難以拿本文的方法與它們進行比較.
4.3 有效性分析
影響外部有效性的因素主要有以下3 點.
1)與其他基于機器學習的檢測方法一樣,本文的訓練數據集也是由人工產生的,這就會受到主觀因素的影響.因此,需要找到一個廣泛認可的設計模式實例庫作為訓練數據集的來源;
2)本文以工廠方法模式為例,定義了它的兩個必備微結構,從而顯著地縮減了候選實例的搜索空間,避免了組合爆炸.但是對于其他設計模式,定義模式必備微結構對避免組合爆炸的有效程度還需要進一步研究;
3)雖然本文在觀察者模式上取得了更好的檢測效果,但是對于其他行為型設計模式的檢測效果還需要進一步驗證.
影響內部有效性的因素主要有以下兩點:(1) 由于訓練樣本不夠豐富以及所采用的度量知識庫和微結構知識庫不夠完備,本文提出的方法對單例模式的檢測效果還不夠理想,不足以驗證所提方法的有效性;(2) 如果模式實例中含有部分存在于第三方庫中角色類,本文的方法無法準確檢測,需要進一步研究如何將第三方庫中的有效信息加載到檢測目標項目中.
5 總結與展望
針對目前設計模式檢測方法的研究中存在的若干問題,本文提出了一種基于機器學習的設計模式檢測方法.首先,針對模式實例變體檢測效果不理想的問題,本文利用面向對象度量特征和微結構特征進行基于堆疊泛化的學習,實驗結果表明,對變體的檢測效果有較大改善;其次,針對行為型設計模式的檢測復雜和難以實現的問題,本文從微結構的角度追蹤行為型設計模式的行為特征,對于觀察者模式,相較于SSA 等經典方法取得了更高的F1-Measure值;再次,針對設計模式檢測中的發生的組合爆炸問題,本文在考慮設計模式繼承層次信息的基礎之上,加入特定的設計模式微結構的考量,從而進一步縮減了模式的搜索空間.
具體地講,本文采用機器學習的方式分別從度量和微結構兩個視圖訓練分類器,然后采用模型堆疊的方式訓練出最終的分類器.在幾個開源項目上的實驗表明:本文的方法相對于P-MARt 和SSA 來講,具有更好的模式檢測效果.
在未來工作中,本文將從如下幾個方面進行改進和擴展.
(1) 本文應用比特向量表示方法類微結構的位置和數目,并通過比特向量及其位運算識別設計模式的方法映射.在未來工作中我們會將這些位置信息也輸入分類器,更充分地利用微結構的位置信息,從而更加準確地追蹤設計模式的行為特征;
(2) 找到更為廣泛認可的設計模式實例庫作為訓練數據集的來源,從而提高設計模式檢測的準確率;
(3) 進一步研究將第三方庫中的有效信息加載到檢測目標項目中的方法并完善度量知識庫和微結構知識庫,從而提高設計模式檢測方法的可用性.
猜你喜歡
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
海峽科技與產業(2016年3期)2016-05-17 04:32:12
Coco薇(2016年2期)2016-03-22 02:42:52
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年4期)2015-05-19 14:47:56
